在 GitHub 上發現一篇教程,作者詳細介紹了如何使用 Python 語言,從零開始構建一個文本到視頻生成模型。
涵蓋了從理解理論概念到架構編碼,最終實現輸入文本提示即可生成視頻的全過程。
相關鏈接
GitHub:github.com/FareedKhan-dev/AI-text-to-video-model-from-scratch
內容介紹

OpenAI 的 Sora、Stability AI 的 Stable Video Diffusion 以及許多其他已經問世或未來將出現的文本轉視頻模型,是繼大型語言模型 (LLM) 之后 2024 年最流行的 AI 趨勢之一。在本博客中,我們將從頭開始構建一個小規模的文本轉視頻模型。我們將輸入一個文本提示,我們訓練過的模型將根據該提示生成視頻。本博客將涵蓋從理解理論概念到編碼整個架構并生成最終結果的所有內容。
由于我沒有高端的 GPU,因此我編寫了小規模架構。以下是在不同處理器上訓練模型所需時間的比較:
我們正在建設什么
我們將采用與傳統機器學習或深度學習模型類似的方法,即在數據集上進行訓練,然后在未見過的數據上進行測試。在文本轉視頻的背景下,假設我們有一個包含 10 萬個狗撿球和貓追老鼠視頻的訓練數據集。我們將訓練我們的模型來生成貓撿球或狗追老鼠的視頻。
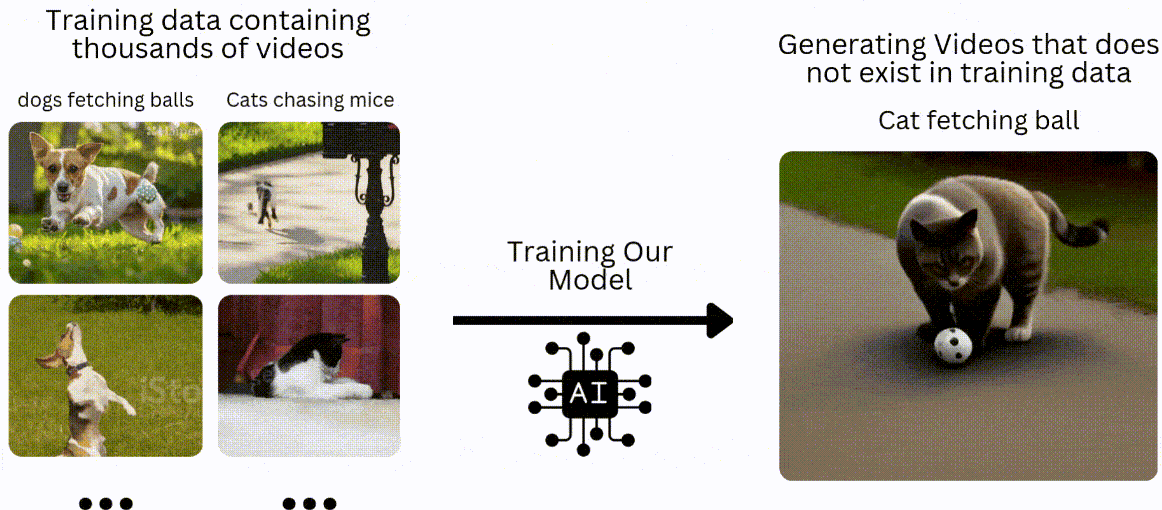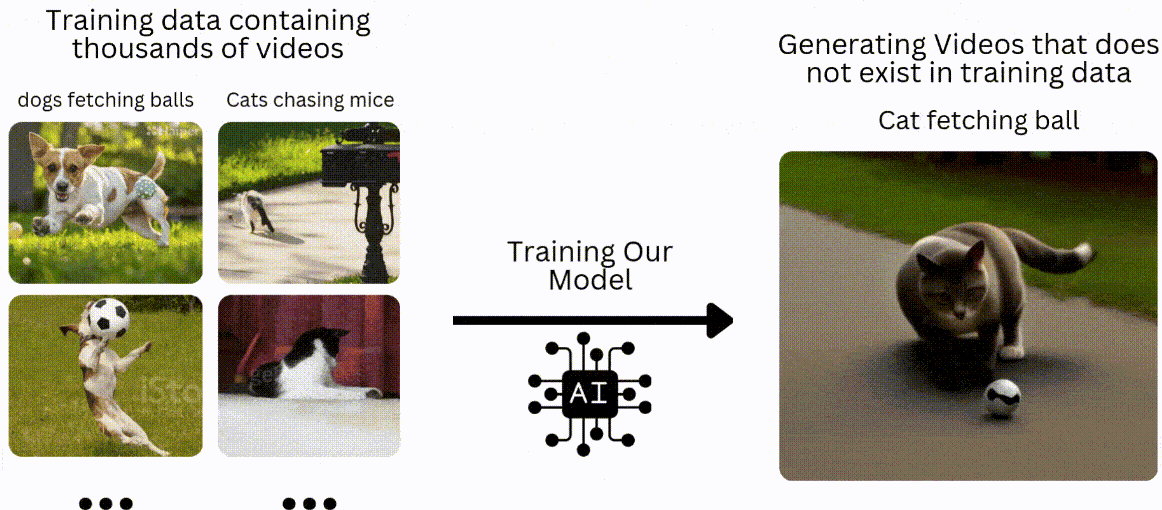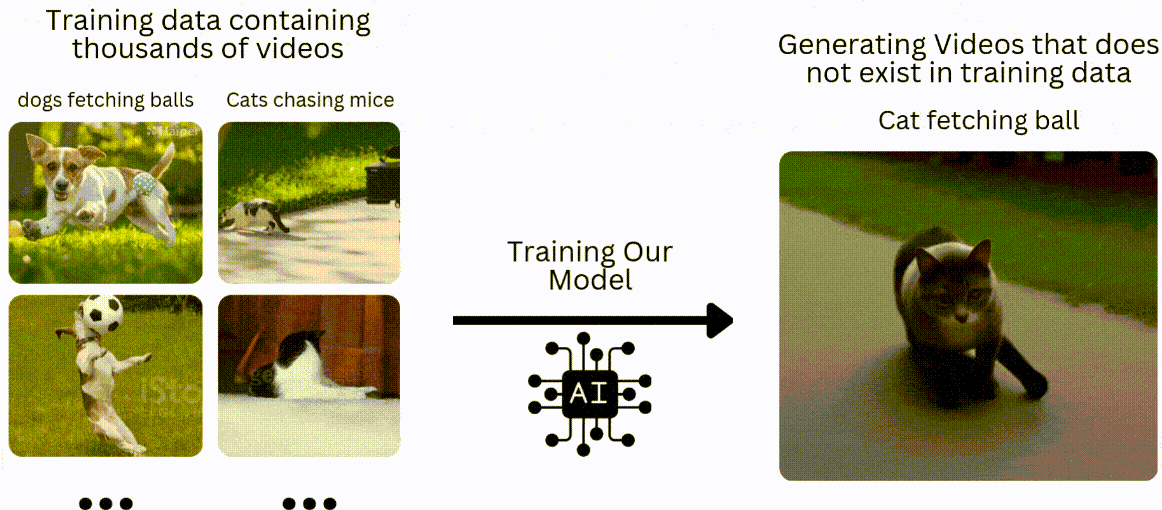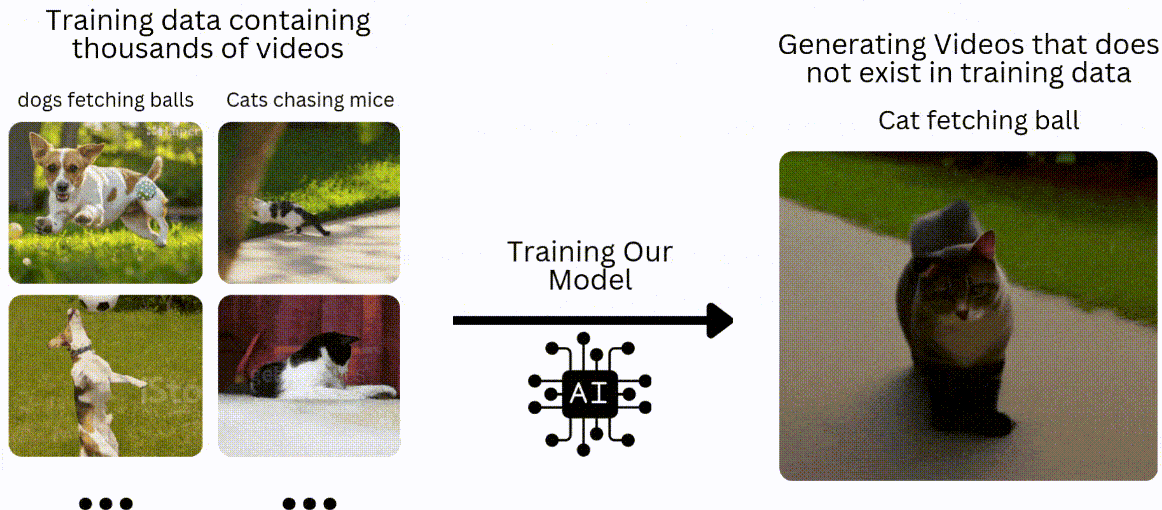
什么是 GAN?
生成對抗網絡 (GAN) 是一種深度學習模型,其中兩個神經網絡相互競爭:一個根據給定的數據集創建新數據(如圖像或音樂),另一個則嘗試判斷數據是真是假。此過程持續進行,直到生成的數據與原始數據無法區分。
實際應用
生成圖像:GAN 根據文本提示創建逼真的圖像或修改現有圖像,例如增強分辨率或為黑白照片添加顏色。
-
數據增強:它們生成合成數據來訓練其他機器學習模型,例如為欺詐檢測系統創建欺詐交易數據。
-
補充缺失信息:GAN 可以填充缺失數據,例如從地形圖生成用于能源應用的地下圖像。
-
生成 3D 模型:將 2D 圖像轉換為 3D 模型,可用于醫療保健等領域,為手術規劃創建逼真的器官圖像。
GAN 如何工作?
它由兩個深度神經網絡組成:生成器和鑒別器。這兩個網絡在對抗設置中一起訓練,其中一個網絡生成新數據,另一個網絡評估數據是真是假。
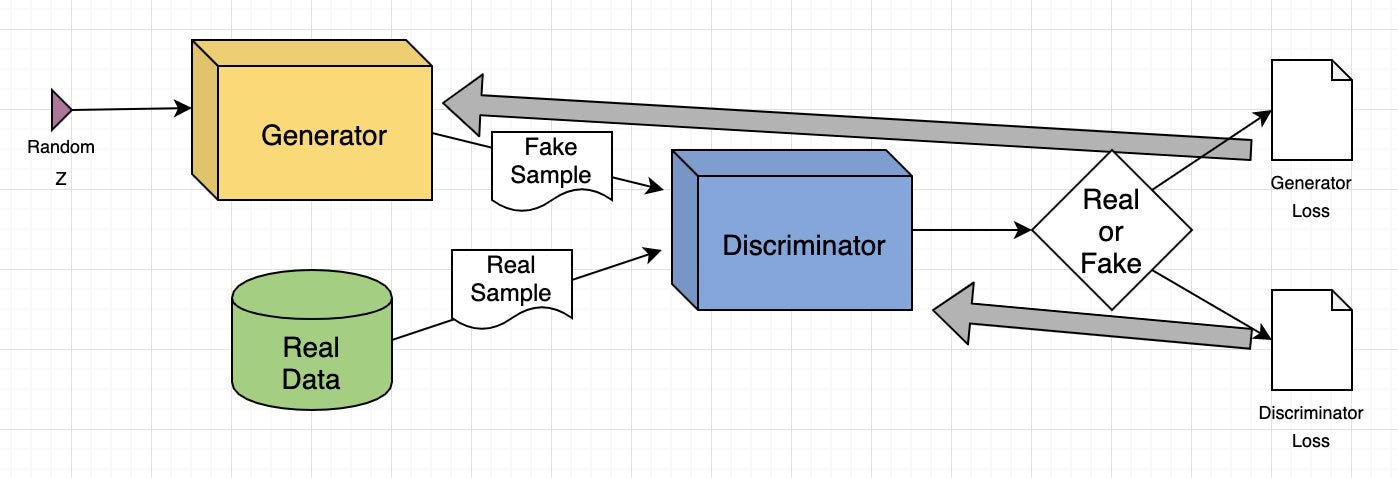
以下是 GAN 工作原理的簡要概述:
-
訓練集分析:生成器分析訓練集以識別數據屬性,而鑒別器則獨立分析相同的數據以學習其屬性。
-
數據修改:生成器向數據的某些屬性添加噪聲(隨機變化)。
-
數據傳遞:修改后的數據被傳遞給鑒別器。
-
概率計算:鑒別器計算生成的數據來自原始數據集的概率。
-
反饋循環:鑒別器向生成器提供反饋,指導其在下一個周期減少隨機噪聲。
-
對抗性訓練:生成器試圖最大化鑒別器的錯誤,而鑒別器則試圖最小化自己的錯誤。通過多次訓練迭代,兩個網絡都會得到改進和發展。
-
平衡狀態:訓練持續進行,直到鑒別器無法再區分真實數據和合成數據,這表明生成器已成功學會生成真實數據。此時,訓練過程已完成。
GAN 訓練示例
讓我們用圖像到圖像轉換的例子來解釋 GAN 模型,重點是修改人臉。
-
輸入圖像:輸入是人臉的真實圖像。
-
屬性修改:生成器修改臉部的屬性,例如在眼睛上添加太陽鏡。
-
生成的圖像:生成器創建一組添加了太陽鏡的圖像。
-
鑒別器的任務:鑒別器接收真實圖像(戴太陽鏡的人)和生成的圖像(添加了太陽鏡的臉部)的混合。
-
評估:鑒別器試圖區分真實圖像和生成的圖像。
-
反饋循環:如果鑒別器正確識別了假圖像,生成器就會調整其參數以生成更令人信服的圖像。如果生成器成功欺騙了鑒別器,鑒別器就會更新其參數以改進其檢測能力。
通過這種對抗過程,兩個網絡都在不斷改進。生成器在創建逼真圖像方面越來越好,而鑒別器在識別假圖像方面也越來越好,直到達到平衡,鑒別器再也無法區分真實圖像和生成的圖像。此時,GAN 已成功學會生成逼真的修改。



)
)
】)


)



優化RF隨機森林結合Adaboost分類預測(二分類及多分類))






