摘要:隨著大型語言模型(LLMs)的迅速發展,對其輸出進行準確反饋和可擴展監督成為一個迫切且關鍵的問題。利用LLMs作為批評模型以實現自動化監督是一個有前景的解決方案。在本研究中,我們專注于研究并提升LLMs在數學批評方面的能力。當前的LLM批評模型在每個步驟上提供的批評過于膚淺和表面化,導致判斷準確度低,且難以提供足夠的反饋來幫助LLM生成器糾正錯誤。為解決這一問題,我們提出了一個新穎且有效的兩階段框架,用于開發能夠針對數學解決方案的每個推理步驟進行深思熟慮的批評的LLM批評模型。在第一階段,我們利用Qwen2.5-72B-Instruct生成4500條長篇批評作為監督微調的種子數據。每條種子批評包含對每個推理步驟的深思熟慮的分步批評,包括多角度驗證以及對初始批評的深入批評。然后,我們使用強化學習對微調后的模型進行訓練,使用PRM800K中現有的人工標注數據或通過基于蒙特卡洛抽樣的正確性估計獲得的自動標注數據,以進一步激勵其批評能力。我們基于Qwen2.5-7B-Instruct開發的批評模型不僅在各種錯誤識別基準測試中顯著優于現有的LLM批評模型(包括相同大小的DeepSeek-R1-distill模型和GPT-4o),而且通過更詳細的反饋更有效地幫助LLM生成器完善錯誤步驟。
本文目錄
一、背景動機
二、實現方法
3.1 監督式微調(階段一)
3.2 強化學習(階段二)
四、實驗結論
4.1 性能提升
4.2 測試時擴展性
4.3 弱監督潛力
五、總結
一、背景動機
論文題目:DeepCritic: Deliberate Critique with Large Language Models
論文地址:https://arxiv.org/pdf/2505.00662
當前使用LLM critics 可以生成對 LLM 生成內容的批判,識別其中的缺陷和錯誤,幫助 LLM 生成器改進輸出,從而實現自動監督和持續改進。然而,現有的 LLM critics 在復雜領域(如數學推理任務)中表現出的批判能力有限,其生成的批判往往過于膚淺,缺乏批判性思維,無法提供準確可靠的反饋。例如,它們通常只是重復原始推理步驟的內容,而不是對其進行深入的批判性分析,導致批判結果不準確且缺乏指導性。
該文章提出了一個名為 DeepCritic 的新型兩階段框架,用于開發能夠對數學解題過程的每個推理步驟進行深入批判的 LLM critics。實驗結果表明,基于 Qwen2.5-7B-Instruct 開發的 DeepCritic 模型在多個錯誤識別基準測試中顯著優于現有的 LLM critics(包括同尺寸的 DeepSeek-R1-distill 模型和 GPT-4o),并且能夠通過更詳細的反饋更有效地幫助 LLM 生成器修正錯誤步驟。

二、實現方法
3.1 監督式微調(階段一)
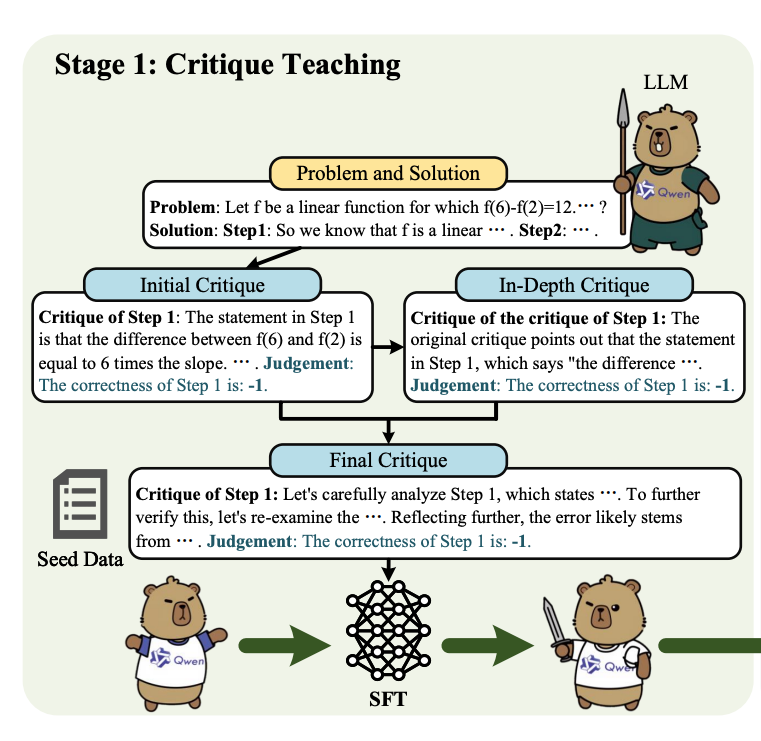
- 初始批判生成:從 PRM800K 數據集中采樣一小部分標注數據作為種子任務輸入,利用 Qwen2.5-72B-Instruct 為每個推理步驟生成初始批判。
-
對于每個步驟,模型生成一個批判和一個判斷結果,表示該步驟的正確性。
-
生成過程是獨立的,即每次只針對一個步驟進行批判,而不是直接生成整個解決方案的批判。
-
生成的初始批判通常較為簡略,主要跟隨原始推理步驟的邏輯進行驗證。
-
- 深入批判生成:基于初始批判,進一步生成深入批判,從不同角度驗證推理步驟的正確性,或對初始批判本身進行批判性分析。
-
基于問題 P、解決方案 S 和初始批判,再次利用 Qwen2.5-72B-Instruct 模型生成深入批判和判斷結果。
-
深入批判的目標是從不同角度驗證推理步驟的正確性,或對初始批判本身進行批判性分析,以發現初始批判中的潛在錯誤。
-
- 最終批判合成:將初始批判和深入批判合并為一個長篇批判,形成完整的解決方案批判。
-
利用 Qwen2.5-72B-Instruct 模型,將初始批判和深入批判合并為一個最終批判 cfinali?。
-
合并過程中,模型會添加一些過渡性的、反思性的語句,使批判內容更加連貫和深入。
-
最終批判不僅包含對每個步驟的詳細分析,還可能包含對初始批判的修正和補充。
-
- 監督微調:使用上述生成的批判數據對目標模型進行監督式微調,使模型能夠進行多視角評估和自我反思。
3.2 強化學習(階段二)
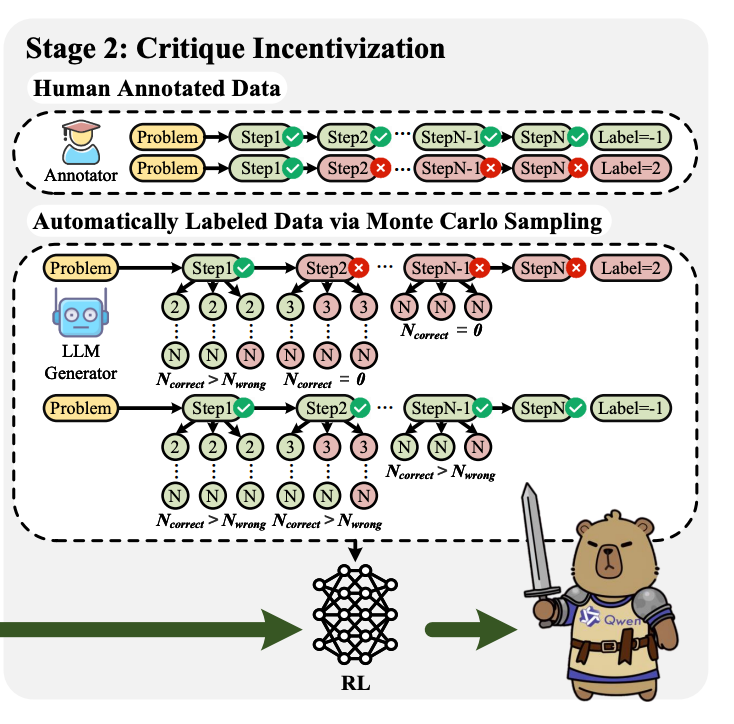
- 數據準備
-
人類標注數據:如果現成的人類標注數據可用(如 PRM800K),直接使用這些數據進行強化學習。
-
自動標注數據:如果沒有人類標注數據,通過蒙特卡洛采樣估計每個推理步驟的正確性,自動生成標注數據。
-
對于每個問題,生成多個逐步解決方案,并通過蒙特卡洛采樣估計每個步驟的正確性。
-
如果某個步驟在大多數采樣路徑中都被認為是錯誤的,則將其標注為錯誤;否則標注為正確。
-
-
- 強化學習優化
-
獎勵機制:如果模型的最終判斷結果正確,則給予獎勵 1.0;否則給予獎勵 0.0。
-
訓練目標:通過強化學習,進一步提升模型的批判能力,使其能夠更準確地識別錯誤并提供詳細反饋。
-
四、實驗結論
4.1 性能提升
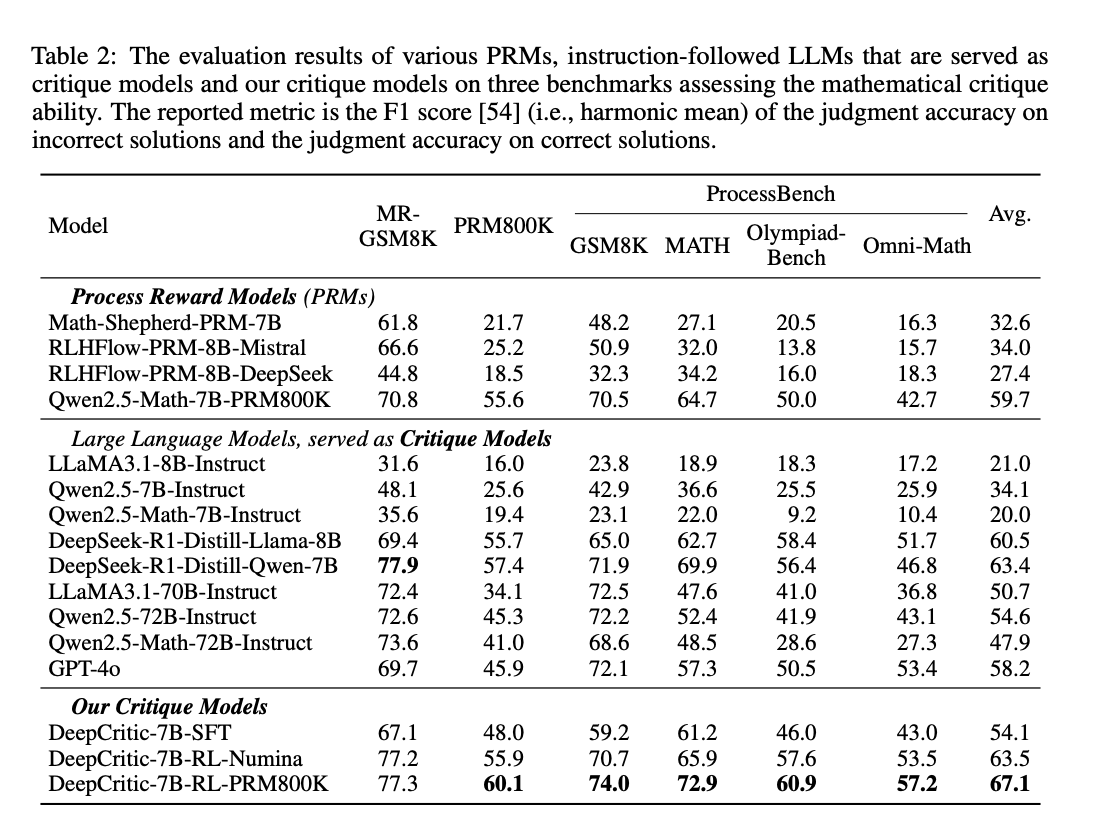
DeepCritic 在多個錯誤識別基準測試中顯著優于現有的 LLM critics 和過程獎勵模型(PRMs),在 6 個測試集中有 5 個測試集的性能超過了 GPT-4o 和其他基線模型。如在 MR-GSM8K 數據集上,DeepCritic-7B-RL-PRM800K 的 F1 分數達到了 77.3%,顯著高于其他基線模型,如 Qwen2.5-7B-Instruct(48.1%)和 GPT-4o(69.7%)。
4.2 測試時擴展性
DeepCritic 在測試時表現出良好的擴展性。通過增加測試時的采樣次數,批判模型的判斷準確性一致提高,如使用 8 次采樣的多數投票(Maj@8)將 DeepCritic-7B-RL-PRM800K 的 F1 分數從 77.3% 提升到 78.7%。
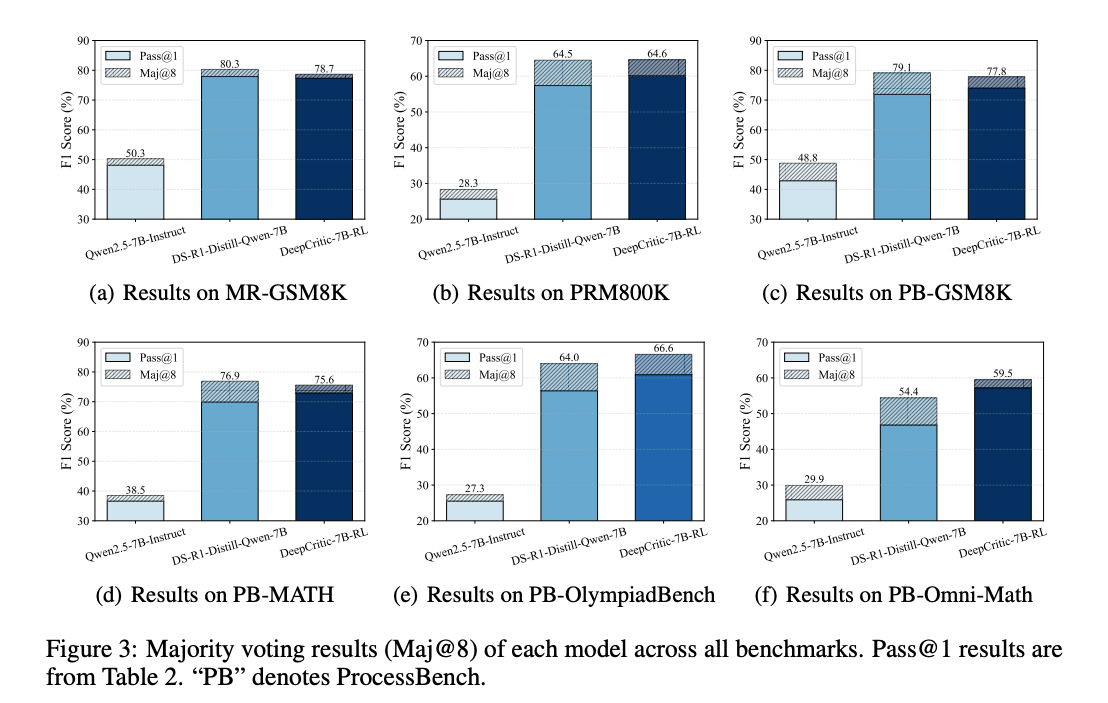
DeepCritic 通過提供詳細反饋幫助 LLM 生成器修正錯誤,有效提升 LLM 生成器的性能,在 MATH500 數據集上,使用 DeepCritic 的反饋進行修正后,Qwen2.5-7B-Instruct 的準確率從 74.0% 提升到 77.2%
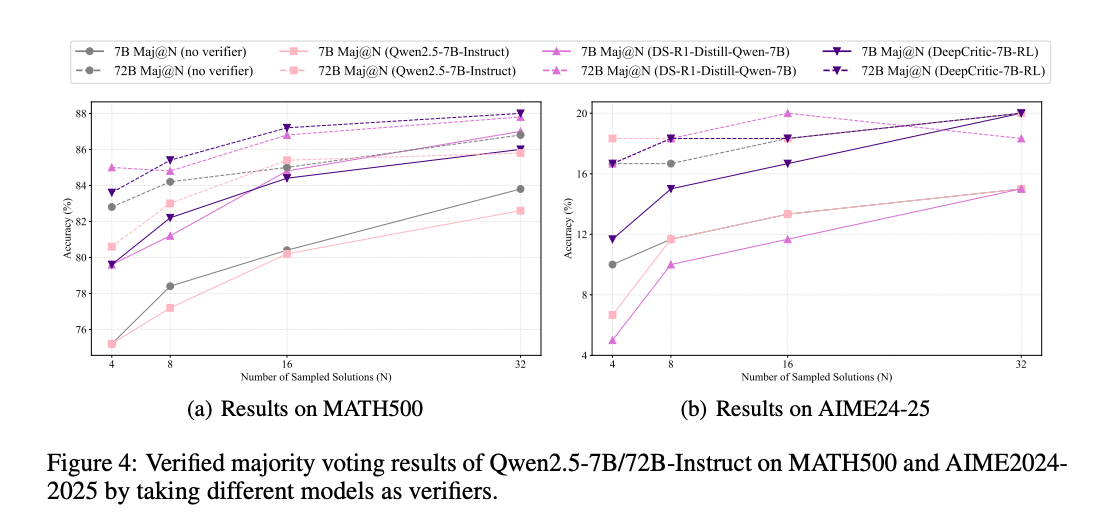
4.3 弱監督潛力
DeepCritic 展示了弱監督的潛力,在 MATH500 數據集上,DeepCritic-7B-RL 能夠有效監督 Qwen2.5-72B-Instruct 的輸出,幫助其修正錯誤,提升整體性能。
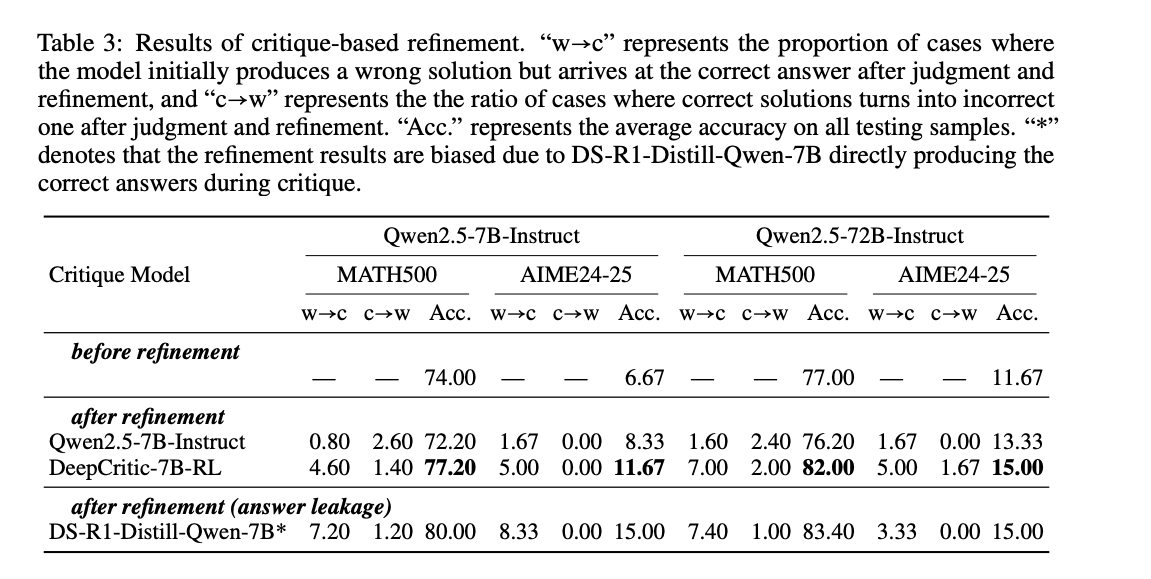
五、總結
文章提出了一種有效的兩階段訓練范式,通過監督式微調和強化學習顯著提升了 LLMs 的數學批判能力。DeepCritic 模型不僅在多個基準測試中表現出色,還展示了在測試時擴展和弱監督方面的潛力。












解決方案)




![2025年滲透測試面試題總結-小鵬[實習]安全工程師(題目+回答)](http://pic.xiahunao.cn/2025年滲透測試面試題總結-小鵬[實習]安全工程師(題目+回答))

