【論文速讀】利用負信號蒸餾:用REDI框架提升LLM推理能力
論文信息
arXiv:2505.24850 cs.LG cs.AI cs.CL
Harnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning
Authors: Shuyao Xu, Cheng Peng, Jiangxuan Long, Weidi Xu, Wei Chu, Yuan Qi
一、研究背景:被浪費的“錯誤寶藏”
想象你在學數學題,老師只給你看正確解答,卻從不講解錯誤思路為啥錯——這時候你可能會疑惑:“我怎么知道自己哪里容易踩坑?”
大語言模型(LLM)的蒸餾訓練就面臨類似問題。傳統方法(如拒絕采樣)只保留老師模型生成的正確推理痕跡(正樣本),扔掉錯誤推理痕跡(負樣本)。但這些負樣本里藏著大量“避坑指南”:比如模型常犯的邏輯錯誤、邊界條件遺漏等。
舉個例子,在數學推理中,老師模型可能試過錯誤的公式套用或步驟順序,這些失敗案例對小模型學習“如何避免犯錯”至關重要。但現有方法白白浪費了這些信息,導致小模型只能“學正確答案”,卻“不懂錯誤根源”,推理能力提升有限。
二、創新點:讓錯誤成為“學習信號”
這篇論文的核心突破是:首次系統利用負樣本進行強化蒸餾,提出兩階段框架REDI(Reinforcement Distillation),解決了三大問題:
- 負樣本利用率低:傳統方法丟棄負樣本,REDI將其轉化為可學習的損失信號。
- 穩定性與性能的矛盾:現有方法(如DPO)依賴KL散度正則化,高正則化雖穩定但限制性能,低正則化則容易訓練崩潰。REDI通過非對稱加權損失(α參數)平衡兩者,既避免崩潰又提升峰值性能。
- 數據效率低下:用更少數據(131k正負樣本)超越需800k專有數據的模型,開源數據也能訓出SOTA。
三、研究方法和思路:兩步走的“糾錯學習法”
階段1:用正確答案打基礎(SFT)
- 目標:讓小模型先學會“正確推理的樣子”。
- 方法:用正樣本(老師的正確推理痕跡)進行監督微調(SFT),優化目標是最大化生成正確痕跡的概率:
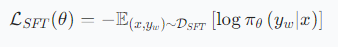
- 作用:建立基礎推理能力,作為后續優化的起點。
階段2:用錯誤答案做強化(REDI目標函數)
- 目標:讓小模型學會“識別錯誤”,避免重復老師的失誤。
- 方法:引入負樣本,設計非對稱加權損失函數,同時優化兩個方向:
-
最大化正樣本概率:讓正確推理更可能被生成。
-
最小化負樣本概率:抑制錯誤推理,但通過參數α降低負樣本的梯度權重(α∈[0,1]),避免過度懲罰導致模型“不敢推理”。
損失函數:
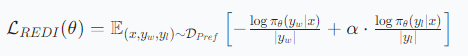
-
α的作用:α=1時等價于對稱損失(易崩潰),α=0時退化為僅用正樣本。實驗發現α=0.8時平衡最佳。
-
實驗驗證:小數據也能超越大廠模型
- 數據:從Open-R1數據集提取78k正樣本(D_SFT)和53k正負樣本對(D_Pref),總數據量131k。
- 對比模型:
- 基線:SFT(僅正樣本)、SFT+DPO/SimPO(傳統強化方法)。
- 競品:DeepSeek-R1-Distill-Qwen-1.5B(用800k專有數據訓練)。
- 結果:
- Qwen-REDI-1.5B在MATH-500基準上達到83.1%準確率(pass@1),超過DeepSeek-R1-Distill-Qwen-1.5B的83.2%,且數據量僅為其1/6。
- 消融實驗顯示,REDI的非對稱加權比對稱損失(α=1)更穩定,比DPO/SimPO性能提升1-2%。
四、主要貢獻:三大突破推動LLM蒸餾
- 方法論創新:提出REDI框架,首次在離線蒸餾中有效利用負樣本,打破“負樣本=無用數據”的固有認知。
- 性能提升:用開源數據實現1.5B模型SOTA,數據效率提升6倍,為小團隊和開源社區提供低成本方案。
- 理論分析:揭示DPO等方法中KL正則化的“性能-穩定性”矛盾,為未來損失函數設計提供方向。
五、總結:錯誤是最好的老師
這篇論文證明,LLM的“錯誤”不是垃圾,而是珍貴的學習信號。REDI通過“先學對、再辨錯”的兩步法,讓小模型既能掌握正確推理模式,又能識別常見錯誤,實現了推理能力的跨越式提升。更重要的是,其數據高效性(131k樣本)和開源友好性(基于Open-R1),讓更多研究者能復現和改進,推動LLM推理能力向低成本、高效化方向發展。
未來,REDI框架可進一步與在線RL結合,形成“離線蒸餾+在線優化”的完整鏈路,或許能解鎖更復雜的推理場景——畢竟,連錯誤都能被利用的模型,才是真正“會學習”的模型。










、業務架構設計、投標任務)





)


