在當今的人工智能和機器學習領域,大型預訓練模型(如GPT、BERT等)已成為解決自然語言處理(NLP)任務的強大工具。然而,要讓這些模型更好地適應特定任務或領域,往往需要進行微調。本文將詳細介紹七種主流的大模型微調方法,幫助你在求職過程中脫穎而出,讓offer拿到爽。
1. LoRA(Low-Rank Adaptation)
LoRA是一種旨在微調大型預訓練語言模型的技術,其核心在于在模型的決定性層次中引入小型、低秩的矩陣。這種方法不需要對整個模型結構進行大幅度修改,僅通過引入低秩矩陣來實現模型行為的微調。LoRA的優勢在于能夠在不增加額外計算負擔的前提下,有效保留模型原有的性能水準。
應用場景:當你需要將一個通用語言模型微調至特定領域(如醫療健康)時,LoRA可以顯著減少調整成本,同時保持模型的高效性。
2. QLoRA(Quantized Low-Rank Adaptation)
QLoRA結合了LoRA方法與深度量化技術,進一步提高了模型微調的效率。通過將預訓練模型量化為4位,QLoRA大幅減少了模型存儲需求,同時保持了模型精度的最小損失。這種方法在資源有限的環境下尤其有用,能夠顯著減少內存和計算需求。
應用場景:在需要高效部署和訓練模型的邊緣計算或移動設備中,QLoRA提供了一種有效的解決方案。
3. 適配器調整(Adapter Tuning)
適配器調整通過在模型的每個層或選定層之間插入小型神經網絡模塊(稱為“適配器”)來實現微調。這些適配器是可訓練的,而原始模型的參數則保持不變。這種方法使得模型能夠迅速適應新任務,同時保持其他部分的通用性能。
應用場景:當你需要微調一個大型模型以執行多個不同任務時,適配器調整提供了一種靈活且高效的解決方案。
4. 前綴調整(Prefix Tuning)
前綴調整是一種在預訓練語言模型輸入序列前添加可訓練、任務特定的前綴來實現微調的方法。這種方法通過在輸入中添加前綴來調整模型的行為,從而節省大量的計算資源,并使單一模型能夠適應多種不同的任務。
應用場景:在需要快速適應不同任務而又不希望為每個任務保存一整套微調后模型權重的情況下,前綴調整提供了一種便捷的解決方案。
5. 提示調整(Prompt Tuning)
提示調整在預訓練語言模型的輸入中引入可學習嵌入向量作為提示,這些向量在訓練過程中更新,以指導模型輸出更適合特定任務的響應。提示調整旨在模仿自然語言中的提示形式,使用較少的向量來模仿傳統的自然語言提示。
應用場景:當你需要通過少量提示信息引導模型生成特定類型的輸出時,提示調整提供了一種有效的方法。
6. P-Tuning及P-Tuning v2
P-Tuning及其升級版P-Tuning v2是另一種在輸入序列中添加連續可微提示的微調方法。這些方法通過優化提示向量來更好地引導模型輸出,同時保持模型的靈活性和通用性。
應用場景:在處理復雜NLP任務時,P-Tuning及其升級版提供了一種強大的工具,幫助模型更好地理解和生成符合任務要求的輸出。
7. 全面微調(Fine-tuning)
全面微調涉及調整模型的所有層和參數,以適配特定任務。這種方法能夠充分利用預訓練模型的通用特征,但需要更多的計算資源。全面微調通常用于對模型性能有較高要求的場景。
應用場景:在資源充足且對模型性能有嚴格要求的情況下,全面微調提供了一種全面優化模型性能的方法。
結語
通過上述七種大模型微調方法,你可以根據具體任務和資源限制選擇最適合的微調策略。無論是LoRA的高效微調、QLoRA的量化優化,還是適配器調整的靈活性,都能夠幫助你更好地利用預訓練模型的優勢,從而在求職過程中脫穎而出,讓offer拿到爽。希望本文能為你在人工智能領域的求職之路提供有力支持。
讀者福利:如果大家對大模型感興趣,這套大模型學習資料一定對你有用
對于0基礎小白入門:
如果你是零基礎小白,想快速入門大模型是可以考慮的。
一方面是學習時間相對較短,學習內容更全面更集中。
二方面是可以根據這些資料規劃好學習計劃和方向。
資源分享

大模型AGI學習包


資料目錄
- 成長路線圖&學習規劃
- 配套視頻教程
- 實戰LLM
- 人工智能比賽資料
- AI人工智能必讀書單
- 面試題合集
《人工智能\大模型入門學習大禮包》,可以掃描下方二維碼免費領取!

1.成長路線圖&學習規劃
要學習一門新的技術,作為新手一定要先學習成長路線圖,方向不對,努力白費。
對于從來沒有接觸過網絡安全的同學,我們幫你準備了詳細的學習成長路線圖&學習規劃。可以說是最科學最系統的學習路線,大家跟著這個大的方向學習準沒問題。
2.視頻教程
很多朋友都不喜歡晦澀的文字,我也為大家準備了視頻教程,其中一共有21個章節,每個章節都是當前板塊的精華濃縮。
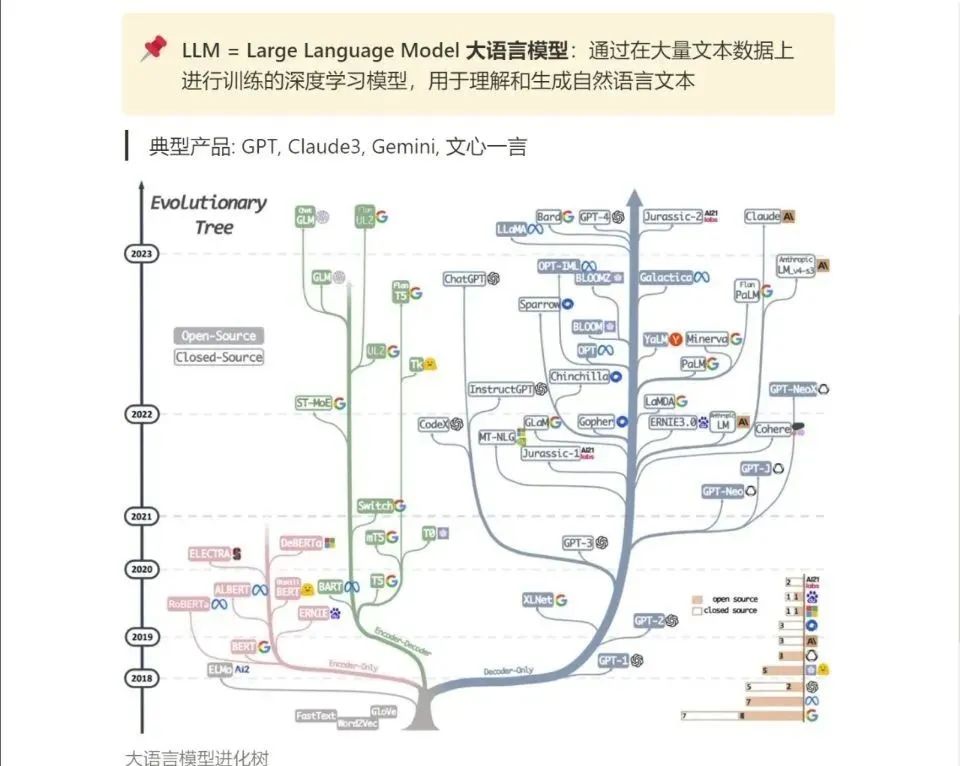
3.LLM
大家最喜歡也是最關心的LLM(大語言模型)
《人工智能\大模型入門學習大禮包》,可以掃描下方二維碼免費領取!






)
)











