1:數據讀取和加載
接著上面的常規操作
加載環境變量---》獲取所有路徑---》加載文檔---》切分文檔
代碼如下:
import os
from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv()) # 獲取folder_path下所有文件路徑,儲存在file_paths里
file_paths = []
folder_path = './llm-universe/data_base/knowledge_db'
for root, dirs, files in os.walk(folder_path):# print('*'*50)# print('root:', root)# print('dirs:', dirs)# print('files:', files)# print('*'*50)for file in files:file_path = os.path.join(root, file)file_paths.append(file_path)
print('*'*50)
print('file_paths:', file_paths)from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader# 遍歷文件路徑并把實例化的loader存放在loaders里
loaders = []for file_path in file_paths:# 按照后綴對文件進行讀取file_type = file_path.split('.')[-1]if file_type == 'pdf':loaders.append(PyMuPDFLoader(file_path))elif file_type == 'md':loaders.append(UnstructuredMarkdownLoader(file_path))# 加載文件并存儲到text
texts = []
for loader in loaders: texts.extend(loader.load())
'''
載入后的變量類型為langchain_core.documents.base.Document, 文檔變量類型同樣包含兩個屬性
page_content 包含該文檔的內容。
meta_data 為文檔相關的描述性數據。
'''
text = texts[1]
# print(f"每一個元素的類型:{type(text)}.",
# f"該文檔的描述性數據:{text.metadata}",
# f"查看該文檔的內容:\n{text.page_content[0:]}",
# sep="\n------\n")from langchain.text_splitter import RecursiveCharacterTextSplitter# 切分文檔
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
print('text_splitter_type:', type(text_splitter))
split_docs = text_splitter.split_documents(texts)
print('split_docs_type:', type(split_docs))
print('split_docs長度:', len(split_docs))
print('split_docs[0]:', split_docs[0])2:加載詞向量模型和向量數據庫
# 定義持久化路徑
persist_directory = './vector_db_test/'# 刪除舊的數據庫文件(如果文件夾中有文件的話),windows電腦請手動刪除 !rm -rf '../../data_base/vector_db/chroma'#加載chroma
from langchain.vectorstores.chroma import Chromavectordb = Chroma.from_documents(documents=split_docs[:5], # 為了速度,只選擇前 20 個切分的 doc 進行生成;使用千帆時因QPS限制,建議選擇前 5 個docembedding=embedding,persist_directory=persist_directory # 允許我們將persist_directory目錄保存到磁盤上
)#存儲向量數據庫
vectordb.persist()
print(f"向量庫中存儲的數量:{vectordb._collection.count()}")在加載chroma的時候如果本身有向量數據庫可能會產生錯誤:
Traceback (most recent call last):File "/workspaces/test_codespace/createVectordb.py", line 94, in <module>vectordb = Chroma.from_documents(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/langchain_community/vectorstores/chroma.py", line 778, in from_documentsreturn cls.from_texts(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/langchain_community/vectorstores/chroma.py", line 736, in from_textschroma_collection.add_texts(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/langchain_community/vectorstores/chroma.py", line 297, in add_textsself._collection.upsert(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/models/Collection.py", line 299, in upsertself._client._upsert(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/segment.py", line 352, in _upsertself._validate_embedding_record(coll, r)File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/segment.py", line 633, in _validate_embedding_recordself._validate_dimension(collection, len(record["embedding"]), update=True)File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/segment.py", line 648, in _validate_dimensionraise InvalidDimensionException(
chromadb.errors.InvalidDimensionException: Embedding dimension 384 does not match collection dimensionality 1024這個就是因為你沒有把之前的刪除干凈,解決方法就是要么刪除原來的,要么重新開一個路徑
3:向量檢索
(1):相似度檢索
Chroma的相似度搜索使用的是余弦距離,即:下面博客里面有相似度計算的向量數據庫相關知識(搬運學習,建議還是看原文,這個只是我自己的學習記錄)-CSDN博客
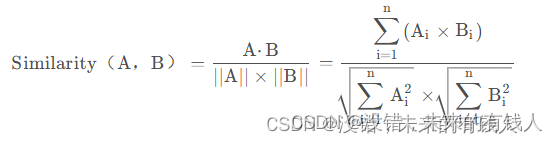
當你需要數據庫返回嚴謹的按余弦相似度排序的結果時可以使用similarity_search函數。
(2):最大邊際相關性 (MMR, Maximum marginal relevance)?檢索
如果只考慮檢索出內容的相關性會導致內容過于單一,可能丟失重要信息。
最大邊際相關性 (MMR, Maximum marginal relevance) 可以幫助我們在保持相關性的同時,增加內容的豐富度。
核心思想是在已經選擇了一個相關性高的文檔之后,再選擇一個與已選文檔相關性較低但是信息豐富的文檔。這樣可以在保持相關性的同時,增加內容的多樣性,避免過于單一的結果。

參考:最大邊界相關算法MMR(Maximal Marginal Relevance) 實踐-CSDN博客
兩個檢索的代碼:
#向量檢索
######相似度檢索
question="什么是大語言模型"
# 按余弦相似度排序的結果
sim_docs = vectordb.similarity_search(question,k=3)
print(f"檢索到的內容數:{len(sim_docs)}")
for i, sim_doc in enumerate(sim_docs):print(f"檢索到的第{i}個內容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")#######MMR檢索
mmr_docs = vectordb.max_marginal_relevance_search(question,k=3)
for i, sim_doc in enumerate(mmr_docs):print(f"MMR 檢索到的第{i}個內容: \n{sim_doc.page_content[:200]}", end="\n--------------\n"))






)






)




![洛谷 P1020 [NOIP1999 提高組] 導彈攔截](http://pic.xiahunao.cn/洛谷 P1020 [NOIP1999 提高組] 導彈攔截)