- 🍁?個人主頁:愛編程的Tom
- 💫 本篇博文收錄專欄:Java專欄
- 👉?目前其它專欄:c系列小游戲?????c語言系列--萬物的開始_?等?? ? ? ? ? ? ?
- 🎉 歡迎 👍點贊?評論?收藏💖三連支持一下博主🤞
- 🧨現在的沉淀就是對未來的鋪墊🎨?
目錄
前言?
1. 搜索樹?
概念
搜索樹的部分操作?
查找?
插入?
刪除?
性能分析?
2. 搜索??
概念及場景?
模型?
3. Map 的使用?
Map的常用方法?
TreeMap和HashMap的區別:?
4. Set 的說明?
常見方法說明?
TreeSet和HashSet的區別?
5. 哈希表?
什么是哈希表
6. 哈希沖突?
什么是哈希沖突?
如何避免?
避免方法1-哈希函數設計?
避免方法2-負載因子調節?
哈希沖突的解決方法?
哈希沖突解決-閉散列?
哈希沖突解決-開散列/哈希桶?
沖突嚴重時的解決辦法?
性能分析?
 ???????
???????
前言?
本篇博客將描述Java當中十分重要的一個概念,即Map和Set的深入知識,幫助大家理解其中內涵,從而更深入的了解到關于HashMap和HashSet的相關內容……
1. 搜索樹?
-
概念
二叉搜索樹又稱二叉排序樹,它或者是一棵空樹,或者是具有以下性質的二叉樹:
- 若它的左子樹不為空,則左子樹上所有節點的值都小于根節點的值
- 若它的右子樹不為空,則右子樹上所有節點的值都大于根節點的值
- 它的左右子樹也分別為二叉搜索樹?
-
搜索樹的部分操作?
-
查找?
此處從根節點開始查找,然后是根的左子樹,根的右子樹。?
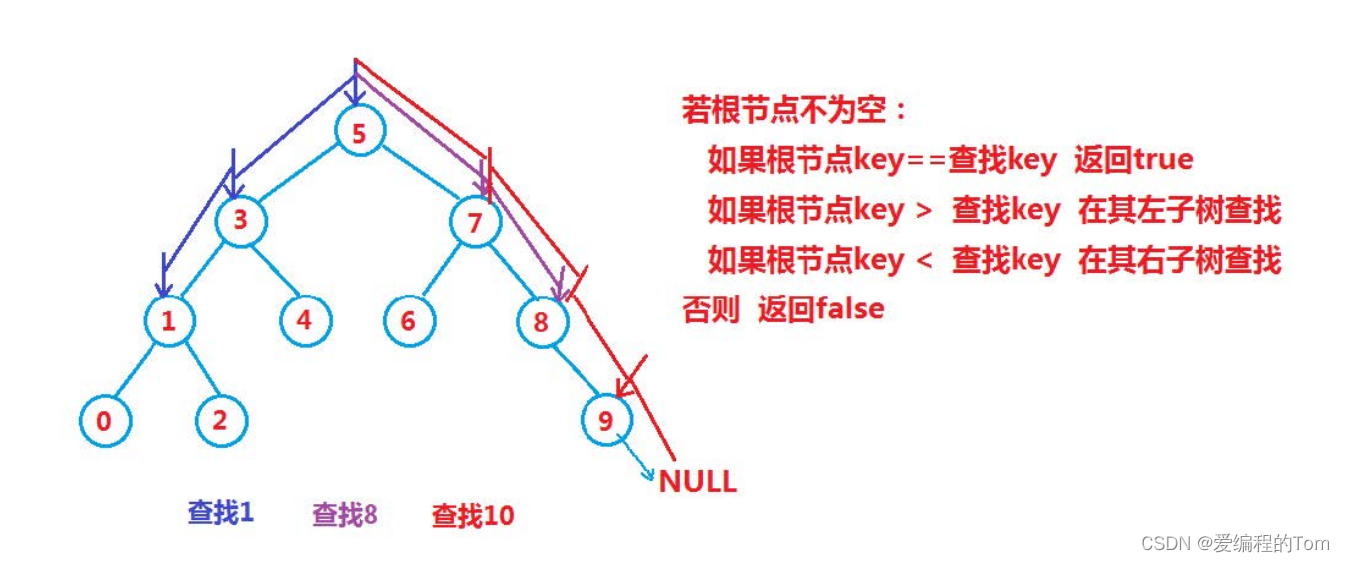
-
插入?
?1. 如果樹為空樹,即根 == null,直接插入

、2. 如果樹不是空樹,按照查找邏輯確定插入位置,插入新結點

-
刪除?
?設待刪除結點為 cur, 待刪除結點的雙親結點為 parent
1. cur.left == null
- ?????????cur 是 root,則 root = cur.right
- ?????????cur 不是 root,cur 是 parent.left,則 parent.left = cur.right
- ?????????cur 不是 root,cur 是 parent.right,則 parent.right = cur.right
2. cur.right == null
- ????????cur 是 root,則 root = cur.left
- ????????cur 不是 root,cur 是 parent.left,則 parent.left = cur.left
- ????????cur 不是 root,cur 是 parent.right,則 parent.right = cur.left
3. cur.left != null && cur.right != null
????????需要使用替換法進行刪除,即在它的右子樹中尋找中序下的第一個結點(關鍵碼最小),用它的值填補到被刪除節點中,再來處理該結點的刪除問題。
下面給出其參考代碼:?
public class BinarySearchTree {public static class Node {int key;Node left;Node right;public Node(int key) {this.key = key;}}private Node root = null;/*** 在搜索樹中查找 key,如果找到,返回 key 所在的結點,否則返回 null* @param key* @return*/public Node search(int key) {Node cur = root;while (cur != null) {if (key == cur.key) {return cur;} else if (key < cur.key) {cur = cur.left;} else {cur = cur.right;}}return null;}/*** 插入* @param key* @return true 表示插入成功, false 表示插入失敗*/public boolean insert(int key) {if (root == null) {root = new Node(key);return true;}Node cur = root;Node parent = null;while (cur != null) {if (key == cur.key) {return false;} else if (key < cur.key) {parent = cur;cur = cur.left;} else {parent = cur;cur = cur.right;}}Node node = new Node(key);if (key < parent.key) {parent.left = node;} else {parent.right = node;}return true;}/*** 刪除成功返回 true,失敗返回 false* @param key* @return*/public boolean remove(int key) {Node cur = root;Node parent = null;while (cur != null) {if (key == cur.key) {break;} else if (key < cur.key) {parent = cur;cur = cur.left;} else {parent = cur;cur = cur.right;}}// 該元素不在二叉搜索樹中if(null == cur){return false;}/*根據cur的孩子是否存在分四種情況1. cur左右孩子均不存在2. cur只有左孩子3. cur只有右孩子4. cur左右孩子均存在看起來有四種情況,實際情況1可以與情況2或者3進行合并,只需要處理是那種情況即可除了情況4之外,其他情況可以直接刪除情況4不能直接刪除,需要在其子樹中找一個替代節點進行刪除return true;}
}-
性能分析?
插入和刪除操作都必須先查找,查找效率代表了二叉搜索樹中各個操作的性能。
對有n個結點的二叉搜索樹,若每個元素查找的概率相等,則二叉搜索樹平均查找長度是結點在二叉搜索樹的深度的函數,即結點越深,則比較次數越多。
但對于同一個關鍵碼集合,如果各關鍵碼插入的次序不同,可能得到不同結構的二叉搜索樹:
 ?
?
最優情況下,二叉搜索樹為完全二叉樹,其平均比較次數為:
最差情況下,二叉搜索樹退化為單支樹,其平均比較次數為:N/2
問題:如果退化成單支樹,二叉搜索樹的性能就失去了。那能否進行改進,不論按照什么次序插入關鍵碼,都可以是二叉搜索樹的性能最佳??
答:可以使用AVL樹
AVL樹是一種嚴格平衡的二叉搜索樹,通過在每次插入和刪除節點后進行旋轉操作,來確保每個節點的左右子樹高度差不超過1。
-
和 java 類集的關系?
TreeMap 和 TreeSet 即 java 中利用搜索樹實現的 Map 和 Set;實際上用的是紅黑樹,而紅黑樹是一棵近似平衡的二叉搜索樹,即在二叉搜索樹的基礎之上 + 顏色以及紅黑樹性質驗證,?
2. 搜索??
-
概念及場景?
Map和set是一種專門用來進行搜索的容器或者數據結構,其搜索的效率與其具體的實例化子類有關。以前常見的搜索方式有:
- 直接遍歷,時間復雜度為O(N),元素如果比較多效率會非常慢
- 二分查找,時間復雜度為 ,但搜索前必須要求序列是有序的
上述排序比較適合靜態類型的查找,即一般不會對區間進行插入和刪除操作了,而現實中的查找比如:
- 根據姓名查詢考試成績
- 通訊錄,即根據姓名查詢聯系方式
- 不重復集合,即需要先搜索關鍵字是否已經在集合中
可能在查找時進行一些插入和刪除的操作,即動態查找,那上述兩種方式就不太適合了
本文介紹的Map和Set是一種適合動態查找的集合容器。?
-
模型?
一般把搜索的數據稱為關鍵字(Key),和關鍵字對應的稱為值(Value),將其稱之為Key-value的鍵值對,所以模型會有兩種:
????????1. 純 key 模型,比如:
- 有一個英文詞典,快速查找一個單詞是否在詞典中
- 快速查找某個名字在不在通訊錄中
????????2. Key-Value 模型,比如:
- 統計文件中每個單詞出現的次數,統計結果是每個單詞都有與其對應的次數:單詞,單詞出現的次數>
- 梁山好漢的江湖綽號:每個好漢都有自己的江湖綽號
Map中存儲的就是key-value的鍵值對,Set中只存儲了Key。?
3. Map 的使用?
 ?
?
 說明:Map是一個接口類,該類沒有繼承自Collection,該類中存儲的是結構的鍵值對,并且K一定是唯一的,不能重復。 ?
說明:Map是一個接口類,該類沒有繼承自Collection,該類中存儲的是結構的鍵值對,并且K一定是唯一的,不能重復。 ?
- Map.Entry<K,V>?
說明:Map.Entry<K,V>?是Map內部實現的用來存放鍵值對映射關系的內部類,該內部類中主要提供了的獲取<key,value>的設置以及Key的比較方式。?

此處需注意:Map.Entry并沒有提供設置Key的方法 ?
-
Map的常用方法?

注意:
1. Map是一個接口,不能直接實例化對象,如果要實例化對象只能實例化其實現類TreeMap或者HashMap
2. Map中存放鍵值對的Key是唯一的,value是可以重復的
3. 在TreeMap中插入鍵值對時,key不能為空,否則就會拋NullPointerException異常,value可以為空。但是HashMap的key和value都可以為空。
4. Map中的Key可以全部分離出來,存儲到Set中來進行訪問(因為Key不能重復)。
5. Map中的value可以全部分離出來,存儲在Collection的任何一個子集合中(value可能有重復)。
6. Map中鍵值對的Key不能直接修改,value可以修改,如果要修改key,只能先將該key刪除掉,然后再來進行重新插入。
7. TreeMap和HashMap的區別
-
TreeMap和HashMap的區別:?
 ?
?
4. Set 的說明?
Set與Map主要的不同有兩點:Set是繼承自Collection的接口類,Set中只存儲了Key。 ?
-
常見方法說明?
 ?
?
- 注意:
1. Set是繼承自Collection的一個接口類
2. Set中只存儲了key,并且要求key一定要唯一
3. TreeSet的底層是使用Map來實現的,其使用key與Object的一個默認對象作為鍵值對插入到Map中的
4. Set最大的功能就是對集合中的元素進行去重
5. 實現Set接口的常用類有TreeSet和HashSet,還有一個LinkedHashSet,LinkedHashSet是在HashSet的基礎 上維護了一個雙向鏈表來記錄元素的插入次序。
6. Set中的Key不能修改,如果要修改,先將原來的刪除掉,然后再重新插入
7. TreeSet中不能插入null的key,HashSet可以。
8. TreeSet和HashSet的區別【如下圖】 ?
-
TreeSet和HashSet的區別?
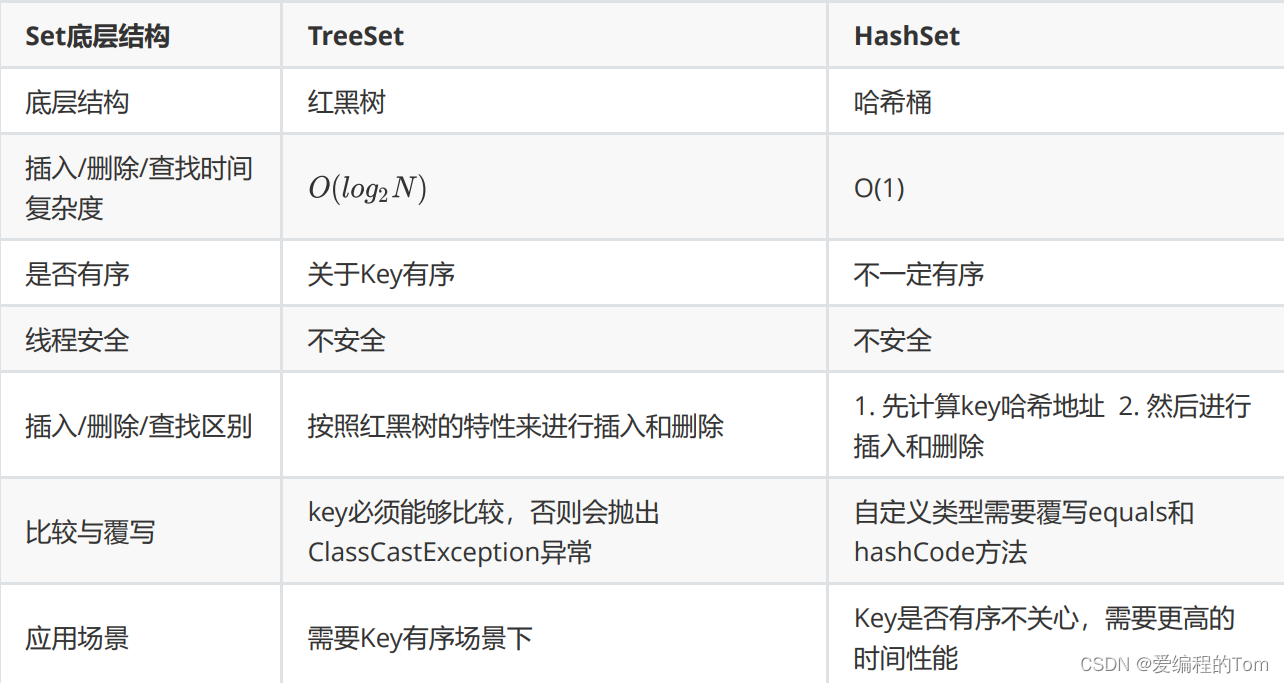 ?
?
5. 哈希表?
-
什么是哈希表
順序結構以及平衡樹中,元素關鍵碼與其存儲位置之間沒有對應的關系,因此在查找一個元素時,必須要經過關鍵碼的多次比較。順序查找時間復雜度為O(N),平衡樹中為樹的高度,即O(log(2)N?),搜索的效率取決于搜索過程中元素的比較次數。
理想的搜索方法:可以不經過任何比較,一次直接從表中得到要搜索的元素。 如果構造一種存儲結構,通過某種函 數(hashFunc)使元素的存儲位置與它的關鍵碼之間能夠建立一一映射的關系,那么在查找時通過該函數可以很快找到該元素。
當向該結構中:
- 插入元素
????????根據待插入元素的關鍵碼,以此函數計算出該元素的存儲位置并按此位置進行存放
- 搜索元素
????????對元素的關鍵碼進行同樣的計算,把求得的函數值當做元素的存儲位置,在結構中按此位置取元素比較,若關鍵碼相等,則搜索成功
該方式即為哈希(散列)方法,哈希方法中使用的轉換函數稱為哈希(散列)函數,構造出來的結構稱為哈希表(Hash Table)(或者稱散列表)
例如:數據集合{1,7,6,4,5,9};
哈希函數設置為:hash(key) = key % capacity;?(capacity為存儲元素底層空間總的大小。)??
具體圖示:
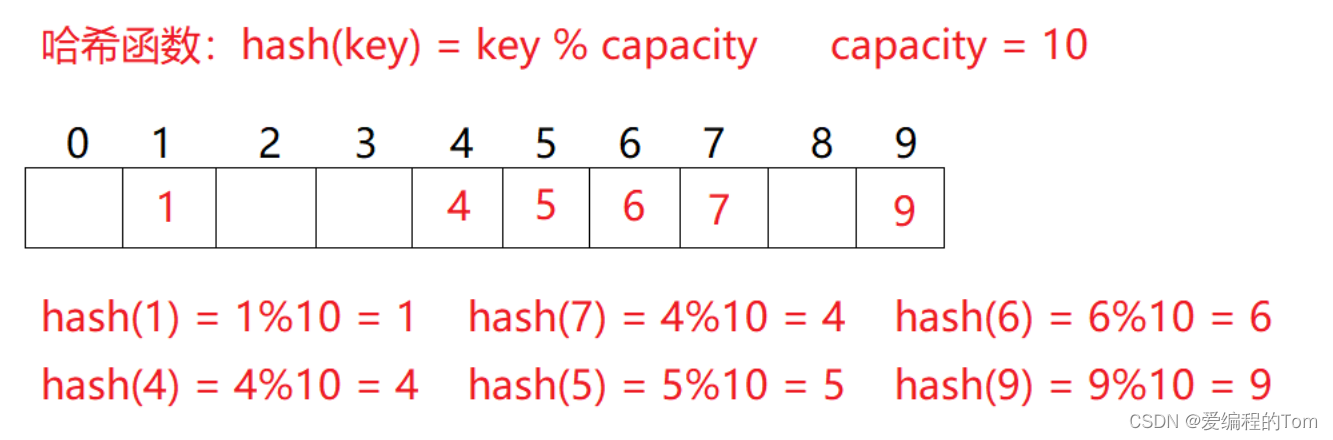 ?
?
用該方法進行搜索不必進行多次關鍵碼的比較,因此搜索的速度比較快 ?
問題:按照上述哈希方式,向集合中插入元 素44,會出現什么問題??
答:會出現沖突現象,4的地址位置已有元素。?
6. 哈希沖突?
-
什么是哈希沖突?
對于兩個數據元素的關鍵字ki和kj(i != j),有ki != kj,但有:Hash(ki ) == Hash(kj ),
即:不同關鍵字通過相同哈希哈數計算出相同的哈希地址,該種現象稱為哈希沖突或哈希碰撞。 把具有不同關鍵碼而具有相同哈希地址的數據元素稱為“同義詞”。?
-
如何避免?
首先,我們需要明確一點,由于我們哈希表底層數組的容量往往是小于實際要存儲的關鍵字的數量的,這就導致一個問題,沖突的發生是必然的,但我們能做的應該是盡量的降低沖突率。?
-
避免方法1-哈希函數設計?
引起哈希沖突的一個原因可能是:哈希函數設計不夠合理。
哈希函數設計原則:
- 哈希函數的定義域必須包括需要存儲的全部關鍵碼,而如果散列表允許有m個地址時,其值域必須在0到m-1 之間
- 哈希函數計算出來的地址能均勻分布在整個空間中
- 哈希函數應該比較簡單 ?
- 常見哈希函數?
1. 直接定制法--(常用)
取關鍵字的某個線性函數為散列地址:Hash(Key)= A*Key + B
優點:簡單、均勻
缺點:需要事先知道關 鍵字的分布情況
使用場景:適合查找比較小且連續的情況
2. 除留余數法--(常用)
設散列表中允許的地址數為m,取一個不大于m,但最接近或者等于m的質數p作為除數,按照哈希函數: Hash(key) = key% p(p將關鍵碼轉換成哈希地址
3. 平方取中法--(了解)
假設關鍵字為1234,對它平方就是1522756,抽取中間的3位227作為哈希地址; 再比如關鍵字為4321,對 它平方就是18671041,抽取中間的3位671(或710)作為哈希地址 平方取中法比較適合:不知道關鍵字的分 布,而位數又不是很大的情況
4. 折疊法--(了解)?
折疊法是將關鍵字從左到右分割成位數相等的幾部分(最后一部分位數可以短些),然后將這幾部分疊加求和, 并按散列表表長,取后幾位作為散列地址。
折疊法適合事先不需要知道關鍵字的分布,適合關鍵字位數比較多的情況
5. 隨機數法--(了解)
選擇一個隨機函數,取關鍵字的隨機函數值為它的哈希地址,即H(key) = random(key),其中random為隨機數 函數。 通常應用于關鍵字長度不等時采用此法
6. 數學分析法--(了解)
設有n個d位數,每一位可能有r種不同的符號,這r種不同的符號在各位上出現的頻率不一定相同,可能在某 些位上分布比較均勻,每種符號出現的機會均等,在某些位上分布不均勻只有某幾種符號經常出現。可根據 散列表的大小,選擇其中各種符號分布均勻的若干位作為散列地址。
數字分析法通常適合處理關鍵字位數比較大的情況,如果事先知道關鍵字的分布且關鍵字的若干位分布較均勻的情況
注意:哈希函數設計的越精妙,產生哈希沖突的可能性就越低,但是無法避免哈希沖突
-
避免方法2-負載因子調節?

- 負載因子和沖突率的關系粗略演示?
 ?
?
所以當沖突率達到一個無法忍受的程度時,我們需要通過降低負載因子來變相的降低沖突率。
已知哈希表中已有的關鍵字個數是不可變的,那我們能調整的就只有哈希表中的數組的大小。?
當負載因子過大時,需要進行擴容,重新哈希,參考代碼如下:
private void reSize() {//大于0.75處理Node[] newArray = new Node[array.length*2];// 重新哈希for (int i = 0; i < array.length; i++) {Node cur = array[i];while (cur != null) {int index = cur.key % newArray.length;//記錄之前的cur.nextNode curNext = cur.next;//實施頭插法,插入到新數組cur.next = newArray[index];newArray[index] = cur;cur = curNext;}}//把數據給到原數組arrayarray = newArray;}-
哈希沖突的解決方法?
解決哈希沖突兩種常見的方法是:閉散列和開散列 ?
-
哈希沖突解決-閉散列?
閉散列:也叫開放定址法,當發生哈希沖突時,如果哈希表未被裝滿,說明在哈希表中必然還有空位置,那么可以 把key存放到沖突位置中的“下一個” 空位置中去。
那如何尋找下一個空位置呢??
1. 線性探測
比如之前的場景,現在需要插入元素44,先通過哈希函數計算哈希地址,下標為4,因此44理論上應該插在該位置,但是該位置已經放了值為4的元素,即發生哈希沖突。
????線性探測:從發生沖突的位置開始,依次向后探測,直到尋找到下一個空位置為止。
????插入 ????????
- ????????通過哈希函數獲取待插入元素在哈希表中的位置
- ????????如果該位置中沒有元素則直接插入新元素,如果該位置中有元素發生哈希沖突,使用線性探測找到 下一個空位置,插入新元素?
?
采用閉散列處理哈希沖突時,不能隨便物理刪除哈希表中已有的元素,若直接刪除元素會影響其他 元素的搜索。比如刪除元素4,如果直接刪除掉,44查找起來可能會受影響。因此線性探測采用標記的偽刪除法來刪除一個元素。?
2. 二次探測
線性探測的缺陷是產生沖突的數據堆積在一塊,這與其找下一個空位置有關系,因為找空位置的方式就是挨著往后逐個去找,因此二次探測為了避免該問題,找下一個空位置的方法為:Hi = ( H0+i^2 )% m, 或者:Hi = ( H0 - i^2)% m。其中:i = 1,2,3…, 是通過散列函數Hash(x)對元素的關鍵碼 key 進行計算得到的位置, m是表的大小。 對于2.1中如果要插入44,產生沖突,使用解決后的情況為: ?
?
研究表明:當表的長度為質數且表裝載因子a不超過0.5時,新的表項一定能夠插入,而且任何一個位置都不 會被探查兩次。因此只要表中有一半的空位置,就不會存在表滿的問題。在搜索時可以不考慮表裝滿的情況,但在插入時必須確保表的裝載因子a不超過0.5,如果超出必須考慮增容。 ?
因此:閉散列最大的缺陷就是空間利用率比較低,這也是哈希的缺陷。?
-
哈希沖突解決-開散列/哈希桶?
開散列法又叫鏈地址法(開鏈法、哈希桶),首先對關鍵碼集合用散列函數計算散列地址,具有相同地址的關鍵碼歸于同一子集合,每一個子集合稱為一個桶,各個桶中的元素通過一個單鏈表鏈接起來,各鏈表的頭結點存儲在哈希表中。?
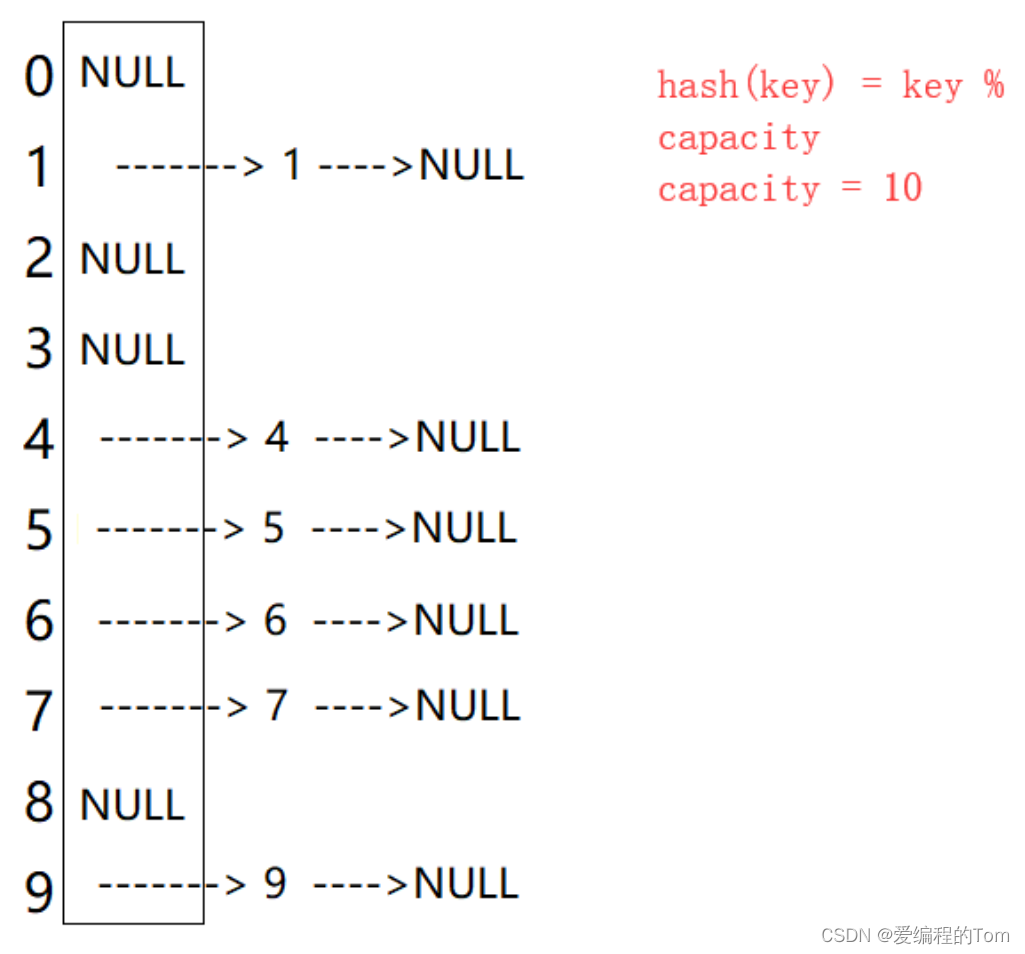 ?
?
從上圖可以看出,開散列中每個桶中放的都是發生哈希沖突的元素。
開散列,可以認為是把一個在大集合中的搜索問題轉化為在小集合中做搜索了。?
-
沖突嚴重時的解決辦法?
剛才我們提到了,哈希桶其實可以看作將大集合的搜索問題轉化為小集合的搜索問題了,那如果沖突嚴重,就意味著小集合的搜索性能其實也時不佳的,這個時候我們就可以將這個所謂的小集合搜索問題繼續進行轉化,
例如:
????????1. 每個桶的背后是另一個哈希表
????????2. 每個桶的背后是一棵搜索樹 ?
這里給出參考實現代碼:
// key-value 模型
public class HashBucket {private static class Node {private int key;private int value;Node next;public Node(int key, int value) {this.key = key;this.value = value;}
}private Node[] ?array;private int size; ? // 當前的數據個數private static ?nal double LOAD_FACTOR = 0.75;public int put(int key, int value) {int index = key % array.length;// 在鏈表中查找 key 所在的結點// 如果找到了,更新// 所有結點都不是 key,插入一個新的結點for (Node cur = array[index]; cur != null; cur = cur.next) {if (key == cur.key) {int oldValue = cur.value;cur.value = value;return oldValue;}}Node node = new Node(key, value);node.next = array[index];array[index] = node;size++;if (loadFactor() >= LOAD_FACTOR) {resize();}return -1;}private void resize() {Node[] newArray = new Node[array.length * 2];for (int i = 0; i < array.length; i++) {Node next;for (Node cur = array[i]; cur != null; cur = next) {next = cur.next;int index = cur.key % newArray.length;cur.next = newArray[index];newArray[index] = cur;}}array = newArray;}private double loadFactor() {return size * 1.0 / array.length;}public HashBucket() {array = new Node[8];size = 0;}
public int get(int key) {int index = key % array.length;Node head = array[index];for (Node cur = head; cur != null; cur = cur.next) {if (key == cur.key) {return cur.value;}}return -1;}
}-
性能分析?
雖然哈希表一直在和沖突做斗爭,但在實際使用過程中,我們認為哈希表的沖突率是不高的,沖突個數是可控的, 也就是每個桶中的鏈表的長度是一個常數,所以,通常意義下,我們認為哈希表的插入/刪除/查找時間復雜度是 O(1) 。?
-
和 java 類集的關系?
1. HashMap 和 HashSet 即 java 中利用哈希表實現的 Map 和 Set
2. java 中使用的是哈希桶方式解決沖突的
3. java 會在沖突鏈表長度大于一定閾值后,將鏈表轉變為搜索樹(紅黑樹)
4. java 中計算哈希值實際上是調用的類的 hashCode 方法,進行 key 的相等性比較是調用 key 的 equals 方 法。所以如果要用自定義類作為 HashMap 的 key 或者 HashSet 的值,必須覆寫 hashCode 和 equals 方法,而且要做到 equals 相等的對象,hashCode 一定是一致的。 ?

)
:嶺回歸、Lasso回歸、彈性網絡回歸構建預測模型)

)







)






