文本分類任務Qwen3-0.6B與Bert:實驗見解
前言
最近在知乎上刷到一個很有意思的提問Qwen3-0.6B這種小模型有什么實際意義和用途。查看了所有回答,有人提到小尺寸模型在邊緣設備場景中的優勢(低延遲)、也有人提出小模型只是為了開放給其他研究者驗證scaling law(Qwen2.5系列豐富的模型尺寸為開源社區驗證方法有效性提供了基礎)、還有人說4B、7B的Few-Shot效果就已經很好了甚至直接調用更大的LLM也能很好的解決問題。讓我比較感興趣的是有大佬提出小模型在向量搜索、命名實體識別(NER)和文本分類領域中很能打,而另一個被拿來對比的就是Bert模型。在中文文本分類中,若對TextCNN、FastText效果不滿意,可能會嘗試Bert系列及其變種(RoBerta等)。但以中文語料為主的類Encoder-Only架構模型其實并不多(近期發布的ModernBERT,也是以英文和Code語料為主),中文文本分類還是大量使用bert-base-chinese為基礎模型進行微調,而距Bert發布已經過去了6年。Decoder-Only架構的LLM能在文本分類中擊敗參數量更小的Bert嗎?所以我準備做一個實驗來驗證一下。
不想看實驗細節的,可以直接看最后的結論和實驗局限性部分。
實驗設置
-
GPU:RTX 3090(24G)
-
模型配置:
| 模型 | 參數量 | 訓練方式 |
|---|---|---|
| google-bert/bert-base-cased | 0.1B | 添加線性層,輸出維度為分類數 |
| Qwen/Qwen3-0.6B | 0.6B | 構造Prompt,SFT |
- 數據集配置:fancyzhx/ag_news,分類數為4,分別為World(0)、Sports(1)、Business(2)、Sci/Tech(3)。訓練樣本數120000,測試樣本數7600,樣本數量絕對均衡。數據集展示:
{"text": "New iPad released Just like every other September, this one is no different. Apple is planning to release a bigger, heavier, fatter iPad that...""label": 3
}
- 選擇該數據集是在
Paper with code的Text Classification類中看到的榜單,并且該數據集元素基本上不超過510個token(以Bert Tokenizer計算)。因為Bert的最大輸入長度是510個token,超過會進行截斷,保留前510個token,所以為了進行公平的比較,盡量避免截斷。 - 因為是多分類任務,我們以模型在測試集上的F1指標為標準,F1值越高,模型效果越好。
Bert訓練細節
Bert的訓練比較簡單,將文本使用Tokenizer轉換成input_ids后,使用Trainer進行正常訓練即可。訓練參數(若未單獨指出,則代表使用Trainer默認值):
| 參數名稱 | 值 |
|---|---|
| lr_scheduler_type(學習率衰減策略) | cosine |
| learning_rate(學習率) | 1.0e-5 |
| per_device_train_batch_size(訓練batch_size) | 64 |
| gradient_accumulation_steps(梯度累積) | 1 |
| per_device_eval_batch_size(驗證batch_size) | 256 |
| num_train_epochs(epoch) | 5 |
| weight_decay | 1e-6 |
| eval_steps(驗證頻率) | 0.1 |
- 訓練過程中模型對測試集的指標變化:
| Step | Training Loss | Validation Loss | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| 938 | 0.191500 | 0.195639 | 0.934737 | 0.935364 | 0.934737 | 0.934773 |
| 1876 | 0.177600 | 0.179451 | 0.938289 | 0.938485 | 0.938289 | 0.938360 |
| 2814 | 0.142200 | 0.186385 | 0.936711 | 0.938738 | 0.936711 | 0.936743 |
| 3752 | 0.146600 | 0.168954 | 0.945526 | 0.945955 | 0.945526 | 0.945572 |
| 4690 | 0.113500 | 0.176878 | 0.945395 | 0.945408 | 0.945395 | 0.945385 |
| 5628 | 0.092200 | 0.177268 | 0.945658 | 0.945759 | 0.945658 | 0.945627 |
| 6566 | 0.081500 | 0.194639 | 0.942763 | 0.943813 | 0.942763 | 0.942817 |
| 7504 | 0.077600 | 0.191445 | 0.944079 | 0.944362 | 0.944079 | 0.944056 |
| 8442 | 0.068100 | 0.194431 | 0.944211 | 0.944457 | 0.944211 | 0.944216 |
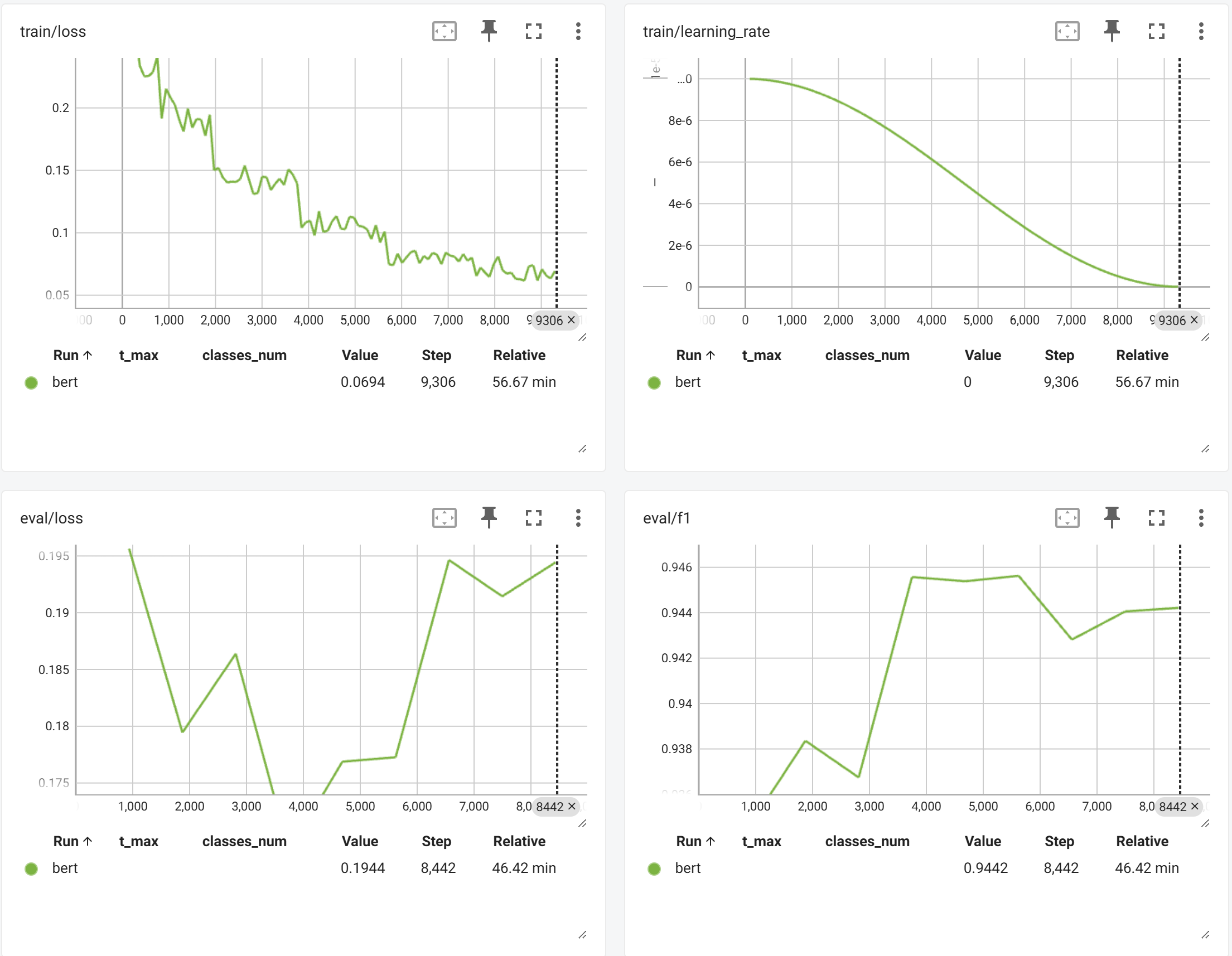
- 可以看到
Bert在3752 step(2 epoch)后出現了嚴重的過擬合,在測試集上最好結果是:0.945
Qwen3訓練細節
- 使用
Qwen3訓練文本分類模型有2種方法。第1種是修改模型架構,將模型最后一層替換為輸出維度為分類數的線性層。第2種是構造Prompt,以選擇題的方式創建問答對,然后進行SFT訓練。第1種方法相當于僅把模型當做一個embedding,但這與擅長生成任務的Decoder-Only訓練方式相違背,所以這里不嘗試第1種方法,只實驗第2種方法。 - 訓練框架使用LLama Factory,Prompt模板為:
prompt = """Please read the following news article and determine its category from the options below.Article:
{news_article}Question: What is the most appropriate category for this news article?
A. World
B. Sports
C. Business
D. Science/TechnologyAnswer:/no_think"""answer = "<think>\n\n</think>\n\n{answer_text}"
- 因為
Qwen3為混合推理模型,所以對非推理問答對要在模板最后加上/no_think標識符(以避免失去推理能力),并且回答要在前面加上<think>\n\n</think>\n\n。 - 按照LLama Factory SFT訓練數據的格式要求組織數據,如:
{'instruction': "Please read the following news article and determine its category from the options below.\n\nArticle:\nWall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\\band of ultra-cynics, are seeing green again.\n\nQuestion: What is the most appropriate category for this news article?\nA. World\nB. Sports\nC. Business\nD. Science/Technology\n\nAnswer:/no_think",'output': '<think>\n\n</think>\n\nC'
}
- 訓練參數配置文件:
### model
model_name_or_path: model/Qwen3-0.6B### method
stage: sft
do_train: true
finetuning_type: full### dataset
dataset: agnews_train
template: qwen3
cutoff_len: 512overwrite_cache: true
preprocessing_num_workers: 8### output
output_dir: Qwen3-0.6B-Agnews
save_strategy: steps
logging_strategy: steps
logging_steps: 0.01
save_steps: 0.2
plot_loss: true
report_to: tensorboard
overwrite_output_dir: true### train
per_device_train_batch_size: 12
gradient_accumulation_steps: 8
learning_rate: 1.2e-5
warmup_ratio: 0.01
num_train_epochs: 1
lr_scheduler_type: cosine
bf16: true
-
因為
Bert在訓練2個epoch后就出現了嚴重的過擬合,所以對Qwen3模型,只訓練1個epoch,每0.2個epoch保存一個檢查點。 -
訓練過程中模型對測試集的指標變化(訓練結束后加載檢查點對測試集進行推理,注意!為保證推理結果穩定,我們選擇選項ppl低的作為預測結果):
| Step | Training Loss | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| 250 | 0.026 | 0.912 | 0.917 | 0.912 | 0.912 |
| 500 | 0.027 | 0.924 | 0.924 | 0.924 | 0.924 |
| 750 | 0.022 | 0.937 | 0.937 | 0.937 | 0.937 |
| 1000 | 0.022 | 0.941 | 0.941 | 0.941 | 0.941 |
| 1250 | 0.023 | 0.940 | 0.940 | 0.940 | 0.940 |
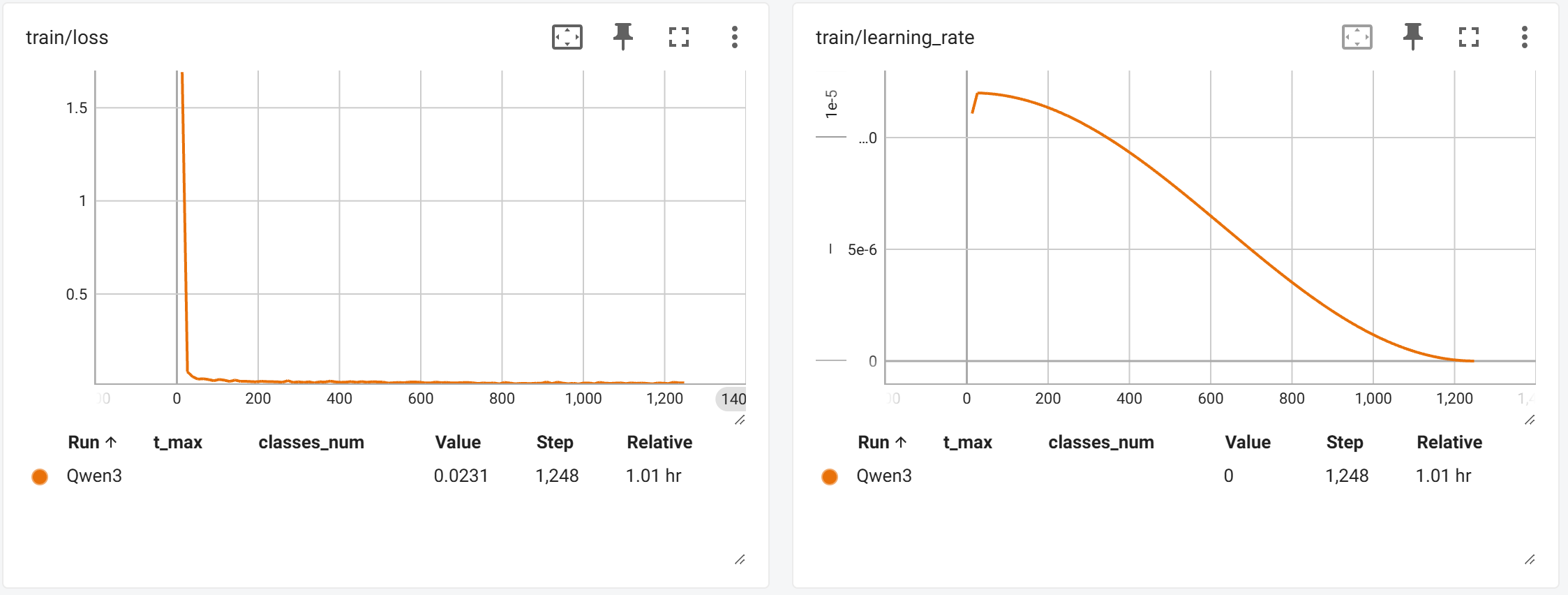
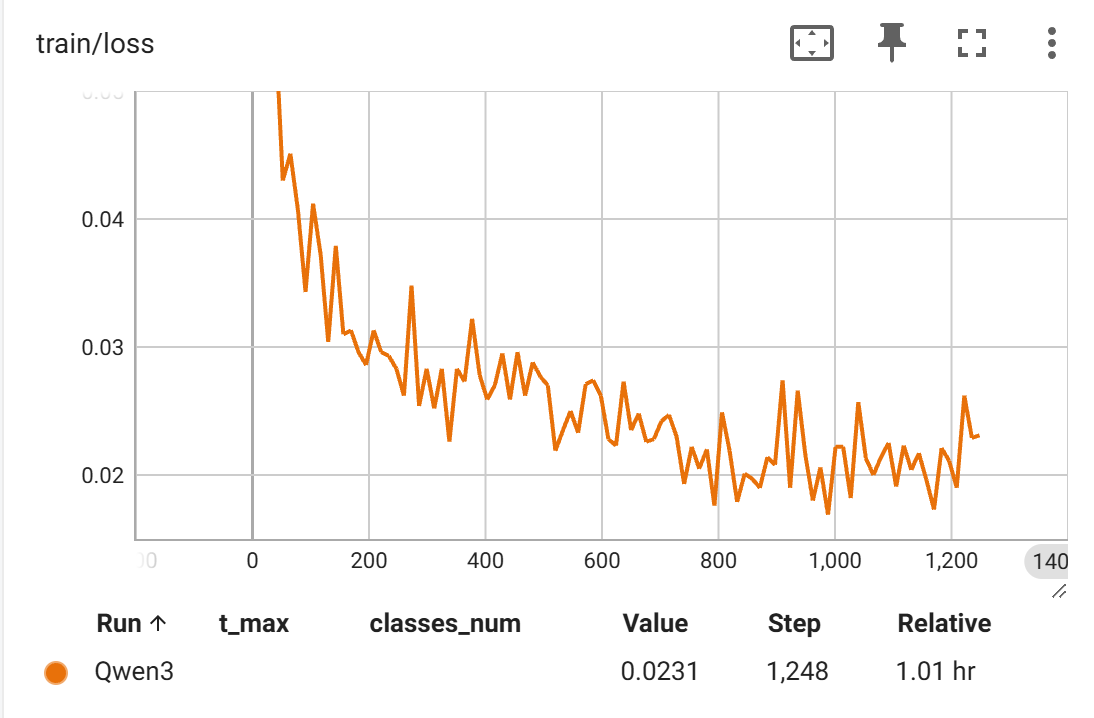
- 可以看到
Qwen3-0.6B模型Loss在一開始就急速下降,然后開始抖動的緩慢下降,如下圖(縱軸范圍調整0.05~0.015)。在測試集上最好結果是:0.941。
Bert和Qwen3-0.6B RPS測試
- 為測試
Bert和Qwen3-0.6B是否滿足實時業務場景,對微調后的Bert和Qwen3-0.6B進行RPS測試,GPU為RTX 3090(24G):
| 模型 | 推理引擎 | 最大輸出Token數 | RPS |
|---|---|---|---|
| Bert | HF | - | 60.3 |
| Qwen3-0.6B | HF | 8 | 13.2 |
| Qwen3-0.6B | VLLM | 8 | 27.1 |
結論
Qwen3-0.6B在Ag_news數據集上并未超過Bert模型,甚至還略遜色于Bert。Qwen3-0.6B似乎非常容易過擬合,前期Loss呈現斷崖式下降。Qwen3-0.6B訓練1個epoch耗時1個3090GPU時(使用HF推理引擎測試耗時0.5個3090GPU時),Bert訓練5個epoch+10次測試集推理共耗時1個3090GPU時。也就是Qwen3-0.6B訓練和推理共耗時1.5 GPU時,Bert訓練和推理共耗時1 GPU時。Bert訓練明顯快于Qwen3-0.6B。Bert的RPS是Qwen3-0.6B(VLLM推理引擎)的3倍。
實驗局限性
- 未實驗在
Think模式下Qwen3-0.6B的效果(使用GRPO直接訓練0.6B的模型估計是不太行的,可能還是先使用較大的模型蒸餾出Think數據,然后再進行SFT。或者先拿出一部分數據做SFT,然后再進行GRPO訓練(冷啟動))。 - 未考慮到長序列文本如
token數(以Bert Tokenizer為標準)超過1024的文本。 - 也許因為
AgNews分類任務比較簡單,其實不管是Bert還是Qwen3-0.6B在F1超過0.94的情況下,都是可用的狀態。Bert(F1:0.945)和Qwen3-0.6B(F1:0.941)的差距并不明顯。如果大家有更好的開源數據集可以用于測試,也歡迎提出。
okenizer為標準)超過1024`的文本。 - 也許因為
AgNews分類任務比較簡單,其實不管是Bert還是Qwen3-0.6B在F1超過0.94的情況下,都是可用的狀態。Bert(F1:0.945)和Qwen3-0.6B(F1:0.941)的差距并不明顯。如果大家有更好的開源數據集可以用于測試,也歡迎提出。 - 未對兩模型進行細致的參數調整。
- 未測試兩模型在中文文本分類任務中的表現。


KV緩存(2))
)




![P1009 [NOIP 1998 普及組] 階乘之和](http://pic.xiahunao.cn/P1009 [NOIP 1998 普及組] 階乘之和)
)



:菜單管理)





