RAG 簡介
什么是檢索增強生成?
檢索增強生成(RAG)是指對大型語言模型輸出進行優化,使其能夠在生成響應之前引用訓練數據來源之外的權威知識庫。大型語言模型(LLM)用海量數據進行訓練,使用數十億個參數為回答問題、翻譯語言和完成句子等任務生成原始輸出。在 LLM 本就強大的功能基礎上,RAG 將其擴展為能訪問特定領域或組織的內部知識庫,所有這些都無需重新訓練模型。這是一種經濟高效地改進 LLM 輸出的方法,讓它在各種情境下都能保持相關性、準確性和實用性。
為什么檢索增強生成很重要?
LLM 是一項關鍵的人工智能(AI)技術,為智能聊天機器人和其他自然語言處理(NLP)應用程序提供支持。目標是通過交叉引用權威知識來源,創建能夠在各種環境中回答用戶問題的機器人。不幸的是,LLM 技術的本質在 LLM 響應中引入了不可預測性。此外,LLM 訓練數據是靜態的,并引入了其所掌握知識的截止日期。
LLM 面臨的已知挑戰包括:
- 在沒有答案的情況下提供虛假信息。
- 當用戶需要特定的當前響應時,提供過時或通用的信息。
- 從非權威來源創建響應。
- 由于術語混淆,不同的培訓來源使用相同的術語來談論不同的事情,因此會產生不準確的響應。
您可以將大型語言模型看作是一個過于熱情的新員工,他拒絕隨時了解時事,但總是會絕對自信地回答每一個問題。不幸的是,這種態度會對用戶的信任產生負面影響,這是您不希望聊天機器人效仿的!
RAG 是解決其中一些挑戰的一種方法。它會重定向 LLM,從權威的、預先確定的知識來源中檢索相關信息。組織可以更好地控制生成的文本輸出,并且用戶可以深入了解 LLM 如何生成響應。
檢索增強生成有哪些好處?
RAG 技術為組織的生成式人工智能工作帶來了多項好處。
經濟高效的實施
聊天機器人開發通常從基礎模型開始。基礎模型(FM)是在廣泛的廣義和未標記數據上訓練的 API 可訪問 LLM。針對組織或領域特定信息重新訓練 FM 的計算和財務成本很高。RAG 是一種將新數據引入 LLM 的更加經濟高效的方法。它使生成式人工智能技術更廣泛地獲得和使用。
當前信息
即使 LLM 的原始訓練數據來源適合您的需求,但保持相關性也具有挑戰性。RAG 允許開發人員為生成模型提供最新的研究、統計數據或新聞。他們可以使用 RAG 將 LLM 直接連接到實時社交媒體提要、新聞網站或其他經常更新的信息來源。然后,LLM 可以向用戶提供最新信息。
增強用戶信任度
RAG 允許 LLM 通過來源歸屬來呈現準確的信息。輸出可以包括對來源的引文或引用。如果需要進一步說明或更詳細的信息,用戶也可以自己查找源文檔。這可以增加對您的生成式人工智能解決方案的信任和信心。
更多開發人員控制權
借助 RAG,開發人員可以更高效地測試和改進他們的聊天應用程序。他們可以控制和更改 LLM 的信息來源,以適應不斷變化的需求或跨職能使用。開發人員還可以將敏感信息的檢索限制在不同的授權級別內,并確保 LLM 生成適當的響應。此外,如果 LLM 針對特定問題引用了錯誤的信息來源,他們還可以進行故障排除并進行修復。組織可以更自信地為更廣泛的應用程序實施生成式人工智能技術。
檢索增強生成的工作原理是什么?
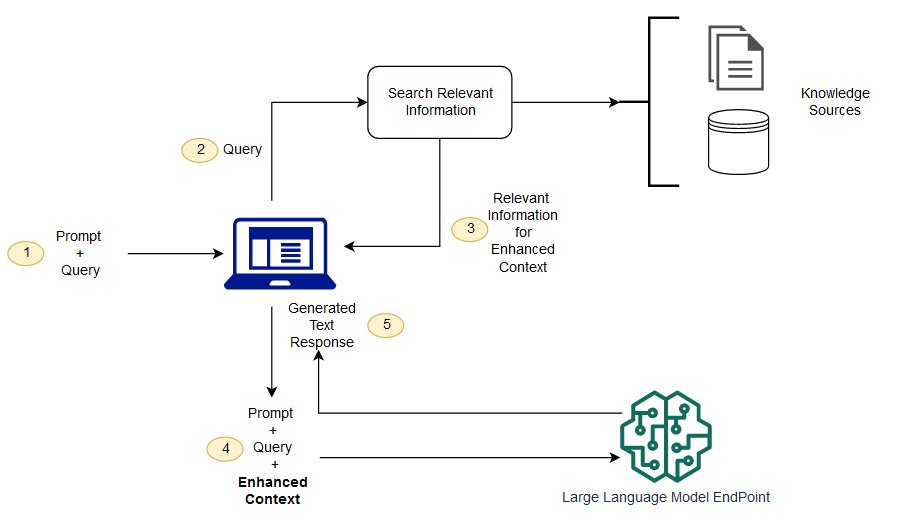
如果沒有 RAG,LLM 會接受用戶輸入,并根據它所接受訓練的信息或它已經知道的信息創建響應。RAG 引入了一個信息檢索組件,該組件利用用戶輸入首先從新數據源提取信息。用戶查詢和相關信息都提供給 LLM。LLM 使用新知識及其訓練數據來創建更好的響應。以下各部分概述了該過程。
創建外部數據
LLM 原始訓練數據集之外的新數據稱為外部數據。它可以來自多個數據來源,例如 API、數據庫或文檔存儲庫。數據可能以各種格式存在,例如文件、數據庫記錄或長篇文本。另一種稱為嵌入語言模型的 AI 技術將數據轉換為數字表示形式并將其存儲在向量數據庫中。這個過程會創建一個生成式人工智能模型可以理解的知識庫。
檢索相關信息
下一步是執行相關性搜索。用戶查詢將轉換為向量表示形式,并與向量數據庫匹配。例如,考慮一個可以回答組織的人力資源問題的智能聊天機器人。如果員工搜索:“我有多少年假?”,系統將檢索年假政策文件以及員工個人過去的休假記錄。這些特定文件將被退回,因為它們與員工輸入的內容高度相關。相關性是使用數學向量計算和表示法計算和建立的。
增強 LLM 提示
接下來,RAG 模型通過在上下文中添加檢索到的相關數據來增強用戶輸入(或提示)。此步驟使用提示工程技術與 LLM 進行有效溝通。增強提示允許大型語言模型為用戶查詢生成準確的答案。
更新外部數據
下一個問題可能是:如果外部數據過時了怎么辦? 要維護當前信息以供檢索,請異步更新文檔并更新文檔的嵌入表示形式。您可以通過自動化實時流程或定期批處理來執行此操作。這是數據分析中常見的挑戰:可以使用不同的數據科學方法進行變更管理。
下圖顯示了將 RAG 與 LLM 配合使用的概念流程。
檢索增強生成和語義搜索有什么區別?
語義搜索可以提高 RAG 結果,適用于想要在其 LLM 應用程序中添加大量外部知識源的組織。現代企業在各種系統中存儲大量信息,例如手冊、常見問題、研究報告、客戶服務指南和人力資源文檔存儲庫等。上下文檢索在規模上具有挑戰性,因此會降低生成輸出質量。
語義搜索技術可以掃描包含不同信息的大型數據庫,并更準確地檢索數據。例如,他們可以回答諸如 “去年在機械維修上花了多少錢?”之類的問題,方法是將問題映射到相關文檔并返回特定文本而不是搜索結果。然后,開發人員可以使用該答案為 LLM 提供更多上下文。
RAG 中的傳統或關鍵字搜索解決方案對知識密集型任務產生的結果有限。開發人員在手動準備數據時還必須處理單詞嵌入、文檔分塊和其他復雜問題。相比之下,語義搜索技術可以完成知識庫準備的所有工作,因此開發人員不必這樣做。它們還生成語義相關的段落和按相關性排序的標記詞,以最大限度地提高 RAG 有效載荷的質量。
Document loaders和Text splitters
Document loaders(文檔加載器)
Document loaders(文檔加載器) 這些類加載文檔對象。LangChain與各種數據源有數百個集成,可以從中加載數據:Slack、Notion、Google Drive等。 每個文檔加載器都有自己特定的參數,但它們可以通過相同的方式使用<font style="color:rgb(28, 30, 33);">.load</font>方法調用。 以下是一個示例用法:
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(... # <-- 在這里添加特定于集成的參數
)
data = loader.load()
如何加載 CSV 文件
逗號分隔值(CSV)文件是一種使用逗號分隔值的定界文本文件。文件的每一行是一個數據記錄。每個記錄由一個或多個字段組成,字段之間用逗號分隔。
LangChain 實現了一個 CSV 加載器,可以將 CSV 文件加載為一系列 Document 對象。CSV 文件的每一行都會被翻譯為一個文檔。
#示例:csv_loader.py
from langchain_community.document_loaders.csv_loader import CSVLoaderfile_path = ("../../resource/doc_search.csv"
)
loader = CSVLoader(file_path=file_path,encoding="UTF-8")
data = loader.load()
for record in data[:2]:print(record)
page_content='名稱: 獅子
種類: 哺乳動物
年齡: 8
棲息地: 非洲草原' metadata={'source': '../../resource/doc_search.csv', 'row': 0}
page_content='名稱: 大熊貓
種類: 哺乳動物
年齡: 5
棲息地: 中國竹林' metadata={'source': '../../resource/doc_search.csv', 'row': 1}
自定義 CSV 解析和加載
<font style="color:rgb(28, 30, 33);">CSVLoader</font> 接受一個 <font style="color:rgb(28, 30, 33);">csv_args</font> 關鍵字參數,用于自定義傳遞給 Python 的 <font style="color:rgb(28, 30, 33);">csv.DictReader</font> 的參數。有關支持的 csv 參數的更多信息,請參閱 csv 模塊 文檔。
#示例:csv_custom.py
from langchain_community.document_loaders.csv_loader import CSVLoaderfile_path = ("../../resource/doc_search.csv"
)
loader = CSVLoader(file_path=file_path,encoding="UTF-8",csv_args={"delimiter": ",","quotechar": '"',"fieldnames": ["Name", "Species", "Age", "Habitat"],},
)
data = loader.load()
for record in data[:2]:print(record)
page_content='Name: 名稱
Species: 種類
Age: 年齡
Habitat: 棲息地' metadata={'source': '../../resource/doc_search.csv', 'row': 0}
page_content='Name: 獅子
Species: 哺乳動物
Age: 8
Habitat: 非洲草原' metadata={'source': '../../resource/doc_search.csv', 'row': 1}
如何加載 HTML
超文本標記語言(HTML)是用于在Web瀏覽器中顯示的文檔的標準標記語言。
這里介紹了如何將HTML文檔加載到LangChain的Document對象中,以便我們可以在下游使用。
解析HTML文件通常需要專門的工具。在這里,我們演示了如何通過Unstructured和BeautifulSoup4進行解析,可以通過pip安裝。請前往集成頁面查找與其他服務的集成,例如Azure AI Document Intelligence或FireCrawl。
使用Unstructured加載HTML
%pip install "unstructured[html]"
#示例:html_loader.py
from langchain_community.document_loaders import UnstructuredHTMLLoaderfile_path = "../../resource/content.html"
loader = UnstructuredHTMLLoader(file_path, encodings="UTF-8")
data = loader.load()
print(data)
[Document(metadata={'source': '../../resource/content.html'}, page_content='風景展示\n\n黃山\n\n黃山位于中國安徽省南部,是中國著名的風景名勝區,以奇松、怪石、云海和溫泉“四絕”聞名。\n\n大峽谷\n\n大峽谷位于美國亞利桑那州,是世界上最著名的自然景觀之一,以其壯觀的地質奇觀和深邃的峽谷聞名。')]
使用BeautifulSoup4加載HTML
我們還可以使用BeautifulSoup4使用<font style="color:rgb(28, 30, 33);">BSHTMLLoader</font>加載HTML文檔。這將將HTML中的文本提取到<font style="color:rgb(28, 30, 33);">page_content</font>中,并將頁面標題提取到<font style="color:rgb(28, 30, 33);">metadata</font>的<font style="color:rgb(28, 30, 33);">title</font>中。
#pip install bs4
#示例:html_bs4.py
from langchain_community.document_loaders import)
安裝筆記)




:零信任架構下的認證授權技術與實戰)



)

)
)


上使用Qt編譯時遇到“type_traits文件未找到”的錯誤)


