第九章節——數據庫技術基礎
數據庫技術基礎
- 第九章節——數據庫技術基礎
- 一、基本概念
- 1. 數據庫與數據庫系統
- 2. 數據庫的三級模式
- 2.1 內模式
- 2.2 概念模式
- 2.3 外模式
- 2.4 數據庫的兩級映射
- 2.5 數據庫設計的基本步驟
- 二、數據模型
- 1. 基本概念
- 2. E-R模型
- 2.1 實體
- 2.2 聯系
- 2.3 屬性
- 3. 實體-聯系方法
- 4. 關系模型
- 三、關系代數
- 1. 關系數據庫的基本概念
- 1.1 屬性和域
- 1.2 笛卡爾積與關系
- 1.3 關系的相關名詞
- 1.4 關系的三種類型
- 1.5 關系數據庫模式
- 1.6 完整性約束
- 1.7 關系運算
- 2. 五種基本的關系代數運算
- 2.1 并(Union)
- 2.2 差(Difference)
- 2.3 廣義笛卡爾積(Extended Cartesian Product)
- 2.4 投影(Projection)
- 2.5 選擇(Selection)
- 3. 擴展的關系代數運算
- 3.1 交(Intersection)
- 3.2 連接(Join)
- 3.3 除(Division)
- 3.4 廣義投影(Generalized Projection)
- 3.5 外連接(Outer Join)
- 四、關系型數據庫SQL語言簡介
- 1. SQL簡介
- 2. SQL數據定義
- 2.1 創建表(Create Table)
- 2.2 修改(Alter Table)
- 2.3 刪除(Drop Table)
- 2.4 索引
- 2.5 視圖
- 3. SQL數據查詢
- 3.1 Select基本結構
- 3.2 連接查詢
- 3.4 子查詢與聚集查詢
- 3.5 分組查詢
- 3.6 更名運算
- 3.7 字符串操作
- 3.8 視圖查詢
- 4. 數據更新
- 4.1 插入
- 4.2 刪除
- 4.3 修改
- 5. 訪問控制
- 5.1 授權
- 5.2 收回授權
- 五、關系數據庫的規范化
- 1. 函數依賴
- 1.1 函數依賴
- 1.2 部分函數依賴
- 1.3 傳遞函數依賴
- 1.4 函數依賴的公理系統(Armstrong公理系統)
- 2. 規范化
- 2.1 1NF(第一范式)
- 2.2 2NF(第二范式)
- 2.3 3NF(第三范式)
- 2.4 BCNF(巴克斯范式)
- 2.5 4NF(第四范式)
- 3. 模式分解及分解特征
- 3.1 分解
- 3.2 無損鏈接
- 3.3 保持函數依賴
- 六、數據庫的控制功能
- 1. 事務管理
- 2. 數據庫的備份與恢復
- 2.1 數據庫故障類型
- 2.2 數據庫的備份方法
- 3. 并發控制
- 3.1 丟失修改(丟失更新)
- 3.2 不可重復讀
- 3.3 讀臟數據
- 3.4 并發控制技術
一、基本概念
1. 數據庫與數據庫系統
數據庫系統(DataBase System,DBS)由數據庫、硬件、軟件和人員組成。數據庫管理系統(DataBase Management System,DBMS)主要實現對共享數據有效地組織、管理和存取。DBMS的功能:數據定義(Data Definition Language,DDL)、數據庫操縱(Data Manipulation
Language,DML)、數據庫運行管理、數據的組織、存儲和管理、數據庫的建立和維護、網絡通信等。DBMS的分類:關系數據庫系統(Relation DataBase System,RDBS)、面向對象的數據庫系統
(0bject-Oriented DataBase System,OODBS)、對象關系數據庫系統(Object-Oriented RelationDataBase Svstem,ORDBS)
2. 數據庫的三級模式
2.1 內模式
也稱存儲模式,是數據物理結構和存儲方式的描述,是數據在數據庫內部的表示方式,定義所有的內部記錄類型、索引和文件的組織方式以及數據控制方面的細節。一個數據庫只有一個內模式。對應數據庫中的物理存儲文件。
2.2 概念模式
也稱模式,是數據庫中全部數據的邏輯結構和特征的描述。一個數據庫只有一個概念模式。對應數據庫中的基本表。
2.3 外模式
也稱用戶模式或子模式,是用戶與數據庫系統的接口,是用戶用到的那部分數據的描述。一個數據庫可以有多個外模式。對應數據庫中的視圖。
2.4 數據庫的兩級映射
(1) 模式/內模式映像:實現了概念模式和內模式間的相互轉換,是表和數據的物理存儲之間的映射,保證了數據的物理獨立性。
(2) 外模式/模式映像:實現了外模式和概念模式間的相互轉換,是視圖和表之間的映射,保證數據的邏輯獨立性。
數據的獨立性:
(1)物理獨立性。物理獨立性是指用戶的應用程序與存儲在磁盤上的數據庫中的數據是相互獨立的。當數據的物理存儲改變時,應用程序不需要改變。物理獨立性存在于概念模式和內模式之間的映射轉換,說明物理組織發生變化時應用程序的獨立程度。
(2)邏輯獨立性。邏輯獨立性是指用戶的應用程序與數據庫中的邏輯結構是相互獨立的。當數據的邏輯結構改變時,應用程序不需要改變。邏輯獨立性存在于外模式和概念模式之間的映射轉換,說明概念模式發生變化時應用程序的獨立程度。
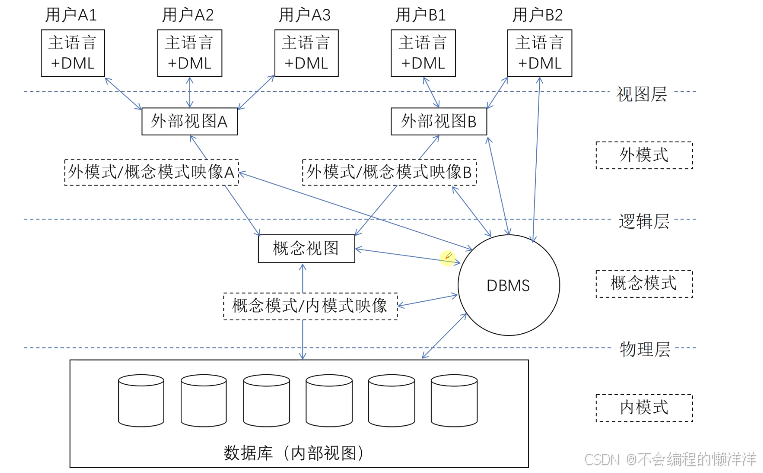
2.5 數據庫設計的基本步驟
(1) 用戶需求分析。即分析數據存儲的要求,產出物有數據流圖、數據字典、需求說明書。獲得用戶對系統的三個要求:信息要求、處理要求、系統要求。
(2) 概念結構設計。就是設計E-R圖,也即實體-聯系圖。工作步驟包括:選擇局部應用、逐一設計分E-R圖、E-R圖合并。分E-R圖進行合并時,它們之間存在的沖突主要有以下3類。
屬性沖突。同一屬性可能會存在于不同的分E-R圖中。命名沖突。相同意義的屬性,在不同的分E-R圖上有著不同的命名,或是名稱相同的屬性在不同的分E-R圖中代表著不同的意義。結構沖突。同一實體在不同的分E-R圖中有不同的屬性,同一對象在某一分E-R圖中被抽象為實體而在另分E-R圖中又被抽象為屬性。
(3)邏輯結構設計。將E-R圖,轉換成關系模式。工作步驟包括:確定數據模型、將E-R圖轉換成為指定的數據模型、確定完整性約束和確定用戶視圖。
(4)物理結構設計。是邏輯模型在計算機中的具體實現方案。步驟包括確定數據分布、存儲結構和訪問方式。
(5)數據庫實施階段。根據邏輯設計和物理設計階段的結果建立數據庫,編制與調試應用程序,組織數據入庫,并進行試運行。
(6)數據庫運行和維護階段。數據庫應用系統經過試運行即可投入運行,但該階段需要不斷地對系統進行
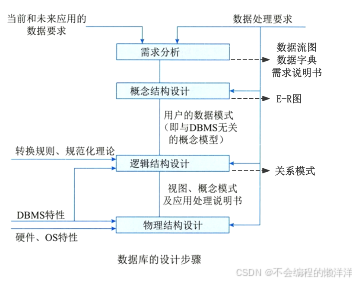
二、數據模型
1. 基本概念
數據模型是對現實世界數據特征的抽象。最常用的數據模型分為概念數據模型和基本數據模型。
(1) 概念數據模型:也稱信息模型,是按用戶的觀點對數據和信息建模,是用戶和數據庫設計人員交流的語言,主要用于數據庫設計。這類模型中最著名的是實體-聯系模型,簡稱E-R模型。
(2) 基本數據模型:它是按計算機系統的觀點對數據建模,是現實世界數據特征的抽象,用于DBMS的實現。
2. E-R模型
E-R模型,就是實體-聯系模型,用來描述現實世界的概念模型(接近于人的思維方式,容易理解),其中有三個主要的概念:實體、聯系和屬性。
2.1 實體
用矩形表示,每個實體由一組屬性表示,包括候選鍵、主鍵、外鍵。實體集是指具有相同屬性的實體集合。
候選鍵能唯一地標識一行元組的屬性集。
主鍵:從候選鍵中選一個作為主鍵。
外鍵:在另一個關系模式中充當主鍵的屬性。
2.2 聯系
用菱形表示,實體集之間的對應關系稱為聯系,分為一對一(1:1)、一對多(1:n或1:*)、多對多(m: n或*:*)。
①一對一聯系(1:1)。實體集A中的一個實體最多只與實體集B中的一個實體相聯系,反之亦然。
②一對多聯系(1:n或1:*)。實體集A中的一個實體可與實體集B中的多個實體相聯系。
③多對多聯系(m:n或*.*)。實體集A中的多個實體可與實體集B中的多個實體相聯系。多對多的聯系會產生一個新的關系模式,此關系模式的屬性由聯系的兩個實體的主鍵以及自己的特有屬性所組成。
樣例:
1:1:一個學校只有一名校長,而每位校長只在一個學校工作。
1:n或1:*:一個學校有很多學生,而每個學生只在一個學校上課。
m:n或*:*:一名學生可以選修多門課程,而一門課程也可以由多名學生講授
2.3 屬性
用橢圓表示,是實體某方面的特性。E-R模型中的屬性分為:
①簡單和復合屬性: 簡單屬性是原子的、不可再分的,復合屬性可以劃分為多個子屬性,如通信地址。
②單值和多值屬性: 對于一個特定的實體都只有一個單獨的值(單值屬性)。例如,對于一個特定的員工,只對應一個員工號、員工姓名。而員工可能有0個、1個或多個親屬,那么員工的親屬姓名可能有多個,這樣的屬性稱為多值屬性。
③NULL屬性: 某個屬性沒有值或屬性值未知時,使用NULL值,表示無意義或不知道。
④派生屬性: 派生屬性可以從其他屬性得來。例如,職工實體集中有“參加工作時間”和“工作年限”"屬性,那么“工作年限”的值可以由當前時間和參加工作時間得到。“工作年限”就是一個派生屬性。
弱實體集: 一個實體的存在必須以另一個實體為前提,這類實體稱為弱實體集。例如:職工的家屬必須以職工在職為前提,依賴于職工。
3. 實體-聯系方法

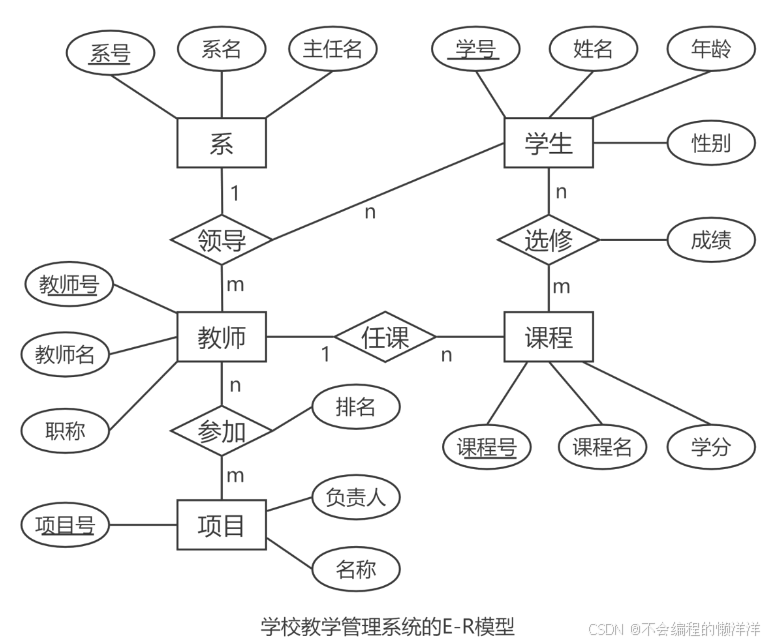
4. 關系模型
在數據庫領域中常見的數據模型有層次模型、網狀模型、關系模型和面向對象模型。關系模型是目前最常用的數據模型之一。在關系模型中用表格結構表達實體集以及實體集之間的聯系。
三、關系代數
1. 關系數據庫的基本概念
1.1 屬性和域
一個現實中的實體(事物)常用若干特征來描述,這些特征稱為屬性。每個屬性的取值范圍對應的集合稱為該屬性的域。
例如:員工(員工號,姓名,性別,參加工作時間,部門號)
1.2 笛卡爾積與關系
設D1,D2,…, Di…,Dn為任意集合,其笛卡爾積為:
D1× D2×…× Di×…× Dn = {(d1, d2,…, di,…, dn) l di ∈ Di, i = 1,2,3,…,n}
其中,每一個元素(d1,d2,…, di,…, dn)稱為一個n元組。
1.3 關系的相關名詞
(1)候選碼(Candidate Key):若關系中的某一屬性或屬性組的值能唯一地標識一個元組,則稱該屬性或屬性組為候選碼。
(2)主碼(Primary Key):若一個關系有多個候選碼,則選定其中一個為主碼。
(3)主屬性(Non-Kcy attribute):包含在任何候選碼中的諸屬性稱為主屬性。不包含在任何候選碼中的屬性稱為非碼屬性。
(4)外碼(Foreign Key):如果關系模式R中的屬性或屬性組不是該關系的主碼,但它是其他關系的主碼,那么該屬性或屬性組是關系模式R的外碼。
員工 (員工號,姓名,性別,參加工作時間,部門號),部門(部門號,名稱,電話,負責人)
1.4 關系的三種類型
(1)基本關系 。通常又稱為基本表,它是實際存在的表,是實際存儲數據的邏輯表示。
(2)查詢表 。查詢表是查詢結果對應的表。
(3)視圖表 。視圖表是由基本表或其他視圖表導出的表。由于它本身不獨立存儲在數據庫中,數據庫中只存放它的定義,所以常稱為虛表。
1.5 關系數據庫模式
關系的描述稱為關系模式(Relation Schema),可以形式化地表示為: R(U , D,dom,F)
其中,R表示關系名;U是組成該關系的屬性名集合;D是屬性的域;dom是屬性向域的映像集合;F為屬性間數據的依賴關系集合。
通常將關系模式簡記為: R(U)或R(A~1~,A~2~,…,A~n~)
其中,R為關系名,A1,Ap,.…An為屬性名或域名,屬性向域的映像常常直接說明屬性的類型、長度。通常在關系模式主屬性上加下劃線表示該屬性為主碼屬性。
員工(員工號,姓名,性別,參加工作時間,部門號)
1.6 完整性約束
完整性規則提供了一種手段來保證當用戶對數據庫做修改時不會破壞數據的一致性。防止對數據的意外破壞。關系模型的完整性規則是對關系的某種約束條件。關系的完整性分為三類:
①實體完整性: 關系的主屬性不能取空。
②參照完整性: 外鍵的值或者為空,或者必須等于對應關系中的主鍵值。
員工(員工號,姓名,性別,參加工作時間,部門號),部門(部門號,名稱,電話,負責人)
③用戶定義完整性: 根據語義要求所自定義的約束條件。
1.7 關系運算
關系操作的特點是操作對象和操作結果都是集合。關系代數運算符有4類:集合運算符、專門的關系運算符、算術比較符和邏輯運算符。
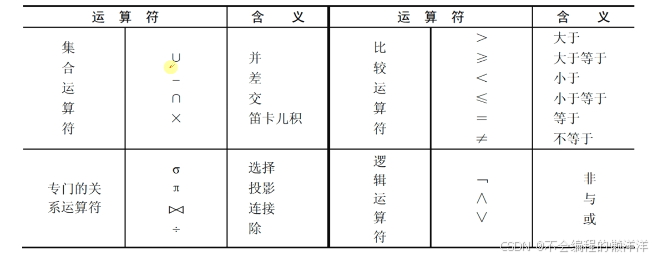
2. 五種基本的關系代數運算
2.1 并(Union)
關系模式在代數運算時可以理解為數據庫表的運算
關系R與S的屬性及屬性的個數相同。并的結果為屬于R或屬于S的元組構成的集合(元組要去重)。
R ∪ \cup ∪S = {t | t ∈ \in ∈R ∪ \cup ∪ t ∈ \in ∈s}

2.2 差(Difference)
關系R與S的屬性及屬性的個數相同。R一S差的結果為屬于R但不屬于S的元組構成的集合。

2.3 廣義笛卡爾積(Extended Cartesian Product)
如果關系模式R中有n個屬性,關系模式S中有m個屬性,則廣義笛卡爾積的結果中有 (n+m)個屬性,其中前n個屬性來自R,后m個屬性來白S。如果R中有K1個元組,S中有K2個元組,則運算結果有K1×K2個元組。

2.4 投影(Projection)
從關系的垂直方向進行運算。在關系R中挑選若干屬性列A組成新的關系。

2.5 選擇(Selection)
從關系的水平方向進行運算,從關系R中選擇滿足條件的元組。
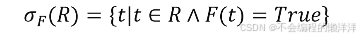
其中,F中運算對象是屬性名(或列的序號)或者常量(用單引號括起來,如'1'表示數字1)、算術運算符(<、 ≤、>、≥、≠)、邏輯運算符( ∧ 、 ∨ 、 ? \wedge、 \vee、\lnot ∧、∨、?)。
3. 擴展的關系代數運算
3.1 交(Intersection)
關系R與S的屬性及屬性的個數相同。關系R與S的交是由屬于R同時又屬于S的元組構成的集合。
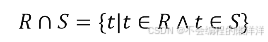
顯然,R ∩ \cap ∩S = R -(R - S),或者R ∩ \cap ∩S =S- (S - R)。
3.2 連接(Join)
連接分為$\theta$連接、等值連接和自然連接3種。連接運算是從兩個關系R和S的笛卡爾積中選取滿足條件的元組。
-
$\theta$連接:從關系R與S的笛卡爾積中選取屬性間滿足一定條件的元組
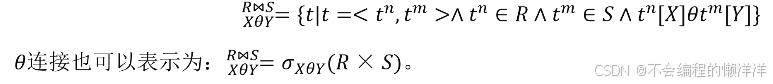
-
等值連接:當 θ \theta θ為"="時,稱之為等值連接。
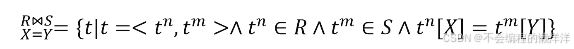
-
自然連接:是一種特殊的等值連接,它要求兩個關系中進行比較的分量必須是相同的屬性組,相同屬性組的值要相等,并且在結果集中將重復屬性列去掉。
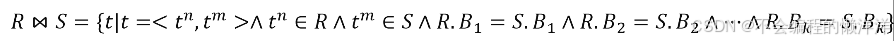
3.3 除(Division)
除運算是同時從關系的水平方向和垂直方向進行運算。
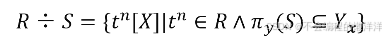
3.4 廣義投影(Generalized Projection)
允許在投影列表中使用算術運算,是對投影運算的補充。
3.5 外連接(Outer Join)
在自然連接中關系R與S的一些元組因為沒有公共屬性會被拋棄。使用外連接就可以避免這樣的丟失。外連接運算就是將自然連接時舍棄的元組也放入新關系,并在新增加的屬性上填入空值。
- 左外連接(Left Outer Join): 記為R ? \rtimes ?S,以左側的關系R為主,保留左側的關系R的所有元組右側的關系S未等值的用NULL填充,加入到RvS中。
- 右外連接(Right Outer Join): 記為R ? \ltimes ?S,以右側的關系S為主,保留右側的關系S的所有元組,左側的關系R未等值的用NULL填充,加入到RS中。
- 全外連接(Full Outer Join): 記為R?S,左外連接和右外連接的并。
四、關系型數據庫SQL語言簡介
這里我只列舉一些軟考用的到的,我之前寫了一篇更加詳細的關于Mysql的sql語言:MySQL數據庫總結
1. SQL簡介
SQL是結構化查詢語言的簡稱,是關系數據庫中最普遍使用的語言,包括數據查詢、數據操縱、數據定義和數據控制,是一種通用的、功能強大的關系數據庫標準語言。
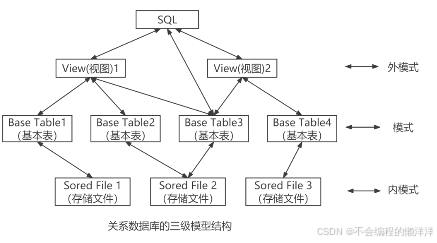
SQL語言支持關系數據庫的三級模式。基本表和視圖都是表,基本表是存儲在數據庫中的表,而視圖是虛表,是從基本表或其他視圖導出的表。數據庫中只存放視圖的定義,不存放視圖的數據。.用戶可用SOL語言對視圖或表進行查詢等操作。
關系數據庫的三級模式:
2. SQL數據定義
SQL的數據定義包括對表、視圖、索引的創建和刪除,屬于數據庫定義語言(DDL)。
2.1 創建表(Create Table)
語句格式: CREATE TABLE <表名>(<列名><數據類型>[列級完整性約束條件] [,<列名><數據類型[列級完整性約束條件]…[,<表級完整性約束條件>);
| 完整性約束 | 樣例 | 列級/表級 |
|---|---|---|
| 非空約束 | Not null | 列級 |
| 唯一約束 | Unique | 列級 |
| 主鍵約束 | Primary Key | 列級/表級 |
| 外鍵約束 | Foreign | 表級 |
2.2 修改(Alter Table)
語句格式: ALTER TABLE<表名>[ADD<新列名><數據類型>[完整性約束條件]][DROP<完整性約束名>][MODIFY<列名><數據類型];
2.3 刪除(Drop Table)
語句格式: Drop Table <表名>;
2.4 索引
數據庫中索引的作用:①通過創建唯一性索引,保證數據記錄的唯一性;② 大大加快數據的檢索速度; ③加速表與表之間的連接;④在使用Order By和Group By子句中進行檢索數據時,可以顯著減少查詢中分組和排序的時間;⑤使用索引可以在檢索數據的過程中使用優化隱藏器,提高系統性能。
索引分為聚簇索引和非聚簇索引。聚簇索引是指索引表中索引項的順序與表中記錄的物理順序一致的索引。
-
創建索引
語句格式: CREATE [UNIQUE][CLUSTER] INDEX<索引名>ON<表名>(<列名>[<次序>][,<列名>[<次序>]]…); -
刪除索引
語句格式: DROP INDEX<索引名>;
2.5 視圖
視圖是由一個或多個基本表或視圖導出的表,其結構和數據是建立在對表的查詢基礎上的,是一張虛擬的表。
- 視圖的創建
語句格式: CREATE VIEW視圖名(列表名) AS SELECT查詢子句 [WITH CHECK OPTION];
注意: 在視圖的創建中必須遵循以下規定。
- 子查詢可以是任意復雜的SELECT語句,但通常不允許含有ORDER BY子句和DISTINCT短語。
- WITH CHECK OPTION表示對UPDATE、INSERT、DELETE操作時保證更新、插入或刪除的行滿足視圖定義中的謂詞條件(即子查詢中的條件表達式)。
- 組成視圖的屬性列名或者全部省略或者全部指定。如果省略屬性列名,則隱含該視圖由SELECT子查詢目標列的主屬性組成。
3. SQL數據查詢
SQL的數據操縱功能包括Insert(插入)、Delete(刪除)、Update(修改)、Select(查詢),屬于數據庫操縱語言(DML)。
3.1 Select基本結構
語句格式: SELECT [ALL/DISTINCT]<目標列表達式[<目標列表達式>]…
FROM<表名或視圖名>[,<表名或視圖名>][WHERE<條件表達式>]
[GROUP BY<列名1>[HAVING<條件表達式>]][ORDER BY<列名2>[ASC|DESC]…]
其中Having只能與Group By搭配使用。
Where子句的條件表達式中可使用的運算符
| 類別 | 運算符 |
|---|---|
| 集合運算符 | In(在集合中)、Not ln(不在集合中) |
| 字符串匹配運算符 | Like (與_和%進行單個或多個字符匹配) |
| 空值比較運算符 | Is Null(為空)、Is Not Null(不為空) |
| 算術運算符 | >、>=、<、<=、=、 |
| 邏輯運算符 | And(與)、Or(或)、Not(非) |
3.2 連接查詢
連接查詢涉及兩個及以上表的查詢。連接運算有=、>、<、>=、<=、!=等。
3.4 子查詢與聚集查詢
子查詢: 子查詢也稱嵌套查詢,是指一個SELECT-FROM-WHERE查詢塊可以嵌入另一個查詢塊之中。
聚集函數
| 聚集函數名 | 功能 |
|---|---|
| Count([Distinct | All]*) |
| Count([Distinct | All]<列名>) |
| Sum([Distinct | All]<列名>) |
| Avg([Distinct | [All]<列名>) |
| Max([Distinct/All]<列名>) | 求一列值的最大值 |
| Min([Distinct | All]<列名>) |
3.5 分組查詢
Group By <列名> [Having <條件表達式>]將查詢結果按某一列或多列進行分組。
3.6 更名運算
SQL提供了可為關系和屬性重新命名的機制,使用“As”實現。
3.7 字符串操作
對于字符串進行的最常用的操作是模式匹配LlKE。使用兩個特殊的字符來描述模式:_“%"匹配任意字符串;“_”匹配任意一個字符。模式匹配是大小寫敏感的。
3.8 視圖查詢
系統執行該語句時,通常先將其轉換成等價的對基本表的查詢,然后執行查詢語句。
示例:Select Sno,Sname,Sage From CS_Student_View Where Sage <20;
4. 數據更新
4.1 插入
語句格式: INSERT INTO基本表名(字段名[,字段名]…) VALUES(常量[,常量]…);
4.2 刪除
語句格式:DELETE FROM基本表名[WHERE條件表達式];
4.3 修改
語句格式:UPDATE基本表名SET 列名=值表達式(,列名=值表達式…)[WHERE條件表達式];
5. 訪問控制
SQL標準包括Insert、Delete、Update和lSelect權限。Select權限對應于Read權限。
5.1 授權
語句格式: GRANT<權限>[,<權限>]…[ON<對象類型<對象名] TO <用戶>[<用戶>]… [WITH GRANT OPTION];
| 對象 | 對象類型 | 操作權限 |
|---|---|---|
| 屬性列 | Table | Insert、Delete、Updatc、Sclect、All Privileges(4種權限的總和) |
| 視圖 | Table | Inscrt、Deletc、Update、Select、All Privileges(4種權限的總和) |
| 基本表 | Table | Insert、Delete、Update、Select、Alter、Index、All Privileges (6種權限的總和) |
| 數據庫 | DataBase | CreateTab建立表的權限,可由DBA授予普通用戶 |
5.2 收回授權
語句格式:REVOKE<權限>[,<權限>]…[ON<對象類型><對象名>] FROM<用戶>[<用戶>]…;
五、關系數據庫的規范化
1. 函數依賴
關系數據庫設計的方法之一就是設計滿足合適范式的模式。關系數據庫規范化理論主要包括數據依賴、范式和模式設計方法。其中核心基礎是數據依賴,數據依賴中最重要、最基本的就是函數依賴。
1.1 函數依賴
設R(U)是屬性集U上的關系模式,X、Y是U的子集。若對R(U)的任何一個可能的關系r,r中不可能存在兩個元組在X上的屬性值相等,而在Y上的屬性值不等,則稱X函數決定Y或Y函數依賴于X,記作X→Y
1.2 部分函數依賴
如果X→Y,但Y不完全函數依賴于X,則稱Y對X部分函數依賴。
例子:(A,B)能確定C,A也能確定C,即(A,B)屬性集中的部分屬性(A)就可以確定C,則C部分函數依賴于(A,B)。
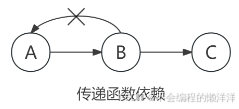
1.3 傳遞函數依賴
在R(U,F)中,如果X →Y,Y ? \subsetneq ? X,Y→Z,則稱Z對X傳遞依賴。其中,U:屬性集,F:是U上的一組函數依賴。
例子:若A→B,B→C,則A→C (B不能→A,防止直接A→C),則稱C傳遞函數依賴A。
函數依賴求候選鍵:從一個或一組屬性出發,通過函數依賴集中的依賴關系,能決定關系模式中的其他所有屬性,則這個屬性或屬性組為候選鍵。
-
求候選鍵最穩靠的辦法是
圖示法。圖示法求候選鍵的過程如下:
(1)將關系的函數依賴關系用“有向圖”的方式表示。
(2)找出入度為0的屬性,并以該屬性集合為起點,嘗試遍歷有向圖,若能正常遍歷圖中所有結點,則該屬性集即為關系模式的候選鍵。
(3)若入度為O的屬性集不能遍歷圖中所有結點,則需要嘗試性的將一些中間結點(既有入度,也有出度的結點)并入度為0的屬性集中,直至該屬性集合能遍歷所有結點,則該屬性集合為候選鍵 -
函數依賴求候選鍵第二種方法:
根據依賴集,找出從未在右邊出現過的屬性,必然是候選鍵之一,以該屬性為基礎,根據依賴集依次擴展,看能否遍歷所有屬性,若無法遍歷所有屬性,將無法遍歷的屬性加入候選鍵中。
1.4 函數依賴的公理系統(Armstrong公理系統)
設關系模式R(U,F),其中U為屬性集,F是U上的一組函數依賴,那么有以下推理規則。
- A1自反律: 若Y ? \subseteq ?X ? \subseteq ?U,則X→Y為F所蘊涵。
- A2增廣律:若X→Y為F所蘊涵,且Z ? \subseteq ?U,則XZ→ YZ為F所蘊涵。
- A3傳遞律:若X→Y, Y →Z為F所蘊涵,則X →Z為F所蘊涵。
根據以上三條推理規則,又可推出以下三條推理規則:
- 合并規則:若X→Y,X →z,則X→YZ為F所蘊含。
- 偽傳遞規則:若X →Y,wY →Z,則XW→Z為F所蘊含。
- 分解規則:若X →Y,Z ? \subseteq ? Y,則X→Z為F所蘊含。
2. 規范化
關系數據庫設計的方法之一就是設計滿足適當范式的模式,通常可以通過判斷分解后的模式達到幾范式來評價模式規范化的程度。范式有: 5 N F ? 4 N F ? B C N F ? 3 N F ? 2 N F ? 1 N F 5NF \subset 4NF\subset BCNF \subset 3NF \subset 2NF \subset 1NF 5NF?4NF?BCNF?3NF?2NF?1NF,其中級別越高,模式規范化程度也就越高。
2.1 1NF(第一范式)
定義:若關系模式R的每一個分量是不可再分的數據項,則關系模式R屬于第一范式。即屬性是原子不可再分的。
1NF存在的問題:數據冗余、插入異常、刪除異常等問題。
2.2 2NF(第二范式)
定義:若關系模式R ∈ \in ∈ 1NF,且每一個非主屬性完全(函數)依賴于碼,則關系模式R∈ 2NF。即每個非主屬性都由整個碼決定。當1NF消除了非主屬性對碼的部分函數依賴,則稱為2NF。
2.3 3NF(第三范式)
定義:若關系模式R(U,F)中不存在這樣的碼X,屬性組Y及非主屬性Z(Z ? \subsetneq ?Y)使得X→Y(Y ? \nrightarrow ?X),Y→Z成立,則關系模式R ∈ 3NF。即當2NF消除了非主屬性對碼的傳遞函數依賴,則稱為3NF。
2.4 BCNF(巴克斯范式)
BCNF是修正的第三范式。規定了每個屬性(包括主屬性)都不傳遞依賴于碼。即當3NF消除了主屬性對碼的部分函數依賴和傳遞函數依賴,則稱為BCNF。
2.5 4NF(第四范式)
4NF主要是消除了多值依賴。
3. 模式分解及分解特征
3.1 分解
模式分解:將一個關系模式分解為多個子模式。
模式分解就是模式規范化的工具,模式分解使用無損連接和保持函數依賴來衡量模式分解后是否導致原有模式中部分信息丟失。
3.2 無損鏈接
判定定理:關系模式R(U,F)的一個分解 ρ \rho ρ={R1(U1,F1),R2(U2,F2).…, Rk(Uk ,Fk)}具有無損連接的充分必要條件是U1 ∩ \cap ∩U2→ U1 - U2 ∈ F+ 或 U1 ∩ \cap ∩ U2→U2 - U1∈ F+。
F是模式分解后子模式函數依賴集的并集。
3.3 保持函數依賴
定義:關系模式R(U,F)的一個分解 ρ \rho ρ={R1(U1,F1),R2(U2,F2).…, Rk(Uk ,Fk)},如果F+ =(Uki=1 π \pi πRi(F+)),則稱分解 ρ \rho ρ保持函數依賴。(分解后的子模式函數依賴集的并集是否保持了原來的函數依賴集,即F+= F )
保持函數依賴,就是模式分解后的F+(各個子模式函數依賴集的并集)是否與F(原有的函數依賴集)等價。F+包含所有F中的函數依賴,則可以得出保持函數的依賴性(充分條件)。如果F+不顯式包含F中的函數依賴,還需進一步判斷,判斷方法有兩條:
- 第一種是通過F+中的屬性閉包去求,是否蘊含函數依賴(這種方法要求做函數投影時,不能缺項);
- 第二種使用給定的算法去求,對投影要求簡單,但過程特別麻煩。
六、數據庫的控制功能
1. 事務管理
事務是DBMS的基本工作單位,是由用戶定義的一個操作序列。
事務的定義語句有:Begin Transaction(事務開始)、Commit(事務提交,表示事務成功地結束)、Rollback
(事務回滾,表示事務非成功地結束〉。
事務的ACID性質:
(1)原子性(Atomicity) :要么都做,要么都不做。
(2)一致性(Consistcncy):事務執行的結果必須從一個一致性狀態轉到另一個一致性狀態。中間狀態對外不可見。
(3)隔離性(Isolation) :事務之間相互隔離,互不干擾。
(4)持久性(Durability):事務成功提交后,對數據庫的更新操作是永久有效的。
2. 數據庫的備份與恢復
2.1 數據庫故障類型
①事務內部故障: 如運算溢出、除零錯誤、并發事務發生死鎖等
②系統故障: 也稱為軟故障,是指造成系統停運的事件,如CPU故障、OS故障、突然停電等
③介質故障: 也稱為硬故障,如磁盤損壞等
④計算機病毒
2.2 數據庫的備份方法
數據庫的轉儲分為靜態轉儲和動態轉儲,海量轉儲、增量轉儲和差量轉儲,以及日志文件。
-
靜態轉儲: 即
冷備份,指在轉儲期間不允許對數據庫進行任何存取、修改操作。
優點是非常快速、容易歸檔(直接物理復制操作)。
缺點是只能提供到某一時間點上的恢復,不能做其他工作,不能按表或按用戶恢復。 -
動態轉儲: 即
熱備份,在轉儲期間允許對數據庫進行存取、修改操作,因此,轉儲和用戶事務可以并發執行。
優點是可在表空間或數據庫文件級備份,數據庫仍可使用,可達到秒級恢復。缺點是不能出錯,否則后果嚴重,若熱備份不成功,所得結果幾乎全部無效。 -
海量轉儲(完全轉儲): 是指每次轉儲全部數據庫。
-
增量轉儲: 是指每次只轉儲上次轉儲后更新過的數據,用于數據庫很大,事務處理頻繁的場景。·差量轉儲:是對最近一次數據庫完全備份以來發生的數據變化進行備份,優點是速度快,占用較小的時間和空間。
-
日志文件: 在事務處理過程中,DBMS把事務開始、事務結束以及對數據庫的插入、刪除和修改的每一次操作寫入日志文件。一旦發生故障,DBMS的恢復子系統利用日志文件撤銷事務對數據庫的改變,回退到事務的初始狀態。
3. 并發控制
并發操作就是在多用戶系統中,可能出現多個事務同時操作同一數據的情況。并發操作會導致3種數據不一致的問題:
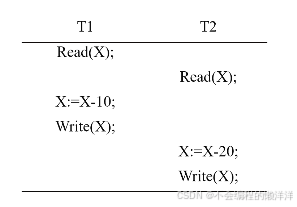
3.1 丟失修改(丟失更新)
把兩個事務T1和T2讀入同一數據做修改,并發執行時,T1把T2,或T2把T1,的修改結果覆蓋掉,造成了數據的丟失更新問題,導致數據不一致。
3.2 不可重復讀
事務T1讀取了數據R,事務T2讀取并更新了數據R。當事務T1再讀取數據R以進行核對時,得到的兩次讀取數據不一致。

3.3 讀臟數據
事務T1更新了數據R,事務T2讀取了更新后的數據R,事務T1由于某種原因被撤銷,進行了事務回滾,數據R恢復原值,事務T2讀取了臟數據。

造成以上3種數據不一致的主要原因是事務的并發操作破壞了事務的隔離性。
3.4 并發控制技術
并發控制的主要技術是封鎖(Lock)技術
| 基本鎖類型 | 特點 |
|---|---|
| 排他鎖(X鎖) | 事務T對數據A加X鎖: (1)只允許務T讀取、修改數據A; (2)只有等該鎖解除之后,其他事務才能夠對數據A加任何鎖類型。解決了X鎖太嚴格,不允許其他事務并發讀的問題。 |
| 共享鎖(S鎖) | 事務T對數據A加S鎖,則: (1)只允許事務T讀取數據A但不能夠修收; (2)可允許其他事務對其加S鎖,但不允許加X鎖。 |



)



![[ctfshow web入門] 零基礎版題解 目錄(持續更新中)](http://pic.xiahunao.cn/[ctfshow web入門] 零基礎版題解 目錄(持續更新中))











