文章目錄
- 1. 背景與動機
- 2. 不使用 KV Cache 的情形
- 2.1 矩陣形式展開
- 2.2 計算復雜度
- 3. 使用 KV Cache 的優化
- 3.1 核心思想
- 3.2 矩陣形式展開
- 3.3 計算復雜度對比
- 4. 總結
- 5. GPT-2 中 KV 緩存的實現分析
- 5.1 緩存的數據結構與類型
- 5.2 在注意力機制 (`GPT2Attention`) 中使用緩存
- 5.3 緩存的更新機制 (`Cache.update`)
- 5.4 在模型整體 (`GPT2Model`) 的 `forward` 方法中處理
- 5.5 因果掩碼 (Causal Mask) 與 KV 緩存的配合
- 5.6 支持多種高效的注意力實現
- 5.7 KV 緩存的完整工作流程 (自回歸生成)
- 5.7.1 初始步驟 (t=0):
- 5.7.2 后續步驟 (t > 0):
- KV 緩存的顯著優勢
- 看圖學kv 很形象清楚
- gpt2源碼
- 分析transformer模型的參數量、計算量、中間激活、KV cache量化分析了緩存
- kv解讀
1. 背景與動機
在自回歸生成(autoregressive generation)任務中,Transformer 解碼器需要在每一步中根據前面已生成的所有 token 重新計算注意力(Attention),這會產生大量重復計算。引入 KV Cache(Key–Value Cache)后,能夠將已計算的鍵值對緩存下來,僅對新增的 Query 進行點乘與加權,從而大幅降低時間與算力開銷。
2. 不使用 KV Cache 的情形
2.1 矩陣形式展開
-
第 1 步(生成第一個 token)
Q 1 , K 1 , V 1 ∈ R 1 × d Q_1, K_1, V_1 \in \mathbb{R}^{1\times d} Q1?,K1?,V1?∈R1×d
A t t e n t i o n 1 = s o f t m a x ( Q 1 K 1 ? d ) , V 1 Attention_1 = \mathrm{softmax}\Bigl(\frac{Q_1 K_1^\top}{\sqrt d}\Bigr),V_1 Attention1?=softmax(d?Q1?K1???),V1?
-
第 2 步(生成第二個 token)
構造全序列的矩陣:
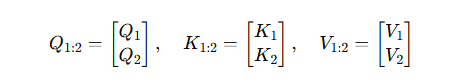
需重算完整注意力矩陣:
A t t e n t i o n 1 : 2 = s o f t m a x ( Q 1 : 2 K 1 : 2 ? d ) , V 1 : 2 Attention_{1:2} = \mathrm{softmax}\Bigl(\frac{Q_{1:2}K_{1:2}^\top}{\sqrt d}\Bigr),V_{1:2} Attention1:2?=softmax(d?Q1:2?K1:2???),V1:2?
計算出一個 2 × 2 2\times 2 2×2 矩陣,但我們只取最后一行作為輸出。
-
第 n 步
Q 1 : n , K 1 : n , V 1 : n ∈ R n × d , A t t e n t i o n 1 : n = s o f t m a x ( Q 1 : n K 1 : n ? d ) , V 1 : n Q_{1:n},K_{1:n},V_{1:n}\in\mathbb{R}^{n\times d},\quad Attention_{1:n} = \mathrm{softmax}\Bigl(\tfrac{Q_{1:n}K_{1:n}^\top}{\sqrt d}\Bigr),V_{1:n} Q1:n?,K1:n?,V1:n?∈Rn×d,Attention1:n?=softmax(d?Q1:n?K1:n???),V1:n?
每步均重新構建并計算 n × n n\times n n×n 注意力矩陣。
2.2 計算復雜度
-
注意力矩陣構建: O ( n 2 ? d ) O(n^2\cdot d) O(n2?d)。
-
整體推理階段:若生成總長度為 N N N,則總復雜度近似為
∑ n = 1 N O ( n 2 d ) ; = ; O ( N 3 d ) \sum_{n=1}^N O(n^2 d);=;O(N^3 d) ∑n=1N?O(n2d);=;O(N3d),
由于每步都做重復計算,效率極低。
3. 使用 KV Cache 的優化
3.1 核心思想
-
緩存已計算的 K, V:對于前序列位置的鍵值對,只需計算一次并存儲。
-
僅對新增 Query 進行點乘:第 n n n 步僅需計算 Q n Q_n Qn? 與所有緩存 K 的點乘,得到長度為 n n n 的注意力權重,再加權疊加對應的 V。
3.2 矩陣形式展開
-
第 1 步:如前,無緩存,計算
A t t e n t i o n 1 = s o f t m a x ( Q 1 K 1 ? / d ) , V 1 Attention_1 = \mathrm{softmax}(Q_1K_1^\top/\sqrt d),V_1 Attention1?=softmax(Q1?K1??/d?),V1?. -
第 2 步:
-
新增 Q 2 ∈ R 1 × d Q_2\in\mathbb{R}^{1\times d} Q2?∈R1×d;
-
緩存矩陣已擴展為
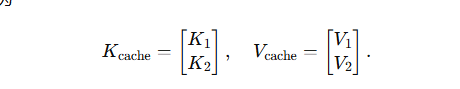
-
只做一次 1 × 2 1\times 2 1×2 點乘:
A t t e n t i o n 2 = s o f t m a x ( Q 2 K c a c h e ? d ) , V c a c h e Attention_2 = \mathrm{softmax}\Bigl(\tfrac{Q_2 K_{\mathrm{cache}}^\top}{\sqrt d}\Bigr),V_{\mathrm{cache}} Attention2?=softmax(d?Q2?Kcache???),Vcache?,
輸出即為所需的 1 × d 1\times d 1×d 向量。
-
-
第 n 步:
K c a c h e ∈ R n × d , V c a c h e ∈ R n × d , A t t e n t i o n n = s o f t m a x ( Q n K c a c h e ? d ) , V c a c h e K_{\mathrm{cache}}\in\mathbb{R}^{n\times d},\quad V_{\mathrm{cache}}\in\mathbb{R}^{n\times d},\quad Attention_n = \mathrm{softmax}\Bigl(\tfrac{Q_n K_{\mathrm{cache}}^\top}{\sqrt d}\Bigr),V_{\mathrm{cache}} Kcache?∈Rn×d,Vcache?∈Rn×d,Attentionn?=softmax(d?Qn?Kcache???),Vcache?.
3.3 計算復雜度對比
| 模式 | 每步復雜度 | 總體復雜度(生成長度 N N N) |
|---|---|---|
| 無 Cache | O ( n 2 d ) O(n^2 d) O(n2d) | O ( N 3 d ) O(N^3 d) O(N3d) |
| 有 KV Cache | O ( n d ) O(n d) O(nd) | ∑ n = 1 N O ( n d ) = O ( N 2 d ) \displaystyle\sum_{n=1}^N O(n d)=O(N^2 d) n=1∑N?O(nd)=O(N2d) |
- 加速比:從二次方級別 O ( n 2 ) O(n^2) O(n2) 降到線性級別 O ( n ) O(n) O(n),對長序列提升顯著。
4. 總結
-
多頭注意力(Multi-Head)
每個 head 獨立緩存自己的 K, V 矩陣,計算時分別點乘再拼接。總體計算與存儲線性可擴展。 -
緩存管理
-
內存占用:緩存矩陣大小隨生成長度增長,應考慮清理過舊不再需要的序列(如 sliding window)。
-
Batch 推理:對多條序列并行生成時,可為每條序列維護獨立緩存,或統一按最大長度對齊。
-
-
硬件優化
-
內存帶寬:KV Cache 減少重復內存載入,對帶寬友好;
-
并行度:線性點乘更易與矩陣乘加(GEMM)指令級并行融合。
-
-
實踐中常見問題
- Cache 不命中:若使用 prefix-tuning 等技術動態修改 key/value,需謹慎處理緩存一致性。
- 數值穩定性:長序列高維 softmax 易出現梯度消失/爆炸,可結合溫度系數或分段歸一化。
5. GPT-2 中 KV 緩存的實現分析
GPT-2(以及許多其他基于 Transformer 的自回歸模型)在生成文本時,為了提高效率,會使用一種稱為 KV 緩存 (Key-Value Cache) 的機制。其核心思想是:在生成第 t 個 token 時,計算注意力所需的鍵 (Key) 和值 (Value) 向量可以部分來自于已經生成的 t-1 個 token。通過緩存這些歷史的 K 和 V 向量,可以避免在每一步生成時都對整個已生成序列重新進行昂貴的 K 和 V 計算。
5.1 緩存的數據結構與類型
Hugging Face Transformers 庫為 GPT-2 提供了靈活的緩存管理機制,主要通過 Cache 基類及其子類實現。
Cache(基類): 定義了緩存對象的基本接口,例如update(更新緩存) 和get_seq_length(獲取當前緩存的序列長度) 等方法。DynamicCache:- 這是自回歸生成時最常用的緩存類型。
- 它允許緩存的序列長度動態增長。當生成新的 token 時,新計算出的 K 和 V 向量會被追加到已有的緩存后面。
- 不需要預先分配固定大小的內存,更加靈活,但可能在內存管理上有一些開銷。
StaticCache:- 在創建時就需要預先分配固定大小的內存空間來存儲 K 和 V 向量。
- 適用于已知最大生成長度或需要更可控內存占用的場景。
- 如果生成的序列長度超過了預分配的大小,可能會出錯或需要特殊處理。
EncoderDecoderCache:- 主要用于 Encoder-Decoder 架構的模型 (如 T5, BART)。
- 它內部會分別管理編碼器-解碼器注意力(交叉注意力)的 KV 緩存和解碼器自注意力的 KV 緩存。
- GPT-2 是一個僅解碼器 (Decoder-only) 模型,所以主要關注自注意力的緩存。
# 相關類的導入,展示了緩存工具的多樣性
from transformers.cache_utils import Cache, DynamicCache, EncoderDecoderCache, StaticCache
5.2 在注意力機制 (GPT2Attention) 中使用緩存
GPT2Attention 類的 forward 方法是 KV 緩存機制的核心應用點。
class GPT2Attention(nn.Module): ... def forward( self, hidden_states: Optional[Tuple[torch.FloatTensor]], layer_past: Optional[Tuple[torch.Tensor]] = None, # 舊版本的緩存參數名 past_key_value: Optional[Cache] = None, # 新版本的緩存對象 attention_mask: Optional[torch.FloatTensor] = None, head_mask: Optional[torch.FloatTensor] = None, use_cache: Optional[bool] = False, output_attentions: Optional[bool] = False, cache_position: Optional[torch.LongTensor] = None, # 指示新token在緩存中的位置 ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]: # 1. 計算當前輸入 hidden_states 的 Q, K, V # self.c_attn 是一個線性層,通常一次性計算出 Q, K, V 然后分割 query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2) # 2. 將 Q, K, V 重塑為多頭形式 (batch_size, num_heads, seq_len, head_dim) query = self._split_heads(query, self.num_heads, self.head_dim) key = self._split_heads(key, self.num_heads, self.head_dim) value = self._split_heads(value, self.num_heads, self.head_dim) # 3. KV 緩存處理 if past_key_value is not None: # 如果是 EncoderDecoderCache,根據是否交叉注意力選擇正確的緩存 if isinstance(past_key_value, EncoderDecoderCache): # ... (GPT-2 不直接使用此邏輯,但展示了其通用性) pass # 使用 cache_position 來更新緩存中的特定位置 cache_kwargs = {"cache_position": cache_position} # 調用緩存對象的 update 方法 # key 和 value 是當前新計算的 K, V # self.layer_idx 標識當前是哪一層的緩存 key, value = past_key_value.update(key, value, self.layer_idx, cache_kwargs) # 此時的 key 和 value 包含了歷史信息和當前新計算的信息 # 4. 計算注意力權重 (Q @ K^T) # ... attn_weights = torch.matmul(query, key.transpose(-1, -2)) # ... 應用注意力掩碼 (causal mask, padding mask) ... # 5. 計算注意力輸出 (attn_weights @ V) attn_output = torch.matmul(attn_weights, value) # ... 合并多頭,返回結果 ... if use_cache: # 如果使用緩存,則 present_key_value 就是更新后的 past_key_value present_key_value = past_key_value else: present_key_value = None return attn_output, present_key_value # 返回注意力的輸出和更新后的緩存
關鍵點解釋:
past_key_value(或layer_past): 這是從上一個時間步或上一個調用傳遞過來的緩存對象。它包含了到目前為止所有先前 token 的 K 和 V 向量。cache_position: 這是一個非常重要的參數,尤其是在使用了諸如 Flash Attention 2 等更高級的注意力實現時。它告訴緩存update方法以及注意力計算函數,新的 K 和 V 向量應該被放置在緩存張量的哪個位置。這對于正確地處理填充(padding)和動態序列長度至關重要。例如,如果當前輸入的是第t個 token(從0開始計數),cache_position可能就是t。self.layer_idx: Transformer 模型通常由多個相同的注意力層堆疊而成。每一層都有自己獨立的 KV 緩存。layer_idx用于標識當前正在處理的是哪一層的緩存,確保數據被正確地存取。use_cache: 控制是否使用和返回緩存。在訓練時通常為False(除非進行特定類型的訓練,如 teacher forcing 的逐token訓練),在推理(生成)時為True。
5.3 緩存的更新機制 (Cache.update)
Cache 對象的 update 方法是實現緩存的核心。雖然具體的實現會因 DynamicCache 或 StaticCache 而異,但其基本邏輯是:
class DynamicCache(Cache): def __init__(self): self.key_cache: List[torch.Tensor] = [] # 每層一個 tensor self.value_cache: List[torch.Tensor] = [] # 每層一個 tensor self.seen_tokens = 0 # 已緩存的token數量 def update( self, key_states: torch.Tensor, # 新計算的 key value_states: torch.Tensor, # 新計算的 value layer_idx: int, # 當前層索引 cache_kwargs: Optional[Dict[str, Any]] = None, ) -> Tuple[torch.Tensor, torch.Tensor]: # 獲取 cache_position cache_position = cache_kwargs.get("cache_position") # 如果是第一次更新這一層 (或緩存為空) if layer_idx >= len(self.key_cache): # 初始化該層的緩存張量 # ... 根據 key_states 和 value_states 的形狀以及預估的最大長度(或動態調整) self.key_cache.append(torch.zeros_like(key_states_preallocated)) self.value_cache.append(torch.zeros_like(value_states_preallocated)) # 將新的 key_states 和 value_states 寫入到緩存的指定位置 # 對于 DynamicCache,通常是直接拼接或在預分配空間中按位置寫入 if cache_position is not None: # 使用 cache_position 精確地更新緩存的特定部分 # 例如: self.key_cache[layer_idx][:, :, cache_position, :] = key_states # self.value_cache[layer_idx][:, :, cache_position, :] = value_states # 這里的維度可能需要根據實際實現調整 # 重要的是理解 cache_position 的作用 # 例如,如果 key_states 的形狀是 (batch, num_heads, new_seq_len, head_dim) # cache_position 的形狀可能是 (batch, new_seq_len) 或廣播的 (new_seq_len) # 需要將 key_states 放置到 self.key_cache[layer_idx] 的正確"槽位" # 對于自回歸,通常 new_seq_len = 1 self.key_cache[layer_idx].index_copy_(dim=2, index=cache_position, source=key_states) self.value_cache[layer_idx].index_copy_(dim=2, index=cache_position, source=value_states) # 更新已見過的token數量 self.seen_tokens = cache_position[-1] + 1 # 取最后一個新token的位置加1 else: # 舊的、不使用 cache_position 的邏輯(通常是簡單拼接) self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=2) self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=2) self.seen_tokens += key_states.shape[2] # 返回包含所有歷史信息(包括剛更新的)的 K 和 V 狀態 return self.key_cache[layer_idx], self.value_cache[layer_idx]
update 方法的關鍵職責:
- 接收當前新計算的
key_states和value_states。 - 根據
layer_idx找到對應層的緩存。 - (可選,但推薦)使用
cache_position將新的 K, V 向量精確地放置到緩存張量的正確位置。這對于處理批處理中不同樣本有不同歷史長度的情況(例如,在束搜索beam search后或 speculative decoding 后),或者在有填充 token 時非常重要。 - 返回完整的、包含所有歷史信息和當前新信息的 K, V 向量,供后續的注意力計算使用。
- 更新內部狀態,如已緩存的 token 數量 (
seen_tokens)。
5.4 在模型整體 (GPT2Model) 的 forward 方法中處理
GPT2Model 的 forward 方法負責協調整個模型的流程,包括緩存的初始化、傳遞和 cache_position 的計算。
class GPT2Model(GPT2PreTrainedModel): def forward( self, input_ids: Optional[torch.LongTensor] = None, past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None, # 舊版緩存元組 attention_mask: Optional[torch.FloatTensor] = None, # ... use_cache: Optional[bool] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, cache_position: Optional[torch.LongTensor] = None, ) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]: # ... (處理輸入ID和嵌入) ... inputs_embeds = self.wte(input_ids) # 詞嵌入 position_embeds = self.wpe(position_ids) # 位置嵌入 hidden_states = inputs_embeds + position_embeds # 1. 緩存初始化和類型轉換 if use_cache: if past_key_values is None: # 如果是第一次調用或沒有提供緩存 # 根據配置決定使用哪種緩存,通常是 DynamicCache # 例如:self.config.cache_implementation == "dynamic" past_key_values = DynamicCache() elif not isinstance(past_key_values, Cache): # 為了兼容舊的元組形式的緩存,將其轉換為新的 Cache 對象 past_key_values = DynamicCache.from_legacy_cache(past_key_values) # else: past_key_values 保持為 None # 2. 計算 cache_position if cache_position is None: # 如果外部沒有提供 cache_position # 獲取當前緩存中已有的 token 數量 past_seen_tokens = past_key_values.get_seq_length(self.config.num_hidden_layers) if past_key_values is not None else 0 # 當前輸入序列的長度 current_seq_length = inputs_embeds.shape[1] # cache_position 從 past_seen_tokens 開始,長度為 current_seq_length cache_position = torch.arange( past_seen_tokens, past_seen_tokens + current_seq_length, device=inputs_embeds.device ) # else: 使用外部傳入的 cache_position # ... (準備注意力掩碼,考慮因果關系和緩存長度) ... # 3. 逐層傳遞和更新緩存 all_hidden_states = () if output_hidden_states else None all_self_attentions = () if output_attentions else None # next_decoder_cache 用于收集下一輪的緩存 (如果 use_cache 為 True) # 在新的 Cache 對象設計中,past_key_values 本身會被原地更新或返回更新后的版本 # 因此,這個 next_decoder_cache 可能不再是必需的,或者其角色由 past_key_values 自身承擔 for i, block in enumerate(self.h): # self.h 是 GPT2Block 的列表 # ... # 將當前層的緩存 (如果存在) 和 cache_position 傳遞給 GPT2Block # GPT2Block 內部會再將其傳遞給 GPT2Attention layer_outputs = block( hidden_states, layer_past=None, # 舊參數,通常為None attention_mask=extended_attention_mask, head_mask=head_mask[i], encoder_hidden_states=None, encoder_attention_mask=None, use_cache=use_cache, output_attentions=output_attentions, past_key_value=past_key_values, # 傳遞整個緩存對象 cache_position=cache_position, ) hidden_states = layer_outputs[0] # 更新 hidden_states # 如果 use_cache,block 會返回更新后的緩存,這里 past_key_values 已被更新 # (在 Cache 對象實現中,update 方法通常返回更新后的完整緩存狀態, # 或者直接在對象內部修改,取決于具體實現) # ... (處理輸出) ... return BaseModelOutputWithPast( last_hidden_state=hidden_states, past_key_values=past_key_values if use_cache else None, # 返回更新后的緩存 hidden_states=all_hidden_states, attentions=all_self_attentions, )
5.5 因果掩碼 (Causal Mask) 與 KV 緩存的配合
在自回歸生成中,模型只能注意到當前 token 及其之前的所有 token,不能注意到未來的 token。這是通過因果掩碼實現的。當使用 KV 緩存時,因果掩碼的構建需要考慮到緩存中已有的 token 數量。
class GPT2Attention(_GPT2Attention): def _update_causal_mask( self, attention_mask: torch.Tensor, # 原始的 attention_mask (可能包含 padding) input_tensor: torch.Tensor, # 當前輸入的 hidden_states cache_position: torch.Tensor, past_key_values: Cache, # 當前的緩存對象 output_attentions: bool, ): # 獲取當前輸入的序列長度 (通常為1,在自回歸生成的每一步) input_seq_length = input_tensor.shape[1] # 獲取緩存中已有的序列長度 past_seen_tokens = past_key_values.get_seq_length(self.layer_idx) # 總的上下文長度 = 緩存長度 + 當前輸入長度 total_context_length = past_seen_tokens + input_seq_length # _prepare_4d_causal_attention_mask_with_cache_position 會生成一個正確的掩碼 # 這個掩碼會確保: # 1. 查詢 Q (來自當前輸入) 只能注意到鍵 K (來自緩存+當前輸入) 中對應位置及之前的部分。 # 2. 處理好 padding (如果 attention_mask 中有指示)。 # 形狀通常是 (batch_size, 1, query_length, key_length) # 其中 query_length 是當前輸入的長度 (如1) # key_length 是總的上下文長度 (past_seen_tokens + input_seq_length) causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position( attention_mask, input_shape=(input_tensor.shape[0], input_seq_length), # 當前輸入的形狀 target_length=total_context_length, # K, V 的總長度 dtype=input_tensor.dtype, cache_position=cache_position, # 關鍵!用于確定當前 Q 在 K,V 序列中的相對位置 ) return causal_mask
_prepare_4d_causal_attention_mask_with_cache_position 這個輔助函數會創建一個上三角矩陣(或類似結構),其中未來的位置會被掩蓋掉(例如,設置為一個非常小的負數,以便 softmax 后變為0)。cache_position 在這里的作用是,確保即使當前查詢 Q 的序列長度很短(例如為1),它在與歷史的 K, V 進行比較時,依然能正確地只關注到歷史和當前 K, V 中該 Q 之前的部分。
5.6 支持多種高效的注意力實現
Hugging Face Transformers 庫允許 GPT-2(以及其他模型)利用更高效的注意力后端實現,例如:
eager: PyTorch 的標準、原生注意力實現。sdpa(Scaled Dot Product Attention): PyTorch 2.0 引入的高度優化的注意力函數torch.nn.functional.scaled_dot_product_attention。它通常比 eager模式更快,內存效率也更高,并且可以自動選擇最優的底層實現(如 FlashAttention 或 memory-efficient attention)。flash_attention_2: 直接集成 FlashAttention v2 庫。這是一種專門為現代 GPU 設計的、IO 感知的精確注意力算法,速度非常快,內存占用小。
KV 緩存機制的設計需要與這些高效實現兼容。例如,torch.nn.functional.scaled_dot_product_attention 和 FlashAttention 都支持直接傳入包含歷史和當前信息的完整 K, V 張量。cache_position 在這里尤為重要,因為它可以幫助這些高效后端理解哪些部分是新的,哪些是舊的,以及如何正確應用因果掩碼。
# 在 GPT2Attention 的 forward 方法中
self.config._attn_implementation 存儲了選擇的注意力實現方式 ("eager", "sdpa", "flash_attention_2") ... (計算 query, key, value) ...
... (更新 key, value 使用 past_key_value 和 cache_position) ...
此時 key 和 value 是拼接/更新后的完整 K, V if self.config._attn_implementation == "sdpa": # 使用 PyTorch SDPA # is_causal=True 會自動應用因果掩碼 # attn_mask 可能需要根據 SDPA 的要求進行調整 attn_output = torch.nn.functional.scaled_dot_product_attention( query, key, value, attn_mask=adjusted_attn_mask, dropout_p=self.attn_dropout.p, is_causal=True )
elif self.config._attn_implementation == "flash_attention_2": # from flash_attn import flash_attn_func # 可能需要對 query, key, value 的形狀或數據類型進行調整以適應 flash_attn_func # causal=True 會應用因果掩碼 attn_output = flash_attn_func( query.transpose(1, 2), # FlashAttention 可能期望 (batch, seq_len, num_heads, head_dim) torch.stack((key.transpose(1,2), value.transpose(1,2)), dim=0), # K, V 打包 dropout_p=self.attn_dropout.p, causal=True, )
else: # "eager" # ... (標準的 PyTorch matmul 實現) ...
5.7 KV 緩存的完整工作流程 (自回歸生成)
5.7.1 初始步驟 (t=0):
- 用戶提供初始的
input_ids(例如,一個[BOS]token 或者一段提示文本)。 past_key_values為None。- 模型
forward方法被調用。 use_cache通常為True。- 初始化一個空的
DynamicCache對象作為past_key_values。 - 計算
cache_position,此時它通常是從 0 開始的序列 (e.g.,torch.arange(0, initial_input_len)). - 對于每一注意力層:
- 計算當前
input_ids對應的 Q, K, V。 - 由于
past_key_values剛被初始化(內部緩存為空),update方法會將這些新計算的 K, V 存入緩存的第一批位置。 - 使用這些 K, V (此時它們只包含當前輸入的信息) 和 Q 進行注意力計算。
- 計算當前
- 模型輸出 logits (用于預測下一個 token) 和更新后的
past_key_values(現在包含了第一個輸入的 K,V)。
5.7.2 后續步驟 (t > 0):
- 從上一步的 logits 中采樣得到新的
input_ids(通常是一個新的 token)。 - 將上一步返回的
past_key_values(包含了 t-1 步及之前所有 token 的 K,V) 作為輸入傳遞給模型。 - 模型
forward方法再次被調用。 use_cache為True。- 計算
cache_position。此時,past_key_values.get_seq_length()會返回已緩存的 token 數量 (例如t)。新的cache_position會是torch.tensor([t]),表示這個新 token 是序列中的第t+1個元素 (如果從1開始計數的話,或者第t個位置如果從0開始計數)。 - 對于每一注意力層:
- 只對新輸入的單個 token 計算其 Q, K, V (這些是"小"張量)。
- 調用
past_key_values.update(new_key, new_value, layer_idx, cache_kwargs={"cache_position": cache_position})。update方法會將這個新 token 的 K, V 追加到對應層緩存中已有的 K, V 之后,并返回完整的 K (包含所有t+1個 token) 和完整的 V。
- 使用新 token 的 Q 和完整的 (歷史+當前) K, V 計算注意力。因果掩碼會確保 Q 只注意到 K,V 中它自己及之前的部分。
- 模型輸出 logits 和再次更新后的
past_key_values。
這個過程一直重復,直到生成了 [EOS] token 或達到最大長度。
KV 緩存的顯著優勢
- 避免冗余計算: 這是最核心的優勢。在生成第
t個 token 時,前t-1個 token 的 K 和 V 向量已經計算并存儲在緩存中,無需重新計算。注意力機制只需要為新的當前 token 計算 K 和 V,然后將它們與緩存中的歷史 K,V 結合起來。 - 顯著提高生成速度: 尤其對于長序列生成,每次迭代的計算量從 O(N2)(N為當前總長度)降低到接近 O(N)(主要是新 Q 與歷史 K,V 的交互),因為主要計算瓶頸(K,V的生成)只針對新token進行。
- 支持高效的批處理生成: 雖然每個樣本在批次中可能有不同的已生成長度(特別是在使用可變長度輸入或某些采樣策略時),通過
cache_position和可能的填充/掩碼機制,KV 緩存可以有效地處理這種情況。 - 與先進注意力實現的兼容性: 如前所述,KV 緩存的設計與 SDPA、FlashAttention 等高效后端良好集成,使得模型可以同時享受到算法優化和底層硬件加速的好處。
)




![P1009 [NOIP 1998 普及組] 階乘之和](http://pic.xiahunao.cn/P1009 [NOIP 1998 普及組] 階乘之和)
)



:菜單管理)








