4月24日復盤
一、CNN
視覺處理三大任務:圖像分類、目標檢測、圖像分割
上游:提取特征,CNN
下游:分類、目標、分割等,具體的業務
1. 概述
? 卷積神經網絡是深度學習在計算機視覺領域的突破性成果。在計算機視覺領域, 往往我們輸入的圖像都很大,使用全連接網絡的話,計算的代價較高。另外圖像也很難保留原有的特征,導致圖像處理的準確率不高。
? 卷積神經網絡(Convolutional Neural Network,CNN)是一種專門用于處理具有網格狀結構數據的深度學習模型。最初,CNN主要應用于計算機視覺任務,但它的成功啟發了在其他領域應用,如自然語言處理等。
? 卷積神經網絡(Convolutional Neural Network)是含有卷積層的神經網絡. 卷積層的作用就是用來自動學習、提取圖像的特征。
? CNN網絡主要有三部分構成:卷積層、池化層和全連接層構成,其中卷積層負責提取圖像中的局部特征;池化層用來大幅降低運算量并特征增強;全連接層類似神經網絡的部分,用來輸出想要的結果。
1.1 使用場景




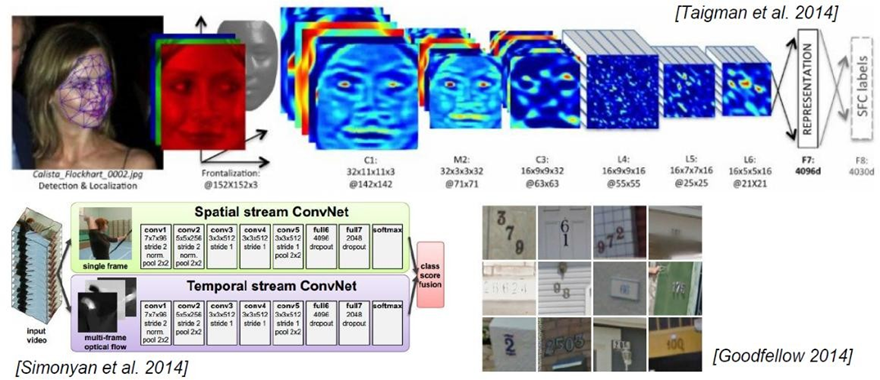
1.2 與傳統網絡的區別
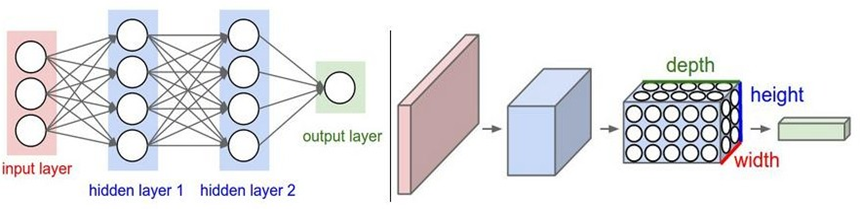
1.3 全連接的局限性
全連接神經網絡并不太適合處理圖像數據…
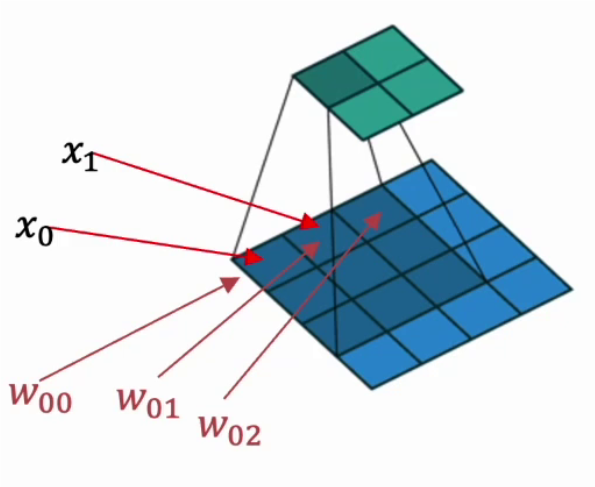
1.3.1 參數量巨大
y = x × W T + b y = x \times W^T + b y=x×WT+b
全連接結構計算量非常大,假設我們有1000×1000的輸入,如果隱藏層也是1000×1000大小的神經元,由于神經元和圖像每一個像素連接,則參數量會達到驚人的1000×1000×1000×1000,僅僅一層網絡就已經有 1 0 12 10^{12} 1012個參數。
1.3.2 表達能力太有限
全連接神經網絡的角色只是一個分類器,如果將整個圖片直接輸入網絡,不僅參數量大,也沒有利用好圖片中像素的空間特性,增加了學習難度,降低了學習效果。
1.4 卷積思想
卷:從左往右,從上往下
積:乘積,求和
1.4.1 概念
? Convolution,輸入信息與卷積核(濾波器,Filter)的乘積。
1.4.2 局部連接
- 局部連接可以更好地利用圖像中的結構信息,空間距離越相近的像素其相互影響越大。
- 根據局部特征完成目標的可辨識性。
1.4.3 權重共享
-
圖像從一個局部區域學習到的信息應用到其他區域。
-
減少參數,降低學習難度。
2. 卷積層
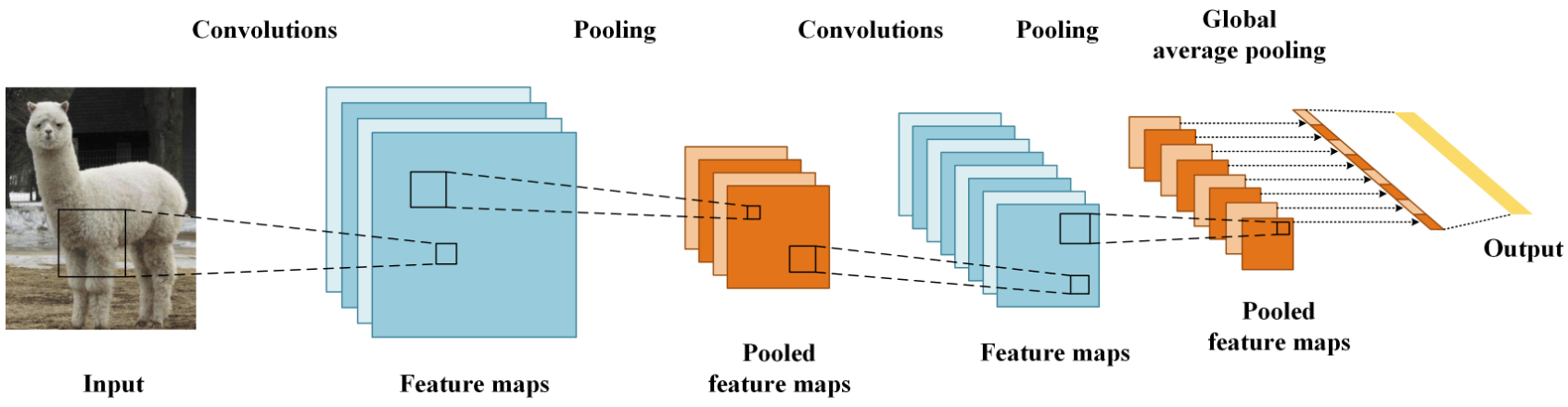
接下來,我們開始學習卷積核的計算過程, 即: 卷積核是如何提取特征的。
2.1 卷積核
? 卷積核是卷積運算過程中必不可少的一個“工具”,在卷積神經網絡中,卷積核是非常重要的,它們被用來提取圖像中的特征。
卷積核其實是一個小矩陣,在定義時需要考慮以下幾方面的內容:
- 卷積核的個數:卷積核(過濾器)的個數決定了其輸出特征矩陣的通道數。
- 卷積核的值:卷積核的值是初始化好的,后續進行更新。
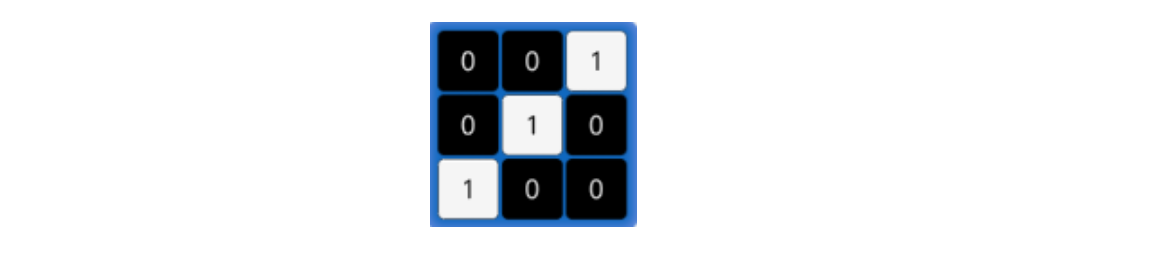
- 卷積核的大小:常見的卷積核有1×1、3×3、5×5等,一般都是奇數 × 奇數。
下圖就是一個3×3的卷積核:
2.2 卷積計算
2.2.1 卷積計算過程
? 卷積的過程是將卷積核在圖像上進行滑動計算,每次滑動到一個新的位置時,卷積核和圖像進行點對點的計算,并將其求和得到一個新的值,然后將這個新的值加入到特征圖中,最終得到一個新的特征圖。
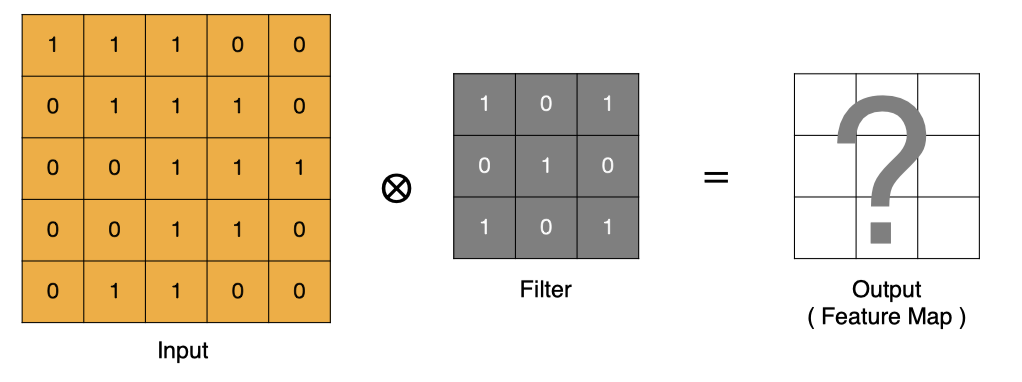
- input 表示輸入的圖像
- filter 表示卷積核, 也叫做濾波器
- input 經過 filter 的得到輸出為最右側的圖像,該圖叫做特征圖
? 那么, 它是如何進行計算的呢?卷積運算本質上就是在濾波器和輸入數據的局部區域間做點積。
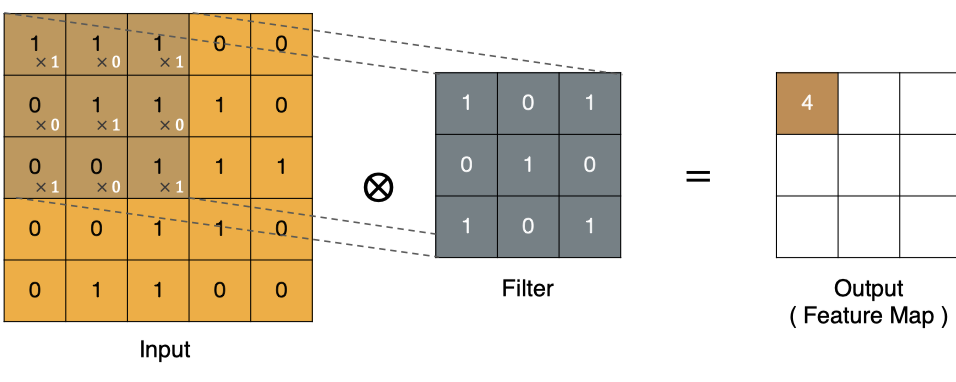
左上角的點計算方法:
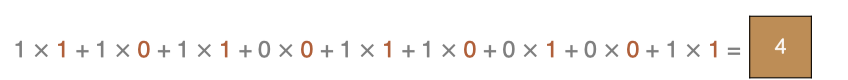
按照上面的計算方法可以得到最終的特征圖為:
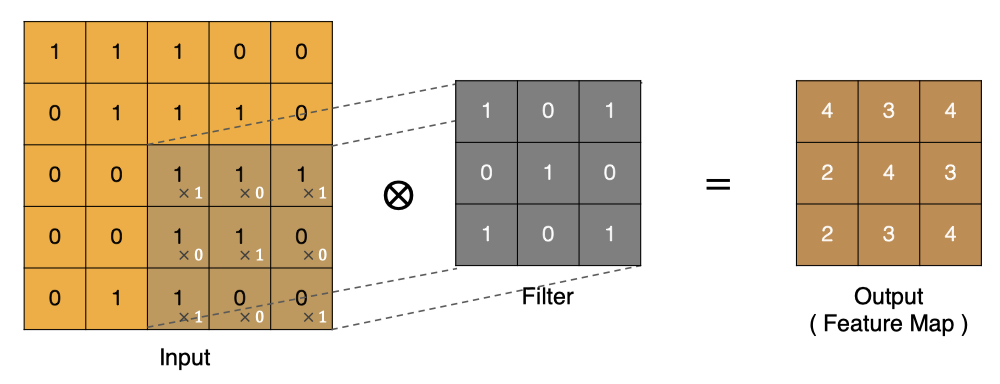
? 卷積的重要性在于它可以將圖像中的特征與卷積核進行卷積操作,從而提取出圖像中的特征。
? 可以通過不斷調整卷積核的大小、卷積核的值和卷積操作的步長,可以提取出不同尺度和位置的特征。
# 面向對象的模塊化編程
from matplotlib import pyplot as plt
import os
import torch
import torch.nn as nndef test001():current_path = os.path.dirname(__file__)img_path = os.path.join(current_path, "data", "彩色.png")# 轉換為相對路徑img_path = os.path.relpath(img_path)# 使用plt讀取圖片img = plt.imread(img_path)print(img.shape)# 轉換為張量:HWC ---> CHW ---> NCHW 鏈式調用img = torch.tensor(img).permute(2, 0, 1).unsqueeze(0)# 創建卷積核 (501, 500, 4)conv = nn.Conv2d(in_channels=4, # 輸入通道out_channels=32, # 輸出通道kernel_size=(5, 3), # 卷積核大小stride=1, # 步長padding=0, # 填充bias=True)# 使用卷積核對圖像進行卷積操作 [9999] [[[[]]]]out = conv(img)# 輸出128個特征圖conv2 = nn.Conv2d(in_channels=32, # 輸入通道out_channels=128, # 輸出通道kernel_size=(5, 5), # 卷積核大小stride=1, # 步長padding=0, # 填充bias=True)out = conv2(out)print(out)# 把圖像顯示出來print(out.shape)plt.imshow(out[0][10].detach().numpy(), cmap='gray')plt.show()# 作為主模塊執行
if __name__ == "__main__":test001()
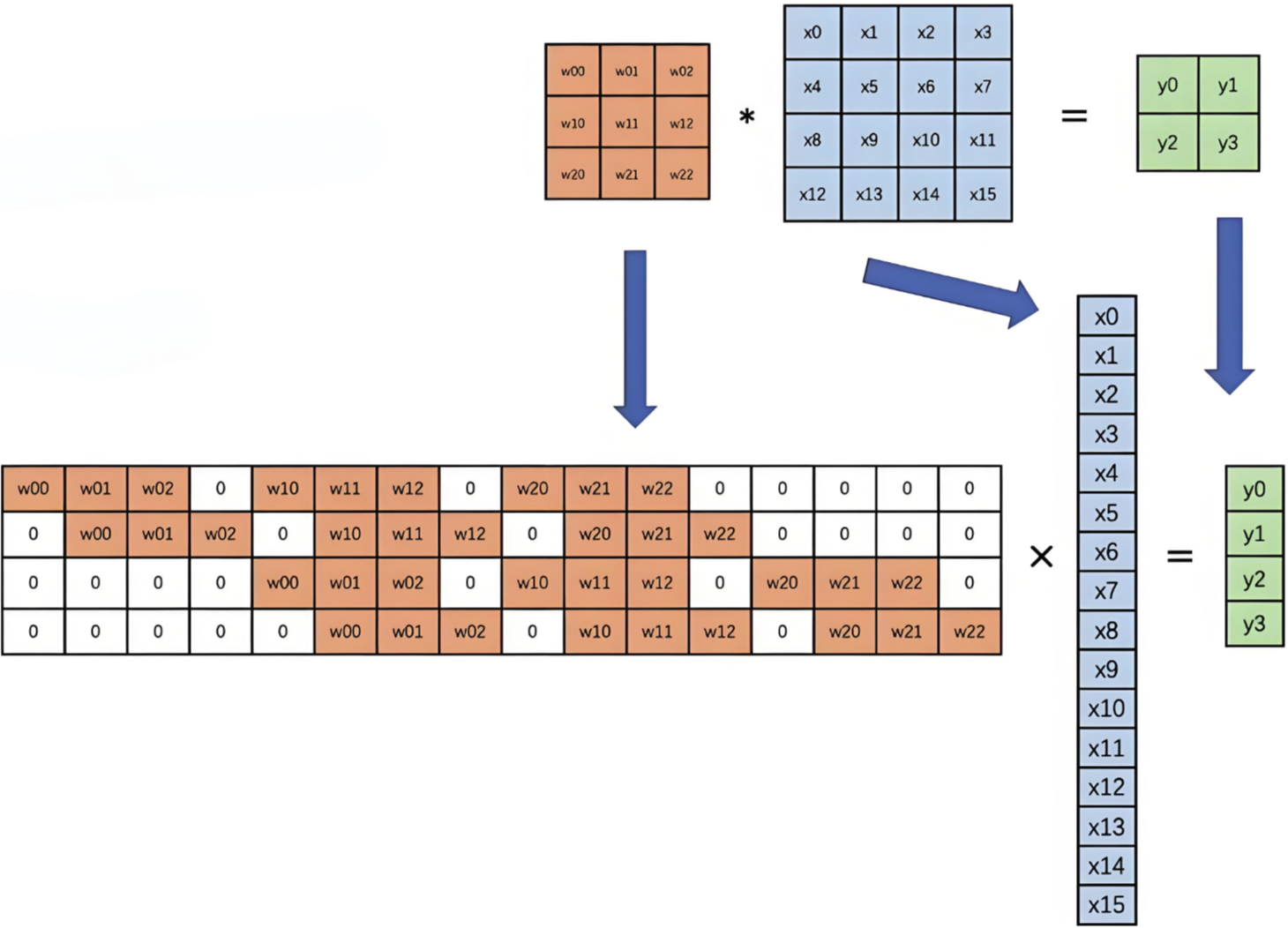
2.2.2 卷積計算底層實現
并不是水平和垂直方向的循環。
下圖是卷積的基本運算方式:
卷積真正的計算過程如下圖:
2.3 邊緣填充
? Padding
? 通過上面的卷積計算,我們發現最終的特征圖比原始圖像要小,如果想要保持圖像大小不變, 可在原圖周圍添加padding來實現。
? 更重要的,邊緣填充還更好的保護了圖像邊緣數據的特征。
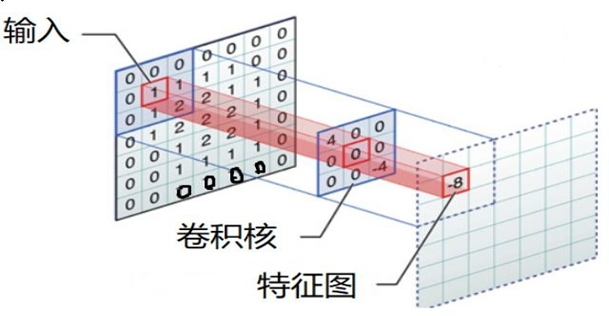
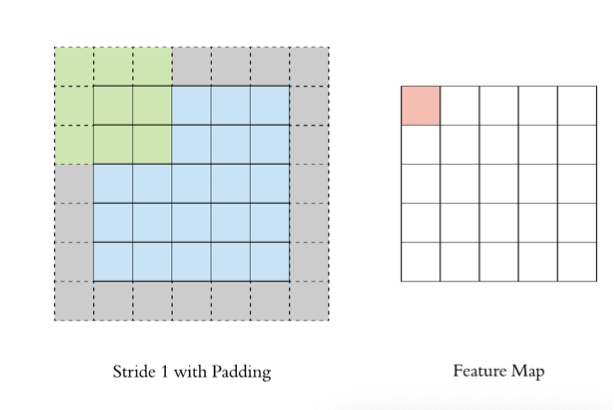
2.4 步長Stride
按照步長為1來移動卷積核,計算特征圖如下所示:

如果我們把 Stride 增大為2,也是可以提取特征圖的,如下圖所示:

stride太小:重復計算較多,計算量大,訓練效率降低;
stride太大:會造成信息遺漏,無法有效提煉數據背后的特征;
2.5 多通道卷積計算
首先我們需要認識下通道,做到顆粒度對齊~
2.5.1 數字圖像的標識
我們知道圖像在計算機眼中是一個矩陣
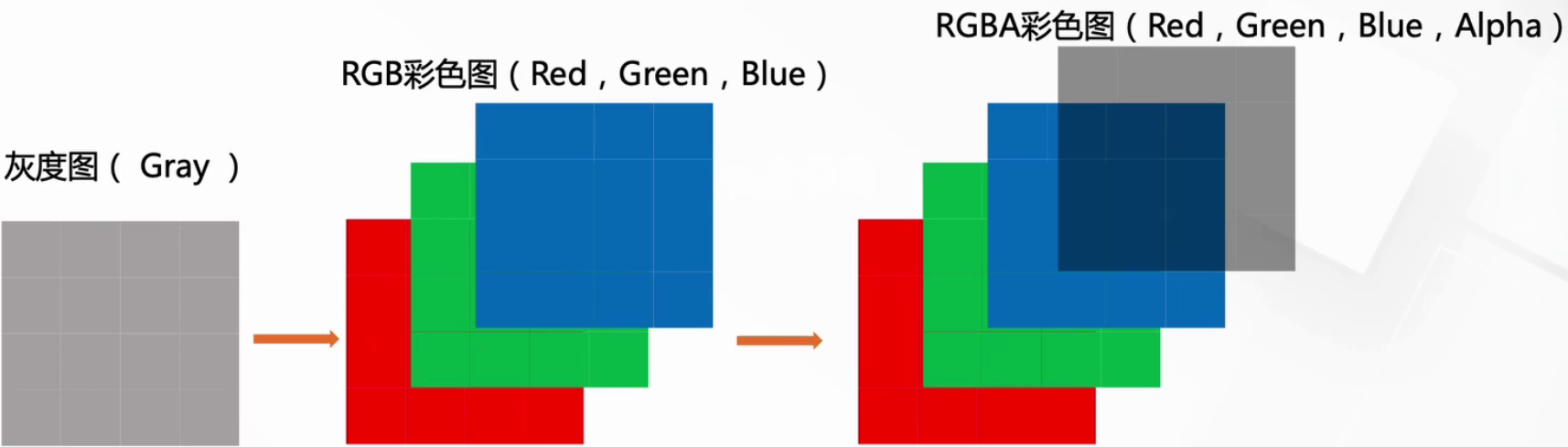
通道越多,可以表達的特征就越豐富~
2.5.2 具體計算實現
實際中的圖像都是多個通道組成的,我們怎么計算卷積呢?
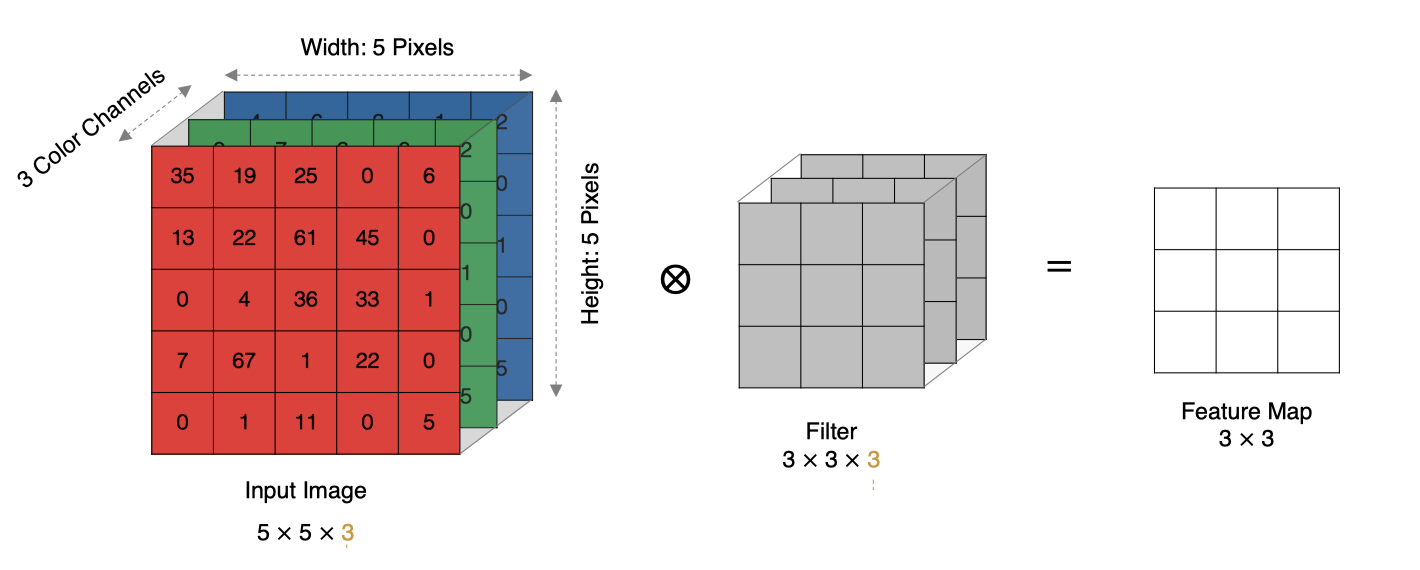
計算方法如下:
- 當輸入有多個通道(Channel), 例如RGB三通道, 此時要求卷積核需要有相同的通道數。
- 卷積核通道與對應的輸入圖像通道進行卷積。
- 將每個通道的卷積結果按位相加得到最終的特征圖。
如下圖所示:
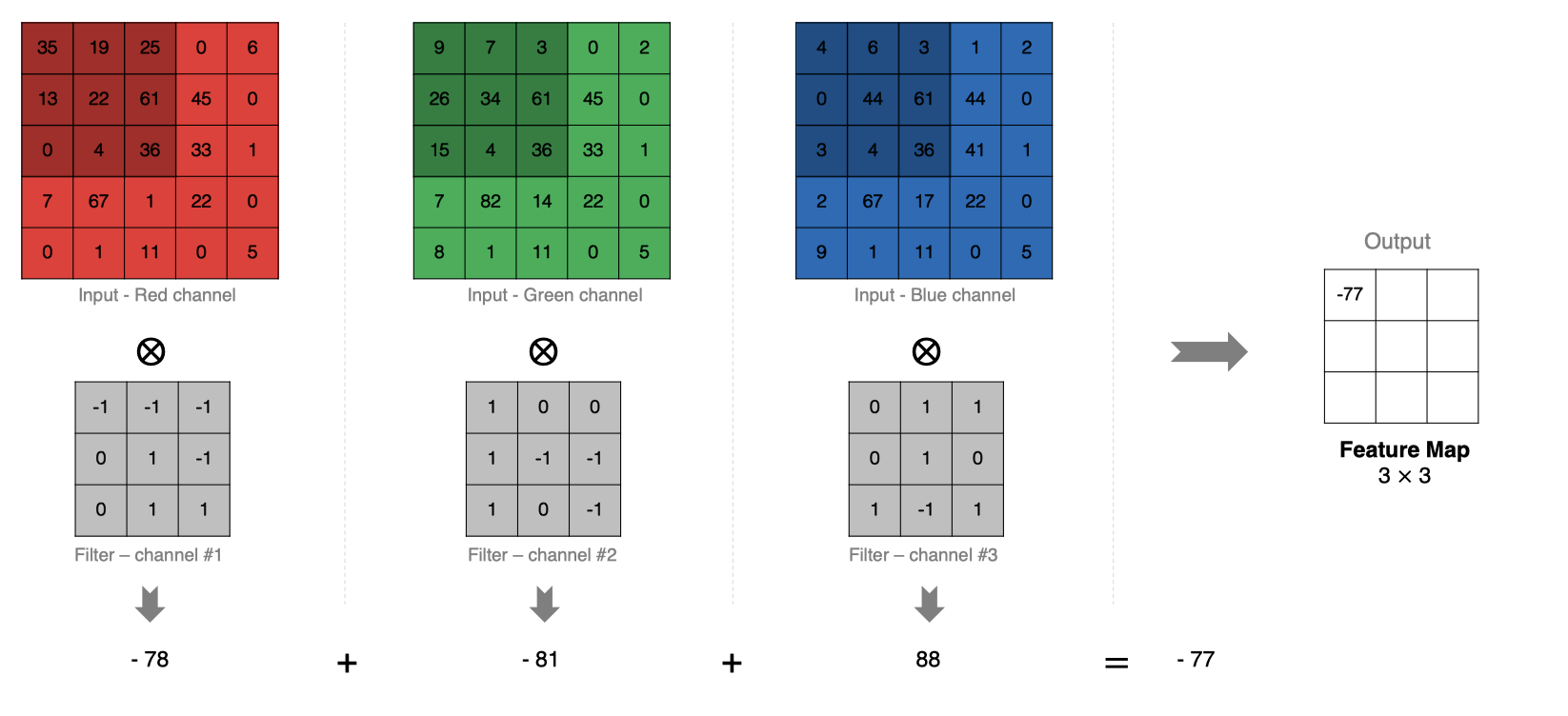
2.6 多卷積核卷積計算
? 實際對圖像進行特征提取時, 我們需要使用多個卷積核進行特征提取。這個多個卷積核可以理解為從不同到的視角、不同的角度對圖像特征進行提取。
? 那么, 當使用多個卷積核時, 應該怎么進行特征提取呢?
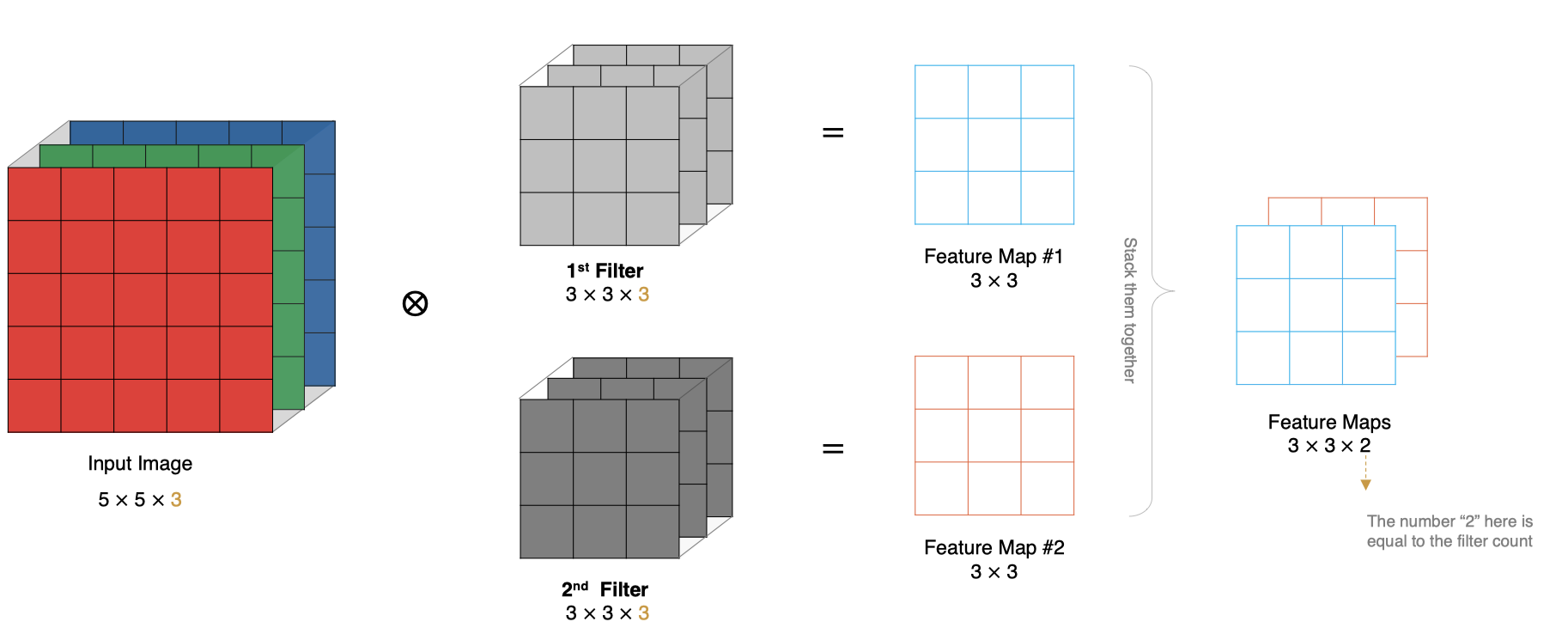
2.7 特征圖大小
輸出特征圖的大小與以下參數息息相關:
- size: 卷積核/過濾器大小,一般會選擇為奇數,比如有 1×1, 3×3, 5×5
- Padding: 零填充的方式
- Stride: 步長
那計算方法如下圖所示:
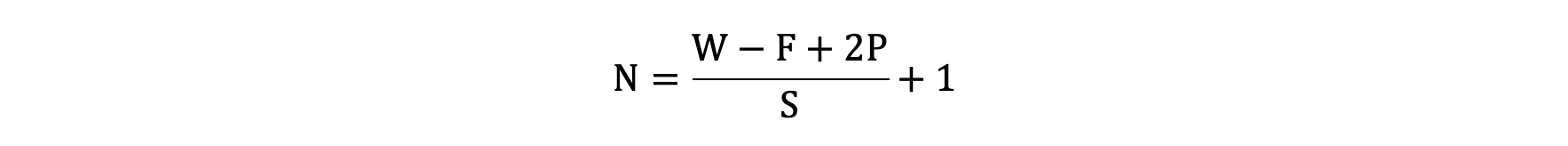
-
輸入圖像大小: W x W
-
卷積核大小: F x F
-
Stride: S
-
Padding: P
-
輸出圖像大小: N x N
以下圖為例:
- 圖像大小: 5 x 5
- 卷積核大小: 3 x 3
- Stride: 1
- Padding: 1
- (5 - 3 + 2) / 1 + 1 = 5, 即得到的特征圖大小為: 5 x 5
2.8 只卷一次?

2.9 卷積參數共享
? 數據是 32 × 32 × 3 32×32×3 32×32×3 的圖像,用 10 10 10 個 5 × 5 5×5 5×5 的filter來進行卷積操作,所需的權重參數有多少個呢?
- 5 × 5 × 3 = 75 5×5×3 = 75 5×5×3=75,表示每個卷積核只需要 75 75 75個參數。
- 10個不同的卷積核,就需要 10 ? 75 = 750 10*75 = 750 10?75=750個卷積核參數。
- 如果還考慮偏置參數 b b b,最終需要 750 + 10 = 760 750+10=760 750+10=760 個參數。
全連接參數量: 10 ? 28 ? 28 ? ( 32 ? 32 ? 3 + 1 ) 全連接參數量: 10 * 28 * 28 *(32 * 32 * 3 + 1) 全連接參數量:10?28?28?(32?32?3+1)
2.10 局部特征提取
? 通過卷積操作,CNN具有局部感知性,能夠捕捉輸入數據的局部特征,這在處理圖像等具有空間結構的數據時非常有用。
2.11 PyTorch卷積層 API

test01 函數使用一個多通道卷積核進行特征提取, test02 函數使用 3 個多通道卷積核進行特征提取:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import osdef showimg(img):plt.imshow(img)# 隱藏刻度plt.axis("off")plt.show()def test001():dir = os.path.dirname(__file__)img = plt.imread(os.path.join(dir, "彩色.png"))# 創建卷積核# in_channels:輸入數據的通道數# out_channels:輸出特征圖數,和filter數一直conv = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=3, stride=1, padding=1)# 注意:卷積層對輸入的數據有形狀要求 [batch, channel, height, width]# 需要進行形狀轉換 H, W, C -> C, H, Wimg = torch.tensor(img, dtype=torch.float).permute(2, 0, 1)print(img.shape)# 接著變形:CHW -> BCHWnewimg = img.unsqueeze(0)print(newimg.shape)# 送入卷積核運算一下newimg = conv(newimg)print(newimg.shape)# 蔣NCHW->HWCnewimg = newimg.squeeze(0).permute(1, 2, 0)showimg(newimg.detach().numpy())# 多卷積核
def test002():dir = os.path.dirname(__file__)img = plt.imread(os.path.join(dir, "彩色.png"))# 定義一個多特征圖輸出的卷積核conv = nn.Conv2d(in_channels=4, out_channels=3, kernel_size=3, stride=1, padding=1)# 圖形要進行變形處理img = torch.tensor(img).permute(2, 0, 1).unsqueeze(0)# 使用卷積核對圖片進行卷積計算outimg = conv(img)print(outimg.shape)# 把圖形形狀轉換回來以方便顯示outimg = outimg.squeeze(0).permute(1, 2, 0)print(outimg.shape)# showimg(outimg)# 顯示這些特征圖for idx in range(outimg.shape[2]):showimg(outimg[:, :, idx].squeeze(-1).detach())if __name__ == "__main__":test002()效果:

知識拓展(AI生成)
1. 什么是多通道卷積?在處理RGB圖像時,如何體現多通道卷積的特性?
多通道卷積是指在卷積神經網絡中,針對輸入數據的多個通道(如RGB圖像的紅、綠、藍三個通道)分別進行卷積操作,并將結果通過加權求和的方式整合為一個輸出特征圖的過程。其特性在處理RGB圖像時主要體現在以下方面:
- 卷積核的深度與輸入圖像的通道數一致(如3通道的RGB圖像對應3深度的卷積核),每個卷積核能夠提取輸入圖像各通道的組合特征。
- 通過多個卷積核的組合使用,能夠捕捉圖像在不同通道上的復雜特征關聯,從而提升模型對圖像內容的理解能力。
2. 假設你有一個3通道(如RGB)的輸入圖像,其尺寸為64x64,應用一個大小為3x3、深度也為3的卷積核進行卷積操作,請描述這個過程。
對于一個尺寸為64x64的3通道(RGB)輸入圖像,應用一個大小為3x3、深度為3的卷積核時,卷積操作的過程如下:
- 卷積核在輸入圖像的每個通道上進行滑動,每個位置計算卷積核與圖像局部區域的逐元素乘積之和。
- 將三個通道的計算結果相加,得到一個標量值,作為輸出特征圖對應位置的值。
- 重復上述操作,覆蓋整個輸入圖像,最終生成一個深度為1的特征圖(若使用多個卷積核,則輸出特征圖的深度等于卷積核的數量)。
3. 請計算一個大小為5x5、深度為3的卷積核應用于具有10個通道的輸入時,需要多少個可學習參數。如果有偏置項,總參數量是多少?
一個5x5大小、深度為3的卷積核應用于具有10個通道的輸入時,可學習參數的數量計算如下:
- 權重參數:卷積核的每個深度(3)與輸入通道數(10)對應,因此權重參數總數為5×5×10×3=750個。
- 偏置參數:若包含偏置項,則每個卷積核對應一個偏置,因此總參數量為750+3=753個。
4. 解釋卷積層中的偏置項是什么,并討論在神經網絡中引入偏置項的好處。
卷積層中的偏置項是一個與卷積核對應的可學習參數,加在卷積操作后的結果上。引入偏置項的好處包括:
- 提供模型的靈活性:偏置項允許模型在激活函數前調整輸出的基準值,使其能夠更好地擬合數據。
- 增強表達能力:偏置項為網絡提供了額外的自由度,有助于提高模型對復雜模式的表達能力。
5. 在實際應用中,為什么有些卷積層會選擇不包含偏置項?列舉并解釋可能的情況。
在實際應用中,有些卷積層選擇不包含偏置項的可能情況包括:
- 當卷積層后面緊跟著批量歸一化(Batch Normalization)層時,偏置項的作用會被歸一化過程吸收,因此可以省略偏置以減少參數量。
- 在某些輕量級模型設計中,為了降低計算復雜度和參數量,可能會省略偏置項,特別是在輸入數據已經過適當歸一化的情況下。
6. 在多通道卷積過程中,權重共享如何在不同通道間實現特征學習的協同作用?請結合實際應用案例進行說明。
多通道卷積過程中,權重共享通過以下方式在不同通道間實現特征學習的協同作用:
- 卷積核的權重在所有輸入通道上共享,使得模型能夠學習跨通道的共性特征。
- 在目標檢測任務中,不同通道的特征(如邊緣、紋理)通過共享權重的卷積核進行整合,形成對目標形狀的有效表示。
7. 當處理高維輸入數據時(例如視頻幀序列或高光譜圖像),針對多個通道上的卷積操作,你可能會采取哪些優化策略以減少計算復雜度并提高模型性能?
針對高維輸入數據(如視頻幀序列或高光譜圖像),可采取以下優化策略:
- 使用深度可分離卷積:將標準卷積分解為逐深度卷積和逐點卷積,顯著減少計算量。
- 應用分組卷積:將輸入通道分組,每組獨立進行卷積操作,降低計算復雜度。
- 采用稀疏連接:設計稀疏連接模式,減少卷積核與輸入通道的全連接關系。
8. 請推導一個多通道卷積層(包括多個濾波器和每個濾波器對應的偏置項)前向傳播過程中的矩陣運算表達式,并解釋反向傳播時這些參數(權重和偏置)的梯度是如何計算的。
前向傳播過程的矩陣運算表達式為:
![[ Y_{ijk} = b_k + \sum_{m=1}^{M} \sum_{p=1}^{P} \sum_{q=1}^{Q} X_{i+p-1,j+q-1,m} \cdot W_{pqmk} ]](https://i-blog.csdnimg.cn/direct/4e6c8af0d65d4a4db1081c7670802e0b.png)
其中,( X ) 是輸入,( W ) 是權重,( b ) 是偏置,( Y ) 是輸出。
反向傳播中權重和偏置的梯度計算基于鏈式法則:
- 權重梯度:通過輸入數據和輸出梯度的卷積計算。
- 偏置梯度:等于輸出梯度在對應特征圖上的總和。
9. 現代深度學習框架中存在將通道注意力機制融入到卷積層的設計,例如SENet中的Squeeze-and-Excitation模塊。請描述這一機制如何影響卷積層對多通道信息的處理,并討論其優勢。
SENet中的Squeeze-and-Excitation模塊通過以下方式影響卷積層對多通道信息的處理:
- Squeeze操作:對每個通道進行全局平均池化,獲取通道級統計特征。
- Excitation操作:通過全連接層學習通道間的依賴關系,生成通道權重。
其優勢在于能夠動態調整通道權重,增強重要特征通道的表達,抑制不重要通道,從而提升模型對關鍵信息的關注能力。
10. 舉例說明一種或多通道特征融合的方法,比如深度可分離卷積中的點wise卷積或者跨通道卷積,并闡述它們如何促進不同通道間的特征交互。
深度可分離卷積中的點wise卷積是一種多通道特征融合方法:
- 點wise卷積使用1x1卷積核,將輸入的多個通道特征進行線性組合,生成新的通道特征。
- 該方法通過跨通道的線性變換,促進不同通道間特征的交互與融合,同時保持計算效率。
11. 假設你在訓練一個用于圖像分類的深度卷積神經網絡時,發現由于輸入圖像的多通道特性導致模型過擬合,請提出至少兩種通過調整卷積層結構或配置來緩解過擬合的技術方案,并討論其原理。
針對多通道特性導致的過擬合,可采用以下技術方案:
- 增加Dropout層:在卷積層后添加Dropout層,隨機丟棄部分神經元輸出,防止模型對訓練數據的過度擬合。
- 應用Batch Normalization:通過歸一化每層的輸入,穩定訓練過程,降低過擬合風險,同時減少對偏置項的依賴。
12. 討論卷積層中偏置項的作用以及它可能引入的問題(如模型的平移不變性)。在某些場景下為何會選擇去除偏置項?如果有,會采用什么替代策略來補償去除偏置帶來的潛在損失?
偏置項在卷積層中的作用包括提供模型靈活性和增強表達能力。然而,它可能引入的問題包括:
- 破壞平移不變性:偏置項的加入可能使模型對輸入的平移變換敏感。
在某些場景下(如使用Batch Normalization后),去除偏置項的原因在于其作用可被歸一化層吸收,從而簡化模型結構并減少參數量。
13. 比較全局平均池化、全局最大池化以及具有偏置項的1x1卷積在獲取通道級統計特征方面的異同,并根據特定任務需求闡述何時選擇哪種方法更為合適。
- 全局平均池化:對每個通道進行全局平均,提取通道的平均響應特征,適用于需要平滑統計的任務(如圖像分類)。
- 全局最大池化:提取通道的最大響應,強調顯著特征,適用于需要突出關鍵信息的任務(如目標檢測)。
- 1x1卷積:通過線性組合通道特征,生成新的通道級表示,適用于特征融合與通道間關系建模任務。
在特定任務中,若需要對通道特征進行非線性組合和降維,1x1卷積可能更為合適;若僅需提取簡單統計特征,則全局池化方法更為高效。
)

)


)
模擬娛樂篇33)










)
安裝筆記)
