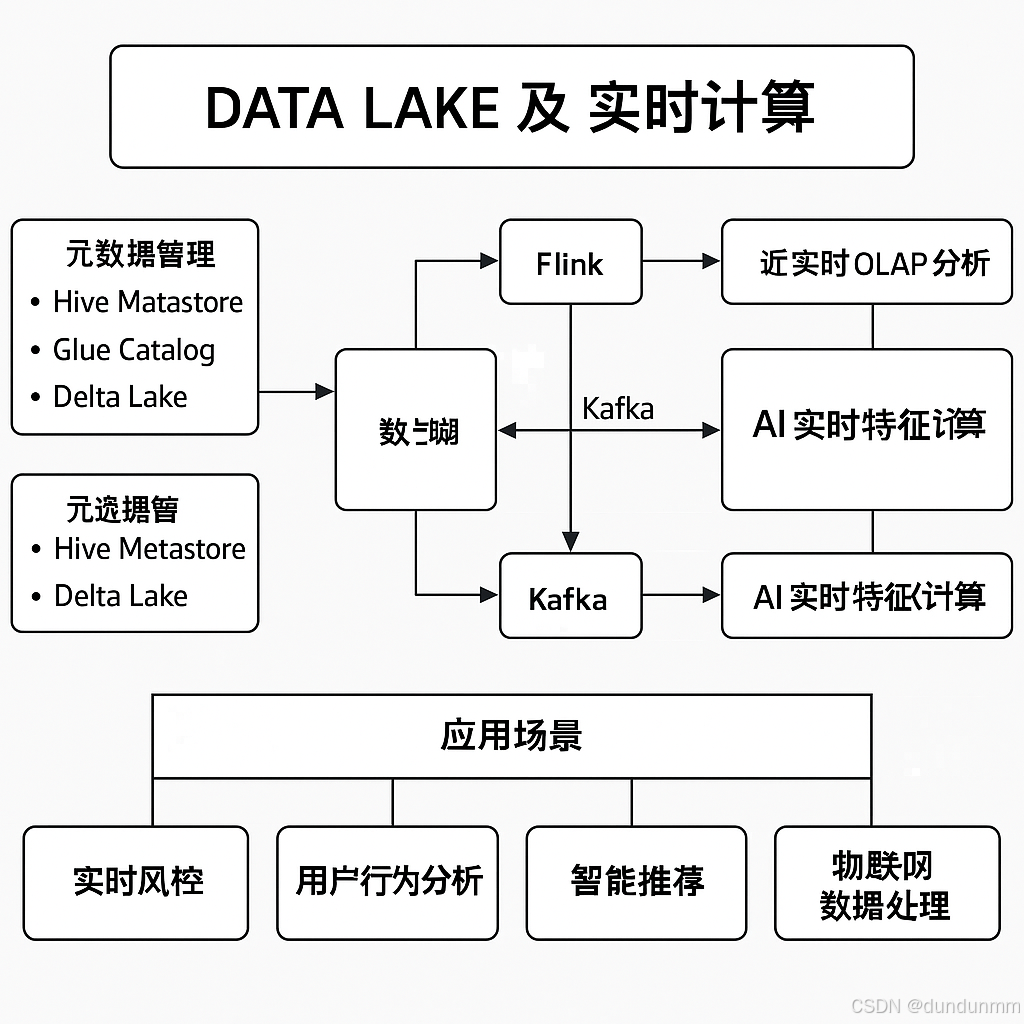
在現代數據架構中,分布式數據湖(Distributed Data Lake) 結合 實時計算(Real-time Computing) 已成為大數據處理的核心模式。數據湖用于存儲海量的結構化和非結構化數據,而實時計算則確保數據能夠被迅速處理和分析,以支持業務決策、流式數據分析和機器學習應用。
1. 分布式數據湖概述
1.1 數據湖的定義
數據湖(Data Lake)是一種能夠存儲 原始格式數據(結構化、半結構化和非結構化數據)的存儲架構,支持 大規模數據管理 和 靈活的數據分析。
與傳統數據倉庫(Data Warehouse)相比,數據湖的特點是:
-
存儲更靈活:數據不需要預定義模式(Schema-on-Read)。
-
支持多種數據格式:如 JSON、Parquet、ORC、CSV、Avro 等。
-
大規模存儲和計算分離:適用于現代云計算和分布式存儲架構。
1.2 分布式數據湖架構
分布式數據湖一般由以下關鍵組件構成:
-
存儲層(Storage Layer)
-
采用 分布式文件系統,如:
-
HDFS(Hadoop Distributed File System)
-
Amazon S3(AWS對象存儲)
-
Google Cloud Storage(GCS)
-
Azure Data Lake Storage(ADLS)
-
-
存儲數據采用 列式格式(Parquet/ORC) 以優化查詢性能。
-
-
元數據管理(Metadata Management)
-
維護數據表結構、Schema 及索引,如:
-
Apache Hive Metastore
-
AWS Glue Catalog
-
Databricks Delta Lake
-
-
通過 ACID 事務(如 Delta Lake)增強數據一致性。
-
-
計算層(Compute Layer)
-
計算框架:Apache Spark、Apache Flink、Presto、Trino
-
執行 批處理(Batch Processing) 和 流計算(Stream Processing)。
-
-
數據訪問接口(Data Access Layer)
-
通過 SQL、API、BI 工具 訪問數據,如:
-
Presto、Trino(查詢)
-
Apache Spark SQL
-
Apache Arrow(高性能數據傳輸)
-
-
-
數據治理(Data Governance)
-
提供 權限管理、數據質量控制,常見工具:
-
Apache Ranger(權限管理)
-
Apache Atlas(數據血緣分析)
-
-
2. 實時計算技術
2.1 實時計算的需求
隨著 物聯網、金融交易、智能推薦、網絡安全監控 等場景的興起,實時計算需求不斷增長:
-
低延遲(Low Latency):秒級甚至毫秒級響應數據變化。
-
高吞吐(High Throughput):每秒處理數百萬條數據流。
-
流式計算(Stream Processing):對數據流進行增量計算。
2.2 實時計算架構
現代實時計算架構通常采用 Lambda 或 Kappa 架構:
-
Lambda 架構
-
由 批處理(Batch)+ 流處理(Streaming) 結合:
-
批處理:Hadoop、Spark
-
流處理:Flink、Kafka Streams
-
-
優點:可提供數據準確性保障(數據回溯)。
-
缺點:代碼維護復雜,數據同步成本高。
-
-
Kappa 架構
-
僅使用 流計算(Streaming Processing) 處理所有數據。
-
主要組件:
-
Kafka/Pulsar(數據流傳輸)
-
Flink/Kafka Streams/Spark Streaming(流處理)
-
-
優點:架構簡單,適用于 事件驅動應用(如欺詐檢測、實時推薦)。
-
2.3 主要實時計算框架
| 框架 | 計算模式 | 適用場景 |
|---|---|---|
| Apache Flink | 實時流處理(Stream Processing) | 高吞吐、低延遲應用 |
| Apache Kafka Streams | 輕量級流處理 | 事件驅動架構 |
| Apache Spark Streaming | 微批(Micro-batch)流計算 | 實時分析 + 兼容 Spark 批處理 |
| Apache Storm | 低延遲流處理 | 高速數據流(金融風控) |
| Apache Druid | 實時 OLAP 分析 | BI、數據可視化 |
3. 分布式數據湖與實時計算的結合
3.1 為什么要結合數據湖與實時計算?
在實際業務中,數據湖的存儲能力與實時計算結合,可以實現:
-
實時分析:基于數據湖的流數據分析,如用戶行為分析。
-
實時 ETL(Extract-Transform-Load):流式數據清洗、轉換、存入數據湖。
-
增量數據處理:結合 Delta Lake、Iceberg 進行 Change Data Capture(CDC),只處理新增數據。
3.2 結合方式
-
數據湖 + 實時流計算
-
數據流入(Streaming Ingestion):
-
Kafka → Flink → Delta Lake / Iceberg
-
-
實時查詢(Streaming Query):
-
Flink SQL 直接查詢數據湖。
-
-
-
數據湖 + 近實時 OLAP
-
數據湖存儲歷史數據,Druid 進行實時聚合分析:
-
Flink → Kafka → Druid
-
-
-
數據湖 + AI 實時特征計算
-
實時機器學習(Online Machine Learning):
-
Flink 計算特征 → 存入 Feature Store(如 Feast)
-
AI 模型使用最新數據訓練 / 推理
-
-
4. 典型應用場景
| 應用場景 | 解決方案 | 主要技術 |
|---|---|---|
| 實時風控 | 監測交易數據,檢測欺詐行為 | Flink + Kafka + 數據湖 |
| 用戶行為分析 | 統計 PV/UV,用戶路徑分析 | Flink SQL + Delta Lake |
| 智能推薦 | 結合用戶實時行為調整推薦策略 | Flink + ML 模型 |
| IoT 數據處理 | 處理海量物聯網設備數據 | Kafka + Flink + Iceberg |
| 日志分析 | 監控系統日志,檢測異常 | Flink + Druid + Elasticsearch |
5. 未來發展趨勢
-
數據湖 + Lakehouse 模式:采用 Delta Lake、Apache Iceberg 統一批流處理能力,支持 ACID 事務。
-
流批一體化(Stream-Batch Unification):Flink/Spark 逐步統一批處理和流處理,提高一致性。
-
自動化數據治理(Automated Data Governance):引入 AI 進行元數據管理和數據質量檢測。
-
云原生架構(Cloud-Native Data Lake):無服務器(Serverless)計算框架,如 AWS Athena、Google BigQuery。
6. 結論
分布式數據湖與實時計算的結合,能夠高效存儲、管理和分析大規模數據,是未來數據架構發展的核心方向。通過采用 Flink、Kafka、Delta Lake 等技術,可以實現 高效實時分析、流式數據處理和 AI 應用,滿足企業級大數據需求。



















