背景
在上個月,有網頁咨詢我怎么才能獲取視頻中的音頻并識別成文本,我當時給他的回答是去問一下AI,讓AI來給你答案。
他覺得我在敷衍他,大罵了我一頓,大家覺得我的回答對嗎?
小編心里委屈,我覺得現在這個時代,什么問題都可以先咨詢AI,實在沒思路了再咨詢專業的人。
歷程
作為一個在軟件開發行業摸爬滾打多年的老碼農,這種工具肯定還是能手到擒來的。
說實話,之前沒想過這個問題,因為從來沒做過音視頻相關的項目,對這方面的知識了解不多。只知道直播行業對這方面的知識要求比較高。
遇事不決,先問AI。
由于之前了解過ffmpeg用這個工具獲取過視頻的時長,對此這個工具有基本的認知。
這里我們打開熱門的AI IDE Trae,直接用Builder模式問一下一般處理音視頻用技術方案,并讓他寫出Markdown文檔。
按照我的要求,給出了獨立的md文檔。
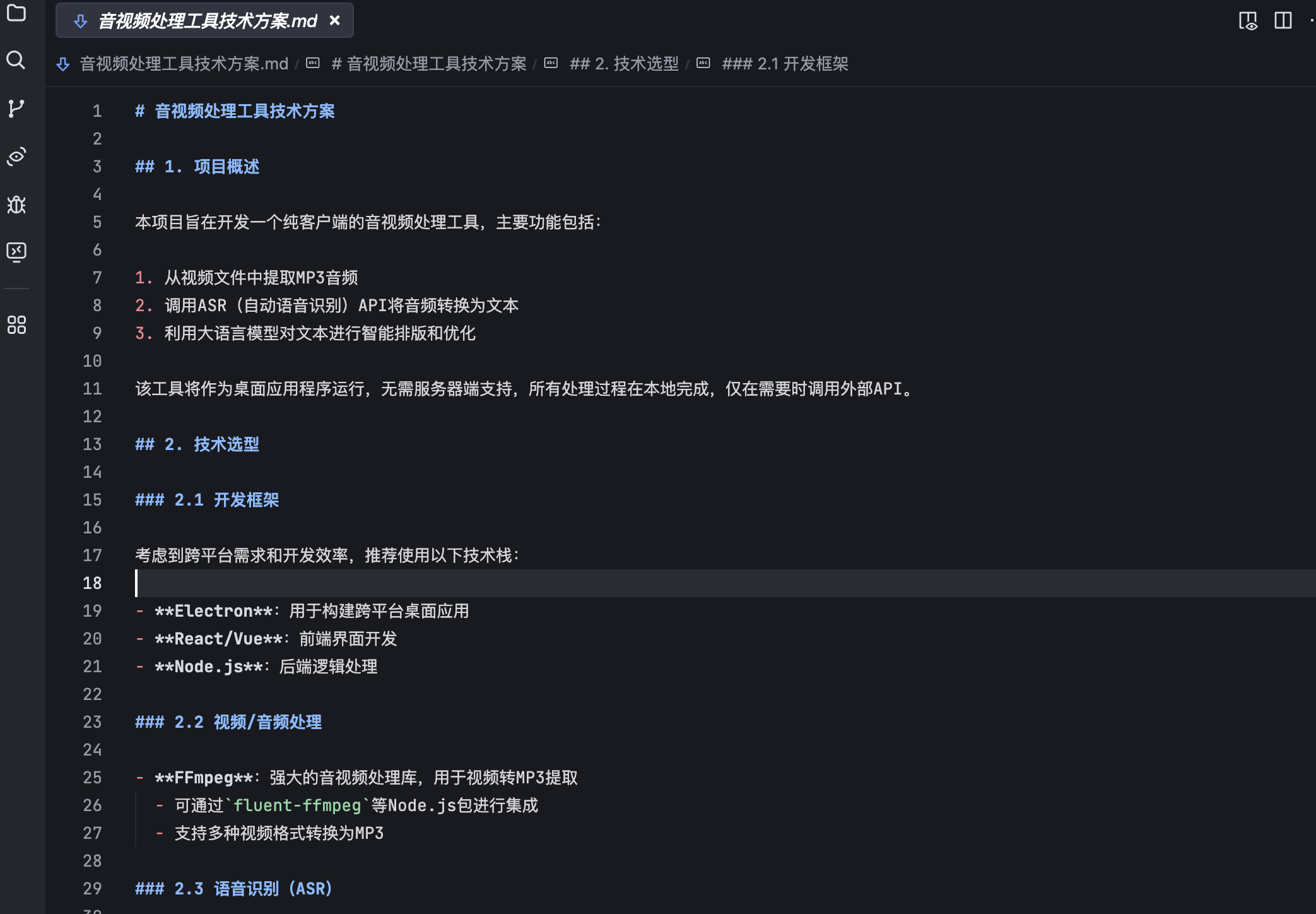
大體的瀏覽了一下,文檔給出的還是不錯的。
能給出具體的技術方案,并給出開發框架的選擇。可以說文檔的質量還是不錯的。修改一下不滿足的地方,可以作為實現的技術文檔。
技術方案最終用的Electron來實現,這是比較熱門的桌面端開發框架。
VSCode、Cherry Studio。
接下來就是讓AI自己按照文檔的要求實現了,實現的第一版,AI用簡單的樣式實現了。
第一版相對來說頁面看起來不美觀,又讓ai用UI組件Element-Plus來實現。
最后的版本是這樣的布局。
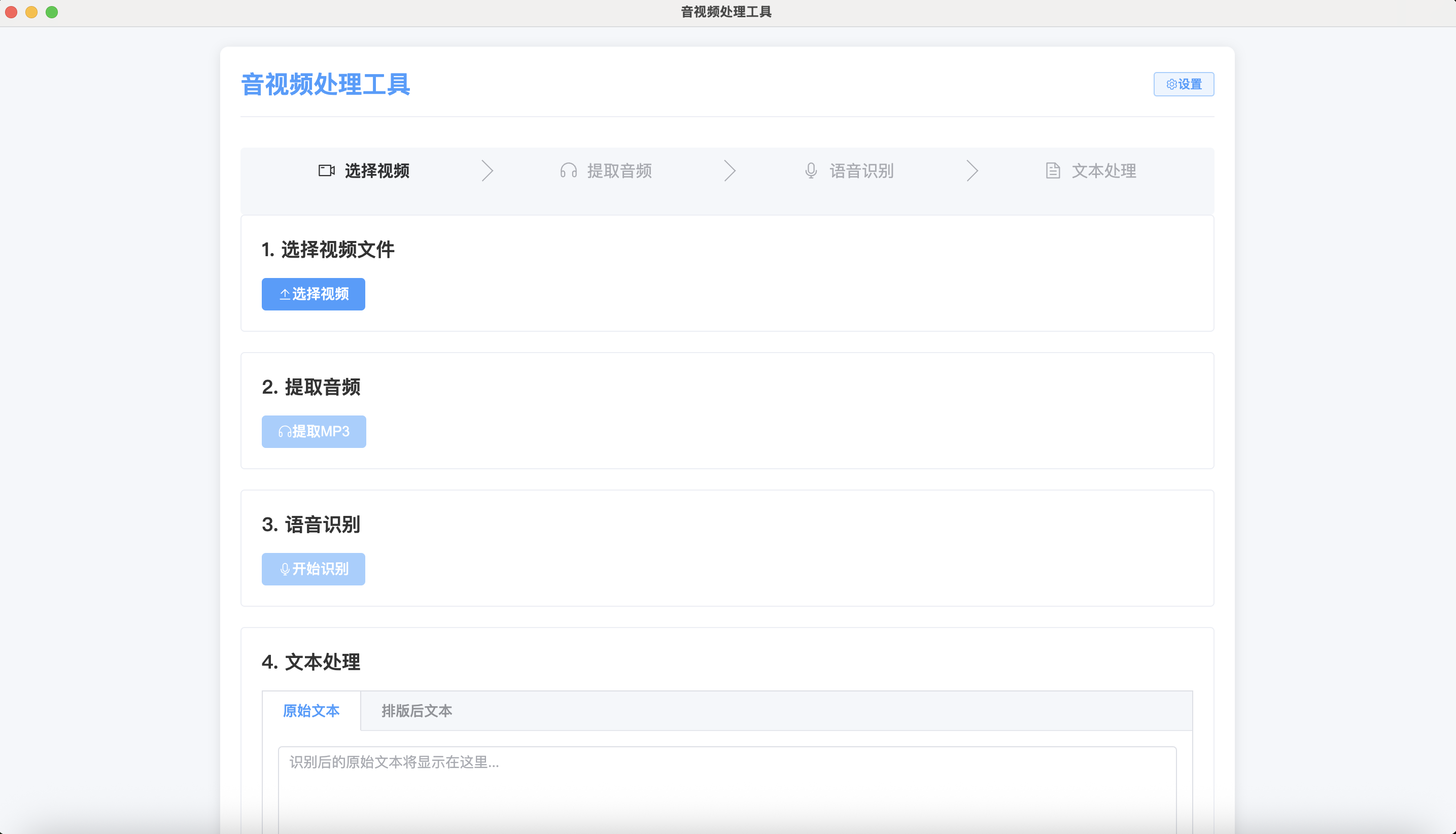
相對來說還是比較簡約的,畢竟功能簡單。沒有太多的實現。如果要添加功能可以在左側增加一個側邊欄。
對于我來說夠用了。
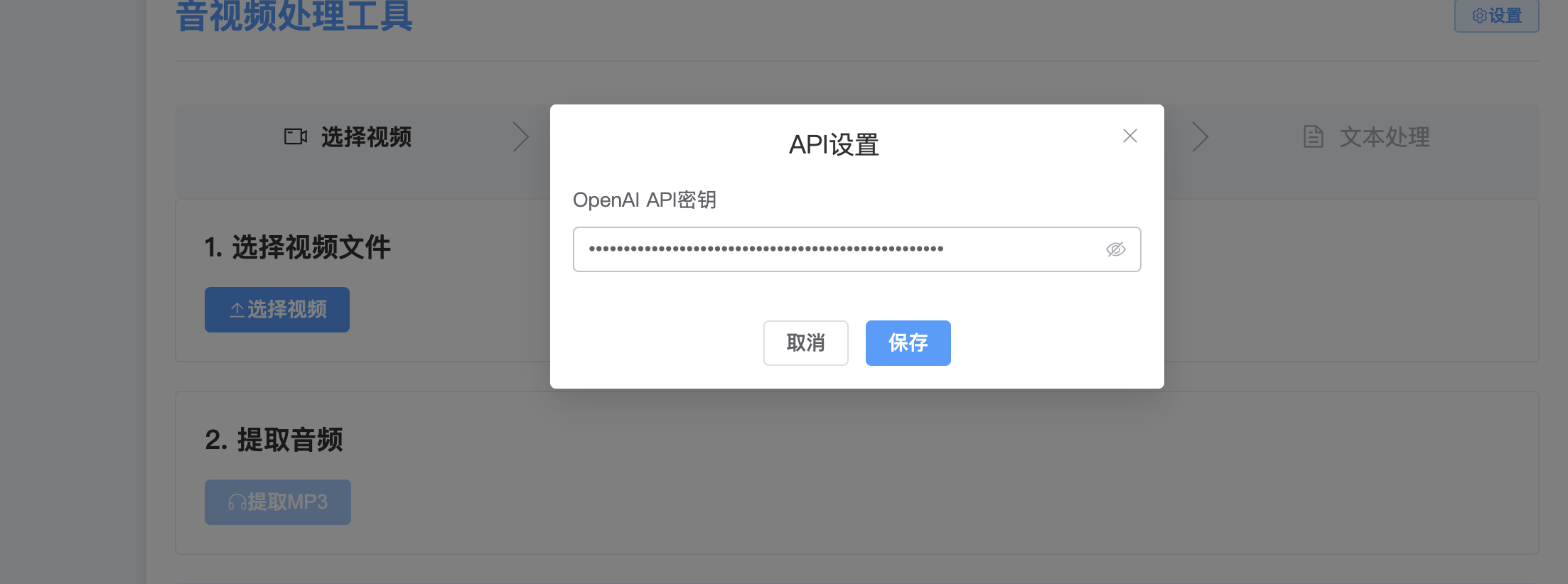
這里設置密鑰,使用了硅基流動的FunAudioLLM/SenseVoiceSmall模型進行的獲取,目前這個模型還是免費的,質量不錯。
最后
看來我沒有騙那個網友,用AI確實能解決他的問題。
技術棧
- Electron
- Element-Plus
- NodeJs
- ffmpeg




![P2572 [SCOI2010] 序列操作 Solution](http://pic.xiahunao.cn/P2572 [SCOI2010] 序列操作 Solution)

)


:集群安全加固全攻略)






)


