1.llm概念
1.目前 主流的開源模型體系 有哪些?
目前主流的開源LLM(語言模型)模型體系包括以下幾個:
- GPT(Generative Pre-trained Transformer)系列:由OpenAI發布的一系列基于Transformer架構的語言模型,包括GPT、GPT-2、GPT-3等。GPT模型通過在大規模無標簽文本上進行預訓練,然后在特定任務上進行微調,具有很強的生成能力和語言理解能力。
- BERT(Bidirectional Encoder Representations from Transformers):由Google發布的一種基于Transformer架構的雙向預訓練語言模型。BERT模型通過在大規模無標簽文本上進行預訓練,然后在下游任務上進行微調,具有強大的語言理解能力和表征能力。
- XLNet:由CMU和Google Brain發布的一種基于Transformer架構的自回歸預訓練語言模型。XLNet模型通過自回歸方式預訓練,可以建模全局依賴關系,具有更好的語言建模能力和生成能力。
- RoBERTa:由Facebook發布的一種基于Transformer架構的預訓練語言模型。RoBERTa模型在BERT的基礎上進行了改進,通過更大規模的數據和更長的訓練時間,取得了更好的性能。
- T5(Text-to-Text Transfer Transformer):由Google發布的一種基于Transformer架構的多任務預訓練語言模型。T5模型通過在大規模數據集上進行預訓練,可以用于多種自然語言處理任務,如文本分類、機器翻譯、問答等。
這些模型在自然語言處理領域取得了顯著的成果,并被廣泛應用于各種任務和應用中。
2.prefix LM 和 causal LM 區別是什么?
Prefix LM(前綴語言模型)和Causal LM(因果語言模型)是兩種不同類型的語言模型,它們的區別在于生成文本的方式和訓練目標。
2.1 Prefix LM
Prefix LM其實是Encoder-Decoder模型的變體,為什么這樣說?解釋如下:
- 在標準的Encoder-Decoder模型中,Encoder和Decoder各自使用一個獨立的Transformer
- 而在Prefix LM,Encoder和Decoder則共享了同一個Transformer結構,在Transformer內部通過Attention Mask機制來實現。
與標準Encoder-Decoder類似,Prefix LM在Encoder部分采用Auto Encoding (AE-自編碼)模式,即前綴序列中任意兩個token都相互可見,而Decoder部分采用Auto Regressive (AR-自回歸)模式,即待生成的token可以看到Encoder側所有token(包括上下文)和Decoder側已經生成的token,但不能看未來尚未產生的token。
下面的圖很形象地解釋了Prefix LM的Attention Mask機制(左)及流轉過程(右)。
Prefix LM的代表模型有UniLM、T5、GLM(清華滴~)
2.2 Causal LM
Causal LM是因果語言模型,目前流行地大多數模型都是這種結構,別無他因,因為GPT系列模型內部結構就是它,還有開源界的LLaMa也是。
Causal LM只涉及到Encoder-Decoder中的Decoder部分,采用Auto Regressive模式,直白地說,就是根據歷史的token來預測下一個token,也是在Attention Mask這里做的手腳。
參照著Prefix LM,可以看下Causal LM的Attention Mask機制(左)及流轉過程(右)。

2.3 總結
- Prefix LM:前綴語言模型是一種生成模型,它在生成每個詞時都可以考慮之前的上下文信息。在生成時,前綴語言模型會根據給定的前綴(即部分文本序列)預測下一個可能的詞。這種模型可以用于文本生成、機器翻譯等任務。
- Causal LM:因果語言模型是一種自回歸模型,它只能根據之前的文本生成后續的文本,而不能根據后續的文本生成之前的文本。在訓練時,因果語言模型的目標是預測下一個詞的概率,給定之前的所有詞作為上下文。這種模型可以用于文本生成、語言建模等任務。
總結來說,前綴語言模型可以根據給定的前綴生成后續的文本,而因果語言模型只能根據之前的文本生成后續的文本。它們的訓練目標和生成方式略有不同,適用于不同的任務和應用場景。
3.大模型LLM的 訓練目標
大型語言模型(Large Language Models,LLM)的訓練目標通常是最大似然估計(Maximum Likelihood Estimation,MLE)。最大似然估計是一種統計方法,用于從給定數據中估計概率模型的參數。
在LLM的訓練過程中,使用的數據通常是大量的文本語料庫。訓練目標是最大化模型生成訓練數據中觀察到的文本序列的概率。具體來說,對于每個文本序列,模型根據前面的上下文生成下一個詞的條件概率分布,并通過最大化生成的詞序列的概率來優化模型參數。
為了最大化似然函數,可以使用梯度下降等優化算法來更新模型參數,使得模型生成的文本序列的概率逐步提高。在訓練過程中,通常會使用批量訓練(batch training)的方法,通過每次處理一小批數據樣本來進行參數更新。
4.涌現能力是啥原因?
大語言模型的涌現能力:現象與解釋 - 知乎 (zhihu.com)
涌現能力(Emergent Ability)是指模型在訓練過程中能夠生成出令人驚喜、創造性和新穎的內容或行為。這種能力使得模型能夠超出其訓練數據所提供的內容,并產生出具有創造性和獨特性的輸出。
涌現能力的產生可以歸因于以下幾個原因:
- 任務的評價指標不夠平滑:因為很多任務的評價指標不夠平滑,導致我們現在看到的涌現現象。如果評價指標要求很嚴格,要求一字不錯才算對,那么Emoji_movie任務我們就會看到涌現現象的出現。但是,如果我們把問題形式換成多選題,就是給出幾個候選答案,讓LLM選,那么隨著模型不斷增大,任務效果在持續穩定變好,但涌現現象消失,如上圖圖右所示。這說明評價指標不夠平滑,起碼是一部分任務看到涌現現象的原因。
- 復雜任務 vs 子任務:展現出涌現現象的任務有一個共性,就是任務往往是由多個子任務構成的復雜任務。也就是說,最終任務過于復雜,如果仔細分析,可以看出它由多個子任務構成,這時候,子任務效果往往隨著模型增大,符合 Scaling Law,而最終任務則體現為涌現現象。
- 用 Grokking (頓悟)來解釋涌現:對于某個任務T,盡管我們看到的預訓練數據總量是巨大的,但是與T相關的訓練數據其實數量很少。當我們推大模型規模的時候,往往會伴隨著增加預訓練數據的數據量操作,這樣,當模型規模達到某個點的時候,與任務T相關的數據量,突然就達到了最小要求臨界點,于是我們就看到了這個任務產生了Grokking現象。
盡管涌現能力為模型帶來了創造性和獨特性,但也需要注意其生成的內容可能存在偏差、錯誤或不完整性。因此,在應用和使用涌現能力強的模型時,需要謹慎評估和驗證生成的輸出,以確保其質量和準確性。
5.為何現在的大模型大部分是Decoder only結構
- Encoder的低秩問題:Encoder的雙向注意力會存在低秩問題,這可能會削弱模型表達能力,就生成任務而言,引入雙向注意力并無實質好處。
- 更好的Zero-Shot性能、更適合于大語料自監督學習:decoder-only 模型在沒有任何 tuning 數據的情況下、zero-shot 表現最好,而 encoder-decoder 則需要在一定量的標注數據上做 multitask finetuning 才能激發最佳性能。
- 效率問題:decoder-only支持一直復用KV-Cache,對多輪對話更友好,因為每個Token的表示之和它之前的輸入有關,而encoder-decoder和PrefixLM就難以做到。
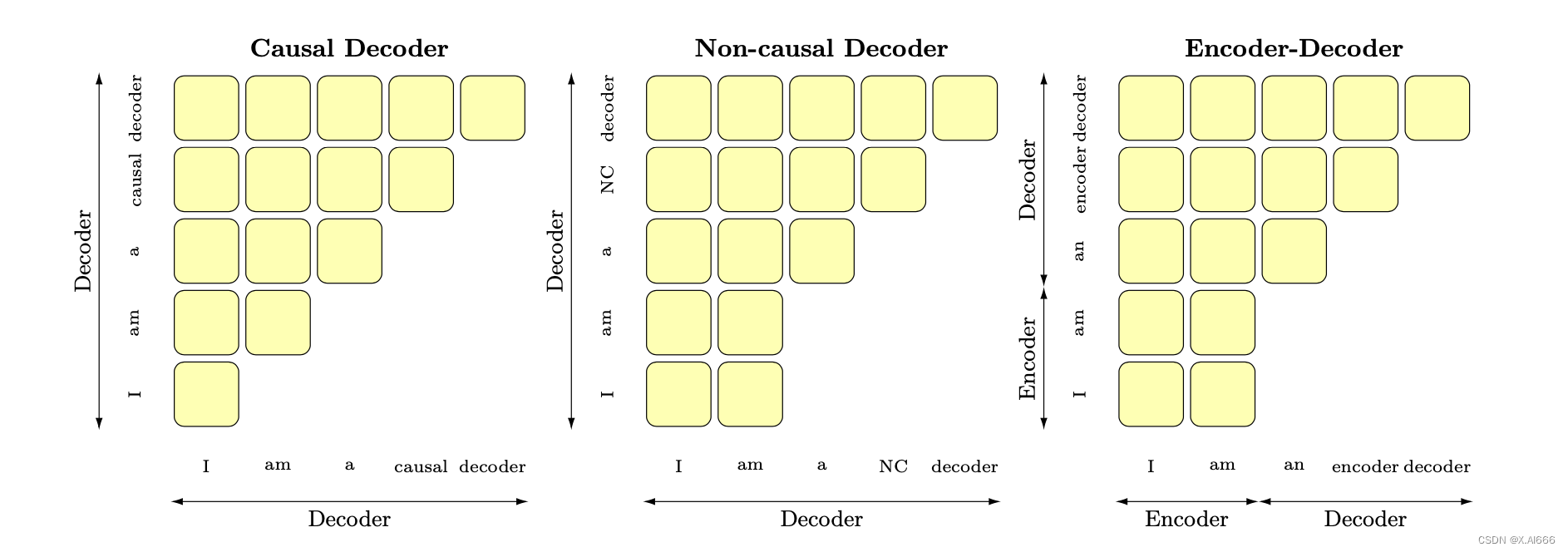
6.大模型架構介紹
Transformer 模型一開始是用來做 seq2seq 任務的,所以它包含 Encoder 和 Decoder 兩個部分;他們兩者的區別主要是,Encoder 在抽取序列中某一個詞的特征時能夠看到整個序列中所有的信息,即上文和下文同時看到;而 Decoder 中因為有 mask 機制的存在,使得它在編碼某一個詞的特征時只能看到自身和它之前的文本信息。
首先概述幾種主要的架構:
- 以BERT為代表的encoder-only
- 以T5和BART為代表的encoder-decoder
- 以GPT為代表的decoder-only,
- 以UNILM9為代表的PrefixLM(相比于GPT只改了attention mask,前綴部分是雙向,后面要生成的部分是單向的causal mask%)
6.LLMs復讀機問題
6.1 什么是 LLMs 復讀機問題?
LLMs復讀機問題(LLMs Parroting Problem)是指大型語言模型在生成文本時過度依賴輸入文本的復制,而缺乏創造性和獨特性。當面對一個問題或指令時,模型可能會簡單地復制輸入文本的一部分或全部內容,并將其作為生成的輸出,而不是提供有意義或新穎的回應。
6.2 為什么會出現 LLMs 復讀機問題?
- 數據偏差:大型語言模型通常是通過預訓練階段使用大規模無標簽數據進行訓練的。如果訓練數據中存在大量的重復文本或者某些特定的句子或短語出現頻率較高,模型在生成文本時可能會傾向于復制這些常見的模式。
- 訓練目標的限制:大型語言模型的訓練通常是基于自監督學習的方法,通過預測下一個詞或掩蓋詞來學習語言模型。這樣的訓練目標可能使得模型更傾向于生成與輸入相似的文本,導致復讀機問題的出現。
- 缺乏多樣性的訓練數據:雖然大型語言模型可以處理大規模的數據,但如果訓練數據中缺乏多樣性的語言表達和語境,模型可能無法學習到足夠的多樣性和創造性,導致復讀機問題的出現。
- 模型結構和參數設置:大型語言模型的結構和參數設置也可能對復讀機問題產生影響。例如,模型的注意力機制和生成策略可能導致模型更傾向于復制輸入的文本。
6.3 如何緩解 LLMs 復讀機問題?
為了緩解LLMs復讀機問題,可以嘗試以下方法:
- 多樣性訓練數據:在訓練階段,使用多樣性的語料庫來訓練模型,避免數據偏差和重復文本的問題。這可以包括從不同領域、不同來源和不同風格的文本中獲取數據。
- 引入噪聲:在生成文本時,引入一些隨機性或噪聲,例如通過采樣不同的詞或短語,或者引入隨機的變換操作,以增加生成文本的多樣性。這可以通過在生成過程中對模型的輸出進行采樣或添加隨機性來實現。
- 溫度參數調整:溫度參數是用來控制生成文本的多樣性的一個參數。通過調整溫度參數的值,可以控制生成文本的獨創性和多樣性。較高的溫度值會增加隨機性,從而減少復讀機問題的出現。
- Beam搜索調整:在生成文本時,可以調整Beam搜索算法的參數。Beam搜索是一種常用的生成策略,它在生成過程中維護了一個候選序列的集合。通過調整Beam大小和搜索寬度,可以控制生成文本的多樣性和創造性。
- 后處理和過濾:對生成的文本進行后處理和過濾,去除重復的句子或短語,以提高生成文本的質量和多樣性。可以使用文本相似度計算方法或規則來檢測和去除重復的文本。
- 人工干預和控制:對于關鍵任務或敏感場景,可以引入人工干預和控制機制,對生成的文本進行審查和篩選,確保生成結果的準確性和多樣性。
需要注意的是,緩解LLMs復讀機問題是一個復雜的任務,沒有一種通用的解決方案。不同的方法可能適用于不同的場景和任務,需要根據具體情況進行選擇和調整。此外,解決復讀機問題還需要綜合考慮數據、訓練目標、模型架構和生成策略等多個因素,需要進一步的研究和實踐來提高大型語言模型的生成文本多樣性和創造性。
7.LLMs輸入句子長度理論上可以無限長嗎?
理論上來說,LLMs(大型語言模型)可以處理任意長度的輸入句子,但實際上存在一些限制和挑戰。下面是一些相關的考慮因素:
- 計算資源:生成長句子需要更多的計算資源,包括內存和計算時間。由于LLMs通常是基于神經網絡的模型,計算長句子可能會導致內存不足或計算時間過長的問題。
- 模型訓練和推理:訓練和推理長句子可能會面臨一些挑戰。在訓練階段,處理長句子可能會導致梯度消失或梯度爆炸的問題,影響模型的收斂性和訓練效果。在推理階段,生成長句子可能會增加模型的錯誤率和生成時間。
- 上下文建模:LLMs是基于上下文建模的模型,長句子的上下文可能會更加復雜和深層。模型需要能夠捕捉長句子中的語義和語法結構,以生成準確和連貫的文本。
8.什么情況用Bert模型,什么情況用LLaMA、ChatGLM類大模型,咋選?
選擇使用哪種大模型,如Bert、LLaMA或ChatGLM,取決于具體的應用場景和需求。下面是一些指導原則:
- Bert模型:Bert是一種預訓練的語言模型,適用于各種自然語言處理任務,如文本分類、命名實體識別、語義相似度計算等。如果你的任務是通用的文本處理任務,而不依賴于特定領域的知識或語言風格,Bert模型通常是一個不錯的選擇。Bert由一個Transformer編碼器組成,更適合于NLU相關的任務。
- LLaMA模型:LLaMA(Large Language Model Meta AI)包含從 7B 到 65B 的參數范圍,訓練使用多達14,000億tokens語料,具有常識推理、問答、數學推理、代碼生成、語言理解等能力。LLaMA由一個Transformer解碼器組成。訓練預料主要為以英語為主的拉丁語系,不包含中日韓文。所以適合于英文文本生成的任務。
- ChatGLM模型:ChatGLM是一個面向對話生成的語言模型,適用于構建聊天機器人、智能客服等對話系統。如果你的應用場景需要模型能夠生成連貫、流暢的對話回復,并且需要處理對話上下文、生成多輪對話等,ChatGLM模型可能是一個較好的選擇。ChatGLM的架構為Prefix decoder,訓練語料為中英雙語,中英文比例為1:1。所以適合于中文和英文文本生成的任務。
在選擇模型時,還需要考慮以下因素:
- 數據可用性:不同模型可能需要不同類型和規模的數據進行訓練。確保你有足夠的數據來訓練和微調所選擇的模型。
- 計算資源:大模型通常需要更多的計算資源和存儲空間。確保你有足夠的硬件資源來支持所選擇的模型的訓練和推理。
- 預訓練和微調:大模型通常需要進行預訓練和微調才能適應特定任務和領域。了解所選擇模型的預訓練和微調過程,并確保你有相應的數據和時間來完成這些步驟。
最佳選擇取決于具體的應用需求和限制條件。在做出決策之前,建議先進行一些實驗和評估,以確定哪種模型最適合你的應用場景。
9.各個專業領域是否需要各自的大模型來服務?
各個專業領域通常需要各自的大模型來服務,原因如下:
- 領域特定知識:不同領域擁有各自特定的知識和術語,需要針對該領域進行訓練的大模型才能更好地理解和處理相關文本。例如,在醫學領域,需要訓練具有醫學知識的大模型,以更準確地理解和生成醫學文本。
- 語言風格和慣用語:各個領域通常有自己獨特的語言風格和慣用語,這些特點對于模型的訓練和生成都很重要。專門針對某個領域進行訓練的大模型可以更好地掌握該領域的語言特點,生成更符合該領域要求的文本。
- 領域需求的差異:不同領域對于文本處理的需求也有所差異。例如,金融領域可能更關注數字和統計數據的處理,而法律領域可能更關注法律條款和案例的解析。因此,為了更好地滿足不同領域的需求,需要專門針對各個領域進行訓練的大模型。
- 數據稀缺性:某些領域的數據可能相對較少,無法充分訓練通用的大模型。針對特定領域進行訓練的大模型可以更好地利用該領域的數據,提高模型的性能和效果。
盡管需要各自的大模型來服務不同領域,但也可以共享一些通用的模型和技術。例如,通用的大模型可以用于處理通用的文本任務,而領域特定的模型可以在通用模型的基礎上進行微調和定制,以適應特定領域的需求。這樣可以在滿足領域需求的同時,減少模型的重復訓練和資源消耗。
10.如何讓大模型處理更長的文本?
要讓大模型處理更長的文本,可以考慮以下幾個方法:
- 分塊處理:將長文本分割成較短的片段,然后逐個片段輸入模型進行處理。這樣可以避免長文本對模型內存和計算資源的壓力。在處理分塊文本時,可以使用重疊的方式,即將相鄰片段的一部分重疊,以保持上下文的連貫性。
- 層次建模:通過引入層次結構,將長文本劃分為更小的單元。例如,可以將文本分為段落、句子或子句等層次,然后逐層輸入模型進行處理。這樣可以減少每個單元的長度,提高模型處理長文本的能力。
- 部分生成:如果只需要模型生成文本的一部分,而不是整個文本,可以只輸入部分文本作為上下文,然后讓模型生成所需的部分。例如,輸入前一部分文本,讓模型生成后續的內容。
- 注意力機制:注意力機制可以幫助模型關注輸入中的重要部分,可以用于處理長文本時的上下文建模。通過引入注意力機制,模型可以更好地捕捉長文本中的關鍵信息。
- 模型結構優化:通過優化模型結構和參數設置,可以提高模型處理長文本的能力。例如,可以增加模型的層數或參數量,以增加模型的表達能力。還可以使用更高效的模型架構,如Transformer等,以提高長文本的處理效率。
需要注意的是,處理長文本時還需考慮計算資源和時間的限制。較長的文本可能需要更多的內存和計算時間,因此在實際應用中需要根據具體情況進行權衡和調整。



)






)




![洛谷 P1020 [NOIP1999 提高組] 導彈攔截](http://pic.xiahunao.cn/洛谷 P1020 [NOIP1999 提高組] 導彈攔截)
)


