0.人工智能概述:
(1)必備三要素:
- 數據
- 算法
- 計算力
- CPU、GPU、TPU
- GPU和CPU對比:
- GPU主要適合計算密集型任務;
- CPU主要適合I/O密集型任務;
【筆試問題】什么類型程序適合在GPU上運行?——面試題<1>
(2)人工智能、機器學習、深度學習區別?

- 機器學習是人工智能的一個實現階段;
- 深度學習是機器學習的一個方法發展而來(神經網絡);
(3)起源:
- 圖靈測試:
- 機器與人隔開情況下,人提問機器回答測試5min,測試完成后讓人回答:在你對面的是人還是機器?若30%的人無法判斷,這個機器就通過了測試。該測試提出者:艾倫.麥席森.圖靈。
- 達特茅斯會議:
- 1956年8月,提出機器模仿人類學習,無實質東西,會議長達2個月,1956年是人工智能元年。
(4)發展經歷:

- 起步
- 反思
- 應用
- 低迷
- 穩步
- 蓬勃
(5)分支:
- 計算機視覺(CV)
指機器感知環境能力,這一技術類別中經典任務有圖像形成、圖像處理、圖像提取和圖像的三位推理。物體檢測和人臉識別是其比較成功的研究領域。
- 自然語言處理(NLP)
- 覆蓋文本挖掘/分類、機器翻譯和語音識別。
語言識別:指識別語言(說出語言)并將其轉換成文本的技術。仍面臨聲紋識別和[雞尾酒會效應]等一些特殊情況的難題。語言識別驗證依賴于云平臺,離線處理可能無法取得利息的工作原理。
文本挖掘和分類:對文字進行情緒分析、對里面垃圾信息檢測。面臨:可能出現歧義。
機器翻譯:將A語言翻譯B語言。面臨:方言、行話表現不好。
- 機器人
固定機器人:工業應用;
移動機器人:工業和家庭應用。
一.機器學習介紹
1.步驟:
- 獲取數據
- 數據基本處理(科學計算庫)
- Matplotlib
- Pandas
- Numpy
- 特征工程
- 機器學習算法
- 模型評估與調優
2.概述:
(1)定義:
機器學習是從數據中自動分析獲得模型,并利用模型對未知數據進行預測。

(2)工作流程:

機器學習工作流程總結:
- 獲取數據
- 數據基本處理
- 特征工程
- 機器學習(模型訓練)
- 模型評估
- 結果達到要求,上線任務
- 沒有達到要求,重新上面步驟
3.工作流程詳述:
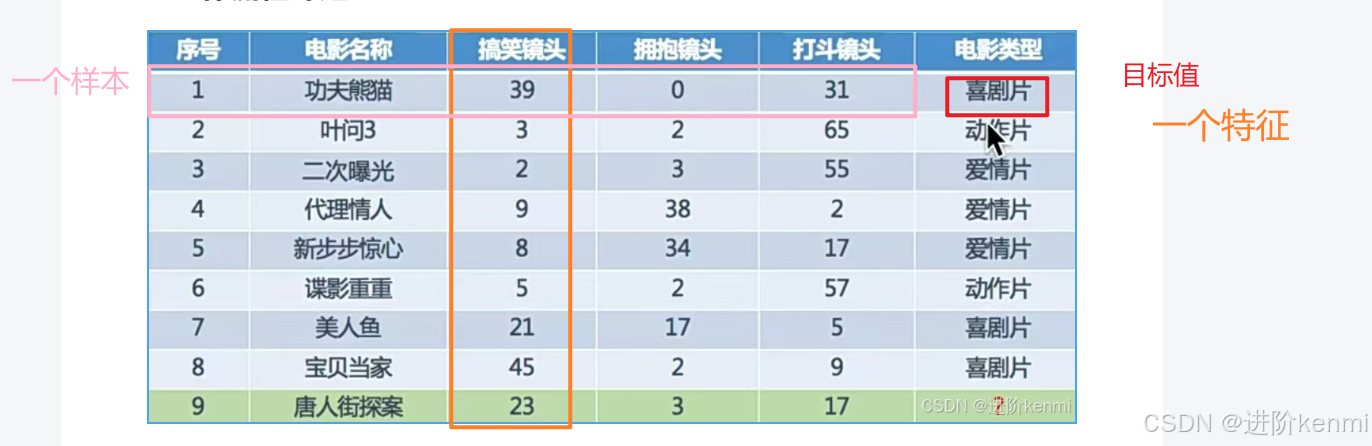
(1)獲取數據:
- 在數據集中一般:
- 一行數據是一個樣本;
- 一列數據是一個特征;
- 有些數據有目標值(標簽值),有些數據沒有目標值(如上表中,電影類型就是這個數據集中的目標值)
- 數據類型構成:
- 數據類型一:特征值+目標值(目標值是連續的和離散的)
- 數據類型二:只有特征值,沒有目標值(典型算法:聚類算法)。
- 數據分割:
- 機器學習一般數據集劃分為兩個部分:
- 訓練數據:用于訓練,構建模型;
- 測試數據:在模型檢驗時使用,用于評估模型是否有效。
- 劃分比例:
- 訓練集:70% 80% 75%
- 測試集:30% 20% 25%
- 機器學習一般數據集劃分為兩個部分:
(2)數據基本處理:
即對數據進行缺失值,去除異常值等處理。
(3)特征工程:
- 定義:特征工程是使用專業背景知識和技巧處理數據,使得特征能在機器學習算法上發揮更好的作用的過程。
- 為什么需要?
- 數據和特征決定機器學習上限,而模型和算法只是逼近這個上限而已。
- 包含內容:
- 特征提取
- 將任意數據(如文本或圖像)轉換為可用于機器學習的特征工程;
- 特征預處理
- 通過一些轉換函數將特征數據轉換成更加適合算法模型的特征數據過程;
- 特征降維
- 指在某些特定條件下,降低隨機變量(特征)個數,得到一組“不相關”主變量的過程;?
- 特征提取
(4)機器學習(模型訓練):
選擇合適算法對模型進行訓練。
(5)模型評估:
對訓練好模型進行評估。
二.機器學習算法分類:
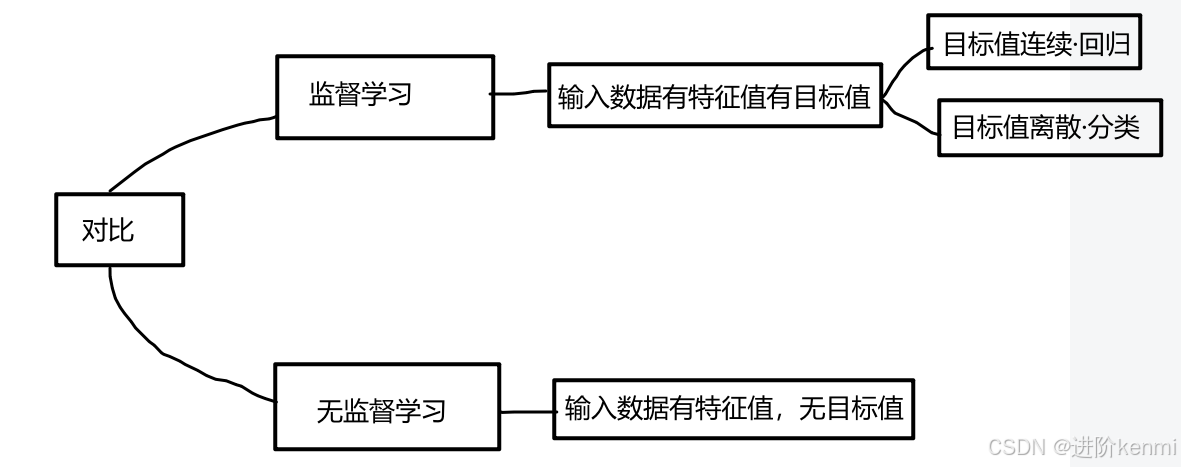
1.監督學習:
1.1.定義:
- 輸入數據是由輸入特征值和目標值所組成;
- 函數的輸出可以是一個連續的值(稱為回歸);
- 或是輸出有限個離散值(稱為分類);
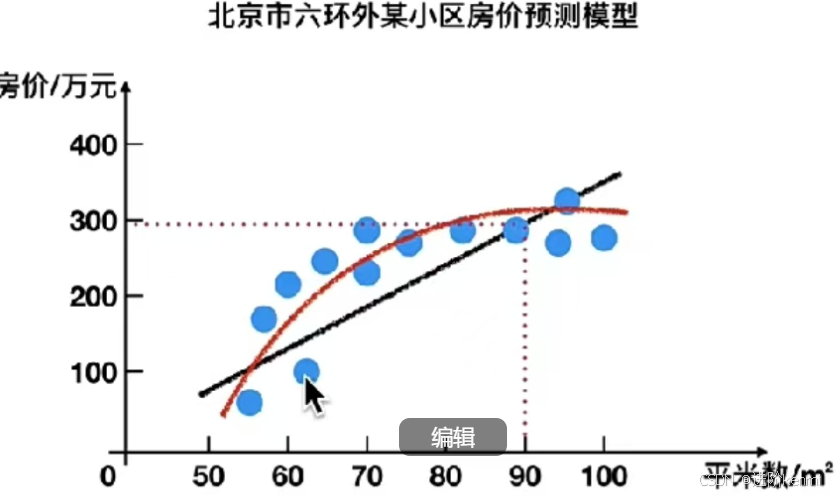
(1)回歸問題:
例如:預測房價,根據樣本集:擬合出一條連續曲線。

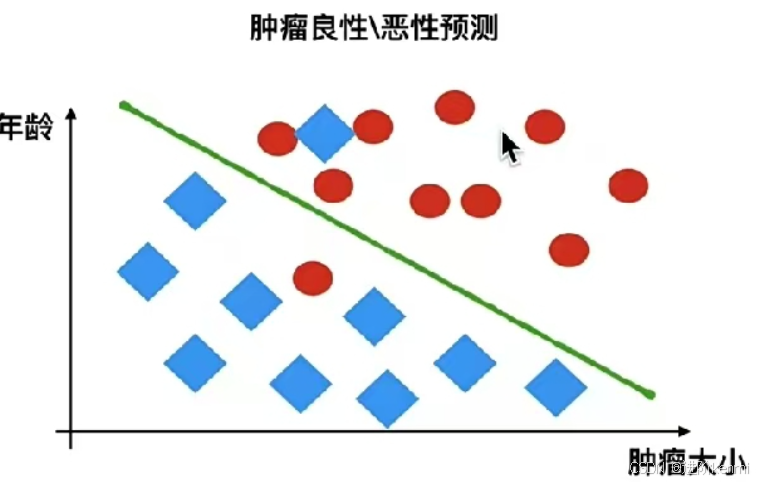
(2)分類問題:
例如:根據腫瘤特征判斷良性還是惡性,得到結果是“良性”或者“惡性”,是離散的。

2.無監督學習:
2.1.定義:
- 輸入數據是由輸入特征值組成,沒有目標值;
- 輸入數據沒有被標記,也沒有確定的結果。樣本數據類別未知;
- 需要根據樣本間的相似性對樣本集進行類別劃分。
- 例:

【無監督與有監督對比】:
3.半監督學習:
3.1.定義:
- 訓練集同時包含有標記樣本數據和未標記樣本數據;
- 例:

監督:從數據庫中得到未標記數據,讓專家預測,得到大量標記過數據,通過標記過數據訓練預測模型;
半監督:從數據庫中得到少部分未標記數據,讓專家預測,得到少量標記過數據,通過少量數據訓練初步模型,再用未標記的數據進行模型得出(優化)。
總之:半監督是通過少量標記數據訓練初步模型,再利用大量未標記數據進行模型優化。
4.強化學習:
4.1.定義:
- 實質是make decisions問題,即自動進行決策,并且可以做到連續決策。
- 例:小孩走路,首先站起來,保持平衡,接下來先邁出左腿還是右腿,邁出一步再邁出一步。
小孩就是agent,他試圖通過采取行動來操縱環境,并且從一個狀態轉變到另一個狀態,當他完成任務的子任務時,孩子得到獎勵;并且當他不能走路時就不會給獎勵。
主要包含五個元素: agent ,action, reward,environment, observation

【強化與監督對比】
| 監督學習 | 強化學習 | |
| 反饋映射 | 輸出的是之間的關系,可以告訴算法什么樣的輸入對應著什么樣的輸出 | 輸出的是給機器反饋reward function,即用來判斷這個行為是好是壞 |
| 反饋時間 | 做了比較壞的選擇會立刻反饋給算法 | 結果反饋有延遲,有時候可能需要走了很多步以后才知道以前的某一步的選擇是好還是壞 |
| 輸入特征 | 輸入是獨立同分布的 | 面對的輸入總是在變化,每當算法做出一個行為,它影響下一次決策的輸入 |
【拓展概念】什么是獨立同分布?
概念:西瓜書中解釋:輸入空間中的所有樣本服從一個隱含未知的分布,訓練數據所有樣本都是獨立的從這個分布上采樣而得。
- 獨立:每次抽樣之間沒有關系,不會相互影響;
- 舉例:給一個骰子,每次拋骰子拋到幾就是幾,這是獨立;如果我要骰子兩次之和大于8,那么第一次和和第二次拋就不獨立,因為第二次拋的結果和第一次相關;
- 同分布:每次抽樣,樣本服從同一個分布
- 舉例:給一個骰子,每次拋骰子得到任意點數的概率都是1/6,這個就是同分布;
- 獨立同分布:i.i.d.,每次抽樣之間獨立而且同分步。
5.小結:
| in | out | 目的 | 案例 | |
| 監督(supervised learning) | 有標簽 | 有反饋 | 預測結果 | 貓狗分類、房價預測 |
| 無監督(unsupervised learning) | 無標簽 | 無反饋 | 發現潛在結構 | “物以類聚人以群分” |
| 半監督(Semi-Supervised learning) | 部分有標簽,部分無標簽 | 有反饋 | 降低數據標記難度 | |
| 強化(reinforcement learning) | 決策流程及激勵系統 | 一系列行動 | 長期利益最大化 | 學下棋 |

三.模型評估:
1.分類模型評估:
- 準確率:
- 預測正確的數站樣本總數的比例;
- 其他評價指標:精確率、召回率、F1-score、AUC指標等。
2.回歸模型評估:
- 均方根誤差( Root Mean Squared Error,RMSE)
- RMSE是一個衡量回歸模型誤差率的常用公式。不過,它僅能比較誤差是相同單位的模型。
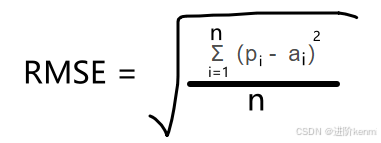
?a = actual target真實值
p = predicted target預測值
- 例:

- RSE:(預測值 - 真實值 )的平方和 /(真實值的均值 - 真實值的平方和)
- MAE:(預測值 - 真實值)的絕對值的和 / 樣本數量
- RAE:(預測值 - 真實值的絕對值和)/ (真實值的均值 減 真實值的絕對值的和)
3.擬合:
模型評估用于評價訓練好的模型的表現效果,其效果大致分為:過擬合、欠擬合。
在訓練過程中,可能會遇到:
訓練數據訓練的很好,誤差不大,為什么在測試集上有問題,出現這種情況就是擬合問題。
3.1.欠擬合(under-fitting):
- 模型學習太過粗糙,連訓練集中的樣本數據特征關系都沒有學出來。
- 訓練集與測試集中表現不好;

3.2.過擬合(over-fitting):
- 所建成的機器學習模型或者深度學習模型在訓練樣本中表現的過于優越,導致在測試數據集中表現不佳。
- 訓練集表現比較好,測試集中表現不好;

四.深度學習簡介:
1.概念:
- 深度學習(deep learning)(也稱為速度結構學習【deep structure learning】、層次學習【Hierarchical learning】或者深度機器學習【deep machine learning】)是一類算法集合、是機器學習的一個分支。
- 深度學習近些年來,在會話識別、圖像識別和對象偵測等領域出現出來驚人的準確性。
- 但是,“深度學習”在1986年有Dechter在機器虛席領域提出,然后在2000年有Aizenberg等人引入到人工神經網絡中。而現在,由于Alex Krizhevsky在2012年使用卷積網絡結構贏得了ImageNet比賽后受到大家矚目。
- 卷積網絡之父:Yann LeCun

2.各層負責內容:
- 1層負責識別顏色及簡單紋理;
- 2層一些神經元可以識別更加細化的紋理,布紋、刻紋、葉紋等;
- 3層一些神經元負責感受黑夜里的黃色燭光,高光,螢火,雞蛋黃色等;
- 4層一些神經元識別萌狗的臉,寵物形貌,圓柱體事物,七星瓢蟲等存在;
- 5層一些神經元負責識別花,黑眼圈動物,鳥,鍵盤,原型屋頂等;

五.Jupyter Notebook
1.定義:
Jupyter 項目是一個非盈利的開源項目,源于2014年的ipython項目,因為它逐漸發展為支持夸所有編程語言的交互數據科學和數據計算。
- Jupyter Notebook,原名IPython Notebook,是IPython的加強網頁版,一個開源Web應用程序;
- 名字源自Julia、Python和R(數據科學的三種開源語言)
- 是一款程序員和科學工作者的編程/文檔/筆記/展示軟件;
- .ipynb文件格式使用于計算型敘述的JSON文檔格式的正式規范;
2.為什么使用:
- 傳統軟件開發:工程/目標明確
- 需求分析:設計框架,開發模版,測試
- 數據挖掘:藝術/目標不明確
- 目的是具體的洞察目標,而不是機械的完成任務;
- 通過執行代碼來解決問題;
- 迭代式改進代碼來解決方法;
實時運行代碼、敘事性的文本和可視化被整合在一起,方便使用代碼和數據來敘述故事。
)








的簡單程序)









