今天讓我們完結高級OpenGL的部分:
Instancing

很多時候,在場景中包含有大量實例的時候,光是調用GPU的繪制函數這個過程都會帶來非常大的開銷,因此我們需要想辦法在每一次調用GPU的繪制函數時盡可能多地繪制,這個過程就是我們的實例化。

具體來說,我們來看調用glDrawArraysInstanced函數的代碼:
float quadVertices[] = {// 位置 // 顏色-0.05f, 0.05f, 1.0f, 0.0f, 0.0f,0.05f, -0.05f, 0.0f, 1.0f, 0.0f,-0.05f, -0.05f, 0.0f, 0.0f, 1.0f,-0.05f, 0.05f, 1.0f, 0.0f, 0.0f,0.05f, -0.05f, 0.0f, 1.0f, 0.0f, 0.05f, 0.05f, 0.0f, 1.0f, 1.0f
}; 這是我們的頂點數組,二維的位置坐標和三維的RGB顏色值。
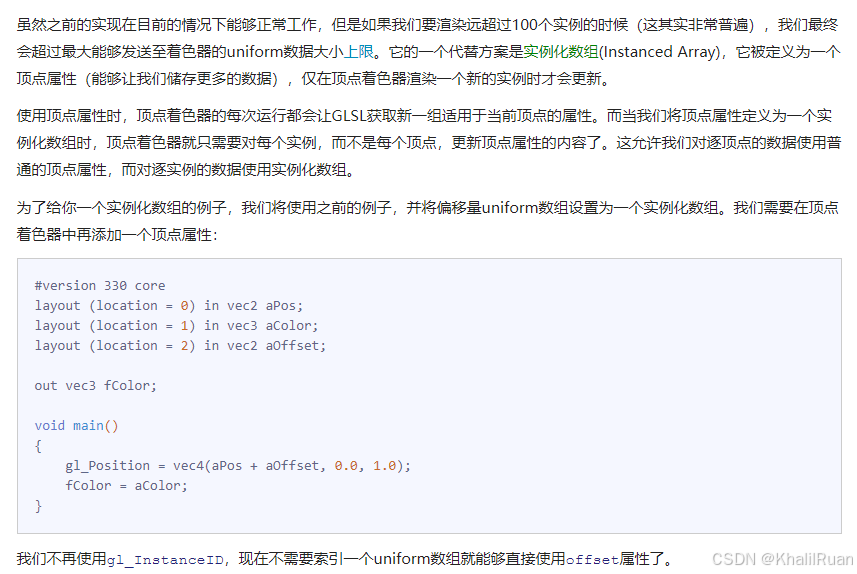
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;out vec3 fColor;uniform vec2 offsets[100];void main()
{vec2 offset = offsets[gl_InstanceID];gl_Position = vec4(aPos + offset, 0.0, 1.0);fColor = aColor;
}這個就是我們的頂點著色器,能夠看到我們有一個uniform偏移量數組,我們用gl_InstanceID作為數組的索引。就像我們之前所言,gl_InstanceID是一個自增的內建變量,我們使用這個變量可以省去一個for循環的過程,當然,前提是我們調用glDrawArraysInstanced函數。
glBindVertexArray(quadVAO);
glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);我們調用glDrawArraysInstanecd和glDrawArrays的方式沒有區別,只是多了一個實例的數目,這里我們是100,這樣的話我們的gl_InstanceID就會從0自增到100。
雖然這種直接在著色器里定義好偏差數組的做法非常的方便快捷,但是顯然在真正的應用中,我們需要的實例數量還會不斷提高。作為定義在著色器里的uniform類型變量是有自己的數據的上限的,這個時候我們就需要去尋找新的方法來解決這個問題,這個新的方法就是實例化數組。
我們用一個代碼實例就能知道效果如何:
// generate a list of 100 quad locations/translation-vectors
// ---------------------------------------------------------glm::vec2 translations[100];int index = 0;float offset = 0.1f;for (int y = -10; y < 10; y += 2){for (int x = -10; x < 10; x += 2){glm::vec2 translation;translation.x = (float)x / 10.0f + offset;translation.y = (float)y / 10.0f + offset;translations[index++] = translation;}}在這里我們定義了一個大小為100的二維向量數組,他們的每一個值都不一樣。
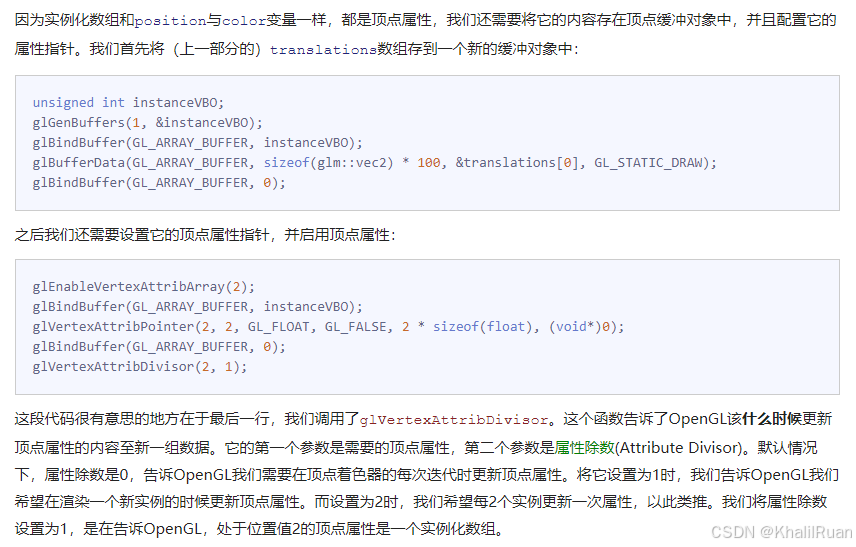
unsigned int instanceVBO;glGenBuffers(1, &instanceVBO);glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW);glBindBuffer(GL_ARRAY_BUFFER, 0);我們專門生成一個VBO對象去把這些值加載進緩沖中。
float quadVertices[] = {// positions // colors-0.05f, 0.05f, 1.0f, 0.0f, 0.0f,0.05f, -0.05f, 0.0f, 1.0f, 0.0f,-0.05f, -0.05f, 0.0f, 0.0f, 1.0f,-0.05f, 0.05f, 1.0f, 0.0f, 0.0f,0.05f, -0.05f, 0.0f, 1.0f, 0.0f,0.05f, 0.05f, 0.0f, 1.0f, 1.0f};這是我們具體的頂點數組,每個頂點有兩個屬性:位置和顏色,其實一個是二維向量一個是三維向量。
unsigned int quadVAO, quadVBO;glGenVertexArrays(1, &quadVAO);glGenBuffers(1, &quadVBO);glBindVertexArray(quadVAO);glBindBuffer(GL_ARRAY_BUFFER, quadVBO);glBufferData(GL_ARRAY_BUFFER, sizeof(quadVertices), quadVertices, GL_STATIC_DRAW);glEnableVertexAttribArray(0);glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)0);glEnableVertexAttribArray(1);glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)(2 * sizeof(float)));// also set instance dataglEnableVertexAttribArray(2);glBindBuffer(GL_ARRAY_BUFFER, instanceVBO); // this attribute comes from a different vertex bufferglVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);glBindBuffer(GL_ARRAY_BUFFER, 0);glVertexAttribDivisor(2, 1); // tell OpenGL this is an instanced vertex attribute.這里我們定義并配置我們的VAO對象和VBO對象,注意我們的VBO的配置過程中,我們把location為0和1的數據交給了我們的quadVBO,而到了location為2的第三個對象實例化數據,我們切換VBO對象為instanceVBO,然后我們還調用了glVertexAttribDivisor函數:這個函數用于告訴GPU我們的實例ID(就是那個內建變量gl_InstanceID)每隔一個實例更新一次(2代表location,1則是隔1個實例自增一次)。
搭配上我們的頂點著色器的定義:
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aOffset;out vec3 fColor;void main()
{fColor = aColor;gl_Position = vec4(aPos + aOffset, 0.0, 1.0);
}效果如圖:

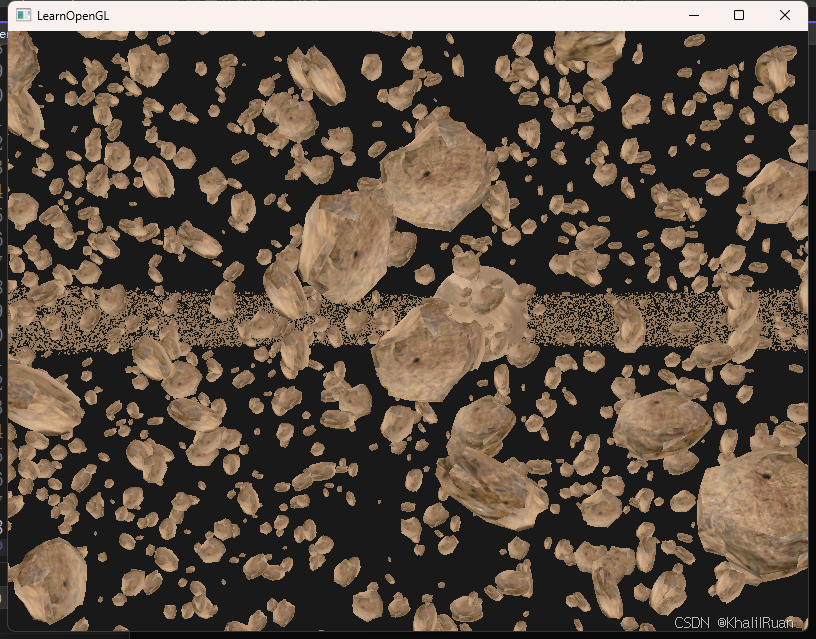
現在讓我們來上點強度,我們把需要渲染的模型的數量提高N個數量級:我們來生成一個小行星帶的效果。
小行星帶,顯然難的不是行星而是行星帶比較難處理,當我們想象行星帶時,我們很容易想到大量的碎石,顯然這些碎石的數量遠遠大小我們的Uniform的數據大小上限(非常大的數量級)。
unsigned int amount = 100000;glm::mat4* modelMatrices;modelMatrices = new glm::mat4[amount];srand(static_cast<unsigned int>(glfwGetTime())); // initialize random seedfloat radius = 150.0;float offset = 25.0f;for (unsigned int i = 0; i < amount; i++){glm::mat4 model = glm::mat4(1.0f);// 1. translation: displace along circle with 'radius' in range [-offset, offset]float angle = (float)i / (float)amount * 360.0f;float displacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;float x = sin(angle) * radius + displacement;displacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;float y = displacement * 0.4f; // keep height of asteroid field smaller compared to width of x and zdisplacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;float z = cos(angle) * radius + displacement;model = glm::translate(model, glm::vec3(x, y, z));// 2. scale: Scale between 0.05 and 0.25ffloat scale = static_cast<float>((rand() % 20) / 100.0 + 0.05);model = glm::scale(model, glm::vec3(scale));// 3. rotation: add random rotation around a (semi)randomly picked rotation axis vectorfloat rotAngle = static_cast<float>((rand() % 360));model = glm::rotate(model, rotAngle, glm::vec3(0.4f, 0.6f, 0.8f));// 4. now add to list of matricesmodelMatrices[i] = model;}我們生成10萬個模型變換矩陣,然后將其坐標設置為繞著圓心的圓上。
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 2) in vec2 aTexCoords;
layout (location = 3) in mat4 aInstanceMatrix;out vec2 TexCoords;uniform mat4 projection;
uniform mat4 view;void main()
{TexCoords = aTexCoords;gl_Position = projection * view * aInstanceMatrix * vec4(aPos, 1.0f);
}這里我們把模型變化矩陣作為一個變量傳進頂點著色器,注意我們傳的是一個mat4變量,而頂點著色器的大小上限是一個vec4變量(mat4是4個vec4),所以我們需要進行一些額外的處理。
// configure instanced array// -------------------------unsigned int buffer;glGenBuffers(1, &buffer);glBindBuffer(GL_ARRAY_BUFFER, buffer);glBufferData(GL_ARRAY_BUFFER, amount * sizeof(glm::mat4), &modelMatrices[0], GL_STATIC_DRAW);// set transformation matrices as an instance vertex attribute (with divisor 1)// note: we're cheating a little by taking the, now publicly declared, VAO of the model's mesh(es) and adding new vertexAttribPointers// normally you'd want to do this in a more organized fashion, but for learning purposes this will do.// -----------------------------------------------------------------------------------------------------------------------------------for (unsigned int i = 0; i < rock.meshes.size(); i++){unsigned int VAO = rock.meshes[i].VAO;glBindVertexArray(VAO);// set attribute pointers for matrix (4 times vec4)glEnableVertexAttribArray(3);glVertexAttribPointer(3, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)0);glEnableVertexAttribArray(4);glVertexAttribPointer(4, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(sizeof(glm::vec4)));glEnableVertexAttribArray(5);glVertexAttribPointer(5, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(2 * sizeof(glm::vec4)));glEnableVertexAttribArray(6);glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(3 * sizeof(glm::vec4)));glVertexAttribDivisor(3, 1);glVertexAttribDivisor(4, 1);glVertexAttribDivisor(5, 1);glVertexAttribDivisor(6, 1);glBindVertexArray(0);}我們可以看到,我們生成VBO之后,我們從指向模型變換矩陣的數組指針開始,我們需要單獨取出每個子碎石的VAO來綁定龐大的模型變換矩陣數組,我們從layout=3的位置開始一行一行地讀取,然后每一個實例都要更新一個實例ID,因為一個頂點數據的最大大小為vec4,所以我們需要四個頂點數據組成完整的mat4變量。這樣做的意思其實就是我們將多達十萬個mat4的數據量直接一次性全部傳入緩存中,這樣的話我們只用單獨Draw Call一次就可以繪制所有的碎石。
效果如圖:
Anti Aliasing
抗鋸齒已經是一個經久不衰的老問題了:

很喜歡閆老師的一句話:世界上所有的失真現象都可以歸結為采樣率不足。
SSAA事實上某種程度來說也算是一種針對抗鋸齒的通解,用更高的算力開銷來從根本上解決問題,但是我們如果想要真正體現出思想優越之處的做法,那就得從頭開始做。
為了理解什么是多重采樣(Multisampling),以及它是如何解決鋸齒問題的,我們有必要更加深入地了解OpenGL光柵器的工作方式。
光柵器是位于最終處理過的頂點之后到片段著色器之前所經過的所有的算法與過程的總和。光柵器會將一個圖元的所有頂點作為輸入,并將它轉換為一系列的片段。頂點坐標理論上可以取任意值,但片段不行,因為它們受限于你窗口的分辨率。頂點坐標與片段之間幾乎永遠也不會有一對一的映射,所以光柵器必須以某種方式來決定每個頂點最終所在的片段/屏幕坐標。

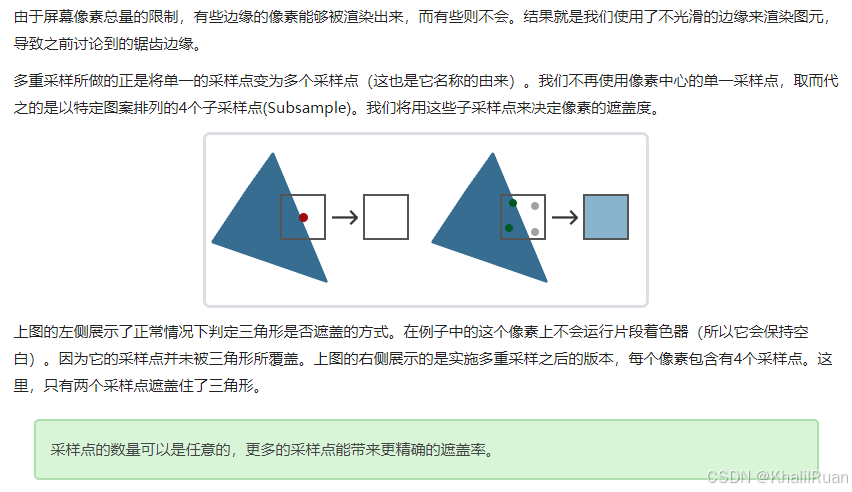
是的,多重采樣的本質就是提高每個像素的采樣點數量,這樣我們可以更清晰地了解具體某個像素有多少個采樣點被采樣,從而體現出顏色的層次并大大減少鋸齒數量。


明白了我們的多重采樣的基本原理之后,讓我們回到OpenGL之中的抗鋸齒技術。
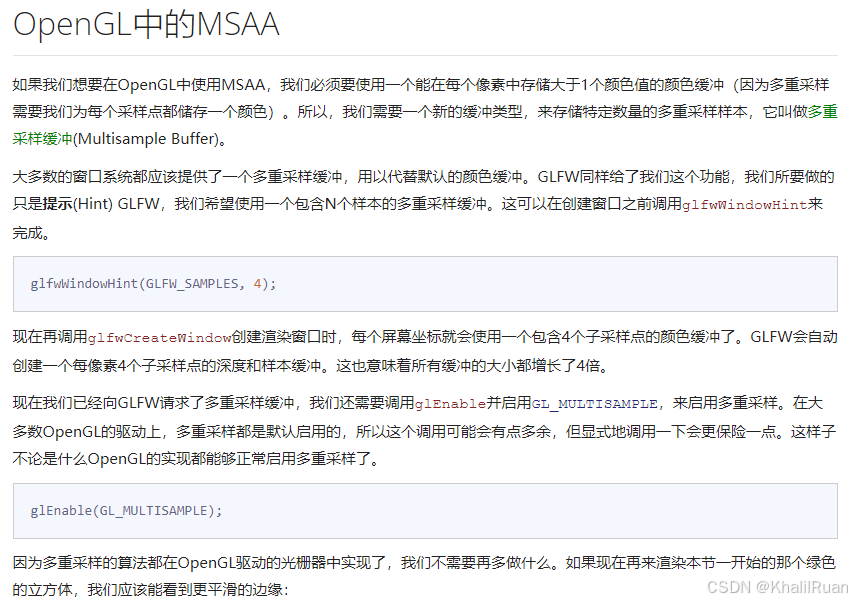
我們的OpenGL之中已經幫我們定義好了MSAA方法,所以我們只需要在生成窗口系統時去顯示地寫明我們的采樣緩沖數量即可,需要注意的是,這里的緩沖是包含所有的幀緩沖,也就是除了顏色緩沖以外還有深度緩沖和模板緩沖。
由于后續的OpenGL課程中并沒有展開對抗鋸齒算法的詳細介紹與具體優化,我也就不再浪費篇幅。





)
)



裝飾器模式)



回溯篇4)
)


、系統保護規則、限流后統一處理及sentinel持久化配置)
