作者:阿里云開發者
原文:https://zhuanlan.zhihu.com/p/1903437079603545114?
一、Introduction
過去一年可謂是RAG元年,檢索增強生成技術迅速發展與深刻變革,其創新與應用已深刻重塑了大模型落地的技術范式。站在2025年,RAG不僅突破了早期文本處理的局限,更通過多模態融合、混合檢索優化和語義鴻溝跨越等突破,開始在各個行業落地。如果把2024之前的RAG稱為RAG 1.0,那目前已進入RAG 2.0時代。
一個顯著的進步是長上下文窗口,這一功能引發了爭議,但到年中逐漸平息。很多人覺得長上下窗口就夠了,傳統的檢索和RAG會被取代。此外,LLMOps?等架構的成熟使企業和個人能夠使用矢量數據庫、嵌入/重新排名模型、分塊工具、Multimodal技術的快速發展。RAG方面的Paper每周達到幾十篇甚至更多。可以說,RAG經歷了野蠻快速生長的RAG,從1.0超快速的進入了2.0時代。
RAG越來越多的應用在企業和生產場景,但是仍面臨很多的技術挑戰,本文我們從RAG 2.0 面臨的主要挑戰和部分關鍵技術來展開敘事。首先快速過一下RAG 2.0的主要問題:
多模態與復雜任務擴展
- 多模態支持不足:當前的RAG技術主要針對文本數據,但在處理圖像、視頻等多模態數據時仍面臨挑戰。例如,如何有效檢索和利用多模態信息仍是一個開放性問題。現有 LLMOps 解決方案大多限于純文本場景。PDF、PPT 或文本與圖像結合的文檔無法充分發揮其商業潛力。這些類型的文檔通常構成企業數據中的大多數。
- 復雜推理任務:盡管RAG通過檢索外部知識增強了模型的推理能力,但在處理多跳推理或復雜邏輯任務時,其性能仍有待提升。
檢索質量與噪聲問題
- 檢索精度不足:RAG的性能高度依賴于檢索到的文檔質量。如果檢索到的文檔與查詢不相關或包含噪聲信息,會導致生成結果不準確甚至錯誤。
- Semantic GAP:RAG 的核心在于搜索功能。只有能夠根據用戶的查詢“搜索”答案時,它才能發揮作用。然而,這一先決條件往往無法滿足,因為查詢模糊或含糊,缺乏明確的意圖,或者“多跳”問題需要從多個子問題中綜合而來。在這種情況下,提出的問題和檢索到的答案之間存在顯著的語義差距,這使得傳統的搜索方法無效。
- 噪聲數據的影響:文檔中的噪聲信息可能混淆模型的推理路徑,導致生成內容出現偏差。例如,過時或不準確的信息會誤導模型,降低生成結果的可信度。
- 召回率低:在某些情況下,RAG可能無法檢索到所有相關文檔,導致生成模型缺乏足夠的背景信息來構造完整的答案。比如,純向量數據庫導致召回率和命中率偏低:單純依賴向量數據庫會導致召回率和命中率偏低,阻礙有效的現實問答。這是因為向量表示無法精確地表示準確的信息,并且在檢索過程中會造成語義損失。
生成過程中的幻覺與冗余
- 幻覺問題:盡管RAG通過檢索外部知識減少了模型生成幻覺的概率,但在檢索信息不足或相關性較低時,模型仍可能生成虛構或不準確的內容[6]。
- 冗余與重復:當檢索到的文檔包含相似信息時,生成內容可能出現冗余或重復,影響回答的質量和簡潔性。
計算資源與效率問題
- 計算資源消耗:RAG需要額外的計算資源來支持檢索機制和數據庫維護,如向量化模型和向量知識庫的構建與更新[6]。
- 推理延遲:由于增加了檢索步驟,RAG的推理時間可能比傳統LLM更長,尤其是在處理復雜查詢時[6]。
- 實時性要求:RAG需要實時檢索最新信息,但知識庫的更新頻率和檢索效率可能無法滿足高實時性需求。
安全與隱私問題
- 數據安全:RAG需要訪問外部知識庫,這可能涉及敏感數據。如何確保數據的安全性和隱私性是一個重要挑戰[8]。
- 對抗性攻擊:RAG系統可能受到對抗性數據注入或上下文沖突等攻擊,導致生成內容被操縱或誤導
獎勵函數與訓練機制優化
- 獎勵函數設計:當前的RAG系統通常采用基于結果的獎勵函數,但在復雜任務場景中,這種設計可能無法捕捉細微差異,影響模型性能[1]。
- 訓練數據依賴:RAG的訓練需要高質量的交互數據,但獲取和標注這些數據可能成本高昂且耗時.
二、技術范式的升級
RAG從最初概念誕生到現在,架構經歷了三個階段演化:基礎檢索生成(Naive RAG)→ 檢索全流程優化(Advanced RAG)→ 具備反思能力的模塊化系統(Modular RAG)。其中模塊化架構通過LLM的遞歸調用實現動態檢索決策,例如讓模型自主判斷何時觸發檢索或修正答案,形成類Agent的交互范式。具體可以看下圖,細節在此不表,重點關注核心技術。
其實不管哪種范式,其本質都是搜索 + LLM的融合,所有核心技術的其實都是搜索和大模型的技術的變革。

三、關鍵技術
3.1 檢索技術
3.1.1 混合搜索
前面提到過目前RAG的Retrieval存在一些弊端,比如召回率低,準確率低,噪聲大,存在冗余查詢,效率和魯棒性差等。因此我們需要Hybrid Search。目前比較通用的混合搜索是三路混合檢索:全文搜索 with BM25 + 稠密向量(語義匹配) + 稀疏向量(關鍵詞增強)。首先我們先簡單介紹一下這集中檢索方式:
全文索引
常使用倒排索引(Inverted Index)等技術,將文檔中的每個單詞映射到包含該單詞的文檔列表,從而實現高效的查詢。查詢速度快,適合精確匹配。支持復雜的查詢語法(如布爾查詢、通配符查詢)。缺點是無法理解語義,僅依賴字面匹配。對同義詞、語義相似性等處理能力有限,當然這可以通過歸一化等預處理來解決。相關性排序,常用算法為BM25算法,基于詞頻、文檔長度和逆文檔頻率的綜合評分。
BM25(Best Matching 25)是一種基于概率模型的文檔相關性評分算法,廣泛用于全文搜索引擎中,用于衡量查詢(Query)與文檔(Document)之間的匹配程度。它是傳統TF-IDF算法的改進版本,尤其在處理文檔長度和詞頻分布上表現更優。BM25通過結合詞頻、逆文檔頻率和文檔長度歸一化,提供了一種高效評估文檔與查詢相關性的方法,具有高效、靈活和魯棒的特點。BM25因其簡潔性和高效性,至今仍是文本檢索的基石技術,尤其在需要快速響應和可解釋性的場景中不可替代。
Sparse vector search
稀疏檢索是一種基于稀疏向量的搜索技術,通常用于傳統的信息檢索任務。稀疏向量是指向量中大部分元素為零,只有少數元素非零。使用詞袋模型(Bag of Words, BoW)或 TF-IDF 等方法將文本表示為稀疏向量,然后通過計算向量之間的相似度(如點積)來檢索相關文檔。主要使用在傳統文本檢索(如搜索引擎)。計算效率高,適合大規模數據集,但是無法理解語義。
稀疏向量難以替代全文搜索:稀疏向量旨在替代全文搜索,其方法是使用標準預訓練模型消除冗余詞并添加擴展詞,從而得到固定維度(例如 30,000 或 100,000 維)的稀疏向量輸出。這種方法在一般查詢任務上表現良好;但是,許多用戶查詢關鍵字可能不存在于用于生成稀疏向量的預訓練模型中,例如特定的機器模型、手冊和專業術語。因此,雖然稀疏向量和全文搜索都服務于精確召回的目的,但它們各有千秋,無法互相替代。
Vector Search
Vector search 是一種基于向量空間模型的搜索技術,將數據(如文本、圖像、音頻)轉換為高維向量(通常是稠密向量),并通過計算向量之間的相似度(如余弦相似度或歐氏距離)來找到最相關的結果。利用機器學習模型(如深度學習)將數據映射到向量空間,語義相近的數據在向量空間中距離較近。主要應用場景是語義搜索(Semantic Search):理解查詢的語義,而不僅僅是關鍵詞匹配。能夠捕捉語義信息,支持模糊匹配。適合處理非結構化數據(如文本、圖像)。但是需要預訓練模型生成向量,計算復雜度較高。對硬件資源(如GPU)要求較高。

采用多種召回方法可以為 RAG 帶來更好的結果。具體來說,將向量搜索、稀疏向量搜索和全文搜索結合起來可以實現最佳召回率。這很容易理解,因為向量可以表示語義;一個句子甚至整篇文章都可以封裝在一個向量中。本質上,向量傳達了文本的“含義”,表示其與上下文窗口內其他文本共現的壓縮概率。因此,向量無法精確表示查詢。例如,如果用戶問:“我們公司 2024 年 3 月的財務計劃包括哪些組合?”結果可能會返回來自其他時間段的數據或不相關的主題,例如運營計劃或營銷管理。相比之下,全文搜索和稀疏向量主要表達精確的語義。因此,將這些方法結合起來可以滿足我們日常對語義理解和精度的需求。

下圖顯示了使用 Infinity 在公共基準數據集上進行評估的結果,比較了單向召回方法(向量、稀疏向量、全文搜索)、雙向召回和三向召回。縱軸表示排序質量,很明顯三向召回取得了最佳結果,充分驗證了 BlendedRAG 的效果。

目前的混合搜索架構中,不同的數據存儲和檢索大都是通過異構數據庫和存儲介質來實現的,這會帶來效率和精準度的問題,因此同時支持多種檢索的數據庫顯得尤為重要,但是有較大挑戰,目前市面上實現此類功能的數據庫有Milvus(支持多模態向量+標量過濾) , Weaviate(內置混合搜索)。
3.1.2?DPR(Dense Passage Retrieval)
在RAG(Retrieval-Augmented Generation,檢索增強生成)系統中,DPR(Dense Passage Retrieval,稠密段落檢索)是檢索模塊的核心技術之一。DPR通過使用密集向量表示來檢索與查詢最相關的文檔或段落,是RAG系統的重要基礎。由 Facebook AI Research 團隊在2020年首次提出。
DPR是一種基于深度學習的檢索方法,專注于將查詢(query)和文檔(passage)編碼為稠密向量,并通過計算向量之間的相似度來檢索與查詢最相關的文檔。DPR是稠密向量檢索在段落檢索任務中的一個具體實現,它利用深度學習模型將查詢和文檔編碼為稠密向量,并通過相似度計算來檢索相關文檔。
DPR的核心功能
1. 雙編碼器架構:DPR采用雙編碼器架構,分別對查詢和文檔進行編碼,將它們映射到高維向量空間中。通過計算查詢向量和文檔向量之間的相似度(如內積),DPR能夠高效地檢索出與查詢最相關的文檔。
2. 語義匹配:與傳統的稀疏檢索方法(如BM25)不同,DPR能夠捕捉查詢和文檔之間的語義相似性,而不僅僅是關鍵詞匹配。這使得DPR在處理復雜的自然語言查詢時表現出色。
3. 高效檢索:DPR利用密集向量表示和高效的最近鄰搜索算法(如MIPS,Maximum Inner Product Search),能夠快速從大規模知識庫中檢索出相關文檔。
DPR作為RAG系統中的檢索器,負責從外部知識庫中檢索與用戶查詢最相關的文檔或段落。這些檢索到的文檔隨后被送至生成模塊,生成模塊利用這些文檔生成高質量、上下文相關的回答。DPR的高效語義檢索能力顯著提升了RAG系統在開放域問答等任務中的表現。
盡管DPR已經取得了顯著的成果,但仍有改進空間。例如,DPR訓練過程中的知識分散化(decentralization)可以進一步優化,以提高檢索的多樣性和準確性。此外,研究者們也在探索如何更好地將DPR與預訓練語言模型結合,以進一步提升檢索和生成的性能。
3.2 重排序 Ranking Models
我們前面講過,三路召回(BM25 + 稠密向量 + 稀疏向量)效果最優,但如何高效融合多路結果并重排序(Reranking)仍是難題。
排名是任何搜索系統的核心。排名涉及兩個組件:一個是用于粗過濾的部分也就是粗排;另一個是用于微調階段的重排序模型也叫重排或者精排。混合檢索能夠結合不同檢索技術的優勢獲得更好的召回結果,但在不同檢索模式下的查詢結果需要進行合并和歸一化(將數據轉換為統一的標準范圍或分布,以便更好地進行比較、分析和處理),然后再一起提供給大模型。這時候我們需要引入一個評分系統:重排序模型(Rerank Model)。
重排序模型會計算候選文檔列表與用戶問題的語義匹配度,根據語義匹配度重新進行排序,從而改進語義排序的結果。其原理是計算用戶問題與給定的每個候選文檔之間的相關性分數,并返回按相關性從高到低排序的文檔列表。常見的 Rerank 模型如:Cohere rerank、bge-reranker 等。

不過,重排序并不是只適用于不同檢索系統的結果合并,即使是在單一檢索模式下,引入重排序步驟也能有效幫助改進文檔的召回效果,比如我們可以在關鍵詞檢索之后加入語義重排序。
在具體實踐過程中,除了將多路查詢結果進行歸一化之外,在將相關的文本分段交給大模型之前,我們一般會限制傳遞給大模型的分段個數(即 TopK,可以在重排序模型參數中設置),這樣做的原因是大模型的輸入窗口存在大小限制(一般為 4K、8K、16K、128K 的 Token 數量),你需要根據選用的模型輸入窗口的大小限制,選擇合適的分段策略和 TopK 值。
需要注意的是,即使模型上下文窗口很足夠大,過多的召回分段會可能會引入相關度較低的內容,導致回答的質量降低,所以重排序的 TopK 參數并不是越大越好。
在RAG(Retrieval-Augmented Generation)系統中,檢索完成后進行重排序(reranking)的目的是為了提高最終生成結果的質量和相關性。盡管初始檢索階段已經返回了一組相關文檔或段落,但這些結果可能并不完全符合生成模型的需求,或者可能存在排序不合理的情況。重排序可以幫助篩選出最相關、最有用的信息,從而提升生成模型的輸出效果。
接下來我們重點介紹幾種常用的Reranker。
3.2.1 Cross-Encoder Reranker
Cross-Encoder Reranker 是一種基于深度學習的重排序模型,通過聯合編碼查詢-文檔對(將查詢和文檔拼接后輸入模型)直接預測相關性分數,而非生成獨立向量。其核心是利用交叉編碼器(Cross-Encoder)架構來評估查詢(query)和文檔(document)對之間的相似度。與雙編碼器(Bi-Encoder)不同,交叉編碼器不是分別對查詢和文檔進行編碼,而是將查詢和文檔作為一個整體輸入到模型中,從而能夠更有效地捕獲兩者之間的交互和關系。這種架構通常由多層神經網絡單元組成,例如Transformer或循環神經網絡(RNN),能夠將輸入序列中的信息編碼為固定大小的表。比傳統向量檢索更精準,能捕捉深層次語義關系。它通過端到端分類任務(如二元相關性判斷)優化,適合對Top-K候選文檔進行精排。代表模型有<font style="color:rgb(64, 64, 64);">BAAI/bge-reranker-large</font>。
Cross-Encoder可以與延遲交互(Late Interaction)結合,如本文前面提到過的ColPali(多模態RAG場景),通過分解查詢-文檔交互矩陣為多向量外積,實現高效語義排序,同時保留細粒度交互能力。
在效率方面,可以將大型Cross-Encoder(如BERT-large)蒸餾為輕量級模型(如TinyBERT),或采用FP16/INT8量化降低推理延遲。這些都是比較通用的方法,在此不表。
使用示例:
import numpy
import lancedb
from lancedb.embeddings import get_registry
from lancedb.pydantic import LanceModel, Vector
from lancedb.rerankers import CrossEncoderRerankerembedder = get_registry().get("sentence-transformers").create()
db = lancedb.connect("~/.lancedb")class Schema(LanceModel):text: str = embedder.SourceField()vector: Vector(embedder.ndims()) = embedder.VectorField()data = [{"text": "hello world"},{"text": "goodbye world"}
]tbl = db.create_table("test", schema=Schema, mode="overwrite")
tbl.add(data)reranker = CrossEncoderReranker()# Run vector search with a reranker
result = tbl.search("hello").rerank(reranker=CrossEncoderReranker()).to_list()3.2.2?Graph-Based Reranking
當前主流RAG系統遵循"檢索-排序-生成"的線性流程,其中重排序環節通常采用兩類方法:(1) 基于獨立編碼的交叉注意力模型(如MonoT5),單獨評估每個文檔與查詢的相關性;(2) 基于列表級損失的排序模型(如ListNet),優化整個文檔序列的排列。這兩種范式都存在根本性局限——它們將文檔視為孤立的個體,完全忽視了文檔間豐富的語義關聯,導致三個關鍵問題:
1. 信息整合失效:當答案需要綜合多篇文檔信息時(如對比型問題"比較A與B的優缺點"),獨立排序可能將與A、B分別相關但單獨評分不高的文檔排在后位,而實際上這些文檔的組合才最具回答價值[2][3]。
2. 冗余放大效應:高度相似的多篇文檔可能因獨立評分都較高而同時位居前列,擠占其他重要但獨特信息的展示空間。論文圖1展示了傳統方法在HotpotQA數據集上出現的典型冗余案例,前5篇文檔中有3篇內容重疊度超過70%。
3. 關系認知盲區:現有系統無法識別文檔間的因果、時序、對比等邏輯關系,而這些關系往往是解答復雜問題的關鍵。例如回答"COVID-19如何導致經濟衰退"需要串聯病因學文檔與經濟分析文檔,盡管它們的主題相似度可能很低。
更本質地,這些問題的根源在于傳統排序將文檔視為獨立同分布樣本,而現實中文檔間存在復雜的條件依賴關系。該論文首次提出將文檔集合建模為圖結構,其中節點表示文檔,邊表示語義關系,通過圖算法挖掘全局結構信息來指導排序決策。
現有RAG系統在處理文檔與問題上下文關系時存在挑戰,當文檔與問題的關聯性不明顯或僅包含部分信息時,模型可能無法有效利用這些文檔。此外,現有方法通常忽視文檔之間的連接,導致無法充分利用文檔間的語義信息。
這篇 Paper 《Don't Forget to Connect! Improving RAG with Graph-based Reranking》該論文提出了一種基于圖的重排方法G-RAG,旨在通過利用文檔之間的連接信息和語義信息,更有效地識別文檔中的有價值信息,從而提高RAG在ODQA中的性能。

關鍵技術
1. 圖結構構建
- 將檢索到的文檔或文本塊表示為圖中的節點,節點間的邊通過以下方式建立:
- 語義相似性(如向量余弦相似度);
- 實體共現關系(如命名實體在同一文檔中的關聯);
- 邏輯依賴(如文檔間的引用或因果鏈)[2][3]。
- 例如,類似GraphRAG的方法會預生成實體知識圖,并通過社區檢測劃分緊密關聯的節點組。
2. 圖神經網絡架構
基于GNN的架構來重排序檢索到的文檔:
- 節點特征:使用預訓練的語言模型(如BERT)編碼文檔文本,并結合AMR圖中的最短路徑信息來增強這些特征。
框架應用預先訓練的語言模型對給定問題 q 的 {p1,p2,?,pn} 中所有 n
檢索到的文檔進行編碼。文檔嵌入表示為
![]()
,其中 d是隱藏維度,
![]()
的每一行由以下公式給出
![]()
某些負面文檔無法與其文本中的問題上下文建立足夠的聯系。此外,負面文檔還會遇到另一種極端情況,即路徑包含大量與問題文本相關的信息,但缺乏有價值信息。這種獨特的模式提供了有價值的見解,可在編碼過程中利用它們來提高重排器的性能。
因此,建議的文檔嵌入由
![]()
給出,并且
X
的每一行可以由
![]()
給出:
![]()
- 邊特征:利用AMR圖中共同節點和邊的數量作為邊特征。結合了AMR圖,不僅捕捉文檔的語義信息,還通過圖結構增強了文檔之間的語義關聯。
- 表示更新:通過GNN模型更新節點和邊的表示,利用消息傳遞機制傳遞信息。
3. 圖算法重排序
- 采用個性化PageRank或社區影響力評分對節點(文檔)進行重要性排序,優先選擇圖中中心性高或與問題節點連接緊密的文檔。
- 類似R4框架的圖注意力機制,學習文檔間的交互關系以優化順序。
- 通過多跳推理挖掘間接關聯的文檔(如RAE框架的鏈式檢索策略)。
4. 動態響應生成
- 對重排序后的文檔集,分兩步生成答案:
1)局部響應生成:每個高權重文檔或社區摘要獨立生成部分答案;
2)全局整合:通過LLM對局部響應去冗余并合成最終答案。
- 類似HippoRAG的神經啟發方法,模擬人腦記憶整合機制優化知識融合。
5. 端到端優化
- 引入強化學習(如R4的獎勵機制)或輕量級評估器(如CRAG)聯合優化檢索與生成模塊。
3.2.3?ColBERT Reranker
ColBERT(Contextualized Late Interaction over BERT)是一種高效的檢索模型,特別適用于大規模文本集合的檢索任務。它通過延遲交互機制(late interaction architecture)結合BERT的上下文表示,實現了高效的檢索和重排序。這里我們Jina-ColBERT-v2
1. 延遲交互機制(Late Interaction):ColBERT引入了一種延遲交互相似性函數,通過分別對查詢和文檔進行編碼,然后在推理時計算查詢和文檔之間的相似性(MaxSim),從而實現延遲交互。這種方法在保持高效推理的同時,能夠捕捉到查詢和文檔之間的復雜關系。
2. 多向量表示:與傳統的單向量檢索模型不同,ColBERT為查詢和文檔中的每個標記生成一個嵌入向量,然后通過聚合這些標記嵌入來計算相關性分數。這種方法能夠更細致地捕捉文本的語義信息。
3. 多語言預訓練:Jina-ColBERT-v2使用XLM-RoBERTa作為其基礎模型,并通過在多種語言的數據上進行預訓練,提高了模型的多語言性能。
4. 弱監督學習:論文提出在大規模的弱監督文本對上進行預訓練,以學習文本的一般語義結構。這些文本對包括句子對、問答對和查詢-文檔對,涵蓋了多種語言和領域。
5. 三元組訓練:在預訓練的基礎上,模型進一步在多種語言的檢索數據上進行微調,使用標注的三元組數據和硬負樣本進行訓練,以提高檢索性能。
3.3 Multimodal RAG 多模態RAG
目前,多模態檢索增強生成(Multimodal RAG) 已成為 RAG 技術中最前沿和流行的方向之一,它通過整合文本、圖像、音頻、視頻等多種模態數據,顯著提升了 AI 系統的理解和生成能力。
對于多模態文檔,傳統方法是使用模型將多模態文檔轉換為文本,然后再進行索引以供檢索。另一種方法是直接多模態向量化,比如利用 視覺語言模型 VLM,直接生成向量,繞過復雜的 OCR 過程。2024 出現的 ColPali。ColPali 將圖像視為 1024 個圖像塊,并為每個塊生成嵌入,有效地將單個圖像表示為張量。比如:

這意味著 VLM 對圖像的理解更加深入,不再僅僅識別日常物品,而是可以高效識別企業級多模態文檔。例如,來自 Google 的開源 3B 模型 PaliGemma,能夠將圖像塊(Image Patches)嵌入到與文本相似的潛在空間中。ColPali 在此基礎上擴展,通過投影層將模型輸出的高維嵌入降維至 128 維,生成多向量表示(每個圖像塊對應一個向量),從而保留文檔的細粒度視覺信息。借鑒文本檢索模型 ColBERT 的“延遲交互”策略,ColPali 在檢索階段計算查詢文本的每個 token 向量與文檔圖像塊向量的最大相似度(MaxSim),而非傳統的單向量相似度。這種方法避免了早期交互的計算負擔,同時提升了檢索精度。

這種技術的優勢非常明顯,端到端處理復雜文檔,直接輸入文檔圖像(如 PDF 頁面),無需傳統 OCR、文本提取或布局分析等預處理步驟,顯著簡化流程并減少錯誤傳播。還可以實現多模態聯合檢索,通過視覺和文本嵌入的統一表示,模型能同時理解圖表、表格和文本內容。例如,在財務報告或科學論文中,ColPali 可檢索出純文本方法可能遺漏的視覺關鍵信息。
如果我們可以使用 RAG 根據用戶查詢在大量 PDF 中查找包含答案的圖像和文本,那么我們就可以使用 VLM 生成最終答案。這就是多模態 RAG 的意義所在,它不僅僅是簡單的圖像搜索。
檢索過程需要一個 Versatile 的數據庫,不僅支持基于張量的重新排序,而且還能在向量檢索階段容納多向量索引。

在這里我們簡單介紹一下直接多模態向量化和模態轉換。
直接多模態向量化
- 核心思想:
- 使用多模態模型(如CLIP、Flamingo)直接生成跨模態的向量表示,跳過中間文本轉換步驟。
- 核心任務:
- 通過模型(如CLIP、Flamingo)將不同模態數據(圖/文/音)映射到同一向量空間,確保語義相似的輸入(如“狗”的圖片和文本“犬”)向量距離相近。
- 關鍵技術:
- 1)對比學習(Contrastive Learning):如CLIP的圖文對齊訓練。
- 2)共享編碼器(Shared Encoder):同一模型處理多模態輸入。
- 輸出:
- 向量(如512維浮點數組),不直接完成檢索任務。
- 流程

模態轉換,多模態轉文本(Modality-to-Text)
- 技術原理:將非文本模態(如圖像、音頻)轉換為文本描述(如 OCR、ASR、圖像描述生成),再使用傳統文本 RAG 進行檢索和生成。
- 優勢:
- 實現簡單,兼容現有文本 RAG 架構。
- 適用于結構化數據(如表格、PDF)和語音轉文本任務。
- 代表工具:
- BLIP-2(Salesforce):生成高質量的圖像描述。
- Whisper(OpenAI):語音轉文本(ASR)。
- 流程

多模態轉文本(Modality-to-Text)和直接多模態向量化(Direct Multimodal Embedding)對比
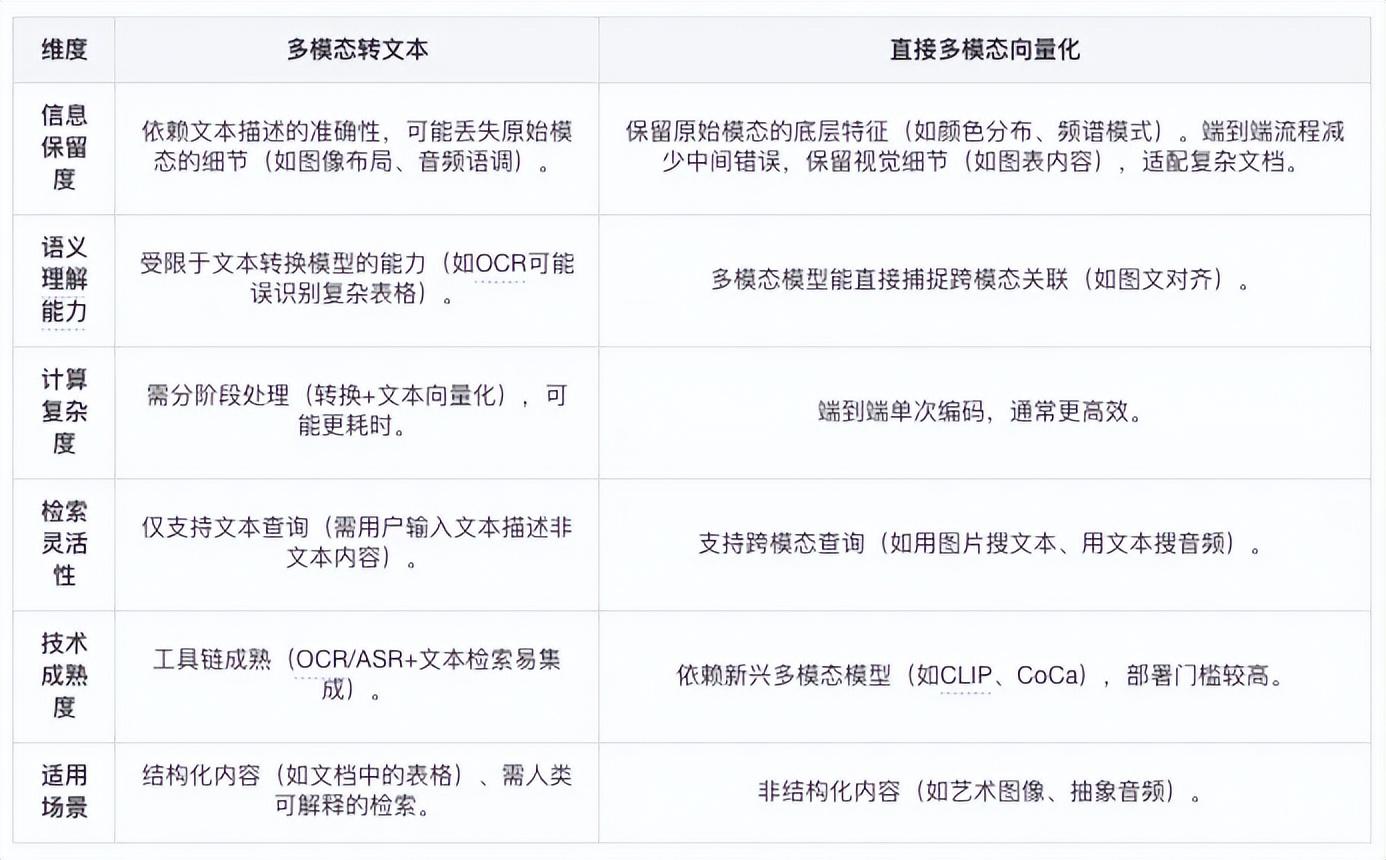
當然,現實情況中,我們有多模態融合的scenarios,這個時候我們需要建立一個共享向量空間,使用跨模態模型(如 OpenAI的CLIP、DeepMind的Flamingo)將不同模態的數據(如圖片、文本、音頻)映射到同一向量空間,文檔中的文本、圖像等模態均可檢索,通過距離計算匹配用戶查詢,實現跨模態語義對齊,比如以圖搜文,以文搜圖等。
3.4 強化學習
3.4.1 DeepRAG
強化學習(Reinforcement Learning, RL)RAG 中的應用并不鮮見。RL能夠優化RAG系統的檢索策略、查詢生成和答案推理過程,可以說,強化學習是 RAG 最好的軍師。比如 DeepSeek-R1 就是通過基于規則的強化學習 (RL) 成功激發推理能力。
這篇 Paper 《DeepRAG: Thinking to Retrieval Step by Step for Large Language Models》提出了DeepRAG,采用馬爾可夫決策過程(MDP)建模檢索增強推理,動態決定何時檢索外部知識。優化了推理精準度,減少不必要檢索,提升計算效率。

- DeepRAG框架:DeepRAG將檢索增強推理建模為馬爾可夫決策過程(MDP),通過迭代分解查詢,動態決定在每一步是否檢索外部知識或依賴參數推理。獎勵函數根據答案的正確性和檢索成本來評估狀態,結合答案正確性和檢索成本,鼓勵高效且準確的推理路徑。
- 檢索敘事(Retrieval Narrative):確保結構化和自適應的檢索流程,根據先前檢索到的信息生成子查詢。
- 原子決策(Atomic Decisions):動態決定每個子查詢是否檢索外部知識或僅依賴LLMs的參數知識。
- 二叉樹搜索(Binary Tree Search):為每個子查詢構建二叉樹,探索基于參數知識或外部知識庫的不同回答策略。
- 模仿學習(Imitation Learning):通過二叉樹搜索合成數據,使模型學習“子查詢生成 - 原子決策 - 中間答案”的模式。
- 校準鏈(Chain of Calibration):通過校準每個原子決策來細化模型對其自身知識邊界的理解,使其能夠更準確地做出檢索必要性的決策。

DeepRAG 將檢索增強推理建模為 MDP,結合二進制樹搜索與校準鏈,實現了動態檢索決策。減少冗余檢索和不必要的噪聲,能夠顯著提高系統的準確性和效率。但是其訓練和推理過程可能需要較高的計算資源,且檢索策略和知識邊界校準方法有待提高,以泛化到更多的場景。
3.4.2 CoRAG
傳統的RAG方法通常在生成過程之前采用一次性檢索策略,也就是只進行一次檢索,但這種方法在處理復雜查詢時可能效果有限,因為檢索結果可能并不完全準確,做過搜索的同學應該都知道,想要完成一次準確的搜索,需要很多步驟,多路找回,多次檢索,合并,粗排,精排等等。這篇Paper 《Chain-of-Retrieval Augmented Generation》提出了CoRAG,核心思想是將檢索過程分解為多個步驟,逐步獲取和整合外部知識。

CoRAG 通過鏈式檢索機制和強化學習,提升了檢索增強生成技術的效率和性能,CoRAG將檢索過程分解為多個步驟,實現了逐步檢索和動態調整,并且通過強化學習訓練檢索策略,使模型能夠根據任務需求自適應調整檢索行為。

鏈式檢索機制
逐步檢索:將檢索增強推理建模為多步決策過程,在生成過程中,模型根據當前生成的內容和任務需求,動態決定是否進行下一步檢索。采用自適應檢索策略:若中間答案置信度低,則重新檢索;否則依賴已有信息繼續生成。檢索策略調整:通過強化學習或啟發式規則,優化檢索策略,確保每次檢索都能獲取最相關的信息。
大多數 RAG 數據集僅附帶查詢 Q 以及相應的最終答案 A ,而無需提供中間檢索步驟。CoRAG 提出了一種通過拒絕抽樣自動生成檢索鏈的方法。
檢索與生成的協同
多步檢索整合:將每次檢索的結果通過注意力機制與生成模型結合,確保生成內容與檢索信息的一致性。
動態生成控制:根據檢索結果的質量和相關性,動態調整生成策略,避免冗余或無關信息的引入。
訓練與優化
訓練數據:使用包含多步檢索任務的數據集進行訓練。數據集中的每個訓練實例都表示為一個元組 (Q,A,Q1:L,A1:L),并附有查詢 Q 和每個子查詢的相應前 k 個檢索文檔。使用多任務學習框架中的標準下一個標記預測目標對增強數據集進行微調。
獎勵設計:結合任務目標(如答案準確性、文本連貫性)設計獎勵函數,引導模型學習最優檢索策略。
模型架構:基于Transformer架構,擴展了檢索決策模塊和檢索結果整合模塊。
3.5 GNN圖神經網絡
傳統RAG方法在處理復雜關系和多源知識整合方面存在不足,難以捕捉知識片段之間的復雜關系(如多跳推理任務),如多步檢索或基于圖的檢索面臨計算成本高、圖結構噪聲或不完整、泛化性差等挑戰。這篇Paper 《GFM-RAG: Graph Foundation Model for Retrieval Augmented Generation》提出了 GFM-RAG,通過構建圖結構來顯式建模知識之間的復雜關系,可以提高檢索和推理的效率。當然,這些方法仍然受到圖結構噪聲和不完整性的影響,可能會限制其性能。

GFM-RAG框架:GFM-RAG通過構建知識圖譜索引(KG-index)和圖基礎模型(GFM)來增強LLMs的推理能力。KG-index從文檔中提取實體和關系,形成一個結構化的知識索引。GFM則利用圖神經網絡(GNN)來捕捉查詢和知識圖之間的復雜關系。

包含三個核心組件:
1. KG索引構建:從文檔中提取實體和關系,構建知識圖譜(KG-index),并通過實體解析增強語義連接。
傳統的基于嵌入的索引方法將文檔編碼為單獨的向量,但這些方法在對它們之間的關系進行建模方面受到限制。另一方面,知識圖譜 (KG) 明確捕捉了數百萬個事實之間的關系,可以提供跨多個文檔的知識的結構化索引。KG 索引的結構性質與人類海馬記憶索引理論非常吻合,其中 KG 索引就像一個人工海馬,用于存儲知識記憶之間的關聯,增強了復雜推理任務對各種知識的整合。
為了構建 KG 索引,給定一組文檔 ,我們首先從文檔中提取實體 ? 和關系 ? 以形成三元組 。然后,構建實體到文檔的倒排索引 M∈{0,1}|?|×| | 來記錄每個文檔中提到的實體。這一過程可以通過現有的開放信息提取 (OpenIE) 工具實現。為了更好地捕捉知識之間的聯系,進一步進行實體解析,在具有相似語義的實體之間添加額外邊 + ,例如 ( USA , equivalent , United States of America )。因此,最終的 KG 索引 構建為 G={(e,r,e′)∈T∪T+}。在實施過程中,利用 LLM 作為 OpenIE 工具,并利用預先訓練的密集嵌入模型進行實體解析。
2. 圖基礎模型檢索器(GFM Retriever):
- 查詢依賴的GNN:動態調整消息傳遞過程,基于查詢語義和KG結構進行多跳推理。
傳統的 GNN 遵循消息傳遞范式,該范式迭代地聚合來自鄰居的信息以更新實體表示。這種范式不適用于 GFM 檢索器,因為它是特定于圖的,并且忽略了查詢的相關性。但是 query-dependent GNNs 在捕獲查詢特定信息和對不可見圖的通用性方面表現出良好:
![]()
其中
![]()
表示初始實體特征,
HqL 表示在經過 L 層依賴于查詢的消息傳遞之后以查詢 q 為條件的更新后的實體表示。
查詢相關的 GNN 表現出更好的表達能力和邏輯推理能力,作為 GFM 檢索器的骨干。它允許 GFM 檢索器根據用戶查詢動態調整消息傳遞過程,并在圖上找到最相關的信息。
- 兩階段訓練
- 無監督KG補全預訓練:在大規模KG上學習圖推理能力
- 有監督文檔檢索微調:優化查詢-文檔相關性。
GFM?檢索器的訓練目標是最大化與查詢相關的實體的可能性,可以通過最小化二元交叉熵 (BCE) 損失來優化:
![]()
其中 q 表示與查詢 q 相關的目標實體集, ?-??? q 表示從 KG 中采樣的負實體集。然而,由于目標實體的稀疏性,BCE 損失可能遭受梯度消失問題。為了解決這個問題,進一步引入了排名損失, 以最大化正負實體之間的邊際:
![]()
最終的訓練目標是 BCE 損失和排名損失的加權組合:
![]()
3. 文檔排序與答案生成:根據實體相關性得分排序文檔,輸入LLM生成最終答案。
鑒于 GFM 檢索器預測的實體相關性得分 Pq∈?|?|×1 ,首先檢索相關性得分最高的前 T 個實體 ?qT :
![]()
然后,文檔排名器使用這些檢索到的實體來獲取最終文檔。為了減少熱門實體的影響,按照實體在文檔倒排索引 M∈{0,1}|?|×| | 中被提及的頻率的倒數來加權實體,并通過對文檔中提及的實體的權重求和來計算最終的文檔相關性得分:

根據文檔相關性得分 Pd 檢索排名前 K 的文檔,并以檢索增強生成的方式輸入到 LLMs 的上下文中,以生成最終答案:

圖基礎模型(GFM):GFM是一個基于查詢的GNN,能夠根據用戶查詢動態調整信息傳遞過程,從而在單步中完成多跳推理。GFM經過兩個階段的訓練:無監督的知識圖完成預訓練和有監督的文檔檢索微調。模型有8M參數,通過大規模訓練(60個KG、14M三元組、700k文檔)實現跨數據集零樣本泛化。在7個領域數據集上 zero-shot 表現優于HippoRAG 18.9%。
關于 Scaling Law,從圖中我們看到模型性能隨模型參數大小和訓練數據大小變化的擬合趨勢線。從趨勢線中我們可以看到 GFM-RAG 的性能隨著模型參數大小和訓練數據大小的增加而提高。同時,隨著模型參數大小的增大,需要更大的訓練數據量才能達到最佳性能。也就是說,同時擴大模型大小和訓練數據可以進一步提高 GFM-RAG 的性能。

訓練過程:
- 無監督知識圖完成預訓練:通過掩碼知識圖中的實體來創建合成查詢,訓練GFM預測被掩碼的實體。
- 有監督文檔檢索微調:使用標注的查詢-文檔對進行訓練,使GFM能夠更好地理解用戶查詢并檢索相關文檔。
GFM-RAG通過圖結構建模和圖神經網絡推理,顯著提升了RAG在復雜推理任務中的性能。但還是同樣的問題,訓練和推理過程可能需要較高的計算資源。如果有更高效的訓練策略和更大的模型規模,模型的效率和泛化性將會得到顯著提高。
3.6 Agentic RAG
LLM橫行的年代,大多數人言則Agent,事實確實如此,LLM的落地一定是Agent,RAG也不例外。代理和 RAG 之間存在著不可分割的關系,RAG 本身是代理的關鍵組件,使它們能夠訪問內部數據;相反,代理可以增強 RAG 功能,從而產生了所謂的 Agentic RAG,例如 Self RAG 和 Adaptive RAG,因此兩者實際上你中有我,我中有你的關系。
這種高級形式的 RAG 允許以受控的方式在更復雜的場景中進行自適應更改。要實現 Agentic RAG,代理框架必須具備“閉環”功能。在 Andrew Ng 的四種代理設計模式中,這種“閉環”能力被稱為反射能力。

Agentic RAG(基于代理的檢索增強生成)代表了RAG技術的最新發展方向,通過將人工智能代理(Agent)的自主規劃與決策能力引入傳統檢索增強生成框架,實現了對復雜查詢任務的高效處理。本文將全面解析Agentic RAG的核心概念、技術架構、優勢特點以及實際應用場景,幫助讀者深入理解這一前沿技術如何通過智能代理的動態編排機制和多跳推理能力,顯著提升傳統RAG系統在復雜信息處理任務中的表現。

3.6.1 核心概念與產生背景
Agentic RAG(基于代理的檢索增強生成)是傳統檢索增強生成技術的高級演進形式,它通過引入人工智能代理(Agent)的自主決策能力,使RAG系統從被動的信息檢索-生成管道轉變為具有主動規劃和反思能力的智能體,本質上是一種融合了Agent能力與RAG架構的混合系統,其核心創新在于將AI智能體的自主規劃(如路由、行動步驟、反思等)能力整合到傳統的RAG流程中,以適應更加復雜的查詢任務。
Agentic RAG的產生背景正是為了解決傳統RAG在復雜場景下的這些不足。隨著企業知識管理需求的日益復雜化,簡單的問答式RAG已不能滿足實際業務需求。企業環境中存在大量異構數據源(如結構化數據庫、非結構化文檔、知識圖譜等),用戶查詢往往需要跨源關聯和綜合推理。同時,許多高級任務還需要結合外部工具(如計算器、API服務等)才能完整解答。這些挑戰促使RAG技術向更智能、更自主的方向發展,從而催生了Agentic RAG這一新興范式。
AI Agent 是具有環境感知、自主決策和行動執行能力的智能體,能夠基于目標動態規劃行動步驟。將這種能力引入RAG系統后,系統能夠自主決定是否需要檢索、選擇哪種檢索策略、評估檢索結果質量、決定是否重新檢索或改寫查詢,以及在必要時調用外部工具。這種進化使RAG系統具備了感知,決策和行動能力。
從系統構成角度看,Agentic RAG可被視為RAG工具化的Agent框架。在這種視角下,傳統的RAG管道(檢索器+生成器)被降級為Agent可使用的一種工具,而Agent則負責更高階的任務規劃與協調。這種架構轉變帶來了設計范式的根本變化:不再是"如何改進RAG管道",而是"如何讓Agent更有效地利用RAG工具",從而打開了更廣闊的設計空間和優化可能性。
表:傳統RAG與Agentic RAG的核心區別

3.6.2 技術架構與關鍵組件
Agentic RAG系統的技術架構呈現出多樣化的設計范式,從單Agent控制到多Agent協同的不同實現方式。與傳統的線性RAG流程不同,Agentic RAG 將檢索與生成過程重構為基于智能代理的動態可編排系統,通過引入規劃、反思和工具使用等Agent核心能力,顯著提升了復雜信息處理任務的解決能力。
單Agent架構模式
單Agent架構是Agentic RAG的基礎實現形式,其核心思想是構建一個具備規劃能力的 Master 智能體,將各種RAG管道和外部工具作為該 Agent 可調用的"工具"。在這種架構中,傳統RAG的檢索器、生成器等組件被工具化,成為 Agent 執行計劃時可選擇的資源。當用戶查詢進入系統后,Master Agent 會首先分析查詢意圖和復雜度,然后動態規劃解決方案,可能包括:決定是否需要檢索、選擇哪種檢索策略(如向量檢索、關鍵詞檢索或混合檢索)、確定是否需要進行多步檢索以及是否需要調用外部工具等。
單Agent架構中的關鍵組件包括:
- 查詢分析器:負責深度理解用戶查詢,識別隱含意圖和所需的信息類型。先進的實現可能采用few-shot學習或思維鏈(Chain-of-Thought)技術提升意圖識別準確率。
- 策略規劃器:基于查詢分析結果,制定檢索與生成策略。例如,對于"比較X和Y"類的對比查詢,規劃器可能決定并行檢索X和Y的相關信息,然后進行對比生成。
- 工具集:包括各種專業化RAG管道(如面向事實查詢的向量檢索、面向摘要任務的文本壓縮檢索等)和外部工具(如計算器、API接口等)。Agent將這些工具視為可插拔的模塊。
- 反思模塊:評估中間結果的質量,決定是否需要調整策略。例如,當首次檢索結果不理想時,反思模塊可能觸發查詢改寫或更換檢索策略。
單Agent架構的優勢在于設計相對簡單和資源需求較低,適合中等復雜度的應用場景。但當面對企業級復雜知識環境(如跨部門多源異構數據)時,單個Agent可能面臨規劃負擔過重、專業知識不足等挑戰,這時就需要考慮更高級的多Agent架構。
多Agent分層架構
多Agent分層架構是應對企業級復雜場景的 Agentic RAG 解決方案,通過引入層級化的 Agent 組織,實現關注點分離和專業化分工。典型的雙層架構包含一個頂層協調Agent和多個專業領域Agent,每個下層Agent負責特定類型的數據源或任務,而頂層Agent則負責任務分解、協調和結果整合。
多Agent架構中的典型角色劃分包括:
- 頂層協調Agent:作為系統入口,接收用戶查詢并進行任務分析和規劃。它了解整個系統的能力分布,負責將復雜查詢分解為子任務并分配給合適的專業Agent。
- 領域Agent:每個Agent專門負責某一類文檔或特定領域的數據源。例如,企業環境中可能有財務Agent(處理財報數據)、產品Agent(管理產品文檔)和客戶Agent(處理CRM數據)等。這些Agent內部可以集成多種RAG工具,如向量檢索、SQL查詢等,根據子任務特點選擇最佳工具。
- 工具Agent:管理外部工具和API的訪問,如網絡搜索Agent、計算工具Agent等。當領域Agent需要額外能力時,可以通過頂層Agent協調調用這些工具Agent。
多Agent架構的核心優勢在于其卓越的可擴展性和專業分工。新增數據源或工具時,只需添加相應的專業Agent而無需修改核心架構。同時,每個Agent可以專注于特定領域,通過精細化優化提供更專業的服務。騰訊云開發者社區的一篇文章中提到,這種架構"既能準確地解析不同類型的文件,還能利用Agent強大的規劃和推理能力,面對用戶Query選擇最合適的路由策略和處理方法,大幅提升系統面對海量文檔、跨文檔檢索、全局提煉與總結等問題時的處理能力"。
在通信機制的設計上,有中心化通信VS去中心化通信。
中心化通信(Centralized communication),在中心化通信中,存在一個中心節點,所有智能體都直接與這個中心節點進行通信。中心節點負責協調和集成所有智能體的信息,然后向各個智能體發出指令或反饋。中心節點可以全局地了解所有智能體的狀態和信息,有助于做出全局最優的決策。但是容易出現單點故障,中心節點的故障可能導致整個系統的通信癱瘓。
去中心化通信(Decentralized communication),在去中心化通信中,智能體之間直接進行通信,沒有中心節點,每個智能體只與它的鄰居或部分智能體交換信息。有單點故障的風險,系統的魯棒性更強,同時可擴展性極強。但是沒有全局信息,難以做出全局最優的決策。
關于Multi Agent系統的設計,又是另外一個復雜的 Topic 了,不做贅述。
四、Challenges and Future Directions in RAG
4.1 統一多模態大模型
通過直接多模態向量化,RAG系統能更自然地處理復雜現實數據,而不僅限于文本世界。實際選型時需權衡計算成本、領域適配性和實時性需求。如GPT-4V、Gemini 1.5的端到端多模態理解。目前的Multimodal 還是處于發展期,遠沒有成熟,問題包括但不限于:
1. 多模態表示與檢索的挑戰
- 跨模態知識表示:不同模態的數據(如文本、圖像、音頻)需要轉換為統一的向量表示,以便進行跨模態的高效檢索。然而,如何設計一個能夠準確捕捉不同模態語義信息的統一表示是一個關鍵問題。例如,CLIP模型通過學習圖像和文本的對齊表示實現了跨模態檢索,但其在復雜場景下的泛化能力仍有待提升。
- 檢索效率與準確性:在大規模多模態數據中進行高效檢索是一個挑戰。向量檢索方法雖然能夠快速找到相似的模態數據,但可能難以區分語義上的細微差別,導致檢索結果不準確。此外,多模態數據的稀疏性也增加了檢索難度,尤其是在信息分散于多個文檔時。
- 數據對齊問題:不同模態的數據在語義上需要對齊,例如一段文本描述了一張圖片的內容,如何將這兩者在語義上進行有效對齊是一個關鍵挑戰。
- 生成內容的質量:多模態RAG系統需要確保生成內容的準確性和一致性。由于檢索到的知識片段可能來自不同的模態和文檔,模型需要有效地整合這些信息,比如我們之前講的如何對多路、多模態Reranker就是一個挑戰。
2. 效率與性能
- 計算資源需求:多模態RAG系統需要處理大量的數據和復雜的模型計算,對計算資源的需求較高。特別是在實時應用中,如何優化檢索和生成過程以減少延遲是一個關鍵問題。
- 模型訓練與微調:為了提升多模態RAG系統的性能,需要對模型進行微調。然而,不同模態數據的訓練難度不同,且微調過程需要大量的標注數據。
- 魯棒性與可解釋性:相比于傳統的搜索系統,多模態RAG系統在復雜場景下的魯棒性不足,當然,這不只是RAG的問題。
4.2 安全 (TrustRAG)
檢索外部知識庫可能引入敏感信息(如專利、隱私數據),RAG模型可能被濫用于生成虛假信息或惡意內容等等,但是我們這里主要講惡意攻擊和注入。這篇Paper 《TrustRAG: Enhancing Robustness and Trustworthiness in RAG》,提出了一種兩階段防御機制:首先,利用 K-means 聚類識別檢索文檔中的潛在攻擊模式,基于語義嵌入有效隔離可疑內容;其次,通過余弦相似度和 ROUGE 指標檢測惡意文檔,并通過自我評估過程解決模型內部知識與外部信息之間的差異。

TrustRAG 的主要工作流:
- 識別惡意文檔:利用 K-means 聚類分析文檔的語義嵌入分布,識別出潛在的惡意文檔簇。
- 過濾惡意內容:根據嵌入分布過濾掉惡意文檔,保留干凈文檔。
- 提取內部知識:利用 LLM 的內部知識生成準確的推理結果。
- 解決沖突:通過整合內部和外部知識,解決知識沖突,去除不相關或矛盾的文檔。
- 生成可靠答案:基于精煉后的文檔生成最終的可靠回答
其實關于安全這一塊,是一個非常重要的課題,可以確定的是,LLM一定會超過單個碳基生命的智慧。如何做好安全防護,一定是使用者首先要關注的,比如Deep Mind就有一個Red Team團隊專門研究大模型安全的課題,這里我們不做過多介紹,后續可以單獨作為一個研究的 Topic。
Reference
- Advanced AI and Retrieval-Augmented Generation for Code Development in High-Performance Computing | NVIDIA Technical Blog:https://developer.nvidia.com/blog/advanced-ai-and-retrieval-augmented-generation-for-code-development-in-high-performance-computing/
- LLM as HPC Expert: Extending RAG Architecture for HPC Data:https://arxiv.org/abs/2501.14733
- Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers:https://arxiv.org/abs/2404.07220
- ColPali: Efficient Document Retrieval with Vision Language Models:https://arxiv.org/abs/2407.01449
- RAG-Reward: Optimizing RAG with Reward Modeling and RLHF:https://arxiv.org/abs/2501.13264
- GFM-RAG: Graph Foundation Model for Retrieval Augmented Generation:https://arxiv.org/abs/2502.01113
- TrustRAG: Enhancing Robustness and Trustworthiness in RAG:https://arxiv.org/abs/2501.00879
- Chain-of-Retrieval Augmented Generation:https://arxiv.org/abs/2501.14342
- VideoRAG: Retrieval-Augmented Generation over Video Corpus:https://arxiv.org/abs/2501.05874
- The Power of Noise: Redefining Retrieval for RAG Systems:https://arxiv.org/abs/2401.14887
- Don’t Forget to Connect! Improving RAG with Graph-based Reranking:https://arxiv.org/abs/2405.18414
- Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG:https://arxiv.org/abs/2501.09136
- Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement Learning:https://arxiv.org/abs/2501.15228
- Dense Passage Retrieval for Open-Domain Question Answering:https://arxiv.org/abs/2004.04906
- DeepRAG: Thinking to Retrieval Step by Step for Large Language Models:https://arxiv.org/abs/2502.01142
- Application of Multi-Way Recall Fusion Reranking Based on Tensor and ColBERT in RAG:https://ieeexplore.ieee.org/document/10761558
- Multimodal Embedding Models | Weaviate:https://weaviate.io/blog/multimodal-models
- R1/o1的風又吹到了RAG,微軟CoRAG高達93%的復雜推理效果~:https://mp.weixin.qq.com/s/9Pu6wijQ9BLbH6nrP6YBTA
- The Rise and Evolution of RAG in 2024 A Year in Review | RAGFlow:https://ragflow.io/blog/the-rise-and-evolution-of-rag-in-2024-a-year-in-review
- Advanced RAG Techniques | Weaviate:https://weaviate.io/blog/advanced-rag
- Jina-ColBERT-v2: A General-Purpose Multilingual Late Interaction Retriever:https://arxiv.org/pdf/2408.16672
- LLMs的推理之路:從鏈式思維到強化學習,邁向大型推理模型:https://mp.weixin.qq.com/s/tesV5lAsLXVBdP2WqUCrmw
- From RAG to Memory: Non-Parametric Continual Learning for Large Language Models:https://arxiv.org/pdf/2502.14802
- RAG vs. GraphRAG: A Systematic Evaluation and Key Insights:https://arxiv.org/pdf/2502.11371
- ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT:https://arxiv.org/abs/2004.12832
- SafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model:https://arxiv.org/pdf/2501.18636
實時與AI智能體進行語音通話
)


:集群安全加固全攻略)






)




:Llama模型的簡單部署)
)


