1 二進制日志(Binlog):配置與核心作用
Binlog 是 MySQL 中跨存儲引擎的核心日志,記錄所有數據修改操作,主要用于主從復制、數據備份恢復與跨庫遷移。
1.1 Binlog 核心操作
開啟 Binlog
若需開啟 Binlog,需在 MySQL 配置文件的 [mysqld] 節點下添加以下配置(配置文件路徑需根據實際部署情況調整):
# 編輯配置文件(以常見路徑為例)
vim /data/mysql/conf/my.cnf# 添加 Binlog 配置:指定日志存儲路徑與前綴
log-bin = /data/mysql/binlog/mysql-bin
配置后需重啟 MySQL 服務使設置生效:
/etc/init.d/mysql.server restart
驗證 Binlog 狀態
通過以下命令查看 Binlog 是否已開啟:
show variables like '%log_bin%';
若結果中 log_bin 取值為 ON,表示 Binlog 已啟用。
關閉 Binlog
關閉 Binlog 分為「全局關閉」與「當前會話關閉」兩種場景:
- 全局關閉(永久生效):
# 1. 編輯配置文件 vim /data/mysql/conf/my.cnf# 2. 注釋原 log-bin 配置 # log-bin = /data/mysql/binlog/mysql-bin# 3. 添加關閉參數(二選一即可) skip_log_bin # 或 disable_log_bin# 4. 重啟 MySQL 服務 /etc/init.d/mysql.server restart# 5. 驗證關閉結果 show variables like '%log_bin%'; - 當前會話關閉(臨時生效,重啟后失效):
set sql_log_bin = 0;
配置 Binlog 大小限制
默認情況下,單個 Binlog 文件最大為 1G,可通過配置調整大小:
# 1. 編輯配置文件
vim /data/mysql/conf/my.cnf# 2. 添加大小限制(示例:設置為 512M)
max-binlog-size = 512M# 3. 重啟 MySQL 服務
/etc/init.d/mysql.server restart# 4. 驗證配置
show variables like 'max_binlog_size';# 5. (可選)單位換算:將字節數轉為 GB(示例)
select @@max_binlog_size / 1024 / 1024 / 1024 as max_binlog_size_gb;
1.2 Binlog 的三大核心作用
- 主從復制:主庫將數據變更記錄到 Binlog,從庫通過 IO 線程讀取主庫 Binlog 并寫入本地中繼日志,再通過 SQL 線程回放中繼日志,實現主從數據同步。
- 數據備份與恢復:當發生誤操作(如誤刪表、誤更新)時,可通過「全量備份 + 增量 Binlog」恢復數據——先恢復全量備份,再執行從備份時間點到誤操作前的 Binlog,排除錯誤操作即可還原數據。
- 跨庫遷移:遷移 MySQL 數據到其他數據庫(如 TiDB、ClickHouse)時,可通過工具(如 Canal、Otter)監聽 Binlog,捕捉增量數據變更并同步至目標數據庫,實現無感知遷移。
2 二進制日志(Binlog)的記錄格式
Binlog 支持三種記錄格式,分別適用于不同場景,需根據業務需求選擇。
2.1 三種記錄格式說明
- STATEMENT:記錄完整的 SQL 語句(如
update user set name='test' where id=1),不記錄行級數據變化。 - ROW:記錄行級數據的具體修改(如「將 id=1 的行的 name 從 ‘old’ 改為 ‘test’」),不記錄原始 SQL。
- MIXED:默認使用 STATEMENT 格式,當 SQL 語句可能導致主從不一致(如使用
uuid()、now()等非確定性函數)時,自動切換為 ROW 格式。
2.2 三種格式的優缺點對比
| 格式 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| STATEMENT | 日志體積小、IO 開銷低、易閱讀、性能高 | 主從可能不一致、不支持閃回 | 無特殊函數的簡單業務、對日志體積敏感場景 |
| ROW | 主從數據絕對一致、支持閃回 | 日志體積大、IO 開銷高、不易直接閱讀 | 主從強一致需求、需閃回數據的場景 |
| MIXED | 兼顧體積與一致性,自動適配場景 | 不支持閃回、部分高可用架構不兼容 | 大多數通用業務場景 |
2.3 修改 Binlog 記錄格式
Binlog 格式修改支持「全局永久生效」與「會話臨時生效」:
- 全局永久生效(需重啟):
# 1. 編輯配置文件 vim /data/mysql/conf/my.cnf# 2. 添加格式配置(取值:ROW/STATEMENT/MIXED) binlog_format = ROW# 3. 重啟 MySQL 服務 /etc/init.d/mysql.server restart - 會話臨時生效(僅當前連接):
set session binlog_format = 'ROW'; - 全局臨時生效(所有新連接,重啟后失效):
set global binlog_format = 'ROW';
3 二進制日志(Binlog)的解析方法
解析 Binlog 是定位數據變更、排查問題的關鍵操作,常見解析方式包括「基于位點」「基于時間」「基于 GTID」等。
3.1 基于位點解析
通過 Binlog 文件的「起始位點」定位解析范圍,適用于已知具體變更位置的場景:
-
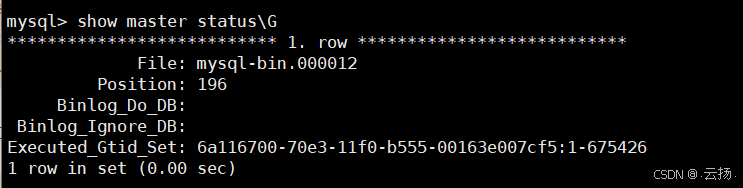
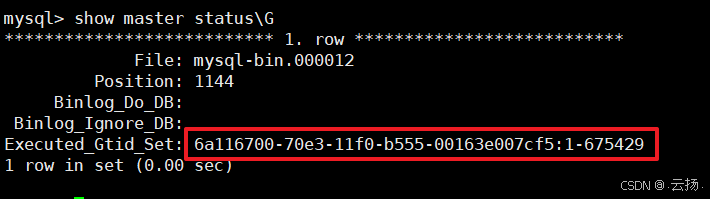
查看當前 Binlog 文件、位點與 GTID:
show master status\G結果中
File為當前 Binlog 文件名,Position為當前位點。
-
執行測試操作(如創建表、插入數據),生成 Binlog 記錄:
# 示例:創建測試表并插入數據 create table martin.binlog_test(id int); insert into martin.binlog_test select 1; -
再次查看位點,確認變更后的位點范圍:
show master status\G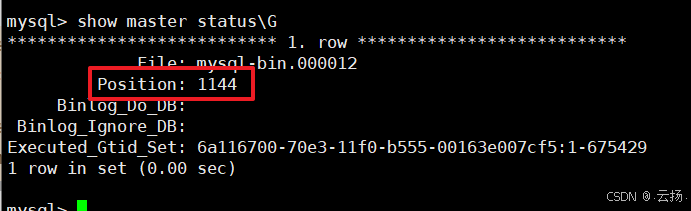
-
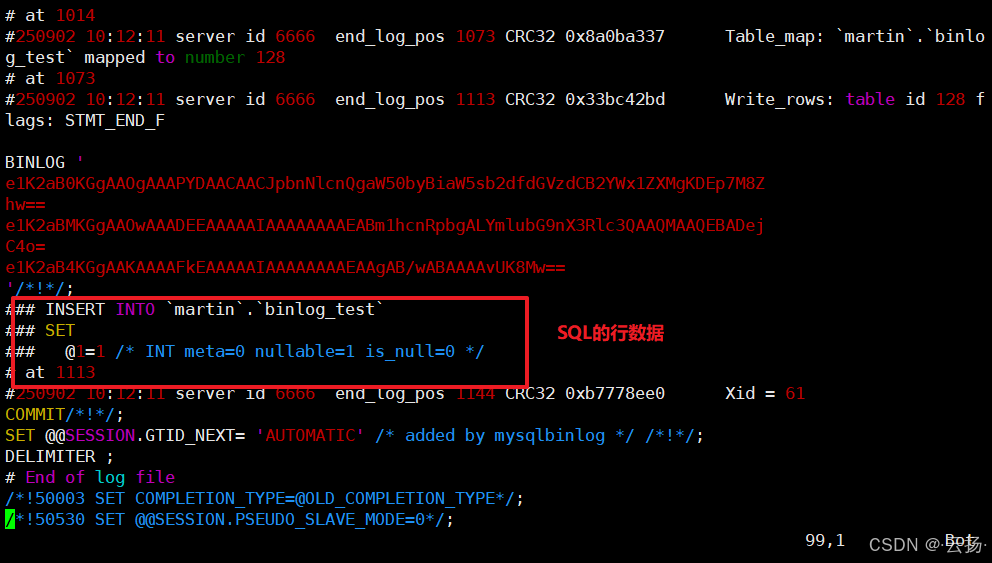
進入 Binlog 存儲目錄,執行解析命令:
# 進入目錄(路徑與開啟 Binlog 時配置一致) cd /data/mysql/binlog/# 解析:從起始位點 618 開始,輸出到指定文件 mysqlbinlog --start-position=618 mysql-bin.000019 -vv > /data/01.sql其中
-vv表示輸出詳細行數據,便于查看具體變更。 -
查看解析結果:
cat /data/01.sql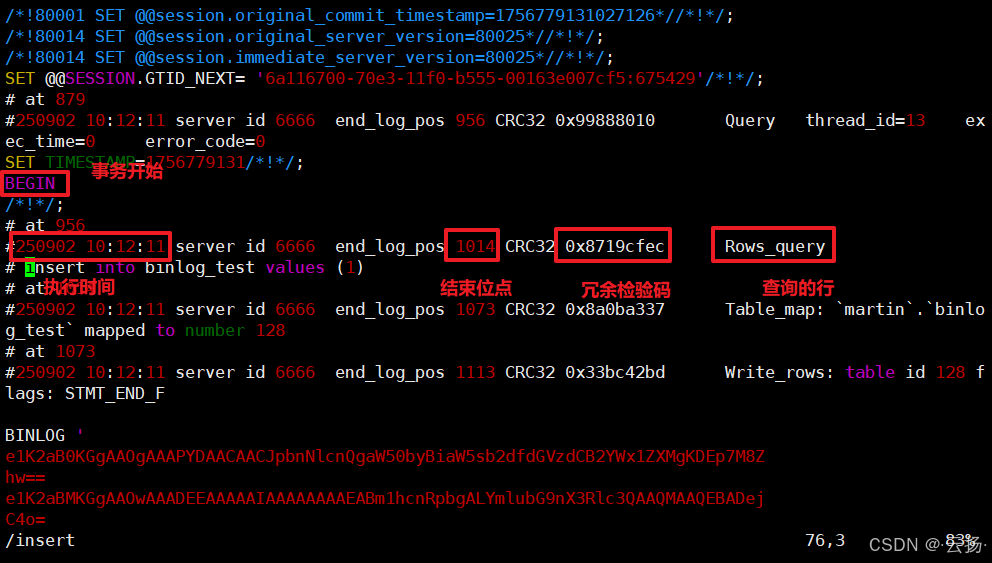
3.2 基于時間解析
通過「起始時間」定位解析范圍,適用于已知變更時間的場景:
# 解析 2023-05-08 22:30:00 之后的 Binlog 記錄
mysqlbinlog --start-datetime="2023-05-08 22:30:00" mysql-bin.000019 > /data/02.sql# 查看解析結果
cat /data/02.sql
若需限定時間范圍,可添加 --stop-datetime 參數(如 --stop-datetime="2023-05-08 23:00:00")。
3.3 基于 GTID 解析
GTID(全局事務ID)是 MySQL 8.0 推薦的事務標識,通過 GTID 解析可精準定位單個事務的 Binlog:
-
查看當前 GTID(需先開啟 GTID 功能):
show master status\G結果中
Executed_Gtid_Set包含已執行的 GTID。
-
基于 GTID 解析 Binlog:
# 解析指定 GTID 的事務(示例 GTID:6a116700-70e3-11f0-b555-00163e007cf5:1-675429) mysqlbinlog --include-gtids '6a116700-70e3-11f0-b555-00163e007cf5:1-675429' mysql-bin.000007 -vv > /data/03.sql# 查看解析結果 cat /data/03.sql
3.4 僅解析指定數據庫的 Binlog
通過 -d 參數指定數據庫,僅解析該庫的變更記錄,適用于多庫隔離場景:
- 執行跨庫測試操作,生成多庫 Binlog:
# 查看當前位點 show master status\G# 在 martin 庫創建表 use martin; create table binlog_test_01(id int);# 在 test 庫創建表 use test; create table aaa(id int);# 查看變更后位點 show master status\G - 僅解析 martin 庫的 Binlog:
# 解析 martin 庫,限定位點范圍(2147 至 2540) mysqlbinlog --start-position=2147 --stop-position=2540 -d martin mysql-bin.000012 -vv > /data/04.sql# 查看解析結果(僅包含 martin 庫的變更) cat /data/04.sql
3.5 解析加密的 Binlog
MySQL 支持對 Binlog 加密存儲,解析時需通過 MySQL 服務認證,無法直接讀取本地文件。
步驟 1:開啟 Binlog 加密
# 1. 編輯配置文件
vim /data/mysql/conf/my.cnf# 2. 添加加密配置
early-plugin-load = keyring_file.so # 加載密鑰文件插件
keyring_file_data = /data/mysql/keyring # 密鑰存儲路徑
binlog_encryption = on # 開啟 Binlog 加密# 3. 重啟 MySQL 服務
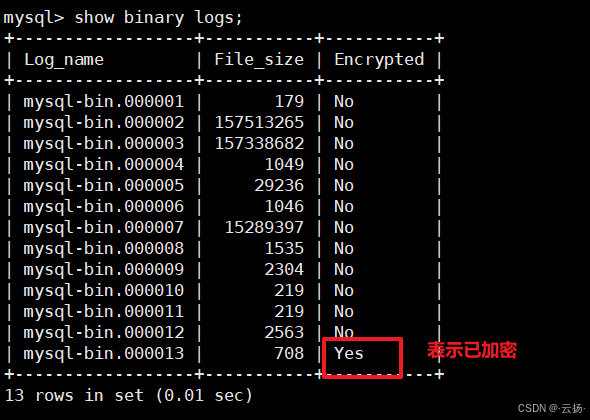
/etc/init.d/mysql.server restart# 4. 驗證加密是否開啟
show binary logs;
步驟 2:解析加密 Binlog
直接讀取加密文件會報錯,需通過 --read-from-remote-server 參數從 MySQL 服務讀取:
# 解析加密 Binlog(需輸入 MySQL 用戶名與密碼)
mysqlbinlog --read-from-remote-server -uroot -p123456 --start-position=155 mysql-bin.000020 -vv > /data/05.sql# 查看解析結果
cat /data/05.sql
其中 --read-from-remote-server 表示從服務端讀取 Binlog,而非本地文件。
步驟 3:關閉 Binlog 加密
# 1. 編輯配置文件,移除加密相關配置
vim /data/mysql/conf/my.cnf
# 刪除以下行:
# early-plugin-load = keyring_file.so
# keyring_file_data = /data/mysql/keyring
# binlog_encryption = on# 2. 備份舊加密 Binlog(避免重啟失敗)
# 把當前的Binlog移除,因為重啟MySSQL會加載之前的Binlog,而之前的Binlog是加密的,會重啟失敗
# 重建備份目錄backup,并且把Binlog移到該目錄下
mkdir /data/mysql/backup
mv /data/mysql/binlog/* /data/mysql/backup/# 3. 重啟 MySQL 服務
/etc/init.d/mysql.server restart# 4. 驗證加密關閉
show binary logs;
4 二進制日志(Binlog)的清除策略
Binlog 會持續占用磁盤空間,需定期清除無用日志,避免磁盤滿載。
4.1 三種清除方式
方式 1:自動清除(推薦)
通過配置 Binlog 保留時間,MySQL 會自動刪除過期日志:
- 查看當前保留時間配置:
# 查看保留天數(未來將廢棄) show global variables like "expire_logs_days";# 查看保留秒數(推薦使用,MySQL 8.0+ 默認) show global variables like "binlog_expire_logs_seconds"; - 動態調整保留時間(示例:保留 7 天):
# 先將 expire_logs_days 設為 0(避免與秒數參數沖突) set global expire_logs_days = 0;# 設置保留 7 天(7*24*60*60 = 604800 秒) set global binlog_expire_logs_seconds = 604800; - 觸發自動清除(可選,默認由 MySQL 定期執行):
flush logs; # 切換新 Binlog 文件,觸發舊日志檢查與刪除
方式 2:刪除指定文件之前的日志
通過文件名精準刪除,適用于需保留特定文件的場景:
- 查看當前 Binlog 文件列表:
show binary logs; - 刪除指定文件之前的所有日志(示例:保留
mysql-bin.000002及之后的文件):purge binary logs to 'mysql-bin.000002'; - 驗證刪除結果:
show binary logs;
方式 3:刪除指定時間之前的日志
通過時間刪除,適用于需清理某個時間點前日志的場景:
# 刪除 2030-02-02 00:00:00 之前的所有 Binlog
purge binary logs before '2030-02-02 00:00:00';# 驗證刪除結果(查看文件列表或磁盤占用)
ll /data/mysql/binlog/
4.2 清除注意事項
- 優先使用自動清除:手動清除易誤刪有用日志,自動清除更安全可控。
- 確認從庫已同步:主從架構中,需確保所有從庫已讀取并回放待清除的 Binlog,避免從庫同步中斷(可通過
show slave status\G查看從庫已讀取的 Binlog 位點)。 - 監控磁盤空間:建議配置磁盤監控,當使用率超過 80% 時觸發告警,及時排查 Binlog 占用問題(避免因 Binlog 暴漲導致服務不可用)。
5 二進制日志(Binlog)的落盤機制
Binlog 并非直接寫入磁盤,而是先寫入緩沖區,再通過配置的策略同步至磁盤,平衡性能與數據安全性。
5.1 落盤流程
- 創建 Binlog 緩沖區:MySQL 啟動時創建 Binlog 緩沖區(內存區域),用于臨時存儲數據變更記錄。
- 寫入緩沖區:執行 DML/DQL 操作時,MySQL 將變更記錄寫入 Binlog 緩沖區。
- 同步至磁盤:根據
sync_binlog參數配置的策略,將緩沖區數據刷入磁盤文件。
5.2 落盤頻率控制參數(sync_binlog)
sync_binlog 決定 Binlog 緩沖區同步至磁盤的頻率,直接影響數據安全性與性能:
# 查看當前配置
show global variables like "sync_binlog";
參數取值及含義:
- sync_binlog = 0:依賴操作系統刷盤(操作系統會定期將內存數據寫入磁盤)。
? 優點:性能最優(減少磁盤 IO);
? 缺點:系統崩潰時可能丟失緩沖區中未刷盤的事務。 - sync_binlog = 1:每次事務提交后立即刷盤。
? 優點:數據最安全(無丟失風險);
? 缺點:性能最差(每次事務都觸發磁盤 IO)。 - sync_binlog = N(N>1):每提交 N 次事務后刷盤。
? 優點:平衡性能與安全性;
? 缺點:系統崩潰時可能丟失最近 N 個事務。
5.3 實驗:驗證 sync_binlog 對性能的影響
實驗目的
對比不同 sync_binlog 值下,批量插入數據的耗時,驗證落盤頻率對性能的影響。
實驗步驟
-
創建測試表與批量插入存儲過程:
# 創建測試表 CREATE TABLE test_table (id INT PRIMARY KEY,data VARCHAR(255) );# 創建存儲過程:插入 10 萬行數據 DELIMITER // CREATE PROCEDURE insert_data() BEGINDECLARE i INT DEFAULT 1;WHILE (i <= 100000) DOINSERT INTO test_table (id, data) VALUES (i, CONCAT('Test data ', i));SET i = i + 1;END WHILE; END// DELIMITER ; -
分別設置
sync_binlog為 0、1、100,執行存儲過程并記錄耗時:- 場景 1:sync_binlog = 0
set global sync_binlog = 0; CALL insert_data(); # 記錄耗時(示例:約 10 秒) truncate table test_table; # 清空表,準備下一場景 - 場景 2:sync_binlog = 1
set global sync_binlog = 1; CALL insert_data(); # 記錄耗時(示例:約 30 秒) truncate table test_table; - 場景 3:sync_binlog = 100
set global sync_binlog = 100; CALL insert_data(); # 記錄耗時(示例:約 15 秒) truncate table test_table;
- 場景 1:sync_binlog = 0
實驗結論
sync_binlog = 0性能最優,但安全性最低;sync_binlog = 1安全性最高,但性能最差;sync_binlog = N需根據業務對「性能」與「安全性」的權衡選擇(如金融場景建議設為 1,非核心場景可設為 100~1000)。
6 查詢日志(General Log):配置與作用
General Log 記錄 MySQL 所有操作(包括查詢、連接、斷開等),主要用于診斷問題與審計,但性能開銷較大,生產環境需謹慎啟用。
6.1 General Log 配置
方式 1:動態開啟(臨時生效)
# 查看當前狀態
show global variables like "general%";# 開啟 General Log
set global general_log = on;# (可選)修改日志存儲路徑(默認路徑可通過 general_log_file 查看)
set global general_log_file = '/data/mysql/log/mysql-general.log';
方式 2:永久開啟(需重啟)
# 1. 編輯配置文件
vim /data/mysql/conf/my.cnf# 2. 添加配置
general_log = on # 開啟日志
general_log_file = /data/mysql/log/mysql-general.log # 日志路徑# 3. 重啟 MySQL 服務
/etc/init.d/mysql.server restart
配置日志輸出方式
General Log 支持輸出到「文件」或「表」,可通過 log_output 配置:
# 查看當前輸出方式
show global variables like "log_output";# 設置輸出方式(FILE:文件;TABLE:表;FILE,TABLE:同時輸出)
set global log_output = 'FILE,TABLE';
- 輸出到表時,日志存儲在
mysql.general_log表中,可通過 SQL 查詢:select * from mysql.general_log limit 10;
6.2 查看 General Log
# 查看文件日志(示例:查看最后 10 行)
tail -n 10 /data/mysql/log/mysql-general.log# 實時查看日志(跟蹤最新操作)
tail -f /data/mysql/log/mysql-general.log
6.3 General Log 的作用與缺點
核心作用
- 問題診斷:記錄所有操作,可定位慢查詢、連接失敗、SQL 語法錯誤等問題(如排查「某條 SQL 為何未執行」)。
- 性能調優:分析操作執行頻率與耗時,識別高頻低效率操作(如頻繁執行無索引的查詢)。
- 安全審計:追蹤用戶操作記錄,排查惡意操作(如誰刪除了關鍵表、誰執行了高危 SQL)。
主要缺點
- 性能開銷大:高并發場景下,General Log 會產生大量 IO 操作,導致 MySQL 性能下降(甚至翻倍增加 CPU/IO 使用率)。
- 日志體積大:日志會快速膨脹(如每秒 thousands 條記錄),短時間內占滿磁盤空間。
- 敏感信息泄露風險:日志中包含用戶名、密碼、業務數據等敏感信息,若未做好權限控制(如僅允許 root 訪問),可能導致數據泄露。
注意:生產環境建議關閉 General Log,僅在排查特定問題時臨時開啟,問題解決后立即關閉。
7 慢查詢日志(Slow Log):定位低效 SQL
Slow Log 記錄執行時間超過閾值的 SQL 語句,是優化查詢性能的核心工具,生產環境建議長期開啟。
7.1 開啟 Slow Log
方式 1:動態開啟(臨時生效)
# 查看當前配置
show global variables like "slow_query_log%";
show global variables like "long_query_time";# 開啟慢查詢日志
set global slow_query_log = 1;# 設置日志存儲路徑
set global slow_query_log_file = '/data/mysql/log/mysql-slow.log';# 設置慢查詢閾值(單位:秒,示例:超過 1 秒的 SQL 記錄)
set global long_query_time = 1;
- 注意:
long_query_time生效后,僅新連接的 SQL 會采用新閾值,現有連接需重新連接才生效。
方式 2:永久開啟(需重啟)
# 1. 編輯配置文件
vim /data/mysql/conf/my.cnf# 2. 添加配置
slow_query_log = 1 # 開啟慢查詢日志
slow_query_log_file = /data/mysql/log/mysql-slow.log # 日志路徑
long_query_time = 1 # 慢查詢閾值(秒)# 3. 重啟 MySQL 服務
/etc/init.d/mysql.server restart
7.2 Slow Log 進階配置
除基礎閾值外,還可配置以下參數增強慢查詢記錄能力:
-
記錄管理語句(如 ALTER、DROP):
# 動態開啟(永久開啟需添加到配置文件) set global log_slow_admin_statements = on;作用:管理語句執行時間可能較長(如
ALTER TABLE加索引),記錄后便于排查運維操作導致的性能問題。 -
記錄未使用索引的查詢:
set global log_queries_not_using_indexes = on;作用:即使查詢執行時間未超過閾值,若未使用索引(可能導致全表掃描),也會記錄到 Slow Log,提前發現低效 SQL。
-
設置檢查行數閾值:
# 查看當前配置 show global variables like "min_examined_row_limit";# 設置為 0(記錄所有符合條件的慢查詢,不限制檢查行數) set global min_examined_row_limit = 0;作用:避免因「檢查行數少」而忽略慢查詢(如全表掃描 100 行但耗時 2 秒的 SQL)。
7.3 查看與解析 Slow Log
步驟 1:生成測試慢查詢
# 執行 sleep(2),模擬耗時 2 秒的慢查詢
select sleep(2);
步驟 2:查看慢查詢日志
# 查看日志內容
tail /data/mysql/log/mysql-slow.log
日志示例(關鍵信息說明):
# Time: 2024-05-20T10:00:00.000000Z # 執行時間
# User@Host: root[root] @ localhost [] # 執行用戶與主機
# Query_time: 2.000000 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1 # 耗時、鎖時間、返回行數、檢查行數
SET timestamp=1716223200; # 時間戳
select sleep(2); # 具體 SQL
步驟 3:使用官方工具分析 Slow Log
MySQL 自帶 mysqldumpslow 工具,可統計慢查詢的頻率、耗時等,快速定位TOP低效SQL:
-
基礎分析(按默認規則排序):
# 進入日志目錄 cd /data/mysql/log# 分析慢查詢日志 mysqldumpslow mysql-slow.log -
按耗時排序(顯示TOP5):
# -s t:按耗時(time)排序;-t 5:顯示前 5 條 mysqldumpslow -s t -t 5 mysql-slow.log -
按執行次數排序(顯示TOP5):
# -s c:按執行次數(count)排序 mysqldumpslow -s c -t 5 mysql-slow.log -
過濾特定數據庫的慢查詢:
# -d martin:僅分析 martin 庫的慢查詢 mysqldumpslow -d martin mysql-slow.log
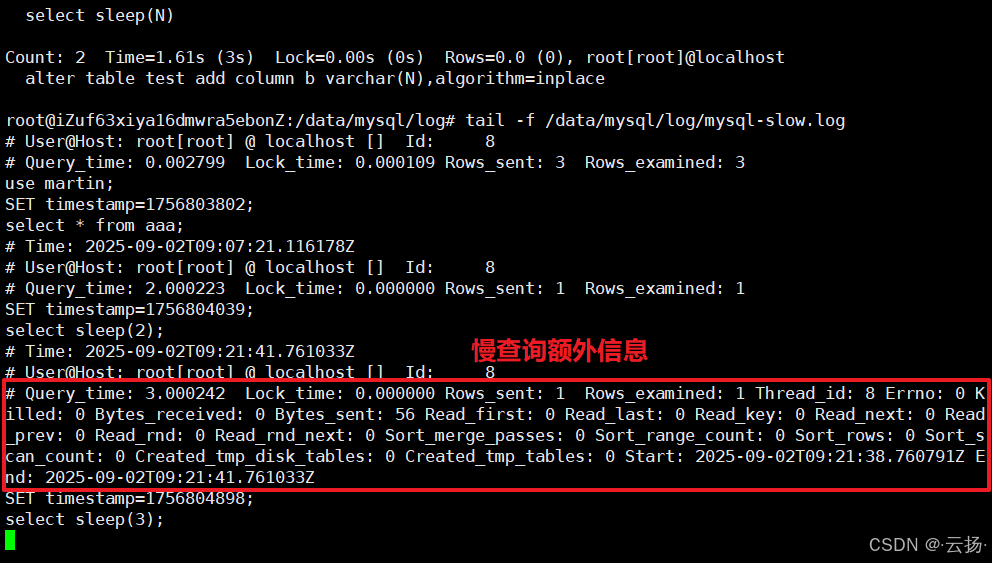
7.4 慢查詢額外信息輸出(MySQL 8.0.14+)
MySQL 8.0.14 新增 log_slow_extra 參數,開啟后可記錄更多慢查詢細節(如全表掃描標記、臨時表使用情況):
# 開啟額外信息輸出
set global log_slow_extra = on;# 生成慢查詢
select sleep(2);# 查看日志(新增信息如 "Rows_affected: 0"、"Full_scan: Yes")
tail /data/mysql/log/mysql-slow.log
8 錯誤日志(Error Log):排查服務異常
Error Log 記錄 MySQL 啟動、關閉、運行過程中的錯誤、警告與調試信息,是解決服務啟動失敗、崩潰、連接異常等問題的核心依據,默認開啟。
8.1 Error Log 配置與查看
查看日志路徑
# 查看錯誤日志存儲路徑
show global variables like "log_error";
默認路徑通常為 data/mysql/hostname.err(如 /data/mysql/localhost.err),也可手動配置路徑:
# 永久配置路徑(需編輯配置文件并重啟)
vim /data/mysql/conf/my.cnf
# 添加:log-error = /data/mysql/log/mysql.err
/etc/init.d/mysql.server restart
配置日志記錄級別
通過 log_error_verbosity 控制日志記錄的詳細程度:
# 查看當前級別
show global variables like "log_error_verbosity";
參數取值及含義:
- 1:僅記錄錯誤信息(Error);
- 2:記錄錯誤與警告信息(Error + Warning);
- 3:記錄所有信息(Error + Warning + Note + 調試信息)。
查看 Error Log
# 查看最后 50 行日志(定位最新錯誤)
tail -n 50 /data/mysql/log/mysql.err# 實時跟蹤日志(監控服務運行狀態)
tail -f /data/mysql/log/mysql.err
8.2 Error Log 的核心作用
作用 1:定位服務啟動異常
若 MySQL 啟動失敗(如執行 service mysql start 后提示失敗),可通過 Error Log 查看具體原因:
-
模擬啟動異常(高危操作:僅限測試環境!):
# 故意修改 redo log 文件屬主,導致啟動失敗 chown root.root /data/mysql/data/ib_logfile0# 嘗試啟動 MySQL /etc/init.d/mysql.server restart # 啟動失敗 -
查看 Error Log 定位原因:
tail -n 50 /data/mysql/log/mysql.err日志會顯示類似錯誤:
[ERROR] [MY-012884] [InnoDB] /data/mysql/data/ib_logfile0 can't be opened in read-write mode.(權限不足)。

-
修復問題并重啟:
# 恢復文件屬主 chown mysql.mysql /data/mysql/data/ib_logfile0# 重新啟動 /etc/init.d/mysql.server start # 啟動成功
作用 2:診斷連接異常
當用戶無法連接 MySQL 時,Error Log 會記錄連接失敗原因(如密碼錯誤、賬戶鎖定):
- 創建測試用戶并設置鎖定規則:
# 創建用戶:試錯 4 次后鎖定 3 天 create user 'test_pass'@'localhost' identified by '123456' failed_login_attempts 4 password_lock_time 3;# 授予查詢權限 grant select on *.* to 'test_pass'@'localhost';# 開啟詳細日志(記錄連接失敗信息) set global log_error_verbosity = 3; - 故意用錯誤密碼連接:
mysql -utest_pass -p'wrong_pass' # 連接失敗 - 查看 Error Log 中的失敗信息:
日志會顯示:tail -f /data/mysql/log/mysql.err[Note] [MY-010926] [Server] Access denied for user 'test_pass'@'localhost' (using password: YES)。
作用 3:記錄死鎖信息
InnoDB 死鎖時,Error Log 會詳細記錄死鎖事務的 SQL、鎖類型、等待關系,便于排查死鎖原因:
-
模擬死鎖(需兩個會話):
-
創建測試表并寫入測試數據
use martin; create table errlog_t1(id int primary key, a varchar(10)) engine=InnoDB; insert into errlog_t1 values (1,'a'),(2,'b'); -
進行死鎖實驗
session1 session2 begin; begin; delete from errlog_t1 where id=1; delete from errlog_t1 where id=2; delete from errlog_t1 where id=2; delete from errlog_t1 where id=1; commit; commit;
-
-
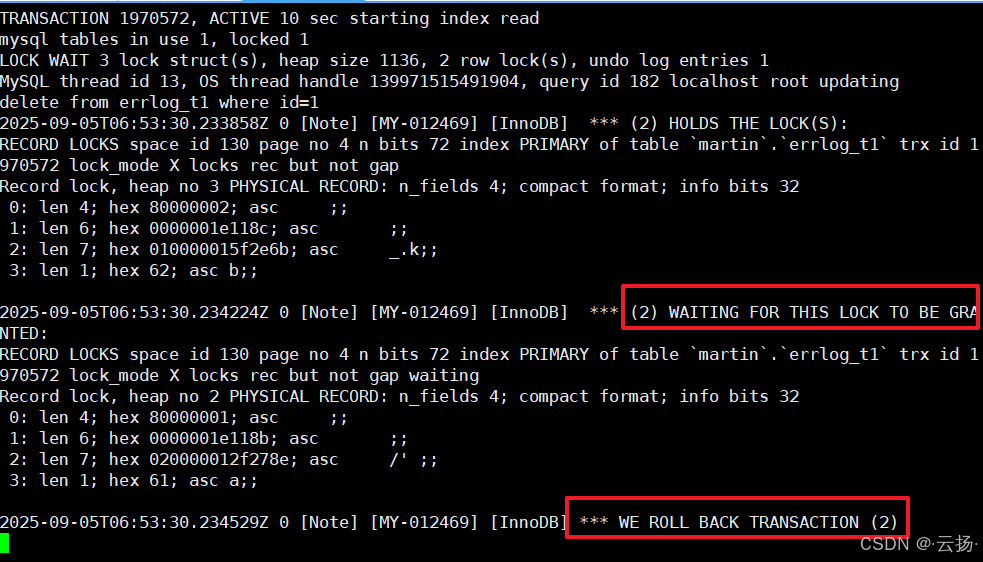
查看 Error Log 中的死鎖信息:
tail -n 100 /data/mysql/log/mysql.err日志會顯示死鎖事務的
TRANSACTION信息、鎖等待關系(如WAITING FOR THIS LOCK TO BE GRANTED)。
8.3 MySQL 8.0+ 錯誤日志過濾(進階)
MySQL 8.0 支持通過過濾器組件控制 Error Log 輸出,避免日志中充斥無用信息(如頻繁的連接失敗日志)。
步驟 1:開啟日志過濾
# 1. 加載過濾器組件(dragnet:MySQL 官方過濾組件)
INSTALL COMPONENT 'file://component_log_filter_dragnet';# 2. 配置日志服務:先過濾再輸出
SET GLOBAL log_error_services = 'log_filter_dragnet; log_sink_internal';
步驟 2:配置過濾規則(示例)
需求:限制「信息類日志(Note)」每分鐘最多記錄 1 條,避免刷屏:
# 設置過濾規則:信息類日志每分鐘不超過 1 條
SET GLOBAL dragnet.log_error_filter_rules = 'IF prio>=INFORMATION THEN throttle 1/60.';
prio>=INFORMATION:匹配信息類及以上級別的日志(Note、Warning、Error);throttle 1/60:每分鐘最多記錄 1 條。
步驟 3:驗證過濾效果
- 短時間內多次觸發信息類日志(如多次用錯誤密碼連接):
mysql -utest_pass -p'wrong_pass' # 第 1 次:記錄日志 mysql -utest_pass -p'wrong_pass' # 第 2 次(1 分鐘內):不記錄 - 查看 Error Log:僅記錄第 1 次連接失敗信息,第 2 次不記錄。
步驟 4:關閉日志過濾
# 1. 恢復日志服務:直接輸出,不經過濾
SET GLOBAL log_error_services = 'log_sink_internal';# 2. 卸載過濾器組件
UNINSTALL COMPONENT 'file://component_log_filter_dragnet';# 3. 恢復日志級別(避免過多調試信息)
set global log_error_verbosity = 2;
8.4 從表中查詢錯誤日志(MySQL 8.0.22+)
MySQL 8.0.22 開始支持將 Error Log 存儲到 performance_schema.error_log 表中,便于通過 SQL 查詢(無需操作文件)。
查看表中日志
# 查看最新 10 條錯誤日志
select * from performance_schema.error_log order by LOGGED desc limit 10;# 查看級別為 ERROR 的日志
select * from performance_schema.error_log where PRIO = 'ERROR'\G;# 查看指定時間范圍的日志
select * from performance_schema.error_log
where LOGGED between '2024-05-20 10:00:00' and '2024-05-20 11:00:00';
注意事項
performance_schema.error_log是系統表,僅支持查詢,不支持INSERT/UPDATE/DELETE;- 表中日志與文件日志內容一致,可根據需求選擇查詢方式(文件適合實時跟蹤,表適合復雜條件過濾);
- 無法通過
TRUNCATE清空表,需通過配置log_error_services重置日志。
9 重做日志(Redo Log):保障事務持久性
Redo Log 是 InnoDB 存儲引擎特有的物理日志,記錄數據頁的修改(如「將數據頁 X 的偏移量 Y 的值從 A 改為 B」),核心作用是保障事務的持久性(ACID 中的 D)——即使 MySQL 崩潰,重啟后可通過 Redo Log 恢復未刷盤的事務。
9.1 Redo Log 的核心概念
為什么需要 Redo Log?
InnoDB 采用「緩沖池(Buffer Pool)」機制:數據讀寫先操作緩沖池中的數據頁,再定期將臟頁(修改過但未刷盤的數據頁)刷入磁盤。若 MySQL 崩潰時臟頁未刷盤,會導致數據丟失。Redo Log 記錄了數據頁的修改,崩潰后可通過 Redo Log 重放修改,恢復臟頁數據,避免丟失。
Redo Log 記錄的內容
Redo Log 是物理日志,記錄「數據頁的變更」,而非 SQL 語句或行數據。例如:
- 執行
update user set name='test' where id=1后,Redo Log 會記錄:
數據頁號:100,偏移量:200,修改前值:'old',修改后值:'test'
9.2 兩階段提交與雙寫(Redo Log 關鍵機制)
兩階段提交(保障 Binlog 與 Redo Log 一致性)
MySQL 崩潰時,需確保「Binlog 與 Redo Log 記錄的事務一致」(避免主從數據不一致),因此采用兩階段提交:
- 準備階段(Prepare):
- 事務執行完成后,將修改記錄寫入 Redo Log,并標記為「Prepare 狀態」;
- 此時 Redo Log 已刷盤,但 Binlog 未寫入。
- 提交階段(Commit):
- 將事務記錄寫入 Binlog 并刷盤;
- 若 Binlog 刷盤成功,將 Redo Log 標記為「Commit 狀態」;
- 若 Binlog 刷盤失敗,事務回滾,Redo Log 的 Prepare 狀態記錄會被忽略。
雙寫(避免數據頁損壞)
Redo Log 重放時需基于完整的數據頁,若數據頁刷盤過程中崩潰(如斷電),會導致數據頁損壞(部分寫入),Redo Log 無法重放。InnoDB 通過「雙寫緩沖區(Doublewrite Buffer)」解決該問題:
- 臟頁刷盤前,先將完整的數據頁寫入「雙寫緩沖區」(內存區域);
- 將雙寫緩沖區的數據刷入磁盤的「雙寫文件」(物理文件,位于共享表空間);
- 確認雙寫文件寫入成功后,再將臟頁刷入實際數據文件;
- 若刷盤過程中崩潰,重啟后可從雙寫文件讀取完整數據頁,修復損壞的實際數據頁,再重放 Redo Log。
9.3 Redo Log 的配置
配置 Redo Log 容量
Redo Log 容量直接影響性能:容量過小會導致頻繁切換日志文件(觸發 checkpoint,刷盤頻繁);容量過大則崩潰恢復時間變長,建議配置為 4G~8G。
-
MySQL 8.0.30 之前版本:
通過innodb_log_file_size(單個文件大小)與innodb_log_files_in_group(文件數量)控制總容量:# 查看當前配置 show global variables like "innodb_log_file%";# 配置示例(總容量 = 2 * 2G = 4G) vim /data/mysql/conf/my.cnf [mysqld] innodb_log_file_size = 2G # 單個文件大小 innodb_log_files_in_group = 2 # 文件數量(默認 2,建議保持)# 重啟 MySQL 服務(需先備份舊日志文件,避免啟動失敗) mv /data/mysql/data/ib_logfile* /data/mysql/backup/ /etc/init.d/mysql.server restart -
MySQL 8.0.30 及之后版本:
新增innodb_redo_log_capacity參數,直接控制總容量(簡化配置):# 查看當前總容量 show global variables like "innodb_redo_log_capacity";# 配置總容量為 4G(無需關心文件數量,MySQL 自動管理) vim /data/mysql/conf/my.cnf [mysqld] innodb_redo_log_capacity = 4G# 重啟 MySQL 服務 /etc/init.d/mysql.server restart
配置 Redo Log 存儲路徑
默認情況下,Redo Log 文件(ib_logfile0、ib_logfile1)存儲在數據目錄(如 /data/mysql/data/),可通過以下參數修改路徑:
# 查看當前路徑
show global variables like "innodb_log_group_home_dir";# 配置新路徑(建議放在獨立磁盤,減少 IO 競爭)
vim /data/mysql/conf/my.cnf
[mysqld]
innodb_log_group_home_dir = /data/mysql/redo_log/ # 新路徑# 創建目錄并授權
mkdir -p /data/mysql/redo_log/
chown -R mysql.mysql /data/mysql/redo_log/# 備份舊日志并重啟
mv /data/mysql/data/ib_logfile* /data/mysql/redo_log/
/etc/init.d/mysql.server restart
9.4 Redo Log 在崩潰恢復中的作用
當 MySQL 崩潰后重啟,InnoDB 會自動執行崩潰恢復,核心流程依賴 Redo Log:
- 分析階段:掃描 Redo Log,識別所有處于「Prepare 狀態」和「Commit 狀態」的事務。
- 重做階段:重放所有「Prepare 狀態且 Binlog 已寫入」和「Commit 狀態」的事務(通過 Redo Log 恢復數據頁修改)。
- 回滾階段:回滾所有「Prepare 狀態但 Binlog 未寫入」的事務(通過 Undo Log 撤銷修改)。
通過以上流程,確保崩潰后數據既不丟失(已提交事務通過 Redo Log 恢復),也不出現臟數據(未提交事務通過 Undo Log 回滾)。
9.5 Redo Log 最佳實踐
- 配置合適的容量:總容量建議為 4G~8G,單個文件不超過 4G(避免恢復時間過長)。
- 獨立磁盤存儲:將 Redo Log 放在獨立的 SSD 磁盤(IO 性能高),避免與數據文件、Binlog 共享磁盤,減少 IO 競爭。
- 監控 Redo Log 使用情況:
若使用率長期超過 80%,需增大 Redo Log 容量。# 查看 Redo Log 使用率(Used %) select variable_value as redo_log_used_pct from information_schema.global_status where variable_name = 'Innodb_redo_log_used_percent'; - 避免頻繁切換日志:若
Innodb_redo_log_switches(日志切換次數)過高(如每分鐘多次),說明容量不足,需擴容。
10 重做日志(Redo Log)的落盤機制
Redo Log 同樣采用「緩沖區 + 磁盤」的存儲方式,落盤頻率通過 innodb_flush_log_at_trx_commit 控制,直接影響事務持久性與性能。
10.1 innodb_flush_log_at_trx_commit 配置說明
# 查看當前配置
show global variables like "innodb_flush_log_at_trx_commit";
參數取值及落盤規則:
- 0:事務提交時不刷盤,依賴操作系統每秒自動刷盤(將 Redo Log 緩沖區數據寫入磁盤文件)。
- 1:事務提交時,立即將 Redo Log 緩沖區數據寫入磁盤文件,并調用
fsync()確保數據刷入物理磁盤(不依賴操作系統緩存)。 - 2:事務提交時,將 Redo Log 緩沖區數據寫入磁盤文件(但僅寫入操作系統緩存),操作系統每秒自動刷入物理磁盤。
10.2 不同配置對性能的影響(實驗驗證)
實驗目的
對比 innodb_flush_log_at_trx_commit 取 0、1、2 時,批量插入數據的耗時,驗證落盤頻率對性能的影響。
實驗步驟
-
創建測試表與批量插入存儲過程:
# 選擇數據庫 use martin;# 創建測試表 create table redo_t1(id int not null auto_increment,a varchar(20) default null,b int default null,c datetime not null default current_timestamp,primary key(id) )engine=innodb charset=utf8mb4;# 創建存儲過程:插入 10 萬行數據 delimiter ;; create procedure insert_t1() begindeclare i int;set i=1;while(i<=100000)doinsert into redo_t1(a,b) values (i,i);set i=i+1;end while; end;; delimiter ; -
分別設置參數并執行存儲過程,記錄耗時:
- 場景 1:innodb_flush_log_at_trx_commit = 0
set global innodb_flush_log_at_trx_commit = 0; call insert_t1(); # 記錄耗時(示例:約 8 秒) truncate table redo_t1; # 清空表 - 場景 2:innodb_flush_log_at_trx_commit = 1
set global innodb_flush_log_at_trx_commit = 1; call insert_t1(); # 記錄耗時(示例:約 25 秒) truncate table redo_t1; - 場景 3:innodb_flush_log_at_trx_commit = 2
set global innodb_flush_log_at_trx_commit = 2; call insert_t1(); # 記錄耗時(示例:約 10 秒) truncate table redo_t1;
- 場景 1:innodb_flush_log_at_trx_commit = 0
實驗結論
| 參數值 | 性能(耗時) | 數據安全性(崩潰時丟失風險) | 適用場景 |
|---|---|---|---|
| 0 | 最優 | 高(丟失 0~1 秒內的事務) | 非核心業務(如日志存儲) |
| 1 | 最差 | 無丟失(完全符合 ACID) | 核心業務(如金融、支付) |
| 2 | 中等 | 低(僅丟失操作系統緩存數據) | 非核心但需低丟失場景 |
注意:若 MySQL 部署在虛擬機或云服務器,
innodb_flush_log_at_trx_commit = 2可能因虛擬機崩潰導致操作系統緩存數據丟失,此時建議設為 1。
10.3 innodb_flush_log_at_trx_commit 配置不同值的對比
| 設置的值 | 特點 | 優點 | 缺點 |
|---|---|---|---|
| 0 | 每秒將日志緩沖區寫入日志文件一次,并在日志文件上執行磁盤刷新操作 | 寫入性能最好 | MySQL崩潰,可能會丟失最后一秒的事務 |
| 1 | 在每次提交事務時,日志緩沖區都會寫入日志文件中,并在日志文件上執行磁盤刷新操作 | 最安全的 | 性能最差 |
| 2 | 在每次提交事務后寫入日志,并且日志每秒刷新一次到磁盤 | 比設置為0更安全,比設置為1性能更好 | 操作系統崩潰或者斷電,可能會丟失最后一秒的事務 |
11 MySQL 8.0 重做日志(Redo Log)的歸檔與禁用
MySQL 8.0 新增 Redo Log 歸檔與禁用功能,分別適用于備份場景與數據導入場景。
11.1 Redo Log 歸檔(MySQL 8.0.17+)
歸檔的作用
Redo Log 采用「循環寫」機制(文件寫滿后覆蓋舊內容),備份數據時若需同步增量 Redo Log,可能因覆蓋導致日志丟失。歸檔功能可將 Redo Log 按順序寫入歸檔文件(追加寫,不覆蓋),確保備份時能獲取完整的增量日志。
開啟 Redo Log 歸檔
-
創建歸檔目錄并授權:
# 創建歸檔目錄(示例:按日期命名) mkdir -p /data/mysql/redolog-archiving/redo-20240520# 授權(確保 MySQL 有權讀寫) chown -R mysql.mysql /data/mysql/redolog-archiving/ chmod 700 /data/mysql/redolog-archiving/redo-20240520 -
配置歸檔路徑并激活:
# 設置歸檔目錄映射(格式:別名:實際路徑) set global innodb_redo_log_archive_dirs = "arch_dir:/data/mysql/redolog-archiving/";# 激活歸檔(參數:目錄別名、歸檔子目錄) do innodb_redo_log_archive_start("arch_dir", "redo-20240520");# 驗證歸檔是否開啟(查看歸檔文件) ll -h /data/mysql/redolog-archiving/redo-20240520/歸檔目錄下會生成
archive_xxx文件,持續寫入 Redo Log 內容。

停止 Redo Log 歸檔
# 停止歸檔
do innodb_redo_log_archive_stop();# (可選)刪除歸檔目錄(備份完成后)
rm -rf /data/mysql/redolog-archiving/redo-20240520/
11.2 Redo Log 禁用(MySQL 8.0.21+)
禁用的作用
Redo Log 會帶來一定的 IO 開銷,當執行大量數據導入(如初始化新實例、批量導入歷史數據)時,可臨時禁用 Redo Log,提升導入速度(通常可提升 2~5 倍)。
禁用 Redo Log
# 1. 禁用 Redo Log(僅支持全局禁用,需 root 權限)
alter instance disable innodb redo_log;# 2. 驗證禁用狀態(Value 為 OFF 表示已禁用)
show global status like "innodb_redo_log_enabled";
性能對比實驗
-
禁用 Redo Log 后導入數據:
# 清空測試表 truncate table martin.redo_t1;# 執行批量插入(禁用 Redo Log) call martin.insert_t1(); # 記錄耗時(示例:約 3 秒) -
啟用 Redo Log 后導入數據:
# 啟用 Redo Log alter instance enable innodb redo_log;# 清空測試表 truncate table martin.redo_t1;# 執行批量插入(啟用 Redo Log) call martin.insert_t1(); # 記錄耗時(示例:約 25 秒)
實驗結論
禁用 Redo Log 后,數據導入速度大幅提升(示例中從 25 秒縮短至 3 秒),但需注意:
- 禁用期間不保證持久性:若 MySQL 崩潰,未刷盤的數據會丟失,因此僅建議在「數據可重新導入」的場景(如初始化實例、導入歷史備份)中禁用。
- 禁用后需及時啟用:數據導入完成后,立即啟用 Redo Log,確保后續業務符合 ACID 特性。
12 回滾日志(Undo Log):事務回滾與 MVCC 基礎
Undo Log 是 InnoDB 特有的邏輯日志,記錄事務修改前的數據狀態,核心作用是支持事務回滾與多版本并發控制(MVCC)。
12.1 Undo Log 的三大核心作用
- 事務回滾:當事務執行
ROLLBACK或崩潰時,InnoDB 通過 Undo Log 恢復數據到事務開始前的狀態(如執行update后,Undo Log 記錄修改前的舊值,回滾時用舊值覆蓋新值)。 - 支持 MVCC:多事務并發讀寫時,讀事務通過 Undo Log 讀取數據的歷史版本(而非當前修改后的版本),實現「非鎖定讀」(如
SELECT無需加鎖,不阻塞寫事務)。 - 崩潰恢復:MySQL 崩潰后重啟,未提交的事務需回滾,InnoDB 通過 Undo Log 撤銷這些事務的修改,確保數據一致性。
12.2 不同操作的 Undo Log 內容
Undo Log 按操作類型分為三類,記錄內容不同:
- INSERT 操作:記錄「刪除該插入行」的邏輯(因插入的行僅當前事務可見,回滾時直接刪除即可)。
- DELETE 操作:記錄「重新插入該刪除行」的邏輯(回滾時需恢復被刪除的行,因此記錄行的完整舊值)。
- UPDATE 操作:記錄「將修改后的列恢復為舊值」的邏輯(如
update user set name='test' where id=1,Undo Log 記錄name的舊值,回滾時將name改回舊值)。
注意:
SELECT操作不產生 Undo Log(無需回滾,也不修改數據)。
12.3 Undo Log 在 MVCC 中的作用
MVCC 是 InnoDB 實現并發控制的核心機制,其核心是「讀事務看到數據的歷史版本」,而歷史版本正是通過 Undo Log 構建的:
- 事務執行
UPDATE時,InnoDB 會:- 為該行生成一個新的版本(記錄新值);
- 生成 Undo Log,記錄該行的舊版本(供其他讀事務訪問);
- 將新版本的
roll_pointer指向 Undo Log 中的舊版本(形成版本鏈)。
- 讀事務執行
SELECT時,InnoDB 會:- 根據事務隔離級別(如
REPEATABLE READ),通過版本鏈找到符合條件的歷史版本; - 若當前版本被其他事務修改,通過
roll_pointer追溯 Undo Log 中的舊版本,直到找到可見版本。
- 根據事務隔離級別(如
例如:
- 事務 A 執行
update user set name='new' where id=1(修改前 name 為 ‘old’); - 事務 B 執行
select name from user where id=1(隔離級別為REPEATABLE READ); - 事務 B 會通過 Undo Log 讀取到 name 的舊值 ‘old’,而非事務 A 修改后的 ‘new’,實現非鎖定讀。
12.4 Undo Log 在崩潰恢復中的作用
MySQL 崩潰后重啟,InnoDB 會執行崩潰恢復,Undo Log 用于回滾未提交的事務:
- 分析 Redo Log,識別所有未提交的事務(處于 Prepare 狀態但未 Commit 的事務);
- 對每個未提交的事務,通過 Undo Log 執行反向操作(如
UPDATE回滾為舊值,DELETE回滾為插入,INSERT回滾為刪除); - 回滾完成后,刪除這些事務的 Undo Log,釋放空間。
12.5 Undo Log 最佳實踐
- 獨立存儲 Undo Log:將 Undo Log 放在 SSD 磁盤(IO 性能高),避免與數據文件、Redo Log 共享磁盤,減少 IO 競爭(配置參數:
innodb_undo_directory)。 - 控制 Undo Log 大小:通過
innodb_max_undo_log_size限制單個 Undo 表空間大小(默認 1G),避免 Undo Log 過度膨脹(配置參數:innodb_undo_log_truncate開啟自動截斷)。 - 避免長事務:長事務會持續占用 Undo Log(需保留歷史版本供 MVCC 訪問),導致 Undo Log 體積增大、回滾時間變長,甚至引發磁盤空間不足。建議將事務拆分為短事務,避免執行耗時超過 10 秒的事務。
13 回滾日志(Undo Log)的清理(Purge)
Undo Log 不會在事務提交后立即刪除(可能有其他讀事務通過 MVCC 訪問其歷史版本),InnoDB 會定期清理無用的 Undo Log,該過程稱為 Purge。
13.1 Purge 的核心邏輯
什么是 Purge?
Purge 是 InnoDB 后臺線程(Purge Thread)執行的清理操作,用于刪除「不再被任何事務訪問的 Undo Log」,釋放磁盤空間。
什么時候觸發 Purge?
Undo Log 需滿足以下條件才會被 Purge:
- 生成該 Undo Log 的事務已提交;
- 所有讀事務都已不需要訪問該 Undo Log 對應的歷史版本(即所有讀事務的「最早可見版本」都晚于該 Undo Log 對應的版本)。
Purge 的觸發時機
- 定時觸發:InnoDB 定期(默認每 1 秒)檢查是否有可 Purge 的 Undo Log;
- 事務提交觸發:當事務提交時,若 Undo Log 數量達到閾值,觸發 Purge;
- Checkpoint 觸發:Redo Log 執行 Checkpoint 時,若 Undo Log 占用空間過大,觸發 Purge。
13.2 如何判斷 Undo Log 可被 Purge?
InnoDB 通過「Read View」判斷 Undo Log 是否可被 Purge:
- Read View:每個讀事務啟動時生成的「可見事務 ID 范圍」,記錄當前活躍事務的最小 ID(
min_trx_id)與最大 ID(max_trx_id)。 - 判斷邏輯:
- 若 Undo Log 對應的事務 ID(
trx_id)小于min_trx_id:表示該事務在所有活躍事務之前提交,其歷史版本不再被任何讀事務訪問,可 Purge; - 若 Undo Log 對應的事務 ID 大于等于
max_trx_id:表示該事務在當前讀事務之后啟動,其歷史版本可能被其他讀事務訪問,不可 Purge; - 若事務 ID 在
min_trx_id與max_trx_id之間:需進一步檢查該事務是否仍活躍,若已提交且無其他讀事務訪問,可 Purge。
- 若 Undo Log 對應的事務 ID(
13.3 Purge 優化策略
1. 調整 Purge 線程數
Purge 線程數默認為 4(MySQL 8.0+),若 Undo Log 堆積嚴重(如長事務多、并發高),可增加線程數提升清理速度:
# 查看當前 Purge 線程數
show global variables like "innodb_purge_threads";# 調整為 8 個線程(永久調整需添加到配置文件)
set global innodb_purge_threads = 8;
2. 配置回滾段清理頻率
innodb_purge_rseg_truncate_frequency 控制每執行多少次 Purge 操作后,檢查并刪除無用的回滾段(回滾段是 Undo Log 的存儲單元):
# 查看當前配置
show global variables like "innodb_purge_rseg_truncate_frequency";# 調整為每 10 次 Purge 檢查一次回滾段(默認 128)
set global innodb_purge_rseg_truncate_frequency = 10;
- 數值越小:回滾段清理越頻繁,Undo 表空間截斷越及時,但可能增加 CPU 開銷;
- 數值越大:回滾段清理頻率低,可能導致 Undo 表空間膨脹,但 CPU 開銷小。
3. 監控長事務
長事務會導致 Read View 的 min_trx_id 長期不變,使大量 Undo Log 無法被 Purge(需等待長事務結束),因此需監控并優化長事務:
# 查看執行時間過長的事務
show processlist;# 查看執行時間超過 60 秒的事務
select trx_id, trx_started, timestampdiff(second, trx_started, now()) as trx_duration_seconds,trx_query
from information_schema.innodb_trx
where timestampdiff(second, trx_started, now()) > 60;
對執行時間過長的事務,分析其 SQL 邏輯,拆分為短事務或優化執行效率(如添加索引、減少數據掃描量)。
4. 開啟 Undo Log 自動截斷
當 Undo 表空間大小超過 innodb_max_undo_log_size 時,自動截斷表空間,釋放空間:
# 查看自動截斷配置
show global variables like "innodb_undo_log_truncate";
show global variables like "innodb_max_undo_log_size";# 開啟自動截斷(永久開啟需添加到配置文件)
set global innodb_undo_log_truncate = on;# 設置 Undo 表空間最大大小為 2G(默認 1G)
set global innodb_max_undo_log_size = 2147483648; # 2G = 2*1024*1024*1024
14 回滾日志(Undo Log)的相關配置
InnoDB 提供多個參數用于配置 Undo Log 的存儲、大小、清理等,需根據業務場景調整。
14.1 核心配置參數說明
| 參數名稱 | 作用 | 默認值 | 建議配置 |
|---|---|---|---|
innodb_undo_directory | Undo 表空間的存儲目錄 | 數據目錄(如 /data/mysql/data/) | 獨立 SSD 目錄(如 /data/mysql/undo/) |
innodb_rollback_segments | 回滾段數量(每個回滾段可支持多個事務) | 128 | 保持默認(足夠支持高并發) |
innodb_undo_log_encrypt | 是否加密 Undo Log(防止數據泄露) | OFF | 核心業務建議開啟(ON) |
innodb_max_undo_log_size | 單個 Undo 表空間的最大大小(超過后觸發截斷) | 1G(1073741824 字節) | 2G~4G(根據磁盤空間調整) |
innodb_undo_log_truncate | 是否自動截斷過大的 Undo 表空間 | ON(MySQL 8.0+) | 保持開啟 |
innodb_purge_threads | Purge 線程數(影響清理速度) | 4 | 高并發場景設為 8~16 |
innodb_purge_rseg_truncate_frequency | 每執行多少次 Purge 檢查并刪除無用回滾段 | 128 | 10~50(平衡清理頻率與 CPU 開銷) |
14.2 配置示例(優化 Undo Log 性能)
-
配置 Undo Log 獨立存儲目錄:
# 1. 編輯配置文件 vim /data/mysql/conf/my.cnf# 2. 添加配置 [mysqld] innodb_undo_directory = /data/mysql/undo/ # 獨立存儲目錄 innodb_rollback_segments = 128 # 回滾段數量 innodb_undo_log_encrypt = on # 開啟加密 innodb_max_undo_log_size = 2147483648 # 單個表空間最大 2G innodb_undo_log_truncate = on # 自動截斷 innodb_purge_threads = 8 # Purge 線程數 8 innodb_purge_rseg_truncate_frequency = 20 # 每 20 次 Purge 檢查回滾段# 3. 創建目錄并授權 mkdir -p /data/mysql/undo/ chown -R mysql.mysql /data/mysql/undo/ chmod 700 /data/mysql/undo/# 4. 重啟 MySQL 服務 /etc/init.d/mysql.server restart -
查看 Undo Log 表空間信息:
# 查看 Undo 表空間列表與路徑 select tablespace_name, file_name, engine from information_schema.files where file_type = 'UNDO LOG';# 查看 Undo 表空間大小(單位:MB) select tablespace_name,round((EXTENT_SIZE * TOTAL_EXTENTS) / 1024 / 1024, 2) as total_size_mb from information_schema.files where file_type = 'UNDO LOG'; -
手動創建 Undo 表空間(MySQL 8.0.14+):
若默認 Undo 表空間不足,可手動創建額外表空間:# 創建 Undo 表空間(指定數據文件) create undo tablespace tmp_undo_001 add datafile 'tmp_undo_001.ibu';# 查看新增的表空間 select tablespace_name from information_schema.files where file_type = 'UNDO LOG'; -
刪除 Undo 表空間(需先設為 inactive):
# 1. 將表空間設為 inactive(停止寫入新的 Undo Log) alter undo tablespace tmp_undo_001 set inactive;# 2. 等待表空間中的 Undo Log 被 Purge(可通過監控表空間大小確認)# 3. 刪除表空間 drop undo tablespace tmp_undo_001;
14.3 Undo Log的相關配置(續)
-
innodb_rollback_segments:配置回滾段的數量。在 MySQL 8.0.2 之前,配置回滾段的數量的參數是 innodb_undo_logs,MySQL 8.0.2 開始就改成了innodb_rollback_segments;回滾段包含撤銷日志的存儲區域,從 MySQL 5.6 開始,回滾段可以駐留在 undo 表空間中,從 MySQL 5.7 開始,回滾段可以分配給全局臨時表空間;InnoDB 使用多個回滾段來組成 undo log,可以保證 MySQL 的并發寫入和持久化。可以這樣理解,一個 undo 表空間里有多個回滾段,當并發執行事務時,不同時候可能執行不同回滾段,該參數可以配置的范圍是 1-128
-
innodb_undo_log_encrypt:控制是否對Undo Log進行加密,默認值為
OFF(不加密)。開啟后可增強數據安全性,防止Undo Log文件被未授權訪問時泄露敏感數據。
配置方式:# 動態開啟(需重啟MySQL生效,且需確保MySQL支持加密功能) set global innodb_undo_log_encrypt = ON; # 永久配置(在my.cnf的[mysqld]中添加) innodb_undo_log_encrypt = ON注意:開啟加密后,Undo表空間文件會以加密格式存儲,需確保密鑰管理安全(如使用MySQL密鑰環插件)。
-
innodb_max_undo_log_size:定義單個獨立Undo表空間的最大閾值,默認值為
1G。當Undo表空間大小超過該值,且innodb_undo_log_truncate開啟時,MySQL會自動截斷Undo表空間,釋放磁盤空間。
配置示例:# 動態調整(需重啟MySQL生效) set global innodb_max_undo_log_size = 2G; # 永久配置 innodb_max_undo_log_size = 2G -
innodb_undo_log_truncate:控制是否自動截斷過大的Undo表空間,默認值為
ON(開啟)。僅對獨立Undo表空間生效(系統表空間中的Undo Log不支持截斷),截斷操作依賴于回滾段的釋放(由innodb_purge_rseg_truncate_frequency控制)。
注意:若關閉該參數,Undo表空間會持續增長,需手動清理,可能導致磁盤空間耗盡。 -
innodb_purge_threads:定義后臺Purge線程的數量,默認值在MySQL 8.0中為
4(早期版本可能為1)。Purge線程負責清理不再需要的Undo Log(如已提交事務的舊版本數據),多線程可提升高并發場景下的Purge效率,避免Undo Log堆積。
配置示例:# 動態調整(需重啟MySQL生效) set global innodb_purge_threads = 8; # 永久配置(根據CPU核心數調整,建議不超過CPU核心數的1/2) innodb_purge_threads = 8 -
innodb_purge_rseg_truncate_frequency:控制Purge操作執行多少次后,檢查并釋放“不再被使用的回滾段”,默認值為
128。回滾段釋放后,對應的Undo表空間才能被innodb_undo_log_truncate截斷。
調整原則:值越低,回滾段釋放頻率越高,Undo表空間截斷越及時,但頻繁檢查會增加CPU開銷;值越高,CPU開銷越低,但可能導致Undo表空間臨時膨脹。
15 Binlog、Redo Log、Undo Log 的區別
Binlog、Redo Log、Undo Log 是 MySQL 中最核心的三類日志,作用與機制差異顯著,需明確區分。
15.1 Binlog 和 Redo Log 的區別
| 對比維度 | Binlog(二進制日志) | Redo Log(重做日志) |
|---|---|---|
| 記錄對象 | 所有存儲引擎(如InnoDB、MyISAM)的修改操作 | 僅InnoDB存儲引擎的修改操作 |
| 記錄內容 | 邏輯日志,記錄“做了什么修改”(如UPDATE table SET ...) | 物理日志,記錄“數據頁做了什么變更”(如“頁123的偏移量456值從A改為B”) |
| 記錄時機 | 僅在事務提交時寫入(一次性寫入事務的所有操作) | 事務執行過程中持續寫入(每執行一個修改操作就寫一次) |
| 寫入方式 | 追加寫(文件滿后自動切換到新文件,不覆蓋舊日志) | 循環寫(固定大小的日志文件組,寫滿后覆蓋最早的文件) |
| 核心用途 | 主從復制(從庫通過Binlog回放變更)、數據備份與恢復(全量+Binlog增量) | 保證事務持久性(崩潰后通過Redo Log恢復未刷盤的已提交事務) |
| 崩潰恢復角色 | 不參與InnoDB崩潰恢復(依賴Redo/Undo Log) | 核心恢復角色(恢復已提交但未刷盤的數據) |
15.2 Undo Log 和 Redo Log 的區別
| 對比維度 | Undo Log(回滾日志) | Redo Log(重做日志) |
|---|---|---|
| 記錄內容 | 反向修改記錄(如“插入了一行id=1,回滾時需刪除id=1”) | 正向變更記錄(如“id=1的字段值從A改為B,恢復時需重新執行該變更”) |
| 寫入順序 | 隨機讀寫(Undo Log存儲在表空間中,修改時可能需定位舊記錄) | 順序寫(固定日志文件組,按操作順序連續寫入,性能高) |
| 核心作用 | 1. 事務回滾(恢復到修改前狀態) 2. 支持MVCC(提供數據歷史版本) | 1. 保證事務持久性(崩潰后恢復未刷盤的已提交事務) 2. 避免頻繁刷盤(僅需寫日志,無需立即刷數據頁) |
| 生命周期 | 事務提交后需保留(直到無事務依賴歷史版本),由Purge線程清理 | 事務提交后,日志可被覆蓋(數據頁刷盤后,對應的Redo Log失效) |
15.3 更新數據時各種日志的寫入時機
當執行一條UPDATE語句(如UPDATE user SET name='test' WHERE id=1)時,日志寫入順序如下:
- 寫Undo Log:在修改數據前,先記錄Undo Log(如“id=1的name原值為’old’,回滾時需改回’old’”),確保后續可回滾。
- 修改內存數據頁:直接更新InnoDB緩沖池中的數據頁(不立即刷盤)。
- 寫Redo Log:記錄數據頁的變更(如“user表id=1的數據頁,name字段從’old’改為’test’”),標記為“prepare”狀態,確保崩潰后可恢復該變更。
- 事務提交:
- 寫Binlog:將整個
UPDATE語句的邏輯日志寫入Binlog,并刷盤。 - 寫Redo Log:將Redo Log的狀態從“prepare”改為“commit”,完成事務提交。
- 寫Binlog:將整個
關鍵結論:Undo Log“先于修改”,Redo Log“伴隨修改”,Binlog“最后提交時寫入”,三者配合確保事務的ACID特性。
16 日志相關問題總結
16.1 MySQL 為什么不用 Redo Log 來進行主從復制
核心原因在于Redo Log的“引擎依賴性”和“寫入特性”不適合跨實例同步:
- 引擎局限性:Redo Log是InnoDB特有的物理日志,而MySQL支持MyISAM、Memory等多種存儲引擎,若用Redo Log復制,非InnoDB引擎的變更無法同步。
- 寫入方式問題:Redo Log是“循環寫”(寫滿后覆蓋舊日志),而主從復制需要“追加寫”的日志(從庫需按順序回放所有變更,不能丟失歷史日志),Redo Log的覆蓋特性無法滿足。
- 同步工具兼容性:主流主從同步工具(如MySQL原生復制、MGR)均基于Binlog的邏輯日志設計,可解析SQL語句或行級變更,而Redo Log的物理格式(數據頁偏移量、二進制值)無法被非InnoDB實例解析。
16.2 其它有關 MySQL 日志相關的問題
問題1:Redo Log 在 prepare 階段是否開始刷盤?
是的。Redo Log在事務執行過程中會“持續刷盤”:當執行數據修改時,Redo Log先寫入內存中的“Redo Log Buffer”,然后通過“后臺線程”或“事務提交觸發”刷盤;在二階段提交的“prepare”階段,Redo Log會確保已刷盤(僅標記為prepare狀態),而Binlog僅在“commit”階段刷盤——這種設計可避免“Redo Log已提交但Binlog未寫”的數據不一致問題。
問題2:二階段提交(2PC)為什么能保證數據一致性?
二階段提交通過“prepare→commit”兩步確保Redo Log和Binlog的一致性:
- prepare階段:寫Redo Log并刷盤(標記prepare),此時事務未完成,若崩潰,重啟后檢查Binlog:若Binlog未寫,則回滾;若Binlog已寫,則提交。
- commit階段:先寫Binlog并刷盤,再將Redo Log標記為commit。此時兩日志均已持久化,事務完成。
核心作用:避免“Redo Log已提交但Binlog未寫”(從庫無法同步)或“Binlog已寫但Redo Log未提交”(主庫崩潰后丟失數據)的不一致場景。
問題3:MySQL Binlog 里面的時間為什么有些不是順序的?
Binlog記錄的是“事務提交時間”,而非“事務開始/執行時間”,若多個事務的“執行順序”與“提交順序”不一致,就會出現Binlog時間不連續的情況。
示例:
- 事務A:10:00開始執行,10:05提交,Binlog記錄時間為10:05。
- 事務B:10:02開始執行,10:03提交,Binlog記錄時間為10:03。
此時Binlog中事務B的時間(10:03)會早于事務A的時間(10:05),但事務A的執行開始時間更早,導致Binlog時間“看似無序”,實則按“提交順序”有序記錄,不影響主從復制(從庫按Binlog順序回放即可)。
17 章末總結
| 知識點 | 需要掌握的內容 |
|---|---|
| Binlog | Binlog的配置、Binlog的作用、Binlog的記錄格式、Binlog內容解析、Binlog的清除、Binlog的落盤 |
| General Log | General Log的配置、查看General Log、General Log的作用及不足 |
| Slow Log | Slow log的開啟、一些特殊設置、Slow Log的解析、8.0 慢查詢額外信息、mysqldumpslow |
| Error Log | Error Log的配置和查看、Error Log的作用、Error Log的過濾、通過表記錄Error Log |
| Redo Log | Redo Log 是什么?如何配置、在崩潰恢復中的作用、Redo Log的最佳實踐、Redo Log的落盤、Redo Log的歸檔、Redo Log的禁用 |
| Undo Log | Undo Log的作用、Undo Log中的內容、不同語句類型Undo Log的區別、Undo Log 在奔潰恢復過程的作用、Undo Log的最佳實踐、Undo Log的Purge、Undo Log的配置 |
| Binlog、Redo Log、Undo Log的區別 | Binlog和Redo Log的區別、Undo Log和Redo Log的區別、更新數據時各種日志的寫入時機 |
本章核心圍繞MySQL的5類關鍵日志展開,各類日志的核心定位與最佳實踐可概括為:
- Binlog:“全局變更日志”,核心用于主從復制和增量備份,關鍵配置包括
log-bin(開啟)、binlog_format(推薦row模式保證主從一致)、binlog_expire_logs_seconds(控制保留時間,避免磁盤溢出)。 - Redo Log:“InnoDB的持久性保障”,關鍵配置
innodb_flush_log_at_trx_commit=1(確保事務提交即刷盤,不丟數據)、innodb_redo_log_capacity(根據業務寫入量調整日志大小,避免頻繁切換)。 - Undo Log:“回滾與MVCC的基礎”,需配置獨立Undo表空間(
innodb_undo_directory)、開啟自動截斷(innodb_undo_log_truncate=ON),并監控長事務(避免Undo Log堆積)。 - General Log:“全量操作日志”,生產環境建議關閉(性能開銷大),僅在排查特殊問題時臨時開啟。
- Slow Log:“性能優化工具”,關鍵配置
long_query_time=1(捕獲1秒以上的慢查詢)、log_queries_not_using_indexes=ON(捕獲無索引查詢),配合mysqldumpslow工具分析優化。
各類日志的協同作用:Binlog保證“跨實例一致性”(復制),Redo/Undo Log保證“InnoDB內部一致性”(崩潰恢復、回滾),Slow Log保證“性能可控”,共同支撐MySQL的穩定運行。
)

)


)





落地(一)環境搭建)







)