?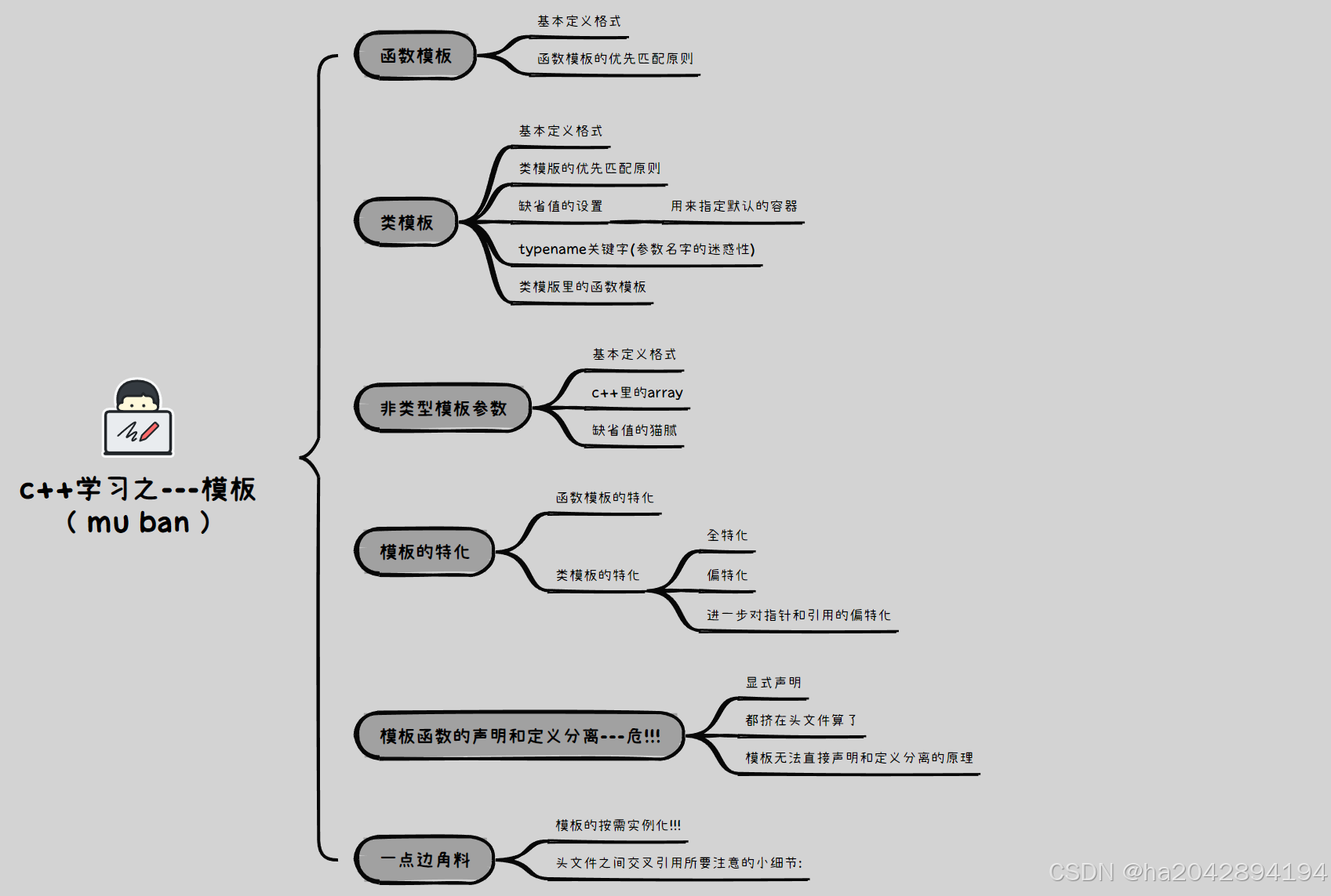
目錄
一、函數模板:
? ? ? ? 1、基本定義格式:
? ? ? ? 2、模版函數的優先匹配原則:
二、類模板:????????
? ? ? ? 1、基本定義格式:
????????2、類模版的優先匹配原則(有坑哦):
????????3、缺省值的設置:
????????4、typename關鍵字(參數名稱的迷惑性):
????????5類模版里的函數模版:
三、非類型模板參數:
? ? ? ? 1、基本定義格式:
????????2、c++里的array:
????????3、缺省值規則的貓膩:
四、模版的特化:
1、函數模板的特化:? ? ? ??
2、類模板的特化:?
? ? ? ? 全特化:
????????偏特化:
? ? ? ? 進一步對指針和引用的偏特化:
五、模版的聲明定義分離---危!!!
????????1、顯式聲明:
????????2、都擠在頭文件算了:
? ? ? ? 3、模板無法直接聲明和定義分離的原理:
六、一點邊角料:
????????1,類模版的按需實例化:
????????2,頭文件之間交叉引用所要注意的小細節:
? ? ? ? 模版,物如其名 。?就是個類似于設計圖紙似的東西,有了圖紙,我們就可以在此基礎上添枝加葉后較為輕松的做出成品;
? ? ? ? c++里的模板也是相同的道理,有了模板,在此基礎上就可以衍生出各種不同的成品(函數和類)。
一、函數模板:
? ? ? ? 1、基本定義格式:
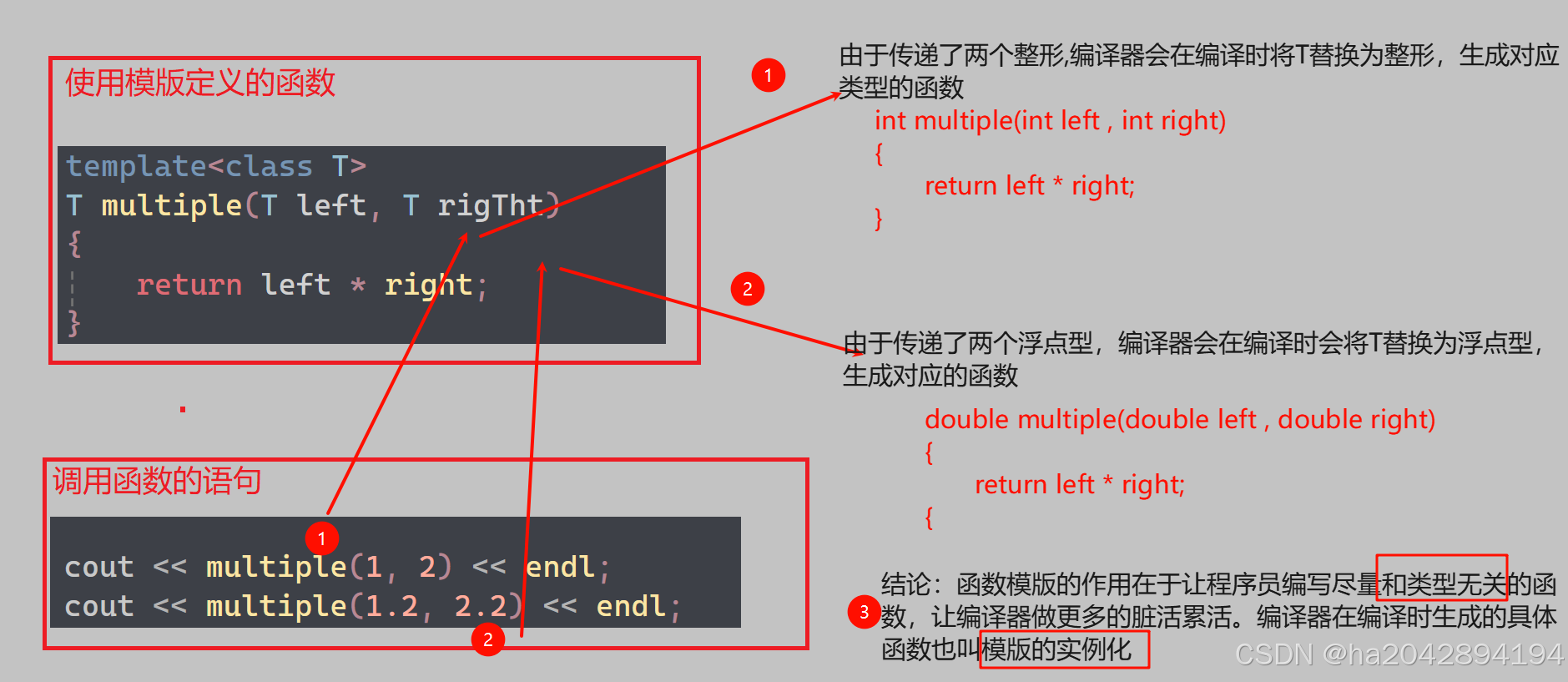
? ? ? ? 定義一個函數模版需要用到的關鍵字是 template? , 然后結合class 或 typename就可以達到定義模版參數的效果。如下:
template<class T> //定義格式:template開頭,用尖括號包圍,里面用class搭配上形參名(比如此處的T)
// template<typename T> //typename 和class在此時沒有區別//這里函數中涉及相關類型的地方用模版參數T替代了T multiple(T left, T rigTht)
{return left * right;
}
? ? ? ? 2、模版函數的優先匹配原則:
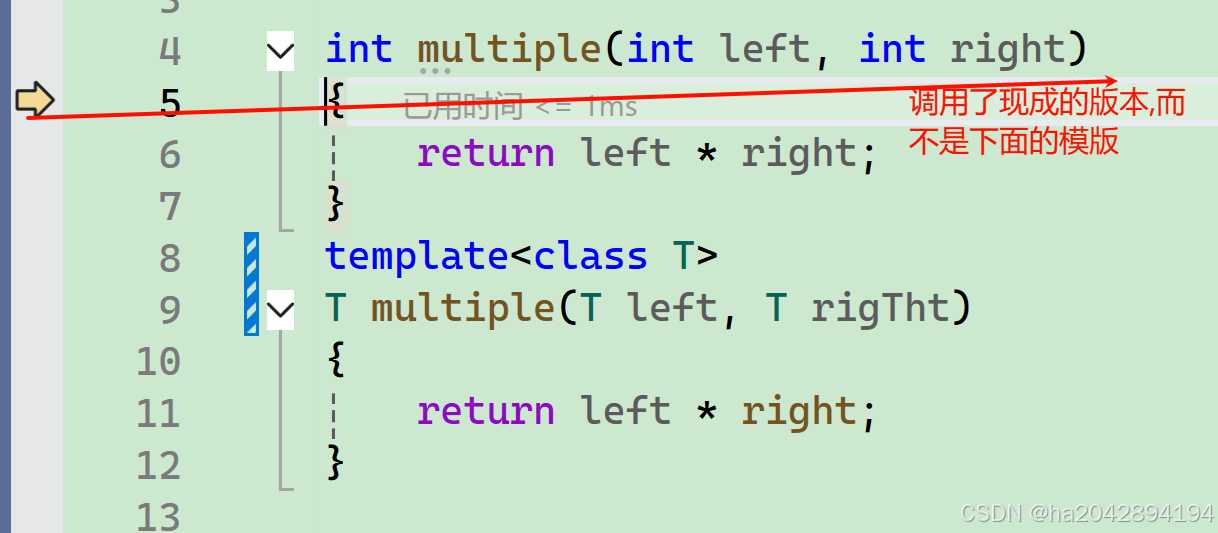
? ? ? ? ? ?雖然上面我們提到模版的一大本質在于讓編譯器根據函數傳參的具體類型在編譯階段生成帶有具體類型的函數,但編譯器只是勤快,而不是傻!!!如果已經有了現成的函數,他就直接調用這個函數,而非吭哧吭哧的埋頭苦干....
? ? ? ? 當調用一個函數時,如果已經存在現成的函數版本,編譯器則會直接調用它,而不是自己另外生成.
//具體類型的函數定義
int multiple(int left, int right)
{return left * right;
}
//模版函數定義
template<class T>
T multiple(T left, T rigTht)
{return left * right;
}//調用語句里傳入了兩個整形值
cout << multiple(1, 2) << endl;? ? ? ? 下面是通過調試觀察到了程序運行時的情況?
二、類模板:????????
? ? ? ? 1、基本定義格式:
? ? ? ? 類模版的定義方式和函數模版類似,同樣關鍵字template、<>、class或typename的組合,只不過作用的范圍是緊隨其后的整個類,整個類里的變量和函數里凡是涉及到類型的地方都可以使用一開始定義的模版參數
template<class T>
class myclass
{
public:T add(T val) //成員函數的返回值和形參使用模版參數類型{T tmp = 0; //函數內部也可以使用模版參數類型return _val1 + _val2 + val;}
private:T _val1; //成員變量使用模版參數類型T _val2;
};????????2、類模版的優先匹配原則(有坑哦):
? ? ? ? 模版的匹配原則起始挺傻瓜的,畢竟在真正實例化出具體的類型之前,編譯器能看到有幾個參數,以及是否相同和順序如何(從左往右匹配)。
? ? ? ? 下面用一個模擬實現vector成員函數的例子來闡釋:
// 用n 個 val初始化的構造函數
vector(int num, const T& val):_start(new T[num])
{for (int i = 0; i < num; i++){*(_start + i) = val;}_finish = _end_of_storage = _start + num;
}
// 用迭代器區間初始化的構造函數
template<class inputIterator>
vector(inputIterator begin, inputIterator end)
{while (begin != end){push_back(*begin);begin++;}
}? ? ? ? ?如果只存在以上兩種vector的構造函數,那么當使用這樣的語句來實例化一個對象時,就會報錯 :vector<int> v(5,7)。也就是傳遞兩個整形值,下面是分析:

? ? ? ? 最簡單的解決方法是自己另外寫一個更加明顯的版本:把int改為size_t ,這樣一來,參數6會被隱式類型轉換為size_t,參數9仍然是正常的int ,但正因如此,就變成了參數類型不同的函數,也就能和第二個函數完美的區分開來。
????????3、缺省值的設置:
? ? ? ? 類似于函數重載,類模版也可以設置缺省值。比較常用的情景就是在為容器適配器設置默認的底層容器,比如stack和queue底層的deque :
? ? ? ? 這樣即使在創建stack或者queue的對象時,沒有特殊情況的話就只是顯式實例化一個模版參數,比如myStack<int>就可以 , 并不需要繁瑣的myStack<int,deueue<T>>。
template<class T , class Container = deque<T>>
class myStack()
{//stack類的相關實現.............
}template<class T , class Container = deque<T>>
class myQueue()
{//queue類的相關實現
..................
}????????4、typename關鍵字(參數名稱的迷惑性):
? ? ? ? 都學習過函數的我們知道,函數的形參的名稱真的就只是一個普通的名稱,僅僅是為了方便內部的使用,甚至不寫形參的名字在語法上也是對的。
????????c++在運算符重載里區分前置和后置的++和--時就利用了這一點,如下圖就是一個日期類的后置++的成員函數:
Date operator++(int) // int參數僅用于區分前置/后置++,因此壓根就不用寫形參名
{ Date temp = *this; *this = *this + 1; return temp;
}?????????下面通過一個printf_container,也就是通用的容器打印函數,來說明形參名稱的迷惑性(模版參數的形參也是形參,只不過不向函數的形參那樣可以省略罷了)。
template<class Container>
void PrintContainer(const Container& obj)
{Container::iterator it = obj.begin(); //這條語句又隱藏的風險while(it != obj.end()){cout << *it <<" ";it++;}
}
? ? ? ? 這里的問題的根源在于程序員和編譯器視角的不同:
- 在我們心中,這里的Container代表各種容器,因此函數里的 Container::Iterator it 的寫法是順理成章的.
- 可是在編譯器眼里, 這里的Container僅僅只是一個類型名,雖然可能是容器類型(自定義類型) , 但同樣也可能是int、double等內置類型。
- 編譯器的做法很嚴謹,為了避免函數在被調用時,參數實例化為了int等內置類型,就在編譯階段進行攔截了?。畢竟,int::iterator it 這樣的語句怎么看怎么逆天...
- 這個問題的解法,是typename關鍵字,顯式的告訴編譯器這是一個類。或者更省心一點,直接用關鍵字auto來讓編譯器自己推導正確的類型。
//正確的寫法
template<class Container>
void PrintContainer(const Container& obj)
{//關鍵代碼
//------------------------------------------------------------------------------------typename Container::const_iterator it = obj.begin(); //在前面加上typename關鍵字//auto iterator it = obj.begin(); //當然auto就更省心啦
//---------------------------------------------------------------------------------------while (it != obj.end()){cout << *it << " ";it++;}
}????????5類模版里的函數模版:
? ? ? ? 一個類的內部并非只能使用在類之前定義的那些模版參數,也就是說:一個類的成員函數還可以定義自己的模版參數。
template<class T>
class myclass
{
public://特立獨行的成員函數add,定義了自己的模版參數
//--------------------------------------------------------------template<class Y>Y add(Y val){return _val1 + _val2 + val;}
//-----------------------------------------------------------------
private:T _val1;T _val2;
};三、非類型模板參數:
? ? ? ? 1、基本定義格式:
? ? ? ? 定義模版類型時,我們既可以用關鍵字class和typename來定義一個通用的類型,反過來,我們也可以直接寫死所期望的類型,比如下面這個例子里:一個成員變量為array類型的類,在模版參數里固定了整形變量,甚至是他的缺省值。
template<class T , int size = 10> //此處的int size就是非類型模版參數,10是他的缺省值
class Array
{
public:Array(){double tmp = 1.2;for (auto& au : obj){au = (tmp += 3.9);}}void PrintSelf(){for (auto au : obj){cout << au << " ";}cout << endl;}
private:array<T, size> obj; //size也就充當了array類型對象的元素個數
};
????????2、c++里的array:
? ? ? ? 在上面對于非類型模版參數的例子中,我使用到了c++里的一個不太起眼的容器——array。看名字咱就很眼熟,誰在初學c語言數組的時候不是這樣定義的數組名稱??? int arr[10] ={0} 。
????????其實array的底層就是一個靜態數組,只不過還夾帶了一點私貨,讓他比普通的靜態數組更加安全和好用。
| 普通的靜態數組 | 封裝了靜態數組的容器array | |
| 安全性 | 僅僅在空間的邊界處設有標志位 | 一旦越界訪問,斷言報錯 |
| 便捷性 | 需要自己寫for循環遍歷 | 支持迭代器遍歷 |
| 可讀性 | int arr [10]中 int [10]才是類型名 | array<int,10> obj 中 obj之前的就是類型名 |
? ? ? ? ?順帶補充一點:普通靜態數組的越界檢查比較簡陋,主要就是在底層封裝了一層邏輯來判斷內存邊界前后的元素是否被修改,這也代表如果只是訪問元素,幾遍非法,也不會報錯。看下面的情況:

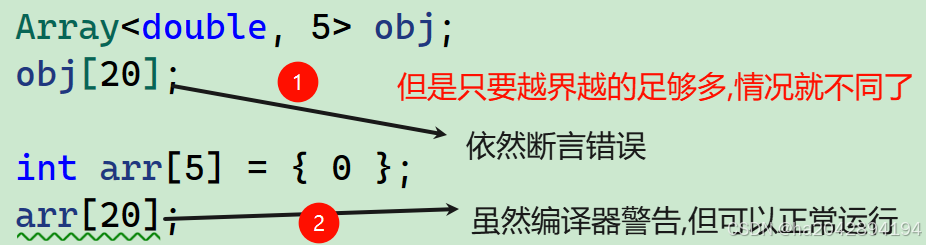

????????3、缺省值規則的貓膩:
? ? ? ? 非類型模版的規則隨著c++標準的迭代經歷了巨多巨多的變更,如下圖所示。看看就好,不用太在意,需要用的時候查資料就好啦。
| 標準版本 | 整型/枚舉 | 指針/引用 | 浮點類型 | 類類型 | 其他特性 |
|---|---|---|---|---|---|
| C++98/03 | ?? | ?? | ? | ? | - |
| C++11/14 | ?? | ?? | ? | ? | nullptr?支持 |
| C++17 | ?? | ?? | ? | ? | auto?推導 |
| C++20 | ?? | ?? | ?? | ??(字面量類) | 字符串字面量間接支持 |
| C++23 | ?? | ?? | ?? | ?? | 結構化綁定 |
四、模版的特化:
? ? ? ? 模版的特化,無論是函數模版還是類模版,都是在原有模版的基礎上進行的更加具象化的定義,因此特化后的模版參數起碼在參數個數上要和原模版相匹配!!!
1、函數模板的特化:? ? ? ??
? ? ? ?特化就是對全部的模版參數特殊處理化。
//函數模版的基礎版本
template<class T , class Y>
Y add(T left, Y right)
{return left + right;
}
//函數模版的全特化版本
template<> //由于是全特化,所以不再使用原來的模版參數,這里可以空著
double add<int,double>(int left, double right) //寫法的關鍵在于函數名之后、括號之前顯示實例化 模版參數(類似于定義模版類對象時的寫法);以及,替換模版參數為具體的類型。
{return left + right;
}2、類模板的特化:?
? ? ? ? 全特化:
//基礎的類模板
template<class T ,class Y>
class Myclass
{
public:
private:T _val1;Y _val2;
};
//全特化的類模板
template<> //全特化就可以把這里空著,因為全部要自己顯式寫
class Myclass<int, double> //顯式實例化(注意模板參數個數要和原模板一致)
{
public:
private:int _val1;double _val2;
};????????偏特化:
//基礎的類模板
template<class T ,class Y>
class Myclass
{
public:
private:T _val1;Y _val2;
};
//偏特化的類模板
template<class T> //這里偏特化模板參數Y,所以原來的參數T還得寫
class Myclass<T,double> //顯式實例化時僅僅將偏特化的模板參數確定即可
{
public:
private:T _val1;double _val2;
};? ? ? ? 進一步對指針和引用的偏特化:
? ? ? ? 偏特化除了可以理解為“對一部分模板參數特殊處理化”之外,也有“對已有的模板參數進一步處理”的功能。
//原模板
template<class T ,class Y>
class Myclass
{
public:
private:T _val1;Y _val2;
};
//偏特化出指針類型
template<class T, class Y>
class Myclass<T*, Y* >
{
public:
private:T _val1;Y _val2;
};
//偏特化出引用類型
template<class T, class Y>
class Myclass<T& ,Y& >
{
public:
private:T _val1;Y _val2;
};
五、模版的聲明定義分離---危!!!
? ? ? ? c、c++是典型的編譯型語言,中途會把每個源文件獨立編譯,最后和頭文件一起鏈接起來生成可執行文件。因此但凡是寫過小項目的人,一定會用到聲明和定義分離的項目組織模式。
? ? ? ? 但是 ,當編寫的函數或者類使用到了模板,卻仍然像效仿c語言那樣直接將聲明和定義分離的話必定會看到撲朔離奇的報錯,下面給出常用的解決方案以及背后所蘊含的原理。
????????1、顯式聲明:
- ?實在是要聲明和定義分離,就必須在源文件里顯式特化,也就是給出具體的類型。
- ?這樣的做法不實用?:傳入的參數的類型可能有很多,一旦是沒有顯示特化的類型,依然會報錯,但是程序員難免會有疏忽導致沒有提前謀劃好此函數可能接受的所有參數類型,從而出現問題。
- 建議在源文件里依然不辭勞苦的寫一份原模板函數,這時c++標準的一項規定。有趣的是:如果在源文件里不寫源模板函數,僅僅是顯示特化的版本,編譯器會警告,但仍然會正常運行......。
- 第三點中的現象的原因在于:編譯器對模板的處理分兩部分,一是在編譯階段檢查基本的語法,此時發現一個聲明后面沒有定義,但由于每個文件都是單獨編譯,編譯器不能排除定義放在其他文件的可能性,所以沒有攔截我們;二是在鏈接時編譯器找到了其他源文件里顯示特化后直接可用的函數版本,所以就一路長虹的執行下去嘍,最后造成了有警告但沒報錯的奇異現象。
//.h 文件的聲明
template<class T>
void testFunc(T a);//.c文件的顯式特化//保留初始版本的函數模版
template<class T>
void testFunc(T a)
{ cout << a << endl;
}
//特化版本
template<>
void testFunc<int>(int a)
{cout << a << endl;
}????????2、都擠在頭文件算了:
? ? ? ? 既然聲明和定義分離有陷阱,那干脆放棄掙扎,直接都放在頭文件里算了
????????類里的成員函數在聲明時就順便定義:類里的代碼量較小成員函數默認會作為內聯函數,代碼量較大的函數則會和普通函數一樣進入符號表后參與編譯的過程。?
? ? ? ? 3、模板無法直接聲明和定義分離的原理:
? ? ? ? 這個就要從c、c++這種編譯型語言的可執行文件生成階段說起了,分別是:預處理、編譯、匯編、鏈接。
- 預處理:展開頭文件、去掉注釋、進行宏替換、執行條件編譯。
- 編譯 : 分別對每個源文件單獨進行詞法語法分析、生成匯編代碼。此階段中,頭文件里的模板函數或類的聲明不會被編譯器是做毒瘤,因為有可能具體實現在其他文件里,要等到鏈接的時候才能下定論;源文件里的模板函數或類由于尚未被調用,沒有實例化出具體的代碼,也就沒有進入符號表,無法被找到。
- 匯編:將匯編代碼轉換為CPU可以直接執行的二進制代碼。
- 鏈接:將所有源文件和頭文件連接,生成可執行程序。此時編譯器發現模板類和模板函數不存在于符號表,也無法確定調用的地址,所以報錯。
????????
六、一點邊角料:
????????1,類模版的按需實例化:
? ? ? ? 模版僅僅是一個模具、一份設計圖紙,就像各種武器還僅僅是一份概念圖而尚未被制造出來時不會別別的國家所忌憚,當然,更多的時候壓根就沒人知道。
? ? ? ? 因此編譯器就好像是一個不知道鄰國正在研發秘密武器的懵懵懂懂的總統,在鄰國的武器制造出來之前,即模版實例化具體的類或者函數之前,都不太會引起總統/編譯器的注意。
? ? ? ? 說人話就是:只要不調用某個類的成員函數,即便這個成員函數內部存在一些荒唐的邏輯錯誤(比如使用了不存在的函數),也不會報錯!!!
//類模版
template<class T , int size = 10>
class Array
{
public:void SecretWeapon(){obj.push_back(666); //成員變量obj是array<T,size>類型,容器array顯然沒有push_back接口}
private:array<T, size> obj;
};?
????????2,頭文件之間交叉引用所要注意的小細節:
? ? ? ?在一個源文件里包含其他頭文件是十分常見的操作,但是在c++里也會有一些和命名空間有關的坑,如下是一個頭文件和一個源文件以及程序運行的報錯結果:
//頭文件 extend.htemplate<class T>
class MyClass
{
public:void Print(){cout << buddy; //這里用到了<iostream>庫,std命名空間里的cout函數!!!}
private:int buddy = 100;
};//源文件 Main.c#include<iostream>
#include"extend.h" //包含了我們自己的頭文件"extend.h",其中有用的官方庫的cout函數
using namespace std;int main()
{cout << "good morning , my dear boY !!!" << endl;return 0;
}
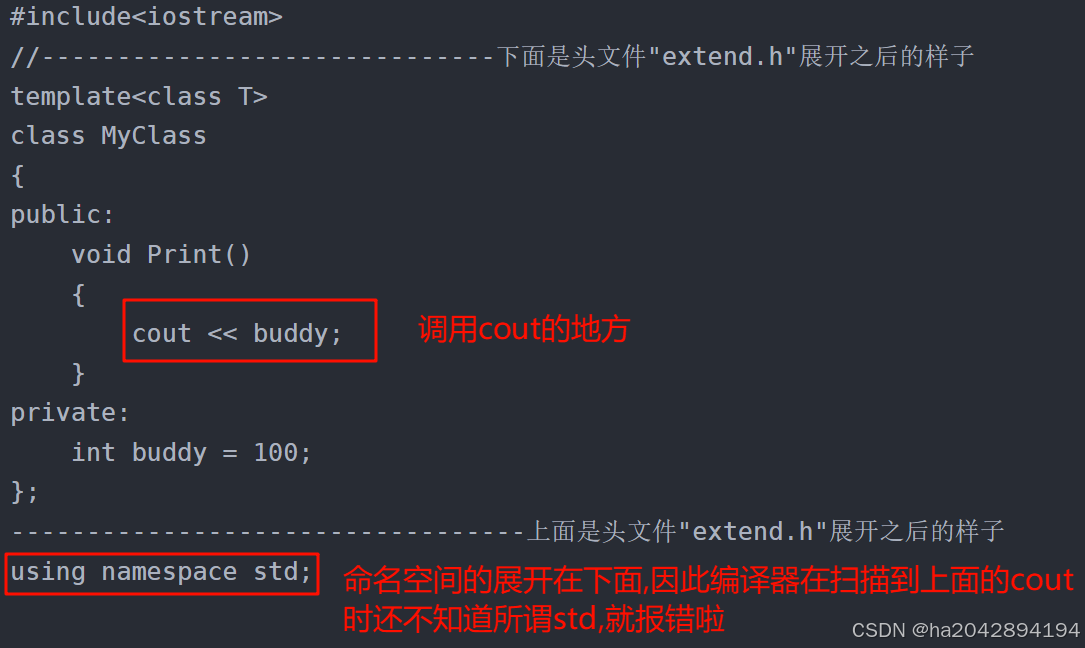
? ? 這樣就很奇怪,畢竟我們既包含了官方庫(#include<iostream>) , 也展開了命名空間(using namespace std) , 可編譯器還是無法找到我們頭文件里的cout函數 . 其實問題就出現在源文件里那幾條語句的聲明順序!!!
? ? ? ? 對于在源文件里包含一個頭文件,不要感到恐慌.當程序在運行之前,首先要進行預處理,這里就是出現問題的關鍵,下面就是我程序們的預處理之后大致的模樣 : 可以看到原先的#include"extend.h"這一句指令被替換成了頭文件里的代碼
#include<iostream>
//------------------------------下面是頭文件"extend.h"展開之后的樣子
template<class T>
class MyClass
{
public:void Print(){cout << buddy;}
private:int buddy = 100;
};
----------------------------------上面是頭文件"extend.h"展開之后的樣子
using namespace std;int main()
{cout << "good morning , my dear boY !!!" << endl;return 0;
}
:RAG下的ETL快速上手)

)







、應用場景、注意事項)








