寫在前面
Kafka 是一個可橫向擴展,高可靠的實時消息中間件,常用于服務解耦、流量削峰。
好像是 LinkedIn 團隊開發的,后面捐贈給apache基金會了。
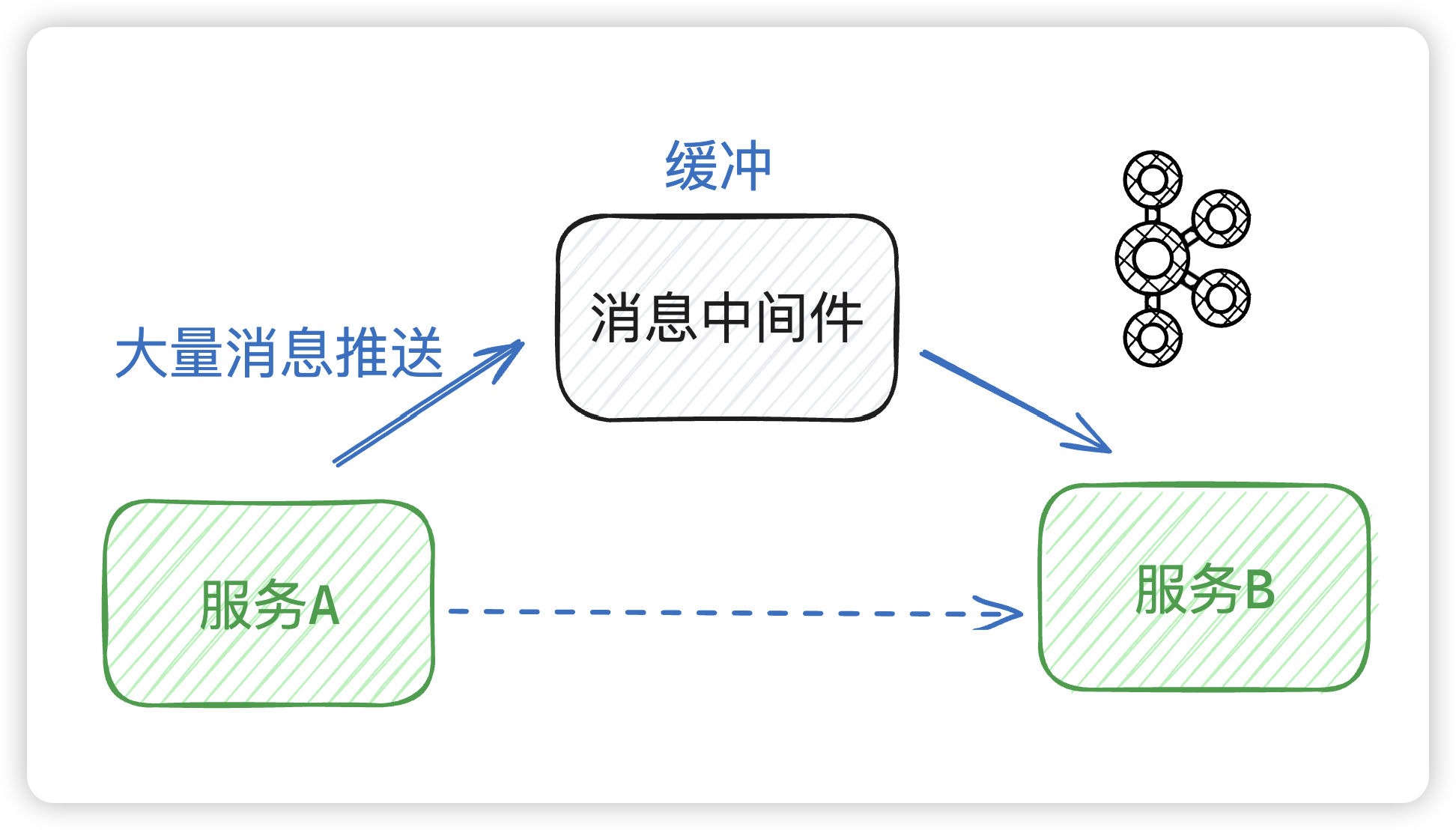
kafka
總體架構圖
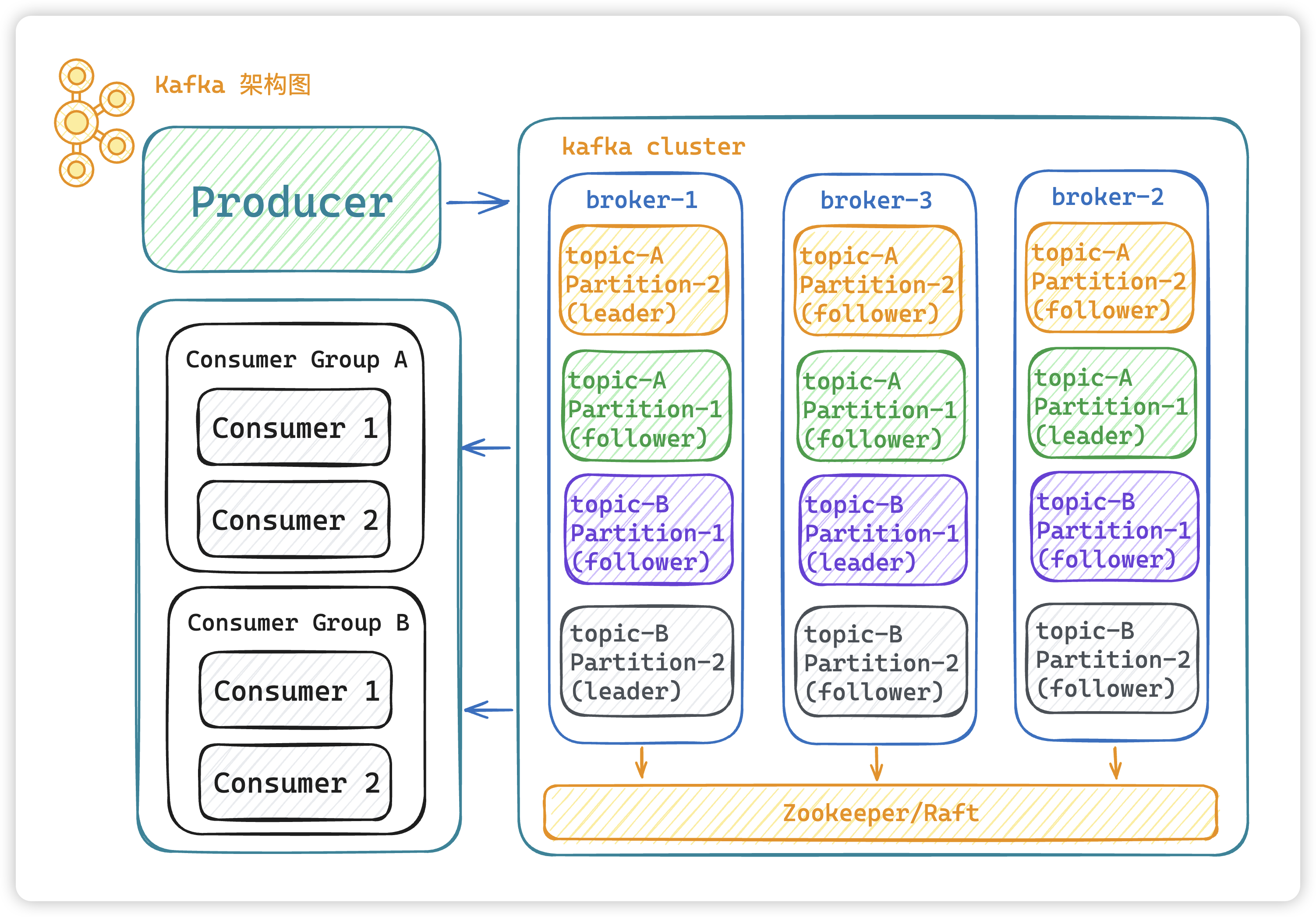
- Producer:生產者,消息的產生者,是消息的入口。
- Broker:Broker 是 kafka 一個實例,每個服務器上有一個或多個 kafka 的實例,簡單的理解就是一臺 kafka 服務器,kafka cluster 表示集群的意思
- Topic:消息的主題,可以理解為消息隊列,kafka的數據就保存在topic。在每個 broker 上都可以創建多個 topic 。
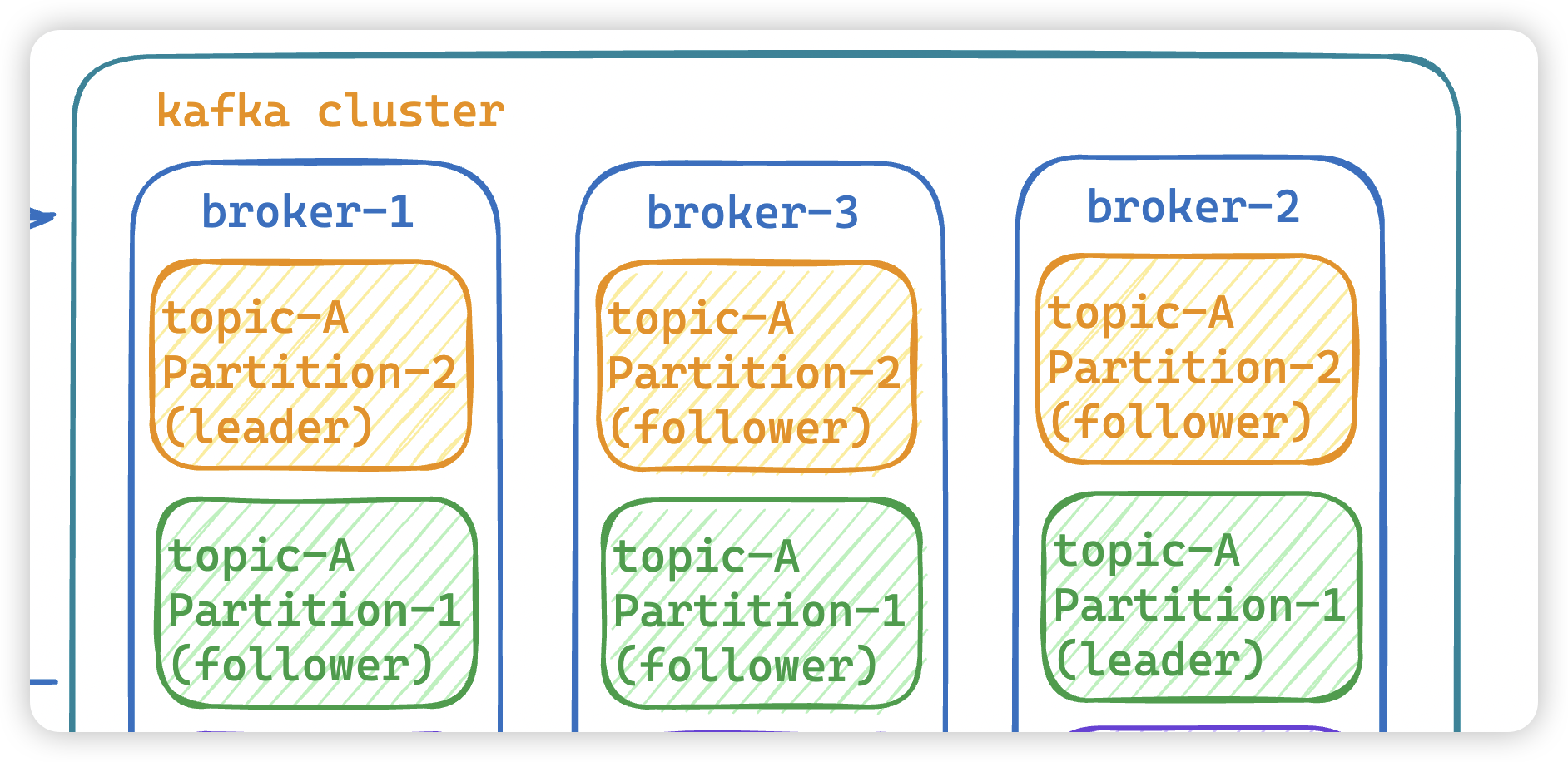
- Partition:
Topic的分區,每個 topic 可以有多個分區,分區的作用是做負載,提高 kafka 的吞吐量。同一個 topic 在不同的分區的數據是不重復的,partition 的表現形式就是一個一個的文件夾。 - Replication:每一個分區都有多個副本,副本的作用是做備胎,leader節點會將數據同步到follow從節點。當leader故障的時候會選擇一個follower ,成為 leader,
follower和leader絕對是在不同的機器,同一機器對同一個分區也只可能存放一個副本。
- Consumer:消費者,消息的消費方,是消息的出口。
- Consumer Group:可以將多個消費組構成一個消費者組,同一個 partition 的數據只能被消費者組中的某一個消費者消費。同一個消費者組的消費者可以消費同一個topic的不同分區的數據,這也是為了提高kafka的吞吐量。
- Zookeeper:kafka 2.8 版本之前是依賴 zookeeper 來保存集群的的元信息,來保證系統的可用性。
- Raft:kafka 2.8 版本之后就根據
raft來保證系統的可用性。
為什么同一個 partition 的數據只能被消費者組中的某一個消費者消費?
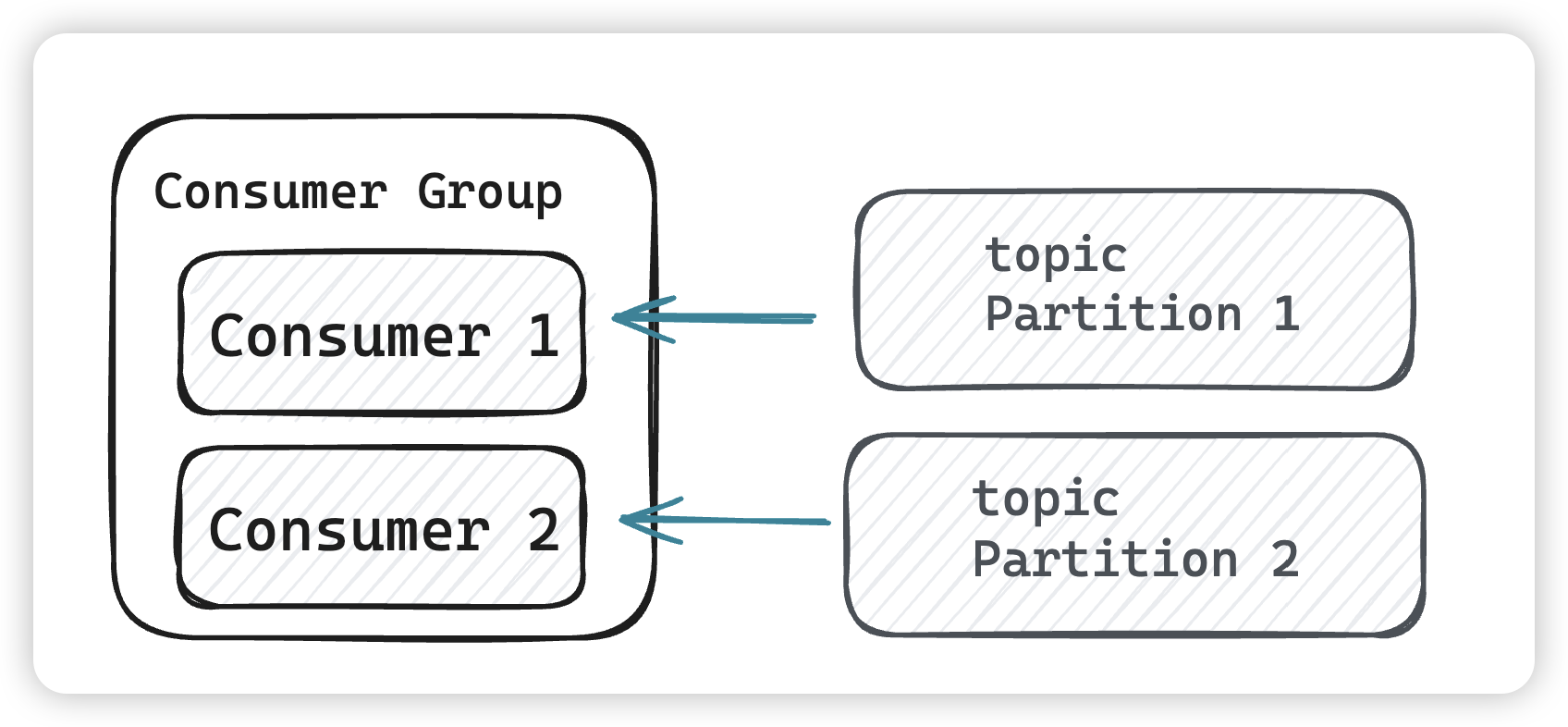
- 順序性:Kafka 保證了同一個分區內的消息是有序的,如果允許多個消費者并行消費同一個分區的消息,那么消息的
順序性將無法得到保證。當然由于各個分區的不同,我們順序性還是不要靠kafka,在自己業務做判定。 - 負載均衡:通過讓不同的消費者組內的消費者分攤不同的分區,Kafka 實現了
負載均衡,確保每個消費者都有機會消費消息,同時避免了重復消費。 - Offset 管理:
每個消費者在消費時都會維護自己的 offset,如果多個消費者同時消費同一個分區,那么 offset 的管理將變得復雜,可能會導致重復消費或者消息丟失。
發送數據
kafka 會每次發送數據都是向 leader節點發送數據,并順序寫入到磁盤,然后 leader節點會將數據同步到各個從節點follower,即使主節點掛了,也不會影響服務的正常運行。
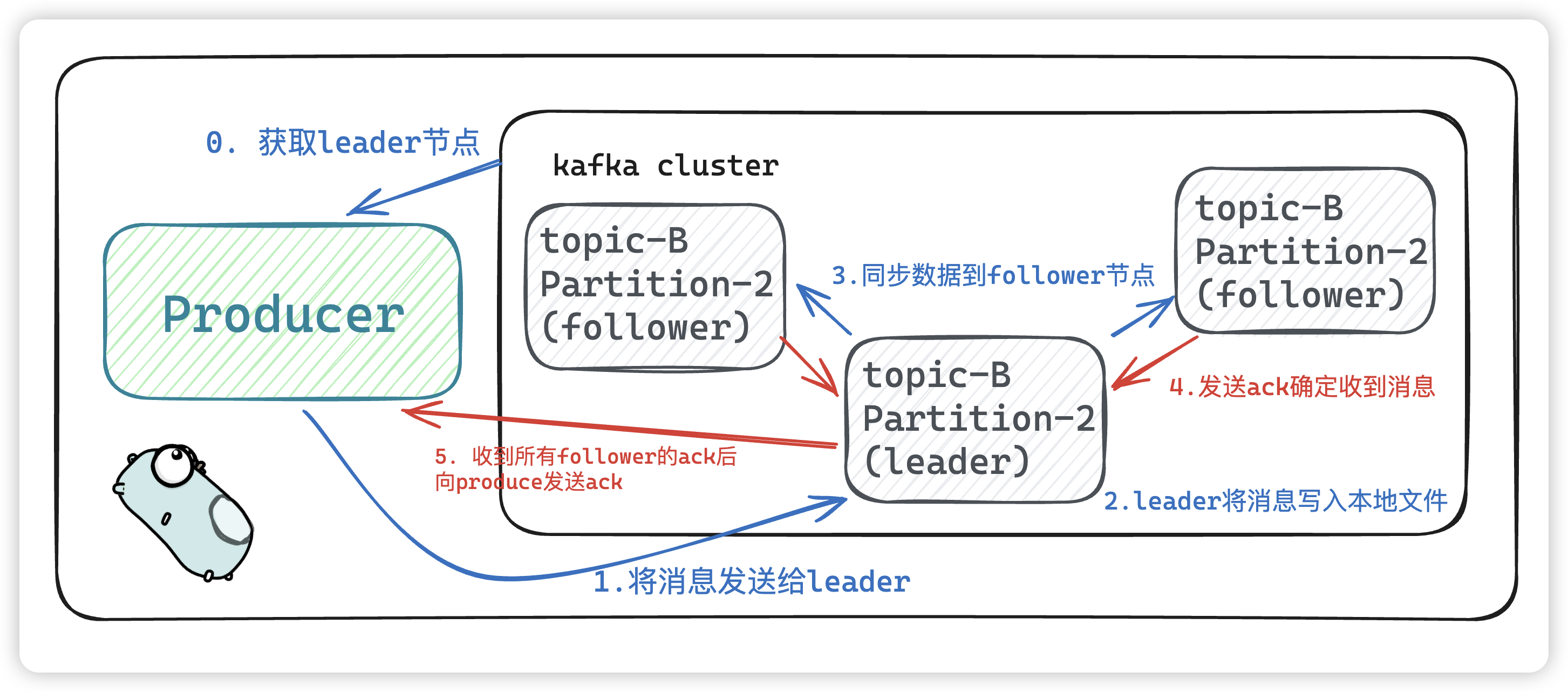
- producer 生產者獲取 leader 節點,將消息發送給leader節點。
- leader節點將消息持久化到本地后,將數據同步到各個follower節點。
- leader節點收到各個follower節點的
ack后,發送ack給producer
消費數據
和生產者一樣,消費者主動到kafka集群中拉取消息時,也是從leader節點去拉取數據。
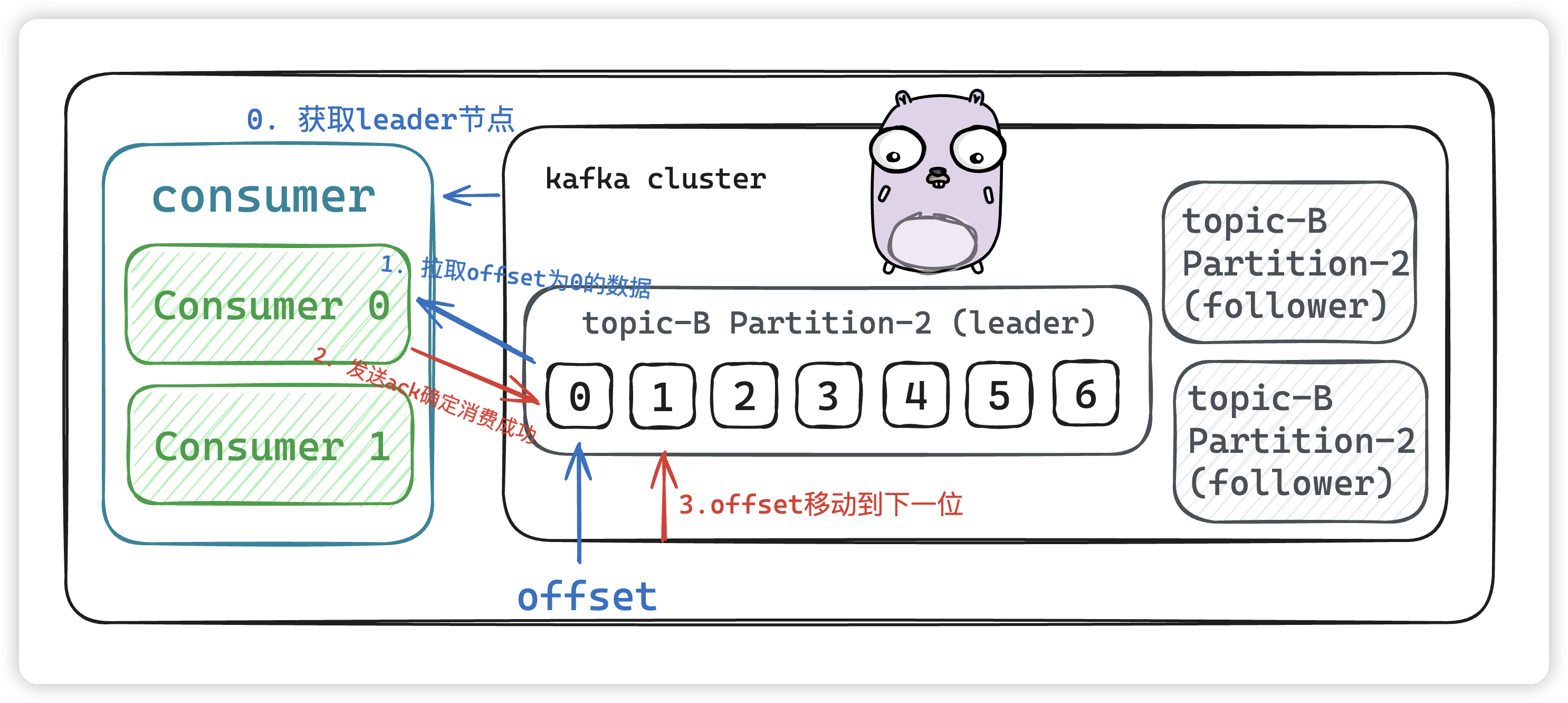
- 獲取leader節點
- 拉去offset為0的數據進行消費
- 消費成功后發送
ack,offset將會移動到下一位,待下次消費定位數據
kafka 為什么會那么快?
一共有四個原因
- 磁盤順序讀寫
- PageCache 頁緩存技術
- 零拷貝技術
- kafka 分區架構
磁盤順序讀寫
生產者發送數據到 kafka 集群中,最終會寫入到磁盤中,會采用順序寫入的方式。消費者從 kafka 集群中獲取數據時,也是采用順序讀的方式。無論是機械磁盤還是固態硬盤 SSD,順序讀寫的速度都是遠大于隨機讀寫的。
- 機械磁盤順序讀寫省去了
磁頭頻繁尋址和旋轉盤片的開銷 - 固態硬盤SSD以Page為單位做讀寫,以Block為單位做垃圾回收。寫相同數據量的情況下,順序寫
制造更少的垃圾Block,所以比隨機寫有更高的性能。
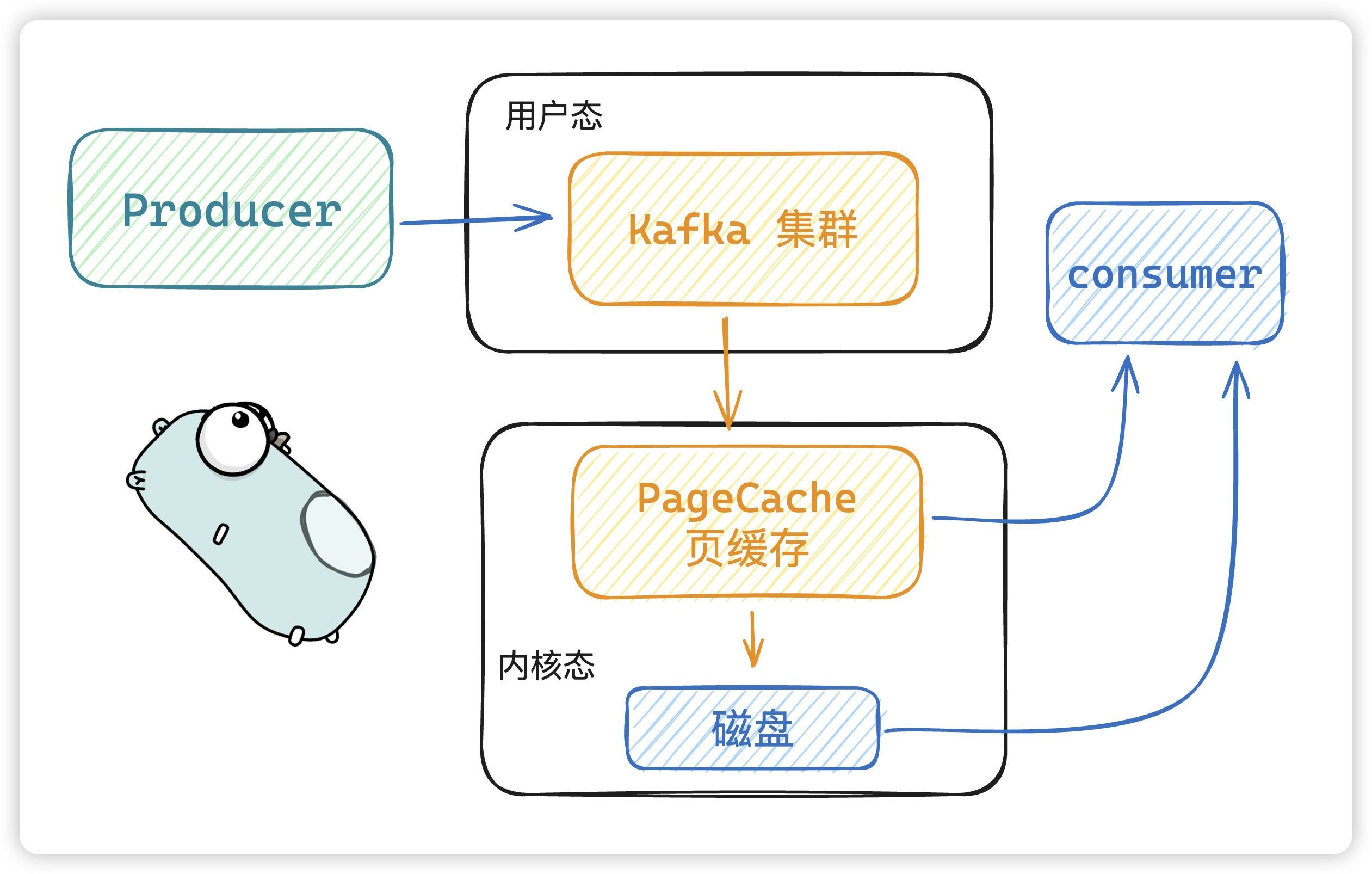
PageCache 頁緩存技術
- 當 kafka 有寫操作時,先將數據寫入
PageCache中,然后在順序寫入到磁盤中。 - 當讀操作發生時,先從
PageCache中查找,如果找不到,再去磁盤中讀取。
零拷貝技術
一般性能的瓶頸都是網絡io、磁盤io。我們來看下從磁盤讀取數據到網卡場景下,傳統 IO 的整個過程:

DMA方式,Direct Memory Access,也稱為成組數據傳送方式,有時也稱為直接內存操作。DMA方式在數據傳送過程中,沒有保存現場、恢復現場之類的工作。
傳統 IO 模型下,從磁盤讀取數據,寫到網卡設備中,經歷了 4 次用戶態和內核態之間的切換和數據的拷貝。紅色箭頭為數據拷貝。
那能不能讓拷貝次數發送的少一點呢?但是kafka 采用了 sendfile 的零拷貝技術

所謂的零拷貝技術不是指不發生拷貝,而是在用戶態沒有進行拷貝。
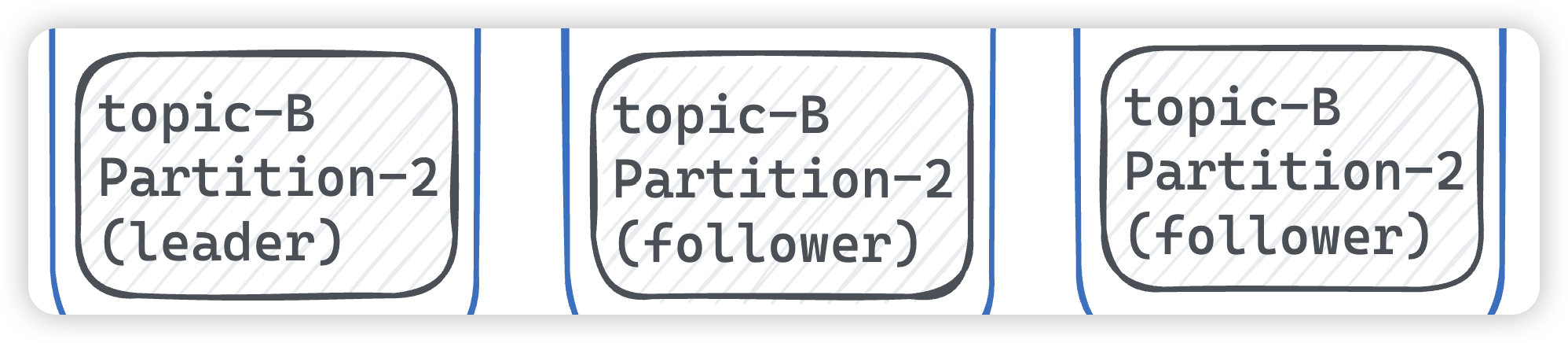
kafka 分區架構
- 分區架構:kafka 集群架構采用了多分區技術,并行度高。
參考
[1] https://strikefreedom.top/archives/why-kafka-is-so-fast
[2] https://cloud.tencent.com/developer/article/2185290
[3] https://serverfault.com/questions/843628/why-do-sequential-writes-have-better-performance-than-random-writes-on-ssds
[4] https://xie.infoq.cn/article/51b6764c48ff70988e124a868


)
)















