目錄
回顧一下xml文件怎么寫
哪個地方使用了哪個技術?
MyBatis-Plus-oj的表結構設計,
管理員登錄功能?
Swagger
Apifox?編輯
BCrypt
日志框架引入(slf4j+logback)
nacos
Swagger無法被所有微服務獲取到修改的原因
身份認證三種方式:
JWT(Json Web Json,一種基于JSON的安全跨平臺信息傳輸格式,JWT(定義了一種緊湊且自包含的方式)用于各方間安全傳輸信息,此信息可以用于驗證和相互信任。
缺點:
改良
Redis
RedisTemplate
Entity
DTO
VO
RouterLink組件
RouterView組件
VUE規則
Axios(代替ajax)
B端功能(定義接口請求方式Get(查詢),Post(新增),Put(修改),Delete(刪除)
PageHelper
Vue聲明周期函數
C端功能流程
阿里云密鑰(阿里云短信登錄)
核心是使用redis來模擬
Jmeter
XXL-job
競賽報名功能
TransmittableThreadLocal
我的競賽功能
?題目詳情緩存 ?(引入ES)
ES是什么
ES寫入提高效率
ES的全文檢索
代碼沙箱(判題功能)
因此引入MQ
用戶拉黑功能
引入注解
引入切面類
我的消息功能
消息發送實現:
競賽排名功能
臨時記錄
Nginx
正向代理
反向代理
負載均衡
動靜分離
題目的順序列表(用戶端的前一題和后一題,怎么做)
2025年5月13日 面試,某某某某達
ES怎么做添加
回顧一下xml文件怎么寫
?namespace=xxx映射命名空間,xml對應的java(Mapper)接口
<mapper namespace="com.bite.system.mapper.exam.ExamMapper">
resultType指,映射到ExamVO這個類中
使用#{}接收傳遞過來的參數
<select id="selectExamList" resultType="com.bite.system.domain.exam.vo.ExamVO">
selectte.exam_id,te.title,te.start_time,te.end_time,te.create_time,ts.nick_name as create_name,te.statusfromtb_exam teleft jointb_sys_user tsonte.create_by = ts.user_id<where> //假如有一個有時候存在,有時候不存在則使用這個if,在where里面使用 <if test="title!=null and title!=''"> AND title like CONCAT('%',#{title},%) 進行一個模糊查詢 </><if test="title !=null and title !=''">AND title LIKE CONCAT('%',#{title},'%')</if><if test="startTime !=null and startTime !='' ">AND te.start_time >= #{startTime}</if><if test="endTime !=null and endTime !='' ">AND te.end_time <= CONCAT(#{endTime},'23:59:59.999')</if></where>ORDER BYte.start_time DESC </select>
接口文檔,接口的說明文檔
作用:簡化前端開發,易于錯誤處理,代碼可維護性,文檔化
//請求方法和請求參數 先是Authorization(奧絲ruai賊神)
接口概述,接口地址,請求方法,請求參數,相應數據,請求和相應示例
HTTP協議:1xx信息.表示臨時相應并且需要請求者繼續執行操作
2XX 成功。操作被成功接受并處理
3xx重定向,表示客戶端必須執行一些其他操作才能完成其請求
4xx客戶端錯誤,請求包含語法錯誤或者無法完成請求
5xx服務器錯誤,這些錯誤可能是服務器本身的錯誤,而不是請求出錯
this(這個/自身)
+this,調用自身的屬性和方法
什么時候使用this,當傳入的參數名字和你的屬性名字一樣時候,就使用this。
this(),調用自己的構造方法,必須要放到首行
MyBatis-Plus-oj的表結構設計,
?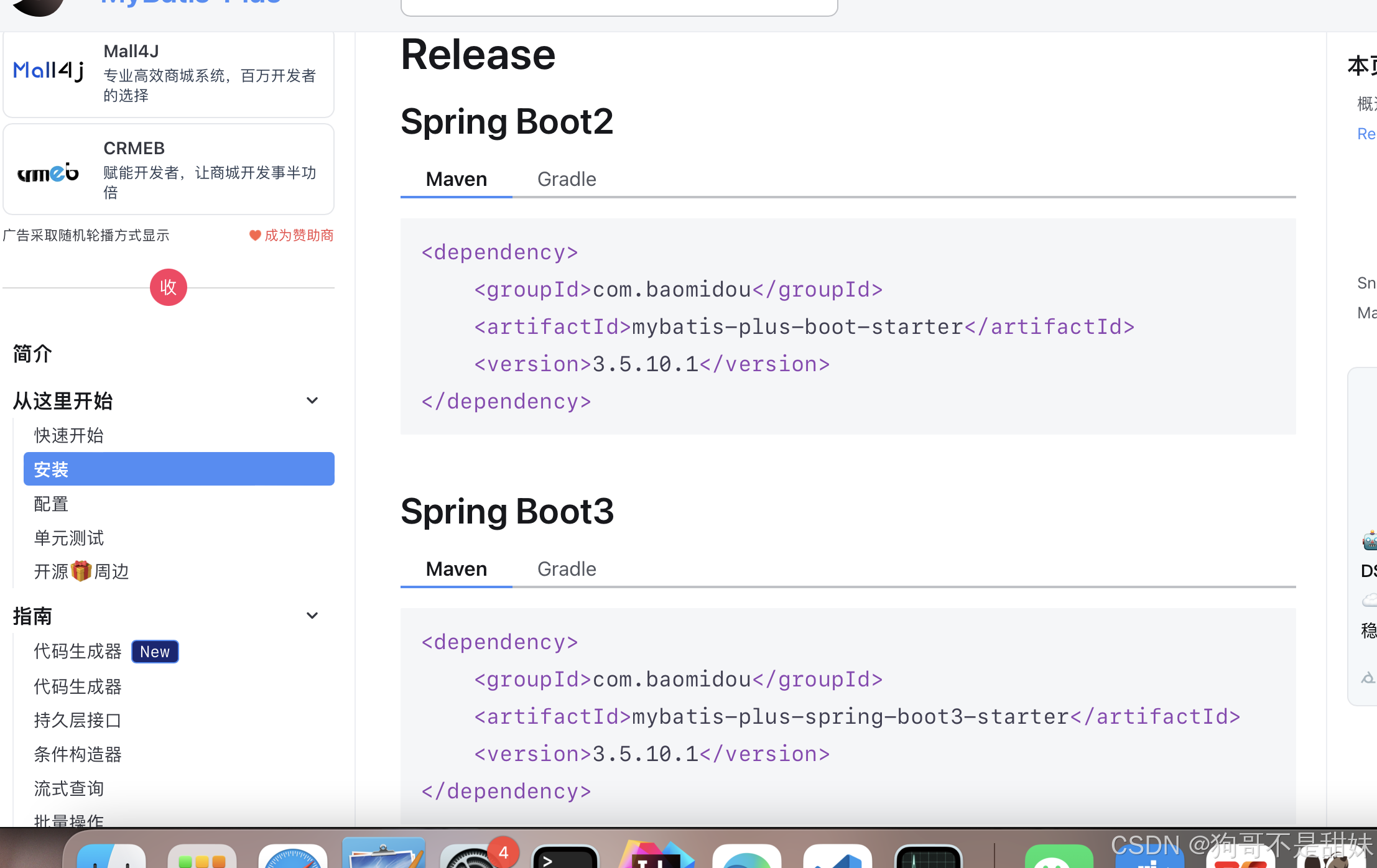
之間無腦快速安裝版本簡單易操作
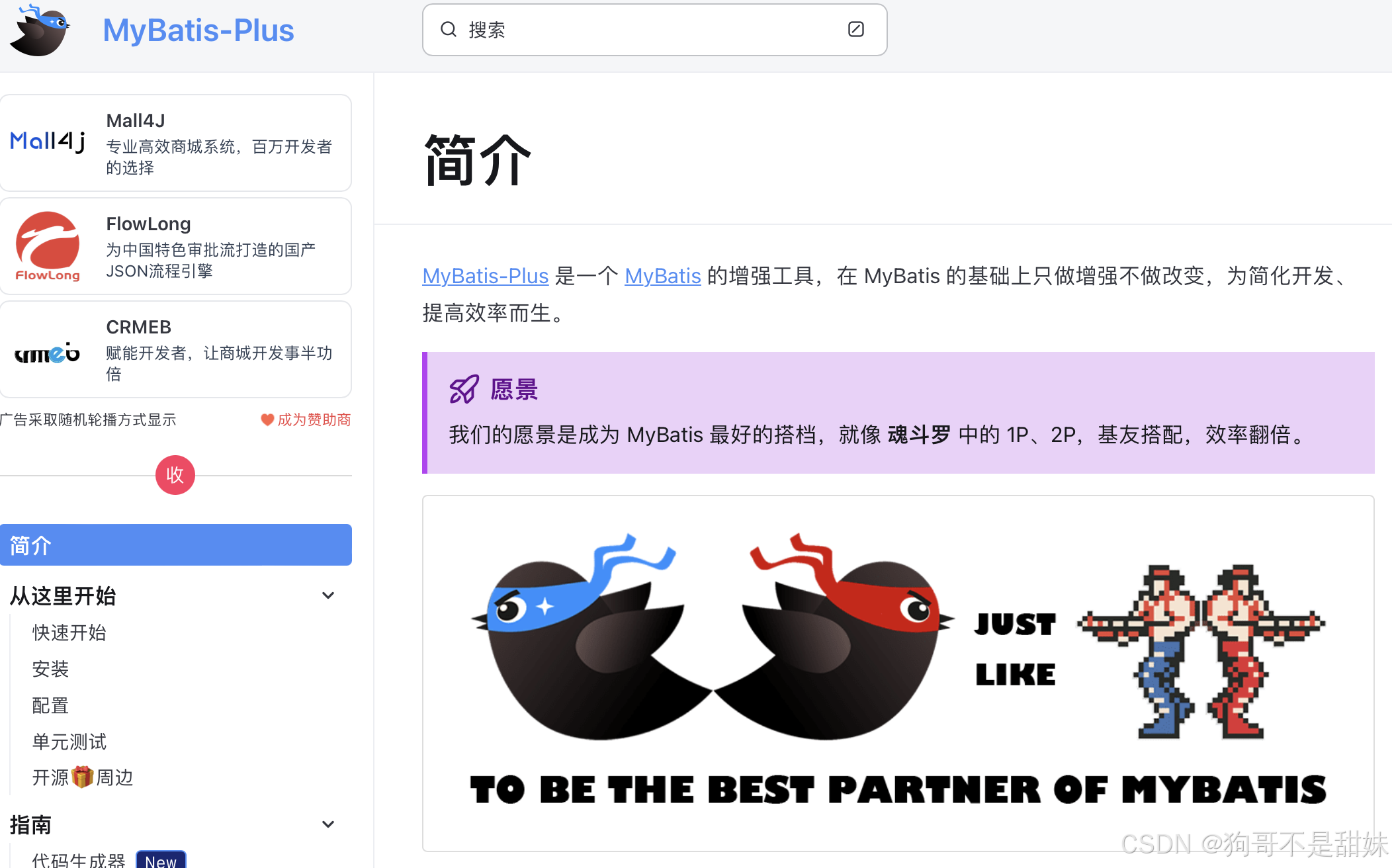
數據庫連接池:借助mybatis-plus操作數據庫雖然給我們很大便捷,但是這樣方式操作會導致一些問題
頻繁的創建來哪和銷毀連接:包括TCP層的握手和Mysql協議的握手,會消耗大量時間
連接數不受控制:在業務流量高峰期,大量應用服務器可能同時請求數據庫連接,而數據庫能夠承載的連接數目有限,這可能導致數據庫性能降低
連接管理困難:開發者需自行管理數據庫連接的創建,使用和關閉,這增加了開發的復雜性和出錯的可能性。
數據庫連接池用來解決這些問題:
提供統一管理:數據庫連接池對數據庫連接創建等操作的統一管理
提高系統性能:由于創建和銷毀數據庫連接需要消耗時間和系統資源,如果每次進行數據庫操作都不斷銷毀,創建會影響性能使用連接池可以復用已經創建好了連接,大大提高系統的性能
提高資源利用率:連接池通過復用已有連接,避免了頻繁創建和銷毀連接帶來的資源浪費,提高了系統資源利用率
提高系統穩定性:數據庫連接池可以有效控制系統中并發訪問數據庫的連接數量,避免因并發連接數過多導致數據庫崩潰,同時連接池還會定時檢查連接的有效性,自動替換掉無效連接,保證了系統的穩定性
常見的:C3P0,Druid,HikariCP
為什么使用HikariCP(controation pool)
高性能:HikariCP是一個高性能的數據庫連接池,他提供了快速,低延遲的連接獲取和釋放機制,在SpringBoot項目中,這可以顯著提高應用程序的響應速度和吞吐量,特別是在高并發場景
資源優化:HikariCP對資源的使用進行精細的管理和優化,他采用一種內存效率極高的數據結構來存儲和管理連接,減少了內存占用和垃圾回收的壓力,還減少了不必要的線程和鎖競爭
配置靈活:HikariCP提供了豐富的配置選項,允許開發者根據項目的具體需求進行微調
與SpringBoot集成良好:SpringBoot對HikariCp提供了良好的支持,可以輕松過集成
線程假如滿了,超時就拋棄,假如空閑時間,沒有使用那個臨時線程,那么就會銷毀這個線程
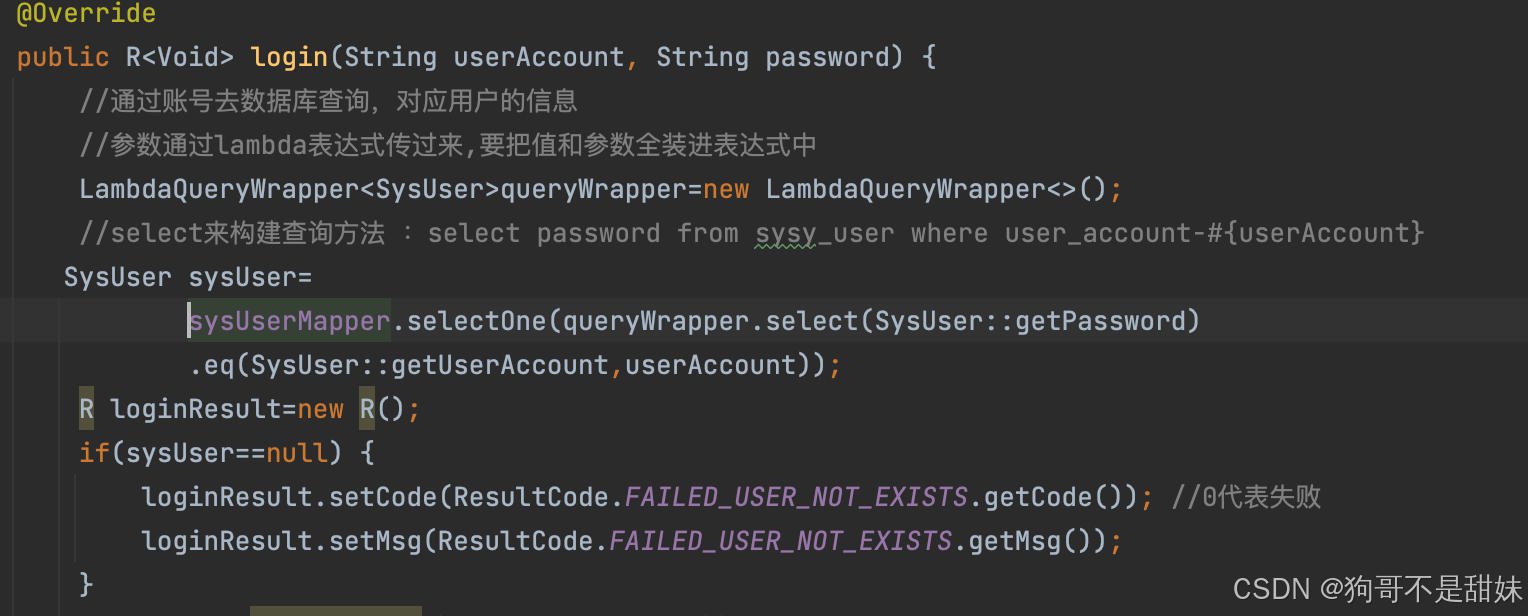
管理員登錄功能?
表結構設計:滿足需求,避免冗余設計,考慮今后發展
1.導入依賴,mapper去繼承這個類,
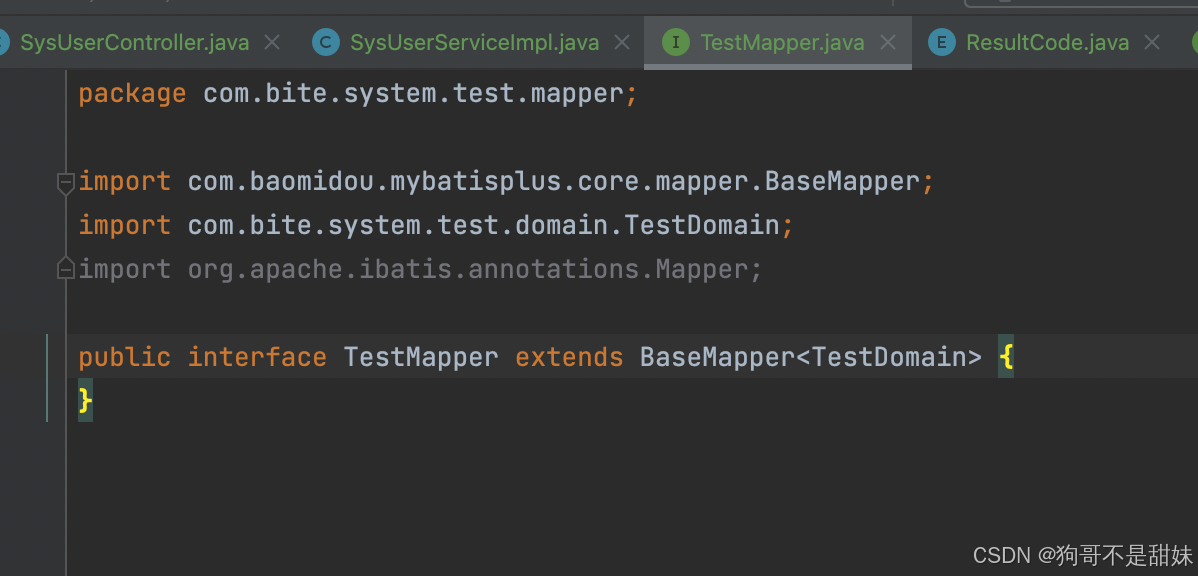
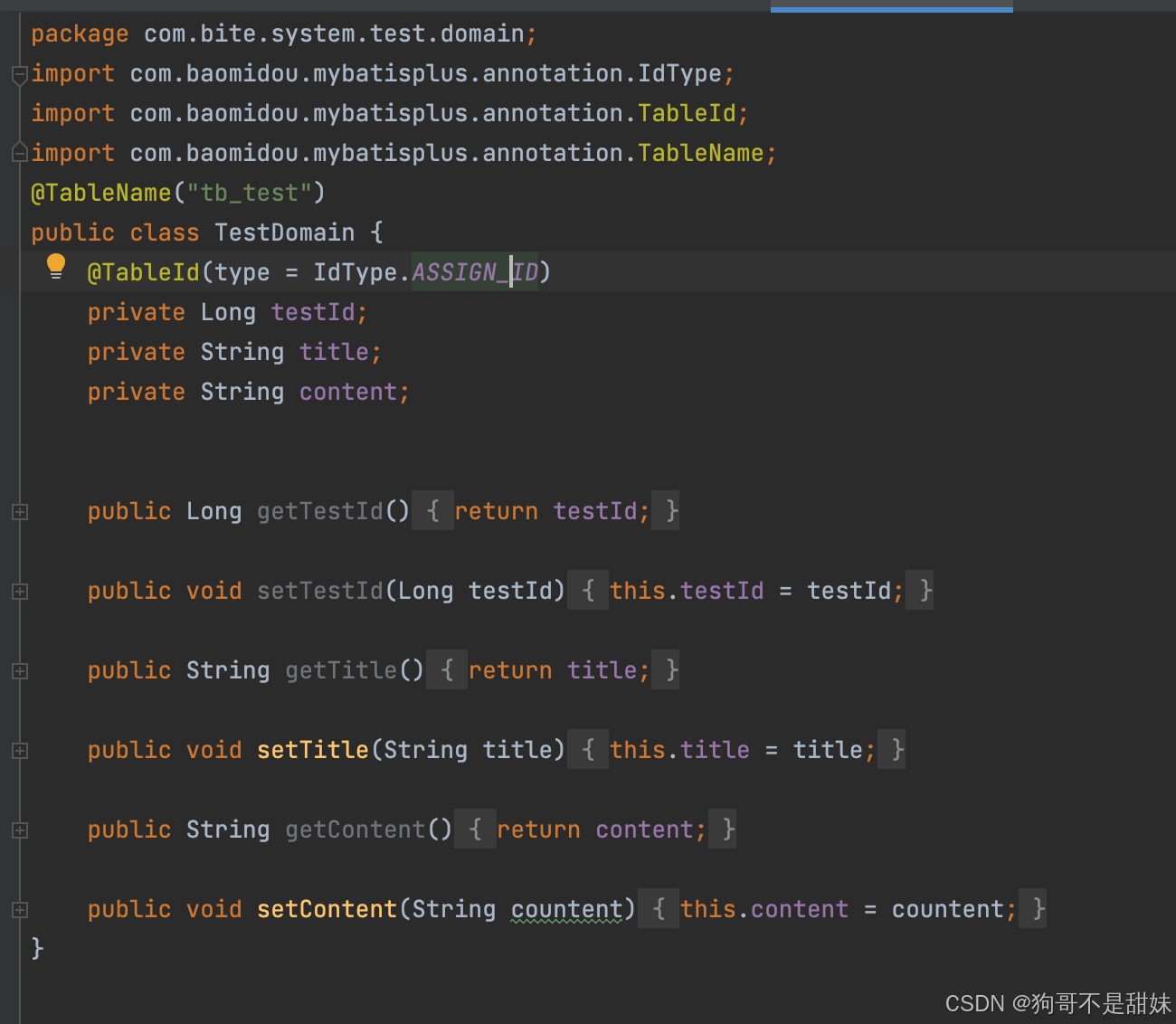
?2.可以理解為接受的對象,就是和數據庫表對應的,然后我們填入那個TableId的名字
3.對應的Service,找到你想要的方法,去實現,假如不是那個查找全部列表就lambda
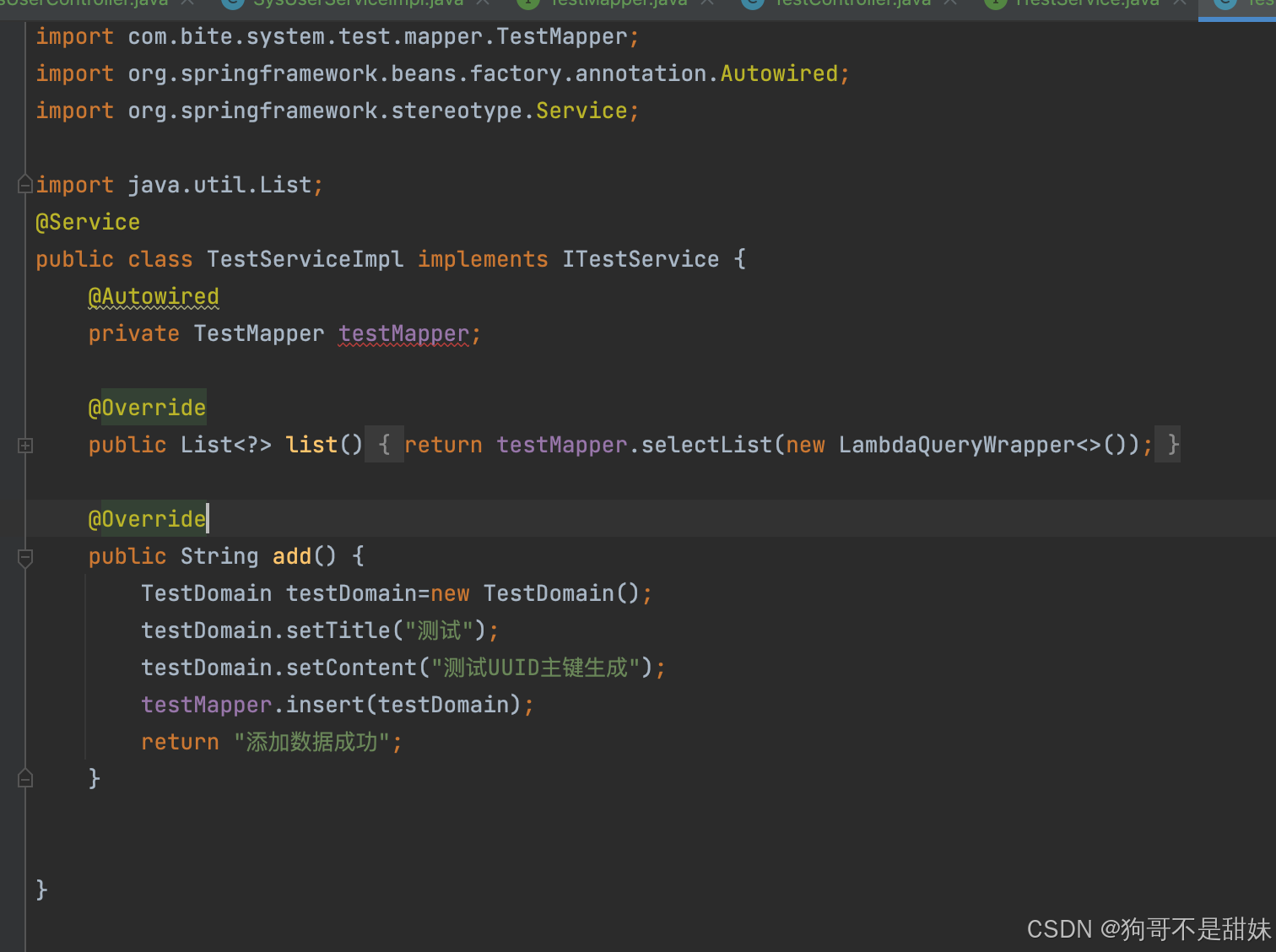
比如這種,使用lambda表達式,傳入的參數填入lambda,需要xx使用xx來查
Swagger
swagger是否是一個公共的呢,沒啥難度,引入就直接操作啦
Apifox
BCrypt
哈希加密算法,被廣泛應用于存儲密碼和進行身份驗證,并且BCrypt算法每次計算都會先生成一個隨機鹽值,與用戶密碼一起參與計算最終得到一個加密的字符串,由于生成鹽值隨機的,所以每次使用相同的密碼得到結果也不相同,這樣有效防止攻擊者破解密碼
日志框架引入(slf4j+logback)
1.重要性
故障的排查和問題定位
系統監控
數據采集
日志審計
2.注意事項
注意日志級別
注意日志內容,日志格式和可讀性
注意日志的滾動和歸檔
為什么選擇slf4j+logback
易于切換,配置靈活
logback性能更好,集成更方便,功能更強大
SpringBoot默認的日志框架
每次修改一個配置都需要重新打包上線,團隊的協作比較困難,環境隔離不足,開發,測試,生產
nacos
配置MYSQL數據庫
- 數據持久性:使用MYSQL作為外置數據庫可以確保數據被持久化存儲,這對于確保服務的穩定性和數據的可靠性非常重要
- 高可用性:NACOS支持集群部署,使用MYSQL作為共享的數據存儲可用確保集群中各個節點的數據一致性,此外MYSQL自身也支持高可用和故障轉移,使用主從復制或者集群解決方案,從而進一步提高系統可用性。
- 性能優化:使用nacos內置的數據庫,雖然能簡化部署,但是性能收到限制,外置的MYSQL可用根據需要進行優化和擴展,滿足更高的性能需求
- 易于管理和維護:我們系統本身用MYSQL,nacos外置數據庫和我們系統采用同樣的數據庫庫,可以保證技術使用的統一,簡化了數據庫的管理和維護工作,降低運維成本。
這里我們項目分為三類
1000 SUCCESS ? ? ?操作成功
2000 ERROR 服務器繁忙請稍后重試(前端根據錯誤碼顯示,服務器繁忙,請稍后重試)
3000 操作失敗,但是服務器不存在異常
3001 未授權
3002 參數校驗失敗
3003資源不存在
3004資源已經存在
3101用戶已經存在
3102用戶不存在
3103用戶或者密碼錯誤
3104 你已被列入黑名單,請聯系管理員
Swagger無法被所有微服務獲取到修改的原因
我們想把Swagger進行一些修改,可是發現為什么改不了呢
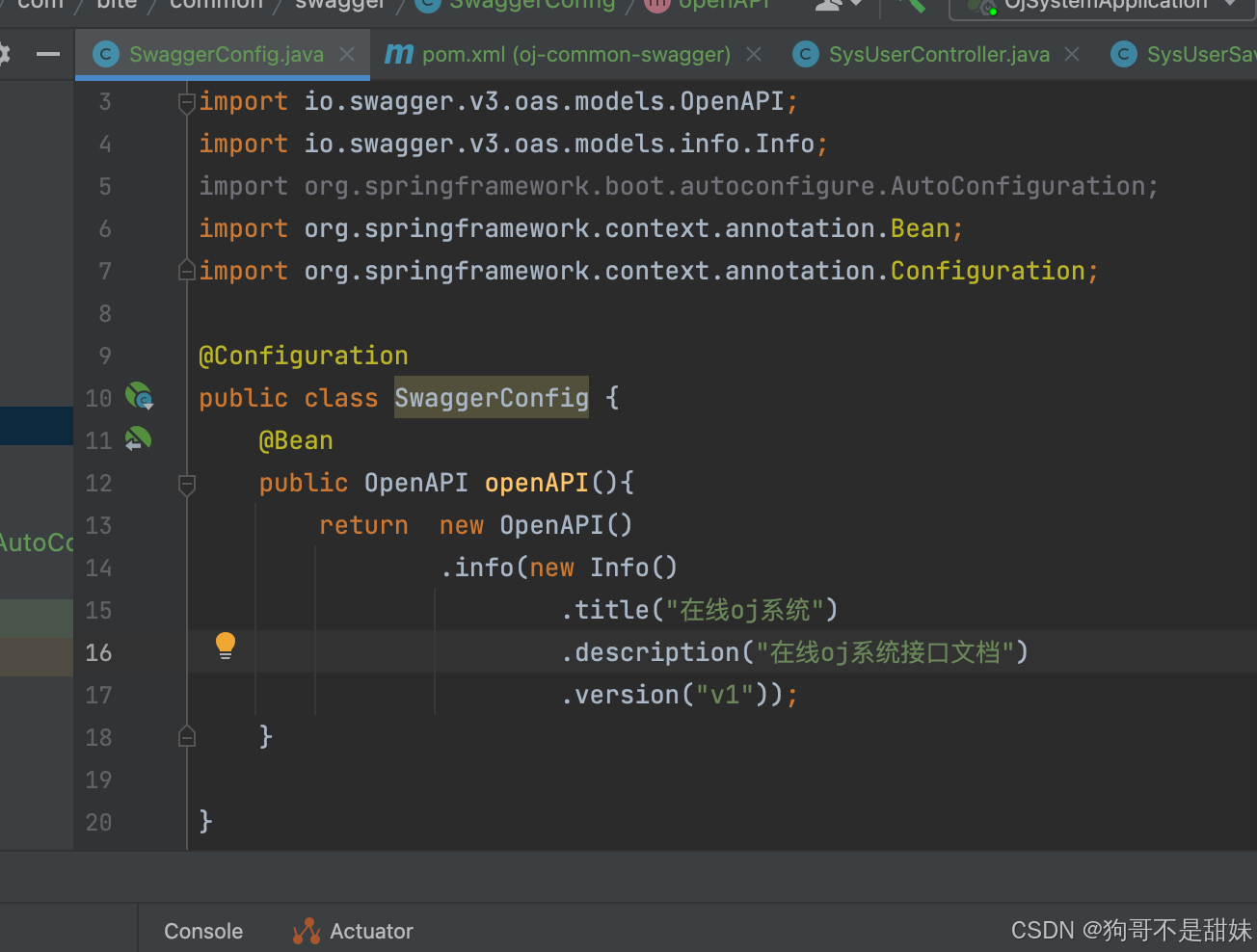
(org.springframework.boot.autoconfigure.AutoConfiguration.imports,明明這個已經寫了,還是在那個目錄里面)
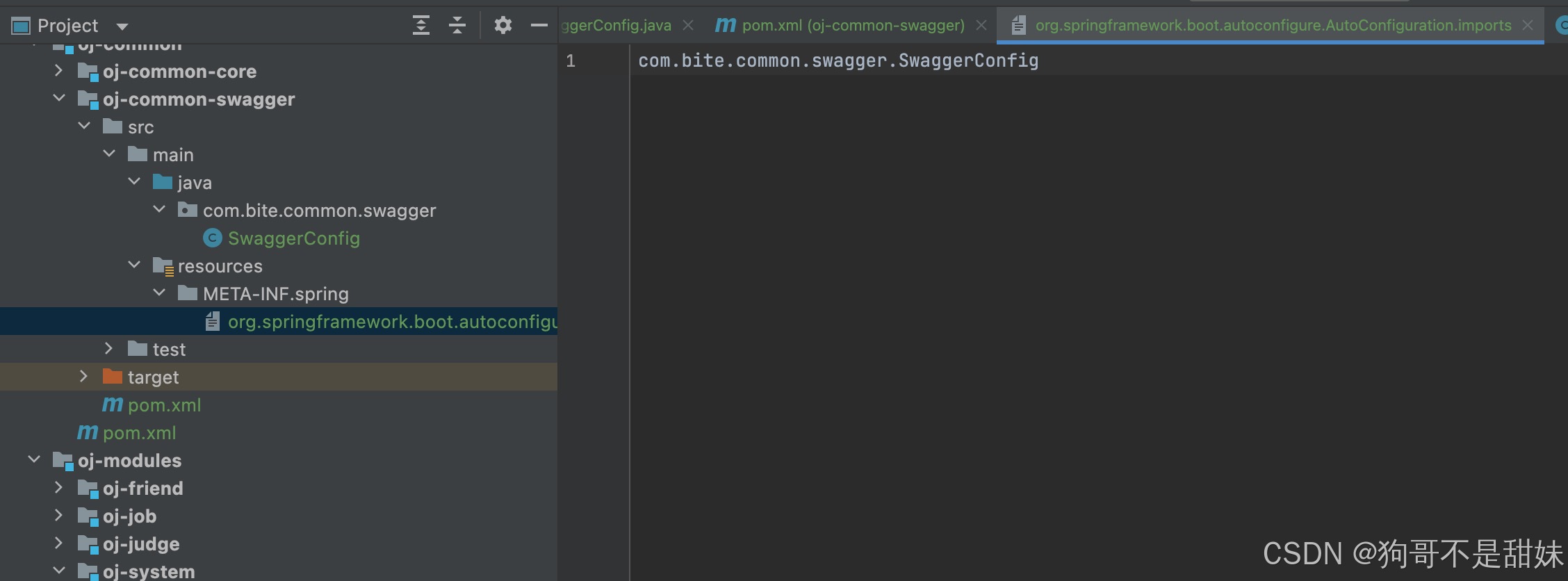
這個是因為你的META-INF.spring,是一步創建的,正常來說這個應該是先創建INF,再去創建spring,由IDEA來合并,可不是你自己就去合并了,這就是導致不能被訪問的原因。
身份認證三種方式:
- 基于Session的身份認證:這個是最常見的身份認證方式,當用戶首次登錄的時候,服務器會將用戶信息存入session并生產一個唯一的SessionID,然后返回給客戶端,此后的請求客戶端會要攜帶這個Session ID,服務器通過Session ID有效性來判斷用戶身份
- 基于OAuth身份認證:OAuth認證機制是一種安全,開發且簡易的授權標準,他允許用戶授權第三方應用訪問其賬戶資源,而無需向這些應用提供用戶名和密碼,如微信,QQ登錄其他網站
- 基于Token的身份認證,這種方式,服務器在用戶登錄過后,會返回一個Token給客戶端,客戶端每次請求資源,都在請求頭上攜帶Token,服務器通過驗證Token的有效性來判斷用戶的身份,這種方式常見于前后端分離的架構中,如JWT進行身份驗證。
JWT(Json Web Json,一種基于JSON的安全跨平臺信息傳輸格式,JWT(定義了一種緊湊且自包含的方式)用于各方間安全傳輸信息,此信息可以用于驗證和相互信任。
由三部分組成:頭部,載荷,簽名
頭部(header):包含令牌類型和使用方法
載荷(payload):包含用戶信息和其他元數據(使用base編碼)
簽名(signatiure):用于檢驗令牌的完整性和真實性
簽名算法{
base64(header+base64編碼(payload)
}
客戶端使用用戶名跟密碼請求登錄
服務端收到請求,去驗證用戶名和密碼
驗證成功后,服務端簽發一個Token,再把這個Token發送客戶端(token上述的jwt串)
客戶端收到Token,會把他存儲起來
每次客戶向服務端請求資源時候,帶著Token
服務端收到請求,驗證客戶端里面帶著的Token,如果驗證成功,向客戶端返回請求的數據。
缺點:
JWT的payload沒有加密,假如token泄漏,那么用戶的信息就完全暴露了,所以完全不能存敏感數據。(用戶手機號,銀行卡號啥的)
jwt,無狀態,假如想要修改其中的內容,就要重新簽發一個新jwt
無法延長jwt的過期時間。
改良(JWT+Redis)
1.payload不存敏感信息,解決:僅僅存儲用戶的唯一標識信息。
第三方存儲敏感信息(根據唯一標識信息,從第三方機制查處相應敏感信息
存儲的查詢性能要高,并且不需要長期存儲,
2.用戶修改了個人信息之后,jwt不變。
滿足第一點后,相當于就是兩個分開了,我只是改了第三方敏感信息
3.控制jwt的過期時間
不能再使用JWT提供的過期時間的參數。
通過第三方記錄jwt的過期時間,并且支持過期時間的修改,最好還有第三方工具提供存儲功能 ? ?
- Redis
當賬號和密碼匹配成功之后,生成JWT
redis(表明用戶身份字段,加上前綴就是)
logintoken+雪花id/或者(假如我們不用雪花id,沒這個條件,只可以自增ID,B,C表全是自增的,肯定會重復,引入hutool工具包的uuid,),存儲的對象是用的里面fastjson序列化器,
把一個對象存入redis(設置過期時間哈要)
假如720分鐘之后,用戶拿著過期的token,我怎么查找出來呢?,我直接通過redis值判斷
token存的是自增主鍵和uuid
y用戶攜帶我們給他返回的token,向我們服務器再次發送請求的時候,我們調用parse方法解析(傳入token和secret鹽值),解析后得到這兩個值,我去拿到redis中,去進行一個查詢,如果查詢到我們之前存的數據key是下面的,然后value有東西就可以
key //LoginToken+userId (因為UserId本身就是唯一的,通過雪花算法)value:用戶身份(管理員/用戶) nickName昵稱,headImage頭像
Redis
jwt+Redis實現身份認證機制。
為什么要封裝Service
package com.bite.common.redis.config; import org.springframework.boot.autoconfigure.AutoConfiguration; import org.springframework.boot.autoconfigure.AutoConfigureBefore; import org.springframework.boot.autoconfigure.condition.ConditionalOnSingleCandidate; import org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration; import org.springframework.cache.annotation.CachingConfigurerSupport; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.StringRedisSerializer;@Configuration @AutoConfigureBefore(RedisAutoConfiguration.class) public class RedisConfig extends CachingConfigurerSupport {@Bean// @ConditionalOnSingleCandidate 初始化這個Bean對象public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactoryconnectionFactory) {//new對象RedisTemplate<Object, Object> template = new RedisTemplate<>();//對屬性進行設置,和redis簡歷連接template.setConnectionFactory(connectionFactory);//new的一個自定義序列化器JsonRedisSerializer serializer = new JsonRedisSerializer(Object.class); // 使?StringRedisSerializer來序列化和反序列化redis的key值 key和value的序列化器是不同的template.setKeySerializer(new StringRedisSerializer());//我們一般對于key,還是哈希的key,都是采用String 類型,所以說,用String類型序列化器完全搞定//但是我們的value可能是存放具體的對象,對象的需要序列化,把序列化結果存起來,使用fastjsontemplate.setValueSerializer(serializer); // Hash的key也采?StringRedisSerializer的序列化?式template.setHashKeySerializer(new StringRedisSerializer());template.setHashValueSerializer(serializer);//完成設置后,對于后續的初始化操作template.afterPropertiesSet();return template;} }直接用redisTemple,他的內部有很多bean對象,通過bean去調用方法進行操作,使用一個redisService(進行一個封裝),使代碼和具體第三方實現解耦
抽象于解耦合:封裝第三方組建可以提供一個更加高級的抽象層,使得你的代碼于具體的第三方實現解耦合,如果未來更換第三方組件,或者調整其配置,你只需要對封裝的Service層,而不用修改整個應用中的大量代碼
統一接口:多個三方提供相似功能,api與用法各自不同,通過封裝提供統一接口,使開發者不用關注底層工具的具體差異
擴展性:更容易為第三方工具添加額外的功能和邏輯
錯誤處理和異常處理:可以統一封裝第三方的特定異常或者錯誤
代碼可讀性和可維護性:使用封裝的service可以使代碼更加清晰,容易理解
RedisTemplate
Boolean haskey(String key)判斷key是否存在
unit是時間單位
boolean expire(final String key ,final long timeout,finalTimeUnit unit ){} 設置有效時間?
getExpire(final String key,final TimeUnit unit){}
deleteObject(String key)刪除單個key
//緩存基本的對象,Integer,String 實體類等。
setCacheObject(final String key,final T value 緩存基本的對象,Integer,String,實體類等)
getCacheObject(final String key,Class<T>clazz)獲得緩存基本對象
getListSize(final String key)獲得List中存儲數據數量
Entity
與數據庫表中的字段--對應的實體類
他與數據庫表一一對應,用于持久化數據
DTO
接受前端的傳遞的數據
DTO(Data Transfer Object,數據傳輸對象),通常是輕量級的,只包含需要傳輸的數據(只傳遞需要的數據,比如登錄人,登錄密碼(對應的數據庫的ID,我們不去傳遞)
VO
VO(View Object 視圖對象),用于在展示層顯示數據,通常是將表示數據的實體對象中的一部分屬性進行選擇性的組合形成一個新的對象,目的是為了滿足展示層數據要求的特定數據結構。 ? ? ?(比如新增或者刪除數據,我們不會把其中的更新時間,更新人放出來)
區分的目的:
提高代碼可讀性和可維護性:每個對象都有特定的職責,使得代碼結構更加清晰,每個對象統一命名,項目變得更加一致和可預測
解耦:Entity,DTO,VO的劃分降低了各個部分的耦合度,修改某一層邏輯或數據時減少對其他層的影響
優化性能:不同的對象,比如DTO和VO可以根據自身功能和當前需求,進行裁剪和拼裝,合理利用網絡傳輸資源,提高性能
但是假如我們劃分過細的話
增加復雜性:過多的概念劃分可能導致開發者需要花費更多時間去理解每個對象的作用和用途,增加了學習和理解的難度,導致開發的效率降低,甚至引入不必要的錯誤。
過度設計/影響性能:過度設計意味著簡單功能時引入了過多抽象和復雜性,增加開發成本,和對象轉化與數據處理直接有性能開銷(比如DTO需要轉化成實體)
維護成本上升:對象劃分的增多,對象數量增加,導致代碼庫的膨脹
耦合度增加:對象劃分為了降低耦合度,過細劃分導致耦合上升,因為創建過多的中間層或者轉化層來處理對象之間不同的交互,導致系統各個部分之間的依賴關系
RouterLink組件
生成可點擊的連接,用于頁面之間的跳轉,RouterLink通過其to屬性指定鏈接的目標地址,當用戶點擊這些鏈接時候,路由會自動切換對應的頁面
RouterView組件
用于根據當前路由狀態動態渲染匹配的組件,在單頁應用中,URL發生變化時候,RouterView會根據當前路由狀態自動渲染對應組件,這意味著無論導航到哪里,RouterView都會顯示與當前路由相匹配的組件內容
VUE規則
assets目錄結構:用于存儲項目中需要導入的靜態資源:如圖片
views:views目錄通常存放安歇路由直接相關的頁面級別的組件
components:components目錄通常用于存放那些可復用的,小巧的,功能單一的組件,組件通常不會被直接渲染到路由對應頁面上
router:存放Vue Router的配置文件
項目工程名:全部小寫方式
目錄和文件夾:全部小寫,短橫線分隔
js文件:全部小寫,優先選擇單個單詞命名
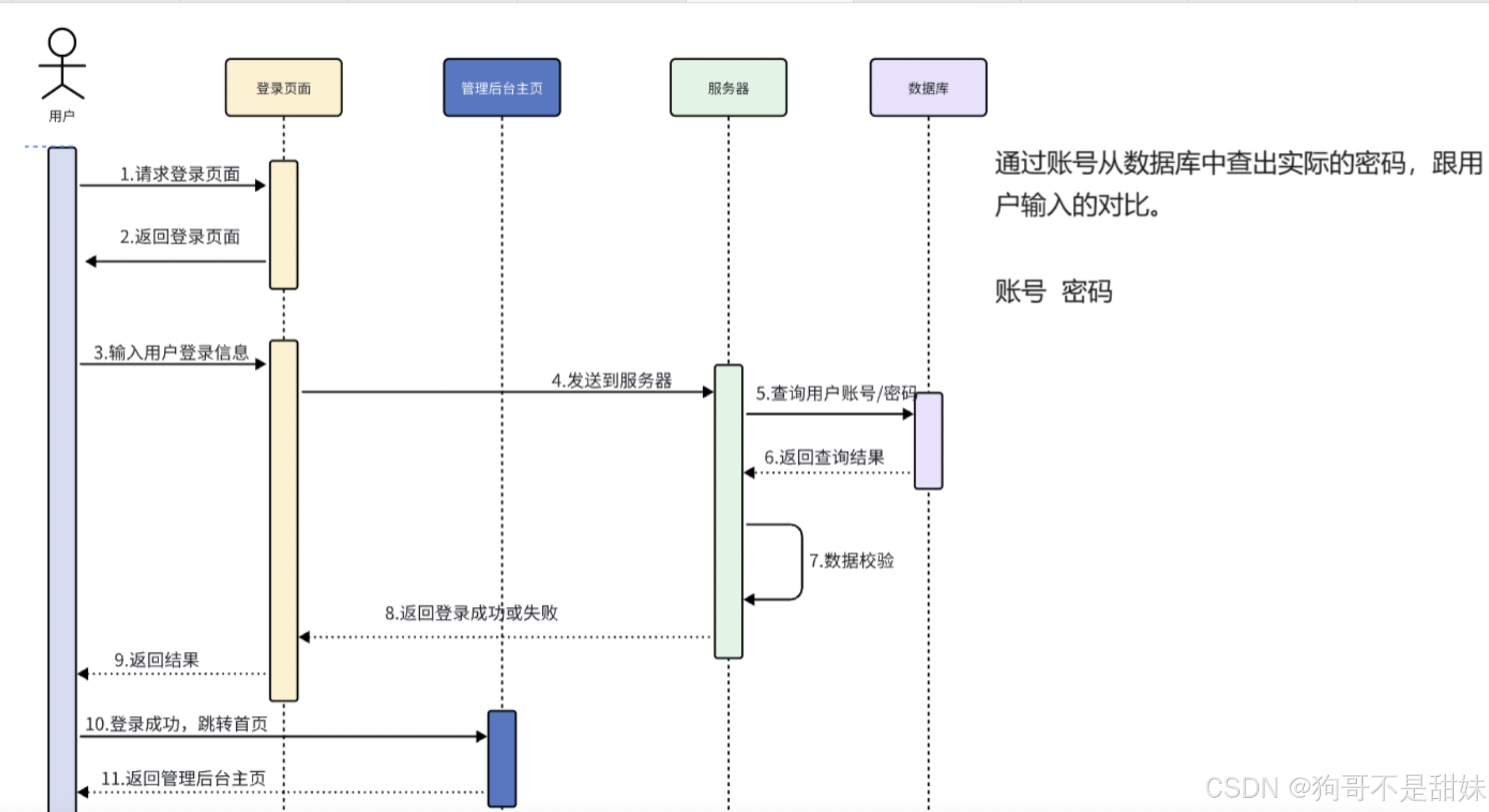
1.前端接受用戶輸入信息(賬號,密碼)
2.攜帶用戶輸入的信息,向后端發起登錄請求
3.后端接收到前端的請求,執行登錄相關的業務邏輯
4.后端執行完相關的邏輯之后,將結果返回前端
5.前端接受到后端返回的結果之后,如果登錄成功,則跳轉到后臺管理頁面,并且前端需要將后端返回到token存儲起來,假如登錄失敗,前端將后端返回錯誤提示,展示給用戶。
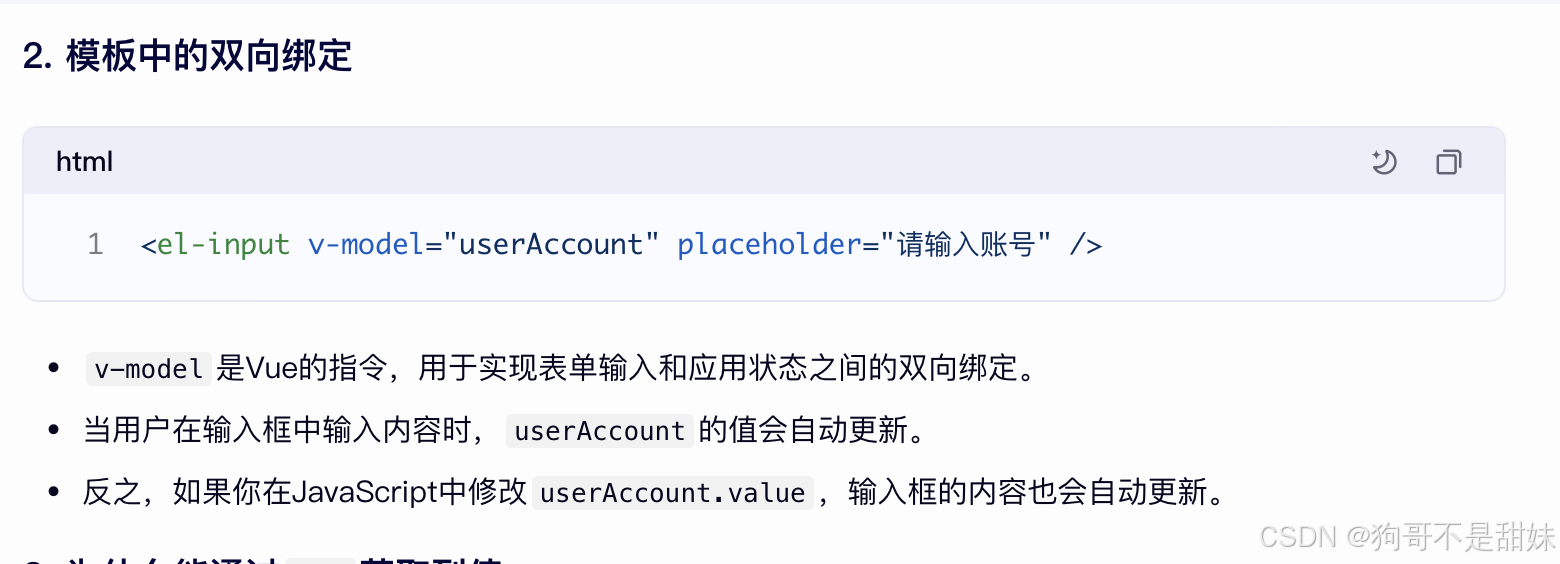
v-model是Vue中用于輸入元素和Vue實例數據直接創建雙向數據綁定的指令,他使得數據和DOM之間能夠相互同步,當輸入框的內容發生變化時,Vue實例中的數據也會自動更新,反之,當Vue實例中的數據發生變化時,輸入框內容也會相應更新。
Axios(代替ajax)

1.前端攜帶token向后端發起請求
2.收到后端響應后,前端應該根據后端返回的結果進行一個判斷,假如成功,從響應結果中獲取用戶昵稱并且展示,如果失敗,將失敗的原因展示給用戶
響應式數據:當數據變化時候,可以自動更新和通知與之相關的視圖和組件
前端發送請求時候,需要攜帶token.,退出登錄時候,怎么讓token認證失敗呢?我可以刪除token,或者加加減減,反正只要不相同就行(把redis用戶睡覺刪除掉就行,讓token認證失敗)(失敗就保持登錄狀態,停留當前頁面,假如成功,就去執行后續流程)
前端清除存儲的token,返回登錄頁面
1.點擊退出登錄,彈出確認框
2.攜帶者token(請求頭中)向后端發起請求
3.前端接受到后端的響應結果之后,如果成功,清除掉cookie存儲token,并且跳轉回登錄頁面,如果失敗,將失敗原因提示給用戶,停留給當前頁面
1.非登錄狀態,訪問除了登錄頁以外的頁面,自動跳轉回登錄頁
2.已經登錄過,并且token沒有過期,此時訪問登錄頁面應該自動跳轉到后臺管理頁面
B端功能(定義接口請求方式Get(查詢),Post(新增),Put(修改),Delete(刪除)
登錄模塊
題庫管理-難度,題目搜索,支持分頁等 -考慮表結構等設計(
題目添加
1.我們登錄后需要點擊題目管理
2.點擊添加題目之后,彈出抽屜
3.添加一些選項,比如難度,標題,內容,默認代碼塊,main函數,輸入相關題目信息,點擊發布
4.向后端發起添加題目的請求(將用戶攜帶的題目信息作為參數發送添加題目的請求)
5.后端收到請求之后,對請求參數進行處理
6.對數據存儲起來,往mysql數據庫里面存儲等
7.后端需要將題目添加的結果返回給前端
8.前端收到后端的響應(如果成功,提示用戶添加成功,并且在列表中,將新增的題目展示在第一個,如果失敗,把失敗原因提示給用戶)
競賽管理 (攜帶token向后端發送請求,發送后請求之后,等待后端處理,前端等待處理,直到前端接受到數據,根據響應結果,如果成功,將題目列表數據展示在頁面中,如果失敗,向用戶提示錯誤信息,頁面保持原樣即可
題目編輯功能:
1.找到要編輯的題目,找到之后,點擊編輯按鈕,
2.攜帶著題目id向后端發起題目詳情的請求
3.后端接受到題目詳情的請求之后,根據題目查詢出題目詳情(從數據庫中查詢出來),并且將查詢結果返回給前端展示(如果查詢失敗,編輯題目流程結束)
4.根據展示出來的題目詳情和對于題目的修改需要,對題目的具體修改,點擊發布操作
5.前端攜帶著題目id,和修改后的內容,向后端發起編輯題目的請求。
6.后端收到編輯請求之后,根據題目id查到對應的題目,在根據修改后的題目內容對題目進行修改。并且將修改后的結果返回給前端.
7.前端接收到后端返回的響應結果之后,成功->提示用戶編輯成功,并且再去查看信息時候應該是修改之后的,失敗則返回失敗原因.
題目刪除:
1.找到要刪除的題目,并且點擊刪除按鈕
2.前端攜帶者題目id向后端發起刪除題目的請求
3.后端接收到請求之后,根據題目id刪除題目,并將刪除的結果返回給前端(成功或者失敗)
4.前端接受后端響應之后,如果成功,提示用戶刪除成功,將刪除的題目從題目列表刪除 假如失敗,提示用戶失敗原因
競賽列表功能:
1.用戶切換到競賽管理
2.前端攜帶著相關參數發起獲取競賽列表的請求
3.后端收到請求之后,根據請求參數,從數據庫中查詢符合條件的競賽.并將查詢結果返回給前端
4.前端接收到后端返回的響應之后,如果成功-把查詢到的列表數據展示到頁面當中
如果失敗,提示用戶失敗的原因
題目新增:
一.不包含題目的新增,我可以先不去包含題目,先去考慮別的,那么此時我們不予許他發布就行,就像是這個csdn一樣(不允許發布)
1.前端帶著用戶輸入的競賽基本信息,向后端發起添加競賽請求,
2.后端接收到請求之后,對相關參數進行處理,將競賽信息存入數據庫,并且將添加結果返回前端(成功/失敗)
3.前端接收到后端的響應之后,如果成功,提示用戶添加成功,并且競賽列表中能看到新增的競賽,如果失敗,提示用戶失敗的原因。
二.包含題目新增 =新增不包含題目都競賽+為這個競賽提供題目(假如我們不保存競賽,就可以添加題目(假如用戶添加了100+題目,然后一個刷新(此時全毀了就,所以不能讓他直接點擊添加按鈕
1.先走上面那三步(不包含題目的新增),
2.點擊添加題目按鈕,獲取題目列表的請求。(請求之前實現的題目列表接口即可)
3.從題目列表中,選擇題目,點擊提交按鈕,攜帶著競賽id和題目id發起為競賽添加題目的請求
4.后端收到請求后,處理相關參數
競賽編輯功能:競賽詳情功能+
競賽詳情功能:
1.攜帶著競賽id向后端發起獲取競賽詳情的請求的
2.后端接收到請求之后,根據競賽id從數據庫中查詢競賽詳情信息,并將查詢結果返回給前端
3.前端接收到后端響應之后,如果成功,頁面展示競賽詳情信息,如果失敗,提示用戶失敗原因。
競賽編輯功能:競賽詳情功能+競賽基本信息進行編輯(可以不去編輯)+競賽題目信息進行編輯(又可能不去編輯)
競賽基本信息編輯:(針對輸入框或者選擇框進行編輯)
1.輸入或者選擇更新后端的數據,點擊保存,前端攜帶著更新后的數據向后端發起編輯競賽的基本信息的請求,
2.后端接收到請求之后,根據競賽id找到要編輯的競賽,根據請求參數對競賽數據進行更新,并且將更新結果要同步到數據庫中,并且將編輯結果返回前端。
3.前端接收到后端響應之后,
如果成功,展示競賽編輯后到信息,并且返回題目列表是看到的題目信息也是更新后得。如果失敗,則提示用戶失敗原因,比拿給所展示的信息還是之前題目的信息。
競賽中題目信息的編輯功能:競賽中題目添加功能+競賽中題目刪除功能
競賽中題目刪除功能:
1.找到競賽中要刪除的題目,點擊刪除按鈕,前端向后端發起刪除競賽中題目的請求,攜帶(參數-看后端要什么你傳什么,刪除的話應該是id)
2.后端接收到請求之后,查出要刪除的競賽,并且判斷是否能夠進行操作,如果不能操作,返回前端不能操作的原因,如果能操作,開始進行競賽中的題目刪除操作。根據題目id找到要被刪除的題目進行刪除操作。刪除數據庫中對應的競賽中的題目數據。
3.前端接收響應,如果成功,競賽題目列表中對應的題目將消失
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?如果失敗,提示失敗原因。
競賽刪除=刪除競賽的基本信息(tb_exam)+刪除競賽對應的題目信息(tb_exam_question)
1.找到要刪除的競賽,點擊刪除按鈕,前端向后端id發起刪除競賽請求,
2.后端接收到請求之后,根據競賽id(先去判斷競賽是否存在。競賽是否開賽),刪除競賽基本信心(tb_exam)和競賽題目信息(tb_exam_question)并且將刪除結果返回給前端
3.前端接收到響應之后,如果成功競賽列表中不在返回該競賽,如果失敗返回失敗原因。
發布競賽:(前提,競賽是存在的,競賽中存在題目)(對于競賽發布的話,后端怎么做?)
1.添加競賽頁面(基本信息保存好,在滿足發布競賽前提之后,點擊發布競賽,前端向后端發起請求(攜帶競賽id))
2.后端接收到請求之后,根據競賽id判斷前提是否成立,如果不成立將不成立的原因發布給前端,如果成立,競賽的狀態字段從0改為1,并且同步到數據庫,再將修改結果返回給前端
3.前端接收到后端響應之后,如果失敗,展示失敗原因,如果成功,挑戰會列表頁,當前的狀態變為已發布,C端競賽要能找到已發布的競賽
競賽撤銷發布:(競賽撤銷前提,1.競賽存在,2.競賽還沒有開始)
1.找到要撤銷發布的競賽,點擊撤銷發布按鈕,前端攜帶著競賽id向后端發起請求。
2.后端接收到請求之后,根據競賽id撤銷對應的競賽是否成立,如果不成立,返回前端不成立的原因。如果成立,將競賽狀態字段再從0變成1,再將結果返回給前端,前端接收到響應之后,如果失敗,顯示失敗原因,如果成功,B端競賽列表中當前競賽狀態,變為未發布,當前競賽C端競賽列表中消失。
)
C端用戶管理(
1.前端攜帶相應的參數向后端發起獲取用戶列表的請求。
2.后端接收前端的請求之后,將參數轉換為查詢條件,從數據中查出符合查詢條件的數據,并且將查詢結果返回給前端(成功/失敗)
修改用戶狀態(拉黑/解禁)
1.前端攜帶參數(userId,status)向后端發起修改用戶狀態的請求。
2.后端接收到請求之后,從數據庫中查詢出要修改狀態的用戶,然后將其狀態進行修改,并且將更新后的狀態同步的到數據庫中,再向前端返回更新結果(成功/失敗)
3.前端接收到后端的響應之后,如果失敗,用戶保持原狀態不變,將失敗原因給用戶
如果成功,用戶狀態變為修改之后的狀態,如果是將用戶拉黑,要限制用戶的操作
如果解禁,那么就去放開之前限制用戶操作的功能的使用權限。
)
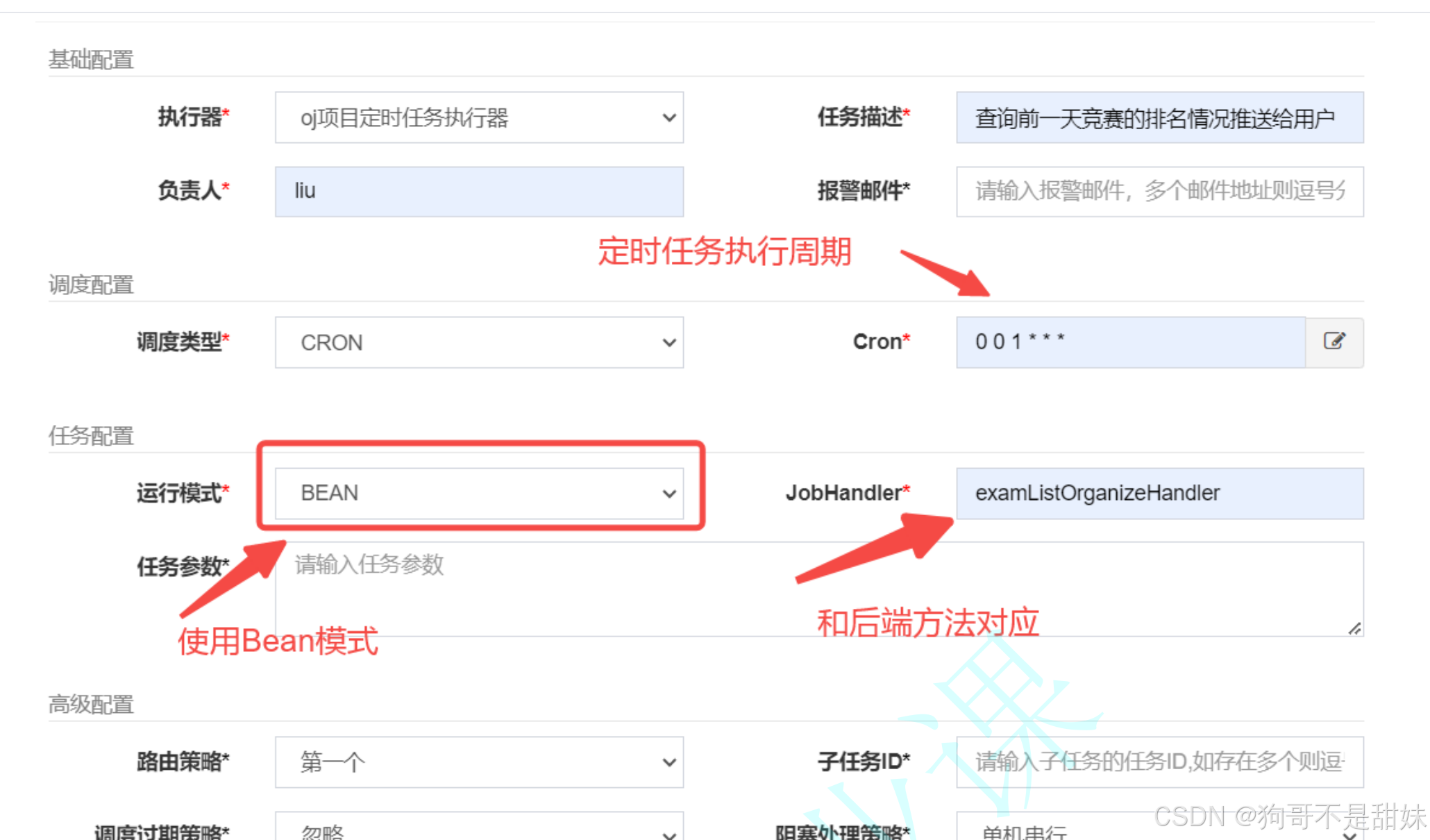
定時任務管理
PageHelper
PageHelper會自動解析你執行的SQL語句,并根據你提供的頁碼和每頁顯示的記錄數,自動添加分頁相關的SQL片段,從而返回正確的分頁結果,無需在SQL語句中手動編寫復雜的分頁邏輯
配置簡單:在SpringBoot項目中國添加依賴,簡單配置即可使用
易于集成:無論你是注解方式還是XML映射方式,都可以方便的使用PageHelper
性能優化:使用物理分頁,比起內存分頁,可以減少內存消耗提高查詢性能
Vue聲明周期函數
每個VUE組件實例創建時候,都需要經歷一系列初始化步驟,如設置好數據偵聽,編譯模版,掛載實例到DOM,以及數據改變時,更新DOM等。(讓開發者有特定機會執行自己的代碼),在這個過程中他也會一直運行:被稱為生命周期的函數
在此過程中他會運行被稱為生命周期鉤子的函數
創建階段:
setup()組件初始化階段的核心函數,用于設置組件的初始狀態,計算屬性等
掛載階段:
onBeforeMount:在組件掛載之前調用,這個鉤子可以做一些準備工作
onMounted:在組件掛載到DOM后調用,在這個鉤子里,你可以訪問和操作DOM元素,如初始化第三方庫,添加事件監聽器等
更新階段
onBeforeUpdate:Vue更新DOM之前調用,可以在這個鉤子里執行一些結算或者邏輯判斷
onUpdated:在組件DOM更新之后調用,可以在鉤子里執行基于更新DOM的操作,如重新綁定事件監聽器
卸載階段
onBeforeUnmount:在組件即將卸載之前調用,用來清除定時器,取消異步請求,移除事件監聽器等。
C端功能流程
C端登錄/注冊功能,分情況討論,新用戶/老用戶,
老用戶:
1.正常輸入手機號,點擊獲取驗證碼,前端向后端發起驗證請求,
2.后端接收到請求之后,隨機生成一個驗證碼,并且將驗證碼發送到用戶的手機上,
3.用戶收到驗證碼之后,在驗證碼的輸入框中輸入收到的驗證碼,點擊登錄/注冊按鈕,發起登錄/注冊請求,搜索一下庫里面,根據手機號看是新還是老用戶,假如是老用戶,執行登錄邏輯,并且將登錄是否成功返回前端
4.后端接收到請求之后,根據用戶的手機號判斷用戶是新用戶還是老用戶,如果是老用戶的話,直接執行登錄邏輯,并將登錄是否成功返回給前端。
5.前端接收到響應,如果成功,跳轉到系統首頁(系統右上角會獲取他的昵稱頭像啥的)
如果失敗,停留當前登錄頁
驗證碼是否能放到數據庫里面呢?假如很多人登錄會很多次都注冊里面,導致服務器壓力很大,驗證碼一般有有效時間
C端題目列表功能(
競賽列表:引入redis-(假如redis+數據庫都沒有數據,假如redis沒有,數據庫有,那么把數據庫同步到redis里面
數據結構:list ? ? ? ? ?key? ? ? ?? ? value
//新用戶,執行注冊邏輯, //先完成驗證碼的比對,通過手機號拿到key,然后比對驗證碼,如果比對成功,往系統中新增一個用戶(向數據庫的用戶表插入一條數據即可)設計一個開關:
如果是投入生產使用的話,我們把開關打開,打開后的邏輯,就是生成隨機驗證碼,并且將驗證碼發送給用戶手機上,假如測試,把開關關閉,生成一個固定的驗證碼123456,不把驗證碼發送出去
阿里云密鑰(阿里云短信登錄)
AccessKey和Access Secret是我們訪問阿里云API的密鑰,具有該賬戶的權限,需要我們妥善保管。?
核心是使用redis來模擬
我們會先對用戶,設置一個驗證碼的接口,我們在redis中統計這個設置驗證碼的次數,然后對你的要求進行比較,看多還是少(第一個多少次20次,第二天計數清0,(code,time)c:t:手機號來存儲(次數),你登錄之后,我就使用(phone,code)p:c:存code,第一次就設置有效時間,需要去動態計算)
C端功能和B端功能使用的群體也不同,C端是給具體的用戶,
sudo chmod -R 777 ? /文件名/oj-fe-c/src ? ? ?
需要兩個頁面:一個登錄注冊頁,一個是首頁
router配置文件中,增加新頁面的路由配置信息
view目錄下,創建兩個頁面級.vue (Login.vue \Home.vue)
獲取競賽列表不同:
展示不同(前端處理)
每個競賽展示的數據不同,C端的更少一些,(只需要調整查詢sql)
搜索條件不同+默認加上是否發布的搜索條件(只需要調整查詢sql)
C端支持游客使用,B端必須先完成登錄(網關配置跳過身份認證)
Jmeter
Apache Jmeter是Apache組織開發的基于Java的壓力測試工具,對于軟件做壓力測試,
可以測試靜態文件,Java小程序,CGI腳本,Java對象
100萬個數據
線程數1000,examList(服務器iP,服務器ip),對數據庫接口的地址,和參數
測試結果說明:
Summary:表示該時間點新增啦多少個請求
in:該時間點內發生的請求數
如:summary +1000 in 00:00:30表示過去30秒內新增了100個請求。? ? ?
5.9/s每秒處理5.9個請求,就是qps(當前性能特別差啦)Error:錯誤請求占用總請求的概率,因為每次壓測的結果不同,受限于場外原因,所有就要考慮一下改啥的(從數據庫里面拿)
加了redis之后,到了300qps,提升差不多60倍
什么時候將C端競賽數據存儲到redis中,特點都是已經發布的競賽,在發布競賽的時候,將C端端競賽數據存儲到redis里,取消發布還需要將C端端競賽數據從redis當中移除,
選擇怎樣的數據結構存儲C端的頁面。Redis的list可以維持他的插入順序,還可以進行分頁。
選擇list:使用兩個list 一個使用未完賽,一個使用歷史比賽,選擇兩個list結構,分別存儲未完賽的競賽列表和歷史競賽列表。
會重復存儲數據,所以不能這么存儲(假如存儲基本信息的話)
key是什么,value是什么
key : ? 競賽:歷史:列表 e:h:l: ? ?value:競賽:未完賽:列表 e:t:l (t:表示還有時間)
value: 競賽基本信息(對象存儲->json形式) ? ? ? ? ? ?->根據value的數據能夠查到下面的信息是最好的(改變方式,存儲examId,我只需要根據這個查找下面的examId )
如何改變
將競賽的基本信息只存儲一份-數據結構
String ?key: ? ? ? value
? ? ? ? ? key盡可能知道我們存的是什么 e:d:examId(詳情描述detail,區分開不同競賽)
value(存儲競賽的基本信息)
什么時候將C端競賽數據存儲到redis中,
都是已經發布的競賽,在發布競賽的時候,應該將C端端競賽數據存儲到redis里,取消發布時候,還需要將C端端競賽數據從redis中移除
如果當前競賽已經結束,就不能再發布了
未完賽列表的競賽如果結束了,怎么從未完賽列表移入到歷史競賽列表。
1.競賽要先結束,當前時間假如小于結束時間。寫一個移入方法,要去長期的反復的去執行競賽移動的方法,(定時任務->按照一定頻率去反復的操作這個方法,如何定義呢?多少頻率:給每個競賽去搞一個定時任務,(那能否一個定時任務解決呢?)每天凌晨1:00去執行一次歷史任務,把未完賽的移入到完賽的(但是細致一想還會有一點點問題:今天結束的競賽:下午4:00就結束了,但是細想一下,今天的任務,也不能叫歷史任務)或者每12h執行一次,但是貌似你的競賽中午去清也不是很好(12-1h ? ?12-1)兩個這樣貌似還可以)
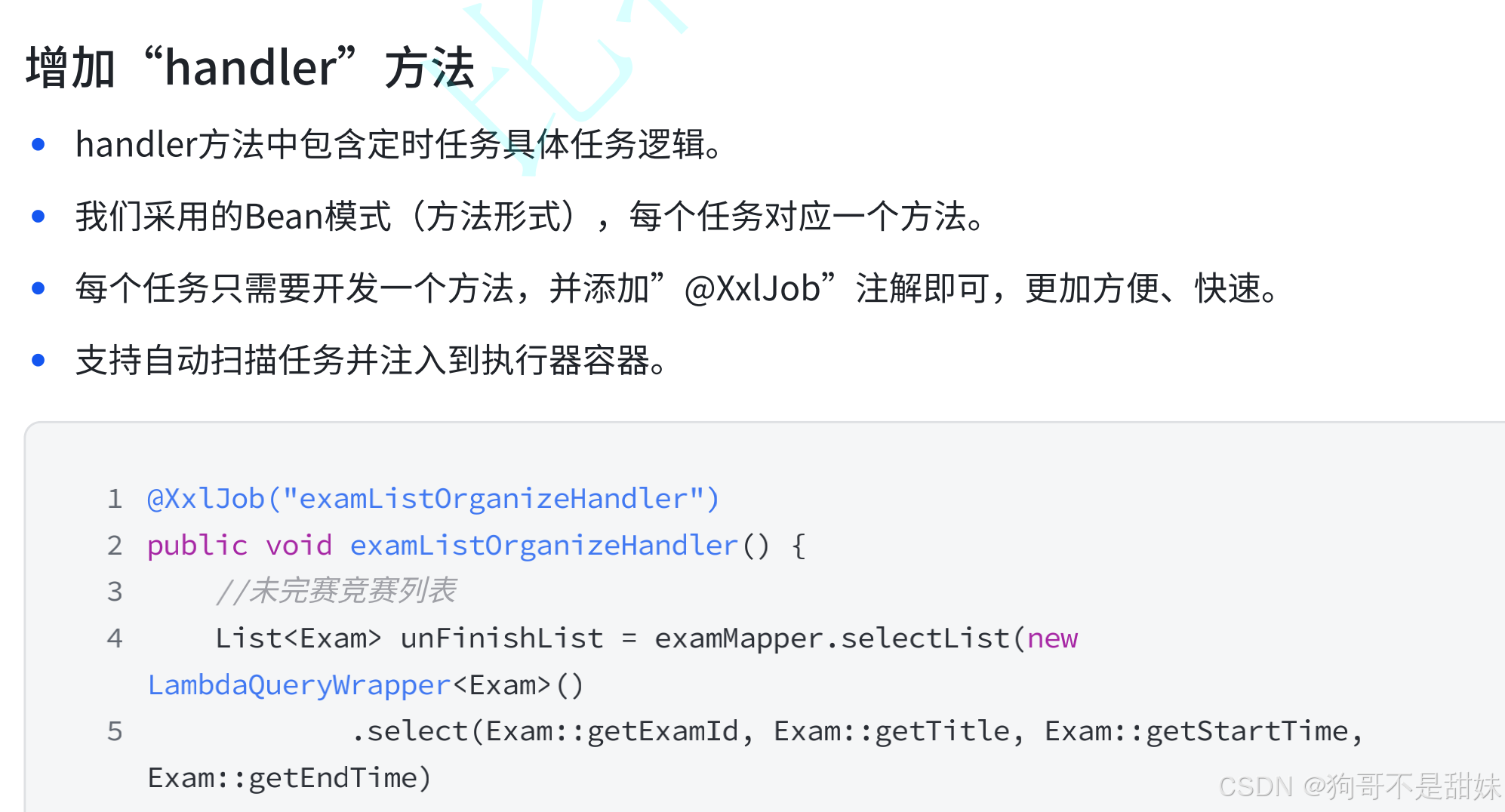
因此引入xxl-job
XXL-job
是一個分布式任務調度平臺,核心設計目標是開發迅速,學習簡單,輕量級
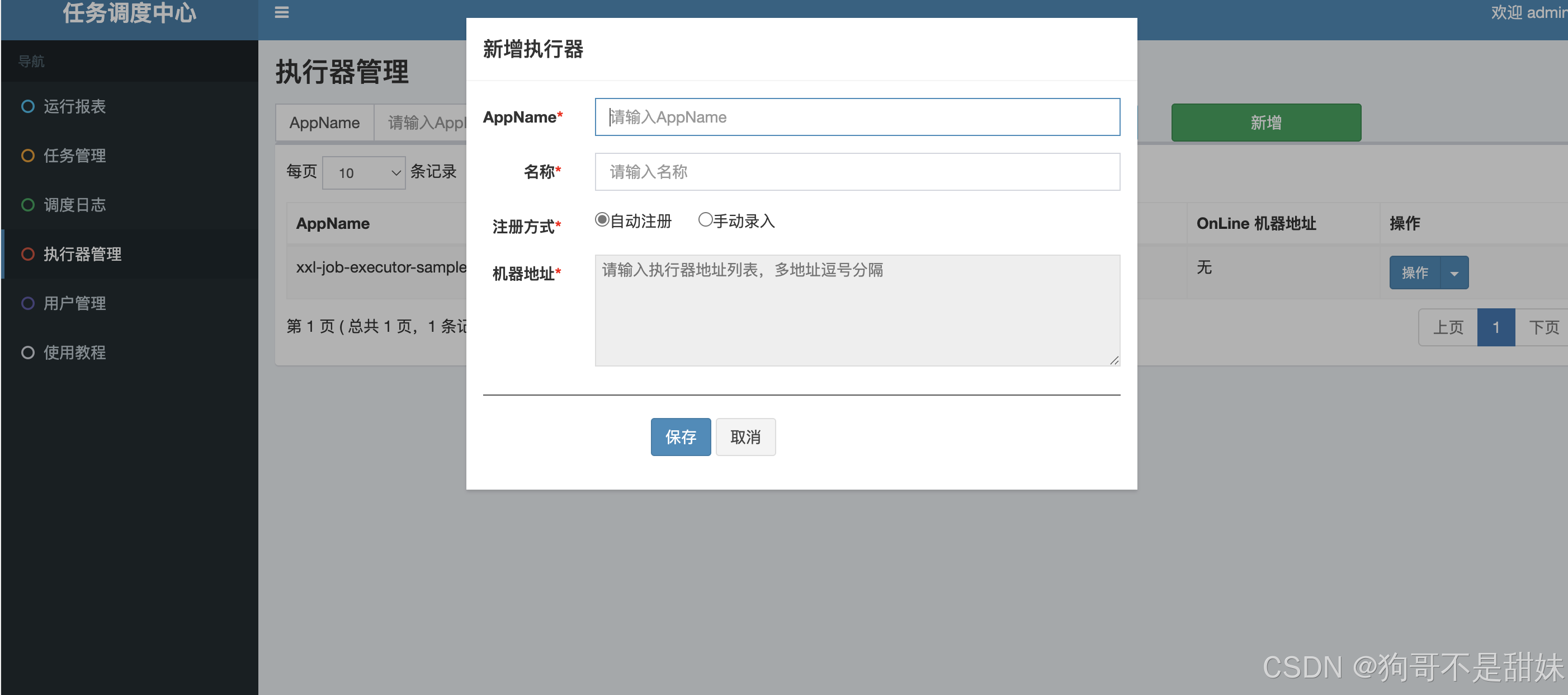
appName長度有限制,執行器在xxl-job里面的唯一標識,要和后臺對應一點,名稱沒要求,就是自己知道是干嘛的就行

競賽報名功能
比賽:已經報名,已經開賽,哪些用戶報名需要記錄下來,報名功能最相關的就是答題頁面,競賽排名功能:比賽已經結束,比賽統計時候只統計對象,是報名參加這個競賽的用戶,
我的競賽功能:當前用戶已經報名的競賽,哪些用戶報名我們需要記錄,
競賽列表功能:競賽可不可以報名的按鈕標簽啥的,需要從是否報名來判斷。
用戶的競賽報名信息,需要存儲到數據庫中,為了查詢到性能,還需要放到redis,這個是我們競賽列表
redis存儲結構 存儲信息 數據結構 key value 未完賽競賽列表 List e:t:l examId 歷史競賽列表 List e:h:l examId 競賽詳情信息 List e:d:examId JSON存儲競賽詳情但是我的競賽列表的緩存,應該不止一個,每個用戶都有一個,所以應該
key: ? ?u:e:l:用戶id? ? ? ? ? ? (user exam list ? 用戶的競賽列表,)
用戶競賽列表 List u:e:l:用戶id examId 競賽詳情信息 String e:d:examID JSON結構存儲競賽詳情先登錄,登錄之后在競賽列表找到要報名的競賽,點擊報名競賽按鈕,前端攜帶競賽id和token想后端發送請求
后端接收請求,需要先判斷是否符合報名條件 如果滿足條件,將用戶的報名信息存儲到數據庫和redis,
報名條件:1.用戶處于登錄狀態,2.不能報名不存在的比賽,3.不能重復報名,4.已經開賽的競賽不能再進行報名
前端接收到后端響應之后,根據返回結果提示用戶報名成功或者失敗
TransmittableThreadLocal
競賽報名后端開發:因為我在開始的時候,我就以及把token解析后,已經獲取來他的用戶ID,此時就給他存起來,那么后面我就不用來回的去解析啥的了,我們要存一個地方,首選redis,但是我的userID屬于哪個用戶(他是作為一個value),ThreadLocal線程本地變量,為每個線程變量,擁有一個獨立的副本,對于其他線程不受影響(useId 用userId存儲時候,我既要存他,還要去區分不同的用戶),相當于每個線程里面存儲的都是一個用戶id,就會解決掉了,把解析的id放到threadLocal,但是原生的ThreadLocal,處理異步任務,異步任務在主線程中,又可能開啟一些子線程,這樣會變成異步的,所以解決的話,使用阿里給的一個TransmittableThreadLocal.導入對應的依賴
我的競賽功能
已開賽(標簽) ?競賽開始時間<當前時間 ? ?前端+后端(返回當前用戶是否報名這個競賽)
? ? ? ? ? ? ? ? ? ? ? ? 當前用戶未報名此競賽
已報名(標簽):競賽開始時間>檔期啊時間,用戶之前報名了這個競賽
競賽練習和查看排名:應該是在歷史的競賽里面才能看到
開始答題:競賽開始時間<當前時間,競賽結束時間>當前時間,用戶已經報名參加了這個競賽
報名參賽:競賽開始時間>當前時間(未開賽)用戶之前未報名這個競賽
?題目詳情緩存 ?(引入ES)
string 類型 ? ? ?key:q:d:questionId ? value:JSON題目詳情 ? ? ?
搜索方式十分難受啊 比如合并兩個有序數組,我搜索這道題目,有多種組合,這樣就很麻煩,我查找后,進行一個過濾,使用java,原生方式,通過for循環從整個列表都過濾一遍,然后返回
2.redis把對應的關鍵字存起來,但是關鍵字的組合過多,而且關鍵字又可能會重復,你假如添加一個競賽,關鍵字對應的里面有什么呢?
value:questionId.(而且拿中文當key有點抽象)
一般使用ElasticSearch,這個用來去解決模糊查詢,(開源分布式搜索引擎,獨特能力,近乎實時的數據搜索能力,全文檢索,模糊查詢,數據分析)
基本使用:
正排索引:
一種索引機制,通常按照文檔的ID或者其他唯一標識符進行排序,正排索引中,索引的鍵是文檔標識符,索引的值是文檔的詳細信息,當你知道一個文檔ID時候,可以通過正排索引迅速找到該文檔的全部信息,
主鍵 ? 數據
1 ? ? ?白蛇
2 ? ? ?白蛇喜歡
3 ? ? ?白蛇吃白狐
4 ? ? ?白蛇猴利謝
5 ? ? ?白蛇大舌頭
倒排索引:按照文檔的(關鍵詞)來組織,倒排索引中,索引的鍵是文檔集合中出現的每個獨特詞匯和關鍵詞,索引的值包含該關鍵詞的所有文檔標識符,以及可選的額外信息。(索引結構匹配模糊搜索)
索引關鍵字 ? ?對應電影序號
白蛇 ? ? ? ? ? ? ? ? 12345
喜歡 ? ? ? ? ? ? ? ? ? 2
吃 ? ? ? ? ? ? ? ? ? ? ?3
大舌頭 ? ? ? ? ? ? ?5
基本概念
MYSQL ElasticSearch 數據庫: DataBase index(索引) 表 : Table Type(類型) 數據行: row Document(文檔) 數據列:column Field(字段) 模式:Schema Mapping(映射)index:具有相同結構的文檔集合,如同數據庫一樣,一個集群可以創建多個索引,如客戶信息索引等,可以給每個索引創建數據結構,索引命名要求全部使用小寫(建立索引,搜索,更新,刪除操作)都需要用到索引名稱(6.0之后下降到相當于數據庫表的級別)
type:在索引內的邏輯細分,但是6.0后版本廢棄。
Document:文檔,相當于每個數據.可以包含多個字段,每個字段包含多個字段,可以是文本,數字,日期等類型。
Field:文檔中的一個元素或者屬性,每個字段都有一個數據類型,如字符串,整數,日期等
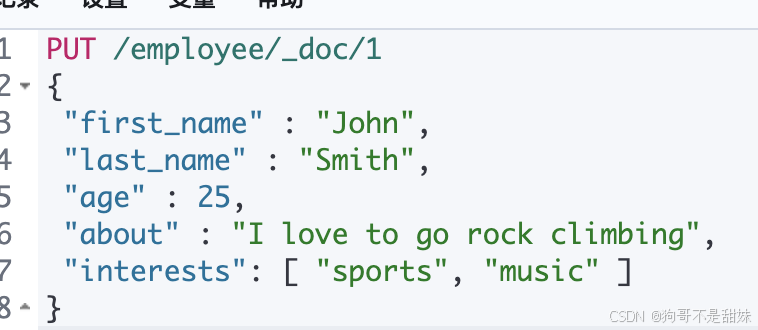
Mapping:ES中很重要的內容,類似傳統關系型數據中的table的schema(定義數據庫的數據如何組織的,包括表的結構,字段的數據類型,鍵的設置(如外鍵,主鍵等),用于定義一個索引等數據結構,在es中,我們手動創建mapping,也采用默認創建方式,默認配置下,ES可以根據插入的數據自動的創建mapping
比如這個命令,他的要求不是十分嚴格,所以employee就相當于是數據庫(自動幫你創建了,因為你寫的很清楚,在xx目錄啥的,doc就是document)

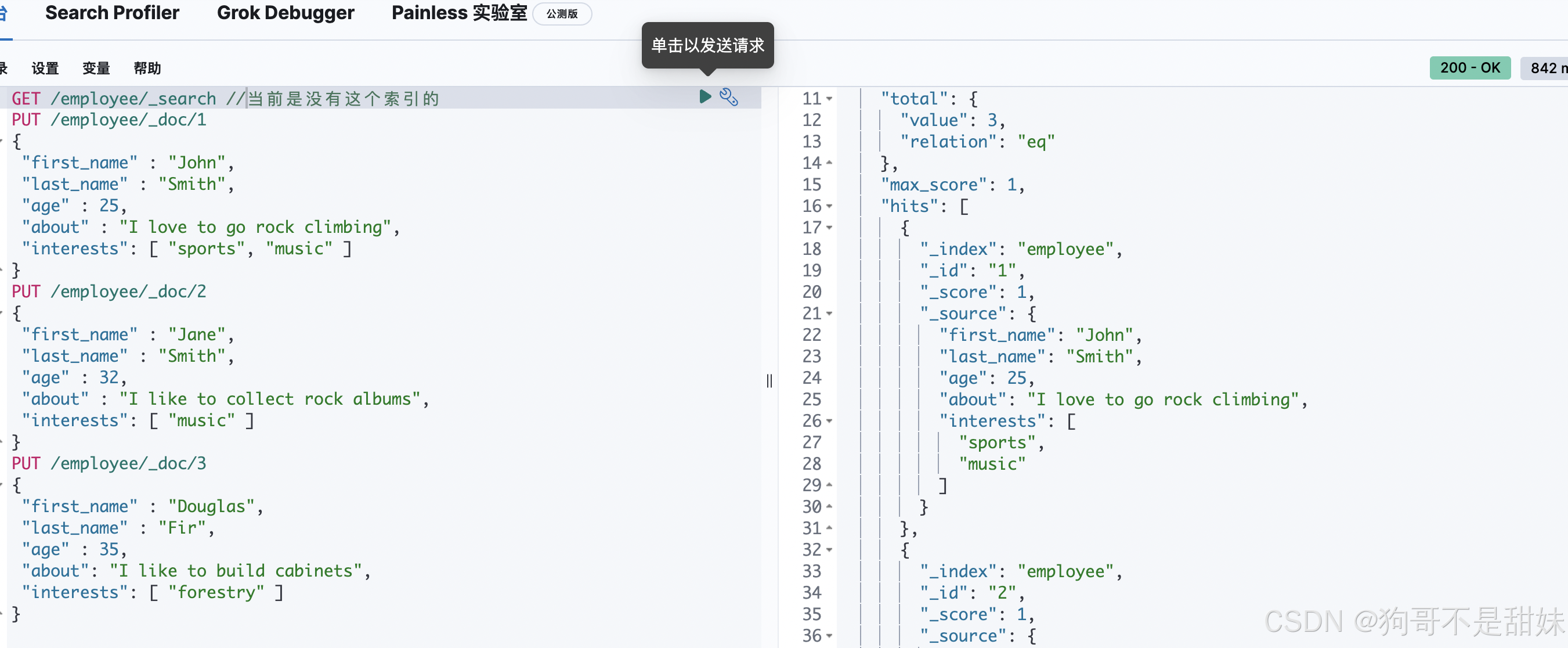
修改
1 POST /employee/_update/3 2 { 3 "doc" : { 4 "last_name" : "mark" 5 } 6 }

題目列表:
先查es:如果能查到數據->前端,如果查不到,再查mysql,數據同步給es,并且將查到的數據返回前端,如果數據庫查不到,返回給前端空。
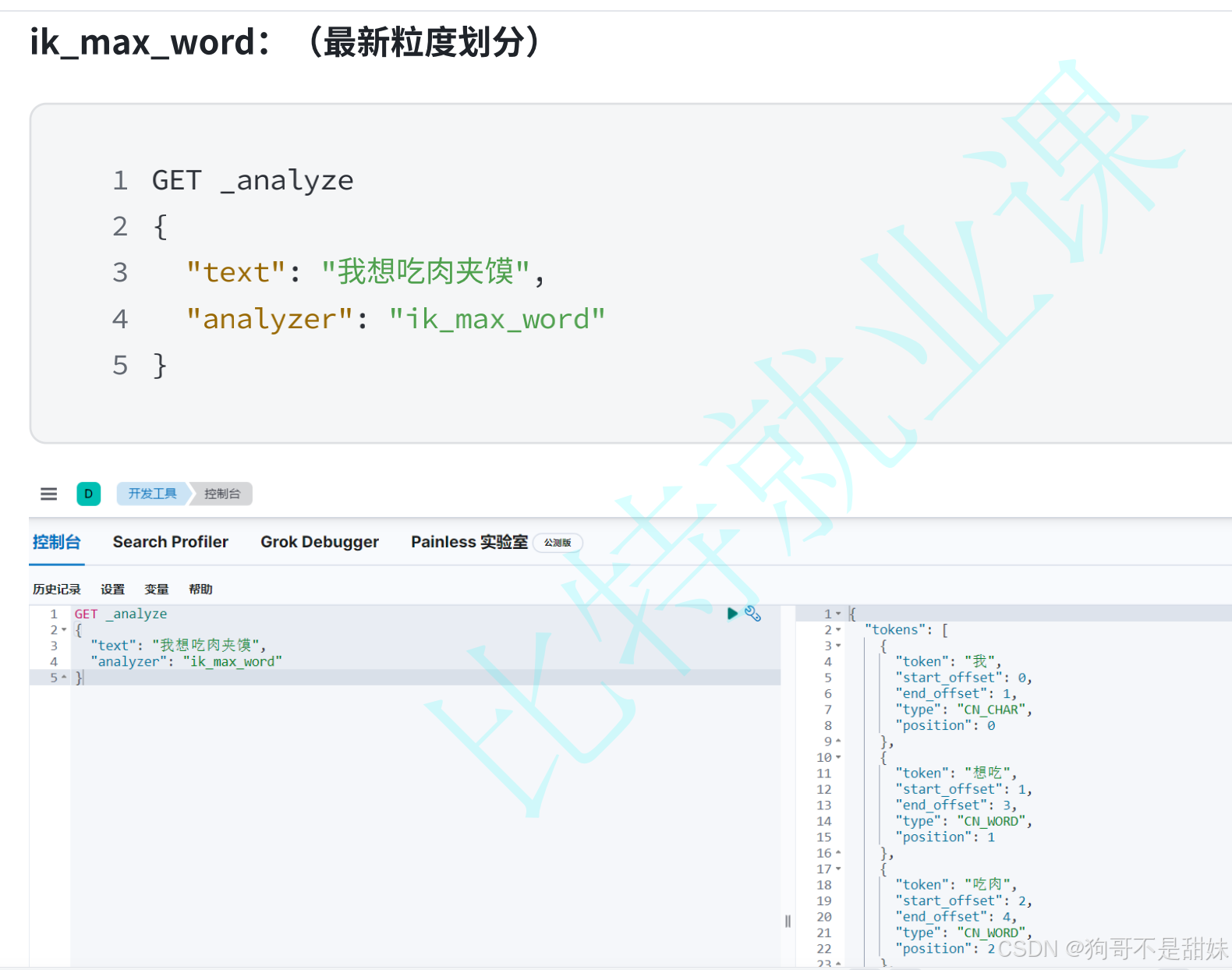
IK分詞器,分為兩塊,一個是ik_smart 和ik_slow
smart盡量保持長詞,比如我想吃肉夾饃
我,想吃,肉夾饃 花合斗
ES是什么
搜索,存儲引擎,非關系型文檔數據庫
特點天生分布式,高性能,高可用,易擴展,易維護?
ES寫入提高效率
減少負分片,對Mapping屬性進行臨時去除,同時可以批量寫入
ES的全文檢索
掃描文本中每個單詞,對單詞建立索引,保存該單詞在文本的位置,以及出現的次數,假如是你的模糊匹配,必須要準確出現那個詞才行,但是這個就是他進行一個分詞之后,你想要什么都可以,比如說es快速入門,es,快速入門,這兩個作為兩個關鍵詞搜索,比如的,呢的過濾
撤銷發布:為啥一般都是發布先變成撤銷發布才可以修改(編輯啥的),因為我們搜索啥的涉及es,但是假如每個都去處理es和redis,是不是不是非常好處理,但假如我們撤銷發布,他會自動把緩存清除了,然后再去編輯啥的,就又省事了
代碼沙箱(判題功能)
判題功能:后端收到前端的請求,獲取參數,我需要知道用戶的語言選擇是啥,根據語言進行不同處理,
根據questionId從es中查詢出對應的main函數和測試用例(入參),將代碼判斷完整。查詢的時候,還需要查詢題目的時間,空間限制,難易程度
javac:將java代碼進行編譯(成功/失敗)
成功:繼續執行后續邏輯 ? (執行java)
失敗:終止邏輯,失敗原因返回前端.
java:
成功:繼續執行后續邏輯
失敗:終止邏輯,失敗原因返回前端。
題目答案的比對:上一步代碼實際輸出的結果,和測試用例中期望結果進行比對。
如果比對一致:題目作答正確,如果不一致,題目作答錯誤。返回錯誤原因給前端。
參數從main函數里面獲取
public static void main(String[]var0){
String var1=var0[0]; ? //一般來說命令行操作,Java命令行后面跟一些參數,可以從這塊獲取
sout(isValid(var1));
}
這個傳遞的參數是啥呢?,難道什么都行嗎,我們是需要插入測試用例的。
使用一個json類型的數組。輸入輸出?
input:參數(從這塊拿你的參數)
output:輸入結果(從這里檢查,預期輸出結果)
時間限制和空間限制的比對:比如代碼執行的所使用的實際的實際和空間和期望的時間和空間進行對比,如果<=期望值,說嗎符合要求,判定題目作答正確,并且結果返回前端,否則則不符合要求,判定題目作答錯誤,并且將錯誤原因返回前端
對于用戶答題結果,無論失敗還是成功,我們都應該存儲到mysql數據庫中,以供后續使用,答題結果在計算的時候,需要注意對于分值的處理(分值的計算和題目難度相關)
對了
用戶的代碼可能有點抽象
資源濫用,攻擊:比如死循環啥的,cpu,網絡,把資源都占完了,那么系統就很難保證運行的穩定性和性能
-分配有限資源,限制cpu,內存資源等資源使用
-運行數據限制,不予許用戶長時間占用資源
安全漏洞;代碼中如果存在病毒會導致系統癱瘓
-限制用戶代碼執行權限,限制文件等讀寫,限制網絡等訪問。
數據異常:用戶提交的代碼有很高權限,可以訪問我們系統里面的文件,如果敏感信息文件讓別人獲取就完了,或者往文件中寫非法的數據
-和系統運行環境隔離開,不同用戶代碼執行環境也隔離開相互干擾:多個用戶同時提交代碼,同個環境下可能互相影響
-如果發現惡意攻擊的用戶,隨時將用戶拉黑處理
使用docker,創建隔離的容器去實現代碼,包括一些權限啥的,而且宿主機隔離的很好。
通過java操作docker,引入什么服務呢?
判題的邏輯很耗時,所以我們之前專門劃分的judge服務,專門去處理判題,能提高系統的性能,可以集中資源去處理這個服務
因為friend里面有什么提交啥的好多功能,假如分開,就好操作了,而且還要維護什么es,啥的,因此,盡可能使judge性能更高,集中精力做一件事。
friend操作號所有數據,然后服務間調用judge服務就好
容器池(開始我們是一個創建容器,然后啟動容器,再去刪除容器,就像是多線程變成線程池)
來個請求,都是創建一下(如果請求大爆發,我們很有可能資源被吃滿,比如競賽,搞一個容器池)
創建一個方法,把用戶提交的代碼放到一個目錄,多個容器,不能用同一個目錄,怎么生成掛在目錄,公共的加容器名
如何存儲容器,存儲到哪里呢? 存到集合里面放到阻塞隊列BlockingQueue<String>containerQueue 初始化就ArrayBlockingQueue<>(限制數量)
為什么引入消息隊列:面對報名一個競賽的時候,報名點擊數目陡增
因此引入MQ
生產者把用戶的信息啥的傳遞給MQ MQ給消費者,讓他去拿,
用戶拉黑功能
B端把C端用戶的所有基本信息都列出來,可以進行拉黑操作,拉黑用戶的目的是限制C端用戶的行為,比如C端用戶有違法操作,惡意攻擊用戶進行拉黑
status=0 拉黑
status=1 正常
限制他報名競賽就好
checkUserStatus這個注解
這里是用了一個自定義注解結合切面類(通過ThreadLocal獲取id,然后我看你的status狀態碼),就類似于那個校驗登錄似的,假如你非法操作,我限制你報名競賽(在你報名點擊競賽之前),用戶被拉黑,我就不予許你被
因為我們要加入注解,給報名方法加上一個Before()前置通知類型的方法,然后我們會在目標方法之前執行。
引入注解
package com.bite.friend.aspect;import java.lang.annotation.*;@Target({ElementType.TYPE, ElementType.METHOD}) // 可標注在類和方法上
@Retention(RetentionPolicy.RUNTIME) // 運行時保留 //因此可以通過反射機制來讀取。
@Documented // 包含在Javadoc中
public @interface CheckUserStatus {// 這是一個標記注解,沒有定義屬性
}引入切面類
- 當調用帶有
@CheckUserStatus注解的方法時 - AOP攔截器會先執行
UserStatusCheckAspect中的before方法 - 在
before方法中去判斷是否被拉黑
package com.bite.friend.aspect;import com.bite.common.core.constants.Constants;
import com.bite.common.core.enums.ResultCode;
import com.bite.common.core.utils.ThreadLocalUtil;
import com.bite.common.security.exception.ServiceException;
import com.bite.friend.domain.user.vo.UserVO;
import com.bite.friend.manager.UserCacheManager;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;import java.util.Objects;@Aspect
@Component
public class UserStatusCheckAspect {@Autowiredprivate UserCacheManager userCacheManager;
//應該是操作某些功能之前,進行一個判斷,前置剛好合適。在報名之前去檢查,注解加到哪里,就是哪個操作之前檢查@Before(value = " @annotation(com.bite.friend.aspect.CheckUserStatus)")public void before(JoinPoint joinPoint) {//獲取當前用戶信息 statusLong userId = ThreadLocalUtil.get(Constants.USER_ID, Long.class);UserVO user = userCacheManager.getUserById(userId);if (user.getStatus() == 0) {throw new ServiceException(ResultCode.FAILED_USER_BANNED);}if (Objects.equals(user.getStatus(), Constants.FALSE)) {throw new ServiceException(ResultCode.FAILED_USER_BANNED);}}
}我的消息功能
站內信:網站內部的一種通信方式
1.用戶和用戶之間的通信(點對點)
2.管理員/系統和某個用戶之間的通信(點對點)
3.管理員/系統和某個用戶群(滿足某一條件的用戶群體)之間的通信.(點對面)
競賽結果通知消息-點對點(因為不同用戶,你當前是多少多少名)
數據庫表設計:
包含消息發送人,接收人,內容
主鍵id, 消息標題,消息接收人,發送人 ? ,消息內容 (長遠來看,假如給用戶和用戶,用戶和用戶群加上,以免因為結構不充足,造成大規模調整,第一種支持,但是用戶群就會冗余了,發送給一個用戶群,我發的消息唯一,那么我要重復好多次)
主鍵 ? ? 消息標題 ? ? 內容 ? 接收人 ? 發送人
1. ? ? ? ? ?福利信息 ? ? 內容 ? ? 1 ? ? ? ? ? 0 ?
1 ? ? ? ? ? 福利信息 ? ? 內容 ? ? 1 ? ? ? ? ? 0 ? ? 這種
分表-
消息發送
消息如何產生:競賽結果通知消息(凌晨的xxljob 通知)
每天凌晨,會對當天(前一天,一個意思)結束的競賽進行用戶排名的統計,消息在統計的過程中,隨即產生了。(為啥凌晨,肯定是要當天所有的競賽,都統計一次,又可能早上一個,中午一個,下午一個,有可能一些人,寫了還沒提交,大部分競賽的結束時間都是晚上xx點,比如10點,11點)
xxl-job凌晨1點執行,統計前一天結束的所有競賽
消息如何發送:
最終效果是用戶能在消息頁面中找到消息,換句話說,只要存在數據庫里面就好,設計redis緩存
存儲信息。 ? ? ? ?redis數據結構 ? ? key ? ? ? ? ? ? ? ? ? ? ?value
用戶消息列表 ? ? ?List ? ? ? ? ? ? ? ? ? u:m:l:用戶ID ? ? ? ? textId
消息詳情信息 ? ? ?String ? ? ? ? ? ? ? m:d:textId ? ? ? ? ? ?JSON結構存儲消息詳情
消息發送實現:
通過定時任務生成消息->將消息存儲到數據庫和緩存當中
競賽排名功能
只有歷史競賽才能查看排名,未完賽你看不了,把得分排名啥的存儲起來,開發和設計我的競賽時候,這么存儲
緩存結構:
數據結構list
key:競賽排名列表 e:r:l:+examId
value:直接存詳情名次, json :examRank ? ? ?userId(通過userId查?
昵稱會改,但是我的id要保證,不能說你id改完,找不到了,除非你緩存也要改
?nickname score)
為什么不是存id呢(假如我們之間是存詳情信息,那我我們會存很多份,因為首先他的競賽就有可能你的題庫和競賽列表有重復的數據,假如有詳情信息, 但是競賽排名會有這個情況嗎,但是競賽的排名數據是基本不會重復)

臨時記錄
我在做項目的時候,想到一個問題,我們微服務,為什么要把一個類,粘貼到另一個類
就比如我的job模塊有User類,我的friend服務也需要這個類,為啥我不能導入job這個依賴,然后我去使用User類呢,這么粘貼不麻煩嗎?
假如你引入啦,不就是變成單體架構啦嗎,那么這里我還有感悟,你的引入依賴,引入的不應該是啟動類的微服務,換句話你應該引入的全部都是工具類。

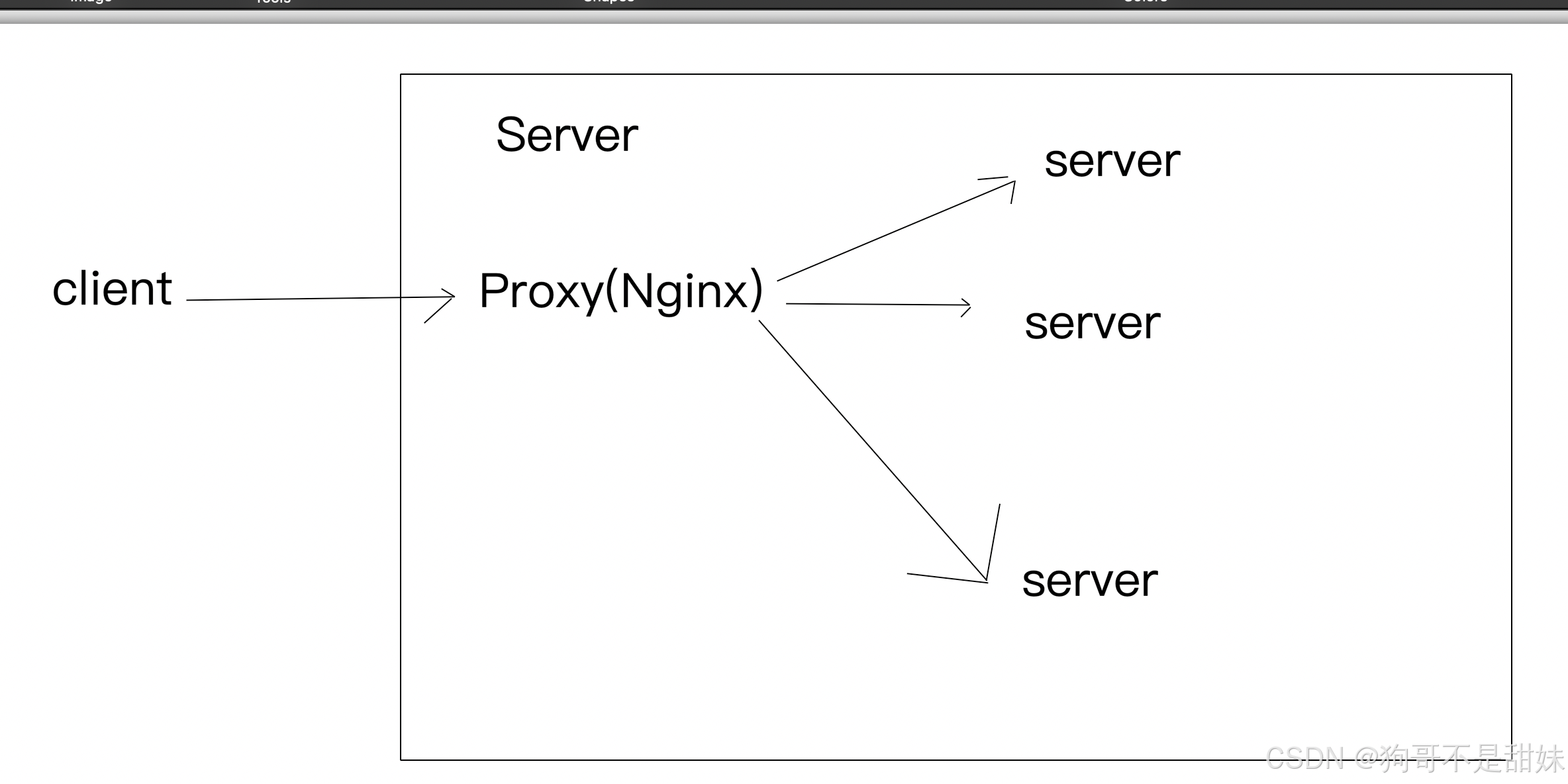
Nginx
Nginx是一個高性能的HTTP和反向代理Web服務器,功能有反向代理,負載均衡和動靜分離
正向代理
客戶端通過代理服務器來訪問互聯網上的其他服務器,這種情況,客戶端配置了代理設置(代理是在客戶端配置的)所有對外的請求都會先發送到代理服務器上,再由代理服務器轉發到真正的目標服務器,
(為什么不直接發目標服務器)
好處:
隱私保護:客戶端的真實IP地址不會直接暴露給外部服務器
緩存:代理服務器具有緩存功能,對于頻繁請求的數據,可以直接從緩存中返回結果,提高響應速度
內容過濾:組織或者企業可以使用正向代理對員工的上網行為進行監控,或者過濾不合適的網站內容。
反向代理
客戶端直接訪問的服務器實際是代理服務器(代理服務器在服務器端配置)這個代理服務器接收客戶端請求后,會把請求轉發給真正的后端服務器,客戶端本身是不知道這個代理服務器的存在的 (好處)
負載均衡:通過反向代理,可以多個后端服務器直接分配請求,分散單個服務器壓力
安全性:隱藏真正的后端服務器地址,增加安全防護
緩存與速度:類似于正向代理,反向代理也可以實現緩存功能,減少負載加快響應速度

負載均衡
為了避免單點故障或者現有的請求使服務器壓力太大無法承受,所以我們搭建一個服務器集群,將原先請求集中到單個服務器上的情況改為將請求分發到多個服務器上,將負載均衡的分發到不同服務器,也就是負載均衡
假如ABCD ,四個服務器,性能不均,怎么做到均衡呢?
Nginx提供了算法
1.輪詢法
每個請求按照時間順序逐一分配(要求所有服務器性能大差不差)
2.權重模式(加權輪詢,weight)
輪詢,weight和訪問比率成正比,用于后端服務器性能不均情況,這種方式比較靈活,當后端服務器性能存在差異的時候,通過配置權重,可以讓服務器性能充分發揮,有效利用資源,weight和訪問比率成正比,權重越高,被訪問的概率越大(能力越大,干的越多)
ip_hash
請求通過哈希算法,自動定位到該服務器。每個請求按照ip的hash結果分配,這樣每個訪客固定訪問一個后端服務器
最少連接
nginx統計每個后端當前活動連接數,分配活動連接數最少的服務器上,根據服務器的實際負載情況動態分配請求,將新請求分配到當前連接數最少的服務器上,避免某些服務器負載過高而其他服務器負載過低的情況。
動靜分離
動:動態資源,動態資源指通過請求服務器獲取到的資源
靜:靜態資源,不需要請求服務器就可以得到的資源如CSS,html,jpg,js)
這些靜態資源既然無需服務器處理,則可以由nginx直接來處理無需后端服務器介入,這樣可以減輕后端服務器的負載,使其專注于處理動態內容,從而提高整體性能,并且可以根據靜態資源的特點做緩存操作
題目的順序列表(用戶端的前一題和后一題,怎么做)
redis的list數據類型,(保證順序,只要差人的順序不變就好,我們只要存入那個題目的id存進去就好) list ?key:q:l?? : ?value:id
查詢一下題目列表,@Component
@redisService
把順序列表查出來
redis應該目前沒數據,我們都是先查redis->沒數據->mysql,
mp的語句
List<Question>questionList=questionMapper.selectList(new ? ? ? ? ?LambdaQueryWrapper<Question> ? ? ? ? ? //要返回的類型?().select(Question::getQuestionId).orderByDesc(Question::getCreateTime)
然后流的使用,集合.steam().map(Question::getQuestionId).collect(Collectors.toList())
尾插,即右插入。
}
2025年5月13日 面試,某某某某達
抽象問題給我打懵逼了
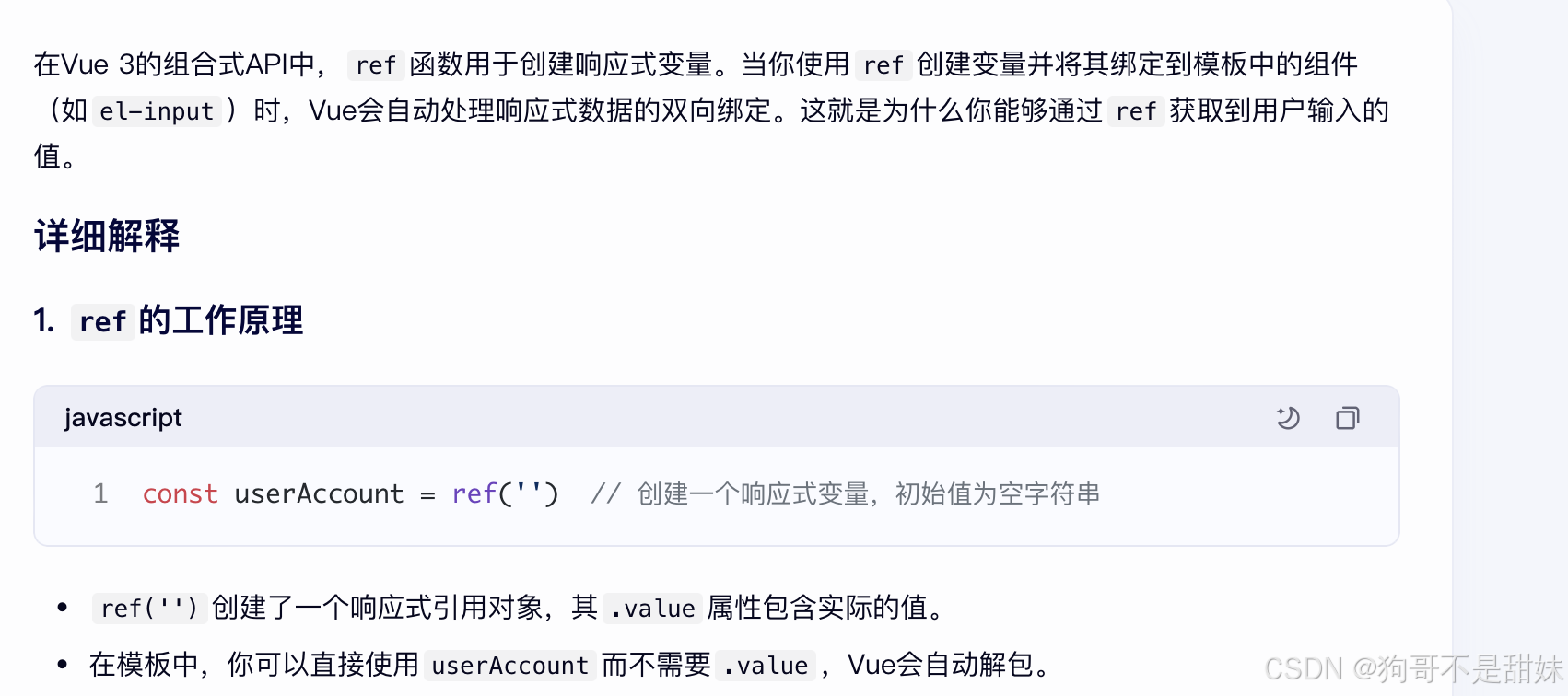
前端通過ref獲取到即時的響應式變量
怎么獲取前端傳過來的數據
el-input 綁定 這個ref,假如你輸入框輸入內容,userAccount自動更新
@PostMapping("/login")接收前端傳遞過來的數據
@RequestBody:接收前端傳遞過來的Body。 我們通常使用一個對象,來包裝這個東西
@ApiResponse:這是Swagger注解,用于定義API的可能響應及其描述。我們采用一個范型R,來包裝
int code;比如成功的統一碼(比如返回0失敗,1成功,3....)
String msg; //通常作為code的輔助說明,一個code對應一個msg.
private T data; //請求某個接口返回的數據 list SysUser范型。
使用一個范型
export function loginService(userAccount,password){return service({url: "/sysUser/login",method: "post",data:{userAccount,password} //接口地址})
}在您參與的定時任務中,是如何處理競賽信息的發布和用戶排名的計算的,有沒有用到一些特定的框架或技術
使用了xxl-job技術,用戶競賽信息的發布,首先要對時間進行一個處理,比如查看一下,當前時間和競賽的開始結束時間比較,
競賽排名信息的發布,因為我們每道題的競賽都有分數,我們用sql都存了。
通過競賽來找分(通過SQL計算時間范圍內,所有競賽id的組合)
ES怎么做添加
ES的結構:



` 和 `關卡藍圖(Level Blueprint)`的關系)



)



)





邏輯圖解+實驗詳解)


OGG 微服務搭建 Oracle 19C CDB 架構同步)
