原文鏈接:SpringAI(GA):RAG下的ETL快速上手
教程說明
說明:本教程將采用2025年5月20日正式的GA版,給出如下內容
- 核心功能模塊的快速上手教程
- 核心功能模塊的源碼級解讀
- Spring ai alibaba增強的快速上手教程 + 源碼級解讀
版本:JDK21 + SpringBoot3.4.5 + SpringAI 1.0.0 + SpringAI Alibaba 1.0.0.2
將陸續完成如下章節教程。本章是第六章(Rag增強問答質量)下的ETL Pipeline快速上手篇
代碼開源如下:https://github.com/GTyingzi/spring-ai-tutorial

往屆解讀可參考:
第一章內容
SpringAI(GA)的chat:快速上手+自動注入源碼解讀
SpringAI(GA):ChatClient調用鏈路解讀
第二章內容
SpringAI的Advisor:快速上手+源碼解讀
SpringAI(GA):Sqlite、Mysql、Redis消息存儲快速上手
第三章內容
SpringAI(GA):Tool工具整合—快速上手
第五章內容
SpringAI(GA):內存、Redis、ES的向量數據庫存儲—快速上手
SpringAI(GA):向量數據庫理論源碼解讀+Redis、Es接入源碼
第六章內容
SpringAI(GA):RAG快速上手+模塊化解讀
獲取更好的觀賞體驗,可付費獲取飛書云文檔Spring AI最新教程權限,目前49.9,隨著內容不斷完善,會逐步漲價。
注:M6版快速上手教程+源碼解讀飛書云文檔已免費提供
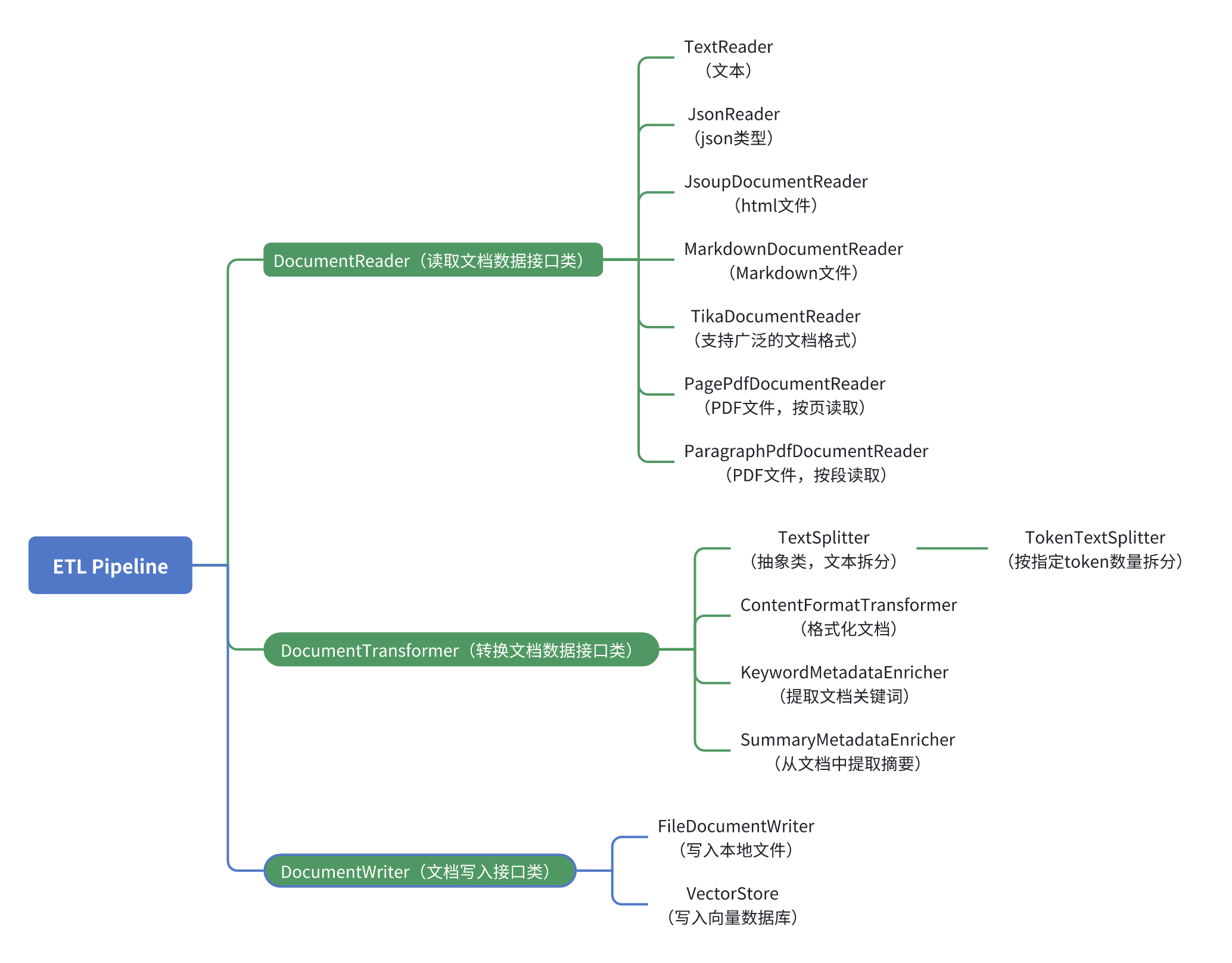
RAG 的 ETL Pipeline 快速上手
[!TIP]
提取(Extract)、轉換(Transform)和加載(Load)框架是《第六章:Rag 增強問答質量》中數據處理的鏈路,將原始數據源導入到向量化存儲的流程,確保數據處于最佳格式,以便 AI 模型進行檢索
實戰代碼可見:https://github.com/GTyingzi/spring-ai-tutorial 下的 rag/rag-etl-pipeline
源碼解讀可見:《ETL Pipeline 源碼解析》
pom 文件
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-autoconfigure-model-openai</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-commons</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-rag</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-jsoup-document-reader</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-markdown-document-reader</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-tika-document-reader</artifactId></dependency></dependencies>
application.yml
server:port: 8080spring:application:name: rag-etl-pipelineai:openai:api-key: ${DASHSCOPEAPIKEY}base-url: https://dashscope.aliyuncs.com/compatible-modechat:options:model: qwen-maxembedding:options:model: text-embedding-v1
提取文檔
Constant
package com.spring.ai.tutorial.rag.model;public class Constant {public static final String PREFIX = "classpath:data/";public static final String TEXTFILEPATH = PREFIX + "/text.txt";public static final String JSONFILEPATH = PREFIX + "/text.json";public static final String MARKDOWNFILEPATH = PREFIX + "/text.md";public static final String PDFFILEPATH = PREFIX + "/google-ai-agents-whitepaper.pdf";;public static final String HTMLFILEPATH = PREFIX + "/spring-ai.html";
}
ReaderController
package com.spring.ai.tutorial.rag.controller;import com.spring.ai.tutorial.rag.model.Constant;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.JsonReader;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.reader.jsoup.JsoupDocumentReader;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.ParagraphPdfDocumentReader;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController
@RequestMapping("/reader")
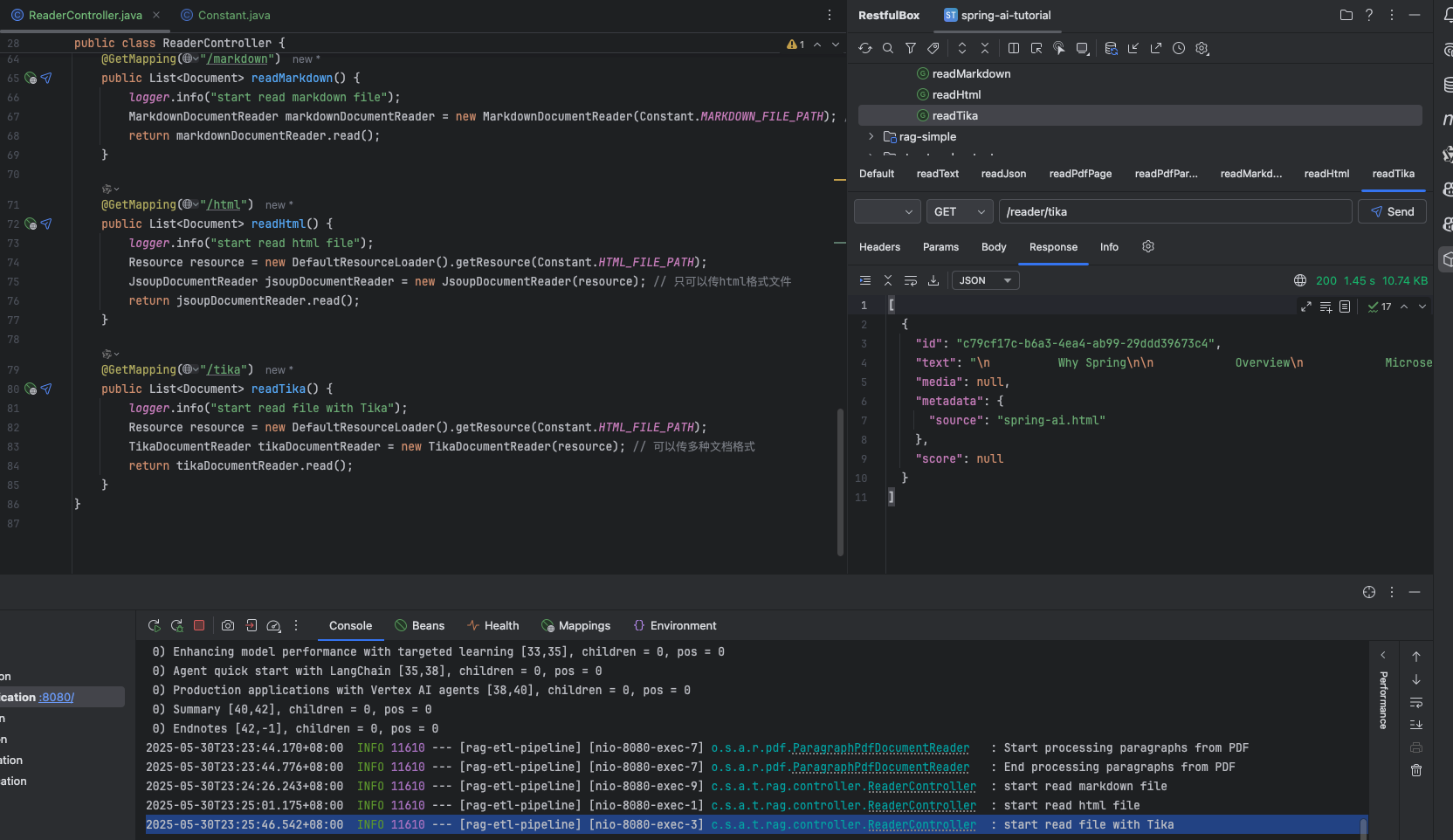
public class ReaderController {private static final Logger logger = LoggerFactory.getLogger(ReaderController.class);@GetMapping("/text")public List<Document> readText() {logger.info("start read text file");Resource resource = new DefaultResourceLoader().getResource(Constant.TEXTFILEPATH);TextReader textReader = new TextReader(resource); // 適用于文本數據return textReader.read();}@GetMapping("/json")public List<Document> readJson() {logger.info("start read json file");Resource resource = new DefaultResourceLoader().getResource(Constant.JSONFILEPATH);JsonReader jsonReader = new JsonReader(resource); // 只可以傳json格式文件return jsonReader.read();}@GetMapping("/pdf-page")public List<Document> readPdfPage() {logger.info("start read pdf file by page");Resource resource = new DefaultResourceLoader().getResource(Constant.PDFFILEPATH);PagePdfDocumentReader pagePdfDocumentReader = new PagePdfDocumentReader(resource); // 只可以傳pdf格式文件return pagePdfDocumentReader.read();}@GetMapping("/pdf-paragraph")public List<Document> readPdfParagraph() {logger.info("start read pdf file by paragraph");Resource resource = new DefaultResourceLoader().getResource(Constant.PDFFILEPATH);ParagraphPdfDocumentReader paragraphPdfDocumentReader = new ParagraphPdfDocumentReader(resource); // 有目錄的pdf文件return paragraphPdfDocumentReader.read();}@GetMapping("/markdown")public List<Document> readMarkdown() {logger.info("start read markdown file");MarkdownDocumentReader markdownDocumentReader = new MarkdownDocumentReader(Constant.MARKDOWNFILEPATH); // 只可以傳markdown格式文件return markdownDocumentReader.read();}@GetMapping("/html")public List<Document> readHtml() {logger.info("start read html file");Resource resource = new DefaultResourceLoader().getResource(Constant.HTMLFILEPATH);JsoupDocumentReader jsoupDocumentReader = new JsoupDocumentReader(resource); // 只可以傳html格式文件return jsoupDocumentReader.read();}@GetMapping("/tika")public List<Document> readTika() {logger.info("start read file with Tika");Resource resource = new DefaultResourceLoader().getResource(Constant.HTMLFILEPATH);TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource); // 可以傳多種文檔格式return tikaDocumentReader.read();}
}
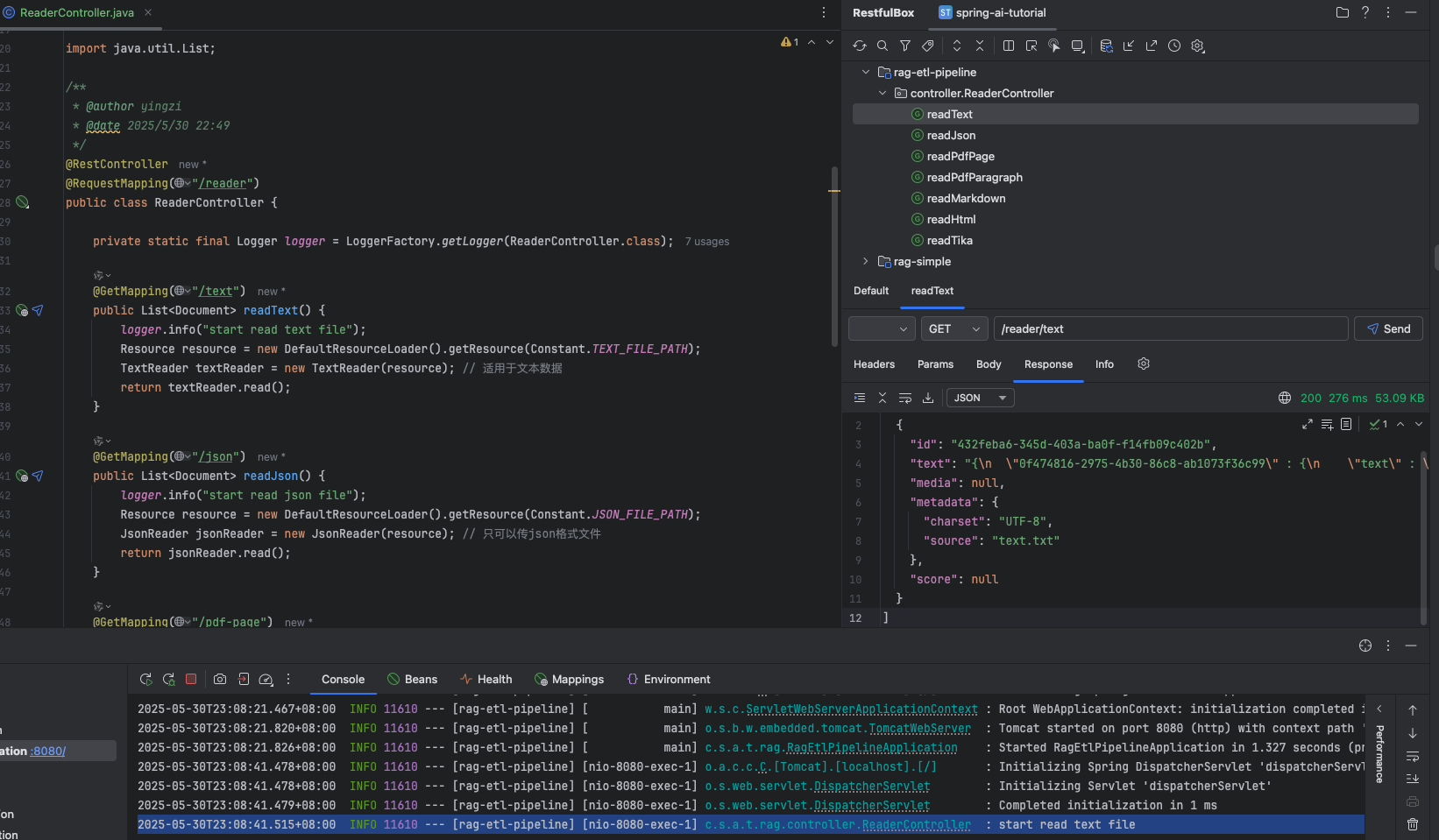
效果
讀取文本文件
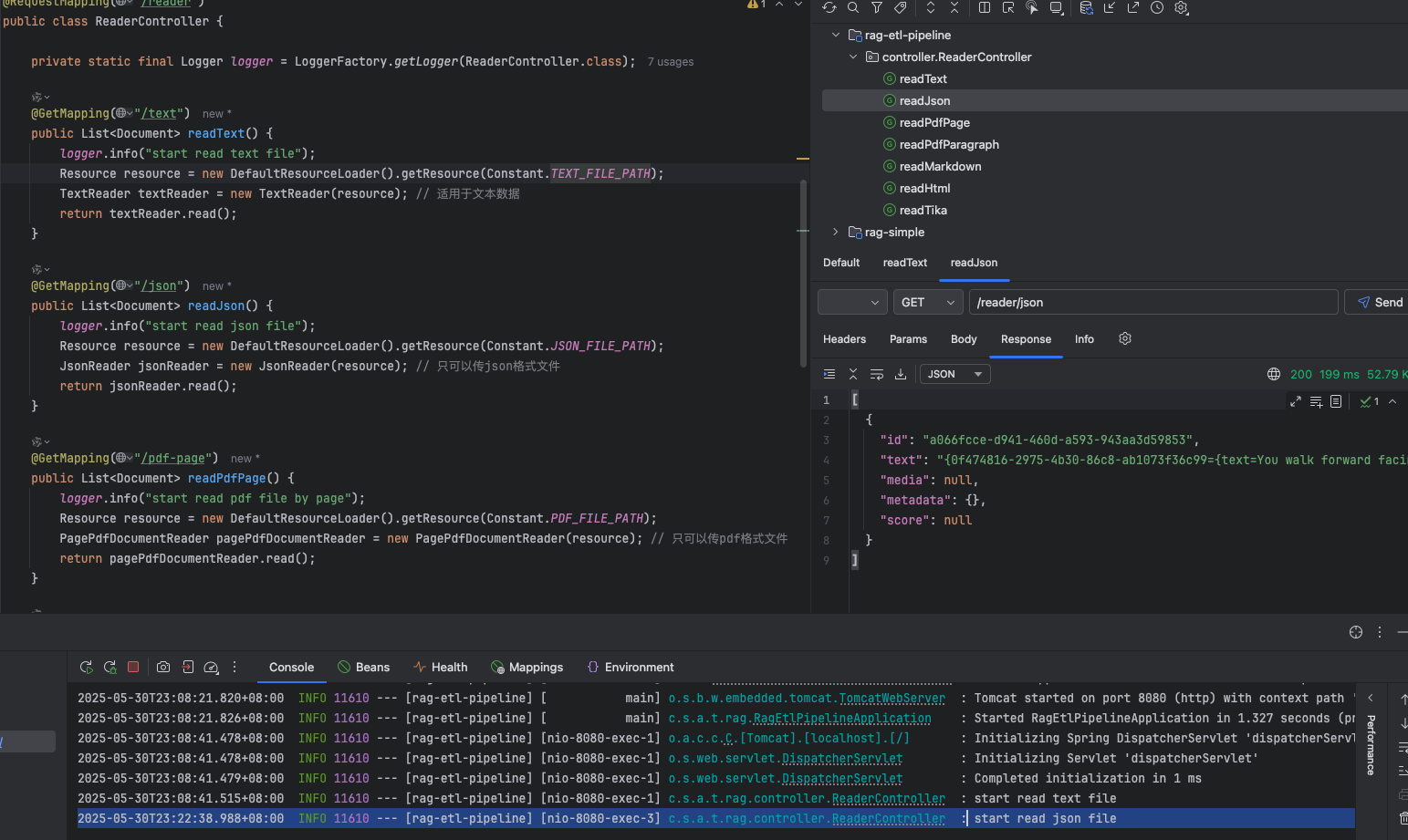
讀取 json 文件
讀取 pdf 文件
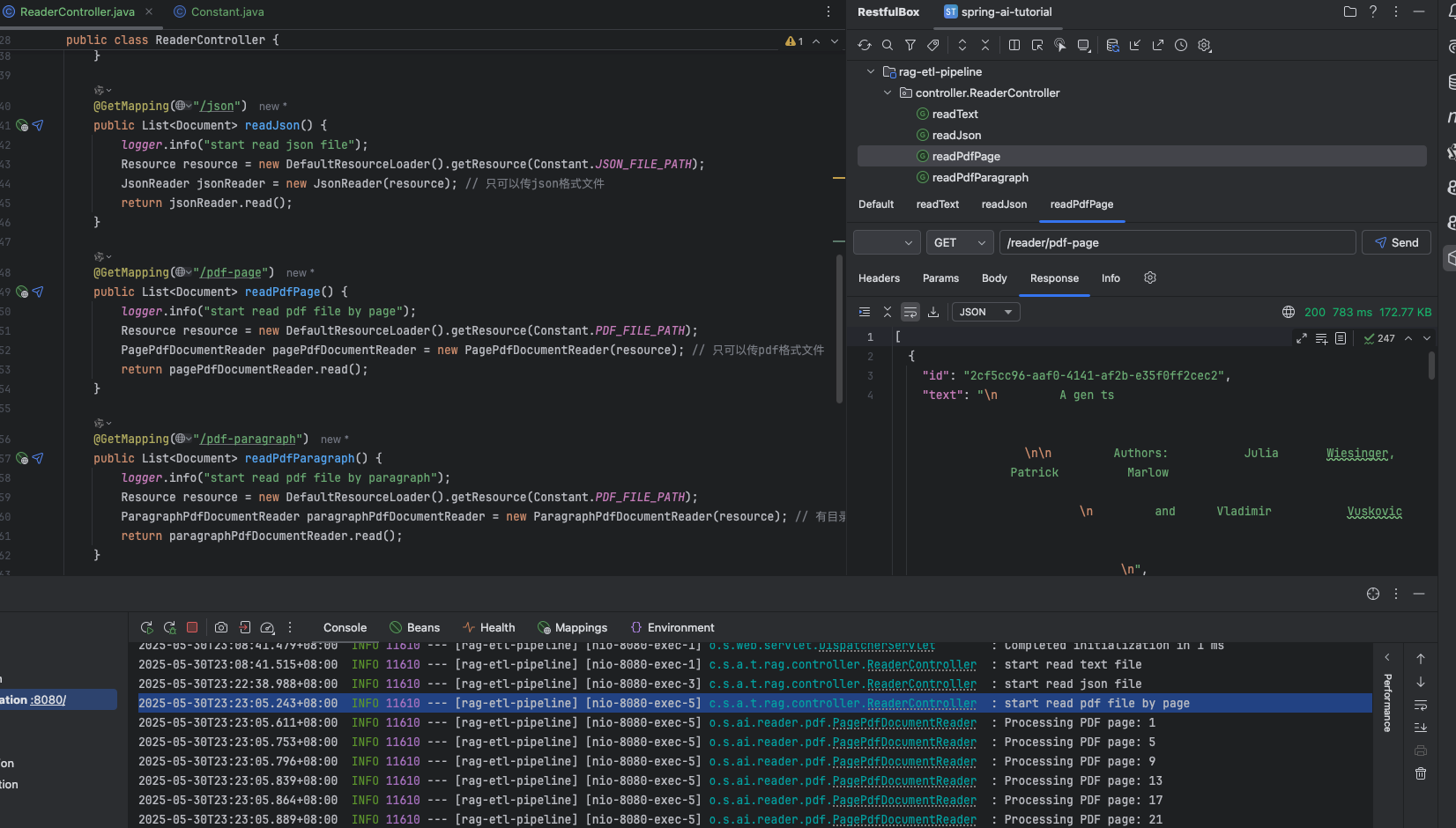
讀取帶目錄的 pdf 文件
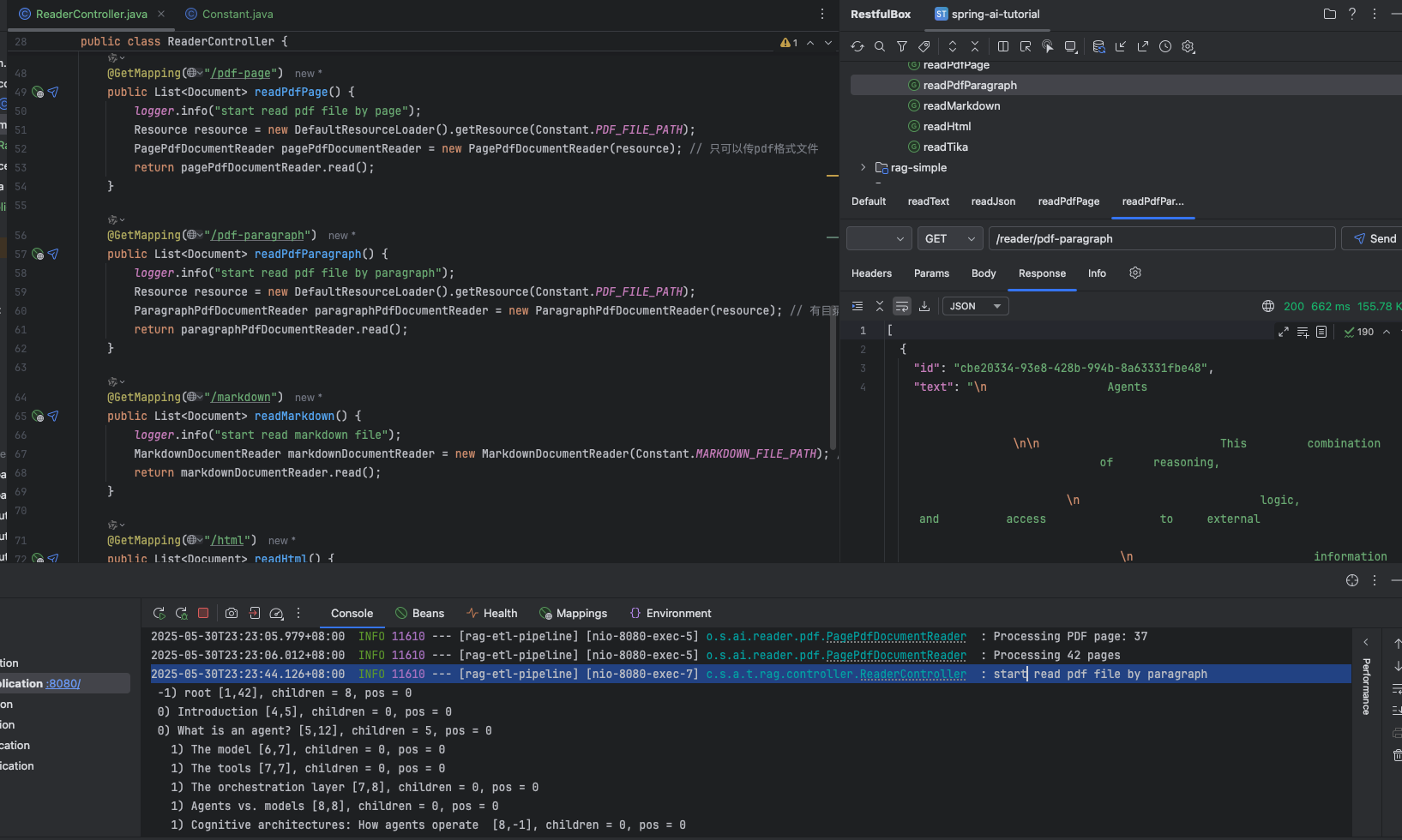
讀取 markdown 文件
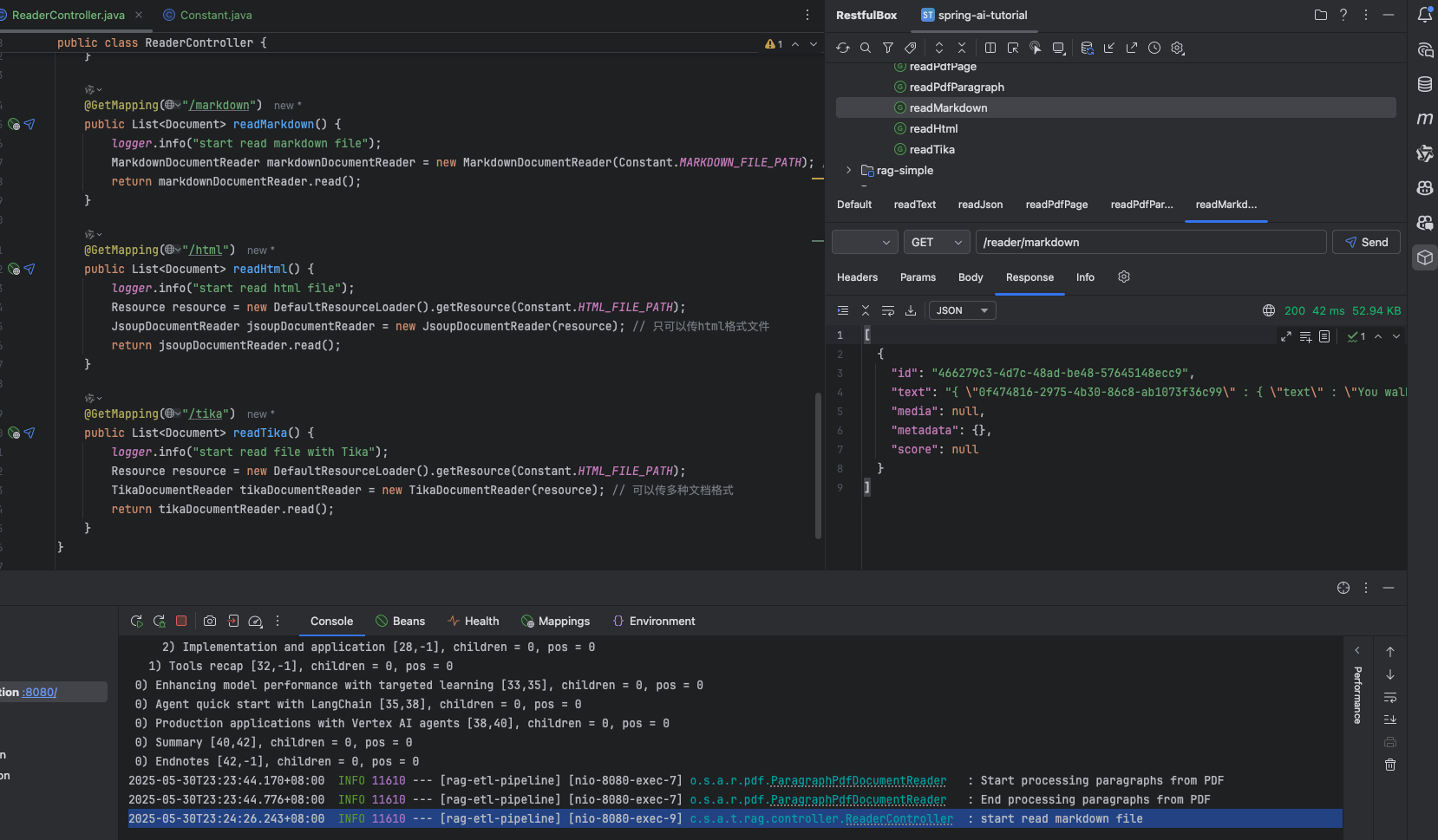
讀取 html 文件
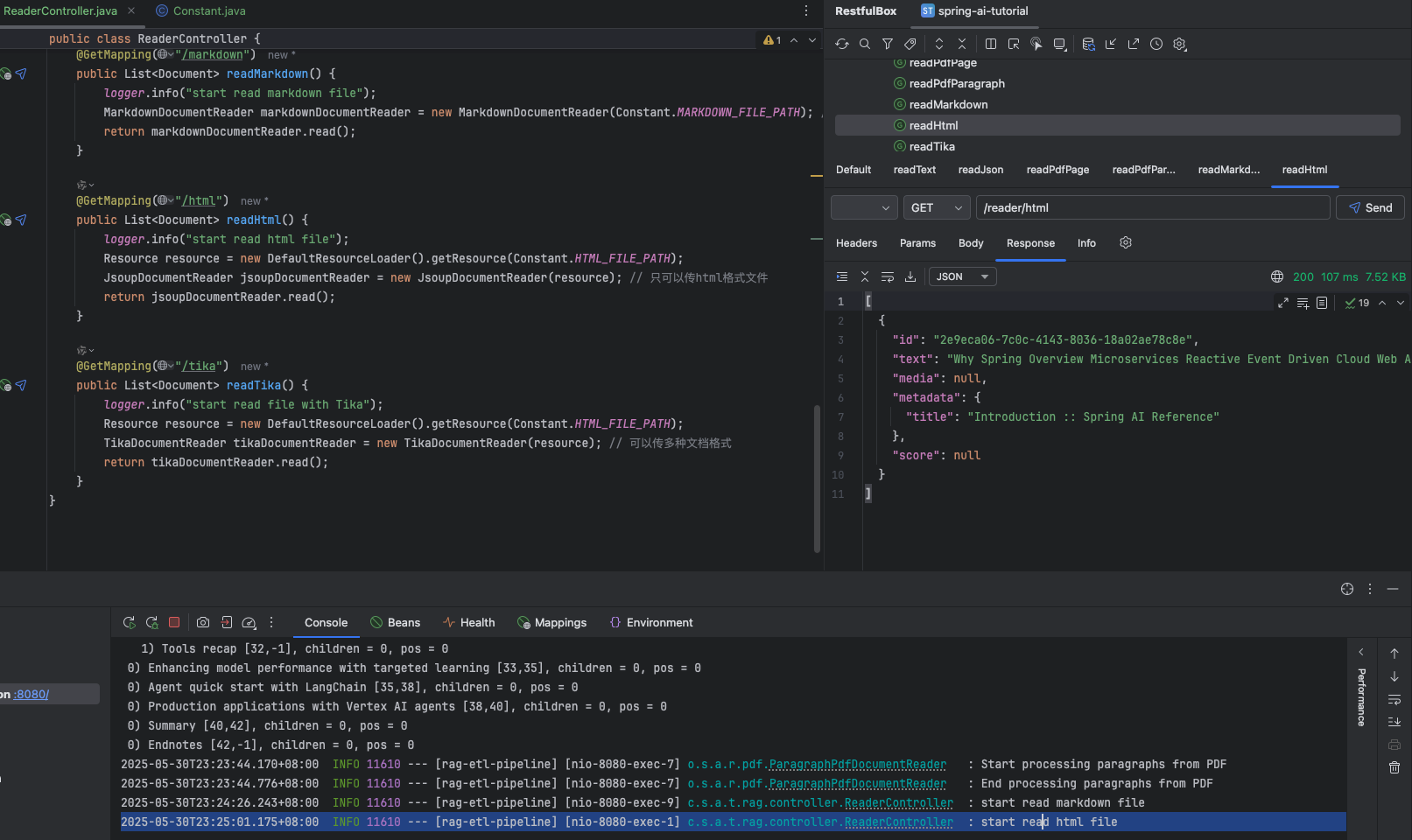
利用 tika 讀取任意文檔格式
轉換文檔
TransformerController
package com.spring.ai.tutorial.rag.controller;import com.spring.ai.tutorial.rag.model.Constant;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.document.DefaultContentFormatter;
import org.springframework.ai.document.Document;
import org.springframework.ai.model.transformer.KeywordMetadataEnricher;
import org.springframework.ai.model.transformer.SummaryMetadataEnricher;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.transformer.ContentFormatTransformer;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController
@RequestMapping("/transformer")
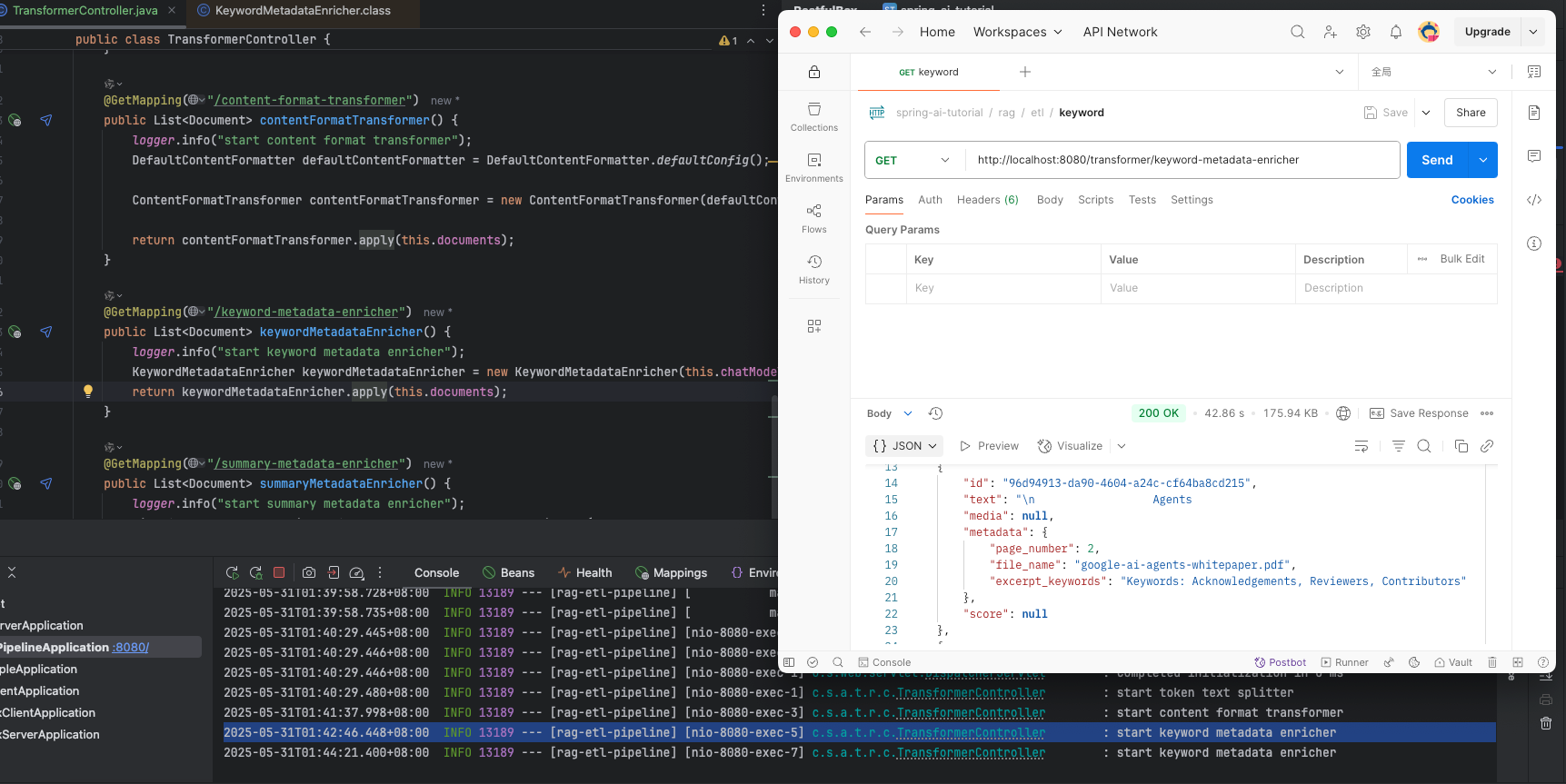
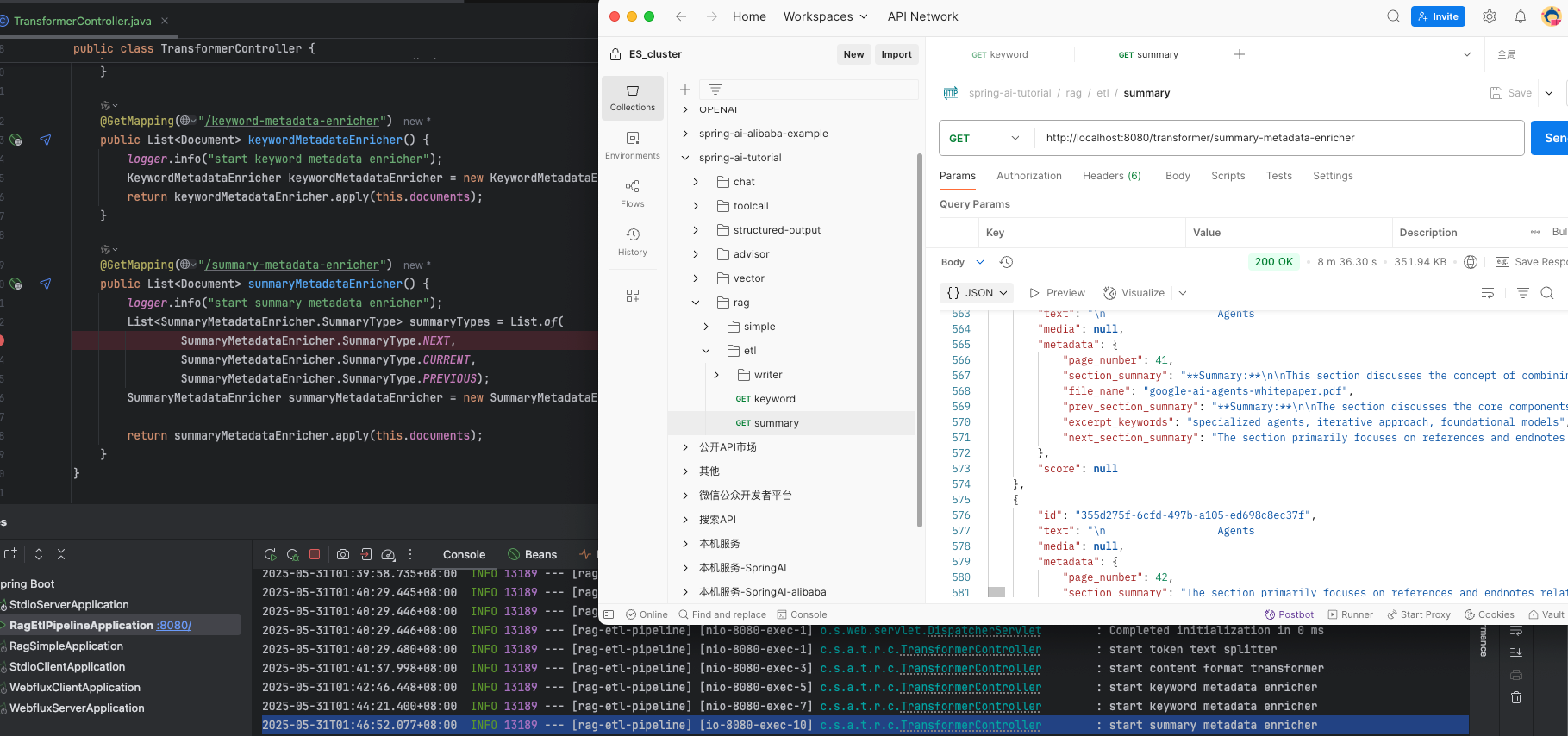
public class TransformerController {private static final Logger logger = LoggerFactory.getLogger(TransformerController.class);private final List<Document> documents;private final ChatModel chatModel;public TransformerController(ChatModel chatModel) {logger.info("start read pdf file by page");Resource resource = new DefaultResourceLoader().getResource(Constant.PDFFILEPATH);PagePdfDocumentReader pagePdfDocumentReader = new PagePdfDocumentReader(resource); // 只可以傳pdf格式文件this.documents = pagePdfDocumentReader.read();this.chatModel = chatModel;}@GetMapping("/token-text-splitter")public List<Document> tokenTextSplitter() {logger.info("start token text splitter");TokenTextSplitter tokenTextSplitter = TokenTextSplitter.builder()// 每個文本塊的目標token數量.withChunkSize(800)// 每個文本塊的最小字符數.withMinChunkSizeChars(350)// 丟棄小于此長度的文本塊.withMinChunkLengthToEmbed(5)// 文本中生成的最大塊數.withMaxNumChunks(10000)// 是否保留分隔符.withKeepSeparator(true).build();return tokenTextSplitter.split(this.documents);}@GetMapping("/content-format-transformer")public List<Document> contentFormatTransformer() {logger.info("start content format transformer");DefaultContentFormatter defaultContentFormatter = DefaultContentFormatter.defaultConfig();ContentFormatTransformer contentFormatTransformer = new ContentFormatTransformer(defaultContentFormatter);return contentFormatTransformer.apply(this.documents);}@GetMapping("/keyword-metadata-enricher")public List<Document> keywordMetadataEnricher() {logger.info("start keyword metadata enricher");KeywordMetadataEnricher keywordMetadataEnricher = new KeywordMetadataEnricher(this.chatModel, 3);return keywordMetadataEnricher.apply(this.documents);}@GetMapping("/summary-metadata-enricher")public List<Document> summaryMetadataEnricher() {logger.info("start summary metadata enricher");List<SummaryMetadataEnricher.SummaryType> summaryTypes = List.of(SummaryMetadataEnricher.SummaryType.NEXT,SummaryMetadataEnricher.SummaryType.CURRENT,SummaryMetadataEnricher.SummaryType.PREVIOUS);SummaryMetadataEnricher summaryMetadataEnricher = new SummaryMetadataEnricher(this.chatModel, summaryTypes);return summaryMetadataEnricher.apply(this.documents);}
}
效果
TokenTextSplitter 切分
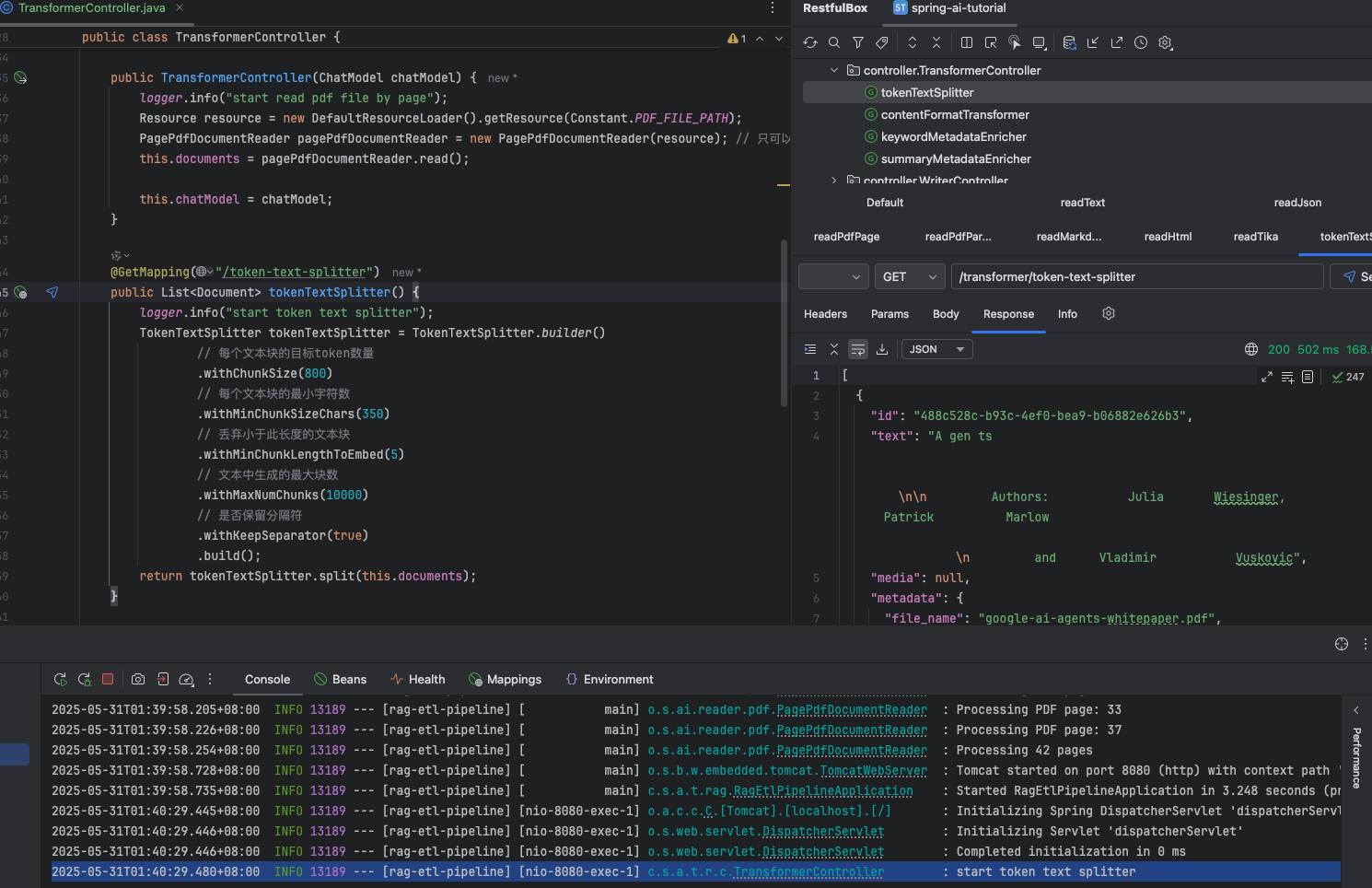
DefaultContentFormatter 格式化
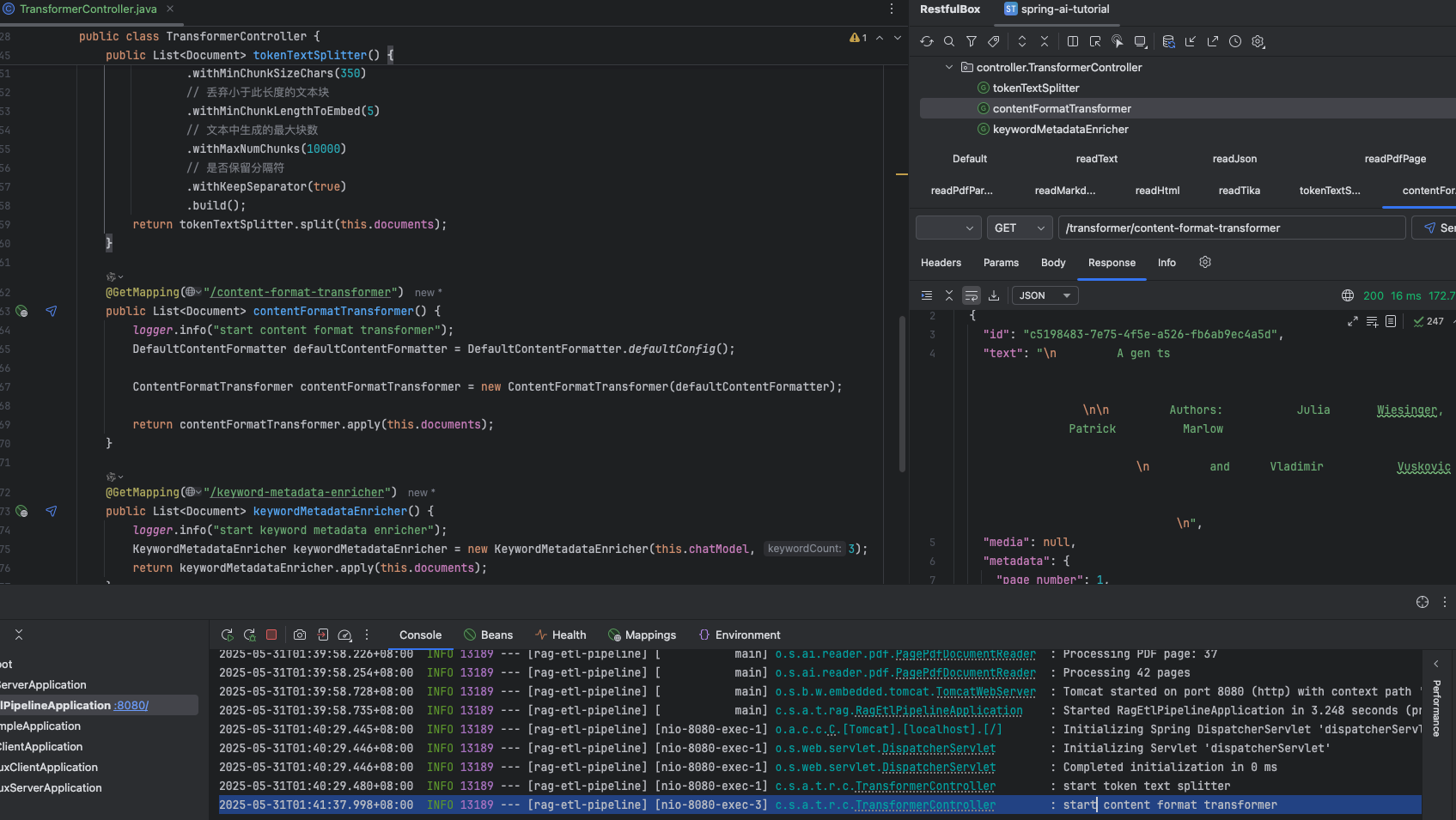
KeywordMetadataEnricher 提取關鍵字
SummaryMetadataEnricher 提取摘要
寫出文檔
WriterController
package com.spring.ai.tutorial.rag.controller;import com.spring.ai.tutorial.rag.model.Constant;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.writer.FileDocumentWriter;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController
@RequestMapping("/writer")
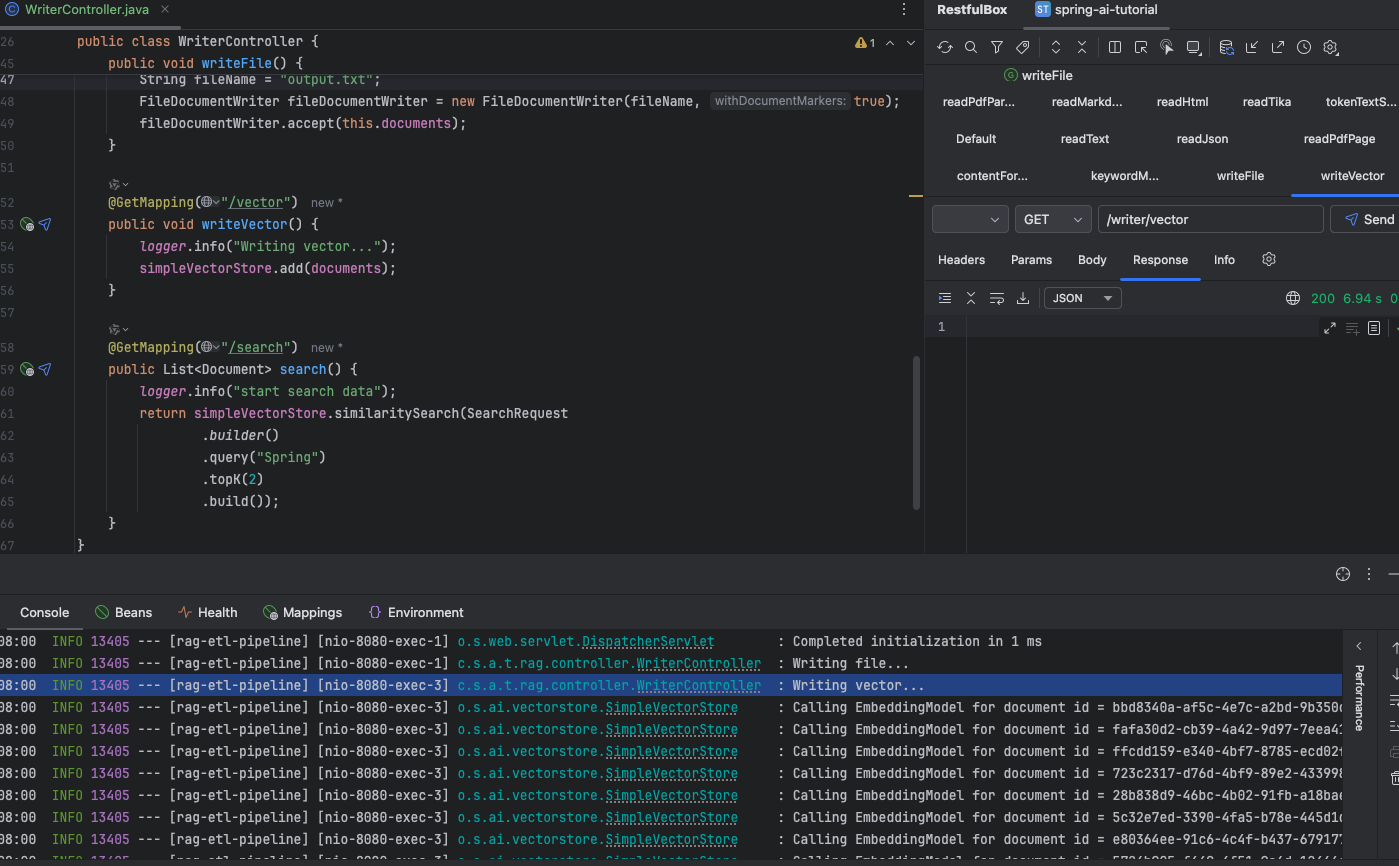
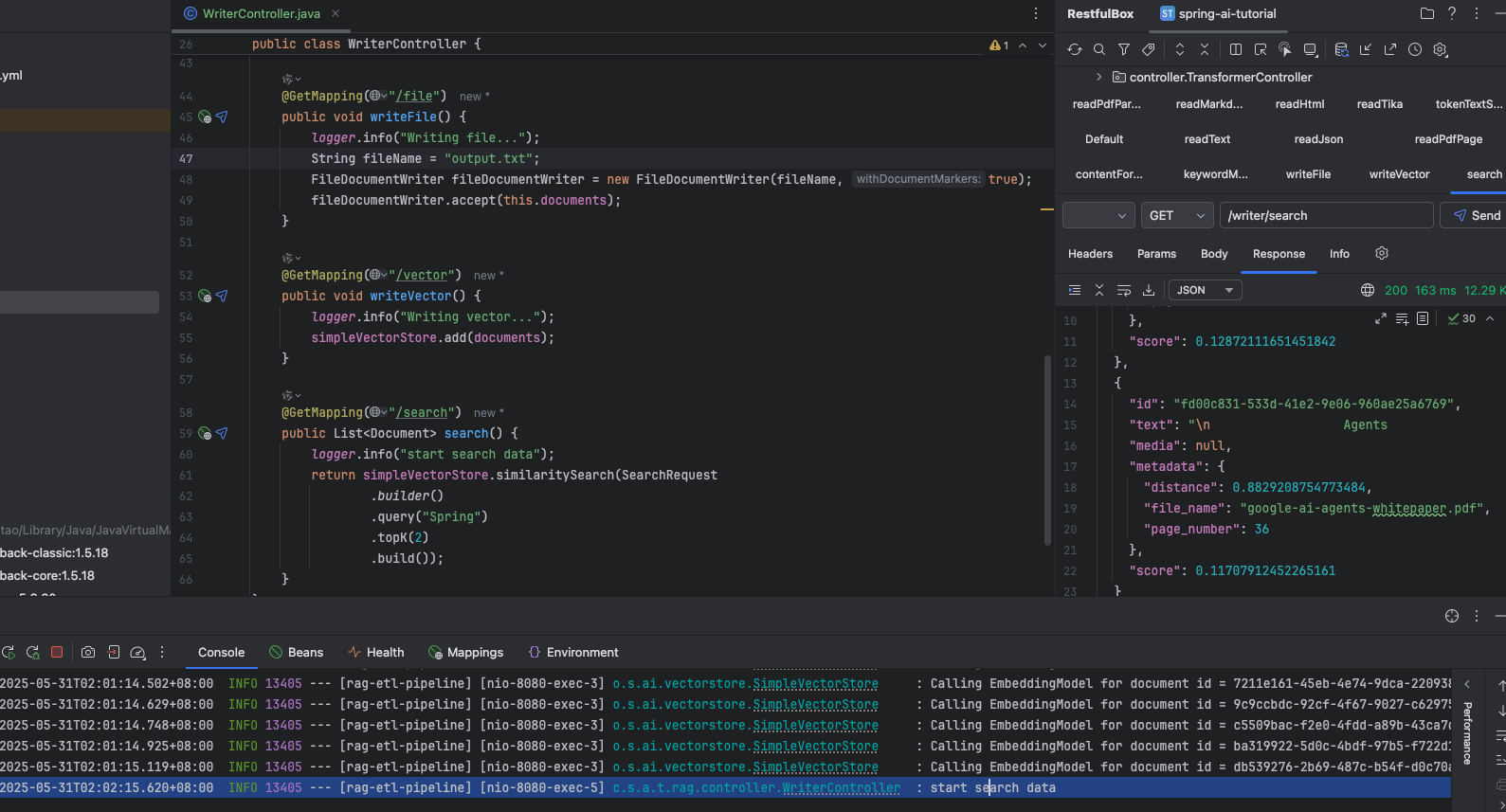
public class WriterController {private static final Logger logger = LoggerFactory.getLogger(WriterController.class);private final List<Document> documents;private final SimpleVectorStore simpleVectorStore;public WriterController(EmbeddingModel embeddingModel) {logger.info("start read pdf file by page");Resource resource = new DefaultResourceLoader().getResource(Constant.PDFFILEPATH);PagePdfDocumentReader pagePdfDocumentReader = new PagePdfDocumentReader(resource); // 只可以傳pdf格式文件this.documents = pagePdfDocumentReader.read();this.simpleVectorStore = SimpleVectorStore.builder(embeddingModel).build();}@GetMapping("/file")public void writeFile() {logger.info("Writing file...");String fileName = "output.txt";FileDocumentWriter fileDocumentWriter = new FileDocumentWriter(fileName, true);fileDocumentWriter.accept(this.documents);}@GetMapping("/vector")public void writeVector() {logger.info("Writing vector...");simpleVectorStore.add(documents);}@GetMapping("/search")public List<Document> search() {logger.info("start search data");return simpleVectorStore.similaritySearch(SearchRequest.builder().query("Spring").topK(2).build());}
}
效果
Document 寫出文本文件
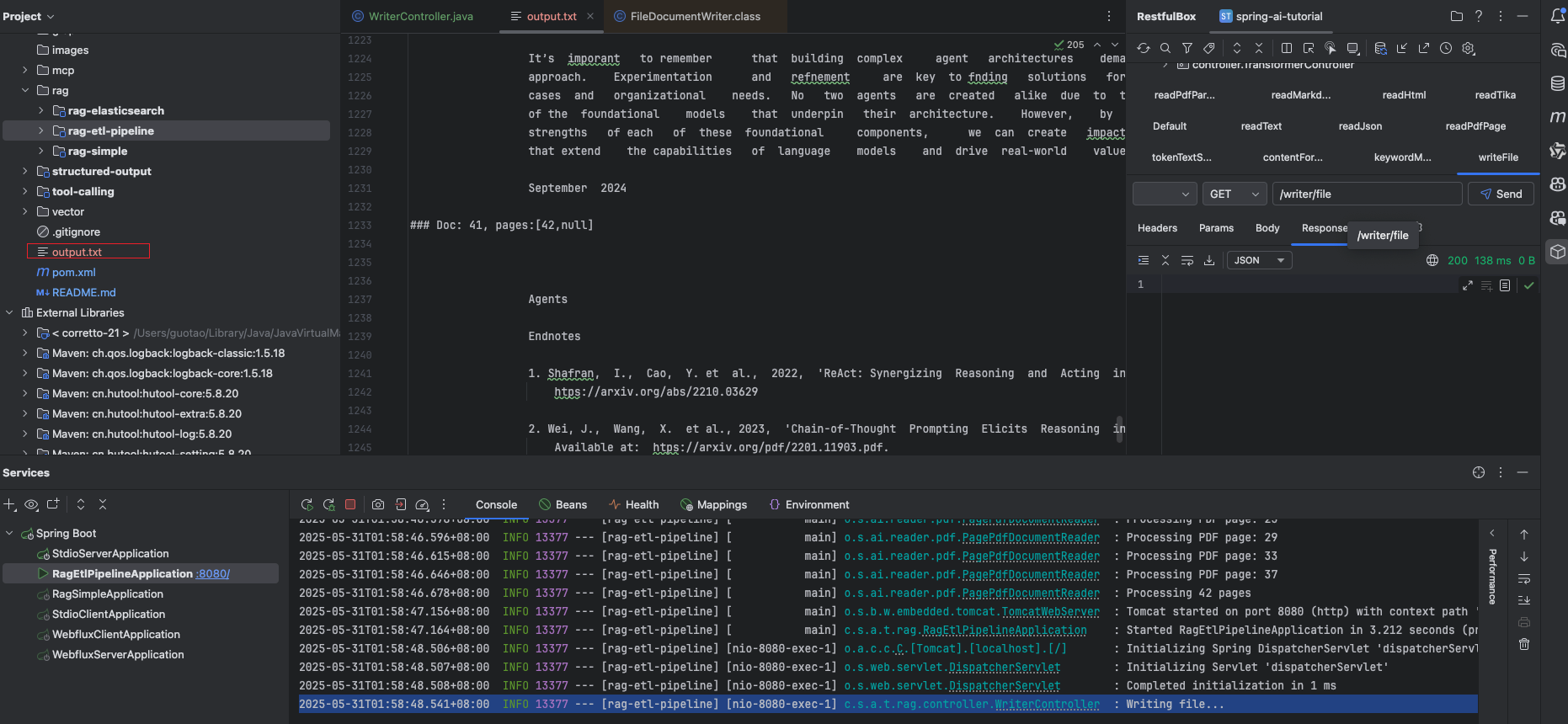
寫入 vector
從 vector 中查找

)







、應用場景、注意事項)









