前言:
本章介紹了計算機識別超分領域和目標檢測領域中常常使用的兩種卷積變體,亞像素卷積(Subpixel Convolution)和可形變卷積(Deformable Convolution),并給出對應pytorch的使用。

亞像素卷積(Subpixel Convolution):
由低維特征圖還原為高維特征圖,在上一章已經介紹了一種常用方法:轉置卷積,鏈接如下:深度學習(第2章——卷積和轉置卷積)_轉置卷積層-CSDN博客![]() https://blog.csdn.net/wlf2030/article/details/147479684?spm=1001.2014.3001.5502
https://blog.csdn.net/wlf2030/article/details/147479684?spm=1001.2014.3001.5502
但轉置卷積的核心為填充0或雙線性插值再正向卷積,這種做法會導致最后還原的圖像出現棋盤偽影(可以通過設置卷積核整除步長或插值上采樣緩解)。
亞像素卷積也是一種上采樣方法,其核心操作為重新排列多個特征圖的單個像素轉化為上采樣特征圖的亞像素,下面圖可以直觀展現這一過程。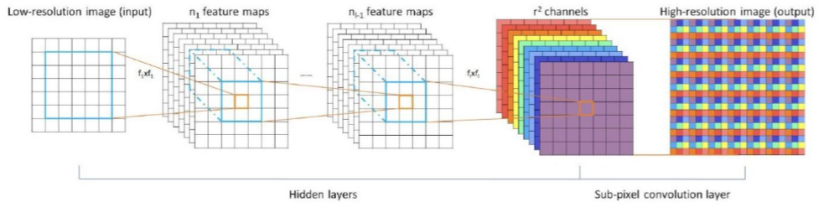
也可借助代碼理解。
import torch
import torch.nn as nn
r = 2 # 上采樣倍率
PS = nn.PixelShuffle(r) # 初始化亞像素卷積操作
x = torch.arange(3*4*9).reshape(1, 3*(r**2),3, 3) #3通道 r*r表示每個像素對應特征圖像素數目,特征圖長寬
print(f'*****************************************')
print(f'input is \n{x}, and size is {x.size()}')
y = PS(x) # 亞像素上采樣
print(f'*****************************************')
print(f'output is \n{y}, and size is {y.size()}')
print(f'*****************************************')
print(f'upscale_factor is {PS.extra_repr()}')
print(f'*****************************************')
使用torch官方提供的已經定義好的亞像素卷積層,形參為上采樣倍數。這里的含義為將一個12通道的3*3的特征圖上采樣還原為一個3通道6*6的特征圖,程序輸出如下:
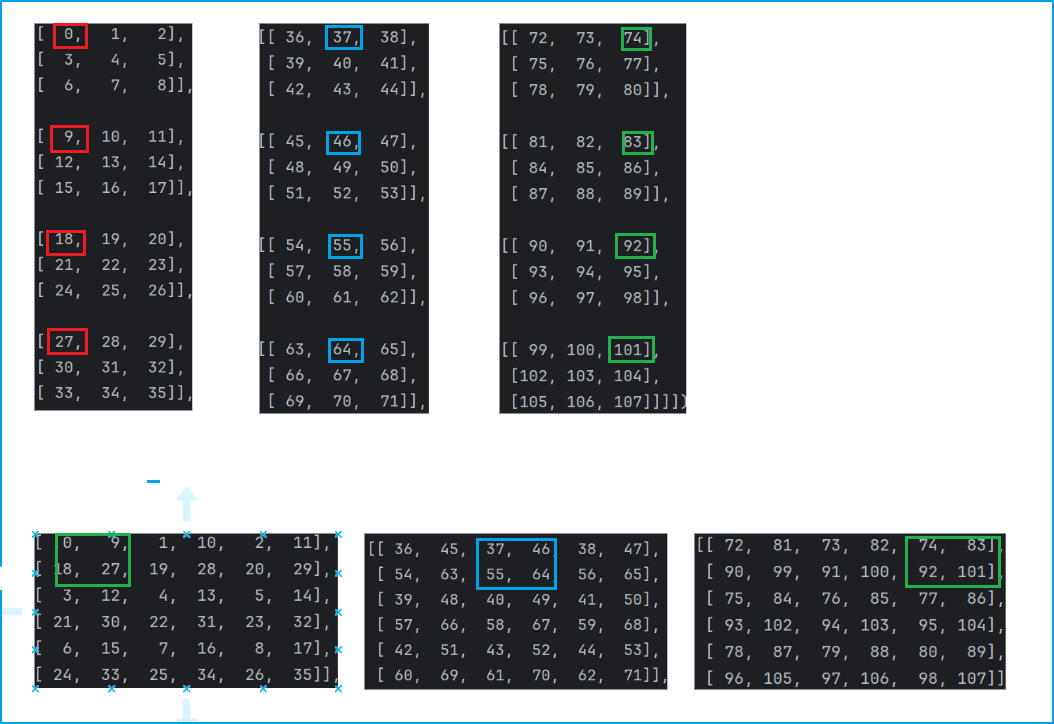
![]() 變為了
變為了![]()
可形變卷積(Deformable Convolution):
傳統卷積使用卷積核滑動遍歷圖片在目標檢測的目標發生扭曲時效果較差,原因在于傳統卷積固定了位置相對關系,比如對于溜冰鞋的目標檢測,卷積層可能提取的特征為在輪子上的鞋子,但當圖片反轉時變成了輪子在鞋子上方就有可能無法檢測到。為了解決相對位置變化對卷積提取的影響,可形變卷積引入一個可學習的偏移矩陣,從而能夠輸入內容動態調整卷積的位置,自適應地捕捉復雜空間變形。傳統卷積操作作用為學習卷積區域的特征,而引入的偏置矩陣用于學習應該使用哪些位置的像素做卷積。
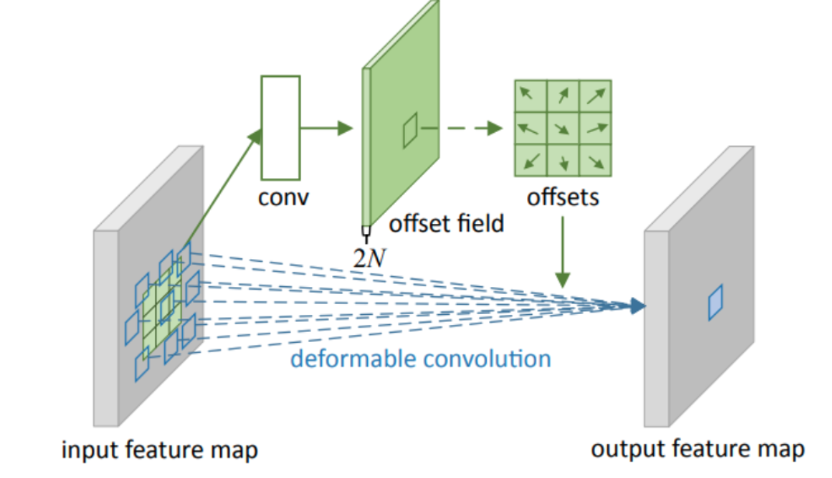
核心注意點:
1.偏移矩陣是針對每次卷積操作卷積核上獲取對應每個像素的x,y坐標偏移量。
2.由于偏移矩陣不可能每輪訓練最終像素都剛好為整數,所以需要使用雙線性插值獲取發生小數偏移對應位置的像素。
3.可形變卷積相當于在傳統卷積前做了一步位置映射操作,其余部分不變。
結合代碼:
import torch
import torch.nn as nn
from torchvision.ops import DeformConv2d# 定義可變形卷積層
class DeformableConv(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3):super().__init__()# 偏移量生成層(學習"Where")self.offset_conv = nn.Conv2d(in_channels,2 * kernel_size * kernel_size, # 2N offsetskernel_size=kernel_size,padding=kernel_size // 2,)# 可變形卷積層(學習"What")self.deform_conv = DeformConv2d(in_channels,out_channels,kernel_size=kernel_size,padding=kernel_size // 2)def forward(self, x):# 生成偏移量offsets = self.offset_conv(x) # [B, 2N, H, W]print(offsets.shape)# 應用可變形卷積return self.deform_conv(x, offsets) # 同時利用卷積核權重和偏移量# 定義輸入 (batch=1, channels=1, height=4, width=4)
input = torch.tensor([[[[1., 2., 3., 4.],[5., 6., 7., 8.],[9., 10., 11., 12.],[13., 14., 15., 16.]]
]], requires_grad=True) # 需要梯度以支持反向傳播
print("Input shape:", input.shape) # [1, 1, 4, 4]dcn = DeformableConv(in_channels=1, out_channels=1, kernel_size=3)
print(dcn(input))
這里是使用一層傳統卷積(offset_conv)獲取偏移量矩陣,輸入通道即為整個可形變卷積層的輸入通道,輸出通道固定為2倍后續傳統卷積的卷積核大小,2表示獲取x,y軸上的偏移,如果是1則只能獲取單個方向的偏移,乘卷積核大小是應為原本傳統卷積對輸入特征圖的一個像素進行卷積是需要計算卷積核大小的數據,當然卷積核中每個像素都需要一對(x,y)的偏移。而獲取偏移量大小的卷積層卷積核大小沒有固定要求,這里建議保持和后續傳統卷積的卷積核大小相同,但padding一定需要保證為設置的卷積核//2(即保證輸入輸出的特征圖大小相同,否則會導致原特征圖的像素1對1映射關系錯誤),同時使用torch定義好的可形變卷積,其作用在于設置偏移量矩陣后完成后續的雙線性插值以及對偏移映射后的矩陣進行傳統卷積,其在設置偏移量=0時數學等價于傳統卷積(實際上仍然會執行雙線性插值可能造成誤差)。
最后輸出如下:
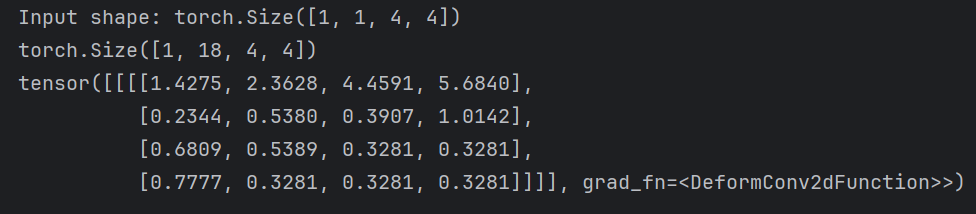
注意訓練時訓練的是提取偏移量的傳統卷積層卷積核參數(而非直接訓練每個特征圖的坐標偏移,坐標偏移實際是由這層卷積獲取的,否則只訓練坐標偏移參數最終相當于仍然固定了映射關系和傳統卷積沒有任何差異,只有訓練卷積核才能讓模型知道對于一張特征圖應當采用怎樣的偏置,以及也可以疊加獲取offset矩陣的層數,這里只使用了一層卷積,從而獲得更好的泛化能力)+可形變矩陣部分的卷積核參數,如果理解這段話的含義,便可以說理解了可形變卷積的核心。
最后:
? ? ? ? 目前本人研究方向有超分,目標檢測和重識別,對上述方向感興趣的小伙伴可以關注,后續會更新以上知識以及相關論文。

)

對比)















