今天主播我把黑馬新版微服務課程MQ高級之前的內容都看完了,雖然在看視頻的時候也記了筆記,但是看完之后還是忘得差不多了,所以打算寫一篇博客再溫習一下內容。
課程坐標:黑馬程序員SpringCloud微服務開發與實戰
微服務
認識單體架構
單體架構(monolithic structure):顧名思義,整個項目中所有功能模塊都在一個工程中開發;項目部署時需要對所有模塊一起編譯、打包;項目的架構設計、開發模式都非常簡單。
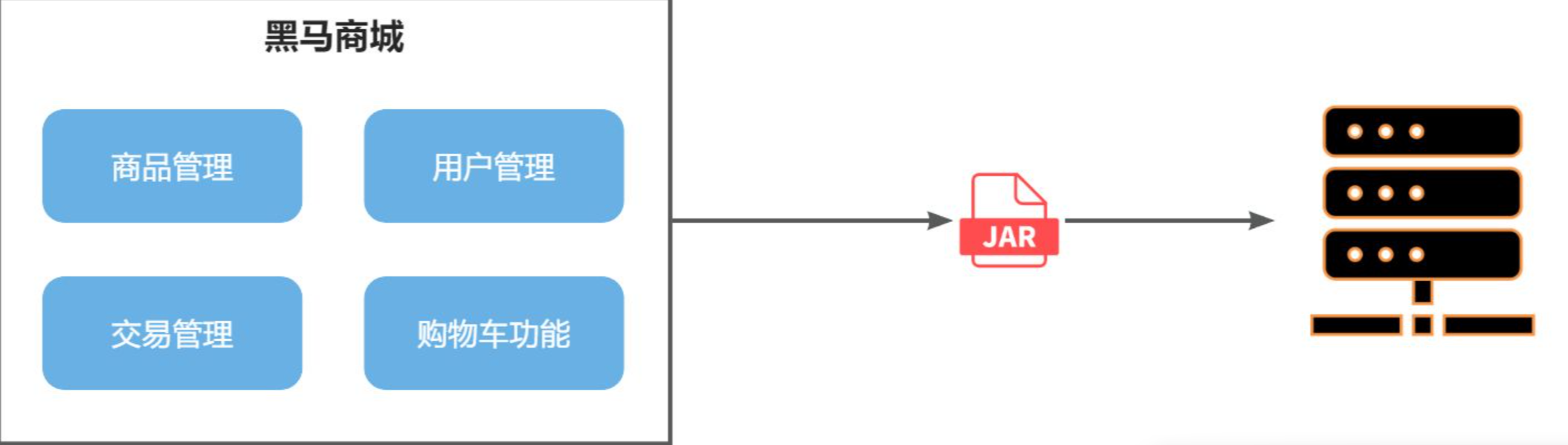
像我們之前寫過的
蒼穹外賣,黑馬點評,他們雖然被拆分成了不同的模塊,但是還是一個單體項目,通過Maven的聚合,讓所有模塊聯系在一起,這種單體項目架構開發起來非常方便,例如我們簡單寫一個后臺管理系統,或者是訪問量較小的個人博客的后臺系統的時候,單體項目是再簡單不過的,但是如果我們用微服務來寫,屬實是大材小用。
但隨著項目的業務規模越來越大,團隊開發人員也不斷增加,單體架構就呈現出越來越多的問題:
團隊協作成本高:試想一下,你們團隊數十個人同時協作開發同一個項目,由于所有模塊都在一個項目中,不同模塊的代碼之間物理邊界越來越模糊。最終要把功能合并到一個分支,你絕對會陷入到解決沖突的泥潭之中。在公司當中一般都是用git來管理代碼,你想象下,你開發一個模塊,別人開發另一個模塊,但是有一天,你們都對公共代碼進行了修改,向git提交的時候是不是就會出現合并沖突。系統發布效率低:任何模塊變更都需要發布整個系統,而系統發布過程中需要多個模塊之間制約較多,需要對比各種文件,任何一處出現問題都會導致發布失敗,往往一次發布需要數十分鐘甚至數小時。系統可用性差:單體架構各個功能模塊是作為一個服務部署,相互之間會互相影響,一些熱點功能會耗盡系統資源,導致其它服務低可用。
關于系統可用性差,我們可以想象下,如果我們單體項目有兩個服務,一個是
不太經常被訪問的接口A,而一個是經常被訪問的熱點接口B,如果我們使用的是單體項目架構,那么熱點接口B在被頻繁訪問的時候就會影響A的訪問速度和性能,這就是單體項目的缺點,功能之間的相互影響比較大。而要想解決這些問題,就需要使用微服務架構了。
認識微服務
微服務架構,首先是服務化,就是將單體架構中的功能模塊從單體應用中拆分出來,獨立部署為多個服務。同時要滿足下面的一些特點:
單一職責:一個微服務負責一部分業務功能,并且其核心數據不依賴于其它模塊。團隊自治:每個微服務都有自己獨立的開發、測試、發布、運維人員,團隊人員規模不超過10人(2張披薩能喂飽)服務自治:每個微服務都獨立打包部署,訪問自己獨立的數據庫。并且要做好服務隔離,避免對其它服務產生影響
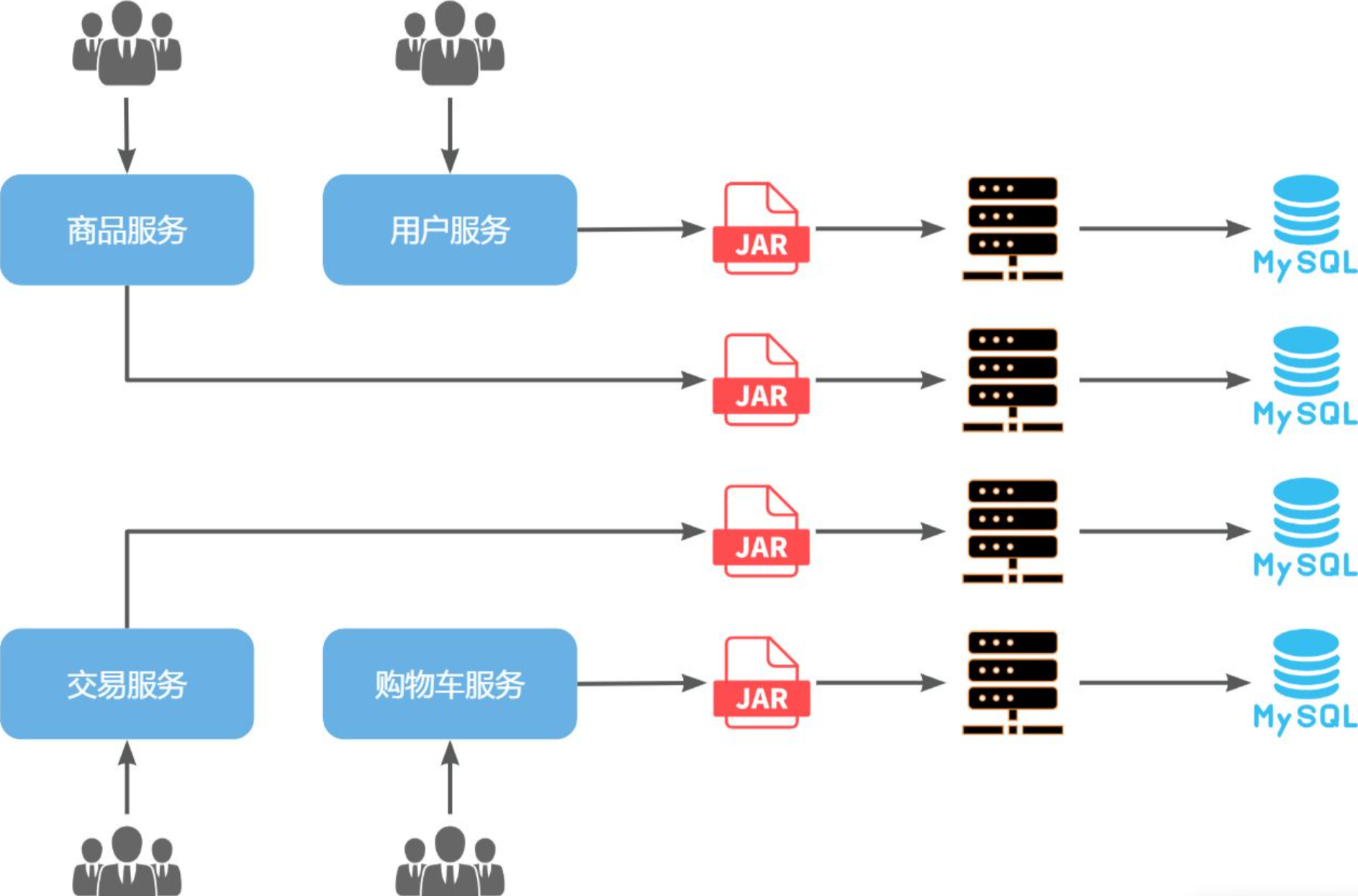
那么,單體架構存在的問題有沒有解決呢?
團隊協作成本高?- 由于服務拆分,每個服務代碼量大大減少,參與開發的后臺人員在1~3名,協作成本大大降低
系統發布效率低?- 每個服務都是獨立部署,當有某個服務有代碼變更時,只需要打包部署該服務即可
系統可用性差?- 每個服務獨立部署,并且做好服務隔離,使用自己的服務器資源,不會影響到其它服務。
SpringCloud
微服務拆分以后碰到的各種問題都有對應的解決方案和微服務組件,而SpringCloud框架可以說是目前Java領域最全面的微服務組件的集合了。
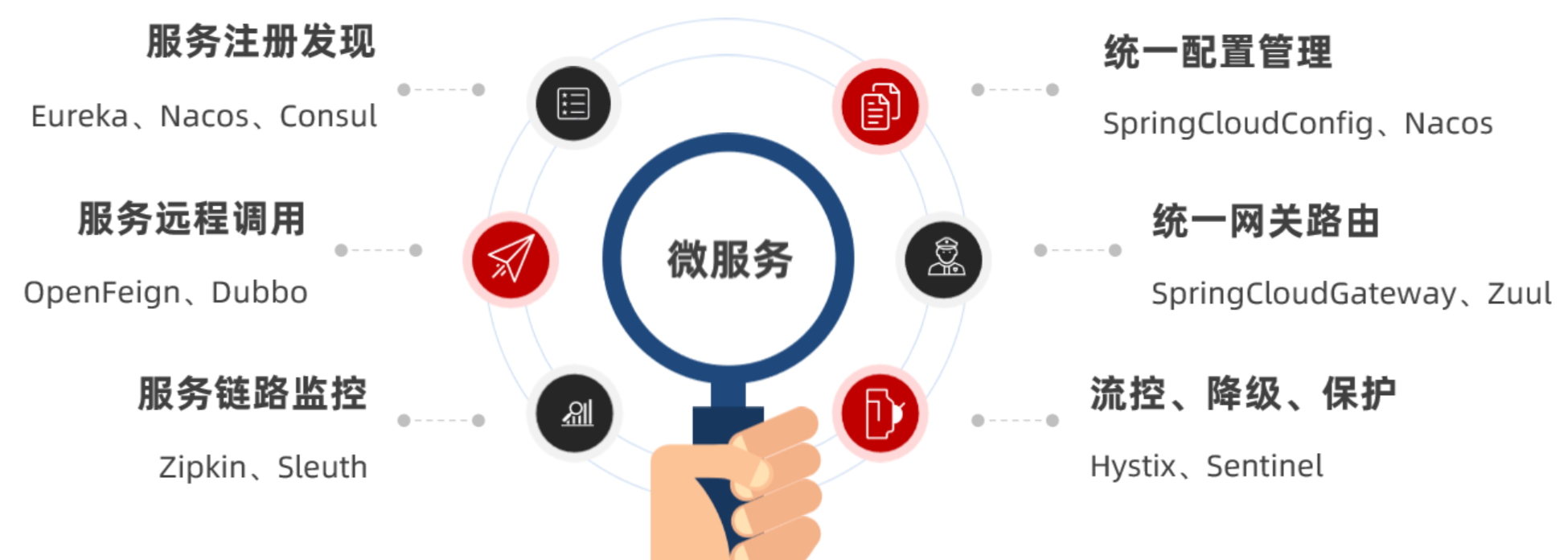
而且SpringCloud依托于SpringBoot的自動裝配能力,大大降低了其項目搭建、組件使用的成本。對于沒有自研微服務組件能力的中小型企業,使用SpringCloud全家桶來實現微服務開發可以說是最合適的選擇了!
SpringCloud官方網址
拆分微服務
拆分原則
服務拆分一定要考慮幾個問題:什么時候拆? 如何拆?
什么時候拆
一般情況下,對于一個初創的項目,首先要做的是驗證項目的可行性。因此這一階段的首要任務是敏捷開發,快速產出生產可用的產品,投入市場做驗證。為了達成這一目的,該階段項目架構往往會比較簡單,很多情況下會直接采用單體架構,這樣開發成本比較低,可以快速產出結果,一旦發現項目不符合市場,損失較小。
如果這一階段采用復雜的微服務架構,投入大量的人力和時間成本用于架構設計,最終發現產品不符合市場需求,等于全部做了無用功。
所以,對于大多數小型項目來說,一般是先采用單體架構,隨著用戶規模擴大、業務復雜后再逐漸拆分為微服務架構。這樣初期成本會比較低,可以快速試錯。但是,這么做的問題就在于后期做服務拆分時,可能會遇到很多代碼耦合帶來的問題,拆分比較困難(前易后難)。
而對于一些大型項目,在立項之初目的就很明確,為了長遠考慮,在架構設計時就直接選擇微服務架構。雖然前期投入較多,但后期就少了拆分服務的煩惱(前難后易)。
怎么拆
之前我們說過,微服務拆分時粒度要小,這其實是拆分的目標。具體可以從兩個角度來分析:
高內聚:每個微服務的職責要盡量單一,包含的業務相互關聯度高、完整度高。低耦合:每個微服務的功能要相對獨立,盡量減少對其它微服務的依賴,或者依賴接口的穩定性要強。
高內聚首先是單一職責,但不能說一個微服務就一個接口,而是要保證微服務內部業務的完整性為前提。目標是當我們要修改某個業務時,最好就只修改當前微服務,這樣變更的成本更低。
一旦微服務做到了高內聚,那么服務之間的耦合度自然就降低了。
當然,微服務之間不可避免的會有或多或少的業務交互,比如下單時需要查詢商品數據。這個時候我們不能在訂單服務直接查詢商品數據庫,否則就導致了數據耦合。而應該由商品服務對應暴露接口,并且一定要保證微服務對外接口的穩定性(即:盡量保證接口外觀不變)。雖然出現了服務間調用,但此時無論你如何在商品服務做內部修改,都不會影響到訂單微服務,服務間的耦合度就降低了。
明確了拆分目標,接下來就是拆分方式了。我們在做服務拆分時一般有兩種方式:縱向拆分 橫向拆分
所謂縱向拆分,就是按照項目的功能模塊來拆分。例如黑馬商城中,就有用戶管理功能、訂單管理功能、購物車功能、商品管理功能、支付功能等。那么按照功能模塊將他們拆分為一個個服務,就屬于縱向拆分。這種拆分模式可以盡可能提高服務的內聚性。
而橫向拆分,是看各個功能模塊之間有沒有公共的業務部分,如果有將其抽取出來作為通用服務。例如用戶登錄是需要發送消息通知,記錄風控數據,下單時也要發送短信,記錄風控數據。因此消息發送、風控數據記錄就是通用的業務功能,因此可以將他們分別抽取為公共服務:消息中心服務、風控管理服務。這樣可以提高業務的復用性,避免重復開發。同時通用業務一般接口穩定性較強,也不會使服務之間過分耦合。
拆分實操
這里我們以商品服務為例子,點擊新建,選擇新建模塊
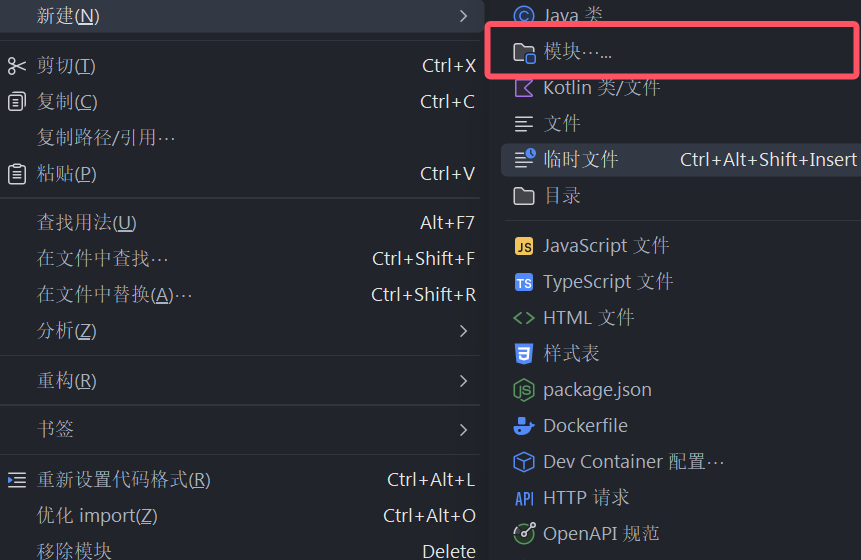
這里我們選擇Java的Maven項目,JDK選擇項目的JDK,父工程選擇項目父工程
引入依賴
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>hmall</artifactId><groupId>com.heima</groupId><version>1.0.0</version></parent><modelVersion>4.0.0</modelVersion><artifactId>item-service</artifactId><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target></properties><dependencies><!--common--><dependency><groupId>com.heima</groupId><artifactId>hm-common</artifactId><version>1.0.0</version></dependency><!--web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--數據庫--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--mybatis--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId></dependency><!--單元測試--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency></dependencies><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
</project>
編寫啟動類
package com.hmall.item;import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@MapperScan("com.hmall.item.mapper")
@SpringBootApplication
public class ItemApplication {public static void main(String[] args) {SpringApplication.run(ItemApplication.class, args);}
}
接下來就是拷貝與商品管理有關的代碼到該微服務項目當中,然后寫配置
server:port: 8081
spring:application:name: item-serviceprofiles:active: devdatasource:url: jdbc:mysql://${hm.db.host}:3306/hm-item?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghaidriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: ${hm.db.pw}
mybatis-plus:configuration:default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandlerglobal-config:db-config:update-strategy: not_nullid-type: auto
logging:level:com.hmall: debugpattern:dateformat: HH:mm:ss:SSSfile:path: "logs/${spring.application.name}"
knife4j:enable: trueopenapi:title: 商品服務接口文檔description: "信息"email: zhanghuyi@itcast.cnconcat: 虎哥url: https://www.itcast.cnversion: v1.0.0group:default:group-name: defaultapi-rule: packageapi-rule-resources:- com.hmall.item.controller
注意在這里所有獲取用戶id的代碼我們需要寫死,后面我們會講到如何獲取。
服務調用
在微服務拆分的時候我們會發現,當一個微服務需要調用另一個微服務里的功能的時候,并不能直接注入Service,最終結果就是查詢到的購物車數據不完整,因此要想解決這個問題,我們就必須改造其中的代碼,把原本本地方法調用,改造成跨微服務的遠程調用(RPC,即Remote Produce Call)。最終就變成了這樣
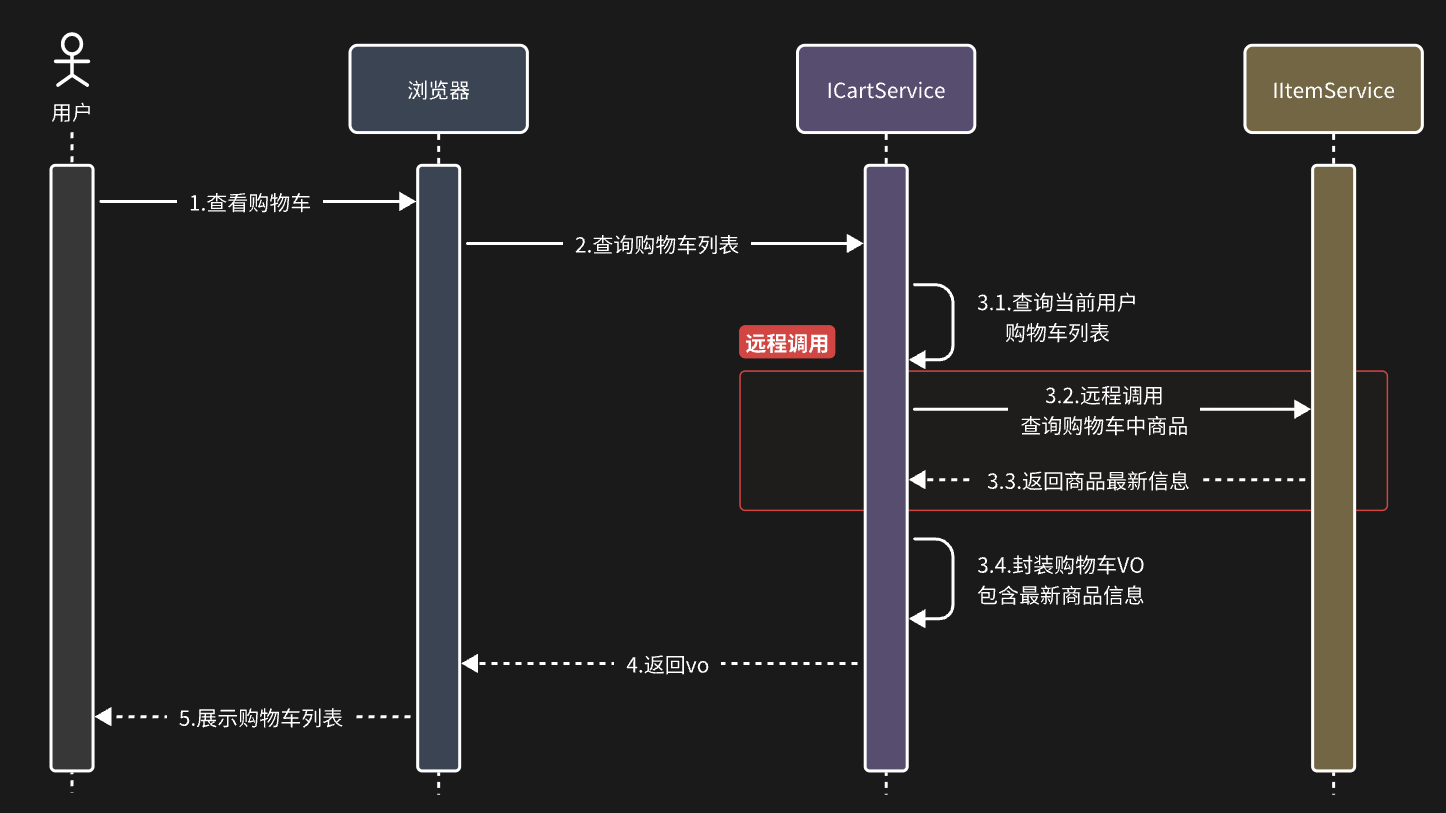
那么問題來了:我們該如何跨服務調用,準確的說,如何在cart-service中獲取item-service服務中的提供的商品數據呢?
大家思考一下,我們以前有沒有實現過類似的遠程查詢的功能呢?
有的兄弟,有的,我們前端向服務端查詢數據,其實就是從瀏覽器遠程查詢服務端數據。比如我們剛才通過Swagger測試商品查詢接口,就是向http://localhost:8081/items這個接口發起的請求:
而這種查詢就是通過http請求的方式來完成的,不僅僅可以實現遠程查詢,還可以實現新增、刪除等各種遠程請求。
假如我們在cart-service中能模擬瀏覽器,發送http請求到item-service,是不是就實現了跨微服務的遠程調用了呢?
那么:我們該如何用Java代碼發送Http的請求呢?
RestTemplate
Spring給我們提供了一個RestTemplate的API,可以方便的實現Http請求的發送。其中提供了大量的方法,方便我們發送http請求。可以看到常見的Get、Post、Put、Delete請求都支持,如果請求參數比較復雜,還可以使用exchange方法來構造請求。

我們先將其注入為一個Bean:
package com.hmall.cart.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;@Configuration
public class RemoteCallConfig {@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}
}
遠程調用
可以看到,利用RestTemplate發送http請求與前端ajax發送請求非常相似,都包含四部分信息:
- ① 請求方式
- ② 請求路徑
- ③ 請求參數
- ④ 返回值類型
ResponseEntity<List<ItemDTO>> response = restTemplate.exchange("http://localhost:8081/items?ids={ids}",HttpMethod.GET,null,new ParameterizedTypeReference<List<ItemDTO>>() {},Map.of("ids", CollUtil.join(itemIds, ","))
);
// 解析響應
if(!response.getStatusCode().is2xxSuccessful()){// 查詢失敗,直接結束return;
}
微服務的注冊與發現
在上一章我們實現了微服務拆分,并且通過Http請求實現了跨微服務的遠程調用。不過這種手動發送Http請求的方式存在一些問題。
試想一下,假如商品微服務被調用較多,為了應對更高的并發,我們進行了多實例部署,如圖:

此時,每個item-service的實例其IP或端口不同,問題來了:
- item-service這么多實例,
cart-service如何知道每一個實例的地址?- http請求要寫url地址,
cart-service服務到底該調用哪個實例呢?- 如果在運行過程中,
某一個item-service實例宕機,cart-service依然在調用該怎么辦?- 如果并發太高,
item-service臨時多部署了N臺實例,cart-service如何知道新實例的地址?
為了解決上面的問題,就必須引入注冊中心的概念了
注冊中心
在微服務遠程調用的過程中,包括兩個角色:
服務提供者:提供接口供其它微服務訪問,比如item-service服務消費者:調用其它微服務提供的接口,比如cart-service
在大型微服務項目中,服務提供者的數量會非常多,為了管理這些服務就引入了注冊中心的概念。注冊中心、服務提供者、服務消費者三者間關系如下:

流程如下
- 服務啟動時就會注冊自己的服務信息(服務名、IP、端口)到注冊中心
- 調用者可以從注冊中心訂閱想要的服務,獲取服務對應的實例列表(1個服務可能多實例部署)
- 調用者自己對實例列表負載均衡,挑選一個實例
- 調用者向該實例發起遠程調用
那么當提供服務的宕機或者開啟了新的服務了,服務調用者該怎么知道呢
心跳機制:服務提供者會定期向注冊中心發送請求,報告自己的健康狀態,當注冊中心長時間收不到提供者的心跳時,會認為該實例宕機,將其從服務的實例列表中剔除- 當服務有
新實例啟動時,會發送注冊服務請求,其信息會被記錄在注冊中心的服務實例列表- 當注冊中心
服務列表變更時,會主動通知微服務,更新本地服務列表
Nacos注冊中心
注冊中心框架很多,目前國內流行的有三個
Eureka:Netflix公司出品,目前被集成在SpringCloud當中,一般用于Java應用Nacos:Alibaba公司出品,目前被集成在SpringCloudAlibaba中,一般用于Java應用Consul:HashiCorp公司出品,目前集成在SpringCloud中,不限制微服務語言
以上幾種注冊中心都遵循SpringCloud中的API規范,因此在業務開發使用上沒有太大差異。但是Nacos是阿里巴巴公司開源的,有中文API,方便我們使用。
Nacos官網
我們部署Nacos是基于Docker進行的,所以先要準備Nacos的相關表,然后我們需要修改Nacos的配置文件,在運行的時候根據官方配置掛載指定目錄
docker run -d \
--name nacos \
--env-file ./nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
nacos/nacos-server:v2.1.0-slim
如果mysql和nacos在同一個網段下,這里直接寫mysql的容器名字就可以,啟動完成之后我們訪問網址
http://虛擬機IP:8848/nacos/,賬號密碼都是nacos
服務注冊
引入依賴
<!--nacos 服務注冊發現-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
配置nacos
spring:application:name: item-service # 服務名稱cloud:nacos:server-addr: 虛擬機IP:8848 # nacos地址
在Nacos注冊的時候,就會根據微服務的名字來注冊,所以每個微服務的名字要唯一不重復
啟動項目之后,我們在網站上可以看到該服務已經被注冊
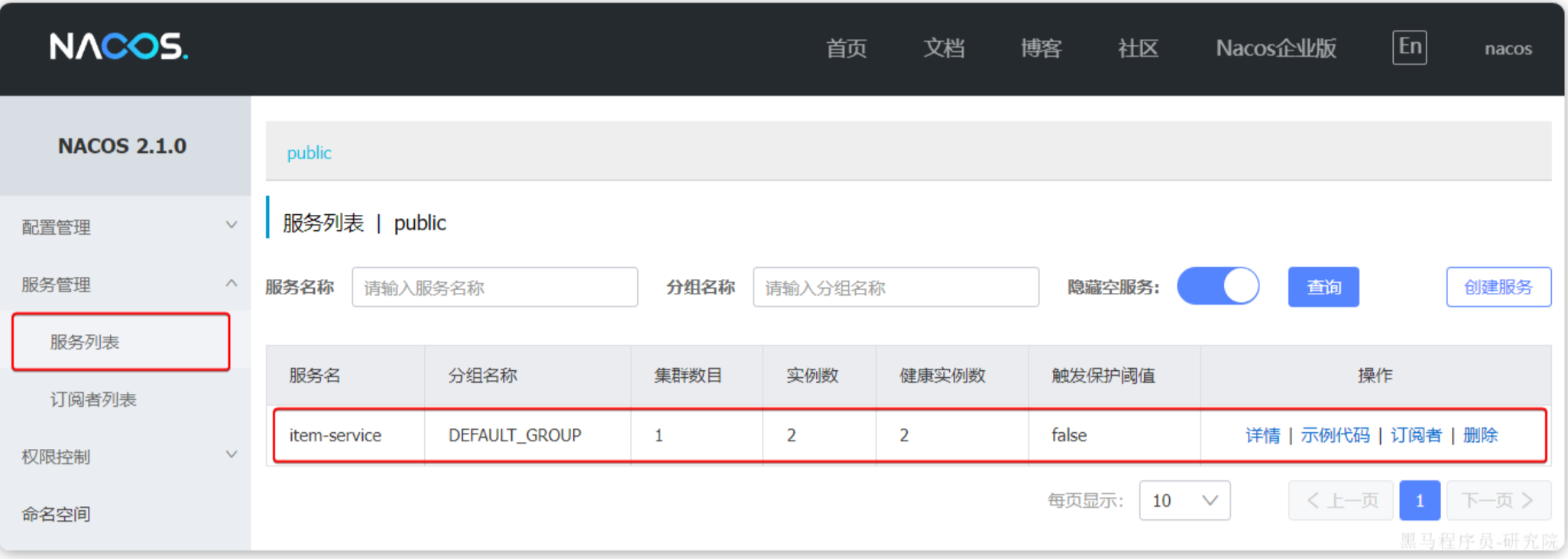
服務發現
服務調用者想要調用其他微服務就要,引入依賴 配置Nacos地址 發現并調用服務 走這三步
引入依賴
服務發現除了要引入nacos依賴以外,由于還需要負載均衡,因此要引入SpringCloud提供的LoadBalancer依賴。
<!--nacos 服務注冊發現-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
可以發現,這里Nacos的依賴于服務注冊時一致,這個依賴中同時包含了服務注冊和發現的功能。因為任何一個微服務都可以調用別人,也可以被別人調用,即可以是調用者,也可以是提供者。
因此,等一會兒cart-service啟動,同樣會注冊到Nacos
配置Nacos
spring:cloud:nacos:server-addr: IP:8848
發現并調用服務
接下來,服務調用者cart-service就可以去訂閱item-service服務了。不過item-service有多個實例,而真正發起調用時只需要知道一個實例的地址。
因此,服務調用者必須利用負載均衡的算法,從多個實例中挑選一個去訪問。常見的負載均衡算法有:
- 隨機
- 輪詢
- IP的hash
- 最近最少訪問
- …
這里我們可以選擇最簡單的隨機負載均衡。
服務的發現需要一個工具,
DiscoveryClient,SpringCloud已經幫我們自動裝配,我們可以直接注入使用
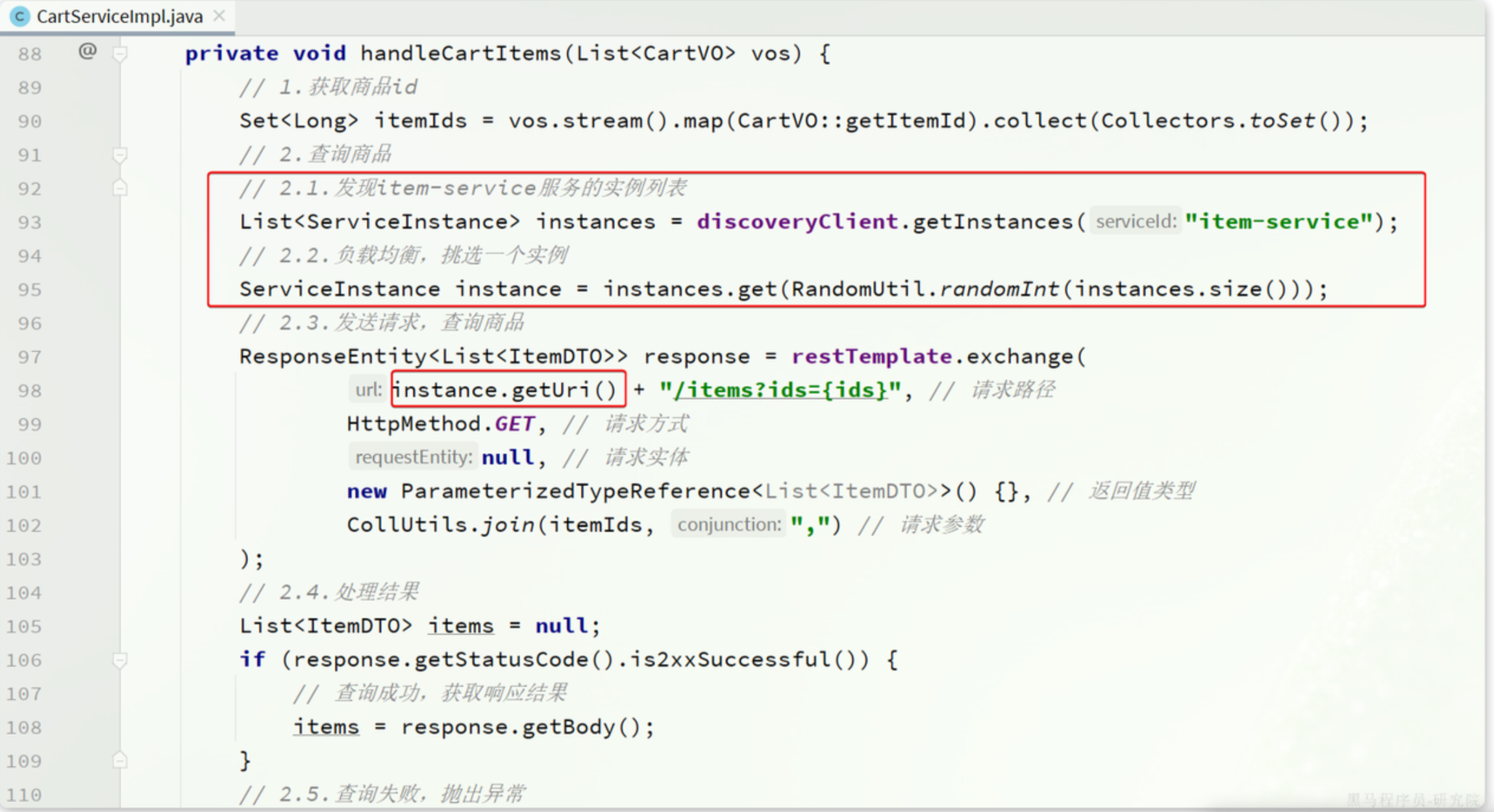
我們先通過這個工具,獲取到所有命名為item-service的實例集合,然后隨機獲取一個,獲取它的URI,然后調用。
OpenFegin
在上一章,我們利用Nacos實現了服務的治理,利用RestTemplate實現了服務的遠程調用。但是遠程調用的代碼太復雜了,而且這種調用方式,與原本的本地方法調用差異太大,編程時的體驗也不統一,一會兒遠程調用,一會兒本地調用。
因此,我們必須想辦法改變遠程調用的開發模式,讓遠程調用像本地方法調用一樣簡單。而這就要用到OpenFeign組件了。
快速入門
引入依賴
<!--openFeign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!--負載均衡器--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency>
啟用OpenFeign
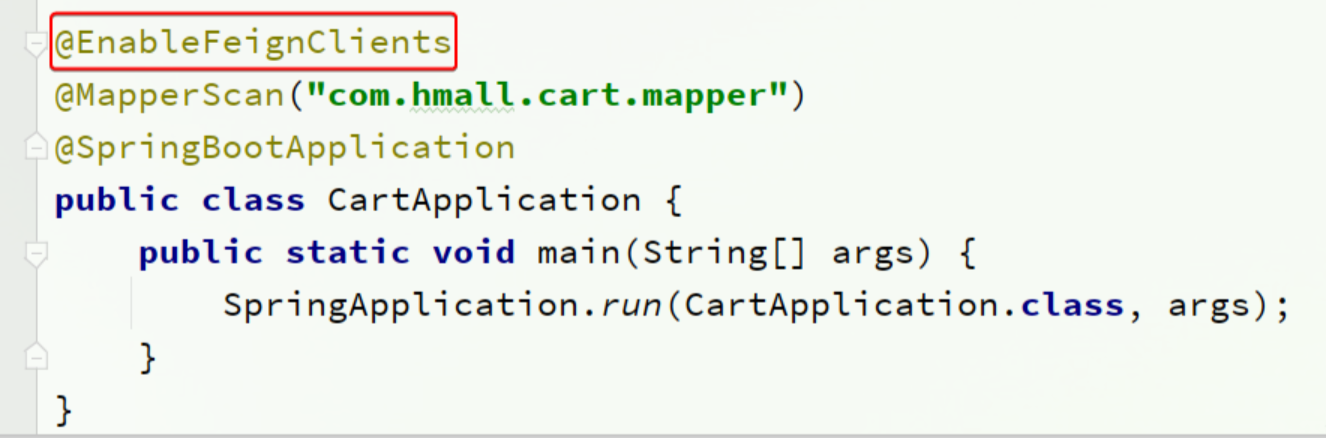
編寫OpenFeign客戶端
package com.hmall.cart.client;import com.hmall.cart.domain.dto.ItemDTO;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;import java.util.List;@FeignClient("item-service")
public interface ItemClient {@GetMapping("/items")List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}
這里只需要聲明接口,無需實現方法。接口中的幾個關鍵信息:
@FeignClient("item-service"):聲明服務名稱@GetMapping:聲明請求方式@GetMapping("/items"):聲明請求路徑@RequestParam("ids") Collection<Long> ids:聲明請求參數List<ItemDTO>:返回值類型
有了上述信息,OpenFeign就可以利用動態代理幫我們實現這個方法,并且向http://item-service/items發送一個GET請求,攜帶ids為請求參數,并自動將返回值處理為List。
我們只需要直接調用這個方法,即可實現遠程調用了。
使用FeignClient
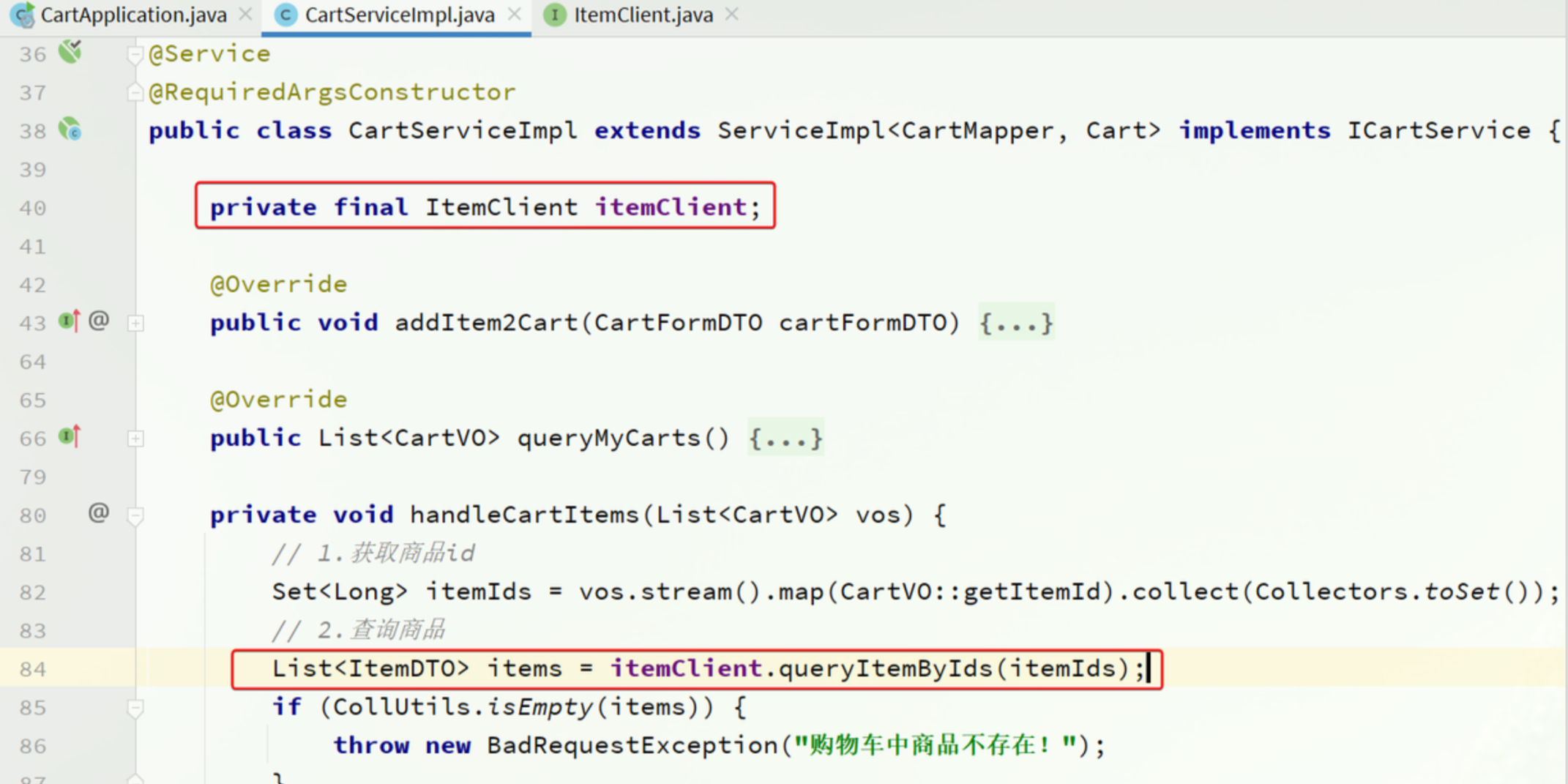
先注入,后使用
連接池
Feign底層發起http請求,依賴于其它的框架。其底層支持的http客戶端實現包括:
HttpURLConnection:默認實現,不支持連接池Apache HttpClient:支持連接池OKHttp:支持連接池
引入依賴
<!--OK http 的依賴 -->
<dependency><groupId>io.github.openfeign</groupId><artifactId>feign-okhttp</artifactId>
</dependency>
配置開啟連接池
feign:okhttp:enabled: true # 開啟OKHttp功能
抽取Feign客戶端
我們在里微服務調同一個接口的時候,如果沒有抽取出來,那么每個微服務是不是都需要重新編寫一下,那么有什么辦法能解決這種重復編碼的問題嗎
這里有兩種解決辦法
- 思路1:抽取到微服務之外的公共module
- 思路2:每個微服務自己抽取一個module

方案1抽取更加簡單,工程結構也比較清晰,但缺點是整個項目耦合度偏高。
方案2抽取相對麻煩,工程結構相對更復雜,但服務之間耦合度降低。
實戰
這里我們選擇方案1,只需要再創建一個模塊,名為hm-all引入需要的依賴,在里面編寫接口就可以。但是這里我們需要注意一個包掃描的問題,我們每個微服務都在獨立的包中,包括這個API模塊也在獨立的保重,boot項目默認掃描的是當前包及其子包 。這里我們有兩種解決方案。
- 第一種是生命掃描包

- 第二種是聲明要用的FeignClient,這里面是一個數組,可以聲明多個

_python版本)
)

![[Vue]App.vue講解](http://pic.xiahunao.cn/[Vue]App.vue講解)

)



)








的簡單程序)
