目錄
- 1.摘要
- 2.問題描述和數學建模
- 3.強化學習多目標灰狼算法MOGWO-RL
- 4.結果展示
- 5.參考文獻
- 6.算法輔導·應用定制·讀者交流

1.摘要
本文針對大規模個性化制造(MPM)中的調度問題,提出了一種新的解決方案。MPM能夠在確保大規模生產的前提下,實現個性化定制,但由于制造任務類型和數量的快速變化,調度難度大大增加。為此,本文提出了分布式混合流車間調度問題(DHFSP-OMTA),通過將異質客戶訂單分解為標準和個性化生產任務,并將其分配到不同工廠來應對這一挑戰。為了解決MPM中的調度問題,本文構建了一個混合整數線性規劃模型,旨在同時最小化完工時間和總能耗。在此基礎上,針對DHFSP-OMTA的高復雜性,設計了一種基于強化學習多目標灰狼算法(MOGWO-RL)。MOGWO-RL采用變量任務分割方法,結合兩種初始啟發式規則,以產生高質量的種群;設計了基于強化學習變量鄰域搜索方法,提升了搜索質量,并有效避免了陷入局部最優解;提出了高效的批次合并方法,以減少運輸過程中的能耗。
2.問題描述和數學建模
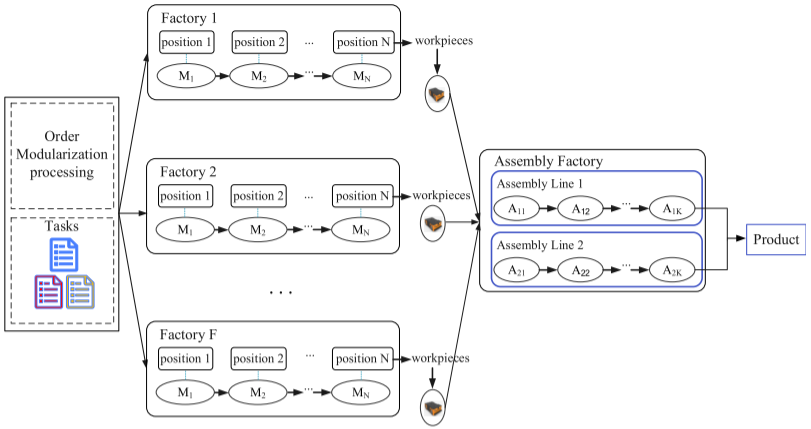
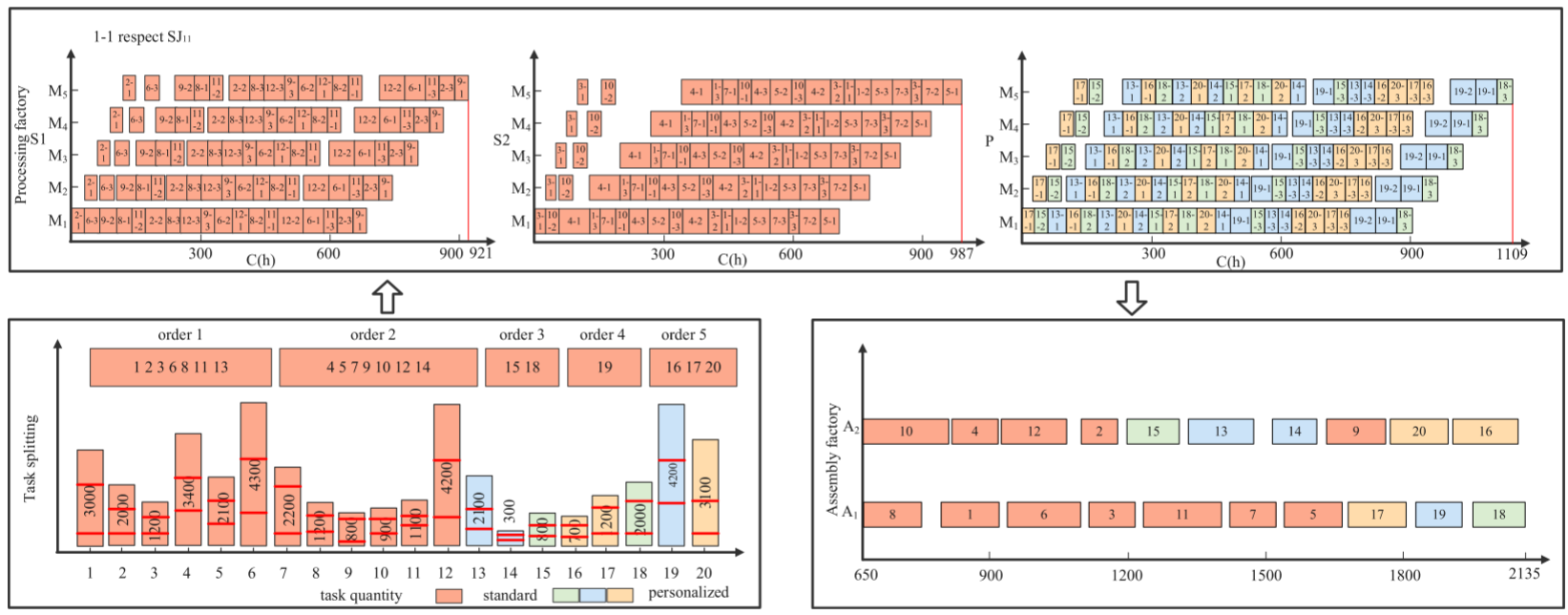
DHFSP-OMTA的整個流程可分為三個主要階段:生產、運輸和裝配。如圖所示,該系統包括多個生產工廠和一個裝配工廠。每個生產工廠配備有一組并行機器,并按指定位置排列。在生產階段,訂單被模塊化分解為多個生產任務,每個任務包含若干批次,任務需分配到不同的生產工廠進行處理。完成的批次將在運輸階段轉移到裝配工廠,后者擁有多個可進行裝配的工作站。在裝配階段,每個批次只能分配給一個工作站進行裝配。
在整個過程中,生產、工作功率和運輸功率等信息都是預先已知的,機器的空閑能耗不被考慮。DHFSP-OMTA中的任務分配主要包括以下幾個方面:(1)批次數量;(2)工廠分配;(3)任務分割;(4)批次順序。這些任務分配對于實現高效調度和優化能耗至關重要。
數學模型

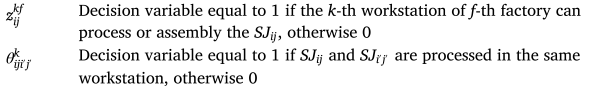
本文目標是最小化最大完工時間,最小化總能耗。


訂單模塊化和任務分配方法
OMTA方法包含兩個主要階段:消費者訂單的模塊化處理和任務分配到不同工廠,目標是通過模塊化處理將消費者訂單轉化為生產任務。因此,需要建立關聯矩陣并量化每種關系強度,該關聯矩陣包括三個關鍵指標:結構關聯、加工關聯和運輸關聯。結構關聯衡量零件之間的結構相似度,結構尺寸相似的零件更可能歸為同一生產任務;加工關聯衡量零件之間的工藝相似度,工藝相似的零件更可能共享相同的加工設備、工具和夾具;運輸關聯衡量兩零件之間的運輸時間要求,同一批次中運輸并在同一工作站組裝的零件更易歸為同一生產任務。
權重系數分別為wsw_sws?、wpw_pwp?和wtw_twt?,假設所有消費者訂單包含NNN個零件。


在任務分配階段,消費者訂單被轉化為具體的生產任務。為了提升DHFSP的制造靈活性,這些任務被分配到標準工廠和個性化工廠,其中少量任務被分配給個性化工廠,以幫助標準工廠減少換工具和設置時間。為了合理分配任務,首先需要計算任務的工作小時數,并與工廠的工作小時能力進行對比。
在此過程中,所有訂單首先形成一個集合OM,SOR表示訂單的總數量。通過訂單模塊化處理后,任務按工作小時數從小到大排序。根據任務的標準或個性化屬性以及工廠的工作小時能力,將任務分配給相應的工廠。最后使用變量分割方法將任務拆分為多個批次。


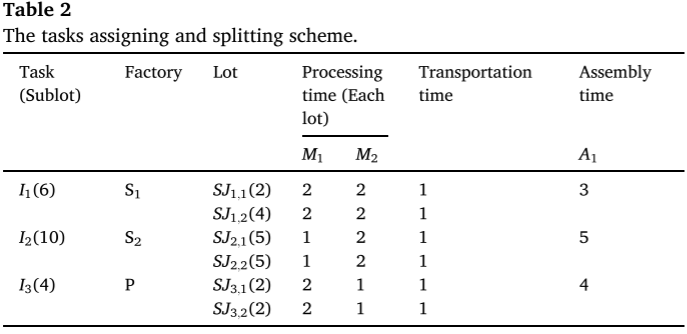
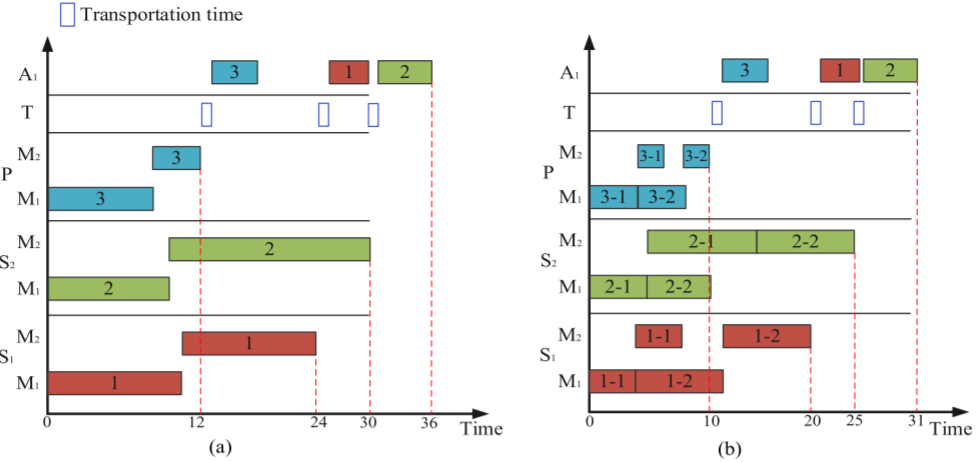
當消費者訂單到達企業時,它們會立即被處理為生產任務,隨后執行調度計劃。為了清晰地解釋任務分配和任務的變量拆分,表中包含3個加工工廠和2個工作站,S/P分別表示標準工廠和個性化工廠,以及1個裝配工廠和1個工作站。通過比較圖(a)和(b),任務分配能夠將一小部分個性化任務分配給特定工廠。
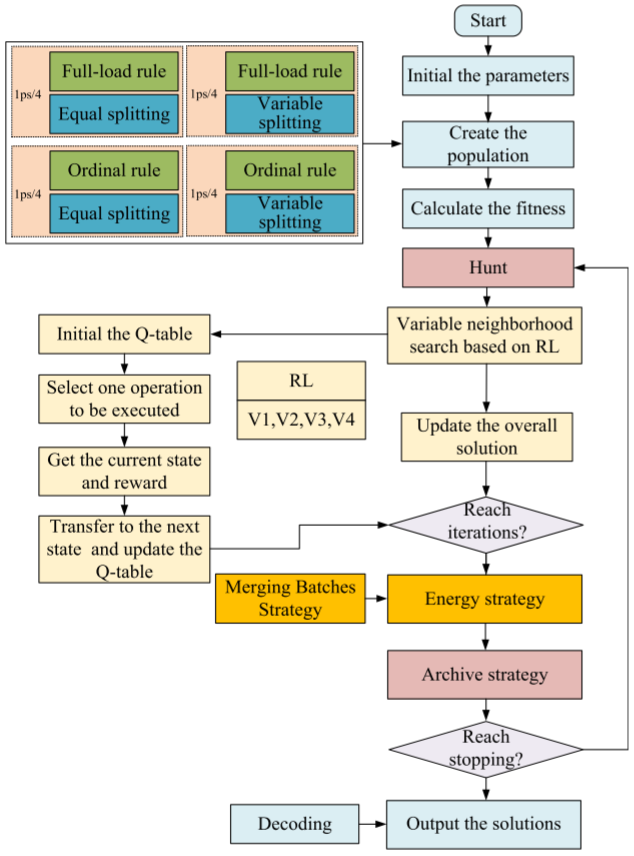
3.強化學習多目標灰狼算法MOGWO-RL
編碼與解碼
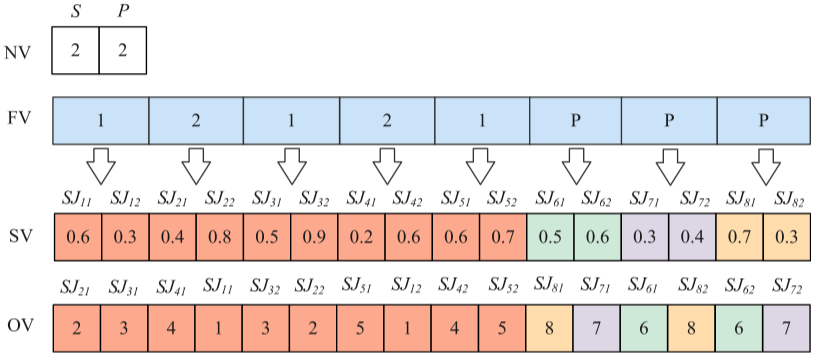
在編碼過程中,四個一維向量用于表示解決方案,包括批次數量、任務分配、每個批次的大小和批次順序。數量向量(NV)表示批次數量,基因的取值范圍為[1, 2, 3]。工廠向量(FV)表示任務分配的工廠類型,個性化任務用P表示,標準任務則用[1, Fs]表示,其中Fs為標準工廠數量。大小向量(SV)表示每個批次的大小,采用變量任務拆分方法,批次數量不超過3,最大批次為任務總數的90%,最小批次為10%。SV的基因采用一個小數表示不同批次之間數量的比例。
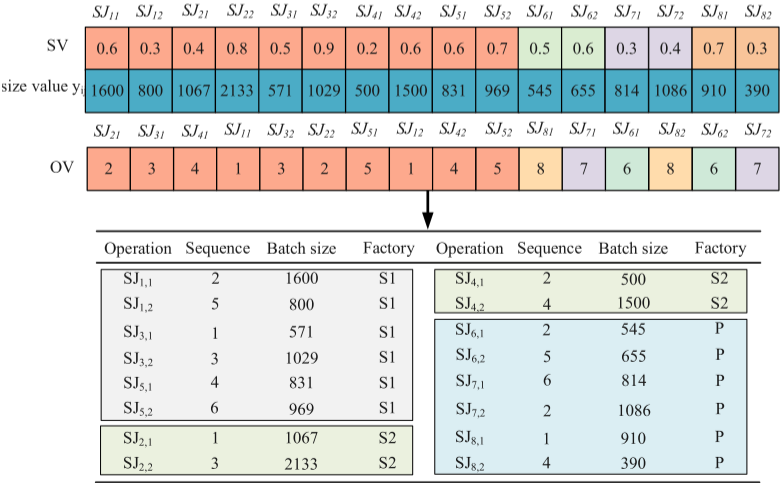
在解碼過程中,計算每個批次的大小并按照OV向量對各工廠的加工順序進行排序。任務的工廠分配依據FV向量的值,最終的完工時間由裝配工作站的完成時間確定。
SJij=?tsi?yij∑yij?,SJij∈IiSJ_{ij}=\left\lfloor ts_{i}\bullet\frac{y_{ij}}{\sum y_{ij}}\right\rfloor,SJ_{ij}\in I_{i} SJij?=?tsi??∑yij?yij???,SJij?∈Ii?
初始化策略
本文提出了兩種初始啟發式規則——任務分配和任務拆分,用于初始化工廠向量(FV)和大小向量(SV)。任務分配通過滿負荷和順序規則將任務分配給不同工廠,確保任務合理分配;任務拆分結合等分拆分和變量拆分規則,以增加SV的多樣性。此外,批次數量和批次順序采用隨機規則,進一步提升初始種群的多樣性。

捕獵策略
調度問題屬于離散問題,因此MOGWO捕獵策略需要進行重新設計。在每次迭代的捕獵操作中,www狼會選擇與三位領導者之一進行交叉,用來探索解空間。
μit+1={cross(μit,μαt),ifrand<13cross(μit,μβt),if13≤rand<23cross(μit,μγt),otherwise\left.\mu_{i}^{t+1}= \begin{cases} cross(\mu_{i}^{t},\mu_{\alpha}^{t}),ifrand<\frac{1}{3} \\ cross\left(\mu_{i}^{t},\mu_{\beta}^{t}\right),if\frac{1}{3}\leq rand<\frac{2}{3} \\ cross\left(\mu_{i}^{t},\mu_{\gamma}^{t}\right),otherwise & \end{cases}\right. μit+1?=????cross(μit?,μαt?),ifrand<31?cross(μit?,μβt?),if31?≤rand<32?cross(μit?,μγt?),otherwise??
基于強化學習的可變鄰域搜索
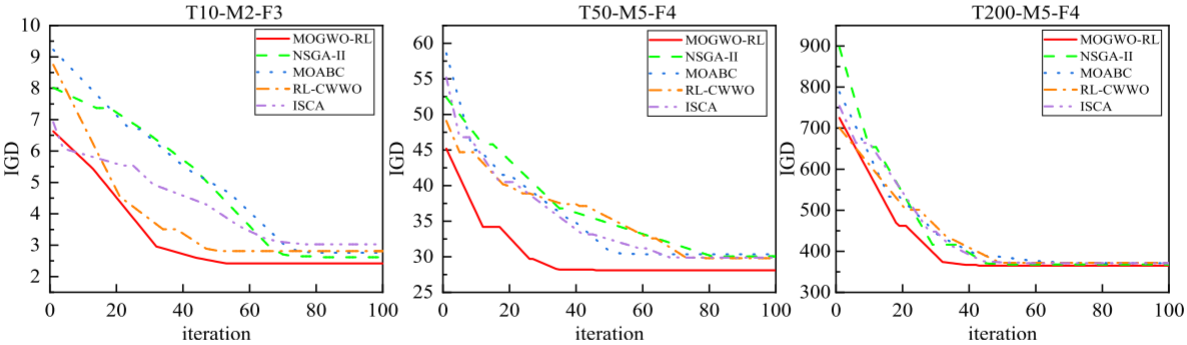
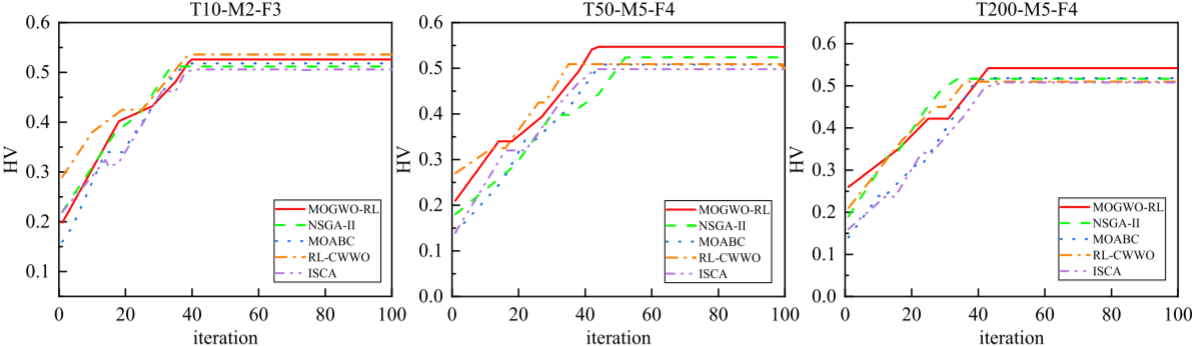
為了提高MOGWO的性能,本文設計了基于強化學習的可變鄰域搜索方法,該方法通過四種鄰域算子優化解:交換關鍵工廠任務(V1)、調整批次大小(V2)、調整任務順序(V3)和改變批次大小(V4)。強化學習用于自動選擇最佳操作,避免陷入局部最優解,并通過IGD和HV評估搜索的收斂性和多樣性。
批次合并策略
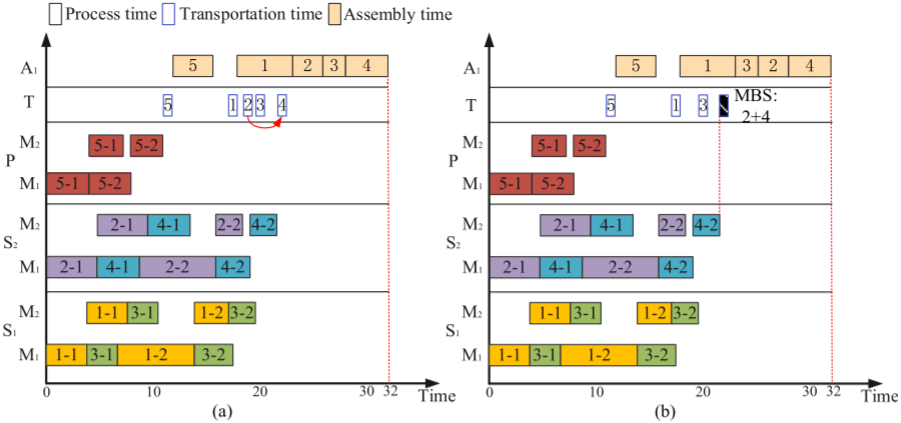
DHFSP-OMTA中的TEC包括工作站和運輸能耗,而流車間的工作站能耗難以降低。通過提出的批次合并策略(MBS)在不增加完成時間的情況下優化TEC。通過在運輸過程中合并裝配階段有時間沖突的批次,可以減少運輸能耗,同時保持完成時間不變。
4.結果展示
5.參考文獻
[1] Chen X, Li Y, Wang L, et al. Multi-objective grey wolf optimizer based on reinforcement learning for distributed hybrid flowshop scheduling towards mass personalized manufacturing[J]. Expert Systems with Applications, 2025, 264: 125866.



















