
簡單來講,爬蟲就是一個探測機器,它的基本操作就是模擬人的行為去各個網站溜達,點點按鈕,查查數據,或者把看到的信息背回來。就像一只蟲子在一幢樓里不知疲倦地爬來爬去。
你可以簡單地想象:每個爬蟲都是你的“分身”。就像孫悟空拔了一撮汗毛,吹出一堆猴子一樣。
你每天使用的百度,其實就是利用了這種爬蟲技術:每天放出無數爬蟲到各個網站,把他們的信息抓回來,然后化好淡妝排著小隊等你來檢索。
搶票軟件,就相當于撒出去無數個分身,每一個分身都幫助你不斷刷新 12306 網站的火車余票。一旦發現有票,就馬上拍下來,然后對你喊:土豪快來付款。
互聯網就像一張網,中間以各種鏈接連接在一起,而小小的爬蟲卻能在這張網上歡快的馳騁,代替人來進行很多繁重的任務,如搶票軟件、某度搜索引擎。
python作為一門易上手的語言,提供了豐富的API來抓取網頁文檔、模擬瀏覽器行為、對抓取到的數據進行處理。后面我們的演示中也會展示python爬蟲的簡介,爬取網頁內容的核心代碼可能只有短短幾行,卻能實現強大的功能。
對于新手來說,最熟悉的還是windows環境。我使用的是anaconda+pycharm進行python代碼的編寫,這里anaconda方便進行外部庫的管理,而pycharm也是功能強大很流行的一款IDE。
至少會一點python的基礎知識,如果不清楚的話,可以參加浙大翁愷的python慕課,或者自己找些介紹文檔,如? ? ? ?python入門教程。同時需要了解關于html的一些基礎知識,比如各種標簽代表的含義:
<!–…–>:定義注釋
<!DOCTYPE>?:定義文檔類型
<html>:html文檔的總標簽
<head>:定義頭部
<body>:定義網頁內容
<script>:定義腳本
<div>:division,定義分區,容器標簽
<p>:paragraph,定義段落
<a>:定義超鏈接
<span>:定義文本容器
<br>:換行
<form>:定義表單
<table>:定義表格
<th>:定義表頭
<tr>:表的行
<td>:表的列
<b>:定義粗體字
<img>:定義圖片
熟悉上面這些html標簽將會方便我們進行正則表達式的處理,以及xPath和BeautifulSoup的學習。
python正則表達式相關知識較多,我們只需要了解一些基礎的即可,如:
python正則表達式 菜鳥教程
python正則表達式官方文檔
import re
import urllib.request
import chardetresponse=urllib.request.urlopen("http://news.hit.edu.cn/")#輸入參數為你想爬取的網頁URLhtml=response.read() #讀取到html變量中
chardet1=chardet.detect(html) #獲取編碼方式
html=html.decode(chardet1['encoding']) #按照獲取到的編碼方式進行處理
? 這里我們以某高校的官方新聞網站為例演示來進行python爬蟲操作,上面短短的幾行代碼就實現了將網頁內容爬取到本地的操作。
接著就是對爬取到的內容進行正則表達式處理,得到我們想要獲取的內容,觀察網頁源代碼:

我們希望對其中的外部鏈接進行匹配,由之前了解到的正則表達式知識,實現如下:
mypatten="<li class=\"link-item\"><a href=\"(.*)\"><span>(.*)</span></a></li>"
mylist=re.findall(mypatten,html)
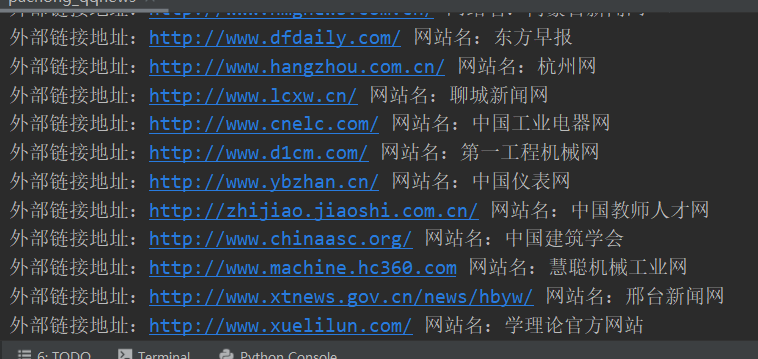
for i in mylist:print("外部鏈接地址:%s 網站名:%s" %(i[0],i[1]))
最后得到的效果是:
除了用正則表達式處理得到的網頁文檔之外,我們還可以考慮網頁自身的架構。
XPath,全稱 XML Path Language,即 XML 路徑語言,它是一門在XML文檔中查找信息的語言。XPath 最初設計是用來搜尋XML文檔的,但是它同樣適用于 HTML 文檔的搜索。
nodename選取此節點的所有子節點
/從當前節點選取直接子節點
//從當前節點選取子孫節點
.選取當前節點
..選取當前節點的父節點
@選取屬性
在這里列出了XPath的常用匹配規則,例如 / 代表選取直接子節點,// 代表選擇所有子孫節點,. 代表選取當前節點,.. 代表選取當前節點的父節點,@ 則是加了屬性的限定,選取匹配屬性的特定節點。
from lxml import etree
import urllib.request
import chardet
response=urllib.request.urlopen("https://www.dahe.cn")html=response.read()
chardet1=chardet.detect(html)
html=html.decode(chardet1['encoding'])
etreehtml=etree.HTML(html)
mylist=etreehtml.xpath("/html/body/div/div/div/div/div/ul/div/li")
BeautifulSoup4是爬蟲必學的技能。BeautifulSoup最主要的功能是從網頁抓取數據,Beautiful Soup自動將輸入文檔轉換為Unicode編碼,輸出文檔轉換為utf-8編碼。BeautifulSoup支持Python標準庫中的HTML解析器,還支持一些第三方的解析器,如果我們不安裝它,則 Python 會使用 Python默認的解析器,lxml 解析器更加強大,速度更快,推薦使用lxml 解析器。
from bs4 import BeautifulSoup
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser") # 縮進格式
print(bs.prettify()) # 格式化html結構
print(bs.title) # 獲取title標簽的名稱
print(bs.title.name) # 獲取title標簽的文本內容
print(bs.title.string) # 獲取head標簽的所有內容
print(bs.head) # 獲取第一個div標簽中的所有內容
print(bs.div) # 獲取第一個div標簽的id的值
print(bs.div["id"]) # 獲取第一個a標簽中的所有內容
print(bs.a) # 獲取所有的a標簽中的所有內容
print(bs.find_all("a")) # 獲取id="u1"
print(bs.find(id="u1")) # 獲取所有的a標簽,并遍歷打印a標簽中的href的值
for item in bs.find_all("a"): print(item.get("href")) # 獲取所有的a標簽,并遍歷打印a標簽的文本值
for item in bs.find_all("a"): print(item.get_text())
最后:如果你對Python感興趣,想要學習Python,希望可以幫到你,一起加油!以上是給大家分享的Python全套學習資料,都是我自己學習時整理的:?
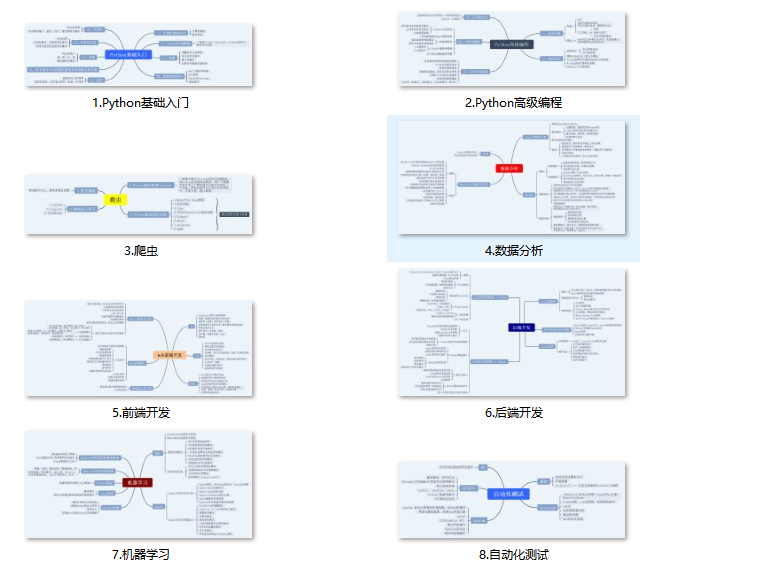
一、Python所有方向的學習路線
Python所有方向路線就是把Python常用的技術點做整理,形成各個領域的知識點匯總,它的用處就在于,你可以按照上面的知識點去找對應的學習資源,保證自己學得較為全面。

二、學習軟件
工欲善其事必先利其器。學習Python常用的開發軟件都在這里了,還有環境配置的教程,給大家節省了很多時間。

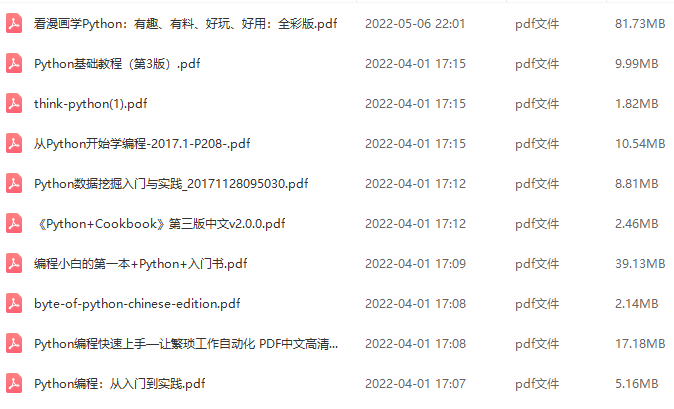
三、全套PDF電子書
書籍的好處就在于權威和體系健全,剛開始學習的時候你可以只看視頻或者聽某個人講課,但等你學完之后,你覺得你掌握了,這時候建議還是得去看一下書籍,看權威技術書籍也是每個程序員必經之路。
四、入門學習視頻全套
我們在看視頻學習的時候,不能光動眼動腦不動手,比較科學的學習方法是在理解之后運用它們,這時候練手項目就很適合了。
五、實戰案例
光學理論是沒用的,要學會跟著一起敲,要動手實操,才能將自己的所學運用到實際當中去,這時候可以搞點實戰案例來學習。
???**學習資源已打包,需要的小伙伴可以戳這里:【學習資料】?






)












