GPU 的通信性能對于大模型的訓練有著至關重要的影響。在 HPN 網絡工程實踐中,我們的核心關注點是如何充分利用網絡硬件資源的能力,將通信性能最大化,從而提升大模型端到端的訓練性能。
1? ? HPN 網絡?—?AIPod
下圖是百度百舸的高性能網絡 HPN — AIPod 的架構示意圖。AIPod 使用 8 導軌網絡架構,以 GPU A800 服務器為例,它配有 8 張網卡,然后每張網卡分別連到一個 TOR 匯聚組的 8 個 TOR 上。在 TOR 和 LEAF 層面,我們是通過?Full?Mesh?的方式進行互聯。如果是三層 RDMA 網絡,我們在 LEAF 和 SPINE 層面也是采用 Full Mesh 的互聯方式。
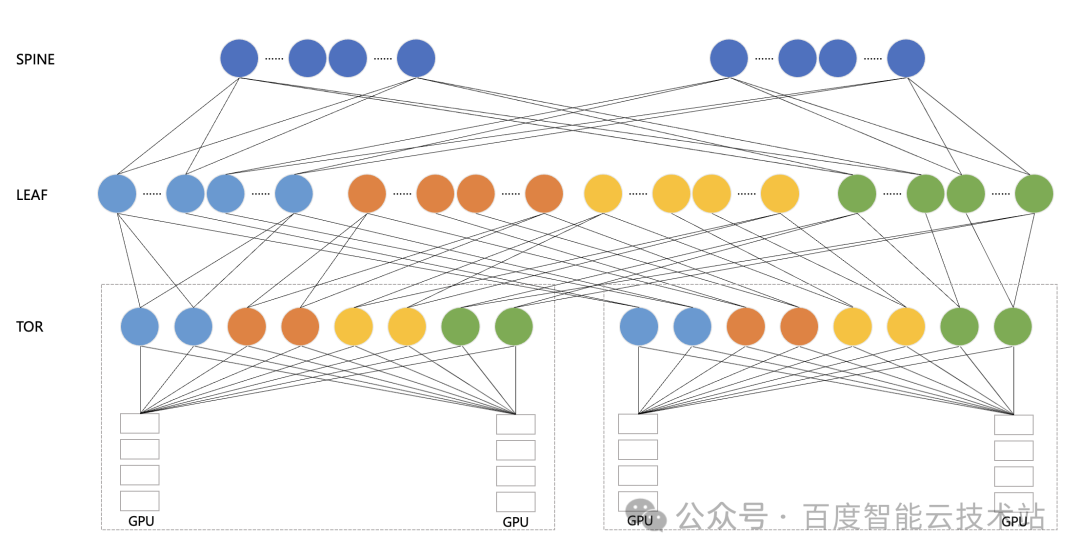
值得一提的是,在大模型訓練場景下,考慮到不同的并行策略,我們在跨機通信組產生的大多數都是同號卡流量。同號卡通信情況下最佳情況可以只經過一跳 TOR,最差情況只經過 LEAF。只有異號卡流量才可能經過 SPINE 中轉。
我們的多導軌架構已經盡可能的把跨機流量放在同 TOR 下進行通信,期望將網絡盡可能地打滿。但是在實際過程中,我們發現 100 Gbps 的網絡鏈路經常只能達到 70 Gbps 左右。
引起降速問題發生原因有很多,其中一項主要因素就是「哈希沖突」。接下來,我們就講一下百度智能云的 AIPod 是如何解決網絡哈希沖突,最終實現 95% 的「物理網絡帶寬有效性」。
2????哈希沖突
哈希沖突其實是 HPN 網絡(高性能網絡)中非常典型的問題,主要是因為 LEAF 和 SPINE 層都是通過 ECMP 來進行報文的轉發。然而 RDMA 本身采用 Kernel?Bypass?和?CPU Bypass?等操作,它很容易瞬間打滿物理網絡的硬件帶寬。在這種情況下,很容易產生哈希沖突。
我們對哈希沖突進行了深入的分析,主要分為上行沖突和下行沖突兩種情況。
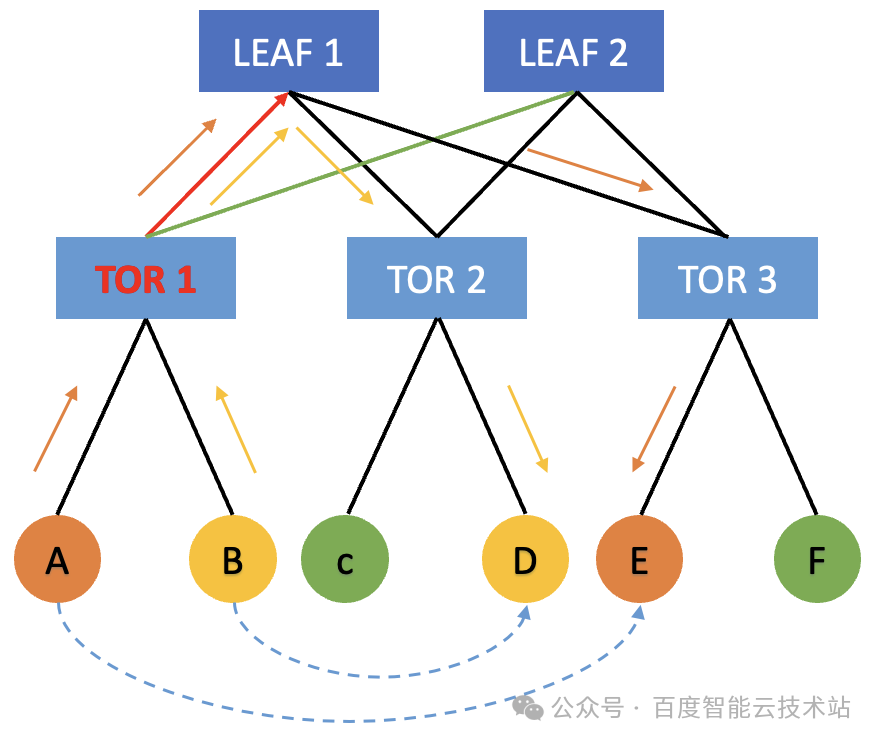
- 上行沖突
機器 A 發起了一個集合通信操作,在網絡上發送 message 的時候,它會盡可能以滿帶寬 100 Gbps 發送給 TOR 1。當 TOR 1 將流量轉發給 LEAF 層時,會根據哈希策略去隨機選擇 LEAF 1 和 LEAF 2。
與此同時,機器 B 它如果也需要向其他機器進行通信,它也會把相關的流量發送給 TOR 1。此時,TOR 1 也會根據哈希結果來選擇把流量轉發給 LEAF 1 或者 LEAF 2。在這種情況下,在 TOR 1 的上行方向就會產生概率性的哈希沖突。比如雙方都哈希到了 TOR 1 到 LEAF 1 這條鏈路,TOR 1 到 LEAF 2 這條鏈路相對空閑。此時機器?A?和機器?B?就會因為出口流量哈希不均的原因,導致各自只有 50 Gbps 的網絡帶寬,這樣就會對通信的性能乃至端到端的性能產生很大的影響。
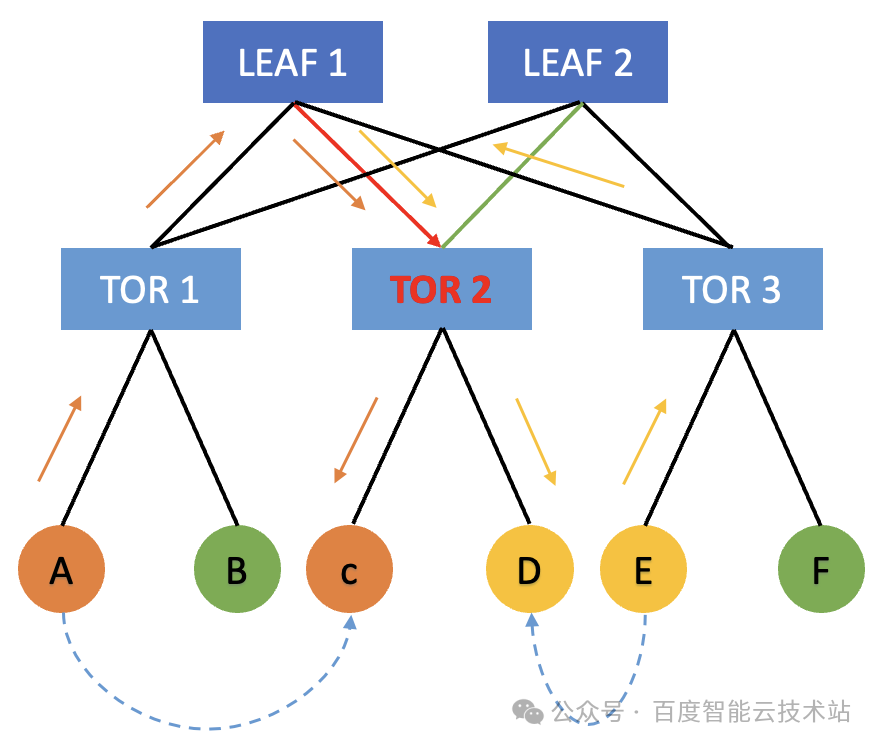
- 下行沖突
機器?A?如果要向機器?C?發送數據,同時機器?E?要向機器 D 發送數據。在哈希過程中,如果 A 機器走了 TOR 1 ->? LEAF 1-> TOR 2 -> C 的鏈路 ,而機器 E 走了 TOR 3 -> LEAF 1 -> TOR 2 -> D 的鏈路,那么也會導致這兩條流出現下行沖突,也會導致網絡流量減半,讓端到端的集合通信的性能下降。
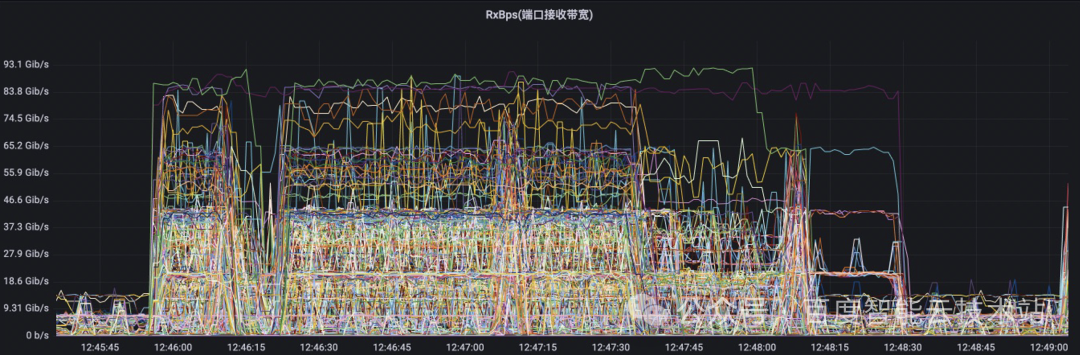
在大模型訓練的場景下,集合通信具有典型的同步特征,如果一個 GPU 通信降速,會導致同通信組的其他 GPU 同步等待,進而導致全集群的 GPU 通信降速。這種同步特征會導致哈希沖突的影響被進一步放大。
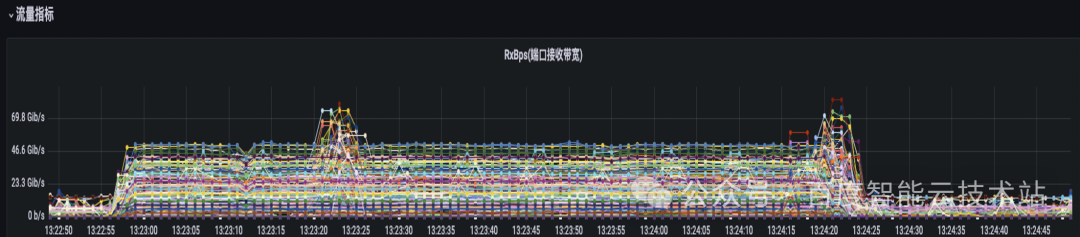
我們用大模型的流量特征圖來舉個例子。在下圖中的每一根線代表的是交換機上的某一條物理鏈路的流量特征。在該 case 中,端到端的擴展效率從 90% 以上降到了 70% 左右。我們可以看到,物理交換機上面的物理鏈路的流量負載情況有很大差距。有些鏈路的帶寬非常的低,有些鏈路的帶寬非常的高。這也意味著我們物理網絡的帶寬沒有得到充分的利用。
這一些流量負載非常高的物理鏈路,說明從 TOR 到 LEAF 的方向上出現了哈希沖突,導致集合通信的性能下降。
3????解決方案 1?—?增加 RDMA 流數
針對上述哈希沖突的問題,我們自然而然想到的一個解決方案是:增加 RDMA 的流數。
比如說目前的網絡中只有 2 條流,那這? 2 條流可能很容易就哈希到同一個鏈路上。如果我們增加 RDMA 的 QP 數,比如說 16 條流、64 條流,那相應的哈希沖突的概率就會減少很多,從而減少交換機哈希沖突的現象。
下圖是一個開啟多 QP 之后的網絡監控圖。可以看到 RDMA 的流量相對均勻地哈希到不同的網絡鏈路上,哈希沖突概率大大降低。
但是在實際的集合通信過程中,增加 QP 會帶來一些額外的開銷。比如網卡側可能會因為多 QP 帶來額外的調度上的開銷。在完全沒有哈希沖突的情況下,多 QP 的性能其實是不如單 QP 的。但是因為哈希沖突問題存在,在這種場景下,我們只能選擇多流來減輕哈希沖突問題。
4????解決方案?2?—?親和性調度
前一種方案的核心思路是圍繞交換機展開的,此時網絡流量已經送到了 LEAF 交換機上。如果出現了哈希沖突,交換機通過多流的方式來減輕哈希沖突的概率。
第二種方案的思路則是圍繞減少流量上送 LEAF 展開的。
通過前面的分析,我們知道哈希沖突主要是在 TOR 到 LEAF 的上行鏈路和 LEAF 到 TOR 的下行鏈路中產生的。所以我們可以通過減少流量上送到 LEAF,或者上送到 SPINE 的方式,從而減少交換機哈希沖突的概率。
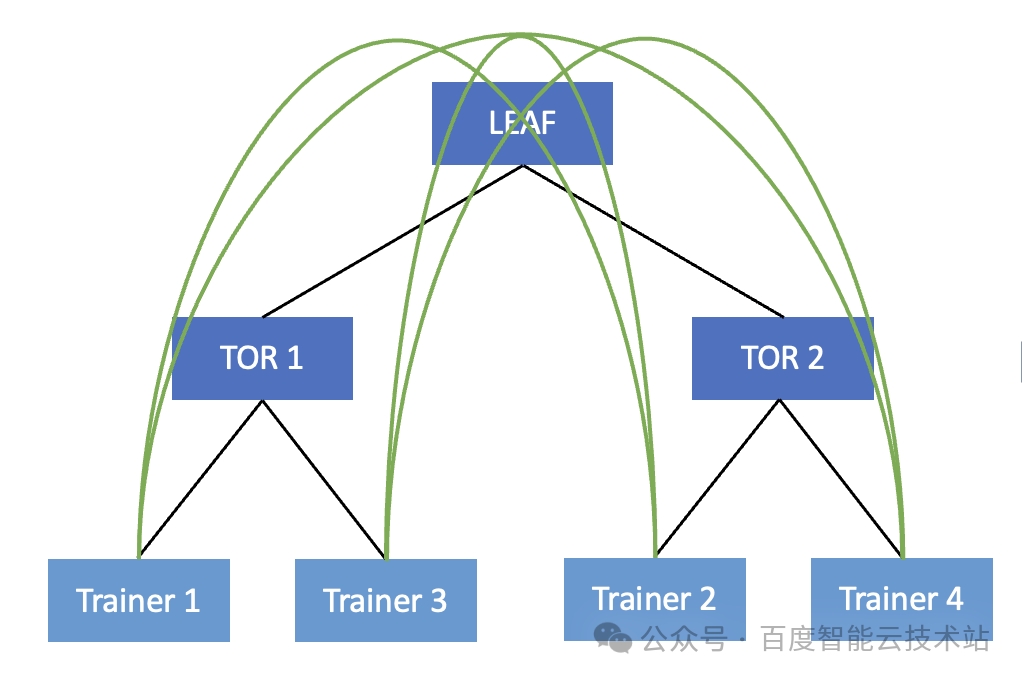
我們以一個簡單場景為例。在下圖中我們將 4 個 Trainer 建立為一個通信組 。在當前通信組內,實際的通信順序為 Trainer 1 -> Trainer 2 -> Trainer 3 -> Trainer 4 -> Trainer 1 。
但是由于當前的接線順序,Trainer 1 和 Trainer 3 連在同一個 TOR 下,Trainer 2 和 Trainer 4 連在同一個 TOR 下。那么實際 Trainer 1 產生的流量,需要上送到 TOR 繞行 LEAF 才能到達 Trainer 2,然后 Trainer 2 的流量再次繞行 LEAF 來到 Trainer 3,Trainer 3 再繞行 LEAF 轉發給 Trainer 4。
我們可以看到在物理網絡層面這是一個無序的調度,很有可能導致集合通信產生的流量都要上送到 LEAF,這就大大增加了交換機產生哈希沖突的概率。
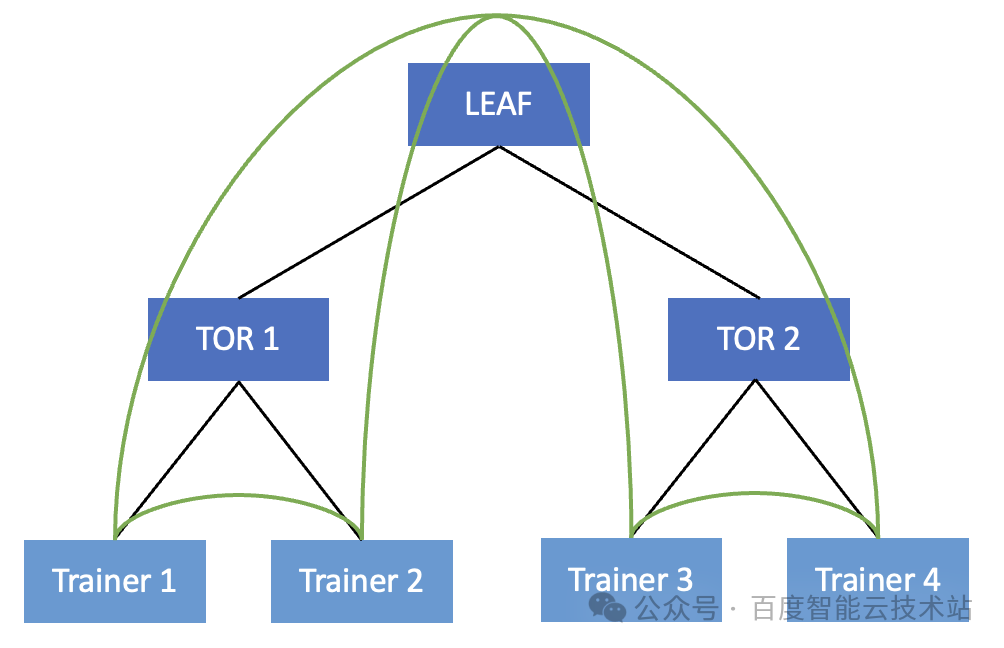
為了解決該問題,我們可以采用一種很簡單的方式。在組建通信組的時候,讓 Trainer 1 和 Trainer 2,Trainer 3 和 Trainer 4 在同一個 TOR 下,做為相鄰的 Trainer。
此時,只有 Trainer 2 發給 Trainer 3 的時候需要繞行,有一半的流量都可以直接在 TOR 內進行轉發。這其實就啟發了我們在做任務 Trainer 排序的時候要盡可能做好 TOR 親和性的調度。具體我們可以從兩個方面入手:
- 在提交任務的過程中,盡可能在同一個 TOR 上去調度機器,來提交相應的訓練任務。
- 在啟動任務的時候,盡可能的把相鄰的 Trainer 調度到同一個 TOR 上面。
5????解決方案 3 — DLB 動態負載均衡
上述兩種方案都是從概率的視角來解決哈希沖突,某種意義上來說都是在撞運氣。網絡哈希沖突不可避免,我們只能減少發生的概率。那有沒有什么終極辦法能夠從根本上去解決交換機的哈希沖突呢?
第三種方法就是 DLB 動態負載均衡。
哈希沖突產生的根源在于如果某一條流根據其五元組特性,哈希到了某一條鏈路中,后續如果產生了其他五元組的流哈希到同一條鏈路來爭搶物理帶寬,每條鏈路的流量將會減半。如果可以允許同一條流的報文轉發到不同的物理鏈路中去,交換機根據鏈路實時負載來轉發報文,那么就可以解決上述的問題,這也是我們 DLB 的核心思路。
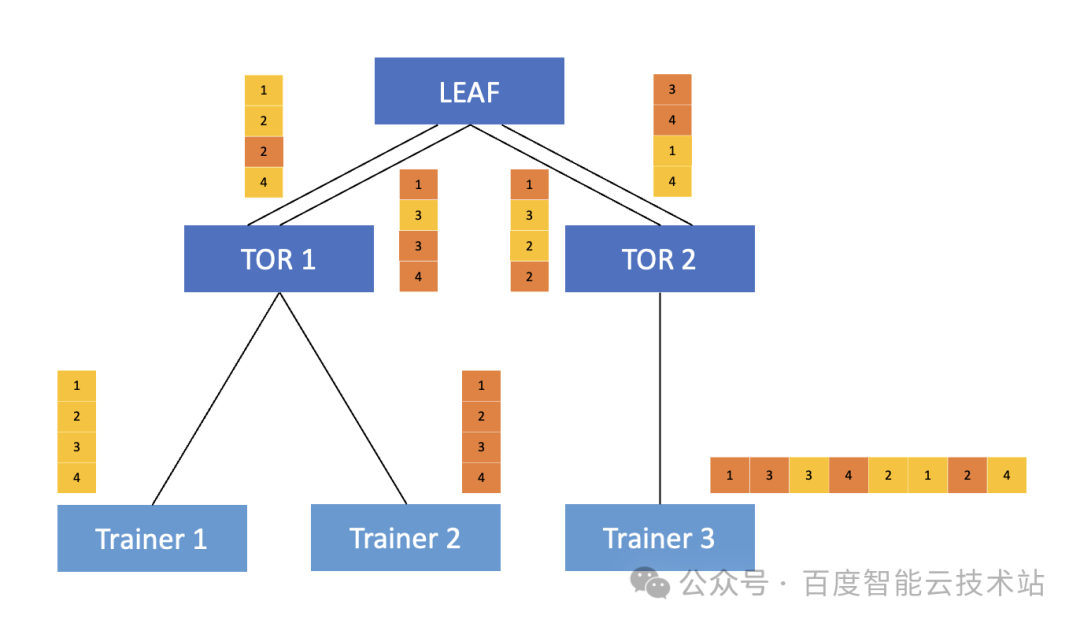
我們看下面這個例子。Trainer 1 和 Trainer 2 要發送數據給到 Trainer 3,在 TOR ?到 LEAF 上存在兩條物理鏈路,其中,Trainer 1 中需要通信的報文為黃色的 1234,Trainer 2 中則是為橙色的 1234。
接下來,我們介紹下在 DLB 場景下的完整的轉發過程。DLB 功能本質上是基于 InfiniBand 的 AR 擴展實現的。
用 Trainer 1 來舉例,網卡在發送報文的時候,對發送的報文做了特殊的 AR bit 標記。當 TOR 識別到了該標記之后,就會對該報文走 DLB 轉發邏輯,在轉發給 LEAF 的時候會根據鏈路的實際負載來進行轉發,將報文送到相對空閑的物理鏈路上,從而保證兩條鏈路上的流量相對均衡。在這種情況下,由于同一條流的不同報文走了不同的轉發路徑,自然會發生亂序,因此當 Trainer 3 收到后,需要收到的亂序的報文進行重組。
以上就是整體 DLB 的實現策略。核心思想是基于鏈路負載選擇相應的轉發路徑,支持對報文的 per-packet 轉發邏輯。
目前 DLB 方案基于百度自研的交換機實現。我們可以實現均衡的把所有接收到的流量分發到不同的物理鏈路中,從根源上解決哈希沖突的問題。在百度內部的大模型訓練場景中,網絡帶寬有效性可以提升 10% 左右。
在百度智能云 HPN 集群 AIPod 中,使用「親和性調度」配合「DLB 動態負載均衡」的方案,可以徹底解決物理網絡集群哈希沖突的難題,這使得物理網絡「帶寬有效性」達到了 95% 。
此外,我們推出的自研的百度集合通信庫 BCCL,聯合框架層做了進一步的性能調優。針對特殊的業務流量特征,比如局部二打一等問題,進行通信層面的深度優化,大模型訓練任務的端到端性能提升 1.5%。

![洛谷 P1020 [NOIP1999 提高組] 導彈攔截](http://pic.xiahunao.cn/洛谷 P1020 [NOIP1999 提高組] 導彈攔截)
)









(一))
![[數據集][目標檢測]人員狀態跑睡抽煙打電話跌倒檢測數據集4943張5類別](http://pic.xiahunao.cn/[數據集][目標檢測]人員狀態跑睡抽煙打電話跌倒檢測數據集4943張5類別)
![[Leetcode 136][Easy]-只出現一次的數字](http://pic.xiahunao.cn/[Leetcode 136][Easy]-只出現一次的數字)




