原文出處
[2111.09734] ClipCap: CLIP Prefix for Image Captioning (arxiv.org)
原文翻譯
接上篇
《ClipCap》論文筆記(上)-CSDN博客
4. Results
Datasets.我們使用 COCO-captions [7,22]、nocaps [1] 和 Conceptual Captions [33] 數據集。我們根據Karpathy等人[17]拆分對前者進行分割(對數據集),其中訓練集每張圖像包含120,000張圖像和5個標題。由于 COCO 僅限于 80 個類別,因此 nocaps 數據集旨在衡量對未曾出現的類和概念的泛化。它僅包含驗證集和測試集,使用 COCO 本身進行訓練。nocaps 數據集分為三個部分——域內僅包含僅描繪 COCO 類的圖像,近域包含 COCO 和新類,域外僅包含新類。正如Li等人[19]所建議的,我們只使用驗證集來評估模型。盡管一些方法利用新類的對象標簽,但我們只考慮沒有額外的監督的設置,因為我們發現它在實踐中更適用。因此,我們不使用受約束的波束搜索 [2]。概念字幕數據集由 3M 對圖像和字幕組成,這些圖像和字幕來自網絡和后處理。由于圖像和字幕的風格種類繁多,它被認為比 COCO 更具挑戰性,而不限于特定類別。為了關注概念,該數據集中的特定實體被替換為一般概念。例如,在圖 1 中,名稱被替換為“政治家”。為了評估,我們使用由 12.5K 圖像組成驗證集,因為測試集不公開。因此,我們沒有使用該集合進行驗證。
Baselines.我們將我們的方法與Li等人[19](稱為Oscar)、視覺語言預訓練模型(VLP)[47]和Anderson等人[4]的杰出工作進行了比較,記為BUTD。這些模型首先使用目標檢測網絡[31]生成視覺特征。然后BUTD利用LSTM生成字幕,而VLP和Oscar使用transformer,訓練方法與Bert相似,VLP 和 Oscar 都在數百萬個圖像-文本對上利用了廣泛的預訓練過程。Oscar [19] 還使用與我們的設置相比的額外監督,以每個圖像的對象標簽形式。
我們的默認配置采用 Transformer 映射網絡,無需微調語言模型,表示為 Ours;Transformer。此外,我們還評估了我們利用 MLP 映射網絡的變體,并對語言模型進行微調,表示為 Ours;MLP + GPT2 tuning。其他配置在表1(D)中進行了評估。

Evaluation metrics.與Li等人[19]類似,我們使用常用指標BLEU[27]、METEOR[10]、CIDEr[37]和SPICE[3]在COCO數據集上驗證我們的結果,以及使用CIDEr和SPICE的nocaps數據集。對于概念字幕,我們報告了作者 [33] 所建議的 ROUGE-L [21]、CIDEr 和 SPICE。此外,我們測量訓練時間和可訓練參數的數量,以驗證我們方法的適用性。減少訓練時間可以快速獲得新數據的新模型,創建一組模型并降低能耗。與其他工作類似,我們報告了 GPU 小時的訓練時間和使用的 GPU 模型。可訓練參數的數量是表示模型可行性的一種流行度量。
Quantitative evaluation.具有挑戰性的概念字幕數據集的定量結果如表中所示。1(A)。可以看出,我們超越了VLP的結果,同時訓練時間減少了幾個數量級。我們注意到,我們沒有微調 GPT-2 的輕量級模型在該數據集上取得了較差的結果。我們假設由于風格種類繁多,比我們的輕模型需要更多的表達模型,這會導致參數計數顯著降低。我們只與VLP進行比較,因為其他基線沒有發布結果,也沒有針對該數據集訓練模型。標簽。
1(B) 顯示了 nocaps 數據集的結果,其中我們獲得了與最先進的 Oscar 方法相當的結果。可以看出,Oscar 獲得了稍好的 SPICE 分數,我們獲得了略好的 CIDEr 分數。盡管如此,我們的方法只使用了一小部分訓練時間和可訓練參數,不需要額外的對象標簽,因此在實踐中更有用。
標簽。1(C) 顯示了 COCO 數據集的結果。Oscar 取得了最好的結果,但是,它以對象標簽的形式使用額外的輸入。我們的結果接近于VLP和BUTD,它利用了更多的參數和訓練時間。請注意,VLP 和 Oscar 的訓練時間不包括預訓練步驟。例如,VLP 的預訓練需要對消耗 1200 GPU 小時的概念字幕進行訓練。
概念字幕和 nocaps 都旨在對比 COCO 更多樣化的視覺概念進行建模。因此,我們得出結論,我們的方法更適合使用快速訓練過程泛化到不同的數據。這源于利用CLIP和GPT-2已經豐富的語義表示。
Qualitative evaluation.圖3和圖4分別給出了概念字幕和COCO數據集測試集中未經策劃的第一個示例的可視化結果。可以看出,我們生成的標題是有意義的,并且成功地描述了兩個數據集的圖像。我們在圖 1 中展示了從網絡中收集的其他示例。可以看出,我們的概念字幕模型可以很好地推廣到任意看不見的圖像,因為它是在相當大的和多樣化的圖像集上訓練的。我們還在智能手機圖像上的圖5結果中展示了這一點,以進一步證明對新場景的泛化。此外,即使僅在 COCO 上訓練,我們的模型也成功地識別了不常見的對象。例如,我們的方法識別木勺或蠟燭比圖 3 中的 Oscar 更好的蛋糕,因為 CLIP 是在一組不同的圖像上進行預訓練的。然而,我們的方法在某些情況下仍然失敗,例如識別圖 3 中火車旁邊的自行車。這繼承自 CLIP 模型,它確實不首先感知自行車。我們得出結論,我們的模型將受益于提高 CLIP 對象檢測能力,但將此方向留給未來的工作。對于概念字幕,我們的方法主要產生準確的字幕,例如感知圖 4 中的綠色 3d 人。正如預期的那樣,我們的方法仍然存在數據偏差。例如,它將圖 4 中的臥室圖像描述為“該屬性在市場上為 1 英鎊”,在訓練期間目睹了此類屬性廣告字幕。


Language model fine-tuning.如第 1 節所述。3,微調語言模型會產生更具表現力的模型,但隨著可訓練參數數量的增加,它也更容易受到過度擬合的影響。從表中可以看出。1,兩種變體——有和沒有語言模型微調——具有可比性。在極其復雜的概念字幕數據集上,我們通過微調獲得了更好的結果。雖然在流行的 COCO 數據集上,避免微調取得了更好的結果。關于 nocaps 數據集,結果大致相等,因此較輕的模型更可取。因此,我們假設呈現獨特風格的極其詳細的數據集或數據集需要更多的表達能力,因此它更有可能從微調中受益。
Prefix Interpretability.
為了進一步理解我們的方法和結果,我們建議將生成的前綴解釋為單詞序列。由于前綴和詞嵌入共享相同的潛在空間,因此可以類似地對待它們。我們在余弦相似度下將每個 kprefix 嵌入解釋為最接近的詞匯標記。圖 6 顯示了圖像、生成的字幕及其前綴解釋的示例。當映射網絡和 GPT-2 都經過訓練時,解釋是有意義的。在這種情況下,解釋包含與圖像內容相關聯的顯著詞。例如,摩托車并在第一個示例中展示。然而,當我們只訓練映射網絡時,解釋基本上變得不可讀,因為網絡還負責操縱固定語言模型(此時mapper純純做一個適配器的作用)。事實上,同一模型的不同圖像之間共享相當大的前綴嵌入部分,因為它對 GPT-2 執行相同的調整。

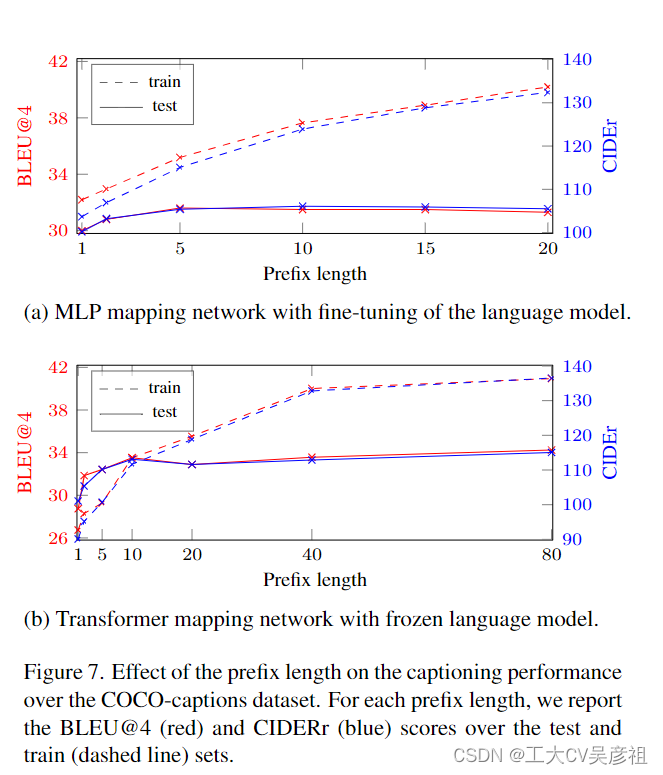
Prefix length.Li 和 Liang [20] 表明,增加前綴長度的大小,直到某個值,可以提高模型在底層任務上的性能。此外,任務之間的飽和度長度可能不同。對于圖像字幕任務,我們在我們方法的兩種配置上使用 COCO 數據集對前綴長度進行了消融研究:Ours;Transformer 和 Ours;MLP + GPT2 調整。結果如圖7所示。對于每個前綴大小和配置,我們訓練網絡5個epoch,并報告測試集和訓練集上的BLEU@4和CIDEr評分。
如圖 7a 所示,由于可訓練參數的數量很大,在允許調整語言模型的同時增加前綴大小會導致對訓練集的過度擬合。然而,當語言模型被凍結時,我們對訓練和測試的評估都有改進,如圖 7b 所示。當然,非常小的前綴長度會產生較差的結果,因為模型不夠表達。此外,我們指出 MLP 架構本質上更有限,因為它不適用于長前綴。例如,前綴大小為 40 意味著具有超過 450M 參數的網絡,這對于我們的單個 GPU 設置是不可行的。Transformer 架構允許增加前綴大小,而參數數量僅略有增加,但僅增加到 80——由于注意力機制的二次內存成本。
Mapping network.映射網絡架構的消融研究如表中所示。1(C),(D)。可以看出,通過語言模型微調,MLP 取得了更好的結果。但是,當語言模型被凍結時,Transformer會更好。我們得出結論,當使用語言模型的微調時,變壓器架構的表達能力是不必要的。
Implementation details.對于 MLP 映射網絡,我們使用 K = 10 的前綴長度,其中 MLP 包含單個隱藏層。對于轉換器映射網絡,我們將 CLIP 嵌入設置為 K = 10 個常量標記,并使用 8 個多頭自注意力層,每個隱藏層有 8 個頭。我們使用 40 的批量大小訓練了 10 個 epoch。為了優化,我們使用 Loshchilov 等人介紹的權重衰減修復的 AdamW [18]。 [24],學習率為 2e-5 和 5000 個預熱步驟。對于 GPT-2,我們采用了 Wolf 等人的實現。 [41]。
5. Conclusion
總體而言,我們基于 CLIP 的圖像字幕方法易于使用,不需要任何額外的注釋,并且訓練速度更快。盡管我們提出了一個更簡單的模型,但隨著數據集變得更加豐富和更多樣化它展示了更多優點。我們將我們的方法視為新的圖像字幕范式的一部分,專注于利用現有模型,同時只訓練最小映射網絡。這種方法本質上學會了將預訓練模型的現有語義理解適應目標數據集的風格,而不是學習新的語義實體。我們相信,在不久的將來利用這些強大的預訓練模型將獲得牽引力。因此,了解如何利用這些組件是非常有意義的。在未來的工作中,我們計劃通過利用映射網絡將預訓練模型(例如 CLIP)合并到其他具有挑戰性的任務中,例如視覺問答或圖像到 3D 翻譯。












)

)
:嶺回歸、Lasso回歸、彈性網絡回歸構建預測模型)

)

