
- 博主簡介:努力學習的22級計算機科學與技術本科生一枚🌸
- 博主主頁: @Yaoyao2024
- 往期回顧:【深度學習】注意力機制| 基于“上下文”進行編碼,用更聰明的矩陣乘法替代笨重的全連接
- 每日一言🌼: 路漫漫其修遠兮,吾將上下而求索。—屈原🌺
0、前言
在上篇文章中,我們介紹了系統且詳細的介紹了注意力機制及其數學原理進行系統且詳細的講解。在本篇博客中,我們圍繞 多頭注意力的代碼實現進行展開。
這篇文章的代碼實現還是youtube管博主所提供的worksheet:https://github.com/kilianmandon/alphafold-decoded.git
在本篇博客中,我們會根據worksheet中的內容,依次實現以下:
- MultiHeadAttention:多頭注意力機制
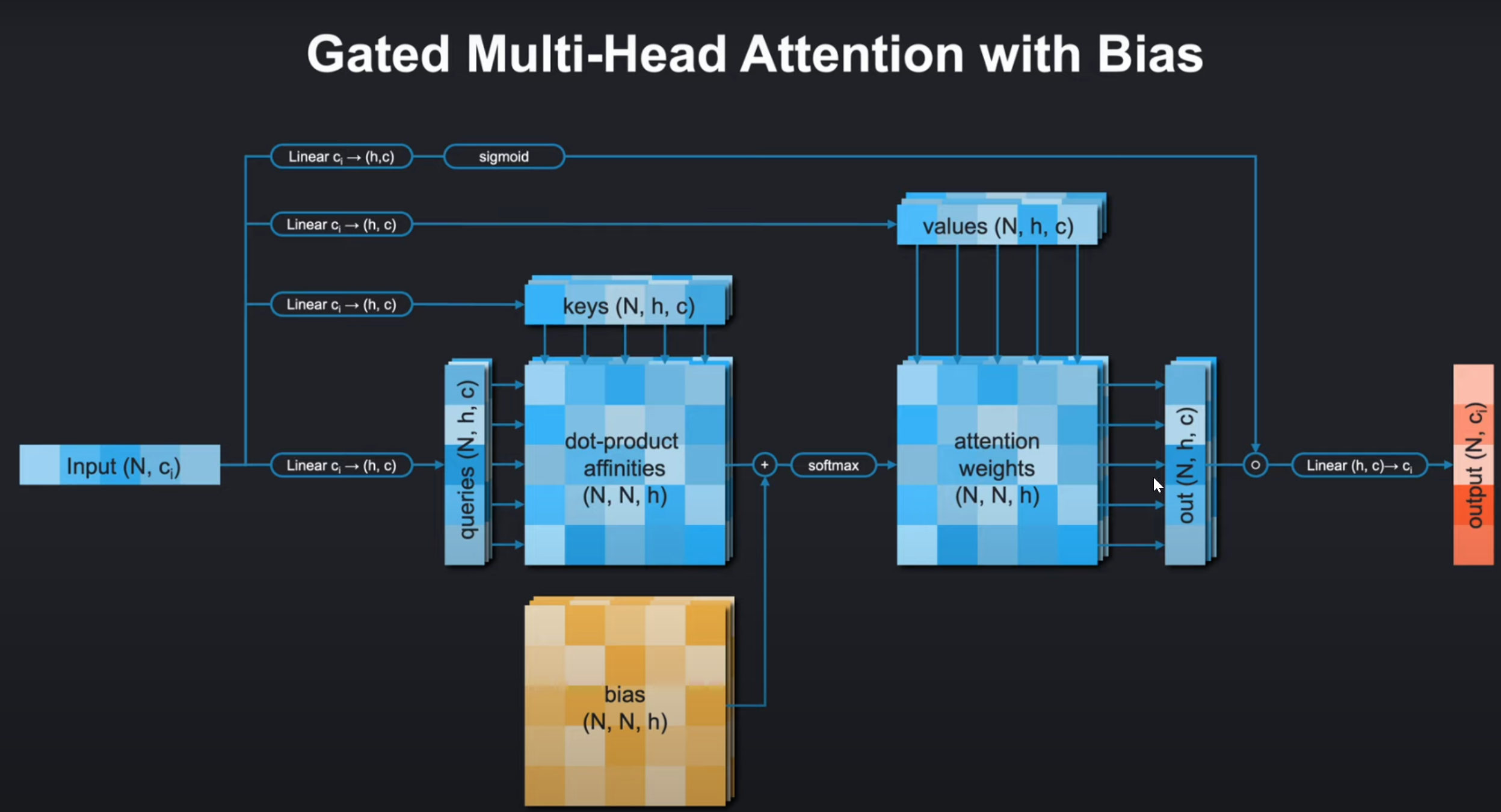
- Gated MultiHeadAttention:帶門控的注意力機制
- Global Gated MultiHeadAttention:全局+門控注意力機制
最終將其整合到一個注意力模塊中,利用傳遞參數的方法選擇使用哪種注意力。不過本篇博客主要是從代碼方面進行講解,讓對python和pytorch不是很熟悉的同學也能看懂代碼。
1. 模型初始化和qkv準備
1.1 def init
class MultiHeadAttention(nn.Module):"""A MultiHeadAttention module with optional bias and optional gating."""def __init__(self, c_in, c, N_head, attn_dim, gated=False, is_global=False, use_bias_for_embeddings=False):"""Initializes the module. MultiHeadAttention theoretically consists of N_head separate linear layers for the query, key and value embeddings.However, the embeddings can be computed jointly and split afterwards,so we only need one query, key and value layer with larger c_out.Args:c_in (int): Input dimension for the embeddings.c (int): Embedding dimension for each individual head.N_head (int): Number of heads.attn_dim (int): The dimension in the input tensor along whichthe attention mechanism is performed.gated (bool, optional): If True, an additional sigmoid-activated linear layer will be multiplicated against the weighted value vectors before feeding them through the output layer. Defaults to False.is_global (bool, optional): If True, global calculation will be performed.For global calculation, key and value embeddings will only use one head,and the q query vectors will be averaged to one query vector.Defaults to False.use_bias_for_embeddings (bool, optional): If True, query, key, and value embeddings will use bias, otherwise not. Defaults to False."""super().__init__()self.c_in = c_inself.c = cself.N_head = N_headself.gated = gatedself.attn_dim = attn_dimself.is_global = is_global
首先在模型初始化中包含這樣幾個參數:
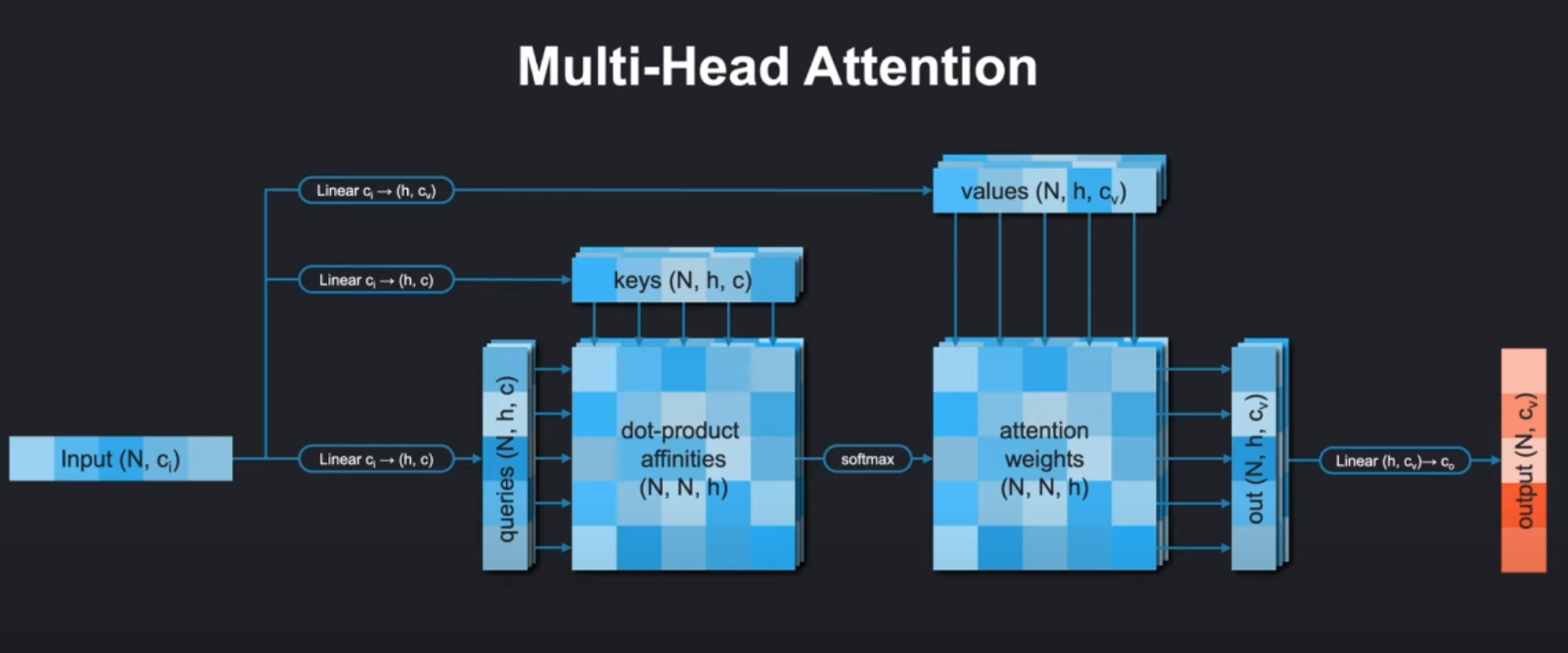
c_in:輸入特征維度c:每個注意力頭的特征維度N_head:注意力頭的數量attn_dim?:計算注意力的維度索引,注意力會沿著這個維度去計算不同元素之間的關聯。比如對于上圖的輸入單詞序列Input(N,ci),這里N代表token個數也是序列長度,注意力模型會沿著這個維度,去計算各個token之間的關聯。
🌸在計算點積親和度(dot - product affinities )時,是在這個維度上不同位置的查詢(queries)、鍵(keys)向量間進行點積運算,衡量不同位置之間的相關性,從而確定注意力權重 。 比如句子中某個詞和其他詞之間關聯程度計算,就是沿著這個維度展開的。gated:是否使用門控機制is_global:是否使用全局注意力:如果是全局注意力key和value在線性層進行變換后只有一個頭,query還是多頭,但是會在后面q/k/v準備的時候沿著注意力頭的方向被平均掉。use_bias_for_embeddings:是否在Q/K/V線性變換中使用偏置(也就是Linear層要不要加偏置和上圖中的在注意力得分后加偏置的意義不同)!
關鍵組件
-
線性變換層:
linear_q:生成查詢(Query)向量,輸出維度為c*N_headlinear_k:生成鍵(Key)向量,全局模式下輸出c,否則c*N_headlinear_v:生成值(Value)向量,維度同linear_klinear_o:輸出變換層,將多頭結果合并回c_in維度
-
門控層(可選):
linear_g:生成門控信號,使用sigmoid激活
########################################################################### TODO: Initialize the query, key, value and output layers. ## Whether or not query, key, and value layers use bias is determined ## by `use_bias` (False for AlphaFold). The output layer should always ## use a bias. If gated is true, initialize another linear with bias. ## For compatibility use the names linear_q, linear_k, linear_v, ## linear_o and linear_g. ###########################################################################
在初始化部分,我們主要是實現模型輸入和輸出的幾個線性層:
self.linear_q = nn.Linear(c_in, c*N_head, bias=use_bias_for_embeddings)c_kv = c if is_global else c*N_headself.linear_k = nn.Linear(c_in, c_kv, bias=use_bias_for_embeddings)self.linear_v = nn.Linear(c_in, c_kv, bias=use_bias_for_embeddings)self.linear_o = nn.Linear(c*N_head, c_in)if gated:self.linear_g = nn.Linear(c_in, c*N_head)
整個代碼實現如上,用pytorch中的nn.Linear即可。對于當時學到這里的我來說,我并不是很理解在is_global下的處理邏輯:
If True, global calculation will be performed.
For global calculation, key and value embeddings will only use one head,
and the q query vectors will be averaged to one query vector.
Defaults to False.
大致意思是說,k,v使用單頭,而q使用多頭(然后在和k進行點積計算注意力得分計算之前沿著attn-dim維度進行平均
1.2 prepare_qkv
非全局注意力的q,k,v準備:
def prepare_qkv(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):"""Splits the embeddings into individual heads and transforms the inputshapes of form (*, q/k/v, *, N_head*c) into the shape (*, N_head, q/k/v, c). The position of the q/k/v dimension in the original tensors is given by attn_dim.Args:q (torch.Tensor): Query embedding of shape (*, q, *, N_head*c).k (torch.Tensor): Key embedding of shape (*, k, *, N_head*c).v (torch.Tensor): Value embedding of shape (*, v, *, N_head*c).Returns:tuple: The rearranged embeddings q, k, and v of shape (*, N_head, q/k/v, c) respectively."""########################################################################### TODO: Rearrange the tensors with the following changes: ## - (*, q/k/v, *, N_head*c) -> (*, q/k/v, N_head*c) with movedim # # - (*, q/k/v, N_head*c) -> (*, q/k/v, N_head, c) ## - (*, q/k/v, N_head, c) -> (*, N_head, q/k/v, c) ############################################################################ Transposing to [*, q/k/v, N_head*c]q = q.movedim(self.attn_dim, -2)k = k.movedim(self.attn_dim, -2)v = v.movedim(self.attn_dim, -2)# Unwrapping to [*, q/k/v, N_head, c]q_shape = q.shape[:-1] + (self.N_head, -1)k_shape = k.shape[:-1] + (self.N_head, -1)v_shape = v.shape[:-1] + (self.N_head, -1)q = q.view(q_shape)k = k.view(k_shape)v = v.view(v_shape)# Transposing to [*, N_head, q/k/v, c]q = q.transpose(-2, -3)k = k.transpose(-2, -3)v = v.transpose(-2, -3)########################################################################### END OF YOUR CODE ###########################################################################return q, k, v
1. 移動 attn_dim 維度到倒數第二個位置
self.attn_dim表示查詢、鍵和值維度在原始張量中的位置。movedim方法用于將attn_dim維度移動到倒數第二個位置,這樣做是為了方便后續的形狀調整操作。經過這一步,張量的形狀變為(*, q/k/v, N_head*c)。
在標準的多頭注意力計算中,通常會將頭的維度放在倒數第三個位置,這樣可以更清晰地表示不同的頭和每個頭的嵌入維度。把 attn_dim 移動到倒數第二個位置,然后再進行后續的維度調整,最終可以得到符合這種習慣的形狀,便于后續的注意力計算和代碼實現。
2. 將 N_head*c 維度拆分為 N_head 和 c
- 首先,通過
q.shape[:-1] + (self.N_head, -1)構建新的形狀元組,將最后一個維度N_head*c拆分為N_head和c。這里的-1表示讓 PyTorch 自動計算該維度的大小。 - 然后,使用
view方法將張量的形狀調整為(*, q/k/v, N_head, c)。
3. 交換倒數第二個和倒數第三個維度
transpose方法用于交換張量的兩個維度。這里交換倒數第二個和倒數第三個維度,將N_head維度移動到倒數第三個位置,最終得到形狀為(*, N_head, q/k/v, c)的張量。
1.3 prepare_qkv_global
def prepare_qkv_global(self, q, k, v):"""Prepares the query, key and value embeddings with the following differences to the non-global version:- key and value embeddings use only one head.- the query vectors are contracted into one, average query vector.Args:q (torch.tensor): Query embeddings of shape (*, q, *, N_head*c).k (torch.tensor): Key embeddings of shape (*, k, *, c).v (torch.tensor): Value embeddings of shape (*, v, *, c).Returns:tuple: The rearranged embeddings q, k, and v ofshape (*, N_head, 1, c) for q and shape (*, 1, k, c) for k and v. """########################################################################### TODO: Rearrange the tensors to match the output dimensions. Use ## torch.mean for the contraction of q at the end of this function. ###########################################################################q = q.movedim(self.attn_dim, -2)k = k.movedim(self.attn_dim, -2)v = v.movedim(self.attn_dim, -2)q_shape = q.shape[:-1] + (self.N_head, self.c)q = q.view(q_shape)q = q.transpose(-2, -3)k = k.unsqueeze(-3)v = v.unsqueeze(-3)q = torch.mean(q, dim=-2, keepdim=True)########################################################################### END OF YOUR CODE ###########################################################################return q, k, v
因為在上面初始化的時候已經講到k,v都是單頭的,所以在這里無需考慮n-head。但對于q來說,它需要考慮。
其次它的不同是,需要在最后沿著attn-dim的方向進行平均,這樣讓一個head下只有一個query和key進行矩陣乘法計算注意力得分。
1.4 解釋:關于global選項下的qkv
到這里為止,我們把多頭注意力的初始化、q/k/v的準備算是講完了。其實到這里我還有一個疑問:
為什么在考慮Global-attention的時候,只對k/v使用單頭?對q保留多頭。后來我發現是自己對q/k/v的本身地位沒有理解透徹。
如果和cnn類比的話,q相當于卷積核,k/v都是用來表示原始數據的信息。只有卷積核不同,模型才能提取出來各種各樣的特征。這里也是類似,只有query不同,模型才能以各個角度去捕捉多樣化的信息。k/v可以不用多頭,因為它們本質主要為注意力計算提供可匹配信息和實際要聚合的特征。單頭足以提供關鍵信息,多頭可能引入過多重復或相似信息,造成資源浪費,單頭能更高效地提供必要信息 (主要是采用單頭計算,能顯著減少線性變換等操作次數)。
1. 核心目的:減少計算量
全局注意力的核心思想是將序列級別的全局信息壓縮為一個"概要向量",從而避免計算龐大的 N × N N \times N N×N 注意力矩陣( N N N) 是序列長度)。
- Key/Value單頭:所有注意力頭共享同一組Key/Value,相當于用單頭生成一個"全局記憶池"。
- 計算量從 O ( N 2 ? H ) O(N^2 \cdot H) O(N2?H) 降至 O ( N 2 + N ? H ) O(N^2 + N \cdot H) O(N2+N?H)( H H H 是頭數)。
- Query多頭:保留多頭設計,讓不同頭從不同角度"查詢"這個全局記憶池,維持特征多樣性。
2. 為什么Query需要多頭?
即使Key/Value是全局共享的,不同注意力頭仍可關注不同的全局模式:
- 舉例(蛋白質序列):
- 頭1可能關注"保守殘基"的全局分布。
- 頭2可能關注"疏水殘基"的全局密度。
- 頭3可能關注"二級結構"(如α螺旋)的周期性。
- 數學上:
多組Query與同一組Key/Value計算注意力,仍會得到不同的加權結果(因Query向量不同)。
3. 為什么Key/Value可以單頭?
- 信息冗余假設:
對于超長序列,Key/Value的全局特征(如蛋白質的總體折疊模式)通常不需要多視角編碼,一個統一的表示足夠。 - 計算效率:
Key/Value矩陣的維度從 N × ( H ? d k ) N \times (H \cdot d_k) N×(H?dk?) 降至 N × d k N \times d_k N×dk?,顯存占用大幅減少。
2. Forward
def forward(self, x, bias=None, attention_mask=None):"""Forward pass through the MultiHeadAttention module.Args:x (torch.tensor): Input tensor of shape (*, q/k/v, *, c_in).bias (torch.tensor, optional): Optional bias tensor of shape(*, N_head, q, k) that will be added to the attention weights. Defaults to None.attention_mask (torch.tensor, optional): Optional attention maskof shape (*, k). If set, the keys with value 0 in the mask willnot be attended to.Returns:torch.tensor: Output tensor of shape (*, q/k/v, *, c_in)"""out = Noneq = self.linear_q(x)k = self.linear_k(x)v = self.linear_v(x)if self.is_global:q, k, v = self.prepare_qkv_global(q, k, v)else:q, k, v = self.prepare_qkv(q, k, v)q = q / math.sqrt(self.c)a = torch.einsum('...qc,...kc->...qk', q, k)if bias is not None:bias_batch_shape = bias.shape[:-3]bias_bc_shape = bias_batch_shape + (1,) * (a.ndim-len(bias_batch_shape)-3) + bias.shape[-3:]bias = bias.view(bias_bc_shape)a = a + biasif attention_mask is not None:attention_mask = attention_mask[..., None, None, :]offset = (attention_mask==0) * -1e8a = a + offseta = torch.softmax(a, dim=-1)# o has shape [*, N_head, q, c]o = torch.einsum('...qk,...kc->...qc', a, v)o = o.transpose(-3, -2)o = torch.flatten(o, start_dim=-2)o = o.moveaxis(-2, self.attn_dim)if self.gated:g = torch.sigmoid(self.linear_g(x))o = g * oout = self.linear_o(o)########################################################################### END OF YOUR CODE ###########################################################################return out- 輸入預處理: Create query, key and value embeddings,Rearrange the embeddings with prepare_qkv
q = self.linear_q(x)
k = self.linear_k(x)
v = self.linear_v(x)
if self.is_global:q, k, v = self.prepare_qkv_global(q, k, v)
else:q, k, v = self.prepare_qkv(q, k, v)
- 通過線性變換生成Query(Q)、Key(K)、Value(V)張量:
(*, N_head, q/k/v, c) - 如果是全局注意力模式(
is_global=True),會調用prepare_qkv_global對KV做特殊處理
- Query縮放:Scale the queries by 1/sqrt( c )
q = q / math.sqrt(self.c)
- 將Query向量除以√d(d是每個頭的維度),防止點積結果過大導致softmax梯度消失
- 注意力得分計算
a = torch.einsum('...qc,...kc->...qk', q, k)
- 使用愛因斯坦求和約定計算Q和K的點積
- 結果張量a的形狀為
[*, N_head, q, k],表示每個查詢位置與每個鍵位置的相似度
- 偏置處理
if bias is not None:bias_batch_shape = bias.shape[:-3]bias_bc_shape = bias_batch_shape + (1,) * (a.ndim-len(bias_batch_shape)-3) + bias.shape[-3:]bias = bias.view(bias_bc_shape)a = a + bias
- 調整偏置張量的形狀使其可以廣播到注意力得分矩陣
- 將偏置加到原始得分上(如AlphaFold中用于注入殘基對信息)
- 注意力掩碼處理
if attention_mask is not None:attention_mask = attention_mask[..., None, None, :]offset = (attention_mask==0) * -1e8a = a + offset
- 對需要屏蔽的位置(attention_mask==0)加上一個很大的負值(-1e8)
- softmax后這些位置的權重會趨近于0
- Softmax歸一化
a = torch.softmax(a, dim=-1)
- 對最后一個維度(k)做softmax,得到歸一化的注意力權重
- 加權求和
o = torch.einsum('...qk,...kc->...qc', a, v)
- 使用注意力權重對Value向量加權求和
- 輸出形狀為
[*, N_head, q, c]
- 輸出重組
o = o.transpose(-3, -2)
o = torch.flatten(o, start_dim=-2)
o = o.moveaxis(-2, self.attn_dim)
- 轉置頭維和查詢維
- 展平多頭輸出
- 將特征維度移動到指定位置(attn_dim)
- 門控機制
if self.gated:g = torch.sigmoid(self.linear_g(x))o = g * o
- 如果啟用門控,生成0-1之間的門控值
- 按元素相乘控制信息流
- 最終輸出變換
out = self.linear_o(o)
- 通過最后一個線性層將維度映射回輸入維度
這個forward方法是多頭注意力機制的核心計算過程,我將逐步解釋它的實現邏輯和關鍵步驟:
1. 輸入預處理
q = self.linear_q(x)
k = self.linear_k(x)
v = self.linear_v(x)
- 通過線性變換生成Query(Q)、Key(K)、Value(V)張量
- 如果是全局注意力模式(
is_global=True),會調用prepare_qkv_global對KV做特殊處理
2. Query縮放
q = q / math.sqrt(self.c)
- 將Query向量除以√d(d是每個頭的維度),防止點積結果過大導致softmax梯度消失
3. 注意力得分計算
a = torch.einsum('...qc,...kc->...qk', q, k)
- 使用愛因斯坦求和約定計算Q和K的點積
- 結果張量a的形狀為
[*, N_head, q, k],表示每個查詢位置與每個鍵位置的相似度
4. 偏置處理
if bias is not None:bias_batch_shape = bias.shape[:-3]bias_bc_shape = bias_batch_shape + (1,) * (a.ndim-len(bias_batch_shape)-3) + bias.shape[-3:]bias = bias.view(bias_bc_shape)a = a + bias
- 調整偏置張量的形狀使其可以廣播到注意力得分矩陣
- 將偏置加到原始得分上(如AlphaFold中用于注入殘基對信息)
5. 注意力掩碼處理
if attention_mask is not None:attention_mask = attention_mask[..., None, None, :]offset = (attention_mask==0) * -1e8a = a + offset
- 對需要屏蔽的位置(attention_mask==0)加上一個很大的負值(-1e8)
- softmax后這些位置的權重會趨近于0(代表不關注這些位置)
6. Softmax歸一化
Use softmax to convert the attention scores into a probability distribution.
a = torch.softmax(a, dim=-1)
- 對最后一個維度(k)做softmax,得到歸一化的注意力權重。
7. 加權求和
o = torch.einsum('...qk,...kc->...qc', a, v)
- 使用注意力權重對Value向量加權求和
- 輸出形狀為
[*, N_head, q, c]
8. 輸出重組
# - Rearrange the intermediate output in the following way: ## * (*, N_head, q, c) -> (*, q, N_head, c) ## * (*, q, N_head, c) -> (*, q, N_head * c) ## * (*, q, N_head * c) -> (*, q, *, N_head * c) ## The order of these transformations is crucial, as moving q
o = o.transpose(-3, -2)
o = torch.flatten(o, start_dim=-2)
o = o.moveaxis(-2, self.attn_dim)
- 轉置頭維和查詢維
- 展平多頭輸出
- 將特征維度移動到指定位置(attn_dim)
9. 門控機制
if gated, calculate the gating with linear_g and sigmoid and multiply it against the output.
if self.gated:g = torch.sigmoid(self.linear_g(x))o = g * o
- 如果啟用門控,生成0-1之間的門控值
- 按元素相乘控制信息流
10. 最終輸出變換
apply linear_o to calculate the final output.
out = self.linear_o(o)
- 通過最后一個線性層將維度映射回輸入維度
關鍵設計特點:
- 高效張量操作:使用
einsum進行批量矩陣運算 - 靈活的維度處理:支持任意批處理維度和自定義注意力維度
- 模塊化設計:可插拔的偏置、掩碼和門控機制
- 全局注意力支持:通過
is_global標志切換模式





)
安裝筆記)




:零信任架構下的認證授權技術與實戰)



)

)
)
