中文大模型基準測評2024上半年報告
原創?SuperCLUE?CLUE中文語言理解測評基準?2024年07月09日 18:09?浙江

SuperCLUE團隊
2024/07
背景
自2023年以來,AI大模型在全球范圍內掀起了有史以來規模最大的人工智能浪潮。進入2024年,全球大模型競爭態勢日益加劇,隨著GPT-4o、Claude3.5、Gemini1.5-pro和Llama3的發布,國內大模型同樣在2024年上半年內進行了波瀾壯闊的大模型追逐賽。中文大模型測評基準SuperCLUE持續對國內外大模型的發展趨勢和綜合效果進行了實時跟蹤。
基于此,我們發布了《中文大模型基準測評2024上半年報告》,在AI大模型發展的巨大浪潮中,通過多維度綜合性測評,對國內外大模型發展現狀進行觀察與思考。
點擊文章底部【閱讀原文】查看高清完整PDF版。
在線完整報告地址(可下載):
www.cluebenchmarks.com/superclue_24h1
![]()
報告核心內容摘要
摘要1:國內外大模型差距進一步縮小
國內外大模型差距進一步縮小:OpenAI最新模型GPT-4o依然是全球表現最好的模型,但國內大模型已將差距縮小至5%以內。
摘要2:國內開源模型崛起
本次登頂SuperCLUE的國內大模型為開源模型Qwen2-72B-Instruct,并且超過了眾多國內外閉源模型。
摘要3:國內開源模型崛起
在文科、理科和Hard任務中,GPT-4o綜合最佳,Claude-3.5在Hard任務表現突出,Qwen2-72B在文科任務表現優異。
摘要4:端側小模型表現驚艷
端側小模型進展迅速,部分小尺寸模型表現要好于上一代的稍大尺寸模型,極大提升了落地的可行性。
詳情請查看#正文或完整報告。
目錄
一、國內大模型關鍵進展
1.?2023-2024年大模型關鍵進展
2.?2024年值得關注的中文大模型全景圖
3. 2023-2024年度國內外大模型技術發展趨勢
二、SuperCLUE通用能力測評
1. 中文大模型基準SuperCLUE介紹
2. SuperCLUE測評體系及數據集說明
3.?測評模型列表
4. SuperCLUE通用能力測評:一級總分
5.?SuperCLUE通用能力測評:二級維度分數
6.?SuperCLUE通用能力測評:三級細粒度分數
7. SuperCLUE模型象限
8. 國內大模型SuperCLUE歷屆Top3
9. 理科測評
10.?文科測評
11. Hard測評
12.?SuperCLUE開源榜單
13.?SuperCLUE端側小模型榜單
14.?大模型對戰勝率分布圖
15. SuperCLUE成熟度指數
16.?評測與人類一致性驗證
三、SuperCLUE多模態能力測評
1.AIGVBench視頻生成測評
2.SuperCLUE-Image文生圖測評
3.SuperCLUE-V多模態理解測評
四、SuperCLUE專項與行業測評
1. 專項基準:SuperCLUE-Math6數學推理
2. 專項基準:SuperCLUE-Coder代碼助手
2. 專項基準:SuperCLUE-RAG檢索增強生成
3. 專項基準:SuperCLUE-Code3代碼生成
4. 專項基準:SuperCLUE-Agent智能體
5. 專項基準:SuperCLUE-Safety安全
6. 專項基準:SuperCLUE-200K超長文本
7. 專項基準:SuperCLUE-Role角色扮演
8. 專項基準:SuperCLUE-Video文生視頻
9. 行業基準:SuperCLUE-Auto汽車
11. 行業基準:SuperCLUE-Fin金融
12. 行業基準:SuperCLUE-Industry工業
13. 行業基準:SuperCLUE-ICabin智能座艙
14. 競技場:瑯琊榜對戰結果及分析
15.?未來兩個月基準發布計劃
五、優秀模型案例介紹
1. 優秀模型案例介紹
正文? ? ??
? ?
一、國內大模型關鍵進展
1.?2023年大模型關鍵進展與中文大模型全景圖
國內學術和產業界在過去一年半也有了實質性的突破。大致可以分為三個階段,即準備期(ChatGPT發布后國內產學研迅速形成大模型共識)、成長期(國內大模型數量和質量開始逐漸增長)、爆發期(各行各業開源閉源大模型層出不窮,形成百模大戰的競爭態勢)。

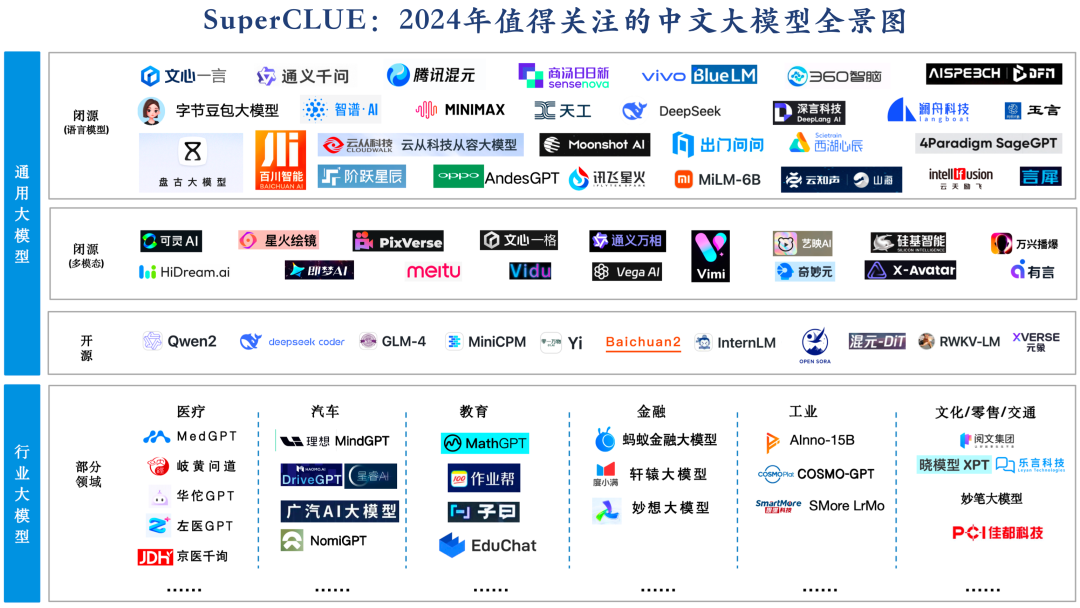
2.?2024年值得關注的中文大模型全景圖
截止目前為止,國內已發布開源、閉源通用大模型及行業大模型已有上百個,SuperCLUE梳理了2024年值得關注的大模型全景圖。
3. 2023-2024年度國內外大模型技術發展趨勢
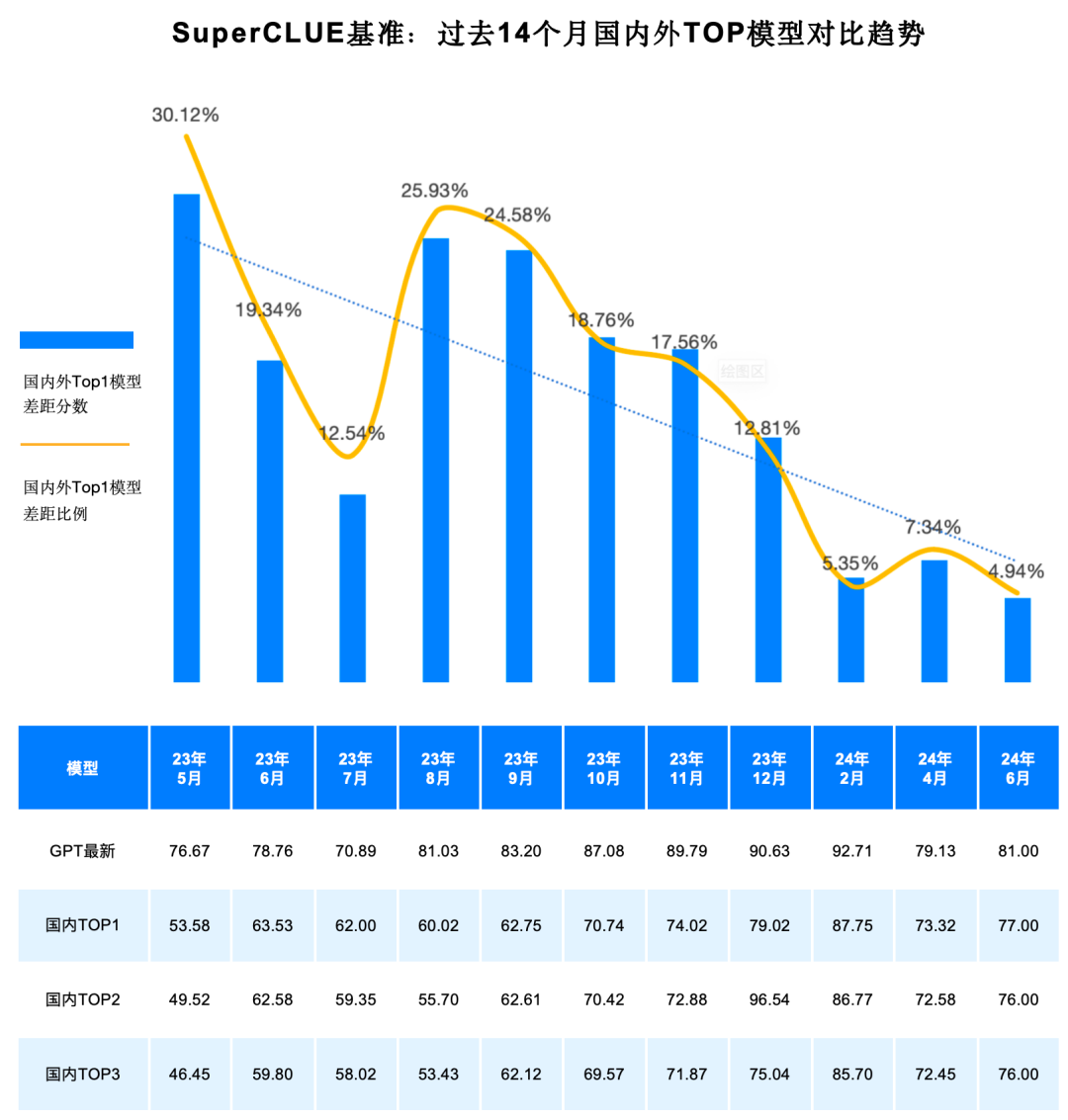
2023年5月至今,國內外大模型能力持續發展。其中GPT系列模型為代表的海外最好模型經過了從GPT3.5、GPT4、GPT4-Turbo、GPT4o的多個版本的迭代升級。國內模型也經歷了波瀾壯闊的14個月的迭代周期,其中Top1的模型經歷了8次易主,不斷提升國內模型的最強戰力。
總體趨勢上,國內外第一梯隊大模型在中文領域的通用能力差距在持續縮小,從2023年5月的30.12%的差距,縮小至2024年6月的4.94%。
來源:SuperCLUE,2024年7月9日
二、SuperCLUE通用能力測評
1.?中文大模型基準SuperCLUE介紹
中文語言理解測評基準CLUE(The Chinese Language Understanding Evaluation)是致力于科學、客觀、中立的語言模型評測基準,發起于2019年。陸續推出CLUE、FewCLUE、KgCLUE、DataCLUE等廣為引用的測評基準。
SuperCLUE是大模型時代CLUE基準的發展和延續。聚焦于通用大模型的綜合性測評。SuperCLUE根據多年的測評經驗,基于通用大模型在學術、產業與用戶側的廣泛應用,構建了多層次、多維度的綜合性測評基準。
傳統測評與SuperCLUE的區別
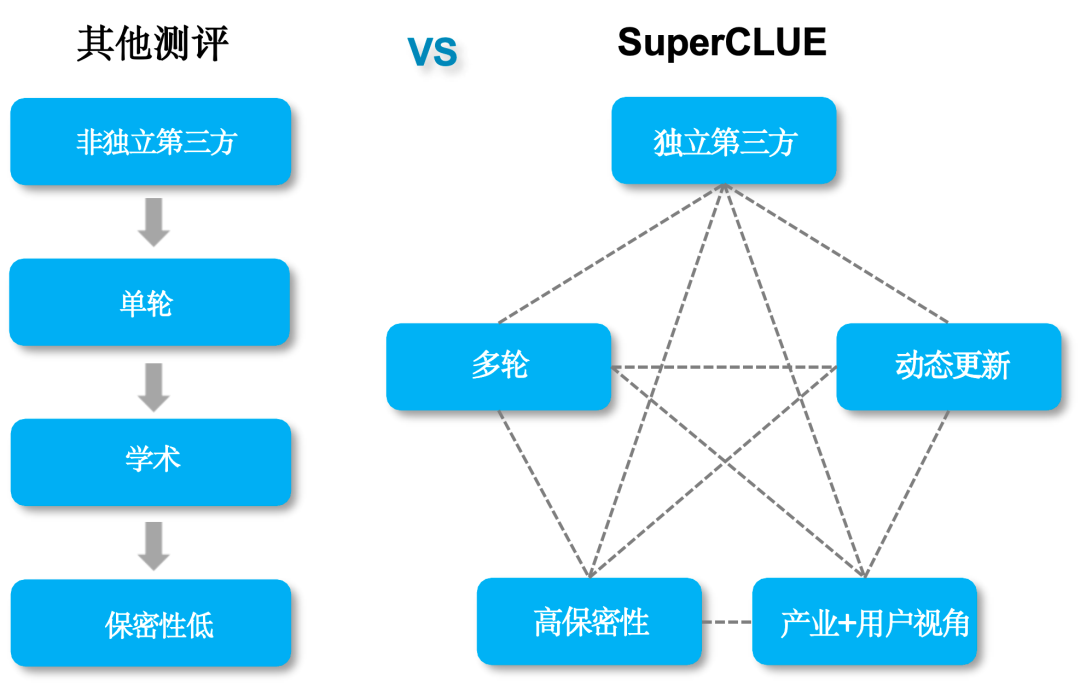
SuperCLUE三大特征
1)?獨立第三方測評,非大模型方主導
隨著國內外大模型的競爭日益激烈,模型開發方主導的評測可能存在偏向自家產品的風險。與之形成鮮明對比的是,SuperCLUE作為一個完全獨立的第三方評測機構,承諾提供無偏倚的客觀評測結果。SuperCLUE采用先進的自動化評測技術,有效消除人為因素帶來的不確定性,確保每一項評測都公正無私。
2)?測評方式與真實用戶體驗目標一致
不同于傳統測評通過選擇題形式的測評,SuperCLUE目標是與真實用戶體驗目標保持一致,所以納入了開放主觀問題的測評。通過多維度多視角多層次的評測體系以及對話的形式,模擬大模型的應用場景,真實有效的考察模型生成能力。
3) “live”更新,測評體系/方法與時俱進
不同于傳統學術領域的評測,SuperCLUE根據全球的大模型技術發展趨勢,不斷升級迭代測評體系、測評維度和方法,以保證盡可能精準量化大模型的技術演進程度。
2.?SuperCLUE測評體系及數據集說明
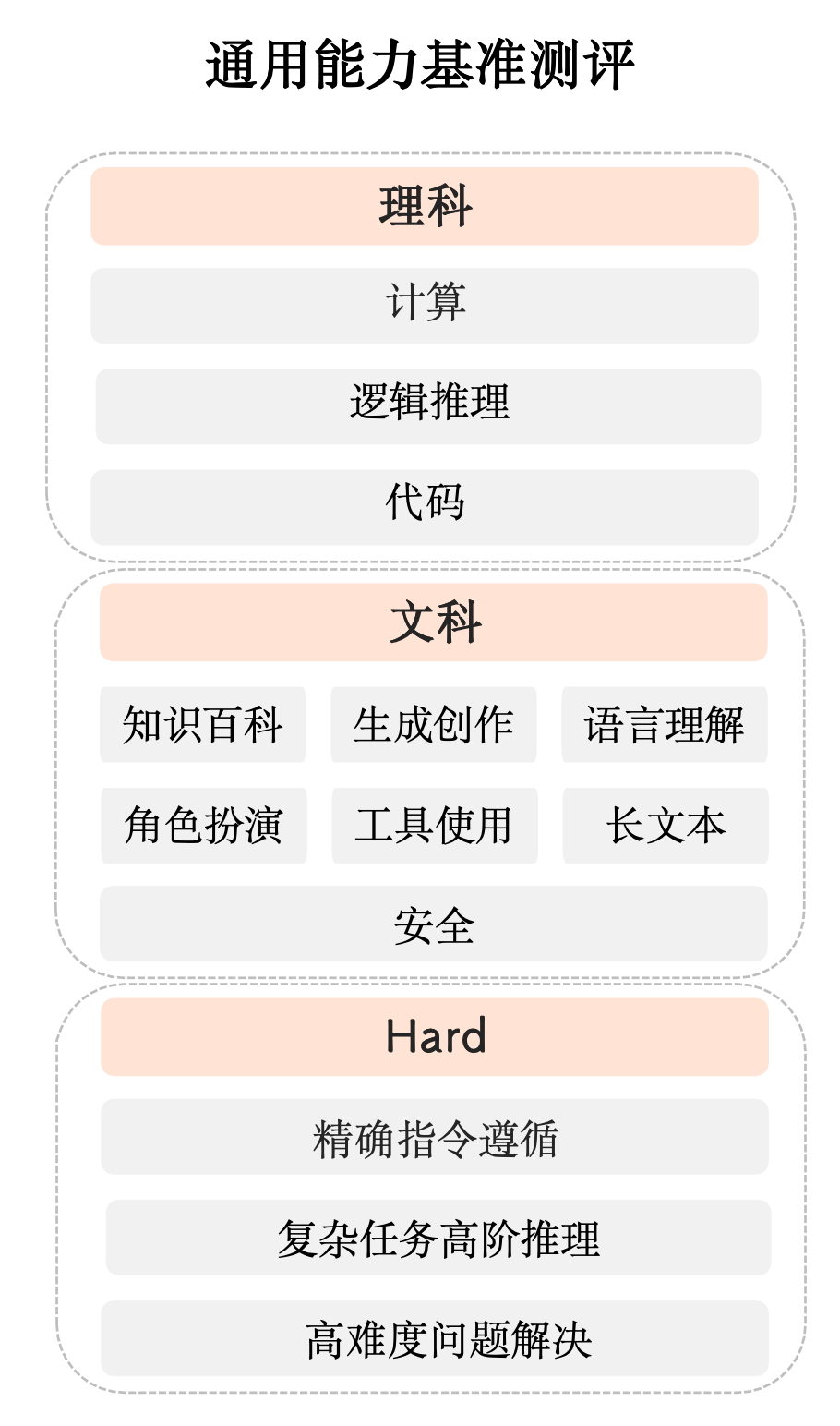
為進一步真實反應大模型能力,本次半年度測評采用多維度、多層次的綜合性測評方案,由理科、文科和Hard三大維度構成。
【理科任務】分為計算、邏輯推理、代碼測評集;
【文科任務】分為知識百科、語言理解、長文本、角色扮演、生成與創作、安全和工具使用七大測評集;
【Hard任務】本次測評首次納入精確指令遵循測評集,另外復雜多步推理和高難度問題解決Hard測評集后續陸續推出。

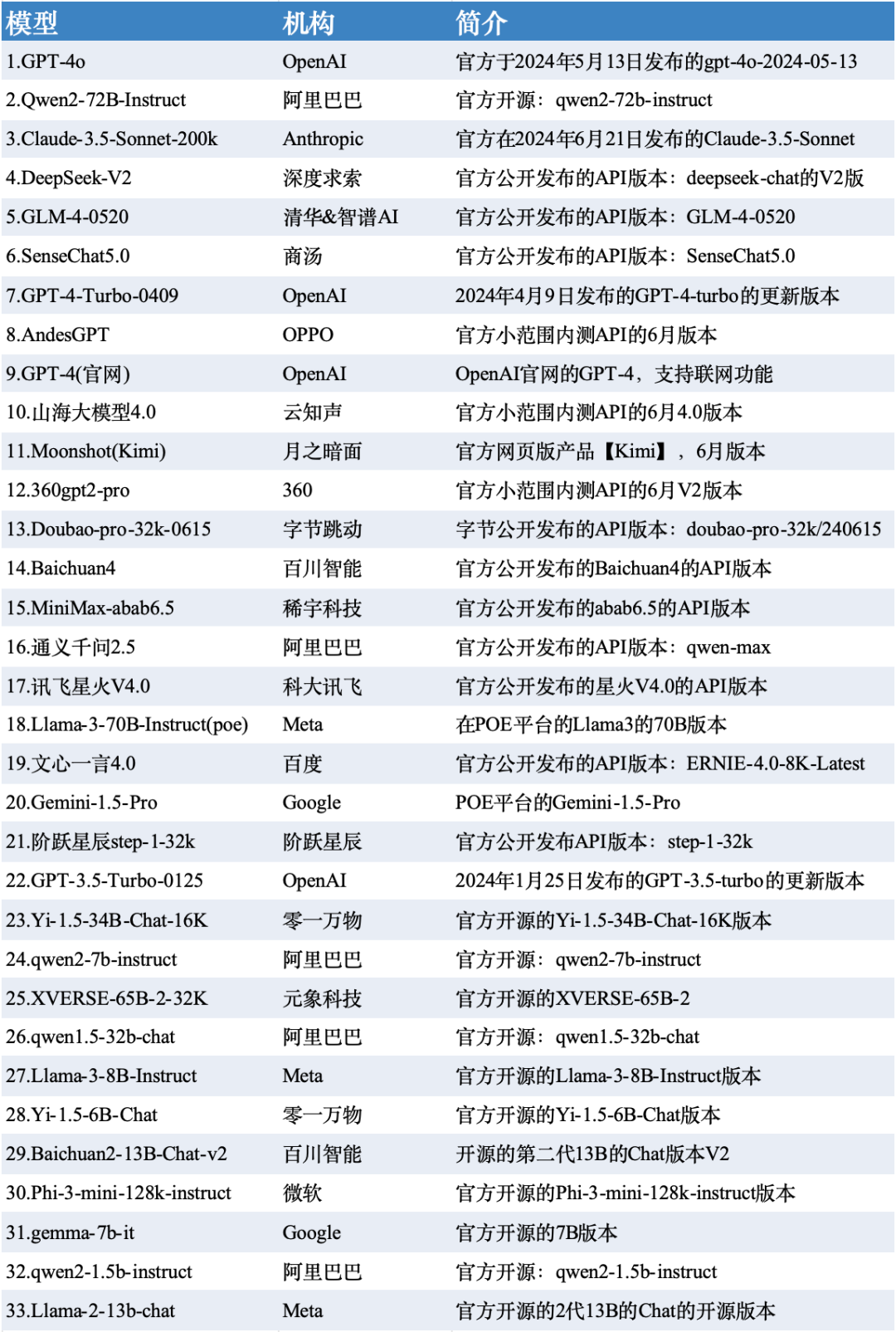
3. 測評模型列表
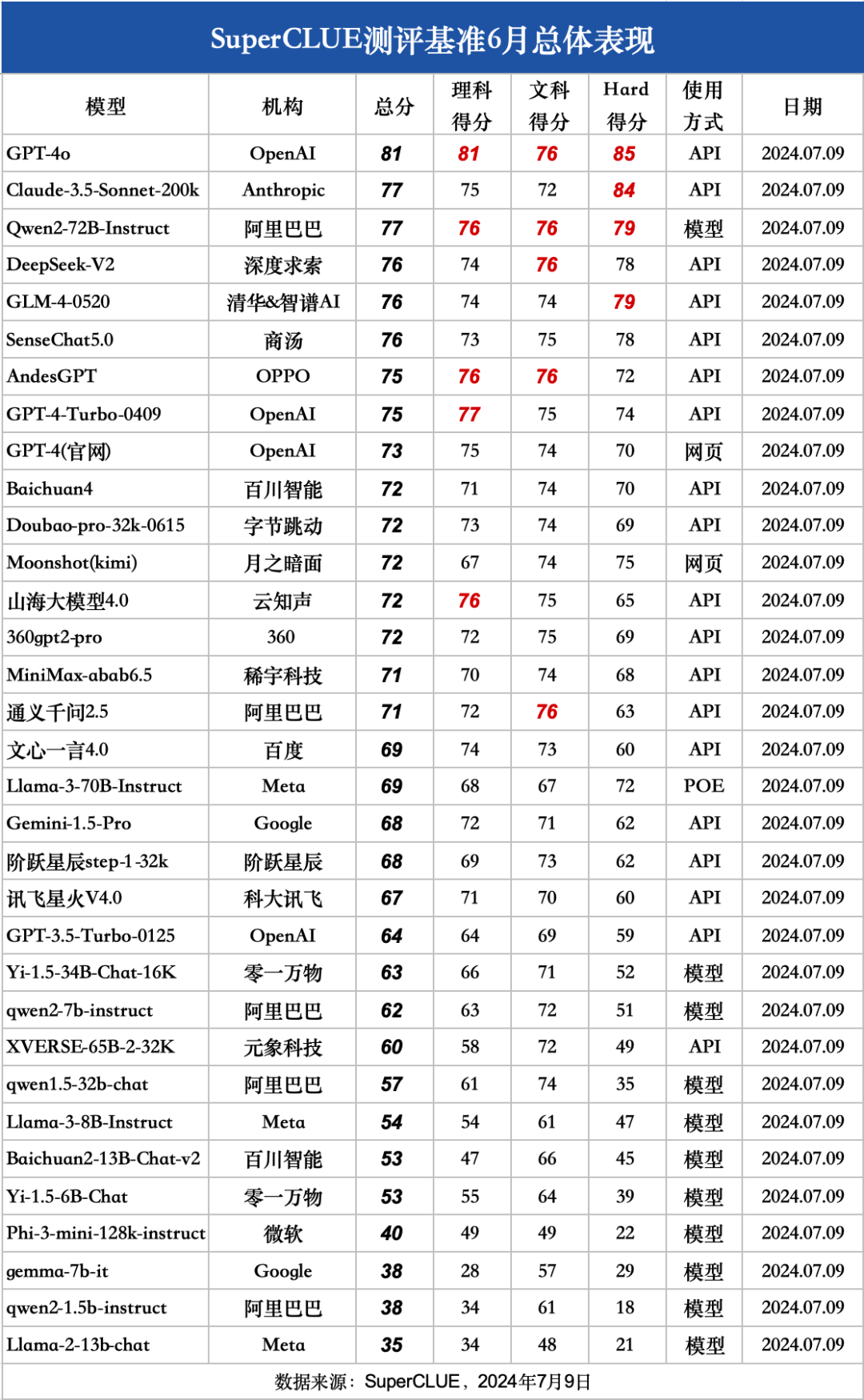
本次測評數據選取了SuperCLUE-6月測評結果,模型選取了國內外有代表性的33個大模型在6月份的版本。
4.SuperCLUE通用能力測評:一級總分
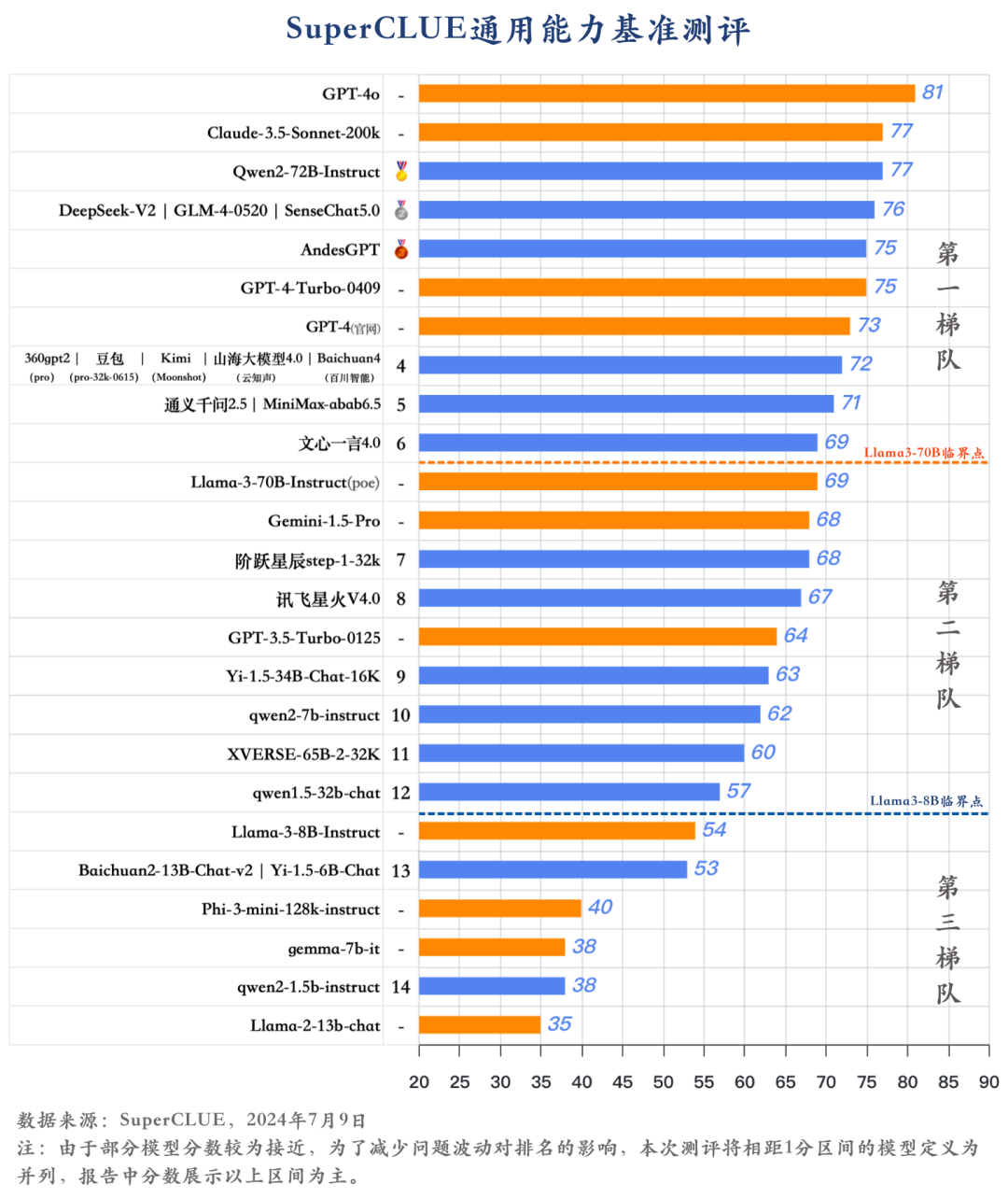
1)GPT-4o領跑,國內大模型進展迅速
-
GPT-4o以81分的絕對優勢領跑 SuperCLUE基準測試,是全球模型中唯一超過80分的大模型。展現出強大的語言、數理和指令遵循能力。
-
國內大模型上半年發展非常迅速,其中有6個國內大模型超過GPT-4-Turbo-0409。絕大部分閉源模型已超過GPT-3.5-Turbo-0125。
2)國內大模型形成三大梯隊,頭部企業引領發展
-
國內大模型市場形成多梯隊格局,頭部企業憑借快速迭代、技術積累或資源優勢,引領國內大模型發展。例如大廠模型以阿里的Qwen2-72B、商湯的SenseChat5.0等均以 75+的分數位居國內大模型第一梯隊。
-
大模型創業公司的代表如GLM-4、Baichuan4、Kimi、MiniMax-abab6.5均有超過70分的表現,位列國內大模型第一梯隊。
3)開源模型極大發展,有超出閉源模型趨勢
-
開源模型Qwen2-72B在SuperCLUE基準中表現非常出色,超過眾多國內外閉源模型,與Claude-3.5持平,與GPT-4o僅差4分。
-
零一萬物推出的Yi-1.5-34B在開源領域表現不俗,有超過60分的表現,較為接近部分閉源模型。
隨著技術進步和應用場景拓展,2024年下半年國內外大模型市場競爭將持續加劇,推動技術創新和產業升級。
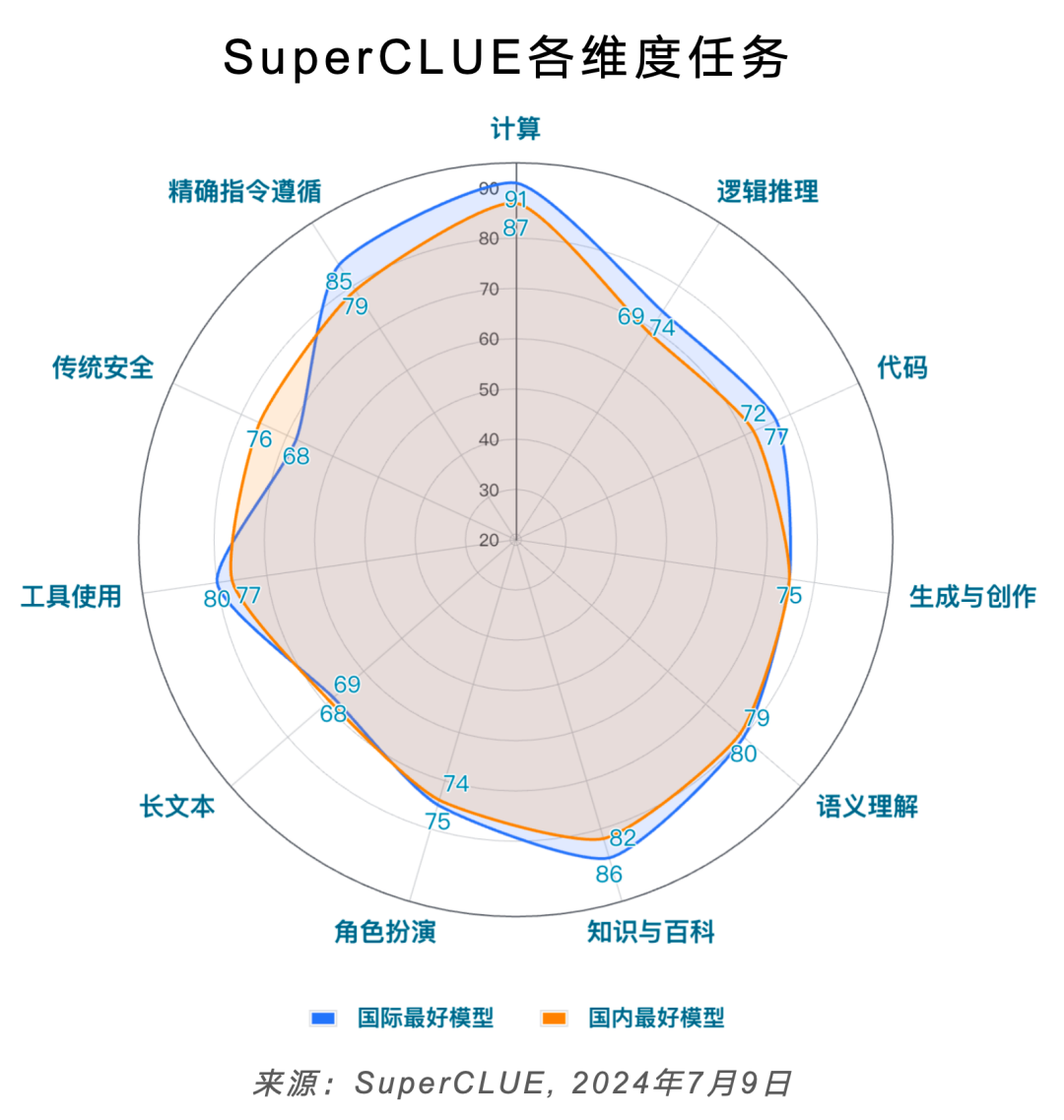
5.SuperCLUE通用能力測評:二級維度分數
6.SuperCLUE通用能力測評:三級細粒度分數
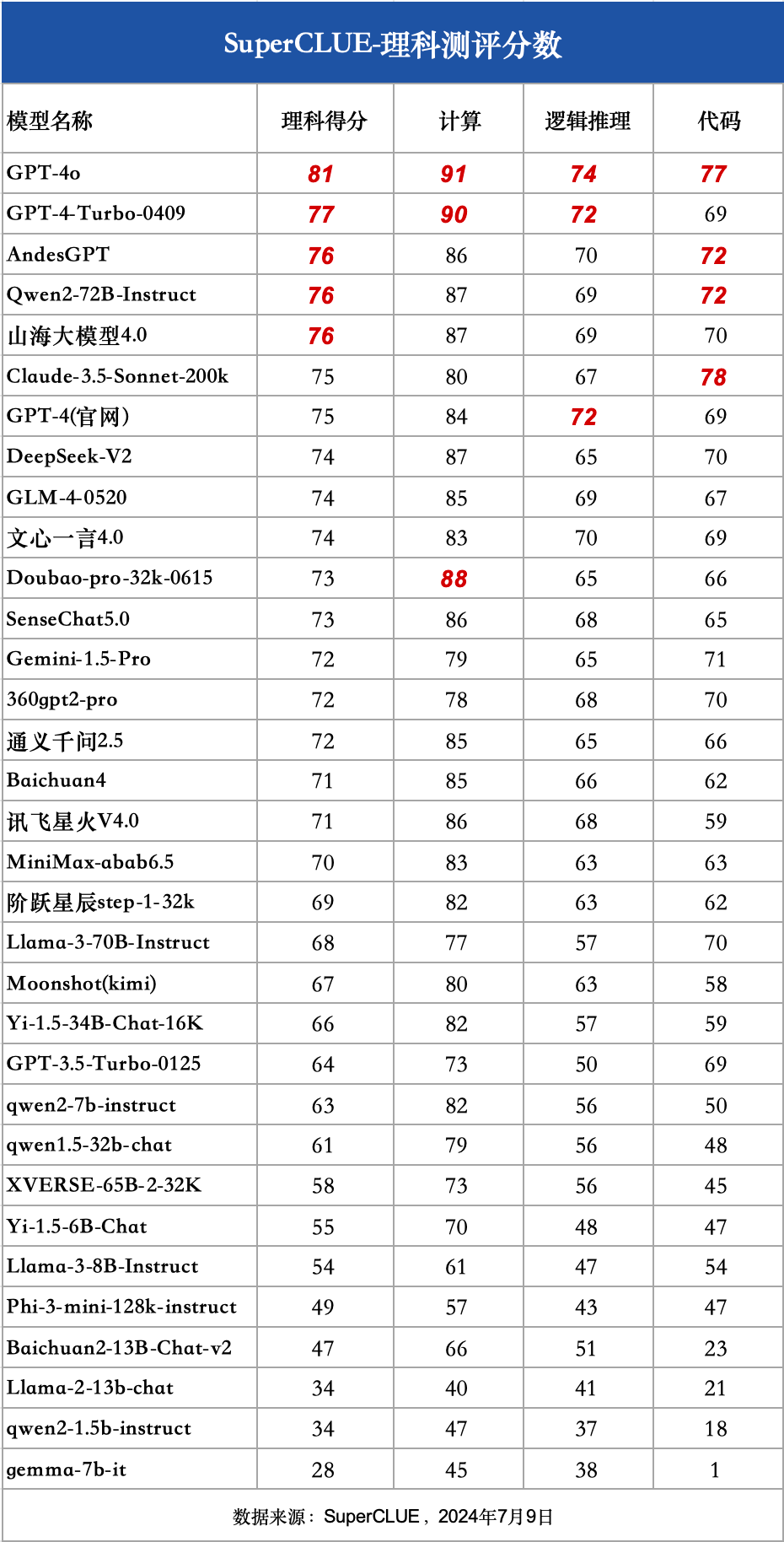
1)理科細粒度分數
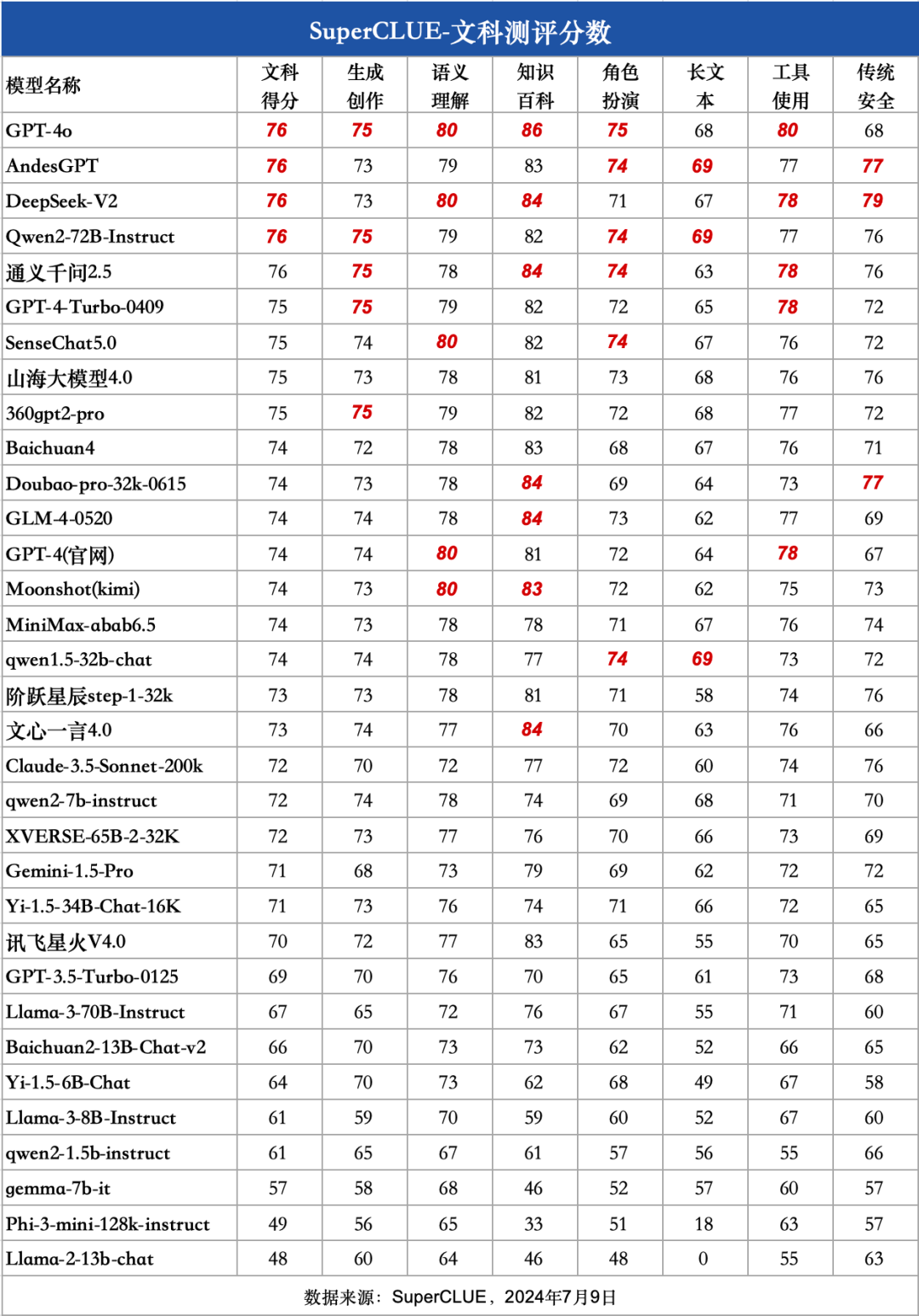
2)文科細粒度分數
3)SuperCLUE細粒度全局分數
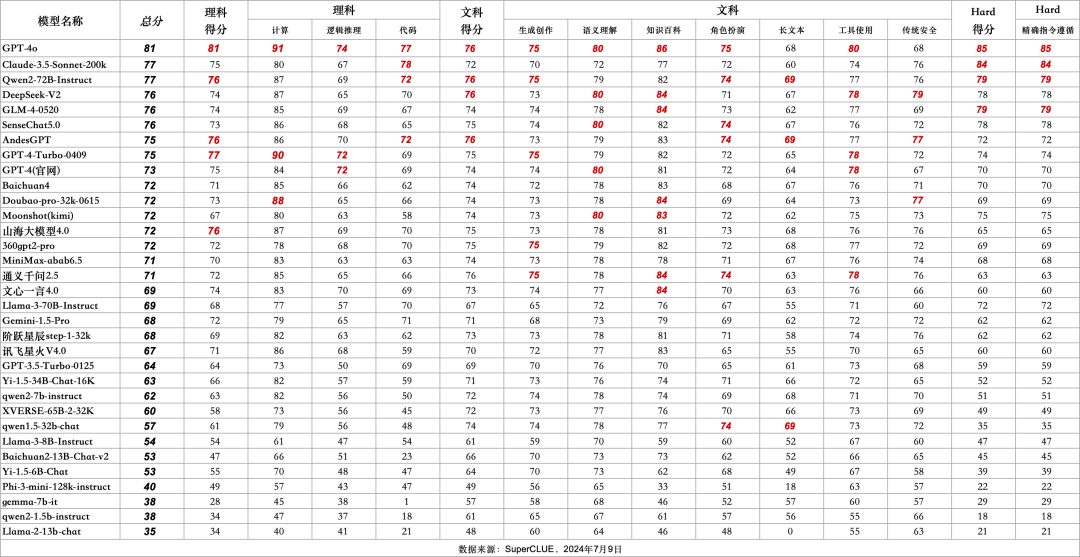
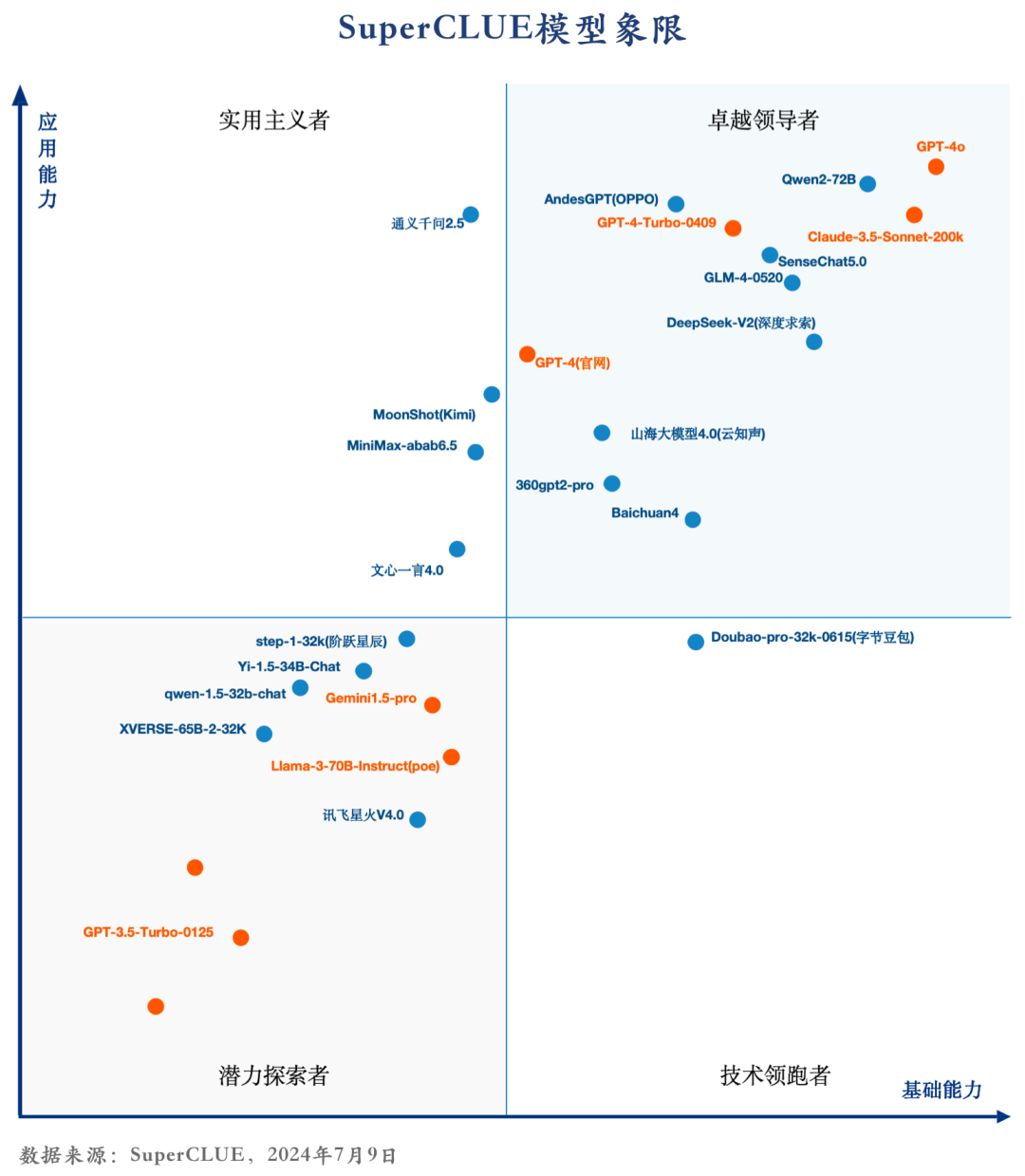
7.SuperCLUE模型象限
SuperCLUE評測任務可劃分為基礎能力和應用能力兩個維度。
基礎能力,包含:計算、代碼、傳統安全等能力。
應用能力,包括:工具使用、角色扮演等能力。
基于此,SuperCLUE構建了大模型四個象限,它們代表大模型所處的不同階段與定位,其中【潛力探索者】代表模型正在技術探索階段擁有較大潛力;【技術領跑者】代表模型聚焦基礎技術研究;【實用主義者】代表模型在場景應用上處于領先定位;【卓越領導者】代表模型在基礎和場景應用上處于領先位置,引領國內大模型發展。
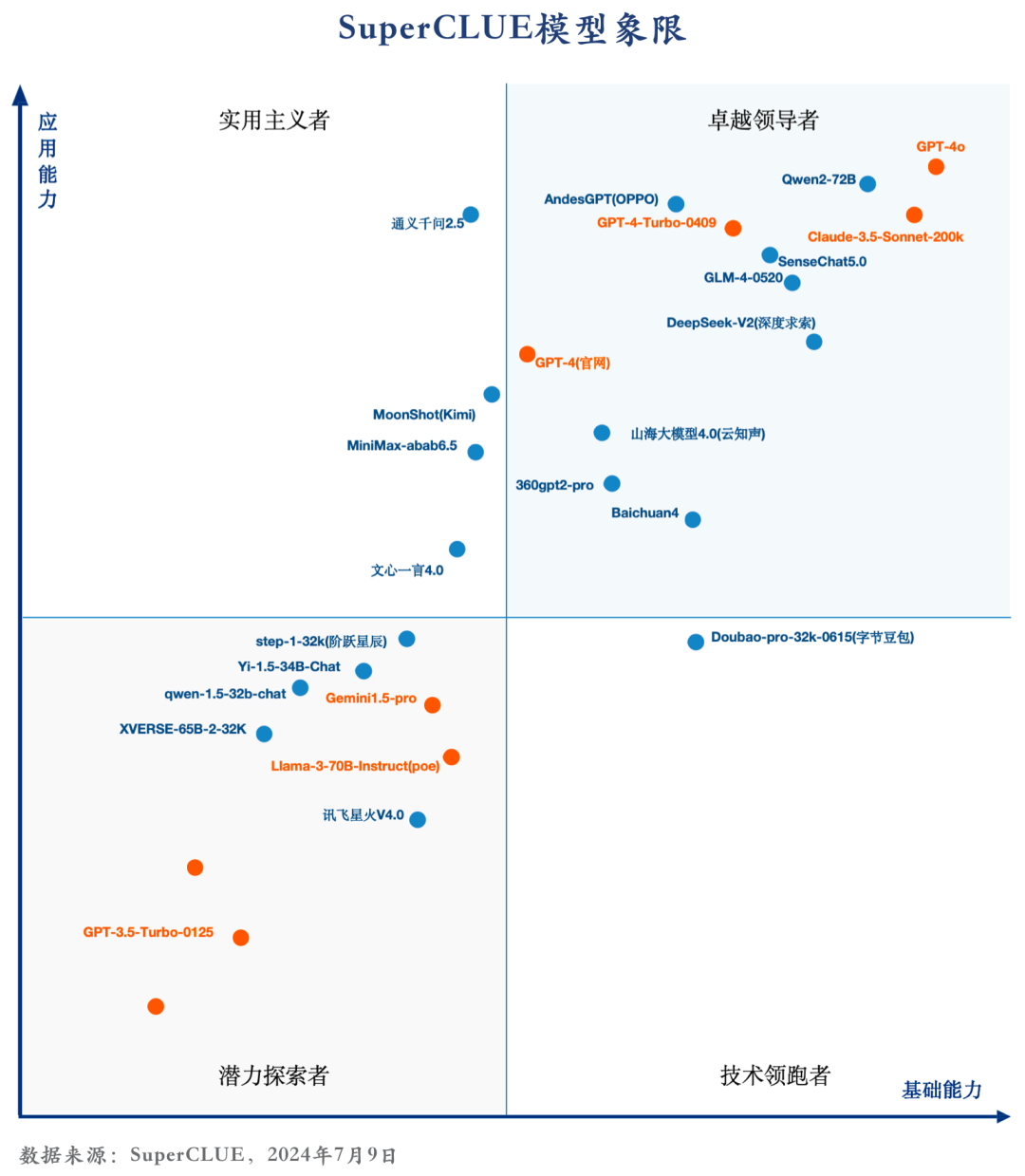
8.?國內大模型SuperCLUE歷屆Top3
過去十一個月國內模型在SuperCLUE基準上的前三名。
9. SuperCLUE理科測評
1)測評數據集及方法說明


2)SuperCLUE理科成績
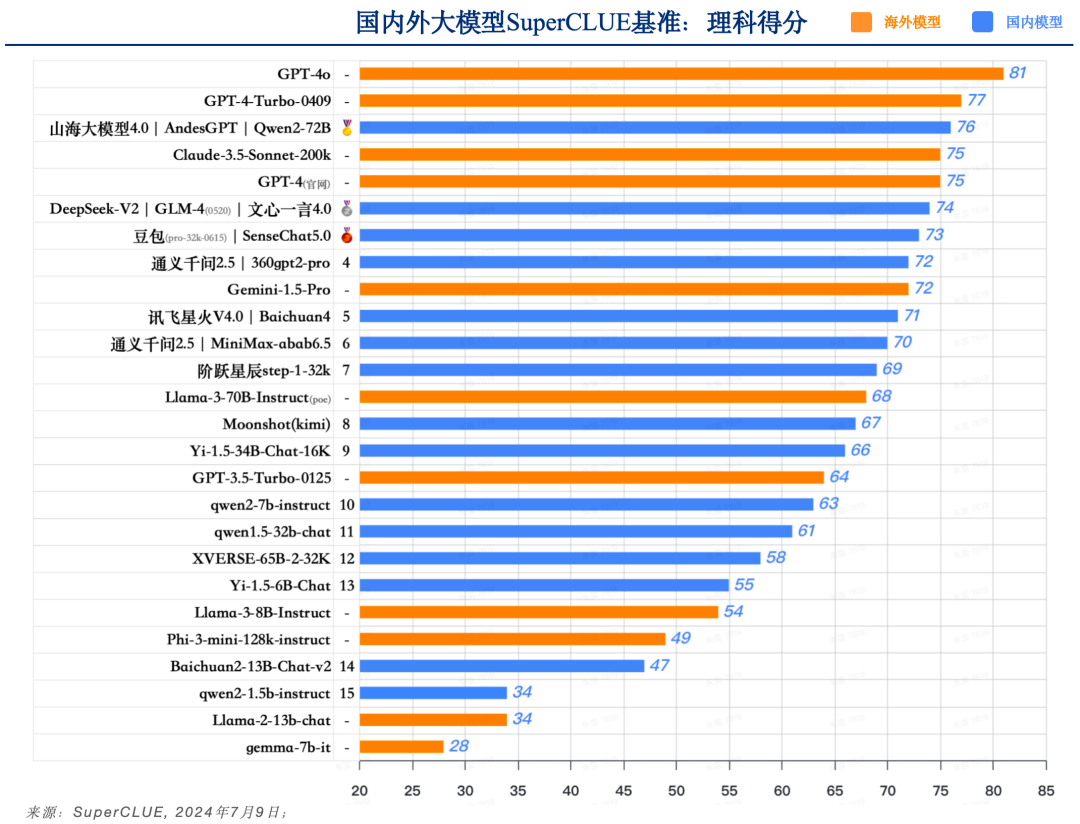
a. GPT-4o領先,國內外有一定差距
-
GPT-4o以81分的絕對優勢領跑SuperCLUE基準理科測試,是全球模型中唯一超過80分的大模型。GPT-4-Turbo-0409得分77分,緊隨其后。
-
國內大模型理科表現優異的模型,如Qwen2-72B、AndesGPT和山海大模型4.0稍落后于GPT-4-Turbo-0409,均取得76分的高分。但與GPT-4o還有較大差距。
b.?理科任務具有較高的挑戰難度,區分度明顯
-
理科任務有較高難度,我們可以發現,GPT-4o和GPT3.5-Turbo有17分的差距,Llama-3-70B比Llama-2-13B有34分的差距。
-
在國內閉源模型中,表現最高的模型(76分)和表現最差模型(58分)有18分的區分度。可見在理科任務上較能反應大模型之間的能力差距。
c.?小參數量模型在理科能力上表現不足
-
參數量較小的模型在SuperCLUE理科測評中,基本均為達到60分及格線,可見在難度較高任務上,參數量依然是影響較大的因素。
理科任務上主要包括計算、邏輯推理和代碼任務,這幾項將是國內外大模型在下半年重點突破的方向。
10. SuperCLUE文科測評
1)測評數據集及方法說明

2)SuperCLUE文科成績
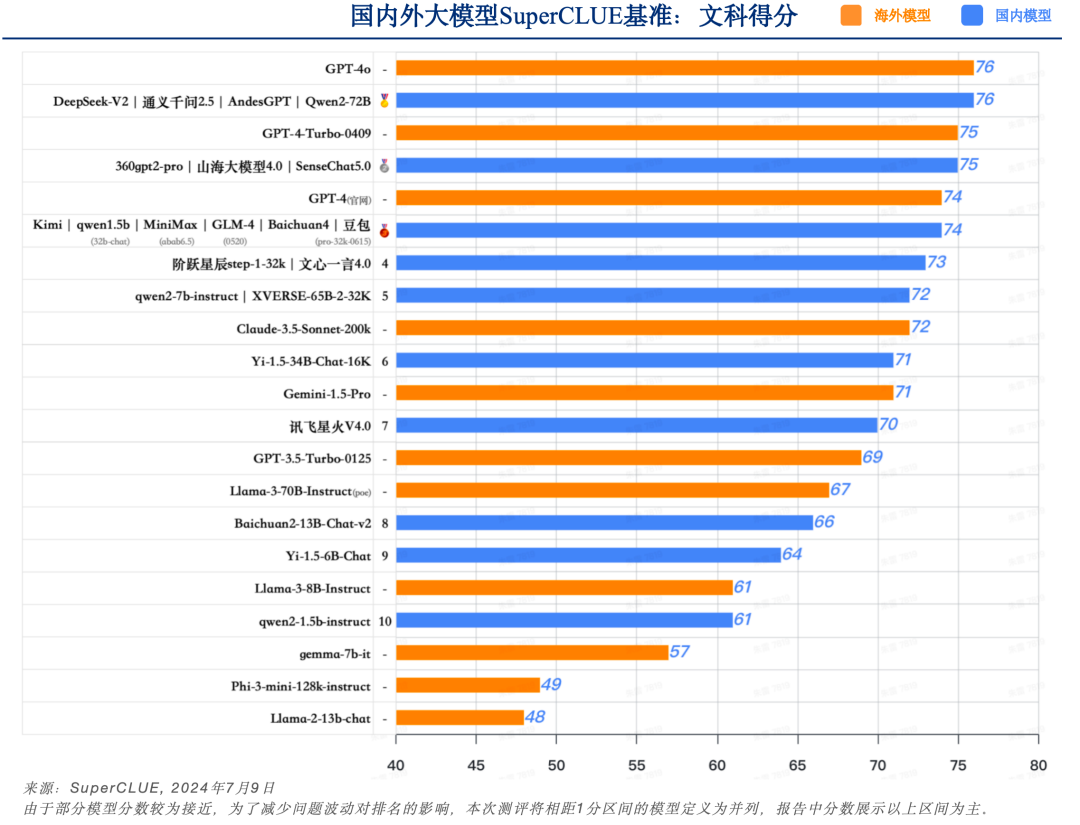
a.?國內外頭部模型處于同一水平,均未達到80分良好線
-
GPT-4o在文科任務上取得76分,并未超過80分,說明文科任務上實現高質量處理依然有較大提升空間。國內擅長文科的模型如Qwen2-72B、AndesGPT、通義千問2.5和 DeepSeek-V2同樣取得76分,與GPT-4o處于同一水平。
-
另外國內大模型如SenseChat5.0、山海大模型4.0和360gpt2-pro取得75分,表現不俗。與GPT-4-Turbo-0409表現相當。
b.?文科任務模型間的區分度不明顯,表現“中規中矩”
-
本次測評所有國內模型得分分布較為集中,沒有較大的區分性,均處于及格線(60分)-良好線(80分)之間。
-
國內外閉源模型得分均處于70-80分,表現“中規中矩”,處理能力較為相似。
-
國內開源模型得分大部分處于60-70分,表現“基本可用”,但在質量上還有較大提升空間。
c.?模型參數量在文科能力上不是模型的決定性因素
-
本次測評中參數量最小的模型qwen2-1.5b(15億參數量),依然有超過60分的表現,而qwen2-7b有超過70分的表現,與文心一言4.0表現接近。
文科任務上如何提高語言處理質量,增加內容生成和理解的優秀水平,是國內外大模型需要進一步優化的方向。
11. SuperCLUE-Hard測評
1)測評數據集及方法說明


2)SuperCLUE-Hard成績
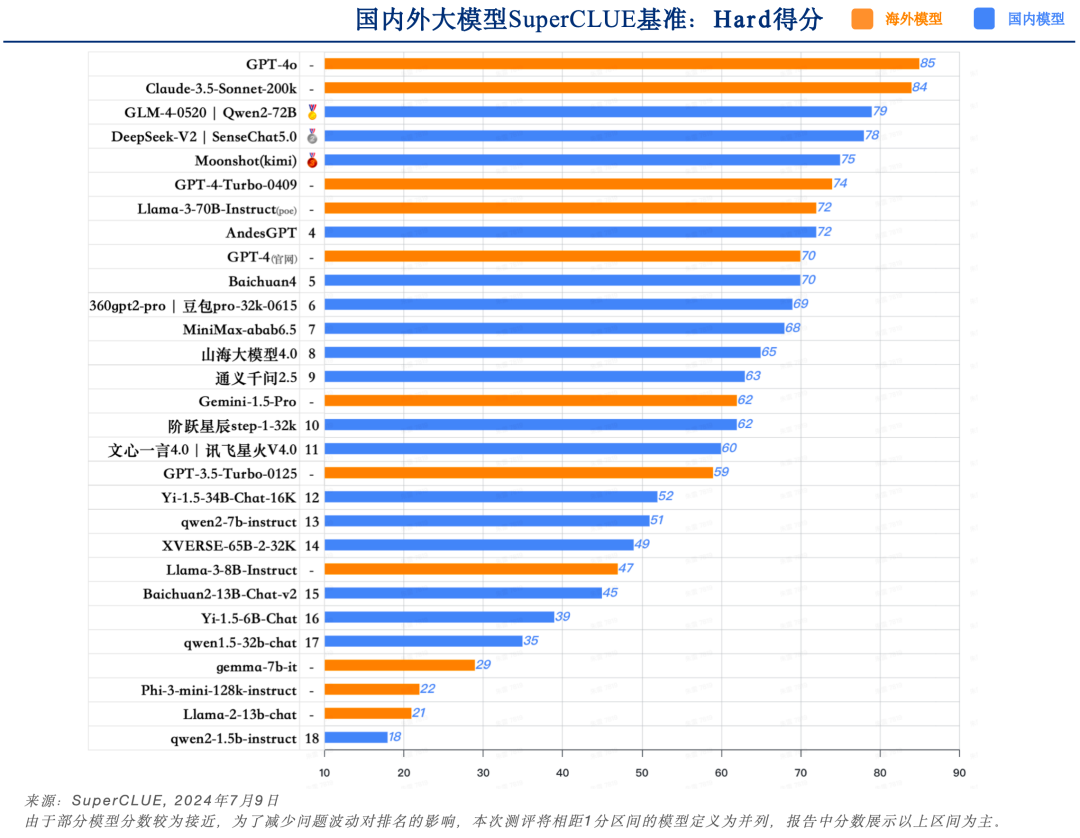
a.?國內外模型在精確指令遵循能力上有一定差距
-
GPT-4o在Hard任務(精確指令遵循)任務上取得85分,領跑全球大模型。Claude-3.5-Sonnet-200k僅隨其后取得84分,表現同樣不俗。是國內外模型中唯二超過80分的大模型。
-
國內表現最好的模型是GLM-4-0520和Qwen2-72B,取得79分,較GPT-4o低6分,還有一定的提升空間。
b.?精確指令遵循有較大區分度
-
本次測評所有模型得分的差異性較大,超出80分只有2個模型,且與排名第三的模型有5分差距。
-
國內僅有4個模型超過了75分,分別為GLM-4-0520、Qwen2-72B、SenseChat5.0和DeepSeek-V2。在國內大模型中較為領先。
-
國內閉源模型中得分最低的僅有60分,這說明高難度任務可以進一步區分模型之間的能力差距。
c.?小模型普遍不擅長精確指令遵循
-
本次測評中參數量最小的開源模型qwen2-1.5b在精確指令遵循任務上僅有18分,并且小于10B的模型均為達到60分及格線,是端側小模型后續需要重點提升的能力。
Hard任務如精確指令遵循,可以很好的考察大模型的極限能力,后續將陸續增加復雜任務高階推理和高難度問題解決等Hard任務,會進一步發現大模型的優化方向。
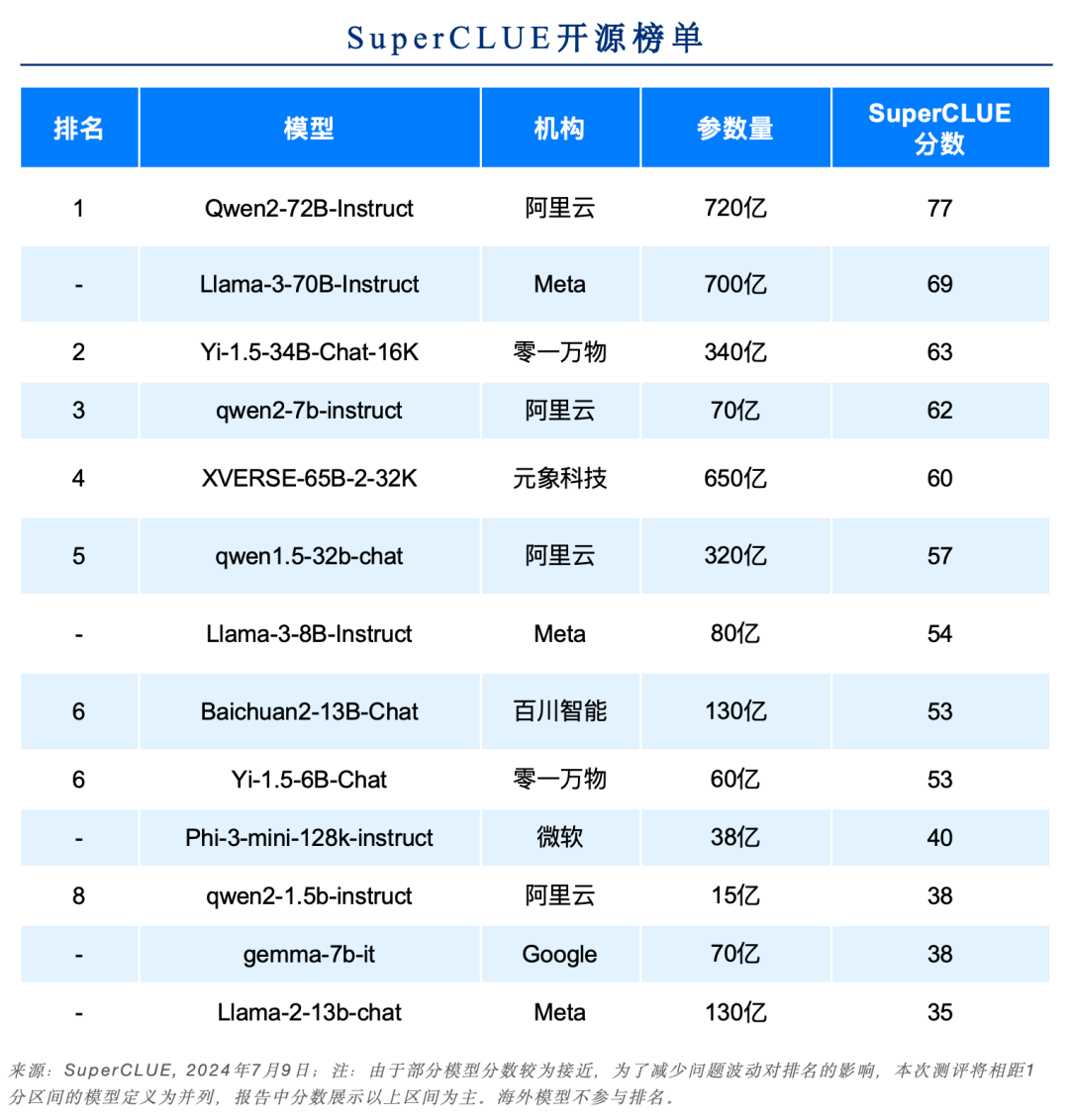
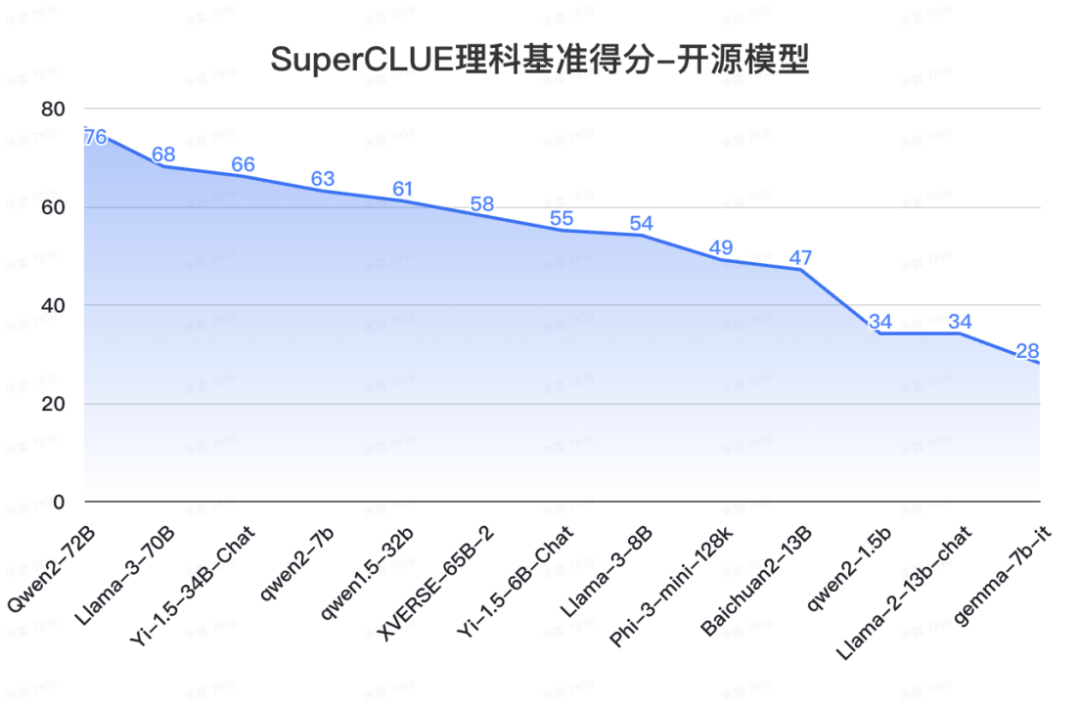
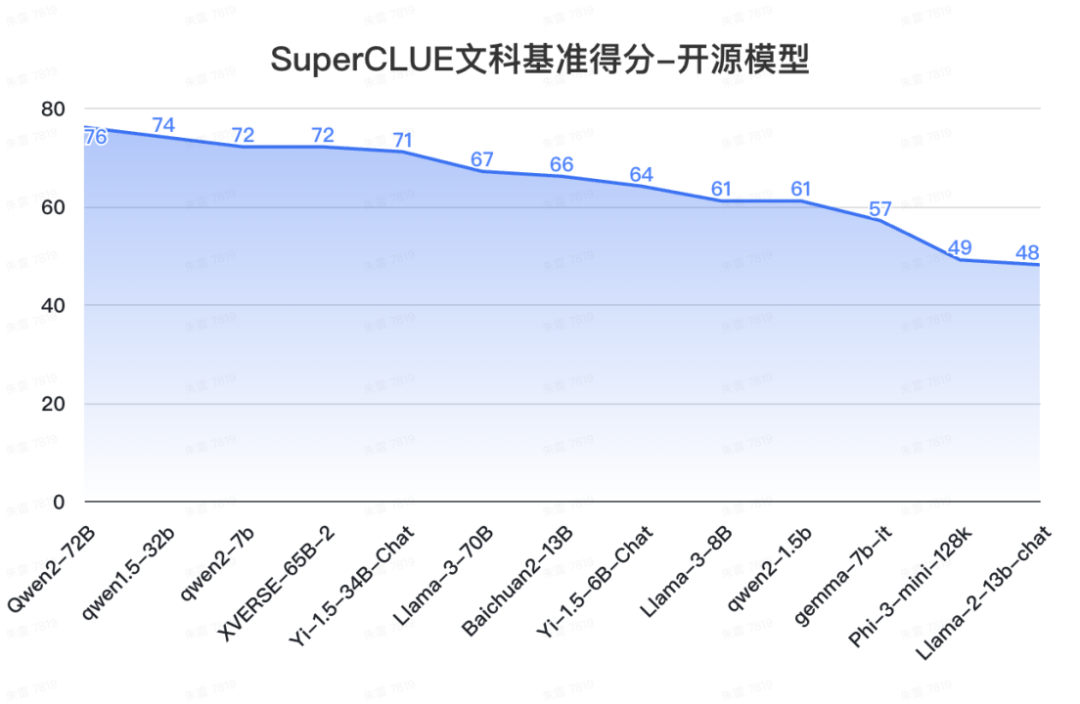
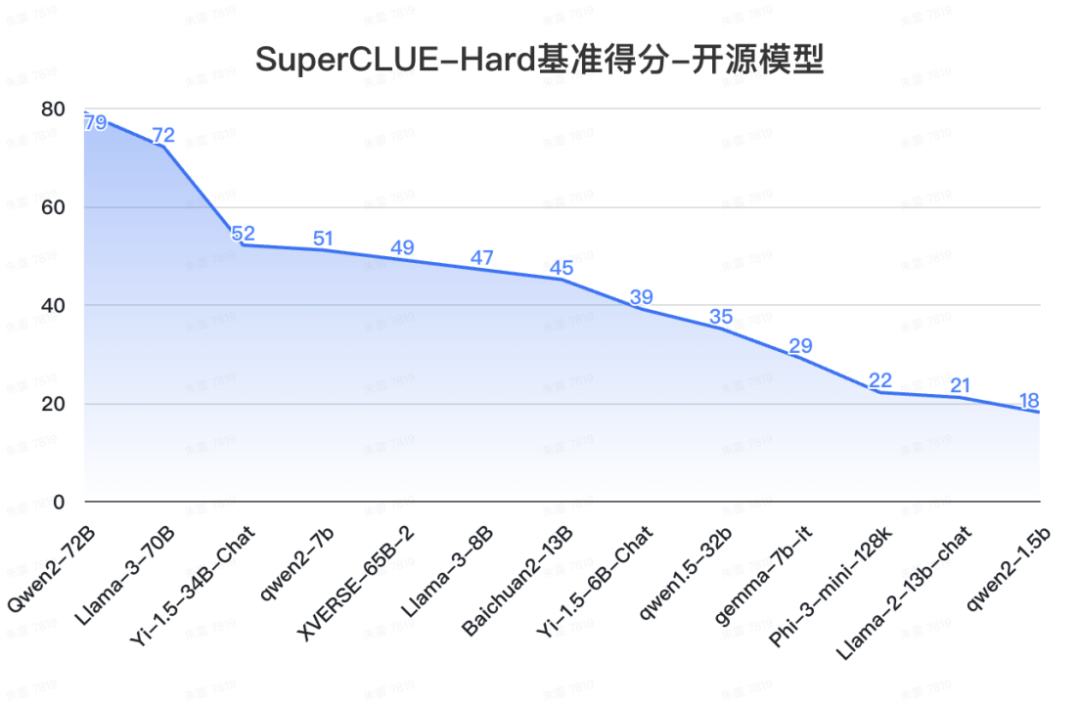
12. SuperCLUE開源榜單
來源:SuperCLUE,2024年7月9日
來源:SuperCLUE,2024年7月9日
來源:SuperCLUE,2024年7月9日
a.?中文場景國內開源模型具備較強競爭力
-
Qwen2-72B領跑全球開源模型,較Llama-3-70B在中文能力上有較大領先性。
-
Yi-1.5系列模型同樣有不俗的表現,其中34B版本有超過60分的表現。
-
小參數量的模型發展迅速,如qwen2-1.5b與gemma-7b表現相當。
b. 在高難度任務上,不同的開源模型區分度較大。
-
在Hard任務中,Qwen2-72B和Llama-3-70B領先幅度很大,均有超出70分的表現。其他開源模型均未達到及格線。
Hard任務如精確指令遵循,可以很好的考察大模型的極限能力,后續將陸續增加復雜任務高階推理和高難度問題解決等Hard任務,會進一步發現大模型的優化方向。
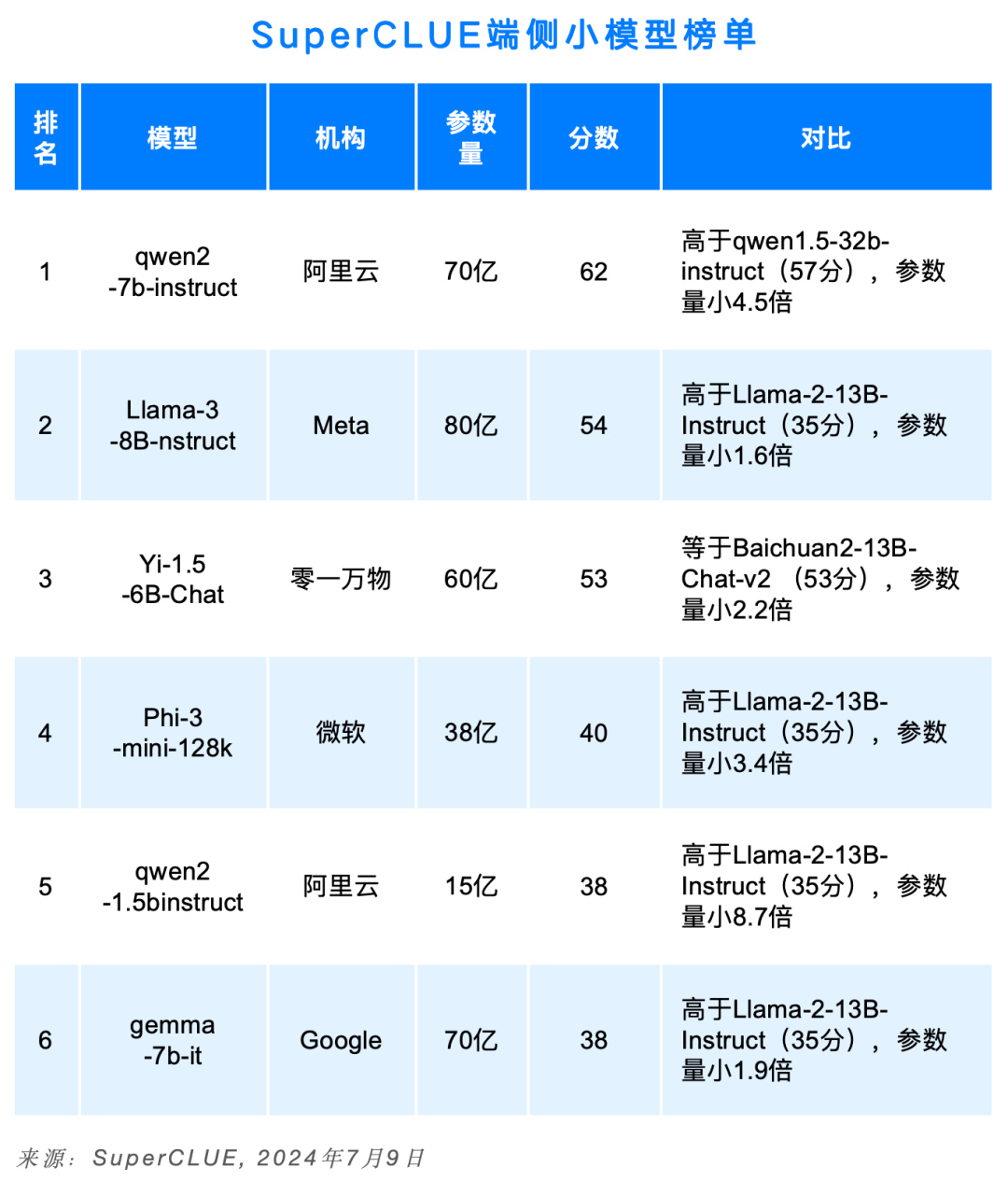
13. SuperCLUE端側小模型榜單
2024年上半年小模型快速發展,可在設備端側(非云)上本地運行,落地在不需要大量推理或需要快速響應的場景。
國內以qwen和Yi系列開源模型為代表,上半年進行了多次迭代。其中qwen2-7b(70億參數)取得62分,打敗了上一代版本的qwen1.5-32b(320億參數),qwen2-1.5b(15億參數)打敗了Llama-2-13B-Instruct(130億參數),展現了更小尺寸的模型的極致性能。
14.?大模型對戰勝率分布圖
我們統計了所有大模型在測評中與GPT4-Turbo-0409的對戰勝率。模型在每道題上的得分與GPT4-Turbo-0409相比計算差值,得到勝(差值大于0.5分)、平(差值在-0.5~+0.5分之間)、負(差值低于-0.5)。
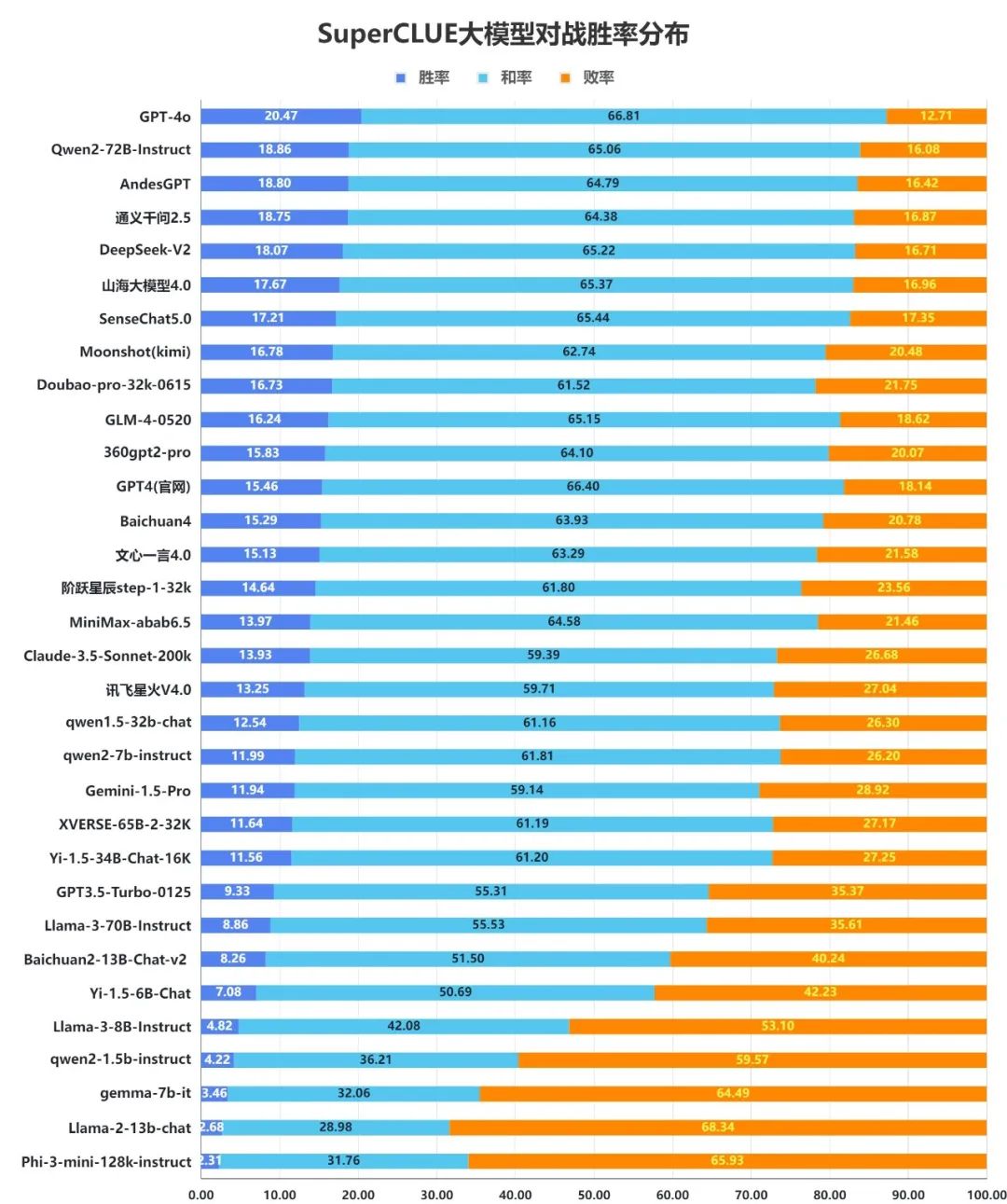
來源:SuperCLUE,2024年7月9日
1)整體勝率表現
從整體對戰來看,國外領先模型GPT-4o以20.47%的勝率,66.81%的和率占據第一位,顯示出其強大的整體能力。緊隨其后的是Qwen2-72B-Instruct,勝率為18.86%,和率為65.06%,也展現出優于GPT4-Turbo-0409的實力。同樣有著較強實力的模型還有AndesGPT、通義千問2.5、DeepSeek-V2、山海大模型4.0和SenseChat5.0等模型。
2)小模型勝率情況
在200億以內參數的模型中qwen-2-7b的勝率排在首位,展現出不俗能力。排在2至3位的是Baichuan2-13B-Chat-v2、Yi-1.5-6B-Chat,同樣有50%以上的勝和率,表現可圈可點。
3)在基礎題目上與GPT-4-Turbo-0409差距有限
從勝率分布數據可以發現,大部分模型的和率都在50%以上。這說明國內外大部分模型在基礎題目上與GPT-4-Turbo-0409的水平相近,隨著任務難度的提升,不同模型的表現會有一定區分度。
15.?SuperCLUE成熟度指數
SuperCLUE成熟度指數用以衡量國內大模型在SuperCLUE能力上是否成熟。
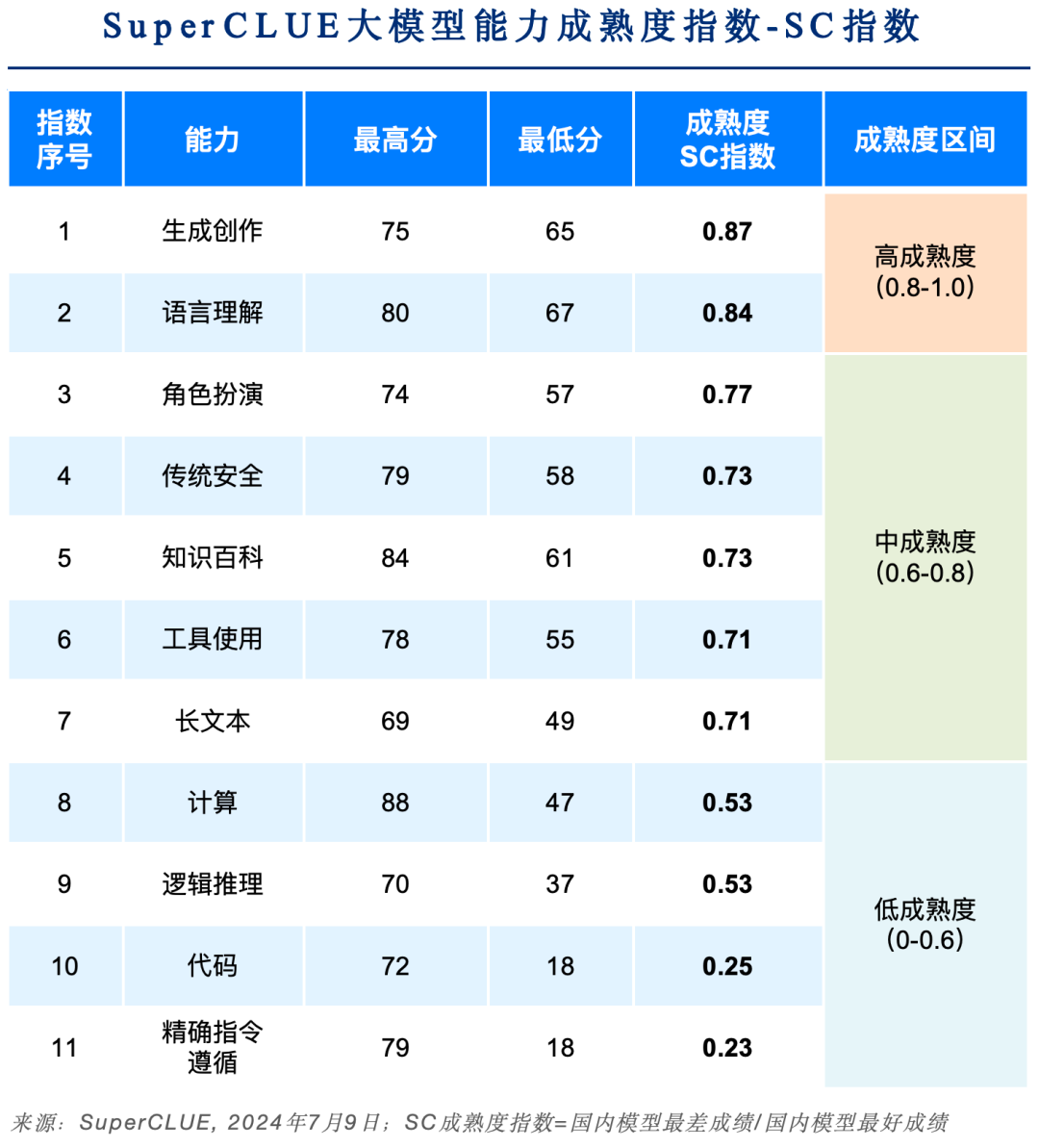
1)高成熟度能力
-
高成熟度指大部分大模型普遍擅長的能力,SC成熟度指數在0.8至1.0之間。
-
當前國內大模型成熟度較高的能力是【生成創作】和 【語言理解】,也是目前產業和用戶側大模型的重點應用場景。
2)中成熟度能力
-
中成熟度指的是不同大模型能力上有一定區分度,但不會特別大。SC成熟度指數在0.6至0.8之間。
-
當前國內大模型中成熟度的能力是【角色扮演】、【傳統安全】、【知識百科】、【工具使用】、【長文本】,還有一定優化空間。
3)低成熟度能力
-
低成熟度指的是少量大模型較為擅長,很多模型無法勝任。SC成熟度指數在0.6以下。
-
當前國內大模型低成熟度的能力是【計算】、【邏輯推理】、【代碼】、【精確指令遵循】。尤其在Hard任務的精確指令遵循的成熟度僅有0.23,是非常有挑戰性的大模型應用能力。
16.?評測與人類一致性驗證
1) SuperCLUE VS Chatbot Arena
Chatbot Arena是當前英文領域較為權威的大模型排行榜,由LMSYS Org開放組織構建, 它以公眾匿名投票的方式,對各種大型語言模型進行對抗評測。其中,皮爾遜相關系數:0.90,P值:1.22e-5;斯皮爾曼相關系數:0.85,P值:1.12e-4 ;說明SuperCLUE基準測評的成績,與人類對模型的評估(以大眾匿名投票的Chatbot Arena為典型代表),具有高度一致性。
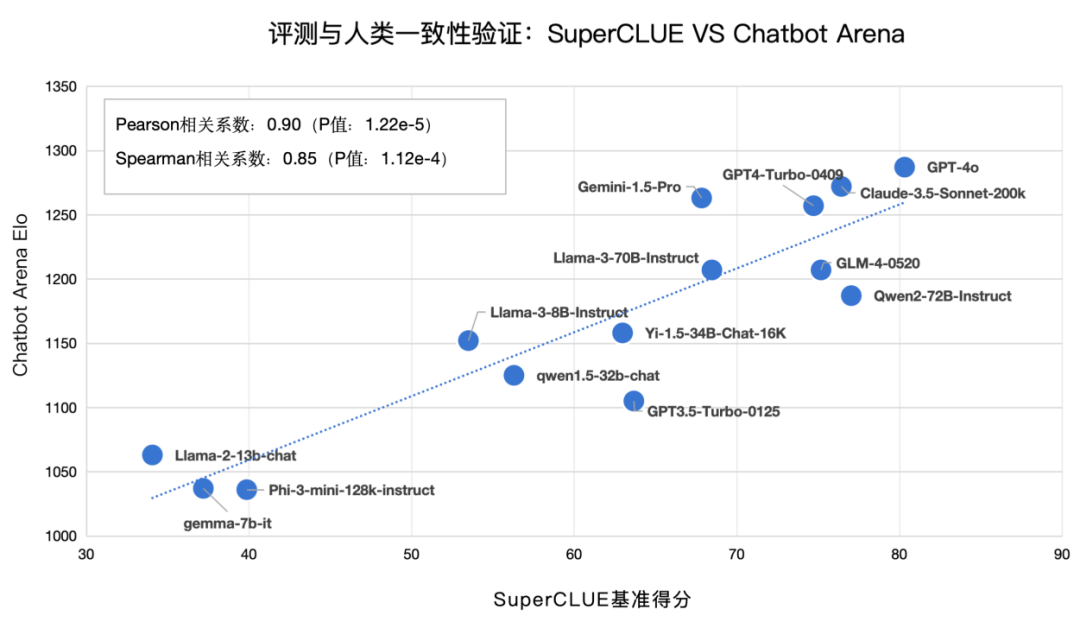
來源:SuperCLUE,2024年7月9日
2) 評測與人類一致性驗證2:自動化評價可靠性的人工評估
為驗證自動化評價的可靠性,SuperCLUE團隊在進行正式測評之前,從2000+道題目中針對4個模型,每個模型隨機抽取了100道題目進行人工復審。
審核內容及標準包括:
評價質量分為:優秀,良好 ,及格,不及格
完全不符合自己的判斷:不及格(60以下)
基本符合自己的判斷:及格(60或以上)或良好(75或以上)
特別符合自己的判斷:評價的特別好:優秀(85或以上)
最后統計可靠性指標,將基本符合、特別符合的結果認定為是可靠性較高的評價。
最終各模型可靠性指標結果如下:

通過4個模型的可靠性分析驗證,我們發現可靠性數據分別為91%、90%、99%、90%,其中可靠性最低有90%,最高為模型的99.00%。平均有92.5%的可靠性。
所以,經過驗證,SuperCLUE自動化評價有較高的可靠性。
多模態測評、行業、專項測評、優秀案例介紹以及更詳細測評數據分析,請查看完整PDF報告。
點擊文章底部【閱讀原文】查看高清完整PDF版。
在線完整報告地址(可下載):
www.cluebenchmarks.com/superclue_24h1
未來兩個月基準發布計劃
未來2-3個月SuperCLUE會持續完善大模型專項能力及行業能力的測評基準。現針對于所有專項及行業測評基準征集大模型,歡迎申請。有意愿參與測評的廠商可發送郵件至contact@superclue.ai,標題:SuperCLUE專項/行業測評,請使用單位郵箱,郵件內容包括:單位信息、大模型簡介、聯系人和所屬部門、聯系方式。
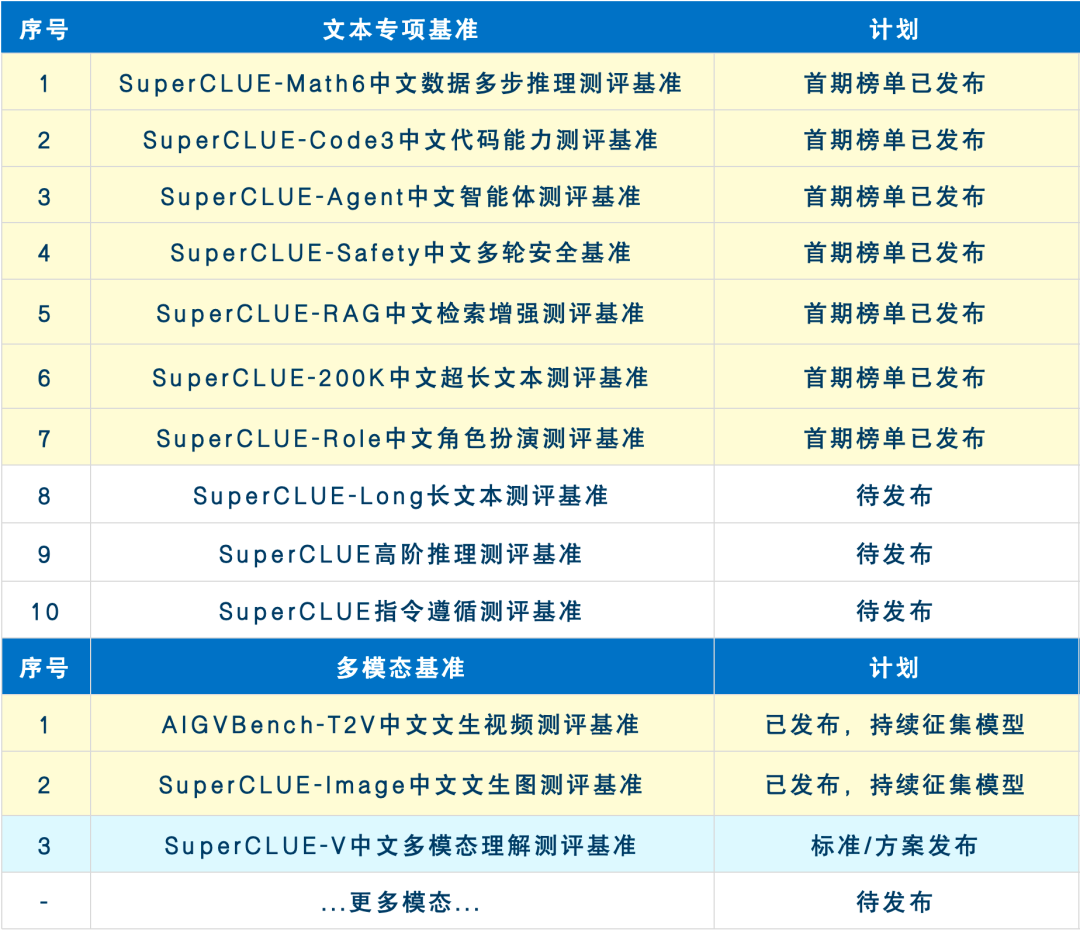
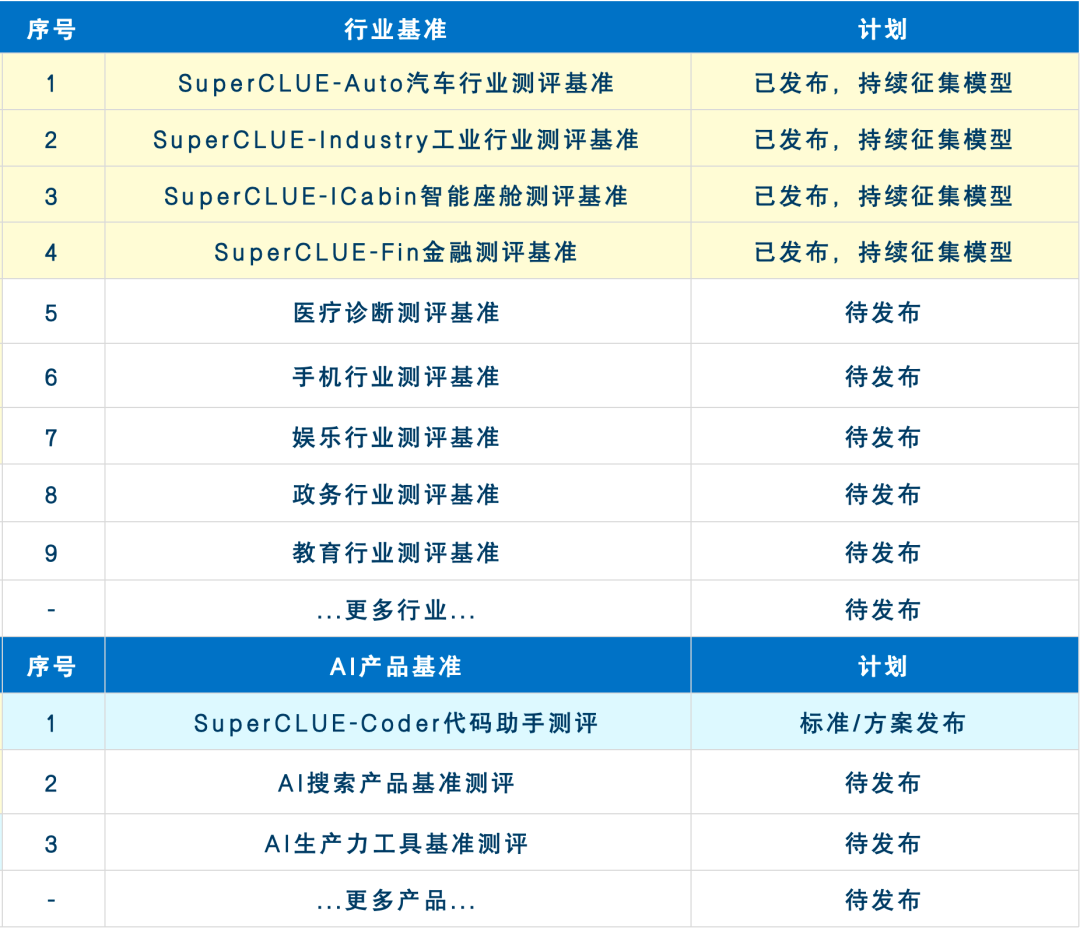
預告:SuperCLUE通用基準測評8月報告將在2024年8月27日發布,歡迎反饋意見、參與測評。
歡迎加入【2024上半年報告】交流群。


擴展閱讀

[1] CLUE官網:www.CLUEBenchmarks.com
[2] SuperCLUE排行榜網站:www.superclueai.com
[3] Github地址:https://github.com/CLUEbenchmark/SuperCLUE
[4] 在線報告地址:www.cluebenchmarks.com/superclue_24h1







 掃描線】218. 天際線問題)

)
)





)


)