參考《DAX 權威指南 第二版》
文章目錄
- 二、DAX簡介
- 2.1 理解 DAX 計算
- 2.2 計算列和度量值
- 2.3 變量
- 2.3.1 VAR簡介
- 2.3.2 VAR的特性
- 2.4 DAX 錯誤處理
- 2.4.1 DAX 錯誤類型
- 2.4.1.1 轉換錯誤
- 2.4.1.2 算術運算錯誤
- 2.4.1.3 空值或 缺失值
- 2.4.2 使用IFERROR函數攔截錯誤
- 2.4.2.1 安全地進行除法運算
- 2.4.2.2 攔截其它錯誤
- 2.4.2.3 使用建議
- 2.4.4 使用ERROR函數生成錯誤
- 2.5 格式化
- 2.6 常見函數
- 2.6.1 聚合函數
- 2.6.2 迭代函數
- 2.6.3 邏輯函數
- 2.6.3.1 常見邏輯函數
- 2.6.3.2 SWITCH
- 2.6.3.3 計算組:參數化計算的首選
- 2.6.4 信息函數
- 2.6.5 數學與三角函數
- 2.6.6 文本函數
- 2.6.7 轉換函數
- 2.6.8 日期和時間函數
- 三、表函數
- 3.1 簡介
- 3.2 DAX查詢
- 3.2.1 DAX 查詢的關鍵字
- 3.2.1.1 EVALUATE(必須)
- 3.2.1.2 ORDER BY(可選)
- 3.2.1.3 START AT(可選)
- 3.2.1.4 DEFINE(可選)
- 3.2.2 DAX 查詢中的參數化與應用示例
- 3.3 FILTER
- 3.3.1 基本用法
- 3.3.2 嵌套使用
- 3.3.3 性能優化
- 3.4 ALL 、 ALLEXCEPT、ALLSELECTED
- 3.4.1 ALL :清除篩選
- 3.4.2 ALLEXCEPT :清除指定列之外的篩選
- 3.4.3 ALLSELECTED 只保留外部(報表)篩選器
- 3.5 VALUES 與 DISTINCT
- 3.5.1 語法
- 3.5.2 空白行的產生
- 3.5.3 處理無效關系
- 3.6 單個值的表
- 3.6.1 使用IF...VALUES組合
- 3.6.2 使用HASONEVALUE...VALUES組合
- 3.6.3 使用SELECTEDVALUE函數
- 3.6.4 使用CONCATENATEX,連接所有表值
- 四、計算上下文
- 4.1 篩選上下文與行上下文
- 4.1.1 篩選上下文的定義與作用
- 4.1.2 行上下文
- 4.2 計算上下文的常見誤區
- 4.2.1 在計算列中使用聚合函數
- 4.2.2 在度量值中使用列
- 4.3 迭代與行上下文
- 4.3.1 使用迭代函數創建行上下文
- 4.3.2 不同表上的嵌套行上下文(`RELATED` 和 `RELATEDTABLE` )
- 4.3.3 同一表上的嵌套行上下文(使用變量處理)
- 4.3.4 EARLIER
- 4.4 多表數據模型中的上下文
- 4.4.1 行上下文與關系
- 4.4.2 篩選上下文與關系
- 4.6 SUMMARIZE
- 4.6.1 SUMMARIZE語法
- 4.6.2 案例:計算所有客戶購買產品時的平均年齡
- 4.6.3 匿名表與模型表
- 4.6.4 數據沿襲(Data Lineage)
二、DAX簡介
2.1 理解 DAX 計算
2.2 計算列和度量值
| 特性 | 計算列 | 度量值 |
|---|---|---|
| 定義 | 通過 DAX 公式創建而非從數據源直接加載的 | 通過DAX創建,用于聚合表中的數據 |
| 計算上下文 | 依賴于當前行進行計算(行上下文),無法直接訪問其他行的值。 | 查詢上下文,依賴于用戶選擇和篩選器 |
| 存儲方式 | 在數據加載時存儲在模型中,占用內存空間 數據刷新時而非查詢時計算,從而提高用戶體驗 | 在查詢時才進行計算,不占用額外內存 |
| 適用場景 | 當需要將計算結果作為篩選器、行或列顯示在報表中時 | 聚合計算時,如計算利潤百分比、產品相對比率等 |
| 總計計算 | 逐行計算的結果直接聚合(如求和或平均),可能導致錯誤 | 根據聚合值動態計算,結果正確 |
| 依賴關系 | 依賴于表中的列,不能直接引用其他行的值 | 可以引用表中的列或其他度量值,依賴于上下文 |
| 使用建議 | 僅在需要逐行計算或作為報表元素時使用 | 每當你可以用計算列和度量值來表達同一個計算時,優先使用度量值 |
??創建復雜計算列時,雖然計算時間是在數據處理階段(而非查詢階段),能夠提升用戶體驗,但計算列會占用寶貴的內存空間。因此,將復雜公式拆分為多個中間列的做法雖然有助于開發,卻會導致內存浪費,不是一個好的習慣。 每當你可以用計算列和度量值來表達同一個計算時,優先使用度量值(不占內存)。計算列的使用應該嚴格限制在少數需要它們的情況
??強烈建議使用 := 來創建度量值公式,使用 = 創建計算列或計算表公式,以便進行更好的區分。
??初學者常常問的問題是:什么時候需要創建計算列?只有一個正確答案,那就是你需要用手把某列從某表中拖出來作圖表而該表列卻不存在時。這句話不是讓你現在理解的,而是讓你記錄并在未來不斷體會的。
??計算列是在行級別上逐行計算的,適用于需要對每一行進行簡單計算的場景,比如,您可以使用以下公式創建計算列來計算銷售額的毛利率:
Sales[SalesAmount] = Sales[Quantity] * Sales[Net Price]Sales[TotalCost] = Sales[Quantity] * Sales[Unit Cost]Sales[GrossMargin] = Sales[SalesAmount] – Sales[TotalCost]Sales[GrossMarginPct] = Sales[GrossMargin] / Sales[SalesAmount]這種方式在行級別上計算是正確的,但在總計級別上會出錯:

??這里毛利率的總計結果是每行毛利率的簡單相加(46.34%+51.58%+…),這個邏輯顯然是錯的。GrossMarginPct (毛利率) 的正確實現是寫一個度量值:
GrossMarginPct := SUM ( Sales[GrossMargin] ) / SUM (Sales[SalesAmount] )

??計算列的聚合結果是逐行計算的總和,而度量值的聚合結果是基于聚合值的比率計算。這就是前面說的,如果需要進行聚合計算,而不是逐行計算,則必須創建度量值。
2.3 變量
2.3.1 VAR簡介
??使用 VAR 關鍵字可以定義變量,避免在表達式中重復相同的計算,提高代碼的可讀性和可維護性。定義一個變量之后,需要提供 RETURN 部分來定義表達式的結果值。例如上一節毛利率的計算公式可改寫為:
VAR TotalSales = SUM ( Sales[SalesAmount] )
VAR TotalCosts = SUM ( Sales[TotalProductCost] )
VAR GrossMargin = TotalSales - TotalCosts
RETURN
GrossMargin / TotalSales
??我們強烈建議盡可能使用變量,因為它們使代碼更易于閱讀。例如下述代碼,遍歷Sales表,僅計算 Quantity 大于 1 的行的銷售額:
Sales Amount Multiple Items :=
SUMX (FILTER (Sales,Sales[Quantity] > 1),Sales[Quantity] * Sales[Net Price]
)
我們使用變量存儲表,將公式進行改寫,使其更易于理解:
Sales Amount Multiple Items :=
VARMultipleItemSales = FILTER ( Sales, Sales[Quantity] > 1 )
RETURNSUMX (MultipleItemSales,Sales[Quantity] * Sales[Unit Price])
2.3.2 VAR的特性
- 作用域:變量僅在定義它們的表達式內部有效,不能在表達式外部使用,不存在全局變量。
- 上下文:變量在定義時捕獲計算上下文,而不是在使用時。這意味著一旦變量的值被計算出來,它在當前上下文中就會保持不變,不會因為上下文的變化而重新計算。
- 延遲計算:變量只有在被使用時才會被計算,如果未被使用,則不會計算。如果多次使用同一個變量,計算只會發生一次,后續使用會直接讀取已計算的值。
下面舉一個使用VAR的常見誤區進行具體的說明。我們可與使用常規方式定義同比增長率(與去年相比):
[Sales] := SUM(銷售表[銷售額])
[Saleslastyear] := CALCULATE([Sales], SAMEPERIODLASTYEAR(日期表[日期]))
[YoY%] := DIVIDE([Sales] - [Saleslastyear], [Saleslastyear])
使用 VAR 定義變量時,可以在一個度量值中完成所有計算:
[YoY% 1] :=
VAR Sales = SUM('訂單'[銷售額])
VAR Saleslastyear =CALCULATE(SUM('訂單'[銷售額]),SAMEPERIODLASTYEAR('日期表'[日期]))
RETURN
DIVIDE(Sales - Saleslastyear, Saleslastyear)
如果CALCULATE函數的第一個參數使用Sales變量,則會計算錯誤:
[YoY% 2] :=
VAR Sales = SUM('訂單'[銷售額])
VAR Saleslastyear =CALCULATE(Sales,SAMEPERIODLASTYEAR('日期表'[日期]))
RETURN
DIVIDE(Sales - Saleslastyear, Saleslastyear)

??Sales 是一個變量,它的值在定義時不會立即計算,而是等到整個表達式需要使用它時才會計算。計算時,是根據其定義的上下文進行計算,并在之后調用時保持不變,即使后面調用時使用CALCULATE函數修改上下文,也不會因為上下文的變化而重新計算。所以[YoY% 2]中,Saleslastyear = Sales,最終得到的結果就是0。
2.4 DAX 錯誤處理
現在您已經了解了語法的一些基本知識,接下來應該學習如何優雅地處理錯誤(無效的計算)。
2.4.1 DAX 錯誤類型
2.4.1.1 轉換錯誤
DAX 會在運算需要時自動嘗試將字符串和數字進行轉換,比如以下DAX表達式都是有效的:
"10" + 32 = 42"10" & 32 = "1032"10 & 32 = "1032"DATE (2010,3,25) = 3/25/2010DATE (2010,3,25) + 14 = 4/8/2010DATE (2010,3,25) & 14 = "3/25/201014"
但如果無法將某些內容轉換為適合運算的類型,就會發生轉換錯誤。例如:
"1 + 1" + 0 // 無法將文本類型的值"1 + 1"轉換為數字類型DATEVALUE ("25/14/2010") // 無效日期格式,無法轉換
解決辦法是在 DAX 表達式中添加錯誤檢測邏輯,以攔截錯誤條件并返回有意義的結果。
2.4.1.2 算術運算錯誤
??除零錯誤:當你把一個數除以零時,DAX 會返回一個無窮大的特殊值 Infinity。此外,在 0 除以 0 或無窮大除以無窮大的特殊情況下,DAX 返回特殊的 NaN(而不是數字值) :

其它算術錯誤(如負數的平方根)會導致計算錯誤。可以使用 ISERROR 函數檢查表達式是否導致錯誤(下文介紹)。
??在 Power BI 中,特殊值如
NaN(“非數字”)會正常顯示,但在 Excel 數據透視表中可能會顯示為錯誤。此外,錯誤檢測函數也會將這些特殊值識別為錯誤。
2.4.1.3 空值或 缺失值
??空值的定義:DAX中使用空值(BLANK)來表示缺失值、空白值或空單元格。空值不是一個真正的值,而是一種特殊的狀態,用于識別這些條件。BLANK 本身不是一個錯誤,它只是顯示為空白結果。可以通過調用BLANK()函數來顯式地返回一個空值:
= BLANK ()
-
空值的運算規則:BLANK()在加減法中可視為0,但在乘除法中會傳播BLANK()
BLANK () + BLANK () = BLANK ()10 * BLANK () = BLANK ()BLANK () / 3 = BLANK ()BLANK () / BLANK () = BLANK ()BLANK () ? 10 = ?1018 + BLANK () = 184 / BLANK () = Infinity0 / BLANK () = NaN -
空值的邏輯規則:個人感覺BLANK可視為0,而0在很多語言中可視為FALSE,這樣理解便于看懂下面的判斷結果:
BLANK () || BLANK () = FALSEBLANK () && BLANK () = FALSE( BLANK () = BLANK () ) = TRUE( BLANK () = TRUE ) = FALSE( BLANK () = FALSE ) = TRUEFALSE || BLANK () = FALSEFALSE && BLANK () = FALSETRUE || BLANK () = TRUETRUE && BLANK () = FALSE -
使用ISBLANK函數檢查空值:BLANK與0或空字符串""的比較會返回TRUE,因此無法通過簡單的相等運算符來區分空值,只能使用ISBLANK函數進行區分。
BLANK () = 0 // 隱式轉換規則,始終返回 TRUEBLANK () = "" // 隱式轉換規則,始終返回 TRUEISBLANK ( BLANK() ) = TRUEISBLANK ( 0 ) = FALSEISBLANK ( "" ) = FALSE
比如下面的表達式計算銷售交易的總折扣,如果折扣為 0,則單元格為空:
=IF (Sales[DiscountPerc] = 0,-- 確認是否有折扣BLANK (),-- 如果不存在折扣,返回空值Sales[DiscountPerc] * Sales[Amount]
)
因此,如果 Sales[DiscountPerc] 或 Sales[Clerk] 為空,則即使分別針對 0 和空字符串做測試,以下條件也會返回 TRUE:
Sales[DiscountPerc] = 0 // 如果 PercSales[DiscountPerc] 為 BLANK 或 0,則返回 TRUESales[Clerk] = " " // 如果 Sales[Clerk] 是 BLANK 或 "",則返回 TRUE
在這種情況下,可以使用 ISBLANK 函數檢查值是否為空值:
ISBLANK ( Sales[DiscountPerc] ) //僅當 Sales[DiscountPerc]為空值時才返回 TRUEISBLANK ( Sales[Clerk] ) //僅當 Sales[Clerk] 是空值時才返回 TRUE
- 與其他工具中空值的對比:
- Excel中的空值:在Excel中,空值在求和或乘法運算中被視為
0,但在除法或邏輯表達式中可能會導致錯誤。 - SQL中的NULL:在SQL中,
NULL在表達式中通常會導致整個表達式計算為NULL,而DAX中的空值并不總是導致空白結果。 - DirectQuery模式:在使用DirectQuery模式時,部分計算在SQL中執行,部分在DAX中執行。由于DAX和SQL對空值的語義不同,可能會導致意外的行為。因此,在使用DirectQuery時,需要特別注意空值的處理。
- Excel中的空值:在Excel中,空值在求和或乘法運算中被視為
2.4.2 使用IFERROR函數攔截錯誤
IFERROR 是 DAX 中用于錯誤處理的常用函數,它能夠優雅地捕獲和處理表達式可能產生的錯誤,使報表更加健壯和用戶友好,其基本語法為:
IFERROR(value, value_if_error)
- value:DAX表達式,計算成功直接返回表達式的結果;
- value_if_error:當表達式出錯時返回的替代值
2.4.2.1 安全地進行除法運算
// 傳統方法需要嵌套IF檢查分母
= IF([Denominator] <> 0,[Numerator] / [Denominator],BLANK()
)// 使用IFERROR更簡潔
= IFERROR([Numerator] / [Denominator],BLANK()
)
??第一種方式,IF函數需要檢查除數是否為零,增加額外計算;使用IFERROR更簡潔,但IFERROR 會先完整計算表達式,再判斷是否出錯。對于安全地進行除法運算,更推薦使用DIVIDE函數 ,其語法為:
DIVIDE(<numerator>, <denominator> [,<alternateresult>])
??<numerator>, <denominator>分別是分子和分母,<alternateresult>是可選的備用結果。DIVIDE 函數可自動處理除數為零的情況。如果未傳入備用結果,分母為零或 BLANK,則函數將返回 BLANK;如果傳入備用結果,則此時返回備用結果。
??以下度量值表達式生成安全的除法運算,但它涉及使用四個 DAX 函數:
Profit Margin =
IF(OR(ISBLANK([Sales]),[Sales] == 0),BLANK(),[Profit] / [Sales]
)
直接使用DIVIDE函數可實現相同的結果,且更高效、更優雅:
Profit Margin =
DIVIDE([Profit], [Sales])
2.4.2.2 攔截其它錯誤
-
處理類型轉換:
如果Sales[Quantity]或Sales[Price]是無法轉換為數字的字符串,或者它們的乘法運算導致錯誤(例如,其中一個值為BLANK()),則返回BLANK()。= IFERROR(Sales[Quantity] * Sales[Price], BLANK()) -
計算錯誤
= IFERROR(SQRT(Test[Omega]), "無效的平方根計算") -
嵌套使用:IFERROR 可以嵌套使用來處理多步計算中可能出現的錯誤:
= IFERROR(SQRT(IFERROR(VALUE([TextValue]),0 // 如果文本轉換失敗使用0作為默認值)),"無效的平方根計算" // 如果SQRT失敗顯示此消息 )
2.4.2.3 使用建議
- 性能影響:
IFERROR會先完整計算表達式,再判斷是否出錯。對于性能敏感的計算,預先檢查條件,比如使用IF進行檢查剔除不需要的計算,可能更高效。在大型數據集上,過度使用IFERROR可能影響性能。 - 隱藏潛在問題:雖然IFERROR可以防止錯誤顯示,但它也可能隱藏數據中的潛在問題。因此,在使用IFERROR時,需要確保默認值的使用不會掩蓋數據質量問題。
2.4.4 使用ERROR函數生成錯誤
??不是所有錯誤都需要捕獲,有時生成一個明確的錯誤信息比返回一個默認值更有意義,更有助于發現數據問題。ERROR函數用于生成一個明確的錯誤信息,以提示用戶數據或計算中存在問題,其語法為:
ERROR(error_message)
error_message:要顯示的錯誤信息,通常是一個字符串。
??例如在一個計算場景中,需要計算開爾文溫度的平方根。因為開爾文溫度的最低極限是0(絕對零度),不可能是負數。在這種情況下,如果我們使用IFERROR函數來處理可能的錯誤,這會導致即使溫度是負數,公式也不會報錯。這樣做雖然避免了錯誤的顯示,但同時也隱藏了數據中的問題。
= IFERROR(SQRT(Test[Temperature]), 0)
正確做法是使用IF函數來檢查溫度值是否合理(即是否大于或等于0):
= IF(Test[Temperature] >= 0,SQRT(Test[Temperature]),ERROR("溫度不能是負數,計算終止")
)
2.5 格式化
??DAX是一種函數語言:函數語言是指一種編程范式,其中程序的構建主要依賴于函數的組合和調用。 DAX就是一種函數語言,每個表達式都可以被視為一個函數的調用,例如,SUM(Sales[Amount])是一個函數調用,IF(Condition, TrueValue, FalseValue)也是一個函數調用。
??由于DAX是基于函數的,復雜的邏輯可以通過嵌套多個函數來實現,這種嵌套結構使得DAX表達式可以非常強大,但也可能導致表達式變得很長。例如:
IF(CALCULATE(NOT ISEMPTY(Balances), ALLEXCEPT (Balances, BalanceDate)),SUMX (ALL(Balances[Account]),CALCULATE(SUM(Balances[Balance]),LASTNONBLANK(DATESBETWEEN(BalanceDate[Date],BLANK(),MAX(BalanceDate[Date])),CALCULATE(COUNTROWS(Balances))))),BLANK())
??以這種格式來理解這個公式的計算內容,幾乎是不可能的,不知道哪個是最外層的函數, 也不知道 DAX 如何評估不同的參數來創建完整的執行流程。而通過格式化,我們可以更清楚的理解整個表達式的結構:
IF (CALCULATE (NOT ISEMPTY ( Balances ),ALLEXCEPT (Balances,BalanceDate)),SUMX (ALL ( Balances[Account] ),CALCULATE (SUM ( Balances[Balance] ),LASTNONBLANK (DATESBETWEEN (BalanceDate[Date],BLANK (),MAX ( BalanceDate[Date] )),CALCULATE (COUNTROWS ( Balances ))))),BLANK ()
)
在這個例子中:
- IF是外層函數,有三個參數;
- CALCULATE和SUMX是嵌套在IF中的第二層函數;
- CALCULATE中又嵌套了NOT ISEMPTY、ALLEXCEPT等函數。
- SUMX中嵌套了ALL、CALCULATE、LASTNONBLANK、DATESBETWEEN等函數。
使用變量(VAR)來進一步優化代碼的可讀性:
IF (CALCULATE (NOT ISEMPTY ( Balances ),ALLEXCEPT (Balances,BalanceDate)),SUMX (ALL ( Balances[Account] ),VAR PreviousDates =DATESBETWEEN (BalanceDate[Date],BLANK (),MAX ( BalanceDate[Date] ))VAR LastDateWithBalance =LASTNONBLANK (PreviousDates,CALCULATE (COUNTROWS ( Balances )))RETURNCALCULATE (SUM ( Balances[Balance] ),LastDateWithBalance)),BLANK ()
)
一些常用的DAX代碼格式化規則如下:
- 函數名稱:始終使用空格將函數名稱(如IF,SUMX和CALCULATE)與參數分開,并使用大寫字母。
- 列引用與度量值引用:在代碼中引用列時,始終加上表名,表名和左方括號之間不加空格;引用度量值時,不要加上表名。
- 區分計算列和度量值:在定義計算列時使用
=,在定義度量值時使用:=。 - 逗號:在逗號后面加空格,但不在逗號前面加空格。
- 單行公式:如果公式適合單行,則不應用其他規則。
- 多行公式:將函數名稱和左括號放在一行上,每個參數占一行,縮進四個空格,最后一個參數后不加逗號,右括號與函數對齊。
CalcCol = SUM ( Sales[SalesAmount] ) // 這是一個計算列
Store[CalcCol] = SUM ( Sales[SalesAmount] ) // 這是一個在 表 Store 中的計算列
CalcMsr := SUM ( Sales[SalesAmount] ) // 這是一個度量值
??格式化代碼是一個耗時的操作,有一個專門用于格式化 DAX 代碼的網站DAXFormatter.com,可自動進行DAX代碼格式化。另外,在編輯欄中書寫DAX代碼時:
- 字體大小:在Power BI、Excel或Visual Studio中,可以通過按住Ctrl鍵并滾動鼠標滾輪來調整字體大小,以便更清晰地查看代碼。
- 換行:按Shift+Enter可以在公式中添加新行。
- 編輯器:如果文本框不適合編輯,可以將代碼復制到其他編輯器(如記事本或DAXStudio)中進行編輯,然后再復制回去。
- 智能提示:Power BI自帶的DAX公式編輯器已經非常強大,提供了智能提示功能。一個重要的技巧請記住:你能用的,它都提示給你;沒提示給你的,都不能用。用,則會報錯語法錯誤。
2.6 常見函數
2.6.1 聚合函數
?? 對表列進行聚合并返回單個值的函數稱為聚合函數。聚合是一種思想,將大量數據快速聚合到少量數據,形成價值密度更高的信息。DAX 在執行聚合時不考慮空單元格(準確講是空值),這與Excel的處理方式不同。
?? 聚合函數大多只對數值或日期進行操作,只有 MIN 和 MAX 可以對文本值進行操作。另外,除了接受表列,MIN 和 MAX還可以接受兩個DAX 表達式作為參數,并返回其中的最小值或最大值,這種方式可以簡化代碼,避免復雜的IF語句,提高可讀性和效率。
MAX函數語法:
MAX(<column>)或者MAX(<expression1>, <expression2>)
??數據處理方式 :Excel:以單元格為單位處理數據,每個單元格可以包含不同類型的數據(數字、文本、布爾值等)。DAX:以列(字段)為單位處理數據,每列都有明確的數據類型(如數字、文本等),并且列中的所有值必須符合該數據類型。在 Excel 中,函數會逐個單元格計算,而 DAX 中的函數會根據列的數據類型進行整體計算。
- 基礎聚合函數:如
SUM,AVERAGE,MIN,MAX,主要用于數字列。 - 擴展聚合函數:DAX 為繼承自 Excel 的聚合函數提供了另一種語法,可以對包含數值和非數值的列進行計算。這些函數都帶后綴“A”,如 AVERAGEA、
COUNTA、MINA和MAXA。在這些函數中,TRUE和FALSE 分別被計算為 1和0,而文本列(包括空字符串)始終被視為 0。
| 事務 ID | 值 | 結果 |
|---|---|---|
| 0000123 | 1 | 計為 1 |
| 0000124 | 20 | 計為 20 |
| 0000125 | n/a | 計為 0 |
| 0000126 | 計為 0 | |
| 0000126 | TRUE | 計為 1 |
| DAX 的計數函數 | 參數 | 返回結果 |
|---|---|---|
| COUNT | 數字列 | 返回非空值的數量 |
| COUNTA | 任何類型的列 | 返回非空值的數量 |
| COUNTBLANK | 任何列 | 返回空單元格的數量(包括空白和空字符串) |
| COUNTROWS | 表 | 返回表中的行數 |
| DISTINCTCOUNT | 任何列 | 返回列中不同值的數量(包括空白值) |
| DISTINCTCOUNTNOBLANK | 任何列 | 返回列中不同值的數量(不包括空白值) |
- DISTINCTCOUNT:是 2012 版 DAX 引入的函數,用于計算列中不同值的數量,包括空白值。在早期版本中,可通過
COUNTROWS(DISTINCT(table[column]))來實現相同功能。- DISTINCTCOUNTNOBLANK:是 2019 年引入的函數,用于計算列中不同值的數量,但不包括空白值。它簡化了 SQL 中的 COUNT DISTINCT 操作,避免了在 DAX 中編寫復雜的表達式。
2.6.2 迭代函數
??聚合函數都是對表列進行操作,如果要聚合整個表或表中不同的列,或者需要減少計算列的使用是,可以使用迭代函數(迭代器)。迭代函數通常接受至少兩個參數:第一個是它們掃描的表,第二個是表中每一行的計算的表達式。迭代函數內部封裝了迭代邏輯,用于逐行計算表達式。比如:
SUM ( Sales[Quantity] )
在內部,SUM函數會被轉換為:
SUMX ( Sales, Sales[Quantity] )
??所以說,聚合函數只是對應迭代器的語法糖版本。使用迭代函數并不會比使用標準聚合函數慢。實際上,迭代函數在內部實現了優化,性能上沒有顯著差異。
| 特性 | 聚合函數 | 迭代函數 |
|---|---|---|
| 定義 | 對單個列的值進行聚合操作,返回單個值 | 對表中的每一行進行計算,不一定都是聚合效果 |
| 典型函數 | SUM、AVERAGE、MIN、MAX、STDEV | SUMX、AVERAGEX、MINX、MAXX、FILTER、ADDCOLUMNS、GENERATE |
| 參數 | 通常只需要一個參數(列引用) | 至少兩個參數:表和每行的計算表達式 |
| 計算方式 | 直接對列進行聚合,不需要逐行計算 | 需要逐行計算表達式,然后聚合結果 |
| 適用場景 | 簡單的單列聚合操作 | 復雜的多列計算或需要減少計算列的情況 |
2.6.3 邏輯函數
2.6.3.1 常見邏輯函數
邏輯函數用于在 DAX 表達式中構建邏輯條件,實現不同的計算邏輯。常見的邏輯函數包括:
| 函數名稱 | 描述 | 函數名稱 | 描述 | 函數名稱 | 描述 | 函數名稱 | 描述 |
|---|---|---|---|---|---|---|---|
| AND | 邏輯與 | FALSE | 返回邏輯值 FALSE | IF | 條件判斷 | IFERROR | 錯誤處理 |
| NOT | 邏輯非 | TRUE | 返回邏輯值 TRUE | OR | 邏輯或 | SWITCH | 多條件判斷 |
例如在之前的章節中,我們使用IFERROR 函數處理表達式中的錯誤:
Sales[Amount] = IFERROR(Sales[Quantity] * Sales[Price], BLANK())
2.6.3.2 SWITCH
SWITCH 特別適合處理多條件判斷,比使用嵌套 IF 函數更加簡潔:
'Product'[SizeDesc] =
IF ('Product'[Size] = "S","Small",IF ('Product'[Size] = "M","Medium",IF ('Product'[Size] = "L","Large",IF ('Product'[Size] = "XL","Extra Large","Other")))
)
使用 SWITCH 可以實現同樣的功能,且更容易閱讀,不過此性能上沒有顯著差異,因為DAX 內部會將其轉換為一組嵌套的 IF 函數。
'Product'[SizeDesc] =
SWITCH ('Product'[Size],"S", "Small","M", "Medium","L", "Large","XL", "Extra Large","Other"
)
??SWITCH 可以結合 TRUE() 用于測試多個條件。例如:
SWITCH (TRUE (),Product[Size] = "XL" && Product[Color] = "Red", "Red and XL",Product[Size] = "XL" && Product[Color] = "Blue", "Blue and XL",Product[Size] = "L" && Product[Color] = "Green", "Green and L"
)
2.6.3.3 計算組:參數化計算的首選
??SWITCH 通常用于檢查參數的值和測量結果。例如,可以創建一個包含 YTD、MTD 和 QTD 的參數表,并讓用戶從三個可用的聚合中選擇在度量中使用哪個聚合。2019年之后由于計算組功能的引進,我們不再需要用到 SWITCH,計算組是參數化計算的首選方法。
2.6.4 信息函數
信息函數用于分析表達式的類型,并返回布爾值,這些函數可以在任何邏輯表達式中使用。常見的信息函數包括:
| 函數名稱 | 描述 | 函數名稱 | 描述 | 函數名稱 | 描述 |
|---|---|---|---|---|---|
| ISBLANK | 檢查值是否為空 | ISERROR | 檢查表達式是否返回錯誤 | ISLOGICAL | 檢查值是否為邏輯值(TRUE 或 FALSE) |
| ISNONTEXT | 檢查值是否為非文本類型 | ISNUMBER | 檢查值是否為數字 | ISTEXT | 檢查值是否為文本 |
//RETURNS: Is Text
= IF(ISTEXT("text"), "Is Text", "Is Non-Text")//RETURNS: Is Text
= IF(ISTEXT(""), "Is Text", "Is Non-Text")//RETURNS: Is Non-Text
= IF(ISTEXT(1), "Is Text", "Is Non-Text")//RETURNS: Is Non-Text
= IF(ISTEXT(BLANK()), "Is Text", "Is Non-Text")
//RETURNS: Is number
= IF(ISNUMBER(0), "Is number", "Is Not number")//RETURNS: Is number
= IF(ISNUMBER(3.1E-1),"Is number", "Is Not number")//RETURNS: Is Not number
= IF(ISNUMBER("123"), "Is number", "Is Not number")
??信息函數的限制:當使用列(而不是單個值)作為參數時,ISNUMBER、ISTEXT 和 ISNONTEXT 函數會根據列的數據類型返回固定值(TRUE 或 FALSE),而不是逐行檢查每個單元格的實際內容。這使得這些函數在 DAX 中的實用性有限。例如,如果列是文本類型,ISNUMBER 總是返回 FALSE,即使某些單元格中的文本可以轉換為數字。
??如果需要檢查文本列中的值是否可以轉換為數字,使用 ISNUMBER是無效的,例如以下表達式結果始終是 FALSE:
// 文本列,始終返回FALSE
Sales[IsPriceCorrect] = ISNUMBER ( Sales[Price] )
正確的方法是嘗試將文本值轉換為數字,并捕獲轉換過程中可能出現的錯誤,例如:
Sales[IsPriceCorrect] = NOT ISERROR(VALUE(Sales[Price]))
- 如果 VALUE(Sales[Price]) 轉換成功,
ISERROR返回 FALSE,因此NOT ISERROR返回 TRUE。 - 如果轉換失敗(例如,文本值為 “N/A”),
ISERROR返回 TRUE,因此NOT ISERROR返回 FALSE。
2.6.5 數學與三角函數
| 函數 | 說明 | 函數 | 說明 |
|---|---|---|---|
| ABS | 返回數字的絕對值 | CEILING | 向上舍入數字到最接近的整數或指定倍數 |
| CONVERT | 將一種數據類型的表達式轉換為另一種數據類型 | CURRENCY | 將結果轉為為貨幣數據類型 |
| DIVIDE | 除法 | EVEN | 向上舍入到最接近的偶數整數 |
| EXP | 返回 e 的給定次冪 | FACT | 返回數字的階乘 |
| FLOOR | 向下舍入到最接近的指定倍數 | GCD | 返回多個整數的最大公約數 |
| INT | 將數字向下舍入到最接近的整數。 | ISO.CEILING | 向上舍入到最接近的整數或指定倍數 |
| LCM | 返回多個整數的最小公倍數 | MOD | 返回除法結果的余數,始終與除數具有相同的符號。 |
| MROUND | 舍入到指定倍數 | ODD | 向上舍入到最接近的奇數整數 |
| PI | 返回 Pi 的值,3.14159265358979,精確到 15 位 | QUOTIENT | 返回除法的整數部分 |
| RAND | 返回 0 到 1 之間的隨機數 | RANDBETWEEN | 返回指定范圍內的隨機數 |
| ROUND | 舍入到指定的小數位數 | ROUNDDOWN | 向下舍入到指定的小數位數 |
| ROUNDUP | 向上舍入到指定的小數位數 | SIGN | 確定列中數字、計算結果或值的符號 |
| SQRT | 返回數字的平方根。 | TRUNC | 截斷數字的小數部分,只保留整數 |
以下是舍入函數的測試結果:
FLOOR = FLOOR ( Tests[Value], 0.01 )TRUNC = TRUNC ( Tests[Value], 2 )ROUNDDOWN = ROUNDDOWN ( Tests[Value], 2 )MROUND = MROUND ( Tests[Value], 0.01 )ROUND = ROUND ( Tests[Value], 2 )CEILING = CEILING ( Tests[Value], 0.01 )ISO.CEILING = ISO.CEILING ( Tests[Value], 0.01 )ROUNDUP = ROUNDUP ( Tests[Value], 2 )INT = INT ( Tests[Value] )FIXED = FIXED ( Tests[Value], 2, TRUE )

??除了可以指定要舍入的位數外,FLOOR、TRUNC 和 ROUNDDOWN 是相似的;CEILING 和 ROUNDUP 結果也是相似的; MROUND 和 ROUND 函數結果有一點差異。
- 基本三角函數:如
COS、SIN、TAN等,以及它們的雙曲函數和反函數。 - 角度轉換:如
DEGREES和RADIANS,用于角度和弧度之間的轉換。
2.6.6 文本函數
| 函數 | 說明 | 函數 | 說明 |
|---|---|---|---|
| COMBINEVALUES | 將多個文本字符串合并為一個文本字符串 | CONCATENATE | 將兩個文本字符串連接成一個文本字符串 |
| CONCATENATEX | 對表中的每一行計算表達式,并將結果連接成一個文本字符串 | EXACT | 比較兩個文本字符串是否完全相同(返回布爾值),區分大小寫。 |
| FIND | 返一個文本字符串在另一個一個文本字符串中的起始位置 | FIXED | 將數字舍入到指定的小數位數,并以文本形式返回 |
| FORMAT | 根據指定的格式將值轉換為文本。 | LEFT | 從文本字符串的開頭返回指定數量的字符 |
| LEN | 返回文本字符串的長度(總字符數) | LOWER 、 UPPER | 將文本字符串中的所有字母轉換為小寫/大寫 |
| MID | 從文本字符串的中間位置返回指定數量的字符 | REPLACE | 替換文本字符串中指定位置的字符 |
| REPT | 重復給定次數的文本。 | RIGHT | 從文本字符串的末尾返回指定數量的字符 |
| SEARCH | 返回特定字符或文本在文本字符串中的位置。 | SUBSTITUTE | 將文本字符串中的某些文本替換為其他文本 |
| TRIM | 刪除文本中的多余空格,僅保留單詞間的單個空格 | VALUE | 將表示數字的文本字符串轉換為數字 |
??下圖展示了如何從包含姓名的字符串中提取名字和姓氏,這些姓名字符串中可能包含一個或兩個逗號,以及可能的Mr。

People[Comma1] =IFERROR ( FIND ( ",", People[Name] ), BLANK () )People[Comma2] =IFERROR ( FIND ( " ,", People[Name], People[Comma1] + 1 ), BLANK () )People[SimpleConversion] =
MID ( People[Name], People[Comma2] + 1, LEN ( People[Name] ) ) & " "& LEFT ( People[Name], People[Comma1] - 1 )People[FirstLastName] =
TRIM (MID (People[Name],IF ( ISNUMBER ( People[Comma2] ), People[Comma2], People[Comma1] ) + 1,LEN ( People[Name] ))
)& IF (ISNUMBER ( People[Comma1] )," "& LEFT ( People[Name], People[Comma1] - 1 ),"")
Comma1,Comma2列:分別計算第一個和第二個逗號的位置;SimpleConversion列:使用 MID 和 LEFT 函數結合逗號位置來提取姓氏和名字。這個公式在字符串中逗號少于兩個時可能會返回不準確的值,如果沒有逗號,則會引發錯誤;FirstLastName列:通過 TRIM 和 MID 函數結合 IF 函數來處理不同的情況(首先檢查 Comma2 是否為數字,即是否存在第二個逗號),確保即使在缺少逗號的情況下也能正確提取姓名。
2.6.7 轉換函數
| 函數名稱 | 說明 | 示例 |
|---|---|---|
| CURRENCY | 將表達式轉換為貨幣類型 | CURRENCY(1234.56) |
| INT | 將表達式轉換為整數 | INT(1234.56) => 1234 |
| DATE | 返回指定年、月、日的日期值 | DATE(2019, 1, 12) => 2019-01-12 |
| TIME | 返回指定小時、分鐘、秒的時間值 | TIME(12, 0, 0) => 12:00:00 |
| VALUE | 將字符串轉換為數字格式 | VALUE("1234.56") => 1234.56 |
| FORMAT | 將數值轉換為文本字符串,可指定格式 | FORMAT(DATE(2019, 1, 12), "yyyy mmm dd") => "2019 Jan 12" |
| DATEVALUE | 將字符串轉換為 DateTime 值,支持不同日期格式 | DATEVALUE("28/02/2018") => 2018-02-28 |
創建一個計算列,使用減法來計算兩個日期列的差值,結果也是日期,可用INT函數將其轉為數字:
Sales[DaysToDeliver] = INT ( Sales[Delivery Date] - Sales[Order Date] )

2.6.8 日期和時間函數
| 函數名稱 | 說明 | 示例 | 返回值 |
|---|---|---|---|
| CALENDAR | 返回包含連續日期集的表 | CALENDAR(DATE(2024,1,1),DATE(2024,12,31)) | 表:Date |
| CALENDARAUTO | 返回包含連續日期集的表,自動處理周末 | CALENDARAUTO(DATE(2024,1,1),DATE(2024,12,31)) | 表:Date |
| DATE | 返回指定年月日的日期 | DATE(2024, 6, 11) | 2024-06-11 |
| DATEDIFF | 返回兩個日期之間的天數差異 | DATEDIFF(DATE(2024,1,1), DATE(2024,6,11), DAY) | 162 |
| DATEVALUE | 將文本形式的日期轉換為日期類型 | DATEVALUE(2024-06-11) | 2024-06-11 |
| DAY | 返回日期中的天數 | DAY(DATE(2024, 6, 11)) | 11 |
| EDATE | 返回開始日期前或后的指定月份數的日期 | EDATE(DATE(2024, 6, 11), 1) | 2024-07-11 |
| EOMONTH | 返回月份的最后一天或前/后的月份的最后一天 | EOMONTH(DATE(2024, 6, 11), 0) | 2024-06-30 |
| HOUR | 返回時間中的小時數 | HOUR(TIME(12, 30, 45)) | 12 |
| MINUTE | 返回時間中的分鐘數 | MINUTE(TIME(12, 30, 45)) | 30 |
| MONTH | 返回日期中的月份 | MONTH(DATE(2024, 6, 11)) | 6 |
| NETWORKDAYS | 返回兩個日期之間的工作日數 | NETWORKDAYS(DATE(2024,1,1), DATE(2024,1,31)) | 22 |
| NOW | 返回當前日期和時間 | NOW() | 2024-06-11 12:00:00 |
| QUARTER | 返回日期所在的季度 | QUARTER(DATE(2024, 6, 11)) | 2 |
| SECOND | 返回時間中的秒數 | SECOND(TIME(12, 30, 45)) | 45 |
| TIME | 將小時、分鐘和秒轉換為時間 | TIME(12, 30, 45) | 12:30:45 |
| TIMEVALUE | 將文本格式的時間轉換為時間類型 | TIMEVALUE(12:30:45) | 12:30:45 |
| TODAY | 返回當前日期 | TODAY() | 2024-06-11 |
| UTCNOW | 返回當前UTC日期和時間 | UTCNOW() | 2024-06-11 12:00:00 UTC |
| UTCTODAY | 返回當前UTC日期 | UTCTODAY() | 2024-06-11 UTC |
| WEEKDAY | 返回日期的星期幾 | WEEKDAY(DATE(2024, 6, 11)) | 3 |
| WEEKNUM | 返回日期所在的周數 | WEEKNUM(DATE(2024, 6, 11)) | 24 |
| YEAR | 返回日期的年份 | YEAR(DATE(2024, 6, 11)) | 2024 |
| YEARFRAC | 計算兩個日期之間的年份分數 | YEARFRAC(DATE(2024,1,1), DATE(2024,6,11)) | 0.4952 |
三、表函數
3.1 簡介
??表函數:返回表而非標量的函數稱為表函數,可代替表作為函數的參數進行傳參。比如我們可以遍歷 sales 表進行迭代計算:
Sales Amount := SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
我們可以使用表函數生成的表代替SUMX中的第一個參數,進行更更復雜的計算:
Sales Amount Multiple Items :=
VARMultipleItemSales = FILTER ( Sales, Sales[Quantity] > 1 )
RETURNSUMX (MultipleItemSales,Sales[Quantity] * Sales[Unit Price])
??表函數嵌套:DAX函數經常嵌套使用,先計算最里面的函數,然后逐層遞進到最外層的函數。下式通過 RELATEDTABLE 獲取與當前產品相關的銷售記錄,然后使用 FILTER 篩選出銷售數量大于1的記錄,最后使用 SUMX 對這些記錄的銷售額進行求和。
'Product'[Product Sales Amount Multiple Items] =
SUMX (FILTER (RELATEDTABLE ( Sales ),Sales[Quantity] > 1),Sales[Quantity] * Sales[Unit Price]
)
?? RELATEDTABLE 函數用于獲取與當前產品相關的所有銷售記錄。它返回一個表,其中包含銷售表中與當前產品相關聯的所有行。
??計算表:表函數還可以用來創建計算表( DAX 表達式生成的表,而不是從數據源加載的)。計算表會存儲為模型的一部分,常用于中間計算。例如創建一個單價大于3000的產品表:
ExpensiveProducts =
FILTER ('Product','Product'[Unit Price] > 3000
)
3.2 DAX查詢
參考《DAX 查詢》
??DAX查詢是一種基于DAX語言的查詢方式,是表格模型(如 Power BI、SSAS)底層數據處理的核心框架。無論是將DAX度量值、計算列或計算表拖放到報表中,還是進行篩選、排序等操作,實質上是在調用 DAX 查詢來計算和顯示結果。這種調用通常是通過工具的引擎自動完成的,用戶無需直接編寫查詢語句。然而,在某些場景下,手動編寫DAX查詢是非常有用的,例如:
- 動態生成臨時分析表,而不修改現有數據模型;
- 測試度量值邏輯,通過DEFINE MEASURE快速驗證其準確性;
- 實現復雜的數據透視,替代Power BI可視化控件的默認聚合邏輯;
- 導出特定的計算結果,例如生成報表的底層數據。
??與DAX公式(如度量值、計算列)不同,DAX查詢獨立于數據模型,通過EVALUATE語句等關鍵字直接動態生成結果。用戶可以利用SQL Server Management Studio(SSMS)、Power BI報表生成器以及開源工具(如DAX Studio)等來創建和運行自己的DAX查詢。接下來,我們將詳細介紹DAX查詢語句的編寫方式。
3.2.1 DAX 查詢的關鍵字
??DAX 查詢的語法相對簡單,主要包括一個必需關鍵字 EVALUATE 以及幾個可選關鍵字,每個關鍵字都定義了一個在查詢期間使用的語句。
| 陳述 | 描述 |
|---|---|
| DEFINE | 用于定義查詢中使用的變量、度量值或表,這些定義僅在當前查詢中有效 |
| EVALUATE | 執行DAX查詢的核心部分,返回表表達式的結果 |
| MEASURE | 定義一個度量值,可在查詢中多次使用 |
| ORDER BY | 對EVALUATE語句返回的的結果進行排序 |
| START AT | 與ORDER BY配合使用,指定排序結果的起始值 |
| VAR | 定義一個變量,存儲中間結果,便于在復雜查詢中復用 |
3.2.1.1 EVALUATE(必須)
??EVALUATE 是 DAX 查詢中最基本的關鍵字,用于指定一個表表達式。一個 DAX 查詢至少需要包含一個 EVALUATE 語句,但也可以包含多個。其語法結構為:
EVALUATE <table>
例如,以下查詢將返回 “Internet Sales” 表中的所有行和列:
EVALUATE'Internet Sales'
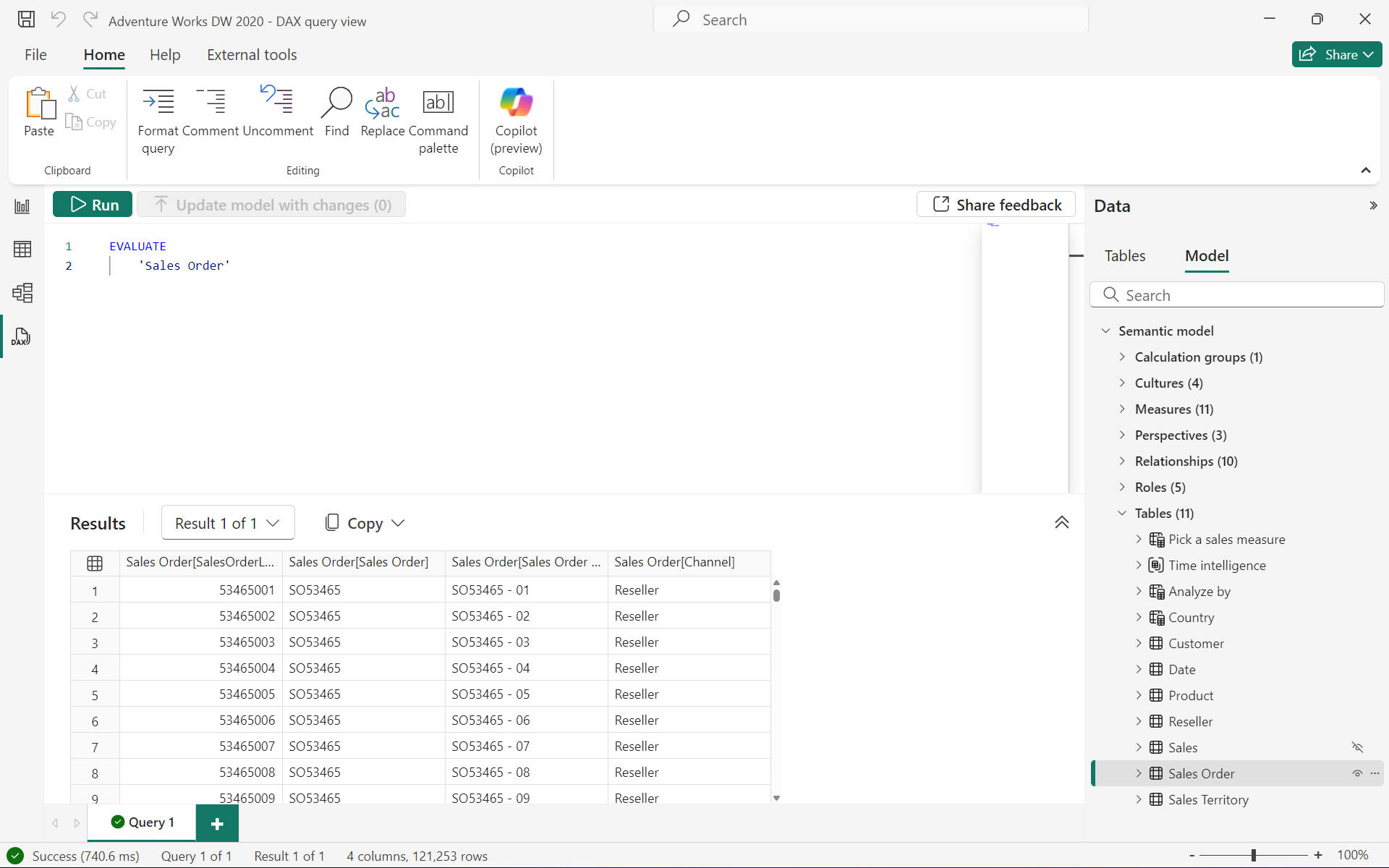
3.2.1.2 ORDER BY(可選)
ORDER BY 關鍵字用于定義一個或多個表達式(返回標量),以對查詢結果進行排序,其語法結構為:
EVALUATE <table>
[ORDER BY {<expression> [{ASC | DESC}]}[, …]]
??其中,ASC 表示升序排序(默認值),DESC 表示降序排序。例如以下查詢將返回 “Internet Sales” 表中的所有行和列,并按 “Order Date” 升序排序:
EVALUATE'Internet Sales'
ORDER BY'Internet Sales'[Order Date]

3.2.1.3 START AT(可選)
??START AT 關鍵字用于 ORDER BY 子句內,定義查詢結果開始的值。START AT 參數必須與 ORDER BY 子句中的列一一對應,其參數數量不能超過 ORDER BY 中的列數量,例如第一個參數定義第一列的起始值,第二個參數定義在第一列值滿足第一個參數的情況下,第二列的起始值。,其語法為:
EVALUATE <table>
[ORDER BY {<expression> [{ASC | DESC}]}[, …]
[START AT {<value>|<parameter>} [, …]]]
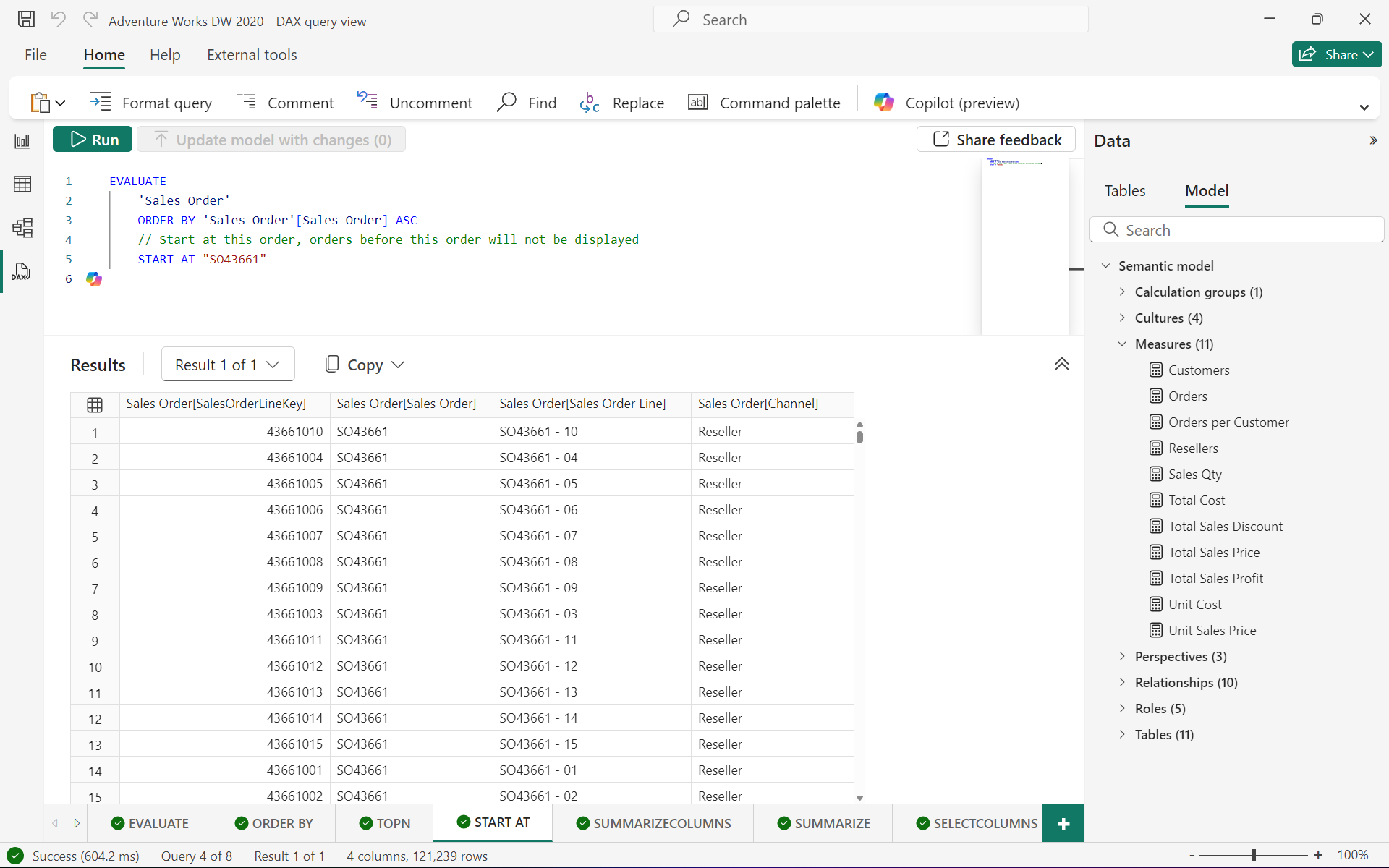
以下查詢將從 “SO7000” 開始返回 “Internet Sales” 表中的所有行和列,并按 “Sales Order Number” 升序排序:
EVALUATE'Internet Sales'
ORDER BY'Internet Sales'[Sales Order Number]
START AT "SO7000"
3.2.1.4 DEFINE(可選)
??DEFINE 關鍵字用于在 DAX 查詢中定義臨時的計算實體(如變量、度量值、表或列),這些定義僅在查詢期間有效。它位于 EVALUATE 語句之前,并且對查詢中的所有 EVALUATE 語句都有效,其語法為:
[DEFINE ((MEASURE <table name>[<measure name>] = <scalar expression>) | (VAR <var name> = <table or scalar expression>) |(TABLE <table name> = <table expression>) | (COLUMN <table name>[<column name>] = <scalar expression>) | ) +
](EVALUATE <table expression>) +
- 定義的實體:可以是MEASURE、VAR、TABLE或COLUMN
- 名稱:定義的實體名稱,必須是文本。此名稱不必是唯一的,因為僅在查詢期間有效。
- 表達式:任何返回表或標量值的 DAX 表達式。如果需要將標量表達式轉換為表表達式,請使用大括號
{}將表達式包裝在表構造函數中,或使用ROW()函數返回一個具有單行的表。
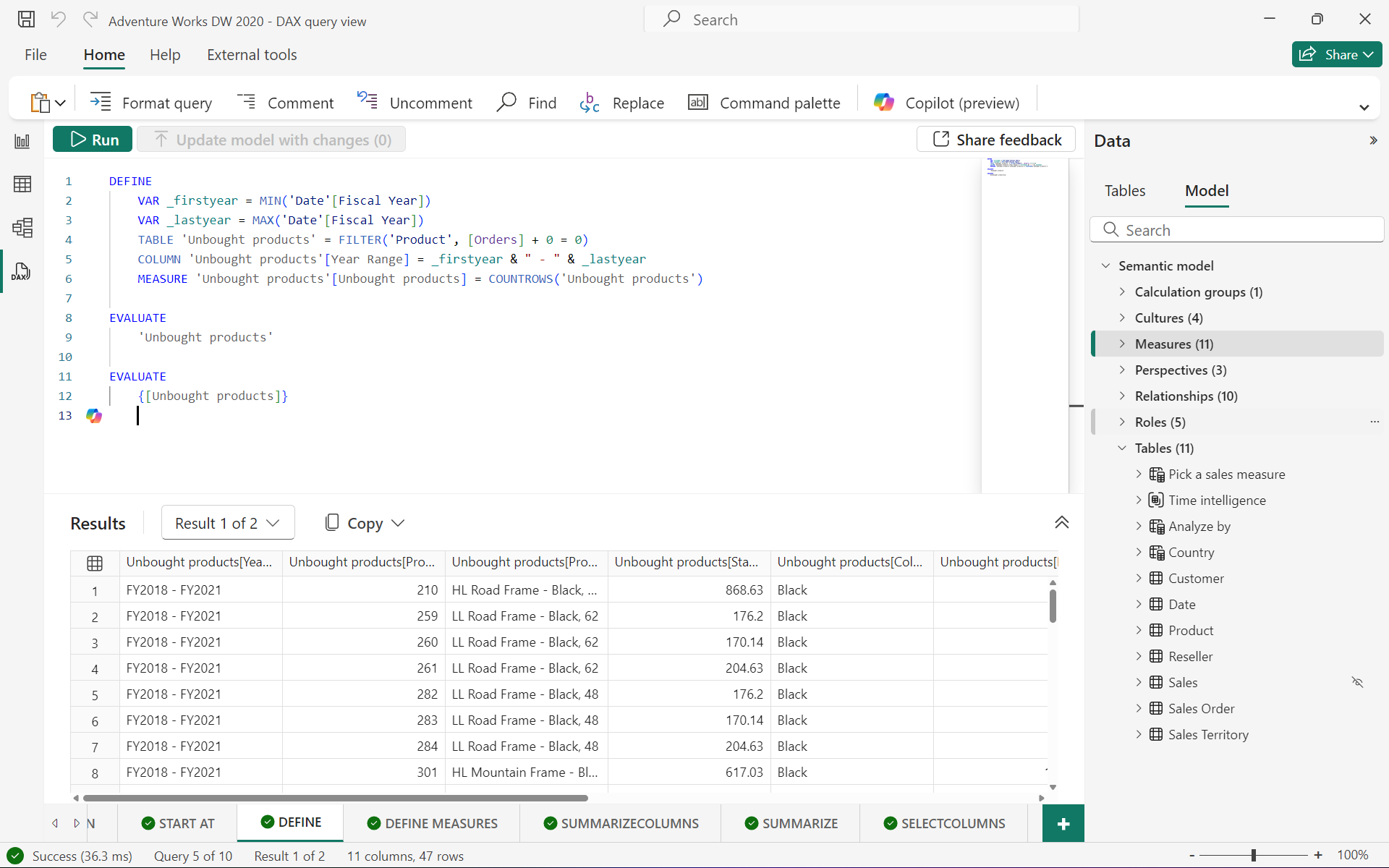
例如定義臨時度量值并計算:
DEFINEMEASURE 'Internet Sales'[Internet Total Sales] =SUM ( 'Internet Sales'[Sales Amount] )EVALUATE
SUMMARIZECOLUMNS ('Date'[Calendar Year],TREATAS ({2013,2014},'Date'[Calendar Year]),"Total Sales", [Internet Total Sales],"Combined Years Total Sales",CALCULATE ([Internet Total Sales],ALLSELECTED ( 'Date'[Calendar Year] ))
)
ORDER BY [Calendar Year]
??該查詢通過 DEFINE 定義了一個度量值 “Internet Total Sales”,然后使用SUMMARIZECOLUMNS函數對數據進行匯總和分析,計算 2013 年和 2014 年的總銷售額,最后將結果按 “Calendar Year” 排序。
注意事項:
- 查詢中只能有一個 DEFINE 語句,但可以包含多個定義;
- 定義臨時度量值(
MEASURE):查詢中的度量值定義會覆蓋同名的模型度量值,但僅在查詢內有效,不會修改數據模型。 - 不建議使用 TABLE 和 COLUMN 定義,因為它們可能會導致運行時錯誤。
- 復雜查詢可能導致性能問題,建議先用
SUMMARIZE或GROUPBY減少數據量。 - 避免在查詢中使用過多嵌套的
FILTER,改用CALCULATE修改上下文。
以下函數常用于 EVALUATE 塊中生成表:
SUMMARIZE:按指定列分組,類似 SQL 的 GROUP BY。ADDCOLUMNS:向現有表添加計算列。FILTER:篩選表中的行。CROSSJOIN:生成多表的笛卡爾積。TOPN:返回前 N 行(如排名分析)
3.2.2 DAX 查詢中的參數化與應用示例
??DAX 查詢支持參數化,用戶可以通過 Execute 方法(XMLA)的 Parameters 元素來定義參數并為其分配值。在查詢中,可以通過為參數名稱加上 @ 字符作為前綴來引用這些參數。參數化查詢可以提高查詢的靈活性和可重用性,用戶只需更改參數值即可重復使用同一個查詢語句。
| 應用場景 | 操作 | 說明 |
|---|---|---|
| 數據探索 | 簡單查詢 | 直接操作物理表,快速提取數據 |
| 動態分析與測試 | 定義臨時度量值進行分析 | 1. 臨時報表需求:快速生成分享一個臨時報表(臨時度量值不會污染數據模型) 2. 驗證度量邏輯:測試 度量值的邏輯是否正確 ,而不用修改模型 3. 動態參數化查詢 |
總結:
- DAX 查詢:適合臨時性、一次性分析,或需要動態調整邏輯的場景。DAX Studio支持調試查詢、查看執行計劃和性能分析;SQL Profiler可監控 SSAS 或 Power BI 的查詢執行過程。
- 模型度量值:適合重復使用、需要與報表交互的固定邏輯。
3.3 FILTER
3.3.1 基本用法
??FILTER 是一個表函數,同時也是迭代器。它的主要作用是從一個表中篩選出滿足特定條件的行。其語法如下。其中,兩個參數分別代表需要篩選的表以及篩選條件表達式。FILTER 函數會逐行掃描表,并返回滿足條件的所有行。
FILTER ( <table>, <condition> )
??FILTER 最基本的用途是根據條件篩選數據。例如,如果要計算紅色產品的數量,如果不使用表函數,一種可能的實現方式是:
NumOfRedProducts :=
SUMX ('Product',IF ( 'Product'[Color] = "Red", 1, 0 )
)
??這段代碼的意圖不夠直觀,它沒有直接表達“計算紅色產品的數量”,而是通過“對每一行判斷顏色并累加計數”的方式實現。而且SUMX 是一個迭代函數,它會對表中的每一行進行迭代計算。雖然 IF 函數本身開銷不大,但當表非常大時,這種逐行迭代的方式可能會導致性能問題。
??更優的方式是使用FILTER 函數先篩選出紅色產品,再進行計算:
NumOfRedProducts :=
COUNTROWS (FILTER ( 'Product', 'Product'[Color] = "Red" )
)
??這段代碼直接表達了“篩選紅色產品并計數”的邏輯,可讀性強,而且DAX 優化器能夠更好地理解其意圖,從而生成更高效的查詢計劃(FILTER 函數在內部進行了優化,能夠更高效地處理篩選邏輯,性能通常優于逐行迭代)。
3.3.2 嵌套使用
??FILTER 函數可以嵌套使用,以實現更復雜的篩選條件。例如,以下代碼篩選出品牌為 Fabrikam 且利潤率高于成本3倍的產品:
FabrikamHighMarginProducts =
FILTER (FILTER ('Product','Product'[Brand] = "Fabrikam"),'Product'[Unit Price] > 'Product'[Unit Cost] * 3
)
雖然嵌套 FILTER 可以實現復雜篩選,但也可以使用 AND 來簡化代碼,并實現相同的功能。例如,上述嵌套 FILTER 可以改寫為:
FabrikamHighMarginProducts =
FILTER ('Product',AND ('Product'[Brand] = "Fabrikam",'Product'[Unit Price] > 'Product'[Unit Cost] * 3)
)
3.3.3 性能優化
-
高選擇性條件優先:在處理大型表時,
FILTER函數的性能至關重要。如果一個條件比另一個條件更具選擇性(即能更快地過濾掉大量行),建議將其放在內層(當存在嵌套調用時,DAX 通常先計算最里面的函數)。例如:// 比起Fabrikam品牌,高于成三倍的產品更少,所以優先篩選 FabrikamHighMarginProducts = FILTER (FILTER ('Product','Product'[Unit Price] > 'Product'[Unit Cost] * 3),'Product'[Brand] = "Fabrikam" ) -
優先使用布爾篩選器:建議盡量使用布爾篩選器,比如直接在 CALCULATE 函數中指定的條件,在在必要時才使用
FILTER函數,比如第一個示例可以寫作:NumOfRedProducts := CALCULATE (COUNTROWS ( 'Product' ),'Product'[Color] = "Red" )- 布爾篩選器的優勢:布爾篩選器直接作用于列,可以快速地在內部進行篩選。這種篩選方式是高度優化的,因為它直接利用了列存儲的索引結構,而表表達式(如
FILTER函數)需要生成一個滿足條件的子表,此過程涉及到逐行迭代和條件評估,因此比直接使用布爾篩選器的開銷要大。 - 布爾表達式的局限性:布爾篩選器作為篩選器參數使用時,存在一些限制,包括不能引用多個表中的列、不能引用度量值、不能使用嵌套 CALCULATE 函數、不能使用掃描或返回表的函數。表表達式可以滿足更復雜的篩選要求,所以建議在必要時才使用
FILTER函數。
- 布爾篩選器的優勢:布爾篩選器直接作用于列,可以快速地在內部進行篩選。這種篩選方式是高度優化的,因為它直接利用了列存儲的索引結構,而表表達式(如
3.4 ALL 、 ALLEXCEPT、ALLSELECTED
| 函數 | 描述 | 適用場景 |
|---|---|---|
ALL | 清除指定表或列的任何篩選條件。 | 用于計算全局值,忽略當前篩選上下文。 |
ALLEXCEPT | 清除表中指定列之外其他列的所有篩選條件。 | 用于計算全局值,但保留某些關鍵列的篩選條件。 |
ALLSELECTED | 保留外部篩選器(報表、頁面或可視化控件上的篩選器) 忽略內部篩選器 | 根據用戶的選擇動態調整計算,返回當前報表或可視化中可見的值 |
3.4.1 ALL :清除篩選
ALL 函數用于返回一個表的所有行,或者指定列的所有不同值。它的語法如下:
ALL ( <table> )
ALL ( <column>, [<column>], ... )
- 如果參數是表名,
ALL返回該表的所有行。 - 如果參數是列名,
ALL返回這些列的所有不同值。如果將多個列作為參數傳遞給ALL,則得到多個列的所有不同值組合
假設我們需要計算銷售額占總銷售額的百分比,ALL 函數可以幫助我們忽略報表中的篩選器,計算總銷售額:
Sales Amount :=
SUMX (Sales,Sales[Quantity] * Sales[Net Price]
)All Sales Amount :=
SUMX (ALL ( Sales ),Sales[Quantity] * Sales[Net Price]
)Sales Pct := DIVIDE ( [Sales Amount], [All Sales Amount] )
??在這個例子中,All Sales Amount 使用 ALL ( Sales ) 忽略了報表中的篩選器,計算了所有銷售額的總和。這樣,即使報表篩選了某個類別,Sales Pct 仍然可以正確計算銷售額的百分比。

3.4.2 ALLEXCEPT :清除指定列之外的篩選
ALLEXCEPT 函數用于從指定表的所有列中移除篩選器,除了你明確指定想要保留的那些列。其語法為:它的語法如下:
ALLEXCEPT ( <table>, <column>, [<column>], ... )
- 參數
<table>是要處理的表。 - 參數
<column>是要排除的列。
假設我們有一個包含多列的 Product 表,我們希望生成一個包含所有列的值組合,但排除 ProductKey 和 Color 列:
ALLEXCEPT ( 'Product', 'Product'[ProductKey], 'Product'[Color] )
??假設我們想要生成一個儀表板,顯示銷售金額超過平均銷售金額兩倍的產品的類別和子類別,代碼如下(更好的方式是使用CALCULATE函數):
BestCategories =
// 存儲所有類別和子類別的列表
VAR Subcategories =ALL ('Product'[Category],'Product'[Subcategory])
// 計算每個子類別的平均銷售額
VAR AverageSales =AVERAGEX (Subcategories,SUMX (RELATEDTABLE ( Sales ),Sales[Quantity] * Sales[Net Price]))
// 使用 FILTER 函數篩選出銷售金額超過平均值兩倍的子類別
VAR TopCategories =FILTER (Subcategories,VAR SalesOfCategory =SUMX (RELATEDTABLE ( Sales ),Sales[Quantity] * Sales[Net Price])RETURNSalesOfCategory >= AverageSales * 2)
RETURNTopCategories

3.4.3 ALLSELECTED 只保留外部(報表)篩選器
??ALLSELECTED只保留用戶通過篩選器或交互操作所選擇的篩選條件,而忽略當前可視化對象內部的篩選條件,最終根據用戶選擇,返回當前報表的可見值。
??假設我們有一個包含矩陣和切片器的報告,在這個報告中,我們計算了一個名為 Sales Pct 的度量值,表示銷售額的百分比。由于使用ALL 函數,不考慮任何我篩選器,所以即使用戶在報表上使用切片器進行類別篩選,計算是還是所有類別的銷售占比,所以總計結果不是100%。
Sales Pct :=
DIVIDE (SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ),SUMX ( ALL ( Sales ), Sales[Quantity] * Sales[Net Price] )
)

??如果使用ALLSELECTED ,計算時只考慮當前用戶通過切片器篩選之后的類別數據,總結為100%。報告的數字反映的是與可見總數的百分比,而不是與所有銷售總額的百分比。這正是我們期望的結果。
Sales Pct :=
DIVIDE ( SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ), SUMX ( ALLSELECTED ( Sales ), Sales[Quantity] * Sales[Net Price] )
)

??ALLSELECTED 是一個強大而有用的 DAX 函數,尤其適用于需要根據用戶選擇的篩選條件動態調整計算范圍的場景。然而,由于其復雜性,ALLSELECTED 有時會返回意外結果(需要動態地根據用戶的選擇和報表的全局篩選條件來調整篩選范圍)。
3.5 VALUES 與 DISTINCT
3.5.1 語法
??常規關系中,當關系無效時,DAX 引擎會自動在表中添加一個空白行,以維護引用完整性(簡單理解就是即使不匹配的項,也添加一個空白行來匹配它,詳見《PowerBI數據建模基礎操作1》2.7章節)。 VALUES與 DISTINCT在處理空白行時表現不同:
| 函數 | 返回結果 | 說明 |
|---|---|---|
VALUES(Column) | 返回列的唯一值列表,考慮篩選器和空白行(如果存在) | 如果某列包含關聯表中不存在的值 計算引擎會添加一個空白項來表示這種不匹配 |
VALUES(TableName) | 返回表的所有行,再加一個空白行(如果存在不匹配情況) | 僅接受表引用 |
DISTINCT(Column) | 返回唯一值列表,考慮篩選器但不考慮空白行 | 純粹基于列本身的去重,不檢查關聯表的有效性。 |
DISTINCT(Table) | 返回表的唯一行,不考慮空白行 | 接受任何有效的表表達式。 |
- 在計算列或計算表中,因為不存在篩選器,
VALUES與DISTINCT和ALL返回的結果是一樣的,如果是在度量值中,因為考慮篩選器,結果會不一樣。 - 根據經驗,
VALUES應該是您的默認選擇,只有當您希望顯式排除可能的空白值時,才使用 DISTINCT。
3.5.2 空白行的產生
??下面演示如何產生空白行。在以下模型中,產品表和銷售表以ProductKey鍵進行一對多連接,其中產品表是“一”方。產品分為不同的種類,每個產品還有不同的顏色,總共16種顏色。

??現在刪除產品表中所有的銀色產品。對于常規關系,為了維護引用完整性,計算引擎會自動為不匹配的關系添加空白行。
- 孤立行:銷售表中的銀色產品無法在產品表中找到匹配的記錄,這些無法匹配的行被稱為“孤立行”
- 引入空白行:為了維護引用完整性,即仍然考慮這些孤立行,DAX 引擎會在產品表中自動添加一個空白行。所有孤立行都會鏈接到這個空白行。
- 空白行的所有列值都是空白(BLANK),且無論銷售表有多少孤立行,產品表中也只會添加一個空白行。
- 表視圖中不可見:如果在表視圖中檢查產品表,是看不到空白行的,因為它是在加載數據模型期間自動創建的行。如果恢復了所有的銀色產品,則一對多關系完全匹配,空白行將從表中消失。
接著創建以下三個度量值,統計產品表中的顏色數:
NumOfAllColors := COUNTROWS ( ALL ( 'Product'[Color] ) ) // ALL 函數始終返回列的所有唯一值,不考慮任何篩選器
NumOfColors := COUNTROWS ( VALUES ( 'Product'[Color] ) ) // VALUES考慮篩選器和空白行
NumOfDistinctColors := COUNTROWS ( DISTINCT ( 'Product'[Color] ) ) // DISTINCT考慮篩選器,但不考慮空白行

3.5.3 處理無效關系
??一個設計良好的模型不應該出現任何無效的關系。因此,如果您的模型是完美的,那么VALUES 與 DISTINCT這兩個函數總是返回相同的值。如果存在無效關系,那么計算時就要注意了。假設我們要計算每個產品的平均銷售額,有三種方式:
-
使用
VALUES:AvgSalesPerProduct := DIVIDE ( SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ), COUNTROWS ( VALUES ( 'Product'[Product Code] ) ) ) -
使用
DISTINCT:AvgSalesPerDistinctProduct := DIVIDE ( SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ), COUNTROWS ( DISTINCT ( 'Product'[Product Code] ) ) ) -
使用
VALUES,但統計連接字段Sales[ProductKey]AvgSalesPerDistinctKey := DIVIDE ( SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ), COUNTROWS ( VALUES ( Sales[ProductKey] ) ) )

AvgSalesPerProduct:VALUES會將所有空白行視為一個單獨的行(分母為1),相當于不同種類的銀色產品的銷量都聚合到一起,結果是一個異常大的數;AvgSalesPerDistinctProduct:DISTINCT完全忽略空白行,孤立行計算結果為空白(BLANK)AvgSalesPerDistinctKey:使用VALUES考慮空白行情況,但直接從銷售表中 進行統計,避免了產品表中可能存在的空白行問題(銷售表的Sales[ProductKey]字段依舊保留所有銀色產品的正確行數)。
3.6 單個值的表
??單一的數字或文本值稱之為標量值(例如3.14),度量值必須返回標量值。不過在 DAX 中,一個只有一行一列的表可以像標量值一樣使用,例如{3.14}。例如VALUES 函數可以用于計算標量值,但需要確保返回的表只有一行一列。
3.6.1 使用IF…VALUES組合
??假設我們有一個按類別和子類別劃分的品牌數量報告,我們還想同時看到品牌名,一種可能的解決方案是使用 VALUES 來檢索不同的品牌并返回它們的值。但是,只有在品牌只有一種值的特殊情況下才是可能的,所以我們需要使用IF 語句保護代碼,如果返回空白,表示存在多個品牌值。
Brand Name :=
IF ( COUNTROWS ( VALUES ( Product[Brand] ) ) = 1, VALUES ( Product[Brand] )
)

3.6.2 使用HASONEVALUE…VALUES組合
??上述代碼使用 COUNTROWS 檢查 Products 表的 Brand 列是否只選擇了一個值,另一個更簡單的函數是HASONEVALUE,它可以自動檢查列是否只有一個可見值(返回TRUE或FALSE):
Brand Name :=
IF ( HASONEVALUE ( 'Product'[Brand] ), VALUES ( 'Product'[Brand] )
)
3.6.3 使用SELECTEDVALUE函數
??為了簡化開發人員的工作,DAX 提供了一個 SELECTEDVALUE 函數,該函數自動檢查列是否包含單個值。如果包含,則將該值作為標量返回;如果有多個值,也可以定義要返回的默認值,其語法為:
// 兩個參數分別是列名和多個值時返回的默認值
SELECTEDVALUE(<columnName>[, <alternateResult>])
上述代碼可改為:
Brand Name := SELECTEDVALUE ( 'Product'[Brand], "Multiple brands" )
3.6.4 使用CONCATENATEX,連接所有表值
??如果想要列出所有品牌,而不是返回 “Multiple brands” 這樣的信息,可以使用 CONCATENATEX 函數。CONCATENATEX可以迭代一個表的值,并將它們連接成一個字符串,其語法為:
CONCATENATEX(<table>, <expression>[, <delimiter> [, <orderBy_expression> [, <order>]]...])
| 參數 | 描述 |
|---|---|
<table> | 要計算的表 |
<expression> | 計算的表達式,逐行迭代,通常是一個列引用或更復雜的表達式。 |
<delimiter> | (可選)用于連接各個值的分隔符。如果不指定,默認為空字符串。 |
<orderBy_expression> | (可選)用于對輸出字符串中的值進行排序的表達式,逐行迭代 |
<order> | (可選)指定排序方式,默認值為降序(DESC、FALSE或0都可以);也可以是是升序 ( ASC、TRUE或1都可以) |
上述代碼可改為:
[Brand Name] :=
CONCATENATEX ( VALUES ( 'Product'[Brand] ), 'Product'[Brand], ", "
)

??注意:
CONCATENATEX是一個迭代函數,如果表非常大,建議先對表進行篩選或優化,比如先使用VALUES或DISTINCT函數去重。
CONCATENATEX可以進行多列計算。假設我們有一個名為 Employees 的表,結構如下:
| FirstName | LastName |
|---|---|
| Alan | Brewer |
| Michael | Blythe |
以下代碼返回 “Alan Brewer, Michael Blythe”。
= CONCATENATEX(Employees, [FirstName] & " " & [LastName], ",")
四、計算上下文
??在 DAX 中,計算上下文是指公式在執行計算時所處的“環境”,同一 DAX 表達式在不同的上下文中可能會產生不同的結果。計算上下文分為兩種:篩選上下文和行上下文,篩選上下文篩選,行上下文迭代。
4.1 篩選上下文與行上下文
4.1.1 篩選上下文的定義與作用
??篩選上下文是 DAX 中最常見的一種上下文,它的作用是對數據進行篩選。篩選上下文由報表中的行、列、切片器以及其他可視化元素(比如報表上的篩選器)共同定義,是所有篩選的集合。每個單元格的篩選上下文是獨立的,它決定了該單元格計算時所使用的數據子集。
??比如以下度量值,放入矩陣中,每個單元格的篩選上下文會同時篩選行(品牌)和列(年份)以及切片器選項(Education),這種篩選上下文的定義使得每個單元格的計算結果都不同。
Sales Amount:= SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
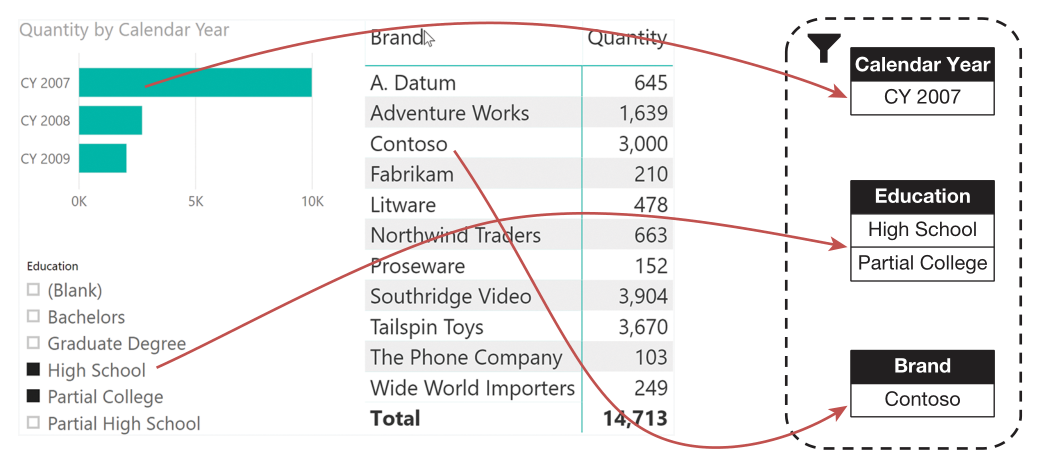
??對于左上角的單元格(A.Datum, CY 2007, 57,276.00),其篩選上下文包含行(品牌Contoso)。列(CY2007)以及切片器的選擇( High School 和 Partial College)。
4.1.2 行上下文
??當我們定義一個計算列時,DAX 會自動為每一行創建一個行上下文,從而逐行計算表達式的結果,而無需手工創建(計算列的計算永遠在行上下文中執行)。例如,定義一個計算列來計算毛利潤:
Sales[Gross Margin] = Sales[Quantity] * (Sales[Net Price] - Sales[Unit Cost])
在這個例子中,DAX 會逐行計算 Sales[Quantity]、Sales[Net Price] 和 Sales[Unit Cost] 的值,并計算出每行的毛利潤。
行上下文也可以通過迭代函數(如 SUMX)來手動創建,例如,定義一個度量值來計算總毛利潤:
Gross Margin :=
SUMX (Sales,Sales[Quantity] * ( Sales[Net Price] - Sales[Unit Cost] )
)
行上下文的一個重要特性是它允許列引用。在行上下文中,DAX 可以通過列引用獲取某行的值。然而,如果沒有行上下文,列引用是無法工作的。例如,以下度量值是非法的:
Gross Margin := Sales[Quantity] * (Sales[Net Price] - Sales[Unit Cost])
這個公式試圖直接引用列的值,但由于沒有行上下文,DAX 無法確定應該使用哪一行的值。因此,這個公式在度量值中是不合法的,但在計算列中是合法的,因為計算列會自動創建行上下文。
| 特性 | 篩選上下文 | 行上下文 |
|---|---|---|
| 作用 | 篩選數據,定義數據子集 | 逐行計算表達式,獲取列值 |
| 創建方式 | 由報表的行、列、切片器等定義 | 通過計算列或迭代函數創建 |
| 影響范圍 | 影響整個數據模型 | 僅影響當前表的行 |
| 使用場景 | 通常用于報表中,通過行、列和切片器等元素定義數據的篩選條件。 | 用于計算列和迭代函數中,逐行計算表達式。 |
4.2 計算上下文的常見誤區
4.2.1 在計算列中使用聚合函數
考慮以下公式,在 Sales 表中的計算列中的使用SUM函數,結果會是怎樣的呢?
Sales[SumOfSalesQuantity] = SUM ( Sales[Quantity] )
- 每行的值不同。
- 所有行的值相同。
- 錯誤;無法在計算列中使用 SUM。-
??正確答案是計算列中的每一行都會顯示相同的值,即 Sales[Quantity] 的總計。因為計算列是在數據刷新時計算的,計算時通過行上下文進行逐行迭代。此公式中只有計算列自動生成的行上下文,沒有篩選上下文,因此篩選上下文為空。SUM 函數在這種情況下會作用于整個 Sales 表,所有行的計算結果都是一樣的,即 Sales[Quantity] 的總計。本質上,此公式等同于:
Sales[SumOfSalesQuantity] = SUMX ( Sales, Sales[Quantity])
??很多人會錯誤地認為,計算列中的每一行會顯示不同的值,即當前行的 Sales[Quantity] 的值。這種誤解的根源在于混淆了篩選上下文和行上下文。實際上,行上下文只是告訴 DAX 在當前行中進行計算,但它不會篩選數據。再次記住:篩選上下文篩選,行上下文迭代。
4.2.2 在度量值中使用列
考慮以下公式,下面三個選項哪個是正確的?
GrossMargin% := ( Sales[Net Price] - Sales[Unit Cost] ) / Sales[Unit Cost]
- 公式工作正常,需要在報表中驗證結果。
- 錯誤,無法編寫公式。
- 可以編寫公式,但在報表中返回錯誤信息。
??這個公式試圖計算毛利百分比,但沒有使用任何聚合函數。由于這個公式沒有提供行上下文,不知道該用哪一行的值進行計算,所以這個公式在度量值中的無效的。不過此公式在計算列中是有效的,因為計算列會自動創建行上下文。
4.3 迭代與行上下文
4.3.1 使用迭代函數創建行上下文
??上一節在度量值中直接使用列引用是不正確的,因為沒有提供行上下文。如果要在度量值中進行列引用,正確的做法是通過迭代函數(比如 SUMX)來創建行上下文,比如上式可改為:
GrossMargin% :=
SUMX (Sales, // 外部篩選上下文和行上下文( Sales[Net Price] - Sales[Unit Cost] ) / Sales[Unit Cost] // 外部篩選上下文、行上下文 以及新的行上下文
)
??在這個式子中,SUMX 作為迭代器函數,在處理 Sales 表(第一個參數)時會創建一個行上下文。計算時,它將每行的值傳遞給表達式(第二個參數)進行以進行逐行計算。所有迭代器函數的執行方式都一樣:
- 根據當前上下文計算第一個參數,以確定需要掃描的表。
- 為表的每一行創建一個行上下文。要注意的是:
- 迭代器函數不會修改已存在的篩選上下文(比如篩選紅色產品),而是在已有的上下文中添加一個新的行上下文。
- 對于嵌套行上下文,DAX 會優先使用當前正在迭代的行上下文,而無法直接訪問外層的行上下文。也就是如果表上已經有行上下文(外層循環),新創建的行上下文(內層循環)會覆蓋之前創建的的行上下文。
- 迭代整張表,在已確定的上下文(篩選上下文+行上下文)中執行表達式(第2個參數)計算。
- 聚合計算結果。
4.3.2 不同表上的嵌套行上下文(RELATED 和 RELATEDTABLE )
??DAX 支持迭代器嵌套,即在一個迭代器的表達式中使用另一個迭代器,這樣可以生成非常強大的表達式,在處理多表關聯時非常有用。例如下面這個嵌套的 SUMX 函數,它掃描三個表:Categories,Products , Sales;計算每個產品分類下的總銷售額,同時考慮了產品的單價和分類的折扣。
SUMX ('Product Category', -- 最外層迭代器,逐行掃描 'Product Category' 表,處理每個產品分類SUMX (RELATEDTABLE ( 'Product' ), -- 對于每個產品分類,獲取與當前產品分類相關的所有產品SUMX (RELATEDTABLE ( Sales ), -- 對于每個產品,獲取相關的銷售記錄Sales[Quantity] * 'Product'[Unit Price] * 'Product Category'[Discount] -- 計算每個銷售記錄的銷售額))
)
??最里面的表達式——三個因子的乘法 ———引用了三張表,每個行上下文均代表當前正在被迭代的表。兩個 RELATEDTABLE 函數返回在當前行上下文中關聯表的行。因此, RELATEDTABLE ( Product ) 是在Categories 表的行上下文中被執行,返回指定產品類型對應的產品。基于同樣的原則,RELATEDTABLE ( Sales ) 返回指定產品對應的銷售記錄。
??這段代碼只是為了演示迭代器嵌套是可行的,但是多嵌套迭代會導致計算量顯著增加。為了提高性能和可讀性,可以使用 RELATED 函數來直接引用相關表中的值,而不是通過嵌套迭代器逐層掃描。優化后的代碼如下:
SUMX (Sales,Sales[Quantity]* RELATED ( 'Product'[Unit Price] ) // 引用了與當前銷售記錄相關的產品的單價* RELATED ( 'Product Category'[Discount] ) // 引用了與當前銷售記錄相關的產品分類的折扣
)
- RELATED :用于從關系中的多端表訪問一端表的列值(返回值);
- RELATEDTABLE:用于從關系中的一端表訪問多端表的的所有行(返回表);
??所以方式1可總結為從一端表中進行計算,每次都迭代掃描多端表中的子表;方式2是在多段表中進行計算,只需要查找一端表中的表值。
??在不同的表中,行上下文是獨立的。對于嵌套迭代,只要是計算不同的表(表之間存在關系),都可以使用方式2進行計算:在一個 DAX 表達式中通過 RELATED 函數來直接引用其它表中的字段。
??如果兩張表間是一對一關系,那么
RELATED和RELATEDTABLE在兩表間都能工作,它們會產生列值或具有單行的表。
4.3.3 同一表上的嵌套行上下文(使用變量處理)
在同一個表上嵌套行上下文是一個常見的場景,尤其是在需要對數據進行排名或比較時。例如,創建計算列來計算每個產品的價格排名,我們可以先使用 PriceOfCurrentProduct 作為占位符來表示當前產品的價格:
1. 'Product'[UnitPriceRank] =
2. COUNTROWS (
3. FILTER (
4. 'Product',
5. 'Product'[Unit Price] > PriceOfCurrentProduct
6. )
7. ) + 1
??FILTER 函數返回所有價格高于當前產品價格的產品,COUNTROWS 函數計算 FILTER 函數結果。現在需要找到一種方法來表達當前產品的價格。 由于代碼是在計算列中編寫的,因此引擎會自動創建一個默認行上下文,用于掃描 Product 表。 此外,FILTER 函數是一個迭代器,FILTER 生成的行上下文會再次掃描產品表。 所以在運行最內層表達式期間,在同一個表上同時有兩個行上下文。
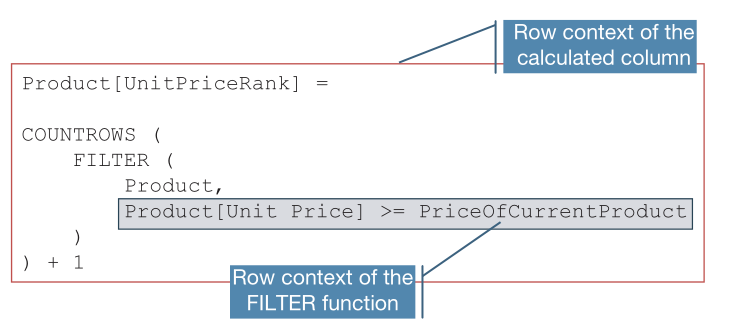
??由FILTER 函數生成的內部行上下文會隱藏外部行上下文,也就是說此時我們無法訪問外層 Product[Unit Price]的值,所以最佳的解決辦法是使用變量保存它,即定義:
VAR PriceOfCurrentProduct = 'Product'[Unit Price]
此外,通過使用更多變量來分解計算的不同步驟,可以使代碼更加易讀。最終代碼為:
'Product'[UnitPriceRank] =
VAR PriceOfCurrentProduct = 'Product'[Unit Price]
VAR MoreExpensiveProducts =FILTER ('Product','Product'[Unit Price] > PriceOfCurrentProduct)
RETURNCOUNTROWS ( MoreExpensiveProducts ) + 1

??這段代碼的結果是非連續排名(多個產品價格相同時,跳過平級排名),如果要改成連續排名(也叫Dense Rank,“密集排名”),可以改成計算高于當前價格的 不同價格 數量,而不是計算產品數量。
'Product'[UnitPriceRankDense] =
VAR PriceOfCurrentProduct = 'Product'[Unit Price]
VAR HigherPrices =FILTER (VALUES ( 'Product'[Unit Price] ), -- 獲取所有不同的價格'Product'[Unit Price] > PriceOfCurrentProduct -- 篩選出高于當前產品價格的所有不同價格)
RETURNCOUNTROWS ( HigherPrices ) + 1 -- 計算高于當前價格的不同價格的數量,并加1
4.3.4 EARLIER
EARLIER 函數是 DAX 中用于訪問外層行上下文的工具,它允許我們在嵌套的行上下文中訪問外層的值,其語法為:
EARLIER(<column>, [<n>])
??是要訪問的列,可選參數n表示要回溯的上下文層級數,默認值為 1。所以在上一節的示例中,我們可以將 EARLIER(Product [UnitPrice])賦值給變量 PriceOfCurrentProduct。
'Product'[UnitPriceRankDense] =
COUNTROWS (FILTER (VALUES ( 'Product'[Unit Price] ),'Product'[UnitPrice] > EARLIER ( 'Product'[UnitPrice] ))
) + 1
??此外,還有一個名為 EARLIEST 的函數,它只訪問最外層的行上下文。在現實情況中,EARLIER 的第二個參數以及 EARLIEST 函數很少使用(很少有3層及以上的嵌套)。自從2015年變量 VAR 出現以后,EARLIER 可以被徹底取代。
4.4 多表數據模型中的上下文
在實際業務中,大多數數據模型包含多張表,這些表通過關系相互關聯。當我們在 DAX 中處理多表數據模型時,行上下文和篩選上下文的行為會受到表之間關系的影響:
- 行上下文:
- 負責迭代單張表中的行,不會自動傳遞到相關表,也就是說每張表的行上下文都是獨立的。
- 如果需要訪問其它表的關聯列,可以使用
RELATED函數或者RELATEDTABLE函數,但必須遵循關系的方向。- 關系鏈方向一致:比如全部是一對多,或者全部是多對一,那么關系可以正確的依次傳遞(單向篩選)
- 關系鏈的方向不一致:比如Customer 表(1:N)? Sales 表(N:1)? Product 表, 那么 Product 表和 Product 表之間是多對多關系,
RELATEDTABLE函數篩選結果會是錯誤的。
- 篩選上下文:負責在整個數據模型中篩選數據,會根據表之間的關系自動傳遞。關系的交叉篩選方向決定了篩選上下文的傳遞方式:
- 單向關系:篩選上下文從一端傳遞到多端。
- 雙向關系:篩選上下文可以在兩端之間雙向傳遞。
4.4.1 行上下文與關系
我們使用以下模型進行測試,該模型中一共6張表,都是一對多的關系:

-
RELATED函數:單次多對一關系傳遞
行上下文僅作用于當前表,無法直接訪問其他表的列,例如下面這個計算列公式會失敗:Sales[UnitPriceVariance] = Sales[Unit Price] – 'Product'[Unit Price]正確的計算方式是:
Sales[UnitPriceVariance] = Sales[Unit Price] - RELATED ( 'Product'[Unit Price] ) -
RELATED函數:多次多對一關系傳遞
以下代碼在 Product 表中創建計算列,從 Product Category 表中復制各類別名稱,關系鏈傳遞方向為 Product 表→Product Subcategory 表→ Product Category表。'Product'[Category] = RELATED ( 'Product Category'[Category] ) -
RELATEDTABLE函數:多次一對多傳遞關系
在 Product Category 表中統計各類產品的銷量,關系鏈傳遞方向為 Product Category 表→ Product Subcategory 表→ Product 表→Sales 表。'Product Category'[NumberOfSales] =COUNTROWS ( RELATEDTABLE ( Sales ) ) -
RELATEDTABLE` 函數:多對多關系時篩選錯誤
使用以下公式在Product 表中創建計算列,計算與當前產品相關的所有銷售記錄。RELATEDTABLE 函數試圖從 Product 表訪問 Customer 表的所有相關行,但由于關系鏈的方向不一致(1:N → N:1),RELATEDTABLE 函數無法沿著這個路徑正確傳遞篩選上下文。因此,RELATEDTABLE(Customer) 返回的是 所有客戶,而不是與當前產品相關的客戶。Product[NumOfBuyingCustomers] =COUNTROWS ( RELATEDTABLE ( Customer ) )

4.4.2 篩選上下文與關系
篩選上下文會根據表之間的關系自動傳遞。比如創建度量值來計算Sales表,Product表和Customer表中相關行數:
[NumOfSales] := COUNTROWS ( Sales )
[NumOfProducts] := COUNTROWS ( Product )
[NumOfCustomers] := COUNTROWS ( Customer )
??如果在 Product 表中篩選 Color 列,篩選上下文會傳遞到 Sales 表(因為它們之間是雙向關系),但不會傳遞到 Customer 表(因為 Customer 和 Sales 之間是單向關系)。

如果改成在Customer表中篩選Education 列,則篩選可以傳遞到Sales表和Product表。

??請注意關系鏈中的單個雙向關系不會使整個關系鏈變成雙向,比如下面的公式計算Subcategory的個數,篩選從Customer表出發,可以傳遞到Sales表和Product表,但不會傳遞到 Product Subcategory 表。
NumOfSubcategories := COUNTROWS ( 'Product Subcategory' )

如果設置Product表和 Product Subcategory 表的篩選的方向為雙向,則可以得到正確的結果:

??注意:雖然雙向篩選看起來可以解決多表篩選的問題,但它的復雜性較高,可能導致意外的結果。建議在特定的度量值中通過
CROSSFILTER函數實現雙向篩選,而不是全局啟用雙向篩選。
4.6 SUMMARIZE
4.6.1 SUMMARIZE語法
??參考《PowerBI之DAX 2》3.2章節,SUMMARIZE函數用于對數據進行分組和匯總,其語法為:
SUMMARIZE(<Table>, // 要進行匯總的表<GroupBy_Expression1>, ..., // 分組表達式,可以有多個<Name1>, <Expression1>, ... // 定義新列的名稱和表達式,可以有多個[, <Filter_Expression>] // 可選的過濾表達式
)
最常用的方式是提取表中多個列的有效組合,比如比如以下表格:

SUMMARIZE可以提取所有有效的產品購買月份記錄:
銷售時間表 = SUMMARIZE('銷售子表','銷售子表'[產品名稱],'日期表'[年度月份])

4.6.2 案例:計算所有客戶購買產品時的平均年齡
??業務要求:計算所有客戶在交易發生時的平均年齡(不是計算各個客戶購買產品時的平均年齡)。如果一個人在同一年齡多次交易,僅計算一次。
-
首先在Sales表中創建計算列,計算銷售時的客戶年齡。DATEDIFF函數用于計算時間差。
Sales[Customer Age] = DATEDIFF(RELATED(Customer[Birth Date]), Sales[Order Date], YEAR) -
計算平均年齡
- 直接求均值:同一客戶同一年齡的多次交易會被重復計算
Avg Customer Age Wrong :=AVERAGE(Sales[Customer Age])- 對年齡去重后求均值:不同客戶同一年齡會被合并為一次記錄
Avg Customer Age Wrong Distinct :==AVERAGEX(DISTINCT(Sales[Customer Age]), Sales[Customer Age])- 對客戶去重后求均值:Sales[CustomerKey]是一個表列,去重結果還是單個列,而AVERAGEX第一個參數必須是表。
Avg Customer Age Invalid Syntax :=AVERAGEX(DISTINCT(Sales[CustomerKey]), Sales[Customer Age]) // 語法錯誤!
-
正確解決方案:使用SUMMARIZE生成客戶與年齡的唯一組合表,再用AVERAGEX計算均值
Correct Average := AVERAGEX(SUMMARIZE(Sales, Sales[CustomerKey], Sales[Customer Age]),Sales[Customer Age] )

4.6.3 匿名表與模型表
對于多步計算可以使用變量來區分,比如使用VAR來存儲計算表:
Correct Average :=
VAR CustomersAge =SUMMARIZE ( Sales, Sales[CustomerKey], Sales[Customer Age]
)
RETURN
--對 Sales 表中 Customer Age 列迭代并計算 Customer Age 的平均值
AVERAGEX ( CustomersAge, Sales[Customer Age]
)
??這里要注意的是,通過 DAX 函數(如 SUMMARIZE、FILTER)動態生成的臨時表是匿名表,僅在計算過程中臨時存在。匿名表可直接用列名,比如直接使用[Customer Age]:
...
RETURN
AVERAGEX ( CustomersAge, [Customer Age]
)
??要注意的是,匿名表不能作為表引用,比如不能寫成CustomersAge[Customer Age]。只有模型表才可以進行表引用,比如上面代碼中SUMMARIZE函數的Sales[Customer Age]參數 。
4.6.4 數據沿襲(Data Lineage)
??匿名表中的列引用,除了直接使用[Customer Age]的方式,還可以根據數據沿襲,使用用原始表的表引用,比如AVERAGEX中的Sales[Customer Age] 。
?? 數據沿襲是 DAX 中列的“身份標識”,它表示某列的數據來源(原始表),即使該列被復制、重命名或重組到其他表中,DAX 仍能識別其原始歸屬。數據沿襲決定了列的歸屬關系,直接影響篩選上下文傳遞(如 RELATED、CALCULATE), 匿名表(臨時生成的表)中的列仍保留原始數據沿襲。對于以下代碼:
VAR CustomersAge = SUMMARIZE(Sales, Sales[CustomerKey], Sales[Customer Age])
??雖然 CustomersAge 是臨時生成的匿名表,但其列 Sales[CustomerKey] 和 Sales[Customer Age] 仍保留來自 Sales 表的數據沿襲。 因此,在 AVERAGEX 中可以直接用 Sales[Customer Age] 引用該列。
| 特性 | 數據模型表 | 匿名表 |
|---|---|---|
| 定義 | 預先在數據模型中定義的表 | 通過 DAX 函數(如 SUMMARIZE、FILTER)動態生成的臨時表 |
| 存儲位置 | 持久化存儲在模型中 | 僅在計算過程中臨時存在 |
| 列引用方式 | 必須用表名限定列(如 Sales[CustomerKey]) | 可直接用列名(如 [Customer Age]),或用原始表名限定(依賴數據沿襲) |
| 能否直接通過變量名引用列 | 是(如 Sales[CustomerKey]) | 否(變量名不是表名,需依賴數據沿襲或直接列名) |
進一步理解,對于VAR X = Order,其中Order是模型表,則有:
SUMX( X , X[Amount] ) // 不可以,匿名表無法進行表引用
SUMX( Order , Order[Amount] ) // 可以,模型表可以進行表引用
SUMX( X , Order[Amount] ) // 可以
SUMX( X , [Amount] ) // 可以,匿名表可直接引用列名,通過數據沿襲找到原始列
SUMX( Order , [Amount] ) // 可以


:Llama模型的簡單部署)
)




Java/python/JavaScript/C/C++/GO最佳實現)



攻擊解析)






