目錄
1.Pytorch--安裝
2.Pytorch--張量
3.Pytorch--定義
4.Pytorch--運算
4.1.Tensor數據類型
4.2.Tensor創建
4.3.Tensor運算
4.4.Tensor--Numpy轉換
4.5.Tensor--CUDA(GPU)
5.Pytorch--自動微分 (autograd)
5.1.backward求導
5.1.1.標量Tensor求導
5.1.2.非標量Tensor求導
5.2.autograd.grad求導
5.3.求最小值
1.Pytorch--安裝
配置環境經常是讓各位同學頭痛不已又不得不經歷的過程,那么本小節就給大家提供一篇手把手安裝PyTorch的教程。
首先,進入pytorch官網,點上方get started進入下載
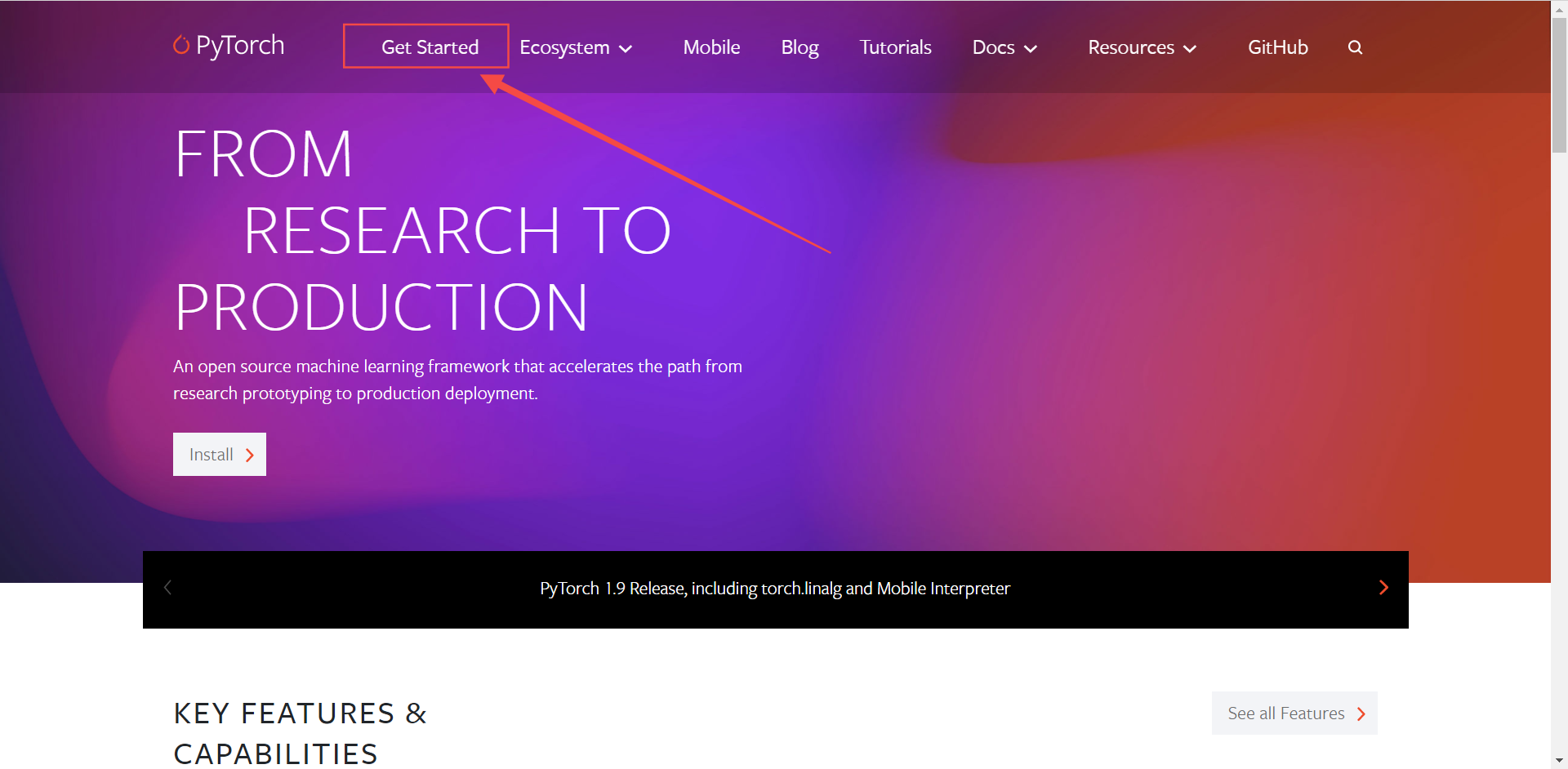
根據你的操作系統選擇對應的版本,安裝方式,CUDA版本等等。

這里作者的設備是window10,python3.8的運行環境,由于設備是AMD顯卡不支持CUDA因此選擇了CPU版本,后面關于CUDA是什么、有什么用我們會單獨出一期教程講解。
如果已經下載了anaconda 可以使用conda安裝,沒有下載就使用Pip安裝,然后打開cmd將生成的命令語句復制到cmd上。
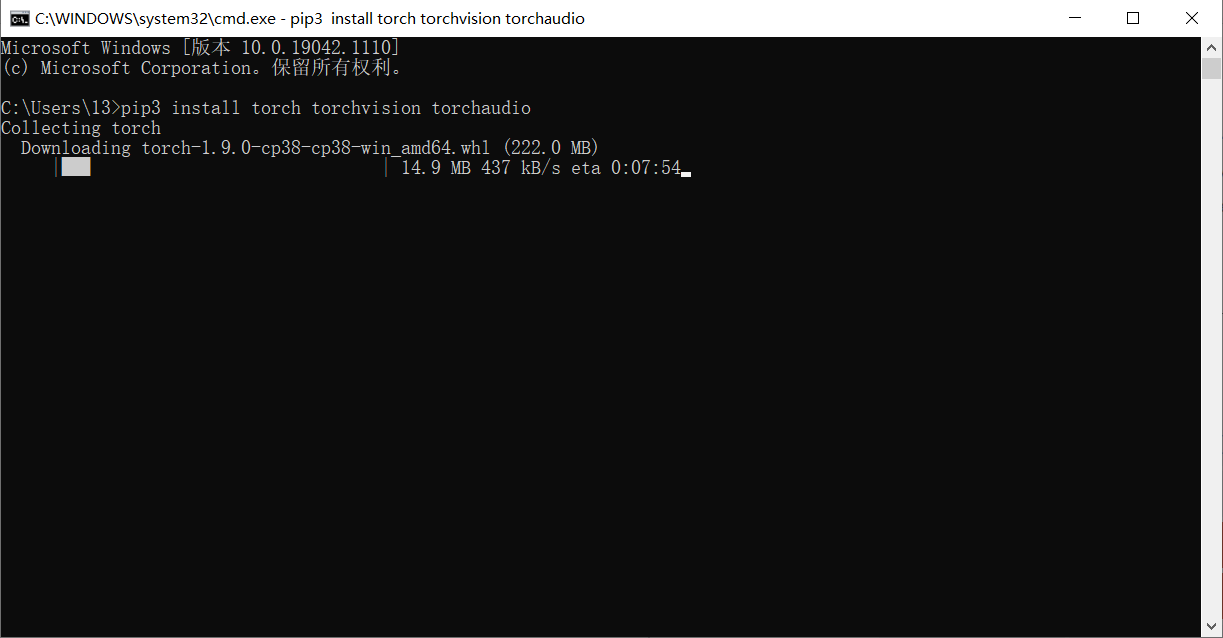
這里直接用 pip install 下載會比較慢,這邊我們可以將源換掉,個人比較推薦阿里源和清華源
1pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/假如喜歡其他源的也可以換成其他源,將指令的網址換一下就好了
阿里云?Simple Index
中國科技大學?Verifying - USTC Mirrors
豆瓣(douban)?http://pypi.douban.com/simple/
清華大學?Simple Index
中國科學技術大學?Verifying - USTC Mirrors
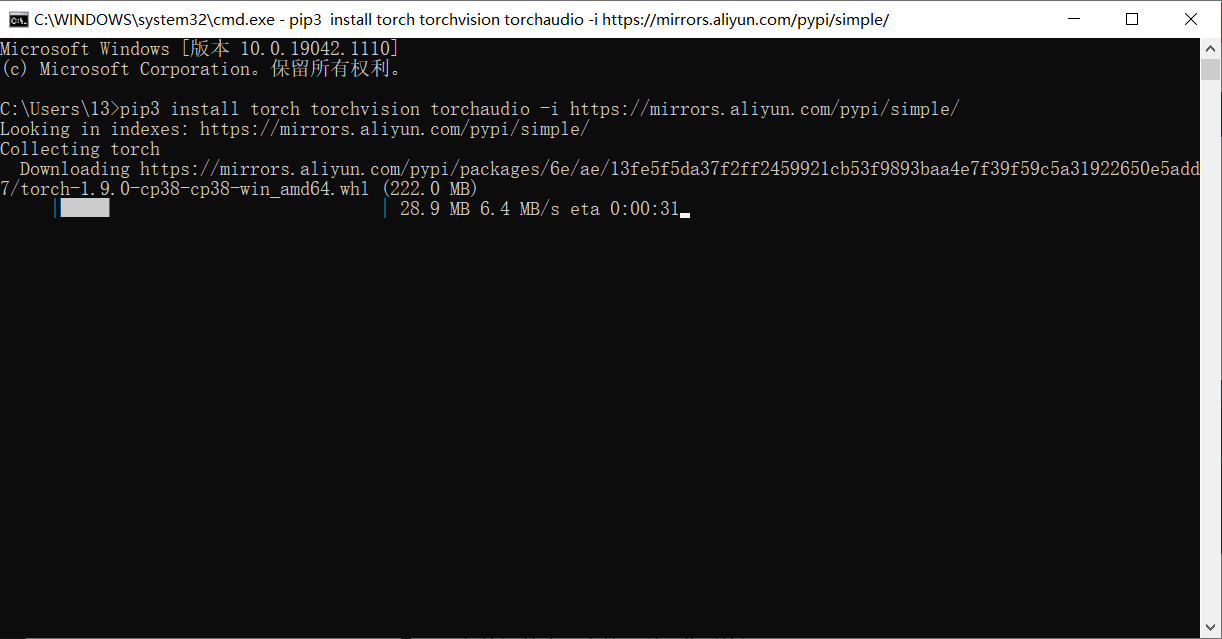
這里用了?-i?臨時換源的方法,只對這次安裝有效,如果你想一勞永逸的話請使用上面提到的換源方法。
![]()
出現這樣的字段說明安裝成功了
測試一下:
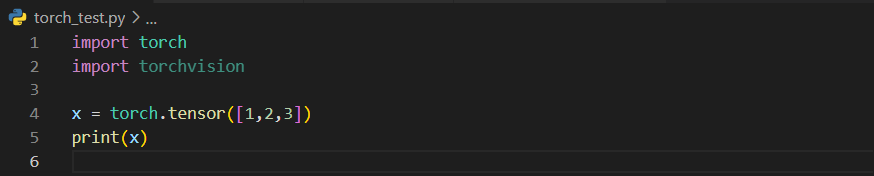
沒有報錯可以正常輸出。
當時我們上面的操作是直接安裝到真實環境中,我們更推薦你使用anaconda創建一個獨立的環境
虛擬環境的創建,使用命令行:
1conda create -n pytorch(虛擬環境名) python=3.6激活環境:
1activate pytorch也可以使用pycharm創建:
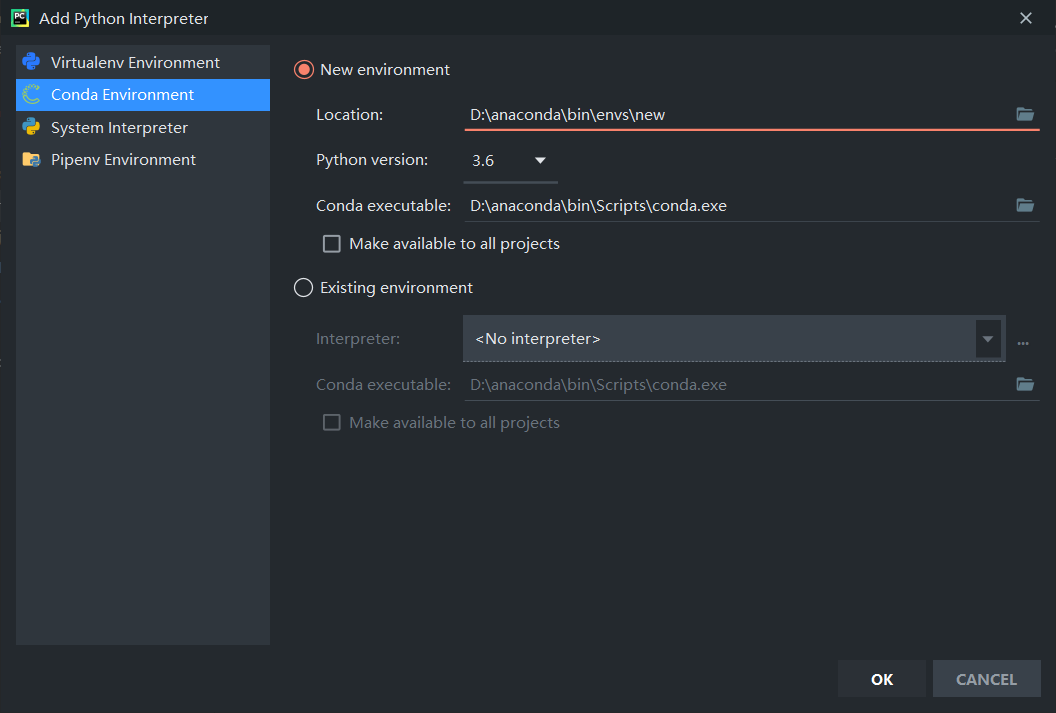
在這里選擇環境名稱和python版本。雖然虛擬環境很方便,但是對于有多個版本python的用戶來說安裝包的時候一定要在相應的python版本下的script的目錄下進行pip,盡量使用pycharm安裝,除非找不到或者安裝很慢。因為一不小心容易把環境搞崩。
使用對應命令完成安裝


2.Pytorch--張量
????????無論是 Tensorflow 還是我們接下來要介紹的 PyTorch 都是以**張量(tensor)**為基本單位進行計算的學習框架,第一次聽說張量這個詞的同學可能都或多或少困惑這究竟是個什么東西,那么在正式開始學習 PyTorch 之前我們還是花些時間簡單介紹一下張量的概念。
????????學過線性代數的童鞋都知道,矩陣可以進行各種運算,比如:
- 矩陣的加法:

- 矩陣的轉置:
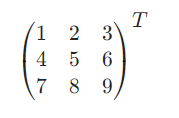
- ?矩陣的點乘:

????????為了方便存儲矩陣及進行矩陣之間的運算,大神們抽象出了 PyTorch 庫,PyTorch 庫中有一個類叫torch.Tensor,這個類存儲了一個矩陣變量,并且有一系列方法用于對這個矩陣進行各種運算。上面的這些矩陣運算都可以通過 torch.Tensor 類的相應方法實現。
比如上面的矩陣加法:
import torch # 引入torch類
x = torch.rand(5, 3) # 生成一個5*3的矩陣x,矩陣的每個元素都是0到1之間的隨機數,x的類型就是torch.Tensor,x里面存了一個5*3的矩陣
y = torch.zeros(5, 3, dtype=torch.float) # 生成一個5*3的矩陣y,矩陣的每個元素都是0,每個元素的類型是long型,y的類型就是torch.Tensor,y里面存了一個5*3的矩陣
y.add_(x) # 使用y的add_方法對y和x進行運算,運算結果保存到y?上面的x、y的類型都是 torch.Tensor,Tensor 這個單詞一般可譯作“張量”。但是上面我們進行的都是矩陣運算,為什么要給這個類型起名字叫張量呢,直接叫矩陣不就行了嗎?張量又是什么意思呢?
這是因為:通常我們不但要對矩陣進行運算,我們還會對數組進行運算(當然數組也是特殊的矩陣),比如兩個數組的加法:
?但是在機器學習中我們更多的是會對下面這種形狀進行運算:
????????大家可以把這種數看作幾個矩陣疊在一起,這種我們暫且給它取一個名字叫“空間矩陣”或者“三維矩陣”。 因此用**“矩陣”不能表達所有我們想要進行運算的變量**,所以,我們使用張量把矩陣的概念進行擴展。這樣普通的矩陣就是二維張量,數組就是一維張量,上面這種空間矩陣就是三維張量,類似的,還有四維、五維、六維張量

那么上面這種三維張量怎么表達呢?
一維張量[1,2,3],:
torch.tensor([1,2,3])?二維張量: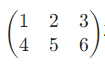 :
:
torch.tensor([[1,2,3],[4,5,6]])聰明的同學可能發現了,多一個維度,我們就多加一個 []。
所以為什么叫張量而不是矩陣呢?就是因為我們通常需要處理的數據有零維的(單純的一個數字)、一維的(數組)、二維的(矩陣)、三維的(空間矩陣)、還有很多維的。PyTorch 為了把這些各種維統一起來,所以起名叫張量。
張量可以看作是一個多維數組。標量可以看作是0維張量,向量可以看作1維張量,矩陣可以看作是二維張量。比如我們之前學過的 NumPy,你會發現 tensor 和 NumPy 的多維數組非常類似。
創建 tensor:
x = torch.empty(5, 3)
x = torch.rand(5, 3)
x = torch.zeros(5, 3, dtype=torch.long)
x = torch.tensor([5.5, 3])
x = x.new_ones(5, 3, dtype=torch.float64)
y = torch.randn_like(x, dtype=torch.float)獲取 tensor 的形狀:
print(x.size())
print(x.shape)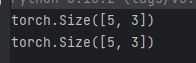 ?
?
tensor 的各種操作:
y = torch.rand(5, 3)
print(x + y) # 加法形式一
print(torch.add(x, y)) # 加法形式二
# adds x to y
y.add_(x) # 加法形式三
print(y)PyTorch 中的 tensor 支持超過一百種操作,包括轉置、索引、切片、數學運算、線性代數、隨機數等等,總之,凡是你能想到的操作,在 PyTorch 里都有對應的方法去完成。
3.Pytorch--定義
PyTorch 是一個基于 python 的科學計算包,主要針對兩類人群:
- 作為 NumPy 的替代品,可以利用 GPU 的性能進行計算
- 作為一個高靈活性,速度快的深度學習平臺
張量 Tensors
Tensor(張量),類似于 NumPy 的?ndarray?,但不同的是 Numpy 不能利用GPU加速數值計算,對于現代的深層神經網絡,GPU通常提供更高的加速,而 Numpy 不足以進行現代深層學習。
而 Tensor 可以利用gpu加速數值計算,要在gpu上運行pytorch張量,在構造張量時使用device參數將張量放置在gpu上。
4.Pytorch--運算
4.1.Tensor數據類型
Tensor張量是Pytorch里最基本的數據結構。直觀上來講,它是一個多維矩陣,支持GPU加速,其基本數據類型如下
| ??數據類型?? | ??CPU Tensor?? | ??GPU Tensor?? |
|---|---|---|
| 8位無符號整型 | torch.ByteTensor | torch.cuda.ByteTensor |
| 8位有符號整型 | torch.CharTensor | torch.cuda.CharTensor |
| 16位有符號整型 | torch.ShortTensor | torch.cuda.ShortTensor |
| 32位有符號整型 | torch.IntTensor | torch.cuda.IntTensor |
| 64位有符號整型 | torch.LongTensor | torch.cuda.LongTensor |
| 32位浮點型 | torch.FloatTensor | torch.cuda.FloatTensor |
| 64位浮點型 | torch.DoubleTensor | torch.cuda.DoubleTensor |
| 布爾類型 | torch.BoolTensor | torch.cuda.BoolTensor |
4.2.Tensor創建
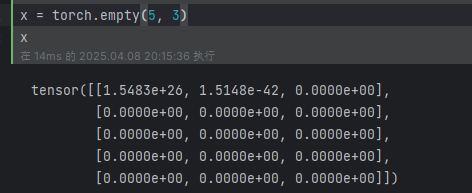
torch.empty():創建一個沒有初始化的 5 * 3 矩陣:
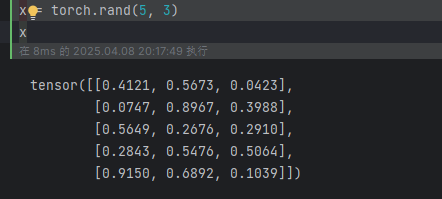
torch.rand(5, 3):創建一個隨機初始化矩陣:
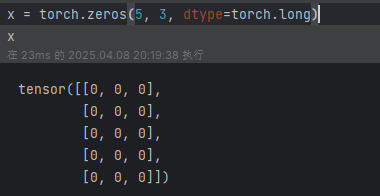
?torch.zeros(5, 3, dtype=torch.long):構造一個填滿 0 且數據類型為 long 的矩陣:
4.3.Tensor運算
| ??函數?? | ??作用?? | ??注意事項?? |
|---|---|---|
torch.abs(A) | 計算張量?A?的絕對值 | 輸入輸出張量形狀相同。 |
torch.add(A, B) | 張量相加(A + B),支持標量或張量 | 支持廣播機制(如?A.shape=(3,1),?B.shape=(1,3))。 |
torch.clamp(A, min, max) | 裁剪?A?的值到?[min, max]?范圍內 | 常用于梯度裁剪(如?grad.clamp(min=-0.1, max=0.1))。 |
torch.div(A, B) | 相除(A / B),支持標量或張量 | 整數除法需用?//?或?torch.floor_divide。 |
torch.mul(A, B) | 逐元素乘法(A * B),支持標量或張量 | 與?torch.mm(矩陣乘)區分。 |
torch.pow(A, n) | 計算?A?的?n?次冪 | n?可為標量或同形狀張量。 |
torch.mm(A, B) | 矩陣乘法(A @ B),要求?A.shape=(m,n),?B.shape=(n,p) | 不廣播,需手動轉置(如?B.T)。 |
torch.mv(A, B) | 矩陣與向量乘(A @ B),A.shape=(m,n),?B.shape=(n,) | 無需轉置?B,結果形狀為?(m,)。 |
A.item() | 將單元素張量轉為 Python 標量(如?int/float) | 僅限單元素張量(如?loss.item())。 |
A.numpy() | 將張量轉為 NumPy 數組 | 需在 CPU 上(A.cpu().numpy())。 |
A.size()?/?A.shape | 查看張量形狀(同義) | 返回?torch.Size?對象(類似元組)。 |
A.view(*shape) | 重構張量形狀(不復制數據) | 總元素數需一致(如?A.view(-1, 2))。 |
A.transpose(0, 1) | 交換維度(如矩陣轉置) | 高維張量可用?permute(如?A.permute(2,0,1))。 |
A[1:] | 切片操作(同 NumPy) | 支持高級索引(如?A[A > 0])。 |
A[-1, -1] = 100 | 修改指定位置的值 | 避免連續賦值(可能觸發復制)。 |
A.zero_() | 將張量所有元素置零(原地操作) | 帶下劃線的函數(如?add_())表示原地修改。 |
torch.stack((A,B), dim=-1) | 沿新維度拼接張量(升維) | A?和?B?形狀需相同(如?stack([A,B], dim=0)?結果形狀?(2,...))。 |
torch.diag(A) | 提取對角線元素(輸入矩陣→輸出向量) | 若?A?為向量,則輸出對角矩陣。 |
torch.diag_embed(A) | 將向量嵌入對角線生成矩陣(非對角線置零) | 輸入向量形狀?(n,),輸出矩陣形狀?(n, n)。 |
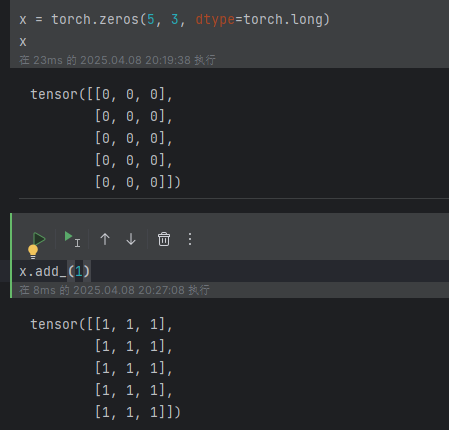
? ? ? :所有的帶_符號的函數都會對原數據進行修改,可以叫做原地操作
例如:X.add_()
?事實上 PyTorch 中對于張量的計算、操作和 Numpy 是高度類似的。
例如:通過索引訪問數據:(第二列)
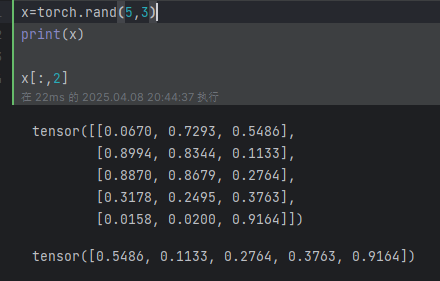
對 Tensor 的尺寸修改,可以采用 torch.view() ,如下所示:
x = torch.randn(4, 4)
y = x.view(16)
# -1 表示給定列維度8之后,用16/8=2計算的另一維度數
z = x.view(-1, 8)
print("x = ",x)
print("y = ",y)
print("z = ",z)
print(x.size(), y.size(), z.size())
x = ?tensor([[-0.3114, ?0.2321, ?0.1309, -0.1945],
? ? ? ? [ 0.6532, -0.8361, -2.0412, ?1.3622],
? ? ? ? [ 0.7440, -0.2242, ?0.6189, -1.0640],
? ? ? ? [-0.1256, ?0.6199, -1.5032, -1.0438]])
y = ?tensor([-0.3114, ?0.2321, ?0.1309, -0.1945, ?0.6532, -0.8361, -2.0412, ?1.3622,
? ? ? ? ?0.7440, -0.2242, ?0.6189, -1.0640, -0.1256, ?0.6199, -1.5032, -1.0438])
z = ?tensor([[-0.3114, ?0.2321, ?0.1309, -0.1945, ?0.6532, -0.8361, -2.0412, ?1.3622],
? ? ? ? [ 0.7440, -0.2242, ?0.6189, -1.0640, -0.1256, ?0.6199, -1.5032, -1.0438]])
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
?如果 tensor 僅有一個元素,可以采用 .item() 來獲取類似 Python 中整數類型的數值:
x = torch.randn(1)
print(x)
print(x.item())tensor([-0.7328])
-0.7328450083732605
4.4.Tensor--Numpy轉換
Tensor-->Numpy:
a = torch.ones(5)
print(a)
b = a.numpy()
print(b)

兩者是共享同個內存空間的,例子如下所示,修改 tensor 變量 a,看看從 a 轉換得到的 Numpy 數組變量 b 是否發生變化。
a.add_(1)
print(a)
print(b)
![]()
Numpy-->Tensor:
轉換的操作是調用 torch.from_numpy(numpy_array) 方法。例子如下所示:
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
print(b)

4.5.Tensor--CUDA(GPU)
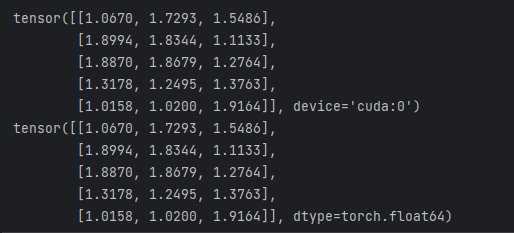
Tensors 可以通過 .to 方法轉換到不同的設備上,即 CPU 或者 GPU 上。例子如下所示:
# 當 CUDA 可用的時候,可用運行下方這段代碼,采用 torch.device() 方法來改變 tensors 是否在 GPU 上進行計算操作
if torch.cuda.is_available():device = torch.device("cuda") # 定義一個 CUDA 設備對象y = torch.ones_like(x, device=device) # 顯示創建在 GPU 上的一個 tensorx = x.to(device) # 也可以采用 .to("cuda") z = x + yprint(z)print(z.to("cpu", torch.double)) # .to() 方法也可以改變數值類型
5.Pytorch--自動微分 (autograd)
對于 Pytorch 的神經網絡來說,非常關鍵的一個庫就是 autograd ,它主要是提供了對 Tensors 上所有運算操作的自動微分功能,也就是計算梯度的功能。它屬于 define-by-run 類型框架,即反向傳播操作的定義是根據代碼的運行方式,因此每次迭代都可以是不同的。
| ??概念/方法?? | ??作用?? | ??典型應用場景?? |
|---|---|---|
requires_grad=True | 啟用張量的梯度追蹤,記錄所有操作歷史 | 訓練參數(如模型權重?nn.Parameter) |
.backward() | 自動計算梯度,結果存儲在?.grad?屬性中 | 損失函數反向傳播 |
.grad | 存儲梯度值的屬性(與張量同形狀) | 查看或手動更新梯度(如優化器步驟) |
.detach() | 返回一個新張量,從計算圖中分離(requires_grad=False) | 凍結部分網絡或避免梯度計算(如特征提取) |
torch.no_grad() | 上下文管理器,禁用梯度計算和追蹤 | 模型評估、推理階段 |
Function?類 | 定義自動微分規則,每個操作對應一個?Function?節點 | 自定義反向傳播邏輯(繼承?torch.autograd.Function) |
.grad_fn | 指向創建該張量的?Function?節點(用戶創建的張量為?None) | 調試計算圖結構 |
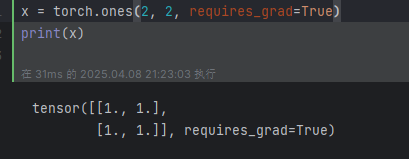
開始創建一個 tensor, 并讓 requires_grad=True 來追蹤該變量相關的計算操作:
5.1.backward求導
5.1.1.標量Tensor求導
import numpy as np
import torch# 標量Tensor求導
# 求 f(x) = a*x**2 + b*x + c 的導數
x = torch.tensor(-2.0, requires_grad=True)#定義x是自變量,requires_grad=True表示需要求導
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a*torch.pow(x,2)+b*x+c
y.backward() # backward求得的梯度會存儲在自變量x的grad屬性中
dy_dx =x.grad
dy_dx
![]()
5.1.2.非標量Tensor求導
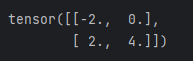
# 非標量Tensor求導
# 求 f(x) = a*x**2 + b*x + c 的導數
x = torch.tensor([[-2.0,-1.0],[0.0,1.0]], requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
gradient=torch.tensor([[1.0,1.0],[1.0,1.0]])
y = a*torch.pow(x,2)+b*x+c
y.backward(gradient=gradient)
dy_dx =x.grad
dy_dx# 使用標量求導方式解決非標量求導
# 求 f(x) = a*x**2 + b*x + c 的導數
x = torch.tensor([[-2.0,-1.0],[0.0,1.0]], requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
gradient=torch.tensor([[1.0,1.0],[1.0,1.0]])
y = a*torch.pow(x,2)+b*x+c
z=torch.sum(y*gradient)
z.backward()
dy_dx=x.grad
dy_dx
5.2.autograd.grad求導
import torch#單個自變量求導
# 求 f(x) = a*x**4 + b*x + c 的導數
x = torch.tensor(1.0, requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a * torch.pow(x, 4) + b * x + c
#create_graph設置為True,允許創建更高階級的導數
#求一階導
dy_dx = torch.autograd.grad(y, x, create_graph=True)[0]
#求二階導
dy2_dx2 = torch.autograd.grad(dy_dx, x, create_graph=True)[0]
#求三階導
dy3_dx3 = torch.autograd.grad(dy2_dx2, x)[0]
print(dy_dx.data, dy2_dx2.data, dy3_dx3)# 多個自變量求偏導
x1 = torch.tensor(1.0, requires_grad=True)
x2 = torch.tensor(2.0, requires_grad=True)
y1 = x1 * x2
y2 = x1 + x2
#只有一個因變量,正常求偏導
dy1_dx1, dy1_dx2 = torch.autograd.grad(outputs=y1, inputs=[x1, x2], retain_graph=True)
print(dy1_dx1, dy1_dx2)
# 若有多個因變量,則對于每個因變量,會將求偏導的結果加起來
dy1_dx, dy2_dx = torch.autograd.grad(outputs=[y1, y2], inputs=[x1, x2])
dy1_dx, dy2_dx
print(dy1_dx, dy2_dx)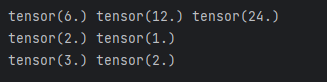
5.3.求最小值
#例2-1-3 利用自動微分和優化器求最小值
import numpy as np
import torch# f(x) = a*x**2 + b*x + c的最小值
x = torch.tensor(0.0, requires_grad=True) # x需要被求導
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
optimizer = torch.optim.SGD(params=[x], lr=0.01) #SGD為隨機梯度下降
print(optimizer)def f(x):result = a * torch.pow(x, 2) + b * x + creturn (result)for i in range(500):optimizer.zero_grad() #將模型的參數初始化為0y = f(x)y.backward() #反向傳播計算梯度optimizer.step() #更新所有的參數
print("y=", y.data, ";", "x=", x.data)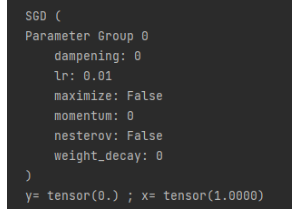






的簡單程序)












