在深度學習的分類問題中,真陽性、真陰性、假陽性和假陰性是評估模型性能的重要指標。它們的定義和計算如下:
-
真陽性(True Positive, TP):
- 定義:模型預測為正類(陽性),且實際標簽也是正類。
- 解釋:模型正確地識別出了正樣本。
-
真陰性(True Negative, TN):
- 定義:模型預測為負類(陰性),且實際標簽也是負類。
- 解釋:模型正確地識別出了負樣本。
-
假陽性(False Positive, FP):
- 定義:模型預測為正類,但實際標簽是負類。
- 解釋:模型錯誤地將負樣本預測為正樣本。
-
假陰性(False Negative, FN):
- 定義:模型預測為負類,但實際標簽是正類。
- 解釋:模型錯誤地將正樣本預測為負樣本。
這些指標可以通過混淆矩陣(Confusion Matrix)來直觀表示。混淆矩陣如下所示:
| 預測為正類(陽性) | 預測為負類(陰性) | |
|---|---|---|
| 實際為正類(陽性) | 真陽性(TP) | 假陰性(FN) |
| 實際為負類(陰性) | 假陽性(FP) | 真陰性(TN) |
評估指標
基于真陽性、真陰性、假陽性和假陰性,可以計算出多個評估分類模型性能的指標:
-
準確率(Accuracy):
- 公式:
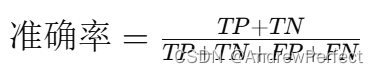
- 解釋:模型預測正確的總體比例。
- 公式:
-
精確率(Precision):
- 公式:?

- 解釋:模型預測為正類的樣本中實際為正類的比例。(FP是假陽性,也就是預測為陽性)
- 公式:?
-
召回率(Recall)或敏感性(Sensitivity):
- 公式:
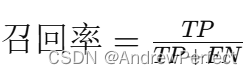
- 解釋:實際為正類的樣本中被正確預測為正類的比例。(FN是假陰性,實際就是陽性)
- 公式:
-
特異性(Specificity):
- 公式:?

- 解釋:實際為負類的樣本中被正確預測為負類的比例。
- 公式:?
-
F1 分數(F1 Score):
- 公式:

- 解釋:精確率和召回率的調和平均。
- 公式:
實際應用中的考慮
在實際應用中,不同的應用場景對假陽性和假陰性的容忍度不同,因此需要根據具體需求選擇合適的評價指標:
- 醫療診斷:假陰性通常更為嚴重,因為未能檢測到疾病可能會導致嚴重后果。在這種情況下,召回率比精確率更重要。
- 垃圾郵件過濾:假陽性通常更為嚴重,因為誤將正常郵件識別為垃圾郵件會影響用戶體驗。在這種情況下,精確率比召回率更重要。(這里要注意判斷是不是被分類為垃圾郵件,所以是假陽性,本身不是垃圾郵件,卻被識別成了垃圾郵件!!)
- 安全監控:在安全監控系統中,假陽性和假陰性都需要考慮,因為錯誤的報警(假陽性)和漏報(假陰性)都會帶來問題。
如何減少假陽性和假陰性
- 改進模型:使用更復雜的模型(如深度學習模型)或結合多種模型(集成學習)以提高預測準確性。
- 優化閾值:調整分類閾值,以找到精確率和召回率之間的最佳平衡點。
- 數據增強:通過數據增強技術增加訓練數據的多樣性,提高模型的泛化能力。
- 特征選擇和工程:選擇和構建更具區分力的特征,以幫助模型更準確地分類。
通過理解假陽性和假陰性及其影響,可以更有效地評估和改進分類模型,提升實際應用中的性能和可靠性。








EBO和glDrawElements)




)





