本章內容的大綱如下:
常見的字典方法
如何處理查找不到的鍵
標準庫中 dict 類型的變種set 和 frozenset 類型
散列表的工作原理
散列表帶來的潛在影響(什么樣的數據類型可作為鍵、不可預知的
順序,等等)
常見的映射方法
映射類型的方法其實很豐富。表 3-1 為我們展示了
dict、defaultdict 和 OrderedDict 的常見方法,后面兩個數據類型
是 dict 的變種,位于 collections 模塊內。
表3-1:dict、collections.defaultdict和
collections.OrderedDict這三種映射類型的方法列表(依然省略
了繼承自object的常見方法);可選參數以[…]表示
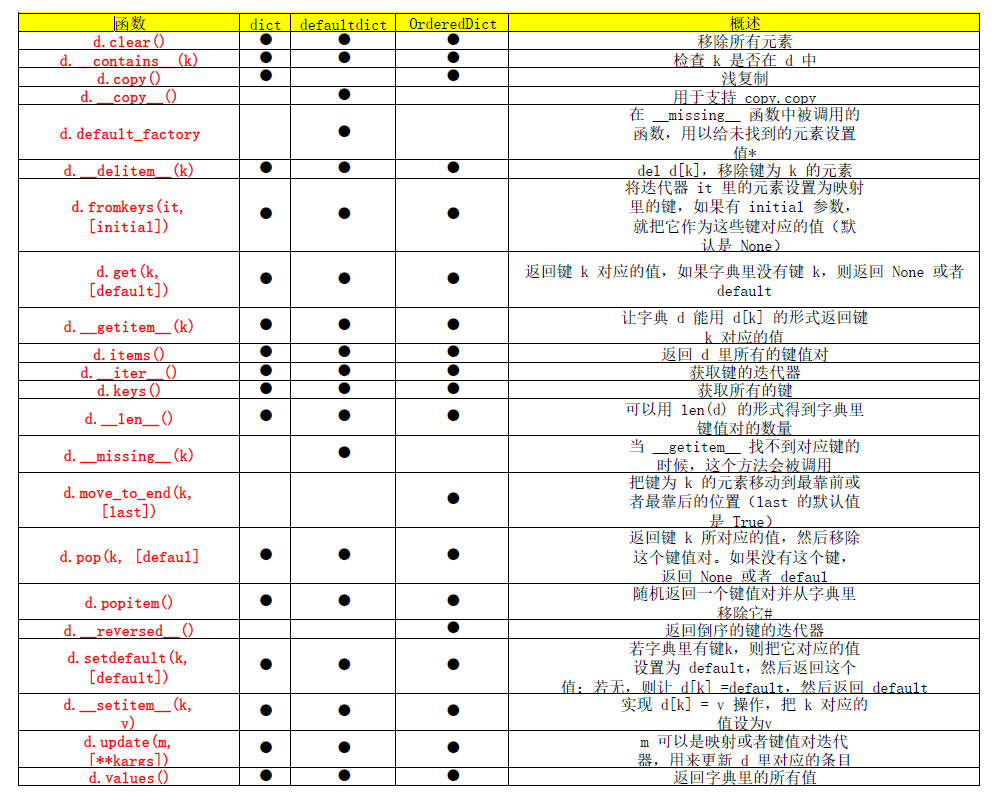
- default_factory 并不是一個方法,而是一個可調用對象(callable),它的值在
defaultdict 初始化的時候由用戶設定。
#OrderedDict.popitem() 會移除字典里最先插入的元素(先進先出);同時這個方法還有一
個可選的 last 參數,若為真,則會移除最后插入的元素(后進先出)。
上面的表格中,update 方法處理參數 m 的方式,是典型的“鴨子類
型”。函數首先檢查 m 是否有 keys 方法,如果有,那么 update 函數就
把它當作映射對象來處理。否則,函數會退一步,轉而把 m 當作包含了
鍵值對 (key, value) 元素的迭代器。Python 里大多數映射類型的構造
方法都采用了類似的邏輯,因此你既可以用一個映射對象來新建一個映
射對象,也可以用包含 (key, value) 元素的可迭代對象來初始化一個
映射對象。
在映射對象的方法里,setdefault 可能是比較微妙的一個。我們雖然
并不會每次都用它,但是一旦它發揮作用,就可以節省不少次鍵查詢,
從而讓程序更高效。如果你對它還不熟悉,下面我會通過一個實例來講
解它的用法。
用setdefault處理找不到的鍵
當字典 d[k] 不能找到正確的鍵的時候,Python 會拋出異常,這個行為
符合 Python 所信奉的“快速失敗”哲學。也許每個 Python 程序員都知道
可以用 d.get(k, default) 來代替 d[k],給找不到的鍵一個默認的
返回值(這比處理 KeyError 要方便不少)。但是要更新某個鍵對應的值的時候,不管使用 getitem 還是 get 都會不自然,而且效率
低。就像示例 3-2 中的還沒有經過優化的代碼所顯示的那
樣,dict.get 并不是處理找不到的鍵的最好方法。
示例 3-2 是由 Alex Martelli 舉的一個例子 變化而來,例子生成的索引
跟示例 3-3 顯示的一樣。
示例 3-2 index0.py 這段程序從索引中獲取單詞出現的頻率信
息,并把它們寫進對應的列表里(更好的解決方案在示例 3-4 中)
"""創建一個從單詞到其出現情況的映射"""
import sys
import re
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:for line_no, line in enumerate(fp, 1):for match in WORD_RE.finditer(line):word = match.group()column_no = match.start()+1location = (line_no, column_no)
# 這其實是一種很不好的實現,這樣寫只是為了證明論點
occurrences = index.get(word, []) ?
occurrences.append(location) ?
index[word] = occurrences ?
# 以字母順序打印出結果
for word in sorted(index, key=str.upper): ?print(word, index[word])
? 提取 word 出現的情況,如果還沒有它的記錄,返回 []。
? 把單詞新出現的位置添加到列表的后面。
? 把新的列表放回字典中,這又牽扯到一次查詢操作。
? sorted 函數的 key= 參數沒有調用 str.uppper,而是把這個方法
的引用傳遞給 sorted 函數,這樣在排序的時候,單詞會被規范成統一
格式。
示例 3-3 這里是示例3-2 的不完全輸出,每一行的列表都代表一
個單詞的出現情況,列表中的元素是一對值,第一個值表示出現的
行,第二個表示出現的列
$ python3 index0.py ../../data/zen.txt
a [(19, 48), (20, 53)]
Although [(11, 1), (16, 1), (18, 1)]
ambiguity [(14, 16)]
and [(15, 23)]
are [(21, 12)]
aren [(10, 15)]
at [(16, 38)]
bad [(19, 50)]
be [(15, 14), (16, 27), (20, 50)]
beats [(11, 23)]
Beautiful [(3, 1)]
better [(3, 14), (4, 13), (5, 11), (6, 12), (7, 9), (8, 11),
(17, 8), (18, 25)]
...
示例 3-2 里處理單詞出現情況的三行,通過 dict.setdefault 可以只
用一行解決。示例 3-4 更接近 Alex Martelli 自己舉的例子。
示例 3-4 index.py 用一行就解決了獲取和更新單詞的出現情況列
表,當然跟示例 3-2 不一樣的是,這里用到了 dict.setdefault
"""創建從一個單詞到其出現情況的映射"""
import sys
import re
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:for line_no, line in enumerate(fp, 1):for match in WORD_RE.finditer(line):word = match.group()
column_no = match.start()+1location = (line_no, column_no)index.setdefault(word, []).append(location) ?
# 以字母順序打印出結果
for word in sorted(index, key=str.upper):print(word, index[word])
? 獲取單詞的出現情況列表,如果單詞不存在,把單詞和一個空列表
放進映射,然后返回這個空列表,這樣就能在不進行第二次查找的情況
下更新列表了。
也就是說,這樣寫:
my_dict.setdefault(key, []).append(new_value)
跟這樣寫:
if key not in my_dict:
my_dict[key] = []
my_dict[key].append(new_value)
二者的效果是一樣的,只不過后者至少要進行兩次鍵查詢——如果鍵不
存在的話,就是三次,用 setdefault 只需要一次就可以完成整個操
作。
那么,在單純地查找取值(而不是通過查找來插入新值)的時候,該怎
么處理找不到的鍵呢?







android編譯)


1667. 修復表中的名字)








)