目錄
- 序言
- docker 部署xinference
- 1WSL環境docker安裝
- 2拉取鏡像運行容器
- 3使用的界面
- 本地跑chatchat
- 1rag踩坑
- 2使用的界面
- 2.1配置個前置條件然后對話
- 2.2rag對話
- 結論
序言
在前兩天的基礎上,將xinference調整為wsl環境,docker部署。
然后langchain chatchat 還是本地虛擬環境直接跑。
以及簡單在這個chatchat框架里上傳了一個文本文件,詢問大模型文件內容。
還行,跑起來了,坑也是不少
docker 部署xinference
1WSL環境docker安裝
參考這個鏈接內容配置下wsl的docker環境,以及配置下國內私人dockerhub鏡像源。
【現在竟然沒有公司或者學校配置的dockerhub鏡像了,奇怪,真奇怪。不配置就要梯子】
參考鏈接1:https://blog.csdn.net/wylszwr/article/details/147671490
這里有個坑,C盤如果空間不夠,wsl最好遷移到D盤,因為大模型挺占空間的。
2拉取鏡像運行容器
參考下面這個鏈接操作一下就好了,然后配置的端口,回頭更新在chatchat的yaml文件就行。
【1050ti的顯卡,cuda和torch這些版本適配有些麻煩,所以我就拉去的cpu版本鏡像。
docker pull xprobe/xinference:latest-cpu】
參考鏈接2:https://inference.readthedocs.io/zh-cn/latest/getting_started/using_docker_image.html
3使用的界面
加載模型界面
就運行這里lunch模型,要等一會兒
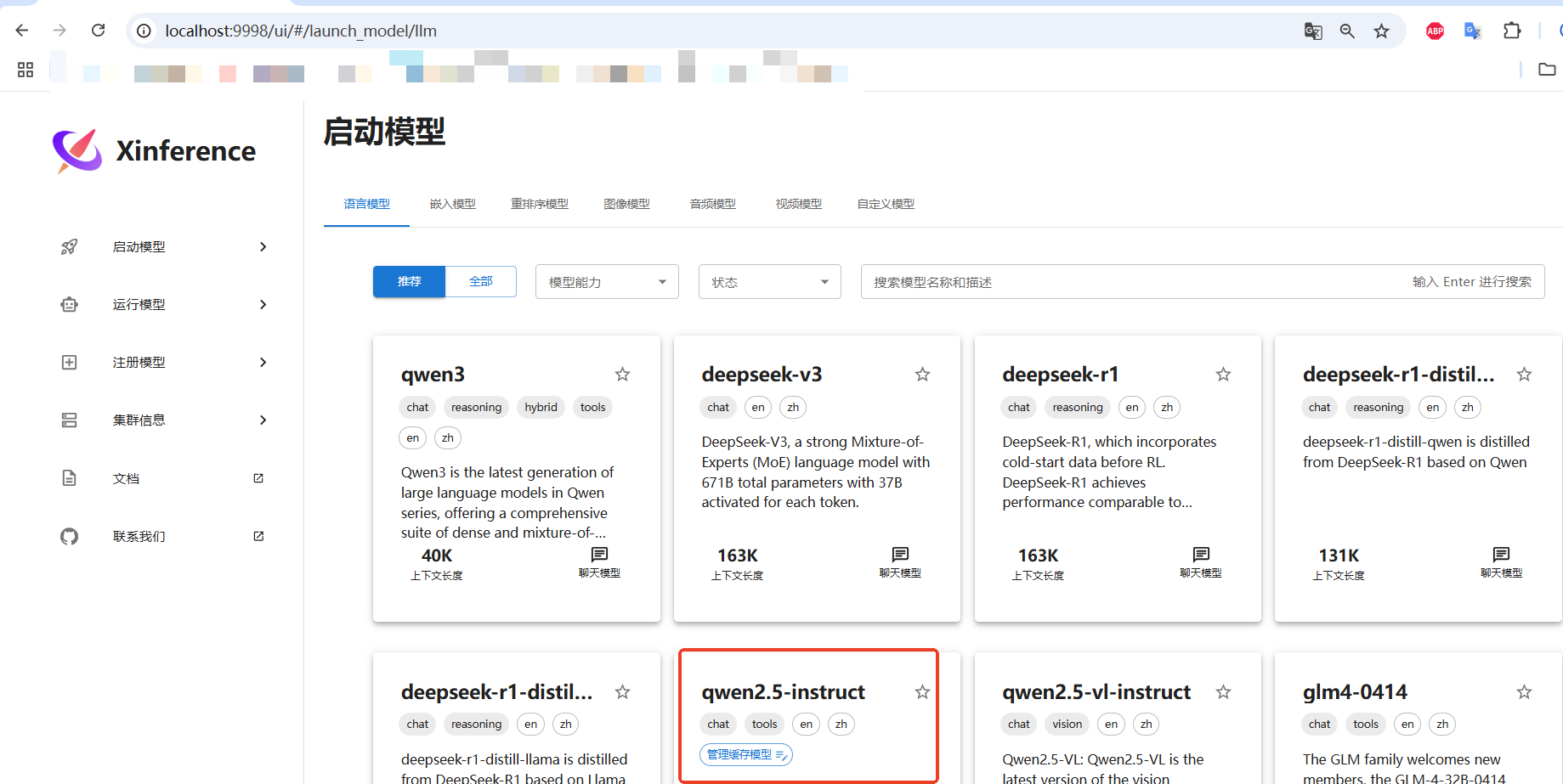
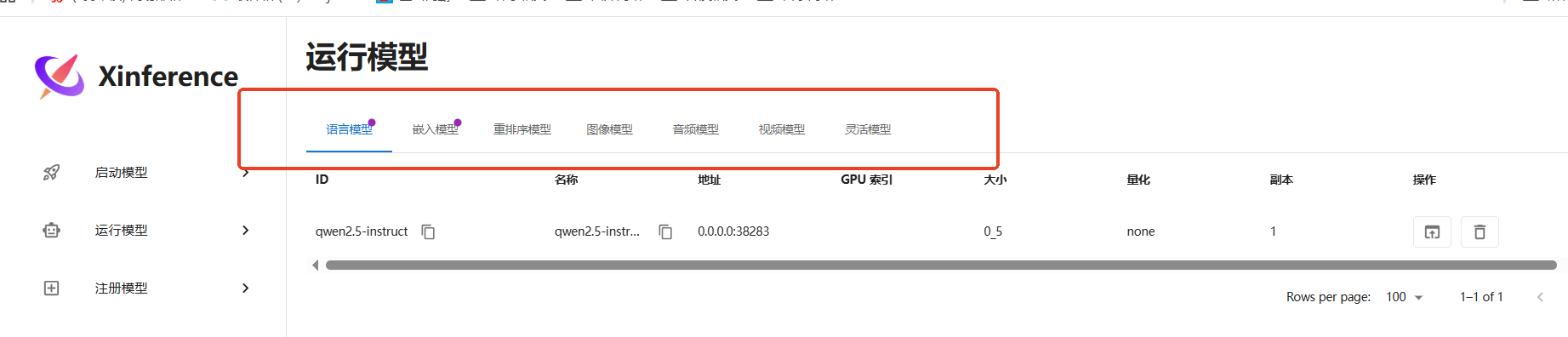
這個運行這里就能看到已經下載到本地的模型了。
語言模型: 就是正常對話的。
嵌入模型embedding模型: 就是把上傳的文本材料,解析成向量,搞到知識庫的。
重排序rerank模型: 目前簡單理解為嵌入模型的升級版(250517)。
參考鏈接3:https://blog.csdn.net/2401_84033492/article/details/144546055
圖像模型: 簡單理解為畫圖的。
音頻模型: 簡單理解為聽聲音,轉換為聲音的。
視頻模型: 生成視頻的。
本地跑chatchat
和上一篇的調整沒啥區別。
就是yaml文件要更新。
【我看有人不建議chatchat在docker跑。我不搞是因為wsl搞docker compose插件有點繁瑣】
1rag踩坑
有個問題就是上傳文件半天沒反應,參考這個降httpx版本就好了。
參考鏈接:https://blog.csdn.net/ddyzqddwb/article/details/144347702
2使用的界面
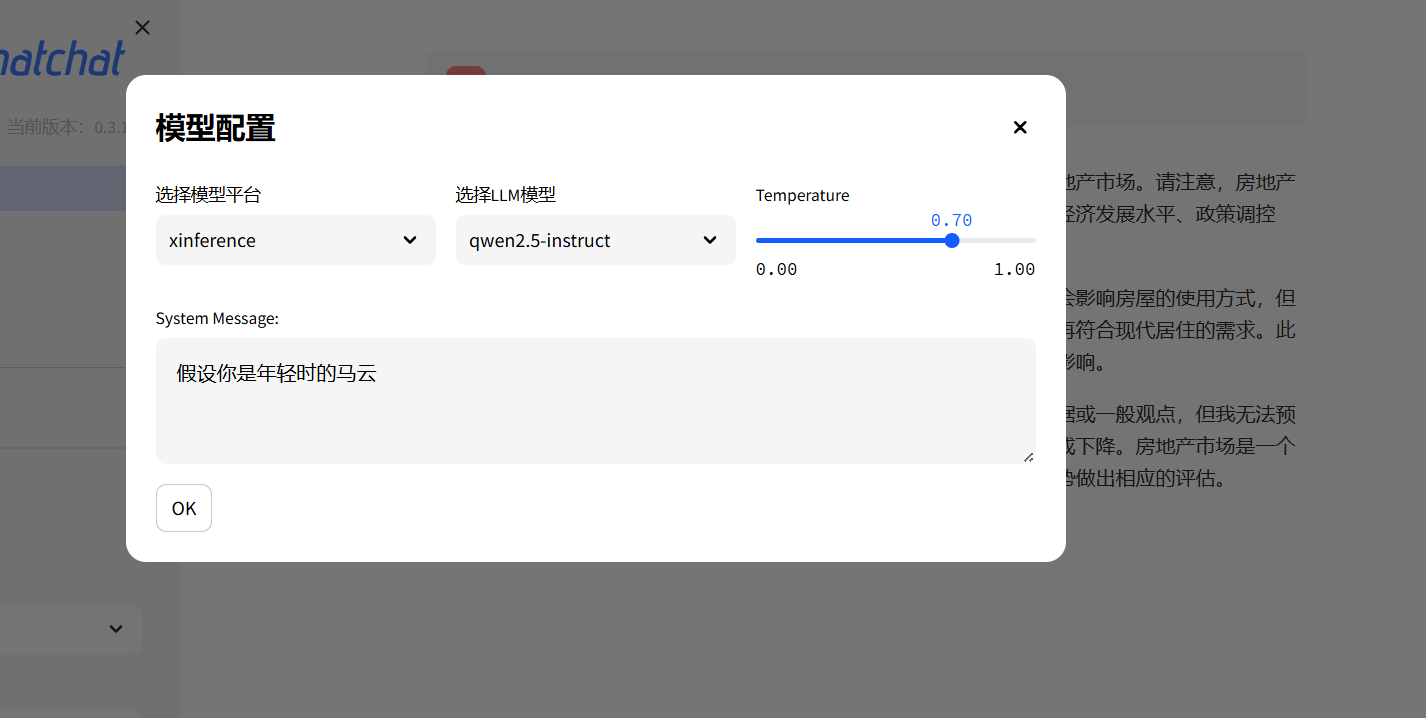
2.1配置個前置條件然后對話
2.2rag對話
往上找了個詩經的txt傳上去,然后用模型閱讀。只是一部分,全是文言文,我自己看著是挺頭大的。
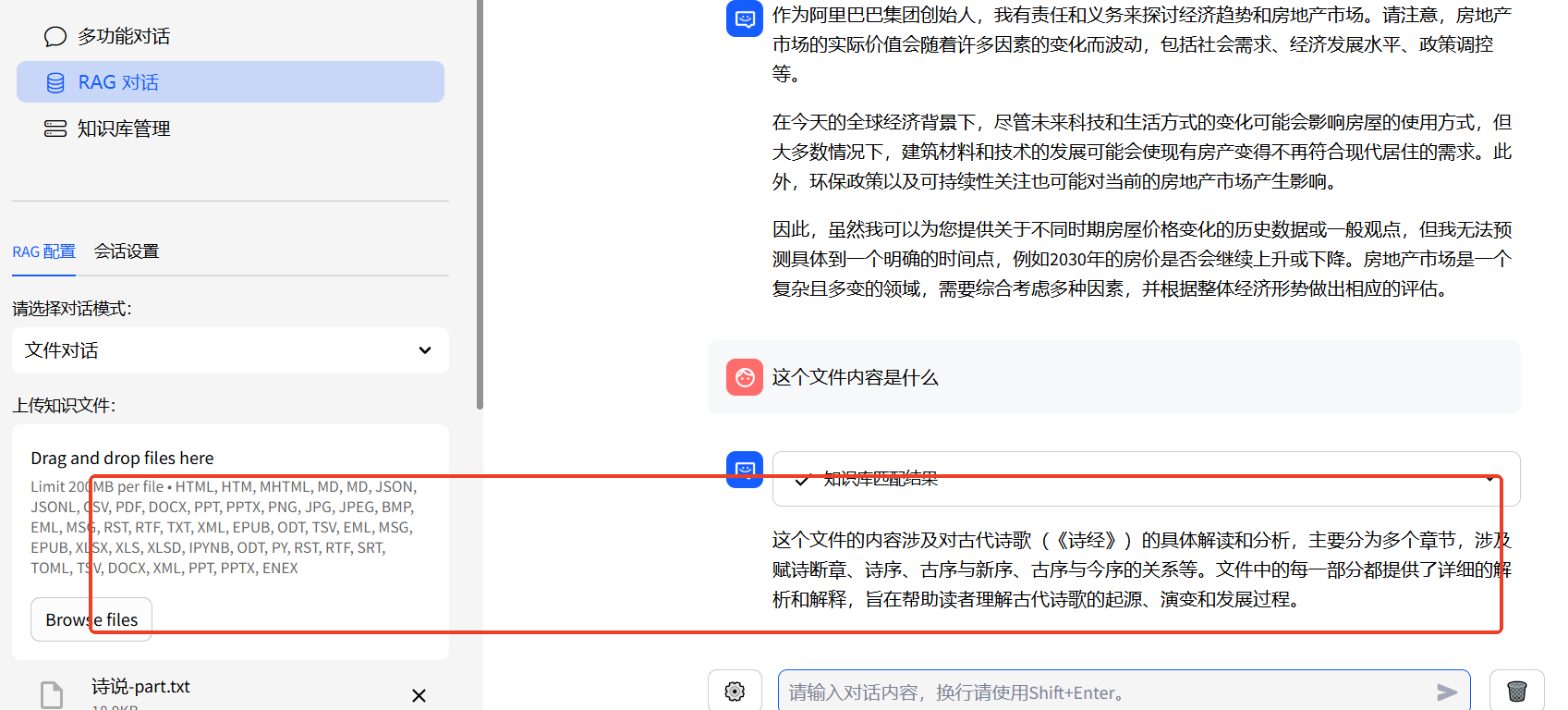
上傳的文言文材料。
結論
windows機器。
wsl環境。
docker跑xinference
本地python環境跑了chatchat
實現大模型的管理加載,以及簡單的知識庫構建與rag管理。
這就是這次的內容。




KV緩存(2))
)




![P1009 [NOIP 1998 普及組] 階乘之和](http://pic.xiahunao.cn/P1009 [NOIP 1998 普及組] 階乘之和)
)



:菜單管理)



