文章目錄
- 插入排序
- 1. 直接插入排序(O(n^2))
- 舉例1:
- 舉例2:
- 直插排序的"代碼"
- 直插排序的“時間復雜度”
- 2. 希爾排序(O(n^1.3))
- 方法一
- 方法二(時間復雜度更優)
- 選擇排序
- 堆排序
- 直接選擇排序
我們學過冒泡排序,堆排序等等。(回顧一下:排升序,建大堆;排降序,建小堆。)
排序:所謂排序,就是使?串記錄,按照其中的某個或某些關鍵字的??,遞增或遞減的排列起來的
操作。
在生活中也會遇到很多排序:購物篩選排序(按照價格、綜合、銷量、距離等排序)、百度熱搜(根據熱搜程度)、院校排名等等。

插入排序
1. 直接插入排序(O(n^2))
基本思想:將(待排序的記錄)按照(關鍵碼值的大小)逐個插入到(已經排好序的有序隊列)中。直到所有的記錄插入完為止,得到一個新的有序序列。
先將arr[end]指向:(有序隊列的最后一個數據),然后將(需要和有序數據進行比較的數據:即arr[end+1])暫時存儲在tmp中,接下來將arr[end]和tmp里的數據進行比較。

注意在一次循環中,tmp的值是不變的(除非end++,才會使tmp的值改變(tmp=arr[end]))
舉例1:
【假設想要排升序】

- 現在arr[end]的值大于tmp,應該排在后面,所以現在將end的值放在end+1的位置,這個時候會發現end+1位置的值被覆蓋了,所以我們需要提前將它的值存儲在tmp中(這就是將值存儲在tmp中的原因)。接下來需要將tmp的值放在end的位置(這個是arr[end]的前面沒有其他值的情況,我們可以直接將tmp的值賦給arr[end])
在交換值之后,將end++,tmp的值為arr[end+1] (它不用修改,因為end已經修改了)

-
如果arr[end]<tmp,并不需要交換呢?(比如5和9)那就直接end++,緊接著tmp的值也變啦。
-
緊接著又是將9和6交換,按照之前的方法(將arr[end]的值賦給arr[end+1],然后將tmp的值賦給arr[end]

-
為什么我們還需要將交換之后的arr[end]的值和這個序列前面的值比較呢?------防止它比前面已經排好序的值小
接下來按照前面的方法,再將9和2進行比較
舉例2:

直插排序的"代碼"
我們需要一個循環來控制end++,往后走;
還需要一個循環來控制:當把arr[end]賦值給arr[end+1]之后,需要將end- -,將前面的數值和tmp繼續比較。
在這里插入代碼片`void InsertSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++) //為什么是i<n-1?{int end = i;int tmp = arr[end + 1];while (end >= 0){if (arr[end] > tmp){arr[end + 1] = arr[end];end--;}else{break;}}arr[end + 1] = tmp;}
}`

- 為什么是
i<n-1呢?
因為tmp存儲的是arr[end+1],我們要確保它是最后一個不會越界,即end+1<n,又因為end=i,所以i+1<n,所以i<n-1。
直插排序的“時間復雜度”
直接插入排序的時間復雜度是O(n^2)
不過O(n^2)是最差的情況。

最差:想將降序----->升序 O(n^2)
最好:升序------->升序 O(n)
2. 希爾排序(O(n^1.3))
希爾排序就是對直接插入排序的一種優化。想要改善降序---->升序的時間復雜度。
希爾排序分為兩步:1.預排序 2.直接插入排序
我們可以將很長的一段數組序列變為n段較短的序列,然后對每段“單獨”進行直接插入排序(這個叫做預排序)。預排結束之后,小的數據大部分都在前半部分了(只是不按順序),接著我們再對整體的數組(已經趨于有序的數組)序列進行一次直插排序,這樣不僅完成了排序,還優化了時間復雜度。
方法一
- 首先我們需要決定一個值:gap,然后將大段分為n個小段(每段的首和尾相隔gap個元素,即第一個值往后數gap個,那個數據是這段的最后一個元素)。
什么情況下預排:當gap>1的時候
什么情況下整段直插:當gap==1的時候

-
從上圖可以知曉:要將一大段數據分為很多組數據,在尋找第二組數據時,需要將上次的首元素下標++。這一步由外層循環控制【遍歷每個子序列的起始位置(從 0 到 gap-1)】,
for(i=0;i<gap;i++)(為什么i<gap?) -
接下來是每組數據中,知道了首元素,然后找這組數據中的剩余數據,即end+gap,這個由第二層循環控制:
for(int j=0;j<n-gap;j+=gap);(為什么內層的j<n-gap?) -
再里面的元素之間比較就沒有什么特別了,使用的是直接插入排序(它也有循環)。
【gap不能太大(若太大的話,會導致每組的數據比較少,但組數比較多),也不能太小(那樣的話每組數據會有很多,那這樣的話時間復雜度又變高了)】我們可以讓gap由元素個數決定,gap=n/3+1,為什么最后還要+1呢?(如果遇到2/3的情況,那商就是0,也就是gap=0,那間距為0,誰和誰比呢?)而我們最后需要讓gap=1,讓已經預排之后的整段數據進行直插排序,所以需要+1.
【gap等于多少,這段數據最終就會被分為幾組數據】如果n特別特別大,n/3之后也特大,先將+1給忽略掉
-
之前我們說到為什么外層循環中
i<gap而不是i<n呢?

我們第一組數據的第二個元素是arr[end+gap]也就是arr[0+gap],既然arr[gap]在第一組數據中已經進行比較過一次,那之后就沒必要再將它比較一次了。大家觀察上圖會發現每個數據都進行比較過,如果外層用 i < n,會導致重復處理同一子序列,效率降低。 -
還有一個問題是:為什么第二層循環需要
j<n-gap,按照方法一個組中,每個數據它們都相鄰gap個(n=8,gap=3第一組元素下標:0,3,6,下標為6的元素后面還有1個元素,但是剩余元素個數不夠gap個,那就只能在這次的循環中將后面的元素舍棄。所以在找每組的數據時(即在第二層循環),循環結束的條件是最后一個元素后面的元素個數小于gap個(有剩余的元素或者剩余個數為0(也就是剛好后面沒有元素了)),也就是它的下標小于n-gap

第一組的數據:7,4,1
第二組的數據:6,3
第三組的數據:5,2
…
- 然后,先排第一組的數據,再排2,3組的數據
(1)初始情況:arr[end]指向第一個元素,tmp指向(與第一個相隔gap的元素).即tmp=arr[end+gap]
- 若
arr[end]>tmp,那么將arr[end]的值賦給tmp所指向的那個值,即arr[end+gap]=arr[end],賦值之后,將end=end-gap - 若
arr[end]>tmp,不用修改值。直接將end+=gap
對于每組數據的值比較的注釋
(2)排完第二組的數據之后,外層的i++,到第二個數據【下標為1】(它作為第二組的首元素),然后進入第二層循環,在進行比較。
到此為止,這個進行了一趟比較
void ShellSort(int* arr, int n)
{int gap = n / 3 + 1;for (int i = 0; i < gap; i++){int j = i;for (j =i; j < n - gap; j += gap){int end = j;int tmp = arr[end + gap];while (end>=0) //將這組數據的每個數據比較,while結束的條件:end>=0;{if (arr[end] > tmp){arr[end + gap] = arr[end];//想繼續和前面有序的數據比較,將end-gapend -= gap;}//到這里,arr[end]<tmp,那就不用賦值,直接將下標+gap,tmp的值隨之改變,繼續比較else {break;}}//在循環中,我們只是將大的數據往后賦值,那當初那個比較小的tmp賦給誰呢?//這組數據如何能比較結束(break)呢?肯定是此時的arr[end]并沒有tmp大,不需要交換了//所以,我們把tmp值賦值給之前一個比較的值(由于是end-=gap,所以上一個是end+gap)arr[end + gap] = tmp;}}
}


之后我們將gap不斷縮小,繼續比較,直至最后gap==1時,進行最后的,對整段進行直插

void ShellSort(int* arr, int n)
{int gap = n;while (gap>1){gap = gap / 3 + 1;for (int i = 0; i < gap; i++){int j = i;for (j = i; j < n - gap; j += gap){int end = j;int tmp = arr[end + gap];while (end >= 0) //將這組數據的每個數據比較,while結束的條件:end>=0;{printf("%d ", gap);if (arr[end] > tmp){arr[end + gap] = arr[end];//想繼續和前面有序的數據比較,將end-gapend -= gap;}//到這里,arr[end]<tmp,那就不用賦值,直接將下標+gap,tmp的值隨之改變,繼續比較else {break;}}//在循環中,我們只是將大的數據往后賦值,那當初那個比較小的tmp賦給誰呢?//這組數據如何能比較結束(break)呢?肯定是此時的arr[end]并沒有tmp大,不需要交換了//所以,我們把tmp值賦值給之前一個比較的值(由于是end-=gap,所以上一個是end+gap)arr[end + gap] = tmp;}}}
}
注意:為什么gap>1還可以對整段進行直插排序呢?
大家先想一想gap==1的條件:肯定是上一個gap>1因而進入了循環,進行了gap=gap/3+1,而gap/3=0,gap/3+1=1,接下來進行了直插。不會有其他意外。
n=10:
第一次,gap=n=10,大于1,進入循環之后,gap=gap/3+1=4,之后進行排序。
第二次,gap=4,大于1,進入循環,gap=gap/3+1=4/3+1=2,之后進行排序
注意gap=2的時候它仍然大于1 ,進入循環了,然后才進行的gap=gap/3+1,得到了gap=1,進行最后的直插
方法二(時間復雜度更優)
在上面的基礎上進行優化:
之前是將一組一組比,現在仍然是相隔gap個的兩個元素進行比較,但是當它倆比較完之后,我們不用找arr[0+gap]再隔gap的值。我們直接找arr[0]的下一個:arr[1],再找arr[1+gap],將他倆比較。那到什么時候停止呢?當i<n-gap時。
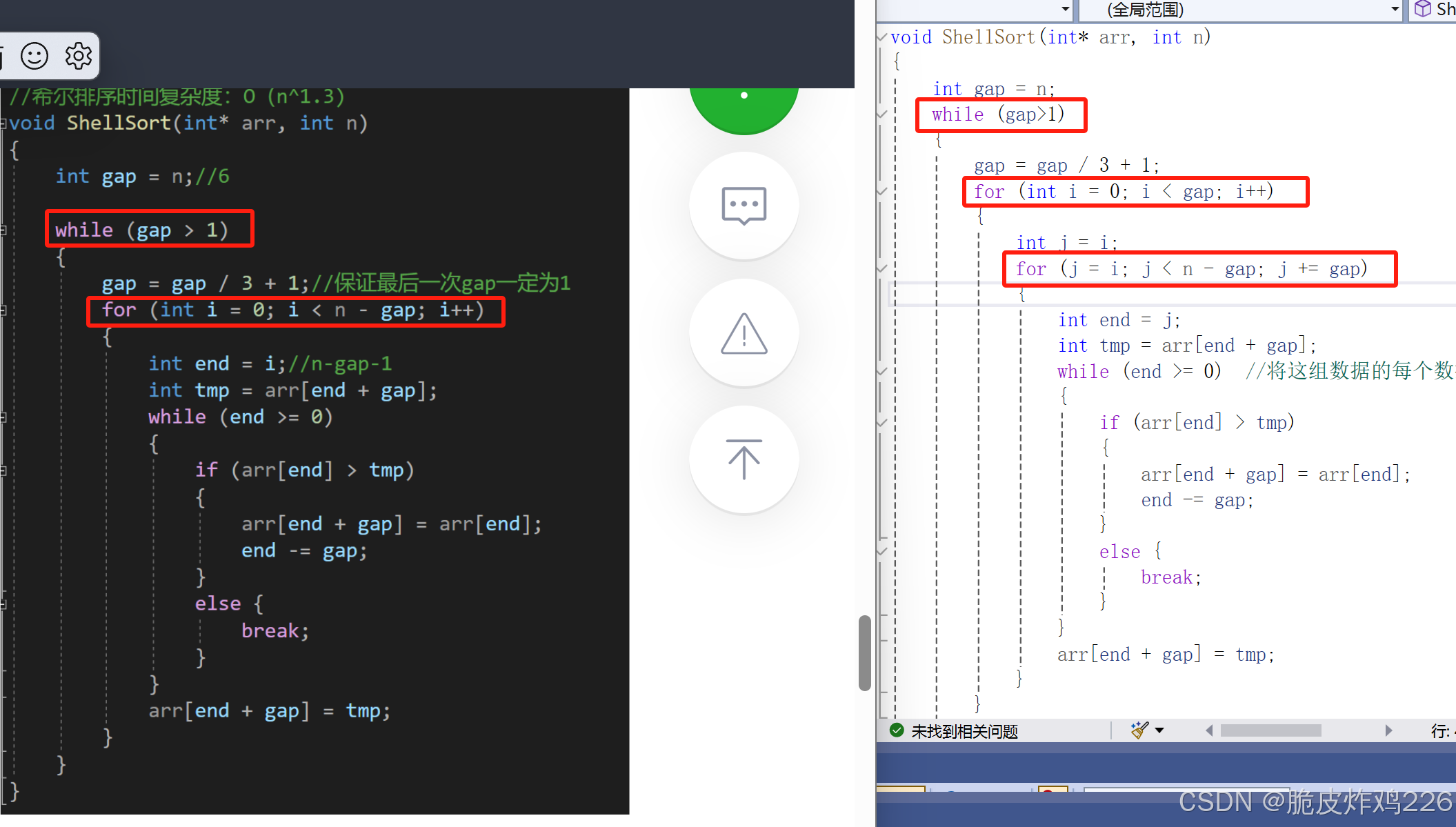
void ShellSort(int* arr, int n)
{int gap = n;while (gap>1){gap = gap / 3 + 1;for (int i=0; i < n - gap; i++){int end = i;int tmp = arr[end + gap];while (end >= 0) //將這組數據的每個數據比較,while結束的條件:end>=0;{if (arr[end] > tmp){arr[end + gap] = arr[end];//想繼續和前面有序的數據比較,將end-gapend -= gap;}//到這里,arr[end]<tmp,那就不用賦值,直接將下標+gap,tmp的值隨之改變,繼續比較else {break;}}//在循環中,我們只是將大的數據往后賦值,那當初那個比較小的tmp賦給誰呢?//這組數據如何能比較結束(break)呢?肯定是此時的arr[end]并沒有tmp大,不需要交換了//所以,我們把tmp值賦值給之前一個比較的值(由于是end-=gap,所以上一個是end+gap)arr[end + gap] = tmp;}}
}

希爾排序的時間復雜度是:O(n^1.3)

選擇排序
堆排序
這是堆排序的文章,點擊鏈接即可跳轉
直接選擇排序
這個名字中的“選擇”已經暴露了它的方法,直接選擇排序是從整個數組中(arr[0]到arr[n-1])選出來min或者max的元素,然后放在整個數組的第一個位置。然后再從arr[1]到arr[n-1]選出來min或max,放在第二個位置。【將min/max放在第一個位置,那原本的數據怎么辦,所以不是直接將這個值放在第一個位置,而是將兩個值交換】
-
思路:
-
- 先設定兩個變量,begin和mini(它倆是下標),begin作為min或者max放置的位置的下標。mini作為遍歷數組時此時位置的下標。[需要知道跳出循環的條件,即放的位置<n]

- 先設定兩個變量,begin和mini(它倆是下標),begin作為min或者max放置的位置的下標。mini作為遍歷數組時此時位置的下標。[需要知道跳出循環的條件,即放的位置<n]
-
但是又一個bug是:每找一次最大/最小值,就需要將數組遍歷一遍(和冒泡排序一樣費時間O(n^2)),時間復雜度很大,我們進行優化。
在遍歷一遍數組的時候,我們可以將min和max同時找出來,將它們放在數組的兩端。這樣就可以省略一半的時間。【但需要注意的是,這個上面那個的循環結束條件就不一樣了,我們不用再遍歷后半部分,就是已經放好特定值的那部分】
void SelectSort(int* arr, int n)
{int begin=0;for (begin = 0; begin < n/2; begin++) //為什么begin<n/2呢?因為begin是前半部分的下標,只用占整個數組的一半{int maxi = begin;int mini = begin;//確定了這趟mini要放的位置,接下來這個循環用來遍歷找最小值/最大值,用j來遍歷int j = begin;for (j = begin+1; j < n-begin; j++) //為什么j<n-begin//第一遍遍歷的時候,需要遍歷所有的//第二次遍歷,就不用遍歷最后一個,已經放了特定的值//第三次遍歷,倒數兩個都不用遍歷了{if (arr[j] < arr[mini])mini=j;if (arr[j] > arr[maxi])maxi=j;}//這一步是什么作用?if (maxi == begin){maxi = mini;}Swap(&arr[begin], &arr[mini]);Swap(&arr[n - 1 - begin], &arr[maxi]);}
}
其中這一步的作用是什么呢?
if (maxi == begin)
{maxi = mini;
}
舉個例子:
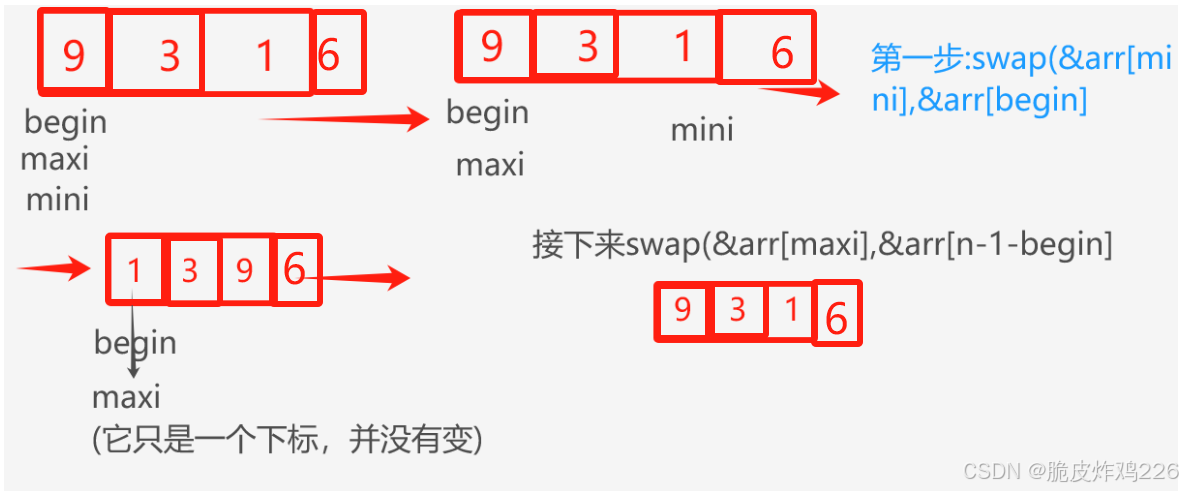
這個的問題就在于:maxi剛好和begin重合了,而arr[begin]先一步和arr[mini]交換了,所以我們需要在交換之前處理一下:如果它倆重合了,那就先讓maxi走到mini的位置。
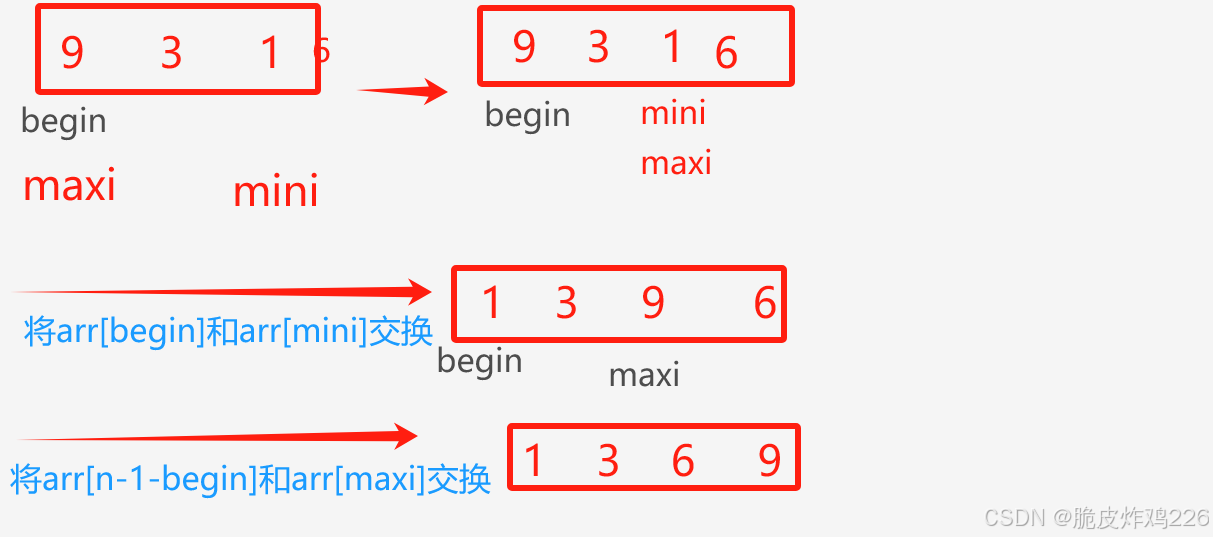
if(maxi==begin)maxi=mini;
)
![【Python] pip制作離線包](http://pic.xiahunao.cn/【Python] pip制作離線包)



:多因素交織下的行業剖析與展望)












)
