相關連接
更新中.......
1、Associating Objects with Transformers for Video Object Segmentation:論文詳解、AOT源碼解析
2、Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
3、Recurrent Dynamic Embedding for Video Object Segmentation
4、XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
5、Decoupling Features in Hierarchical Propagation for Video Object Segmentation
6、Tracking Anything with Decoupled Video Segmentation
7、Putting the Object Back into Video Object Segmentation:論文詳解
目錄
- 1、Associating Objects with Transformers for Video Object Segmentation
- 1)背景知識
- 2)研究方法
- 3)實驗結果
- 4)結論
- 2、Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
- 1)背景知識
- 2)研究方法
- 3)實驗結果
- 4)關鍵結論
- 3、Recurrent Dynamic Embedding for Video Object Segmentation
- 1)背景知識
- 2)研究方法
- 3)實驗結果
- 4)關鍵結論
- 4、XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
- 1)背景知識
- 2)研究方法
- 3)實驗結果
- 4)關鍵結論
- 5、Decoupling Features in Hierarchical Propagation for Video Object Segmentation
- 1)背景知識
- 2)研究方法
- 雙分支傳播
- 門控傳播模塊(GPM)
- 3)實驗結果
- 4)關鍵結論
- 6、Tracking Anything with Decoupled Video Segmentation
- 背景知識
- 研究方法
- 雙向傳播
- 時序傳播模塊
- 實驗結果
- 關鍵結論
- 7、Putting the Object Back into Video Object Segmentation
- 1)背景知識與研究動機
- 2)研究方法
- 3)實驗
- 關鍵數值結果
- 4)結論
1、Associating Objects with Transformers for Video Object Segmentation
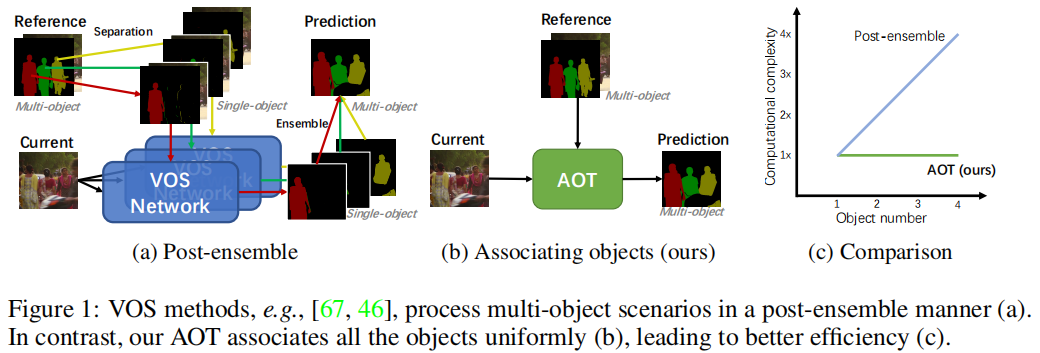
這篇文章提出了一種名為“Associating Objects with Transformers (AOT)”的新方法,用于解決半監督視頻目標分割(VOS)任務中的多目標場景問題。AOT通過將多個目標統一嵌入到同一個高維嵌入空間中,實現了多目標的匹配和解碼,顯著提高了效率,并在多個基準測試中取得了優異的性能。
1)背景知識
視頻目標分割(VOS)是視頻理解中的一個基礎任務,其目標是根據視頻序列中第一幀提供的目標掩碼,跟蹤并分割整個視頻中的目標。半監督VOS是其中的主要任務類型。盡管已有方法取得了顯著進展,但它們大多針對單個目標進行解碼,導致在多目標場景下需要獨立匹配每個目標,并將單目標預測組合成多目標分割,這種后處理方式效率低下,尤其是在計算資源有限的情況下。
2)研究方法
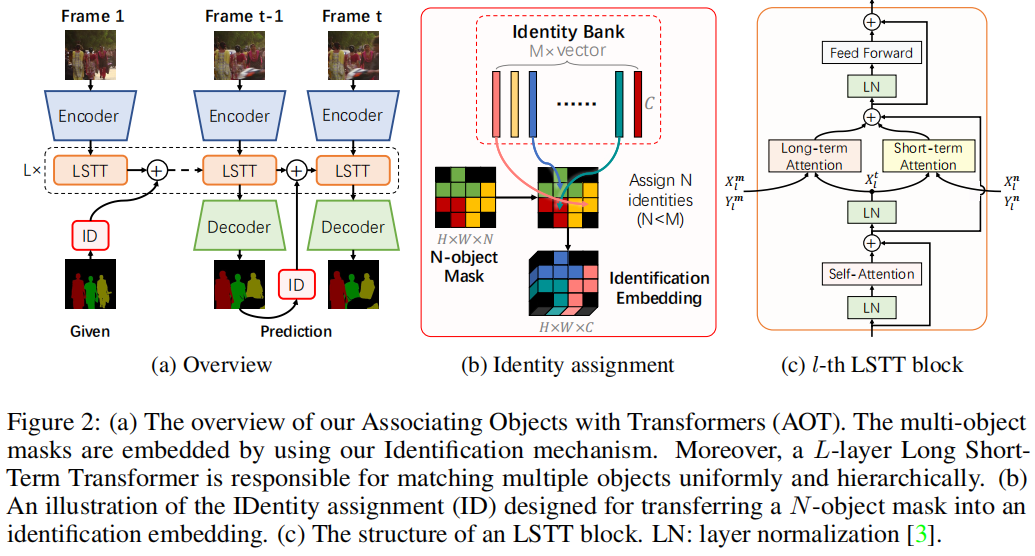
AOT的核心在于提出了一個識別機制,將多個目標嵌入到同一個特征空間中,從而可以同時處理多個目標的匹配和分割解碼,效率與處理單個目標相當。具體來說,AOT包含以下幾個關鍵部分:
-
識別機制:通過為每個目標分配一個唯一的身份標識,并將這些目標嵌入到同一個特征空間中,網絡可以學習目標之間的關聯。這種機制允許直接從聚合的特征中解碼多目標分割。
-
長短期變換器(LSTT):為了充分建模多目標關聯,設計了LSTT模塊,用于構建層次化的匹配和傳播。LSTT模塊結合了長期注意力(匹配第一幀的嵌入)和短期注意力(匹配附近幾幀的嵌入),以更有效地關聯多個目標。
-
網絡架構:AOT使用輕量級的MobileNet-V2作為骨干網絡,并設計了不同復雜度的變體,包括AOT-Tiny、AOT-Small、AOT-Base和AOT-Large,以滿足不同的效率和性能需求。
3)實驗結果
實驗部分,作者在YouTube-VOS、DAVIS 2017和DAVIS 2016這三個流行的基準數據集上驗證了AOT的性能。結果顯示:
- YouTube-VOS:AOT在驗證集2018和2019的分割性能(J&F指標)上均優于所有現有方法,例如AOT-L達到了83.8%和83.7%,而之前的最佳方法CFBI+為82.8%和81.8%。同時,AOT在多目標運行時效率上也顯著優于其他方法,例如AOT-T在保持實時性能(41.0 FPS)的同時,性能優于CFBI+。
- DAVIS 2017:AOT在驗證集和測試集上均取得了最佳性能,例如R50-AOT-L在驗證集上達到了84.9%,在測試集上達到了79.6%,并且保持了較高的運行效率(18.0 FPS)。
- DAVIS 2016:盡管AOT主要針對多目標VOS,但在單目標場景下也取得了新的最佳性能,例如R50-AOT-L達到了91.1%,并且運行效率是現有方法的兩倍。
此外,文章還提供了與其他最新實時方法(如SAT和GC)的比較,AOT在保持實時性能的同時,顯著優于這些方法。
4)結論
AOT通過其創新的識別機制和LSTT模塊,在多目標視頻目標分割任務中實現了效率和性能的雙重提升。該方法不僅在多個基準測試中取得了優異的性能,還保持了較高的運行效率,使其在實際應用中具有很大的潛力。此外,AOT的架構設計允許通過調整LSTT模塊的數量來靈活平衡性能和速度,為未來的研究和應用提供了更多的可能性。
2、Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
這篇文章提出了一種名為“Space-Time Correspondence Network (STCN)”的新型視頻目標分割(VOS)方法,旨在通過改進時空對應關系建模來提高效率和性能。STCN通過直接在幀之間建立對應關系,避免了為每個目標重新編碼掩碼特征,從而實現了一個高效且魯棒的框架。該方法在DAVIS和YouTubeVOS數據集上取得了新的最高性能,并且運行速度超過20 FPS,顯著優于現有方法。
1)背景知識
視頻目標分割(VOS)任務的目標是在視頻序列中標記和分割目標實例。本文關注半監督設置,即第一幀的分割掩碼已知,算法需要推斷剩余幀的分割掩碼。與視頻目標跟蹤不同,VOS需要詳細的目標掩碼,而不僅僅是簡單的邊界框。一個高性能的算法應該能夠在部分或完全遮擋、外觀變化和目標變形的情況下,將目標從背景或其他干擾因素中區分出來。
2)研究方法
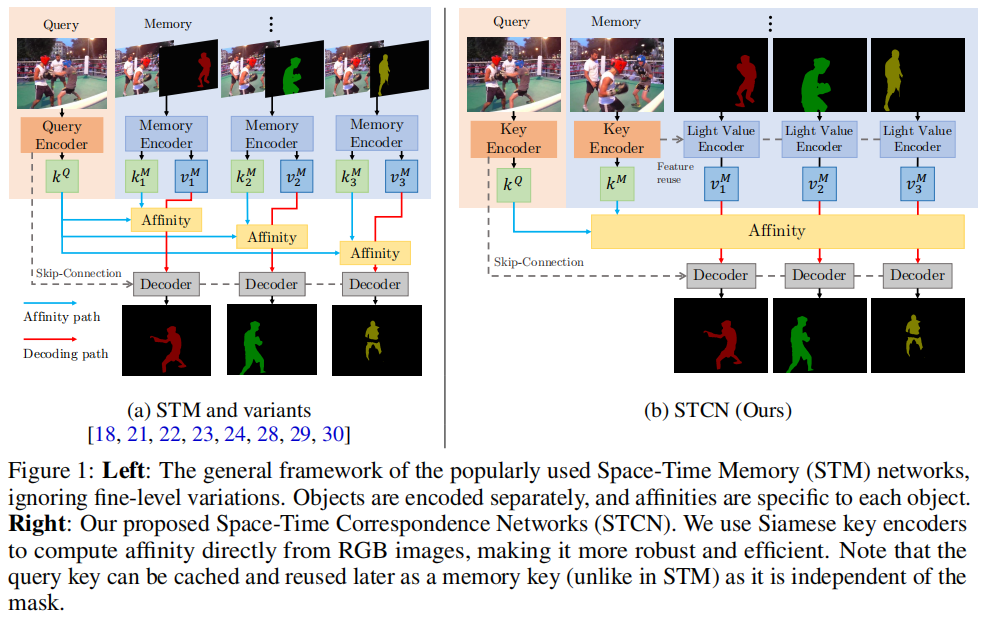

STCN的核心思想是直接在幀之間建立對應關系,而不是為視頻中的每個目標構建特定的內存庫和親和力。這種方法不僅更高效,而且更魯棒,因為模型被迫學習所有目標之間的關系,而不僅僅是標記的目標。STCN通過以下關鍵步驟實現:
-
特征提取:STCN使用ResNet50作為鍵編碼器(僅輸入圖像)和ResNet18作為值編碼器(輸入圖像和掩碼)。鍵特征(和結果親和力)可以獨立于掩碼提取,每個幀只計算一次,并且在內存和查詢之間是對稱的。這種設計允許在不引入掩碼作為干擾的情況下,在視頻幀之間建立對應關系。
-
記憶讀取和解碼:給定T個記憶幀和一個查詢幀,STCN計算記憶鍵和查詢鍵之間的親和力矩陣,并使用softmax歸一化。然后,通過加權和的方式從記憶特征中聚合查詢幀的特征,這些特征隨后被傳遞到解碼器以生成掩碼。
-
記憶管理:STCN在記憶管理上進行了優化,避免了使用臨時記憶幀,因為這會導致記憶鍵與查詢幀過于相似,從而導致漂移。這種修改減少了對值編碼器的調用次數,顯著提高了速度。
-
親和力計算:STCN提出了使用負平方歐幾里得距離代替點積來計算親和力。這種改變確保了每個記憶節點都有機會顯著貢獻(給定正確的查詢),從而提高了性能、魯棒性和內存使用效率。
3)實驗結果
STCN在DAVIS 2017和YouTubeVOS 2018驗證集上進行了廣泛的實驗,并與其他方法進行了比較。結果顯示:
- DAVIS 2017:STCN在驗證集上取得了85.4%的J&F分數,超過了之前最好的方法MiVOS(83.3%)和STM(81.8%),并且運行速度為20.2 FPS,顯著快于STM(10.2 FPS)。
- YouTubeVOS 2018:STCN在驗證集上取得了83.0%的G分數,超過了之前的最高成績82.7%,并且在多目標場景下運行速度超過20 FPS。
此外,STCN在DAVIS 2016和YouTubeVOS 2019驗證集上也取得了優異的成績,并在DAVIS交互式賽道上展示了其性能。
4)關鍵結論
STCN通過直接幀到幀的對應關系和改進的親和力計算方法,提供了一種簡單、高效且強大的視頻目標分割解決方案。它不僅在性能上超越了現有的最先進方法,而且在運行速度上也具有顯著優勢。STCN的提出為未來視頻目標分割的研究提供了一個新的高效基線。
盡管STCN在多個基準測試中取得了優異的性能,但它在處理具有相似外觀且相隔較遠的目標時可能會出現錯誤分割的情況。這是因為STCN目前沒有考慮時間一致性線索,例如光流或局部匹配。作者認為,STCN的框架足夠簡單,可以很容易地擴展以包含時間一致性考慮,從而實現進一步的改進。
3、Recurrent Dynamic Embedding for Video Object Segmentation
這篇文章提出了一種名為“Recurrent Dynamic Embedding (RDE)”的新型視頻目標分割(VOS)方法,旨在解決基于時空記憶(STM)的VOS網絡在處理長視頻時面臨的內存需求不斷增加和噪聲積累的問題。RDE通過引入循環動態嵌入和時空聚合模塊(SAM),構建了一個固定大小的記憶庫,并通過無偏指導損失和自校正策略來提高模型的魯棒性和準確性。該方法在多個基準數據集上取得了優異的性能,并在合成長視頻中展示了其有效性。
1)背景知識
視頻目標分割(VOS)是視頻理解中的一個基礎任務,特別是在半監督設置中,給定第一幀的實例標注,算法需要分割出其他幀中的實例。現有的基于STM的VOS網絡通過不斷增加記憶庫的大小來提高性能,但這種方法存在兩個主要問題:一是硬件難以承受不斷增加的內存需求;二是存儲大量信息會引入噪聲,不利于從記憶庫中讀取最重要的信息。
2)研究方法

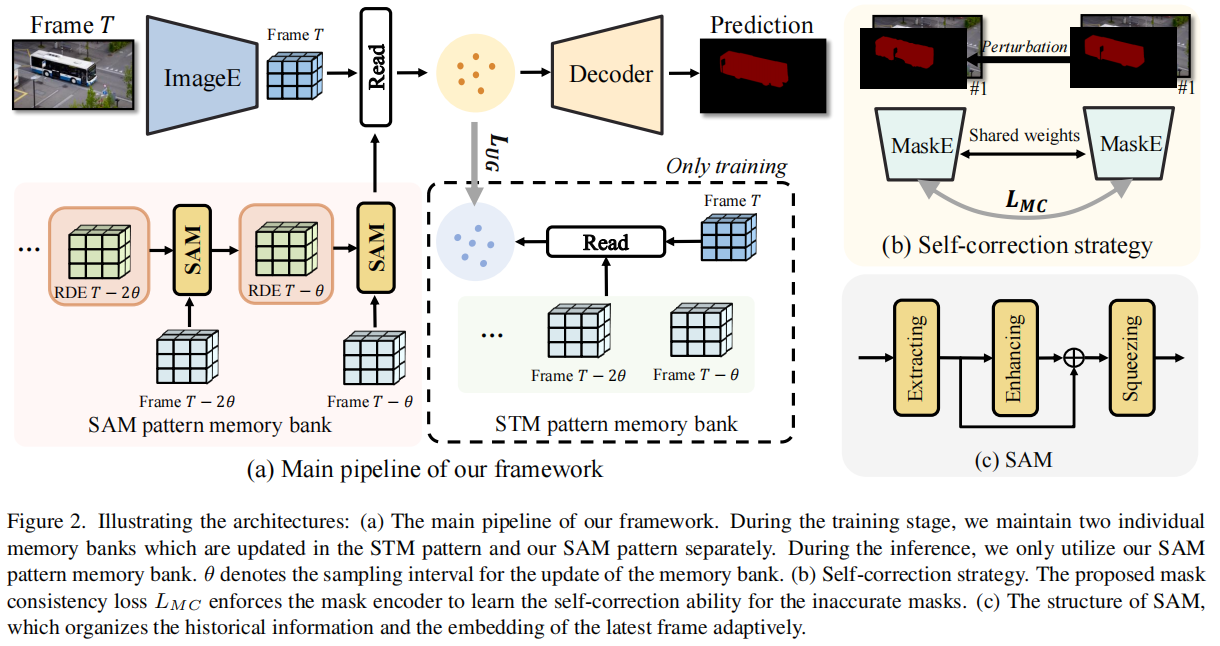
為了解決上述問題,文章提出了RDE方法,其核心是構建一個固定大小的記憶庫。具體來說,RDE通過以下三個關鍵部分實現:
-
循環動態嵌入(RDE):RDE通過SAM生成和更新,利用歷史信息的線索和最新幀的嵌入來提供更豐富的表示。RDE的更新過程包括三個部分:提取、增強和壓縮。提取部分負責組織歷史RDE和最新幀嵌入之間的時空關系;增強部分通過空洞空間金字塔池化(ASPP)強化這種關系;壓縮部分則通過卷積操作壓縮增強后的特征。
-
時空聚合模塊(SAM):SAM負責生成和更新RDE,通過組織歷史信息和最新幀的嵌入來適應性地更新記憶庫。SAM包括提取、增強和壓縮三個部分,分別負責組織時空關系、強化關系和壓縮信息。
-
無偏指導損失(Unbiased Guidance Loss):為了避免SAM在長視頻中由于循環使用而導致的誤差累積,文章提出了一種無偏指導損失。這種損失通過比較SAM模式記憶庫和STM模式記憶庫的分布來控制SAM的更新過程,使其在訓練階段更加穩定。
-
自校正策略(Self-correction Strategy):考慮到記憶庫中掩碼的質量會影響查詢幀的分割性能,文章設計了一種自校正策略,通過模擬不同質量的掩碼并約束這些掩碼的嵌入與真實掩碼的嵌入接近,從而在訓練階段學習自校正能力。
3)實驗結果
文章在DAVIS 2017、DAVIS 2016和YouTube-VOS 2019等多個基準數據集上進行了廣泛的實驗。實驗結果表明,RDE方法在性能和速度上都取得了最佳的權衡:
- DAVIS 2017驗證集:RDE方法達到了86.1%的J&F分數,比STCN高出0.7%,并且速度更快(27 FPS對比20.2 FPS)。
- DAVIS 2017測試集:RDE方法在測試集上也表現出色,J&F分數為78.9%。
- DAVIS 2016驗證集:RDE方法達到了91.6%的J&F分數,速度為35 FPS,比STCN快40%。
- YouTube-VOS 2019驗證集:盡管RDE方法沒有超過STCN,但它仍然超過了其他最先進的方法,無論是否使用BL30K數據集進行訓練。
此外,文章還通過合成長視頻實驗驗證了RDE方法在處理長視頻時的有效性。實驗結果表明,隨著合成長視頻長度的增加,RDE方法的性能和速度幾乎不受影響,而STCN的性能和速度明顯下降。
4)關鍵結論
文章提出的RDE方法通過構建固定大小的記憶庫,有效地解決了STM方法在處理長視頻時面臨的內存需求和噪聲積累問題。通過SAM模塊和無偏指導損失,RDE方法在訓練階段更加穩定,并且能夠自適應地更新記憶庫。自校正策略進一步提高了模型對記憶庫中掩碼質量的魯棒性。實驗結果表明,RDE方法在多個基準數據集上都取得了優異的性能,并且在處理長視頻時表現出色。
4、XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
這篇文章介紹了一種名為 XMem 的新型視頻目標分割(VOS)架構,專門針對長視頻設計,靈感來源于 Atkinson-Shiffrin 記憶模型。XMem 通過引入多種獨立但深度連接的特征記憶庫,解決了傳統 VOS 方法在處理長視頻時面臨的內存需求和性能衰減問題。該方法在長視頻數據集上大幅超越了現有技術,并在短視頻數據集上與現有技術持平。
1)背景知識

視頻目標分割(VOS)任務的目標是在給定視頻中標記和分割出特定的目標對象。在半監督設置中,用戶提供了第一幀的標注,算法需要盡可能準確地分割出其他幀中的目標對象,同時盡量實現實時在線處理,并在處理長視頻時保持較小的內存占用。現有的 VOS 方法大多使用單一類型的特征記憶庫來存儲目標對象的深度網絡表示,但對于超過一分鐘的長視頻,單一記憶庫模型會將內存消耗和準確性緊密聯系在一起,限制了模型的擴展性。
2)研究方法

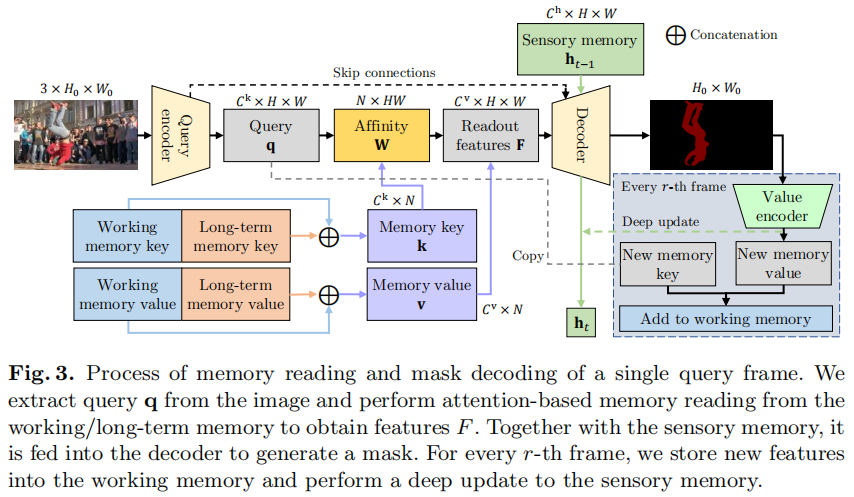
XMem 的核心在于模仿 Atkinson-Shiffrin 記憶模型,引入了三種特征記憶庫:
- 感覺記憶(Sensory Memory):快速更新,提供時間平滑性,但不適合長期預測,因為存在表示漂移問題。
- 工作記憶(Working Memory):從歷史幀的子集中聚合而來,不隨時間漂移,用于短期預測。
- 長期記憶(Long-term Memory):緊湊且持久,通過記憶強化算法將工作記憶中的元素整合到長期記憶中,避免內存爆炸并最小化長期預測的性能衰減。
XMem 的關鍵創新點包括:
- 記憶強化算法(Memory Potentiation Algorithm):通過聚合更豐富的信息到長期記憶的原型中,防止由于子采樣導致的混疊現象。
- 記憶閱讀機制(Memory Reading Mechanism):結合工作記憶和長期記憶,通過注意力機制提取查詢幀所需的特征。
- 自適應更新策略(Adaptive Update Strategy):根據視頻內容動態調整記憶庫的更新頻率,確保在不同場景下都能保持高效的性能。
3)實驗結果
XMem 在多個基準數據集上進行了廣泛的實驗,包括長視頻數據集和短視頻數據集。實驗結果表明,XMem 在長視頻數據集上大幅超越了現有技術,同時在短視頻數據集上與現有技術持平。具體結果如下:
- 長視頻數據集(Long-time Video Dataset):XMem 在長視頻數據集上取得了顯著的性能提升,例如在 3× 變體上,XMem 的 J&F 分數為 90.0%,而其他方法如 STCN 的分數為 84.6%,性能衰減僅為 0.2%,而 STCN 的衰減為 -2.7%。
- 短視頻數據集(DAVIS 和 YouTube-VOS):XMem 在 DAVIS 2017 驗證集上達到了 86.2% 的 J&F 分數,在 YouTube-VOS 2018 驗證集上達到了 85.7% 的 G 分數,與現有技術持平,同時在處理長視頻時保持了較低的內存占用。
4)關鍵結論
XMem 通過引入多種特征記憶庫和記憶強化算法,有效地解決了傳統 VOS 方法在處理長視頻時面臨的內存需求和性能衰減問題。XMem 不僅在長視頻數據集上取得了顯著的性能提升,還在短視頻數據集上與現有技術持平,展示了其在不同場景下的廣泛適用性。此外,XMem 的內存占用低,適合在資源受限的設備上運行,例如移動設備。
盡管 XMem 在處理長視頻時表現出色,但在目標對象移動過快或存在嚴重運動模糊的情況下,即使是更新速度最快的感官記憶也無法跟上目標對象的變化,導致分割失敗。作者認為,使用具有更大感受野的感官記憶可以解決這一問題。
5、Decoupling Features in Hierarchical Propagation for Video Object Segmentation
這篇文章提出了一種名為 Decoupling Features in Hierarchical Propagation (DeAOT) 的新型視頻目標分割(VOS)方法,旨在解決現有基于層次傳播的VOS方法(如AOT)在傳播過程中因增加目標特定信息而導致目標無關視覺信息丟失的問題。DeAOT通過解耦目標無關和目標特定的特征傳播,并引入高效的門控傳播模塊(Gated Propagation Module, GPM),顯著提高了VOS的性能和效率。
1)背景知識
視頻目標分割(VOS)是視頻理解中的一個基礎任務,目標是在給定視頻中標記和分割出特定的目標對象。半監督VOS要求算法在給定某些幀的標注掩碼后,能夠將這些掩碼信息傳播到整個視頻序列中。近年來,基于注意力機制的VOS方法取得了顯著進展,其中AOT通過引入基于Transformer的層次傳播機制,實現了從過去幀到當前幀的信息傳播,并將當前幀的特征從目標無關(object-agnostic)轉換為目標特定(object-specific)。
2)研究方法
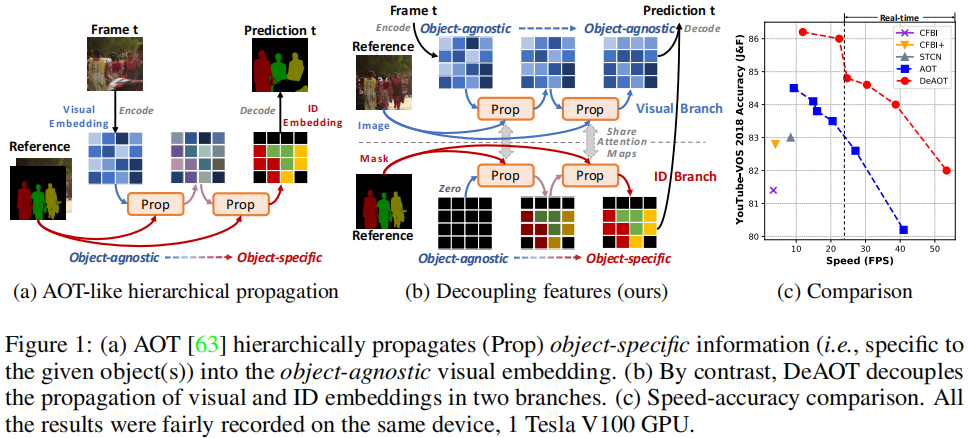
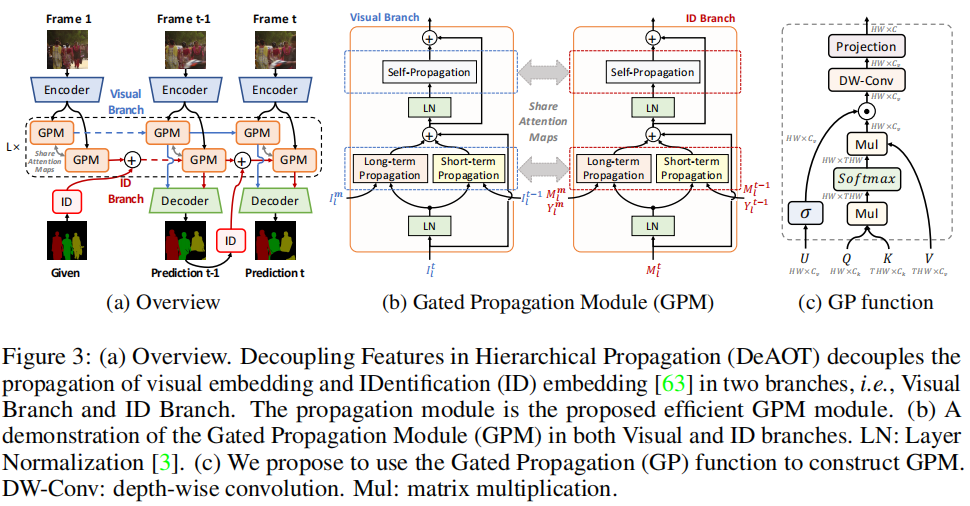
DeAOT的核心思想是將目標無關和目標特定的特征傳播解耦到兩個獨立的分支中,即視覺分支(Visual Branch)和ID分支(ID Branch)。視覺分支負責匹配對象、收集過去的視覺信息并細化對象特征;ID分支則利用視覺分支計算的注意力圖(attention maps)將ID嵌入從過去幀傳播到當前幀。這種雙分支結構避免了在深層傳播層中丟失目標無關的視覺信息,從而有助于學習更魯棒的視覺嵌入。
雙分支傳播
- 視覺分支:通過計算注意力圖在視覺嵌入上進行對象匹配,并傳播過去的視覺信息。
- ID分支:利用視覺分支的注意力圖將ID嵌入從過去幀傳播到當前幀。
門控傳播模塊(GPM)
為了提高效率,DeAOT提出了一種基于單頭注意力的GPM模塊,用于構建層次傳播。GPM包括長時傳播、短時傳播和自傳播三種類型的傳播過程,每種傳播過程都使用了門控傳播函數(GP function)。
3)實驗結果
DeAOT在多個基準數據集上進行了廣泛的實驗,包括YouTube-VOS、DAVIS 2017、DAVIS 2016和VOT 2020。實驗結果表明,DeAOT在準確性和運行速度上均優于現有的AOT方法。
- YouTube-VOS:DeAOT在2018和2019年的驗證集上分別達到了86.0%和85.9%的J&F分數,運行速度為22.4fps,顯著優于AOT的84.1%和14.9fps。
- DAVIS 2017:DeAOT在驗證集和測試集上分別達到了85.2%和80.7%的J&F分數,運行速度為27fps,優于AOT的83.8%和18.7fps。
- DAVIS 2016:DeAOT達到了92.3%的J&F分數,運行速度為27fps,優于AOT的91.1%和18.0fps。
- VOT 2020:DeAOT在EAO分數上達到了0.622,顯著優于現有的跟蹤方法。
4)關鍵結論
DeAOT通過解耦目標無關和目標特定的特征傳播,避免了在深層傳播層中丟失視覺信息,從而提高了VOS的性能。此外,DeAOT提出的GPM模塊在保持高效的同時,進一步提升了性能。DeAOT在多個基準數據集上取得了新的最高性能,并在運行速度上優于現有方法。
盡管DeAOT在多個基準數據集上取得了優異的性能,但在處理具有嚴重遮擋的多個高度相似目標時,DeAOT仍然可能失敗。這表明在復雜場景下,進一步改進特征傳播和目標匹配機制仍然是一個挑戰。
6、Tracking Anything with Decoupled Video Segmentation
這篇文章提出了一種名為 DEVA(Decoupled Video Segmentation Approach)的新型視頻分割方法,旨在通過解耦圖像級分割和時序傳播來實現對任意目標的跟蹤和分割。DEVA通過結合任務特定的圖像級分割模型和通用的時序傳播模型,有效減少了對大規模視頻訓練數據的依賴,并在多個視頻分割任務中取得了優異的性能。
背景知識
視頻分割是計算機視覺中的一個基礎任務,對于視頻理解至關重要。傳統的端到端視頻分割方法需要在標注好的視頻數據集上進行訓練,這在大規模詞匯表或開放世界設置中變得不切實際,因為標注成本高昂且難以擴展。DEVA通過解耦圖像級分割和時序傳播,利用更便宜的圖像級模型和通用的時序傳播模型,減少了對大規模視頻訓練數據的需求。

研究方法
DEVA的核心思想是將視頻分割任務分解為兩個獨立但相互協作的模塊:圖像級分割模塊和時序傳播模塊。圖像級分割模塊負責提供特定任務的分割假設,而時序傳播模塊則負責在視頻序列中傳播這些分割假設,生成連貫的分割結果。
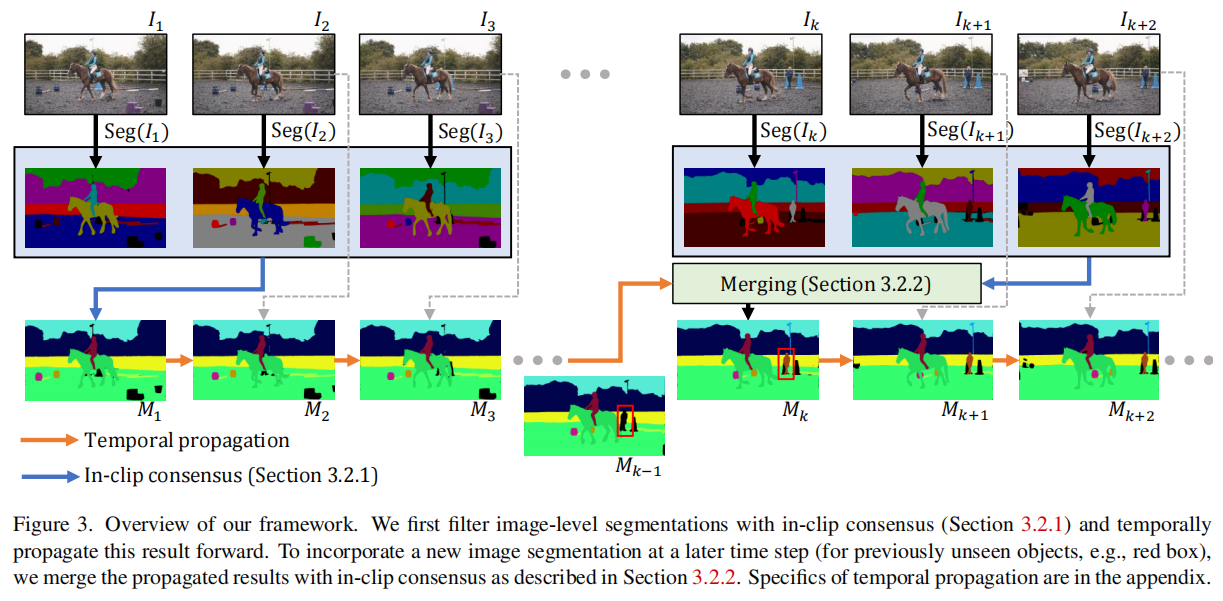

雙向傳播
DEVA提出了一種雙向傳播算法,用于在(半)在線設置中融合不同幀的分割假設。具體來說,DEVA通過以下步驟實現:
- In-clip Consensus(剪輯內共識):通過查看未來幾幀的分割結果,DEVA在當前幀上達成共識,從而減少單幀分割的噪聲。
- Temporal Propagation(時序傳播):將經過剪輯內共識處理后的分割結果傳播到后續幀。
- Merging Propagation and Consensus(傳播和共識的融合):將傳播得到的分割結果與新的圖像分割結果合并,以處理新出現的對象。
時序傳播模塊
DEVA的時序傳播模塊基于XMem模型,該模型通過維護一個內部特征記憶來實現高效的視頻對象分割。DEVA對XMem進行了幾項改進,包括增加感知記憶的通道數、使用加法而不是連接來融合記憶讀出結果,以及引入輔助損失來監督感知記憶。
實驗結果
DEVA在多個基準數據集上進行了廣泛的實驗,包括大規模視頻全景分割(VIPSeg)、開放世界視頻分割(BURST)、引用視頻分割(Ref-YouTubeVOS 和 Ref-DAVIS)以及無監督視頻對象分割(DAVIS-16 和 DAVIS-17)。實驗結果表明,DEVA在這些任務中均取得了優異的性能。
- 大規模視頻全景分割(VIPSeg):DEVA在VIPSeg驗證集上取得了42.1%的VPQ分數,顯著優于現有的端到端方法。
- 開放世界視頻分割(BURST):DEVA在BURST數據集上取得了69.9%的OWTA分數,優于現有的跟蹤方法。
- 引用視頻分割:DEVA在Ref-YouTubeVOS和Ref-DAVIS數據集上分別取得了66.0%和66.3%的J&F分數,優于現有的方法。
- 無監督視頻對象分割:DEVA在DAVIS-16和DAVIS-17數據集上分別取得了88.9%和73.4%的J&F分數,表現出色。
關鍵結論
DEVA通過解耦圖像級分割和時序傳播,有效地減少了對大規模視頻訓練數據的依賴,并在多個視頻分割任務中取得了優異的性能。這種方法特別適合于大規模詞匯表或開放世界設置,其中視頻數據和標注成本高昂且難以獲取。DEVA的雙向傳播算法和改進的時序傳播模塊是其實現高性能的關鍵。
盡管DEVA在多個任務中表現出色,但它也有一些限制。首先,由于時序傳播模塊是任務無關的,它無法自行檢測新對象,這可能導致新對象的檢測延遲。其次,在數據充足的情況下,端到端方法仍然優于DEVA,但DEVA在大規模詞匯表或開放世界設置中更具潛力。
7、Putting the Object Back into Video Object Segmentation
這篇文章介紹了一種名為Cutie的視頻目標分割(Video Object Segmentation, VOS)網絡,它通過對象級別的記憶讀取來提高在復雜場景下的分割性能。Cutie的核心創新在于其對象級別的記憶讀取機制,通過對象查詢和對象變換器(object transformer)實現,能夠有效地將對象從記憶中重新引入到查詢幀中,從而在具有挑戰性的數據集上取得了顯著的性能提升。
1)背景知識與研究動機
視頻目標分割(VOS)任務要求在給定第一幀注釋的情況下,跟蹤并分割視頻中的目標對象。近年來,基于記憶的VOS方法通過從過去的分割幀中計算記憶表示,并在新查詢幀中讀取這些記憶來實現分割。然而,這些方法主要依賴于像素級別的匹配,容易受到干擾,尤其是在存在干擾物的情況下,導致性能下降。為了解決這一問題,Cutie提出了一種對象級別的記憶讀取方法,通過對象查詢和對象變換器來整合像素特征,從而在復雜場景下實現更魯棒的分割性能。

2)研究方法
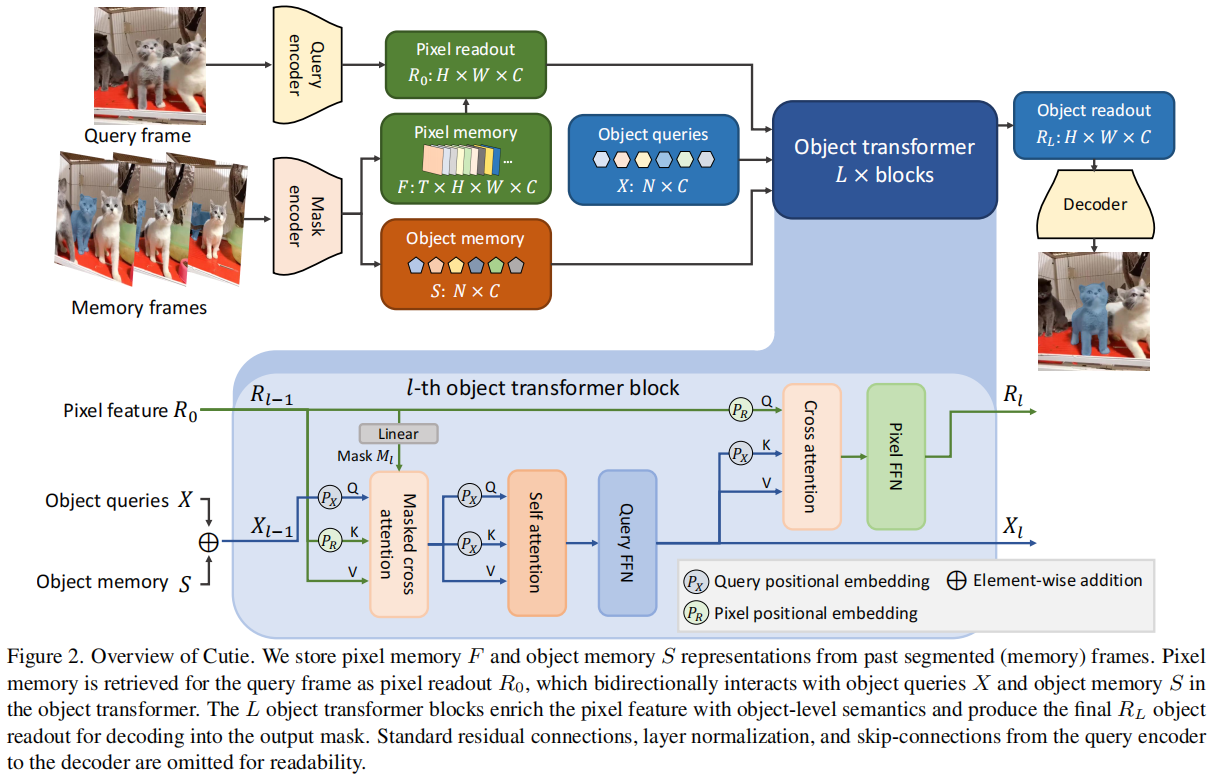
Cutie的核心是對象級別的記憶讀取機制,它通過以下三個主要部分實現:
- 對象變換器(Object Transformer):Cutie使用一組對象查詢(object queries)與從像素記憶中讀取的特征進行交互。這些對象查詢作為目標對象的高級摘要,而高分辨率特征圖則用于精確分割。對象變換器通過迭代的方式將對象查詢與像素特征結合起來,從而在保持全局對象信息的同時,也保留了高分辨率的像素特征。
- 前景-背景掩碼注意力(Foreground-Background Masked Attention):為了清晰地分離前景和背景的語義,Cutie擴展了掩碼注意力機制,使得部分對象查詢只關注前景,而其余的則只關注背景。這種分離有助于在存在干擾物的情況下保持分割的準確性。
- 緊湊對象記憶(Compact Object Memory):Cutie引入了一個緊湊的對象記憶來總結目標對象的特征,這些特征在查詢時被檢索為目標特定的對象級表示,從而增強了對象查詢的表示能力。
3)實驗
實驗部分評估了Cutie在多個標準基準測試上的性能,包括DAVIS 2017、YouTubeVOS和具有挑戰性的MOSE數據集。結果顯示,Cutie在MOSE數據集上相較于XMem和DeAOT等方法有顯著的性能提升,同時在DAVIS和YouTubeVOS數據集上也保持了競爭力,無論是在準確性還是效率上。
關鍵數值結果
- 在MOSE數據集上,Cutie相比于XMem提升了8.7 J&F,同時保持了類似的運行時間。
- 在DAVIS-2017和YouTubeVOS數據集上,Cutie-base模型的J&F分數分別為67.9和87.7,表現出色。
- 在長視頻評估中,Cutie在BURST數據集上的表現也優于其他方法,例如Cutie-base在長視頻上的HOTA分數為61.8%,優于XMem的57.9%。
4)結論
Cutie通過其對象級別的記憶讀取機制,在復雜場景下的視頻目標分割任務中取得了顯著的性能提升。它有效地整合了自頂向下的對象級信息和自底向上的像素級特征,使得在存在干擾物和遮擋的情況下也能保持魯棒的分割性能。此外,Cutie的設計允許它在實時應用中保持高效率。
盡管Cutie在許多情況下表現出色,但在高度相似的對象靠近或相互遮擋時,它可能會失敗。這種情況下,像素記憶和對象記憶可能無法提供足夠的區分特征供對象變換器操作。





` 和 `關卡藍圖(Level Blueprint)`的關系)



)



)





邏輯圖解+實驗詳解)