
原文鏈接:A Survey on Evaluation of Large Language Models | ACM Transactions on Intelligent Systems and Technology
本文從三個關鍵維度:評價什么、在哪里評價和如何評價,對這些 LLMs 評價方法進行了全面回顧。
- 首先,我們從評價任務的角度進行了概述,包括一般自然語言處理任務、推理、醫學應用、倫理學、教育、自然科學和社會科學、代理應用以及其他領域。
- 其次,我們通過深入研究評估方法和基準來回答 "在哪里"和 "如何做"的問題,這些方法和基準是評估 LLM 性能的重要組成部分。
- 然后,我們總結了 LLM 在不同任務中的成功和失敗案例。
- 最后,我們闡明了 LLMs 評估未來面臨的幾項挑戰。我們的目標是為 LLMs 評估領域的研究人員提供寶貴的見解,從而幫助開發更完善的 LLMs。
我們的核心觀點是對 LLMs 的評估應成為一門重要學科,以更好地幫助 LLMs 的發展。我們一直在維護相關的開源材料,網址是: GitHub - MLGroupJLU/LLM-eval-survey: The official GitHub page for the survey paper "A Survey on Evaluation of Large Language Models".
1. INTRODUCTION
理解智能的本質以及確定機器是否體現了智能,是科學家們面臨的一個迫切問題。人們普遍認為,真正的智能具備推理能力,使我們能夠檢驗假設,并為未來的可能情況做好準備[92]。人工智能(AI)研究人員尤其關注機器智能的發展,而不是生物智能的發展[136]。適當的測量有助于理解智力。例如,對人類個體一般智力的測量通常圍繞 IQ 進行測試[12]。
在人工智能領域,圖靈測試[193]是一項廣受認可的測試,它通過辨別反應是源于人類還是機器來評估智能。研究人員普遍認為,成功通過圖靈測試的計算機可以被認為是智能的。因此,從更廣闊的視角來看,人工智能的編年史可以被描述為智能模型和算法的創建與評估時間表。每出現一種新的人工智能模型或算法,研究人員都會通過使用特定的、具有挑戰性的任務進行評估,仔細研究其在現實世界場景中的能力。例如,20 世紀 50 年代被譽為人工通用智能(AGI)方法的感知器算法[49],后來因無法解決 XOR 問題而被揭露其不足之處。隨后,支持向量機(SVM)[28] 和深度學習[104] 的興起和應用標志著人工智能領域的進步和挫折。從之前的嘗試中得出的一個重要啟示是,人工智能評估至關重要,它是識別當前系統局限性和設計更強大模型的重要工具。
最近,大型語言模型(LLMs)在學術和工業領域都引起了極大的興趣[11, 219, 255]。正如現有工作[15]所證明的那樣,LLMs 的卓越性能讓人們相信它們可以成為這個時代的 AGI。LLMs 具備解決各種任務的能力,這與之前局限于解決特定任務的模型形成了鮮明對比。由于 LLMs 在處理一般自然語言任務和特定領域任務等不同應用方面表現出色,越來越多的人開始使用 LLMs 來滿足學生或病人等對信息的重要需求。
評估對 LLMs 的成功至關重要,原因有以下幾點。首先,評估 LLM 有助于我們更好地了解 LLM 的優缺點。例如,PromptBench [262] 基準表明,當前的 LLM 對對抗性提示很敏感,因此,要想獲得更好的性能,就必須對提示進行精心設計。其次,更好的評估可以為人類與 LLMs 的交互提供更好的指導,從而為未來的交互設計和實施提供靈感。第三,LLMs 的廣泛適用性強調了確保其安全性和可靠性的極端重要性,尤其是在安全敏感領域,例如金融機構和醫療機構。最后,隨著 LLM 的規模越來越大,具備更多新興能力,現有的評估協議可能不足以評估其能力和潛在風險。因此,我們希望通過回顧當前的評估協議,提高社區對 LLMs 評估重要性的認識,最重要的是,為設計新的 LLMs 評估協議的未來研究提供啟示。
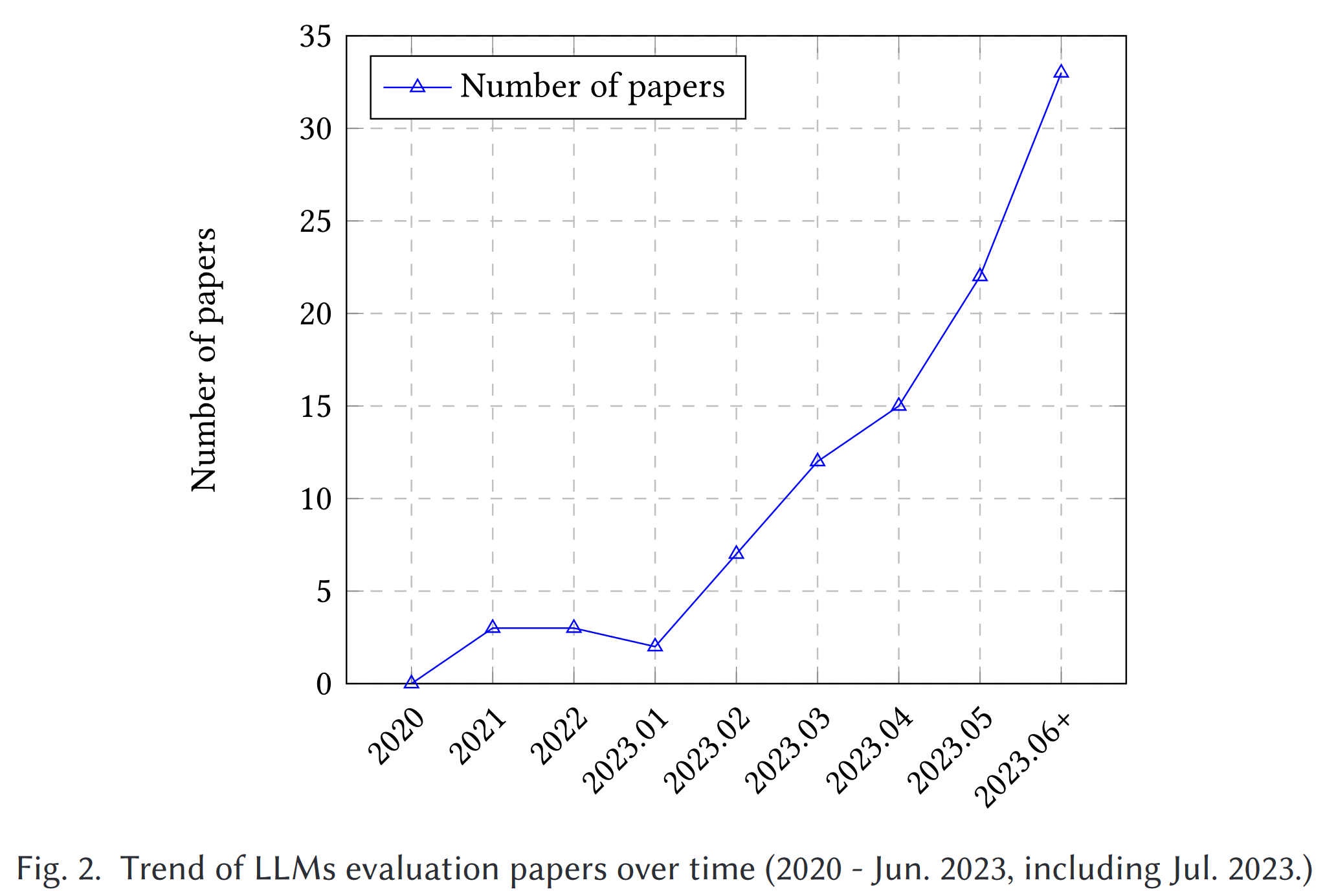
隨著 ChatGPT [145] 和 GPT-4 [146]的問世,許多研究工作都旨在從不同方面評估 ChatGPT 和其他 LLM(圖 2),包括 natural language tasks, reasoning, robustness, trustworthiness, medical applications, and ethical considerations 等一系列因素。盡管做出了這些努力,但目前仍缺乏一個全面的概述來捕捉整個評估范圍。此外,LLM 的不斷發展也為評估帶來了新的方面,從而對現有的評估協議提出了挑戰,并加強了對全面、多方面評估技術的需求。雖然 Bubeck 等人[15]現有的研究聲稱 GPT-4 可被視為 AGI 的火花,但也有人對這一說法提出質疑,因為其評估方法具有人為設計的性質。
本文是對大型語言模型評估的首次全面調查。如圖 1 所示。

我們從三個方面探討了現有工作:1) 評估什么;2) 在哪里評估;3) 如何評估。具體來說,"評估什么 "概括了現有的 LLM 評估任務,"在哪里評估 "涉及選擇合適的數據集和基準進行評估,而 "如何評估 "則涉及對任務和數據集的評估過程。這三個方面是 LLM 評估不可或缺的部分。隨后,我們將討論 LLMs 評估領域未來可能面臨的挑戰。
本文的貢獻如下:
(1) 我們從 "評價什么"、"在哪里評價 "和 "如何評價 "三個方面對 LLMs 的評估進行了全面概述。我們的分類具有普遍性,涵蓋了 LLMs 評估的整個生命周期。
(2)關于 "評價什么",我們總結了各個領域的現有任務,并就 LLMs 的成功和失敗案例得出了深刻的結論(第 6 節),為今后的研究提供了經驗。
(3) 關于 "在哪里評估",我們總結了評估指標、數據集和基準,對當前的 LLMs 評估有了深刻的了解。在如何評價方面,我們探討了當前的協議,并總結了新穎的評價方法。
(4) 我們進一步討論了 LLMs 評估的未來挑戰。我們將 LLMs 評估的相關資料開源并維護在 GitHub - MLGroupJLU/LLM-eval-survey: The official GitHub page for the survey paper "A Survey on Evaluation of Large Language Models". 網站上,以培養一個合作社區,從而更好地進行評估。
本文的結構如下。第 2 節,我們介紹了 LLM 和人工智能模型評估的基本信息。然后,第 3 節從 "評估什么 "的角度回顧了現有工作。之后,第 4 節是 "在哪里評估 "部分,總結了現有的數據集和基準。第 5 節討論如何進行評估。第 6 節總結了本文的主要發現。第 7 節討論了未來的重大挑戰,第 8 節是本文的結尾。
2. BACKGROUND
2.1. Large Language Models
語言模型(LM)[36, 51, 96] 是一種能夠理解和生成人類語言的計算模型。語言模型具有轉換能力,可預測詞序列的可能性或根據給定輸入生成新文本。N-gram 模型[13]是最常見的 LM 類型,它根據前面的上下文來估計單詞的可能性。然而,LM 也面臨著一些挑戰,如罕見詞或未見詞問題、過擬合問題以及難以捕捉復雜語言現象的問題。研究人員正在不斷改進 LM 架構和訓練方法,以應對這些挑戰。
大型語言模型(LLMs)[19, 91, 255]是一種先進的語言模型,具有龐大的參數規模和卓越的學習能力。許多 LLM(如 GPT-3 [43]、InstructGPT [149] 和 GPT-4 [146])背后的核心模塊是 Transformer [197] 中的自我注意模塊。自注意力模塊是語言建模任務的基本構件。Transformers 能夠高效處理序列數據,實現并行化,并捕捉文本中的長距離依賴關系,從而在 NLP 領域掀起了一場革命。LLM 的一個主要特點是上下文學習 [14],即根據給定的上下文或提示來訓練模型生成文本。這使得 LLMs 能夠生成更加連貫和與上下文相關的回復,從而使其適用于交互式和對話式應用。從人類反饋中強化學習(RLHF)[25, 266] 是 LLMs 的另一個重要方面。這項技術包括利用人類生成的回復作為獎勵對模型進行微調,使模型能夠從錯誤中吸取教訓,并隨著時間的推移不斷改進其性能。
在自回歸語言模型(如 GPT-3 和 PaLM [24])中,給定上下文序列 X 時,LM 任務的目的是預測下一個標記 y。模型的訓練方法是最大化給定標記序列在上下文條件下的概率,即 P(y|X ) = P(y|x1, x2,...,xt-1) ,其中 x1, x2,...,xt-1 是上下文序列中的標記,t 是當前位置。利用鏈式規則,條件概率可以分解為每個位置的概率乘積:

其中 T 為序列長度。這樣,該模型就能以自回歸的方式預測每個位置上的每個標記,從而生成一個完整的文本序列。
與 LLMs 交互的一種常見方法是提示工程(prompt engineering)[26, 221, 261],即用戶設計并提供特定的提示文本,引導 LLMs 生成所需的回復或完成特定任務。這種方法在現有的評估工作中被廣泛采用。人們還可以參與問答互動[83],即向模型提出問題并得到答案,或者參與對話互動,與 LLM 進行自然語言對話。總之,LLM 憑借其 Transformer 架構、上下文學習和 RLHF 能力,已經徹底改變了 NLP,并在各種應用中大有可為。表 1 簡單比較了傳統 ML、深度學習和 LLM。

2.2. AI Model Evaluation
人工智能模型評估是評估模型性能的重要步驟。目前有一些標準的模型評估方案,包括 k-fold cross-validation、holdout validation、leave one out cross-validation (LOOCV)、bootstrap 和 reduced set [8,95]。例如,K-fold cross-validation 將數據集分為 k 部分,其中一部分作為測試集,其余部分作為訓練集,這樣可以減少訓練數據的損失,獲得相對更準確的模型性能評價[48];Holdout validation 將數據集分為訓練集和測試集,計算量較小,但可能存在較大偏差;LOOCV 是一種獨特的 k 倍交叉驗證方法,只用一個數據點作為測試集[222];Reduced set 用一個數據集訓練模型,用剩余數據進行測試,計算簡單,但適用性有限。應根據具體問題和數據特征選擇合適的評價方法,以獲得更可靠的性能指標。
圖 3 展示了人工智能模型(包括 LLM)的評估過程。由于深度學習模型需要大量的訓練,某些評估協議可能無法對其進行評估。因此,長期以來,在靜態驗證集上進行評估一直是深度學習模型的標準選擇。例如,計算機視覺模型利用 ImageNet [33] 和 MS COCO [120] 等靜態測試集進行評估。LLM 也使用 GLUE [200] 或 SuperGLUE [199] 作為常用測試集。

隨著 LLM 的流行,可解釋性卻越來越差,現有的評估協議可能不足以全面評估 LLM 的真正能力。我們將在第 5 節介紹最近對 LLM 的評估。
3. WHAT TO EVALUATE
我們應該評估 LLMs 在哪些任務中的表現?在本節中,我們將現有任務分為以下幾類:自然語言處理、魯棒性、倫理、偏見和可信度、社會科學、自然科學和工程學、醫學應用、agent 應用以及其他應用。
3.1. 自然語言處理任務
開發語言模型,特別是大型語言模型的最初目的是提高自然語言處理任務的性能,包括理解和生成兩個方面。因此,大多數評估研究都主要集中在自然語言任務上。表 2 總結了現有研究的評估方面,我們將在下文中重點介紹其結論。

3.1.1. 自然語言理解(NLU)
自然語言理解是一個范圍廣泛的任務,其目的是更好地理解輸入序列。我們從幾個方面總結了最近在 LLM 評估方面所做的努力。
情感分析(Sentiment analysis)是一項分析和解釋文本以確定情感傾向的任務。它通常是一個二元(正面和負面)或三元(正面、中性和負面)分類問題。評估情感分析任務是一個流行的方向。Liang 等人[114]和 Zeng 等人[242]的研究表明,該任務的模型性能通常很高。ChatGPT 的情感分析預測性能優于傳統的情感分析方法 [129],并接近 GPT-3.5 [159]。在細粒度情感和情緒原因分析中,ChatGPT 也表現出了卓越的性能 [218]。在低資源學習環境中,LLM 與小語言模型相比具有顯著優勢 [249],但 ChatGPT 理解低資源語言的能力有限 [6]。總之,LLM 在情感分析任務中的表現值得稱贊。未來的工作重點應放在提高 LLMs 理解低資源語言情感的能力上。
文本分類(Text classification)和情感分析是相關領域;文本分類不僅關注情感,還包括對所有文本和任務的處理。Liang 等人[114]的研究表明,GLM-130B 是表現最好的模型,在雜項文本分類中的總體準確率為 85.8%。Yang和Menczer[232]發現,ChatGPT可以為各種新聞媒體提供可信度評級,而且這些評級與人類專家的評級有適度的相關性。此外,ChatGPT 在二元分類情況下達到了可接受的準確度(AUC=0.89)。Pe?a 等人[154]討論了公共事務文檔的主題分類問題,并表明使用 LLM backbone 與 SVM 分類器相結合是在公共事務領域執行多標簽主題分類任務的有效策略,準確率超過 85%。總體而言,LLM 在文本分類方面表現出色,甚至可以處理非常規問題環境中的文本分類任務。
自然語言推理(NLI)是判斷給定的 "假設 "是否符合 "前提 "的邏輯。Qin 等人[159]的研究表明,ChatGPT 在自然語言推理任務方面的表現優于 GPT-3.5。他們還發現,ChatGPT 在處理事實輸入方面表現出色,這可能要歸功于它的 RLHF 訓練過程偏重于人的反饋。然而,Lee 等人[105] 觀察到 LLM 在 NLI 范圍內表現不佳,而且在表示人類分歧方面進一步失敗,這表明 LLM 在這一領域仍有很大的改進空間。
語義理解(Semantic understanding)是指對語言及其相關概念的意義或理解。它涉及對單詞、短語、句子以及它們之間關系的解釋和理解。語義處理超越了表層,側重于對潛在含義和意圖的理解。Tao 等人[184]全面評估了 LLMs 的事件語義處理能力,包括對事件語義的理解、推理和預測。結果表明,LLMs 擁有對單個事件的理解能力,但他們感知事件間語義相似性的能力受到限制。在推理任務中,LLMs 在因果關系和意向關系方面表現出了強大的推理能力,但是在理解有意義的短語和無意義的短語是出現了問題,并始終將高度無意義的短語歸類為有意義的短語。GPT-4 的性能有了明顯改善,但仍明顯低于人類。總之,LLM 在語義理解任務中的表現不佳。今后,我們可以從這方面入手,著力提高其在這一應用中的性能。
社會知識理解(social knowledge understanding)方面,Choietal.[23] 評估了模型在學習和識別社會知識概念方面的表現,結果表明,盡管 BERT 等有監督模型的參數數量要少得多,但與使用 GPT [162]、GPT-J-6B [202] 等最先進 LLM 的 zero-shot 模型相比,經過微調的有監督模型的性能要好得多。這說明監督模型的性能明顯優于 zero-shot 模型,表明在這種特定情況下,參數的增加并不一定能保證更高水平的社會知識。
3.1.2. 推理能力
推理任務給智能人工智能模型帶來了巨大挑戰。為了有效地完成推理任務,模型不僅需要理解所提供的信息,還需要在沒有明確回答的情況下利用推理和推斷來推導出答案。表 2 顯示,人們對評估 LLM 的推理能力越來越感興趣,越來越多的文章專注于這方面的探索就是證明。目前,對推理任務的評估可大致分為數學推理、常識推理、邏輯推理和特定領域推理。
ChatGPT 在大多數任務中的算術推理能力都優于 GPT-3.5 [159]。然而,它在數學推理方面的能力仍有待提高[6, 45, 263]。在符號推理任務中,ChatGPT 的表現大多不如 GPT-3.5,這可能是因為 ChatGPT 容易出現不確定的回答,導致表現不佳[6]。Wu等人[226]通過LLMs在反事實條件任務變體上的不良表現,說明目前的LLMs在抽象推理能力上存在一定的局限性。在抽象推理方面,Gendron 等人[56] 發現現有 LLM 的能力非常有限。在邏輯推理方面,Liu 等人[124]的研究表明,ChatGPT 和 GPT-4 在大多數基準測試中都優于傳統的微調方法,證明了它們在邏輯推理方面的優勢。然而,這兩個模型在處理新數據和分布外數據時都面臨挑戰。ChatGPT 的表現不如其他 LLM,包括 GPT-3.5 和 BARD [159, 228]。這是因為 ChatGPT 是專門為聊天而設計的,因此在保持合理性方面做得非常出色。FLAN-T5、LLaMA、GPT-3.5 和 PaLM 在一般演繹推理任務中表現出色 [170]。GPT-3.5 在保持歸納推理的方向性方面表現不佳[228]。對于多步推理,Fu 等人[47]的研究表明,PaLM 和 Claude2 是僅有的兩個性能相近的模型族(但仍比 GPT 模型族差)。此外,LLaMA-65B 是迄今為止最穩健的開源 LLM,其性能與 code-davinci-002 非常接近。一些論文單獨評估了 ChatGPT 在某些推理任務中的表現:ChatGPT 在常識推理任務上的表現一般較差,但在非文本語義推理上的表現相對較好[6]。同時,ChatGPT 也缺乏空間推理能力,但在時間推理方面表現較好。最后,雖然 ChatGPT 在因果推理和類比推理上的表現尚可,但在多跳推理能力上卻表現不佳,這與其他 LLM 在復雜推理上的弱點類似[148]。在專業領域推理任務中,zero-shot InstructGPT 和 Codex 能夠勝任復雜的醫學推理任務,但仍需進一步改進[117]。在語言洞察問題方面,Orrù等人[147]證明了ChatGPT在解決語言洞察問題方面的潛力,因為ChatGPT的表現與人類參與者相當。值得注意的是,上述大多數結論都是針對特定數據集得出的。相比之下,更復雜的任務已成為評估 LLM 能力的主流基準。
這些任務包括數學推理 [225, 236, 243] 和結構化數據推理 [86, 151]。總體而言,LLM 在推理方面展現出巨大潛力,并呈現出不斷改進的趨勢,但仍面臨諸多挑戰和限制,需要更深入的研究和優化。
3.1.3. 自然語言生成(NLG)
NLG 評估的是 LLM 生成特定文本的能力,其中包含多項任務,例如摘要、對話生成、機器翻譯、問題解答和其他開放式生成任務。
摘要總結(Summarization)是一項生成任務,目的是為給定句子學習一個簡潔的摘要。在這項評估中,Liang 等人[114]發現 TNLG v2 (530B) [179] 在兩種情況下都獲得了最高分,OPT (175B) [245] 緊隨其后,排名第二。微調后的 Bart [106]仍然優于 zero-shot ChatGPT。具體來說,ChatGPT 與文本-davinci-002 [6]的 zero-shot 性能相當,但不如 GPT-3.5。這些發現表明,LLM,尤其是 ChatGPT,在摘要任務中表現一般。
評估 LLM 在對話任務中的表現對于開發對話系統和改善人機交互至關重要。通過評估,可以提高模型的自然語言處理能力、語境理解能力和生成能力,從而實現更智能、更自然的對話系統。與 GPT-3.5 相比,Claude 和 ChatGPT 在所有維度上都取得了更好的性能[121, 159]。在比較 Claude 和 ChatGPT 模型時,這兩個模型在不同的評估維度上都表現出了有競爭力的性能,其中 Claude 在特定配置下的性能略優于 ChatGPT。Bang 等人的研究[6]強調,在面向任務和基于知識的對話語境中,為特定任務定制的全參數微調模型超過了 ChatGPT。此外,Zheng 等人[257] 整理了一個全面的 LLMs 對話數據集 LMSYS-Chat-1M,包含多達一百萬個樣本。該數據集是評估和改進對話系統的寶貴資源。
雖然 LLMs 并未明確針對翻譯任務進行訓練,但它們仍能表現出強大的性能。Wang 等人[208]的研究表明,與商業機器翻譯(MT)系統相比,ChatGPT 和 GPT-4 在人類評估中表現出更優越的性能。此外,它們在 sacreBLEU 分數方面也優于大多數文檔級 NMT 方法。在對比測試中,與傳統翻譯模型相比,ChatGPT 的準確率較低。不過,GPT-4 在解釋話語知識方面表現出了強大的能力,盡管它偶爾會選擇不正確的候選翻譯。Bang 等人[6]的研究結果表明,ChatGPT 能很好地完成 X → Eng 翻譯,但仍缺乏完成 Eng → X 翻譯的能力。Lyu 等人[130] 研究了利用 LLMs 進行 MT 的幾個研究方向。這項研究極大地促進了 MT 研究的發展,并凸顯了 LLMs 在提高翻譯能力方面的潛力。總之,雖然 LLM 在多項翻譯任務中的表現令人滿意,但仍有改進的余地,例如增強從英語到非英語語言的翻譯能力。
問題解答(Question answering)是人機交互領域的一項重要技術,在搜索引擎、智能客戶服務和質量保證系統等場景中得到了廣泛應用。如何衡量 QA 模型的準確性和效率將對這些應用產生重大影響。根據 Liang 等人的研究[114],在所有被評估的模型中,InstructGPT davinci v2 (175B) 在 9 個質量保證場景中表現出最高的準確性、魯棒性和公平性。與 GPT-3 相比,GPT-3.5 和 ChatGPT 在回答常識問題的能力上都有顯著進步。在大多數領域,ChatGPT 的性能比 GPT-3.5 高出 2% 以上[9, 159]。不過,ChatGPT 在 CommonsenseQA 和 Social IQA 基準上的表現略遜于 GPT-3.5。這可以歸因于 ChatGPT 的謹慎性,因為當可用信息不足時,它往往會拒絕提供答案。
微調模型,如 Vícuna 和 ChatGPT 以接近滿分的成績展示了卓越的性能,大大超過了缺乏監督微調的模型 [5,6]。Laskar 等人[102]評估了 ChatGPT 在一系列學術數據集上的有效性,包括回答問題、總結文本、生成代碼、常識推理、解決數學問題、翻譯語言、檢測偏見和解決道德問題等各種任務。總之,LLM 在 QA 任務中的表現完美無瑕,并有望在未來進一步提高他們在社會、事件和時間常識方面的能力。
我們還可以探索其他生成任務。在句子風格轉換領域,Pu 和 Demberg[158]通過在同一子集上進行 few-shot 學習訓練,證明 ChatGPT 超越了之前的 SOTA 有監督模型,這一點可以從較高的 BLEU 分數中看出。然而,在控制句子風格的形式方面,ChatGPT 的表現與人類行為仍有很大差異。在寫作任務中,Chiaetal.[22]發現 LLM 在信息、專業、論證和創意寫作等不同類別中表現出一致的性能。這一發現意味著 LLMs 具有熟練的寫作能力。在文本生成質量方面,Chen 等人[20]的研究發現,即使在沒有參考文本的情況下,ChatGPT 也能從多個角度評估文本質量,其表現超過了大多數現有的自動評測指標。在所研究的各種測試方法中,使用 ChatGPT 為文本質量生成數字分數是最可靠、最有效的方法。
3.1.4. 多語言任務
雖然英語是主要語言,但許多 LLM 都是在混合語言訓練數據的基礎上進行訓練的。多語言數據的結合確實有助于 LLMs 獲得處理輸入和生成不同語言響應的能力,使其在全球范圍內被廣泛采用和接受。然而,由于這項技術的出現相對較晚,LLMs 主要是在英語數據上進行評估,這就導致了對其多語言性能評估的潛在疏忽。為了解決這個問題,一些文章對 LLM 在不同非英語語言的各種 NLP 任務中的表現進行了全面、公開和獨立的評估。這些評估為未來的研究和應用提供了寶貴的見解。
Abdelali 等人[1]評估了 ChatGPT 在標準阿拉伯語 NLP 任務中的表現,發現在大多數任務中,ChatGPT 在 zero-shot 設置下的表現低于 SOTA 模型。Ahuja 等人[2]、Bang 等人[6]、Lai 等人[100]、Zhang 等人[248]在多個數據集上使用了更多語言,涵蓋了更廣泛的任務,并對 LLM 進行了更全面的評估,包括 BLOOM、Vicuna、Claude、ChatGPT 和 GPT-4。結果表明,這些 LLM 在處理非拉丁語系語言和資源有限的語言時表現不佳。盡管將輸入翻譯成了英語并將其作為查詢,但與 SOTA 模型相比,生成式 LLM 在不同任務和語言中的表現仍然不盡如人意[2]。此外,Bang 等人[6] 強調,ChatGPT 在翻譯語言資源豐富的非拉丁字母語言所寫的句子時仍然面臨限制。上述情況表明,在多語言任務中,LLMs 面臨著眾多挑戰和大量改進機會。未來的研究應優先考慮實現多語言平衡,解決非拉丁語系和低資源語言所面臨的挑戰,以便更好地支持全球用戶。同時,應注意語言的公正性和中立性,以減少任何可能影響多語言應用的潛在偏見,包括英語偏見或其他偏見。
3.1.5. 事實性(Factuality)
LLM 中的事實性是指模型提供的信息或答案與現實世界的真理和可驗證的事實相一致的程度。LLM 中的事實性會對各種任務和下游應用產生重大影響,例如質量保證系統、信息提取、文本摘要、對話系統和自動事實檢查,在這些應用中,不正確或不一致的信息可能會導致嚴重的誤解和曲解。為了信任并有效地使用這些模型,對事實真實性進行評估非常重要。這包括這些模型與已知事實保持一致、避免產生誤導或虛假信息(即 "事實幻覺")以及有效學習和回憶事實知識的能力。人們提出了一系列方法來衡量和改進 LLM 的事實性。
Wang 等人[204]通過檢測幾個大型模型(即 InstructGPT、ChatGPT-3.5、GPT-4 和 BingChat [137])回答基于自然問題[98]和 TriviaQA [88]數據集的開放式問題的能力,評估了這些模型的內部知識能力。評估過程包括人工評估。研究結果表明,雖然 GPT-4 和 BingChat 能為 80% 以上的問題提供正確答案,但要達到完全準確仍有超過 15% 的差距。在 Honovich 等人的研究中[74],他們對當前的事實一致性評價方法進行了回顧,并強調了缺乏統一的比較框架以及相關分數與二進制標簽相比參考價值有限的問題。為了解決這個問題,他們將現有的事實一致性任務轉化為二進制標簽,特別是只考慮是否與輸入文本存在事實沖突,而不考慮外部知識。研究發現,建立在自然語言推理和問題生成回答基礎上的事實評估方法表現出更優越的性能,并且可以相互補充。Pezeshkpour [156] 基于信息論提出了一種新的度量方法,用于評估 LLM 中是否包含特定知識。該指標利用知識中的不確定性概念來衡量事實性,通過 LLMs 填寫提示和檢查答案的概率分布來計算。論文討論了將知識注入 LLM 的兩種方法:在提示中明確包含知識,以及利用知識相關數據對 LLM 進行隱式微調。研究表明,這種方法超越了傳統的排名方法,準確率提高了 30% 以上。Gekhman 等人[55]改進了總結任務中事實一致性的評估方法。該研究提出了一種新方法,即使用多個模型生成的摘要訓練學生 NLI 模型,并由 LLM 進行注釋,以確保事實一致性。然后使用訓練好的學生模型進行摘要事實一致性評估。Manakul 等人[133]就 LLM 如何生成事實或幻覺反應提出了兩個假設。該研究提出使用三種公式(BERTScore [247]、MQAG [134] 和 n-gram)來評估事實一致性,并使用替代 LLMs 為黑盒語言模型收集標記概率。研究發現,只需計算句子似然或熵就能幫助驗證回答的真實性。Min 等人[138] 將 LLM 生成的文本分解為單個 "原子 "事實,然后對其正確性進行評估。FActScore 用于通過計算 F1 分數來衡量估計器的性能。該論文測試了各種估計器,結果表明當前的估計器在有效處理任務方面仍有一段路要走。Lin 等人[119] 引入了 TruthfulQA 數據集,旨在讓模型犯錯。通過提供事實性答案對多種語言模型進行了測試。這些實驗的結果表明,僅僅擴大模型的規模并不一定能提高模型的真實性,并對訓練方法提出了建議。該數據集已被廣泛用于評估 LLM 的真實性[89, 146, 192, 219]。
3.2. 魯棒性、道德、偏差和可信度(Robustness, Ethics, Bias, and Trustworthiness)
評估包括穩健性、道德、偏差和可信度等重要方面。這些因素在全面評估 LLMs 的績效方面越來越重要。表 3 顯示了研究摘要。

3.2.1. 魯棒性
魯棒性研究的是系統在面對意外輸入時的穩定性。具體來說,分布外(OOD)[207] 和對抗魯棒性是魯棒性的兩個熱門研究課題。Wang 等人[206]的早期研究利用 AdvGLUE [203]、ANLI [140] 和 DDXPlus [41] 數據集等現有基準,從對抗和 OOD 兩個角度評估了 ChatGPT 和其他 LLM。Zhuo 等人[265] 評估了語義解析的魯棒性。Yang等人[233]通過擴展GLUE[200]數據集評估了OOD的魯棒性。這項研究的結果強調了在處理視覺輸入時對整個系統安全的潛在風險。對于視覺語言模型,Zhao 等人[256] 評估了視覺輸入的 LLM,并將其轉移到其他視覺語言模型,揭示了視覺輸入的脆弱性。Li 等人[111]概述了語言模型的 OOD 評估:對抗魯棒性、領域泛化和數據集偏差。在這些研究方向之間,作者進行了比較分析,將三種方法統一起來。他們簡明扼要地概述了每個研究方向的數據生成過程和評估協議,同時強調了當前的挑戰和未來的研究前景。此外,Liu 等人[123] 引入了大規模魯棒視覺指令數據集,以提高大規模多模態模型處理相關圖像和人類指令的性能。
在對抗魯棒性方面,Zhu 等人[262] 通過提出一個名為 PromptBench 的統一基準,評估了 LLM 對提示的魯棒性。他們從多個層面(字符、單詞、句子和語義)全面評估了對抗性文本攻擊。結果表明,當代的 LLM 很容易受到對抗性提示的攻擊,這突出了模型在面對對抗性輸入時的魯棒性。至于新的對抗數據集,Wang 等人[201]引入了 AdvGLUE++ 基準數據來評估對抗魯棒性,并實施了新的評估協議,通過越獄系統提示來審查機器道德。
3.2.2. 道德與偏見
研究發現,LLMs 會內化、傳播并可能放大抓取的訓練語料中存在的有害信息,通常是有毒語言,如冒犯、仇恨言論和侮辱[53],以及社會偏見,如對具有特定人口特征(如性別、種族、宗教、職業和意識形態)的人的刻板印象[175]。最近,Zhuo 等人[264]使用傳統測試集和指標[37, 53, 153]對 ChatGPT 的毒性和社會偏見進行了系統評估,發現它在一定程度上仍表現出有害內容。Deshpande 等人[35]又進一步將角色扮演引入模型,并觀察到生成的毒性增加了 6 倍。此外,這種角色扮演還造成了對特定實體的偏見性毒性。與簡單測量社會偏見不同,Ferrara[42]研究了 ChatGPT 可能產生的這些偏見的來源、潛在機制和相應的倫理后果。除了社會偏見,還有人通過政治羅盤測試和 MBTI 測試等基于問卷的政治傾向和人格特質 [65, 167],對 LLMs 進行了評估,結果顯示 LLMs 具有進步觀點傾向和 ENFJ 人格類型。此外,從道德基礎理論[58]來看,GPT-3 等 LLMs 存在道德偏差[176];[69]的研究表明,現有 LMs 在道德判斷方面具有潛力,但仍需改進。[254]提出了中文會話偏見評估數據集 CHBias,發現了預訓練模型中的偏見風險,并探討了去偏方法。此外,在評估 GPT-4 配對時,[209] 發現了系統性偏差。ChatGPT 也被觀察到在文化價值觀上表現出一定程度的偏差[16]。Wang 等人[201]還使用有針對性和無針對性的系統提示,納入了一個專門用于衡量刻板印象偏差的評估數據集。所有這些倫理問題都可能引發嚴重的風險,阻礙 LLM 的部署,并對社會產生深遠的負面影響。
3.2.3. 可信度
在 2023 年的研究《DecodingTrust》中,Wang 等人[201]對 GPT 模型,尤其是 GPT-3.5 和 GPT-4 中的可信度漏洞進行了多方面的探索。他們的評估超出了典型的可信度問題,包括八個關鍵方面:毒性、刻板偏見、對抗性和分布外魯棒性、對抗性演示的魯棒性、隱私、機器倫理和公平性。DecodingTrust 的調查采用了一系列新構建的場景、任務和指標。他們發現,雖然在標準評估中,GPT-4 的可信度通常比 GPT-3.5 有所提高,但它同時也更容易受到攻擊。
在 Hagendorff 和 Fabi 的另一項研究中[62],對認知能力增強的 LLM 進行了評估。他們發現,這些模型可以避免人類常見的直覺和認知錯誤,表現出超理性的性能。通過利用認知反思測試和語義錯覺實驗,研究人員深入了解了 LLM 的心理層面。這種方法為評估模型偏差和倫理問題提供了新的視角,而這些問題可能是以前沒有發現的。此外,[227] 的一項研究引起了人們對一個重要問題的關注:當面臨質疑、否定或誤導性提示等干擾時,即使最初的判斷是準確的,LLMs 判斷的一致性也會明顯降低。該研究深入探討了旨在緩解這一問題的各種提示方法,并成功證明了這些方法的有效性。
LLM 能夠生成連貫且看似符合事實的文本。然而,生成的信息可能包含與事實不符的內容或不符合實際情況的陳述,這種現象被稱為幻覺[163, 251]。評估這些問題有助于改進 LLM 的訓練方法,減少幻覺的出現。為了評估大規模視覺模型中的幻覺,Liu 等人[123]引入了一個全面而穩健的大規模視覺教學數據集:LRV-Instruction。通過 GAVIE 方法,他們對評估視覺指令進行了微調,實驗結果表明 LRV-Instruction 能有效緩解 LLM 中的幻覺。此外,Li 等人[113] 對大規模視覺語言模型中的錯覺進行了評估,通過實驗發現視覺指令中物體的分布對 LVLM 中的物體錯覺有顯著影響。為了加強對 LVLM 中物體錯覺的評估,他們引入了一種基于輪詢的查詢方法,即 POPE。這種方法改進了對 LVLM 中物體錯覺的評估。
3.3. 社會科學
社會科學涉及對人類社會和個人行為的研究,包括經濟學、社會學、政治學、法學和其他學科。評估 LLMs 在社會科學領域的表現對于學術研究、政策制定和社會問題解決都非常重要。這種評估有助于提高社會科學模型的適用性和質量,增加對人類社會的了解,促進社會進步。Wu 等人[223]評估了 LLMs 在解決社會科學中的比例和測量問題方面的潛在用途,發現 LLMs 可以生成有關政治意識形態的有意義的回應,并顯著改善社會科學中的文本即數據方法。
在計算社會科學(CSS)任務中,Ziems 等人[267]對 LLMs 在多個 CSS 任務中的表現進行了全面評估。在分類任務中,LLMs 在事件論據提取、人物情節、隱性仇恨和移情分類方面的絕對性能最低,準確率低于 40%。這些任務要么涉及復雜的結構(事件論據),要么涉及主觀的專家分類法,其語義與 LLM 預訓練時學習到的語義不同。相反,LLM 在錯誤信息、立場和情感分類方面表現最佳。在生成任務方面,LLM 所生成的解釋通常會超過人群工作者提供的黃金參考文獻的質量。總之,雖然 LLMs 可以大大增強傳統的 CSS 研究流水線,但它們不能完全取代傳統的 CSS 研究流水線。
一些文章還就法律任務對 LLMs 進行了評估。在法律案件的判決摘要中,LLMs 的 zero-shot 表現平平。LLMs 存在一些問題,包括句子和單詞不完整、無意義的句子合并,以及更嚴重的錯誤,如信息不一致和幻覺[34]。結果表明,要使 LLMs 在法律專家的案件判決摘要中發揮作用,還需要進一步改進。Nay 等人[139]指出,LLMs,尤其是與提示增強功能和正確的法律文本相結合時,可以發揮更好的作用,但尚未達到稅務律師專家的水平。
最后,在心理學領域,Frank[44]采用了跨學科的方法,從發展心理學和比較心理學中汲取靈感,探索評估 LLM 能力的替代方法。通過整合不同視角,研究人員可以加深對認知本質的理解,有效利用大型語言模型等先進技術的潛力,同時降低潛在風險。
總之,在處理與社會科學有關的任務時,LLMs 的使用對個人大有裨益,從而提高了工作效率。LLMs 的產出是提高生產力的寶貴資源。不過,必須承認,現有的 LLMs 不能完全取代這一領域的專業人員。
3.4. 自然科學與工程
評估 LLM 在自然科學和工程學領域的表現有助于指導科學研究、技術開發和工程學研究的應用和發展。表 4 顯示了自然科學和工程任務的摘要。

3.4.1. 數學
對于基本的數學問題,大多數大型語言模型(LLMs)都能熟練地進行加法和減法運算,并具有一定的乘法運算能力。然而,它們在處理除法、指數、三角函數和對數函數時面臨挑戰。另一方面,LLM 在處理十進制數、負數和無理數方面表現出了能力[240]。在性能方面,ChatGPT 和 GPT-4 明顯優于其他模型,顯示了它們在解決數學任務方面的優勢[220]。這兩個模型在處理大數(大于 1e12)和復雜冗長的數學查詢時優勢明顯。GPT-4 的準確率比 ChatGPT 高出 10 個百分點,相對誤差減少 50%,這得益于它出色的除法和三角計算能力、對無理數的正確理解以及對長表達式的連貫分步計算。
在面對復雜和具有挑戰性的數學問題時,LLM 的性能不盡如人意。具體來說,GPT-3 的性能幾乎是隨機的,GPT-3.5 有所改進,而 GPT-4 的性能最好[3]。盡管新模型取得了進步,但值得注意的是,與專家相比,其峰值性能仍然相對較低,而且這些模型缺乏從事數學研究的能力[15]。代數操作和計算的具體任務仍然是 GPT 面臨的挑戰[15, 27]。GPT-4 在這些任務中表現不佳的主要原因是代數操作錯誤和難以檢索相關領域的特定概念。Wu 等人[224]評估了 GPT-4 在高中競賽難題中的使用情況,結果發現 GPT-4 在半數題目中的準確率達到了 60%。中級代數和微積分只能以 20% 左右的低準確率解決。ChatGPT 不擅長解答導數及應用、Oxyz 空間微積分和空間幾何等題目[31]。Dao和Le[31]、Wei等人[220]的研究表明,隨著任務難度的增加,ChatGPT的性能也會下降:在識別水平上,它能正確回答83%的問題;在理解水平上,它能正確回答62%的問題;在應用水平上,它能正確回答27%的問題。而在認知復雜度最高的層次上,只有 10%。鑒于較高知識水平的問題往往更為復雜,需要深入理解和解決問題的技能,這種結果是意料之中的。
這些結果表明,LLMs 的有效性在很大程度上受到它們所遇到問題的復雜性的影響。這一發現對于設計和開發能夠成功處理這些挑戰性任務的優化人工智能系統具有重要意義。
3.4.2. 通用科學
在化學領域應用 LLM 還需要進一步改進。Castro Nascimento 和 Pimentel[18]提出了五個來自不同化學子領域的簡單任務,以評估 ChatGPT 對該學科的理解能力,準確率從 25% 到 100% 不等。Guo 等人[61]創建了一個包含八個實用化學任務的綜合基準,旨在評估 LLM(包括 GPT-4、GPT-3.5 和 Davinci-003)在每個化學任務中的表現。根據實驗結果,GPT-4 的性能優于其他兩個模型。文獻[3]顯示,LLM 在物理問題上的表現比化學問題差,這可能是因為在這種情況下,化學問題的推理復雜度比物理問題低。在普通科學領域對 LLM 的評估研究還很有限,目前的研究結果表明,LLM 在這一領域的性能還需要進一步提高。
3.4.3. 工程學
在工程學中,任務可按難度由高到低的順序排列,包括代碼生成、軟件工程和常識規劃。
在代碼生成任務中,為這些任務訓練的小型 LLM 在性能上具有競爭力,CodeGen-16B [141] 在使用較大參數設置時與 ChatGPT 的性能相當,達到約 78% 的匹配 [125]。盡管在掌握和理解編程語言的某些基本概念方面面臨挑戰,但 ChatGPT 仍展示出了值得稱贊的編碼水平 [263]。具體來說,ChatGPT 在動態編程、貪婪算法和搜索方面掌握了高超的技能,超過了能力出眾的大學生,但在數據結構、樹和圖論方面卻舉步維艱。GPT-4 展示了根據給定指令生成代碼、理解現有代碼、推理代碼執行、模擬指令影響、用自然語言表達結果以及有效執行偽代碼的高級能力[15]。
在軟件工程任務中,ChatGPT 通常表現良好并能提供詳細的回答,往往超過人類專家的輸出和 SOTA 的輸出。但是,對于某些任務,如代碼漏洞檢測和基于信息檢索的測試優先級排序,當前版本的 ChatGPT 無法提供準確的答案,因此不適合這些特定任務 [181]。
在常識規劃任務中,LLM 可能表現不佳,甚至在人類擅長的簡單規劃任務中也是如此 [194, 195]。Pallagani 等人[150]的研究表明,經過微調的 CodeT5 [214]在所有考慮的領域中表現最佳,推理時間最短。此外,該研究還探討了 LLM 在計劃泛化方面的能力,發現其泛化能力似乎有限。事實證明,LLM 可以處理簡單的工程任務,但在復雜的工程任務上表現不佳。
3.5. 醫療應用
最近,LLM 在醫學領域的應用受到了極大關注。因此,本節旨在對目前致力于在醫療應用中實施 LLM 的工作進行全面回顧。如表 5 所示,我們將這些應用分為三個方面:醫療問詢、醫療檢查和醫療助理。對這些類別的研究將加深我們對 LLMs 在醫學領域的潛在影響和優勢的理解。
3.5.1. 醫療問詢
在醫療查詢方面評估 LLM 的意義在于提供準確可靠的醫療答案,以滿足醫護人員和患者對高質量醫療信息的需求。如表 5 所示,醫療領域的大多數 LLM 評估都集中在醫療查詢方面。ChatGPT 為遺傳學[39]、腫瘤放射物理學[73]、生物醫學[81]等多種醫學查詢生成了相對準確的信息,在一定程度上證明了其在醫學查詢領域的有效性。至于其局限性,Thirunavukarasu 等人[186]評估了 ChatGPT 在初級醫療中的表現,發現其在學生綜合評估中的平均得分低于及格分,說明還有改進的空間。Chervenak 等人[21]強調,雖然 ChatGPT 可以生成與生育相關臨床提示中現有來源類似的回答,但其在可靠引用來源方面的局限性和編造信息的可能性限制了其臨床實用性。
3.5.2. 醫療檢查
Gilson 等人[57]和 Kung 等人[97]的研究通過美國醫學執照考試(USMLE)評估了 LLM 在醫學考試評估中的表現。結果表明,ChatGPT 在不同的數據集上取得了不同的準確率。然而,在 NBME-Free-Step1 和 NBME-Free-Step2 數據集中,與正確答案相比,斷章取義信息的出現率較低。Kung 等人[97]的研究表明,ChatGPT 在這些考試中達到或接近了及格線,而無需定制訓練。該模型顯示出高度的一致性和洞察力,表明其具有協助醫學教育和臨床決策的潛力。ChatGPT 可用作回答醫學問題、提供解釋和支持決策過程的工具。這為醫科學生和臨床醫生的教育和臨床實踐提供了額外的資源和支持。Sharma 等人[173]發現,與谷歌搜索結果相比,ChatGPT 生成的答案更具上下文意識,演繹推理能力更強。
3.5.3. 醫療助手
在醫療助手領域,LLMs 展現了潛在的應用前景,包括胃腸道疾病識別研究 [99]、癡呆癥診斷 [217]、加速 COVID-19 文獻評估 [93],以及其在醫療保健領域的整體潛力 [17]。然而,它也存在局限性和挑戰,例如缺乏原創性、輸入要求高、資源限制、答案的不確定性以及與誤診和患者隱私問題相關的潛在風險。
此外,一些研究還評估了 ChatGPT 在醫學教育領域的性能和可行性。Oh 等人的研究[143]評估了 ChatGPT,特別是 GPT-3.5 和 GPT-4 模型對外科臨床信息的理解及其對外科教育和培訓的潛在影響。結果表明,GPT-3.5 的總體準確率為 46.8%,GPT-4 為 76.4%,這表明兩個模型之間存在顯著的性能差異。值得注意的是,GPT-4 在不同的亞專科中始終表現良好,這表明它有能力理解復雜的臨床信息,并加強外科教育和培訓。Lyu 等人的另一項研究[131]探討了在臨床教育中使用 ChatGPT 的可行性,尤其是將放射學報告翻譯成通俗易懂的語言。研究結果表明,ChatGPT 能有效地將放射學報告翻譯成通俗易懂的語言,并提供一般性建議。此外,與 GPT-4 相比,ChatGPT 的質量有所提高。這些研究結果表明,在臨床教育中使用 LLMs 是可行的,盡管還需要進一步努力解決其局限性并充分釋放其潛力。
3.6. Agent 應用
LLM 不應只專注于一般語言任務,它可以作為各種領域的強大工具加以利用。為 LLM 配備外部工具可以大大擴展模型的功能[160]。ToolLLM [161] 提供了一個綜合框架,為開源大型語言模型配備了工具使用功能。Huang 等人[77]介紹了 KOSMOS-1,它能夠理解一般模式、遵循指令并根據上下文進行學習。Karpas 等人[90] 對 MRKL 的研究強調了了解何時以及如何使用外部符號工具的重要性,因為這種知識取決于 LLM 的能力,尤其是當這些工具能夠可靠地執行功能時。此外,還有兩項研究,即 Toolformer [172] 和 TALM [152],探討了如何利用工具來增強語言模型。Toolformer 采用訓練方法來確定特定 API 的最佳使用方法,并將獲得的結果整合到隨后的標記預測中。另一方面,TALM 將不可區分的工具與基于文本的方法相結合,以增強語言模型,并采用了一種稱為 "自我游戲 "的迭代技術,以最少的工具演示為指導。此外,Shen 等人[174] 提出了 HuggingGPT 框架,該框架利用 LLM 連接機器學習社區內的各種人工智能模型(如 Hugging Face),旨在解決人工智能任務。
3.7. 其他應用
除上述領域外,還在教育、搜索和推薦、個性測試以及特定應用等其他領域進行了評估。表 6 匯總了這些應用。

3.7.1. 教育
LLMs 在教育領域的變革中大有可為。它們有可能在多個領域做出重大貢獻,如幫助學生提高寫作技巧、促進更好地理解復雜概念、加快信息傳遞,以及提供個性化反饋以提高學生的參與度。這些應用旨在創造更高效、更互動的學習體驗,為學生提供更廣泛的教育機會。然而,要充分發揮 LLM 在教育領域的潛力,還需要廣泛的研究和不斷的改進。
對 LLMs 教育助手的評估旨在調查和評估其對教育領域的潛在貢獻。這種評估可以從不同的角度進行。根據 Dai 等人的研究[30],ChatGPT 展示了生成詳細、流暢、連貫的反饋的能力,超過了人類教師。它能準確評估學生的作業,并就任務完成情況提供反饋,從而幫助培養學生的技能。然而,ChatGPT 的回復可能缺乏新穎性或對教學改進的深刻見解[210]。此外,Hellas 等人的研究[67]表明,LLMs 可以成功識別學生代碼中的至少一個實際問題,但也存在誤判的情況。總之,盡管在熟練掌握輸出格式化方面仍存在挑戰,但使用 LLMs 在解決程序邏輯問題方面還是大有可為的。值得注意的是,雖然這些模型可以提供有價值的見解,但它們仍可能產生類似于學生所犯的錯誤。
在教育考試中,研究人員旨在評估 LLM 的應用效果,包括自動評分、問題生成和學習指導。de Winter [32]的研究表明,ChatGPT 平均正確率達到 71.8%,與所有參與學生的平均得分相當。隨后,使用 GPT-4 進行了評估,結果為 8.33 分。此外,該評估還顯示了通過 "溫度"參數結合隨機性的引導技術在診斷錯誤答案方面的有效性。Zhang 等人[246]聲稱,GPT-3.5 可以解決麻省理工學院的數學和電子工程科學考試,而 GPT-4 的性能更好。然而,事實證明這并不公平,因為他們不小心將正確答案包含在了提示中。
3.7.2. 搜索和推薦
在搜索和推薦中對 LLM 的評估可大致分為兩個方面。首先,在信息檢索領域,Sun 等人[183]研究了生成式排序算法(如 ChatGPT 和 GPT-4)在信息檢索任務中的有效性。實驗結果表明,引導式 ChatGPT 和 GPT-4 在流行的基準測試中表現出極具競爭力的性能,甚至超過了監督式方法。此外,將 ChatGPT 的排序功能提取到一個專門模型中,與在 BEIR 數據集中對 40 萬個注釋的 MS MARCO 數據進行訓練相比,在對 10K ChatGPT 生成的數據進行訓練時顯示出更優越的性能[185]。此外,Xu 等人[231] 進行了一項隨機在線實驗,研究用戶在使用搜索引擎和聊天機器人工具執行信息檢索任務時的行為差異。參與者被分為兩組:一組使用與 ChatGPT 類似的工具,另一組使用與谷歌搜索類似的工具。結果顯示,ChatGPT 組在所有任務上花費的時間都較少,兩組之間的差異并不顯著。
其次,在推薦系統領域,LLM 已成為利用自然語言處理能力理解用戶偏好、項目描述和上下文信息的重要組件[40]。通過將 LLM 納入推薦管道,這些系統可以提供更準確、更個性化的推薦,從而改善用戶體驗和整體推薦質量。然而,解決與使用 LLMs 進行推薦相關的潛在風險也至關重要。Zhang 等人最近的研究[244]強調了由 ChatGPT 生成的不公平推薦問題。這強調了在推薦場景中使用 LLM 時評估公平性的重要性。Dai 等人[29]認為,ChatGPT 在推薦系統中表現出很強的性能。他們發現使用列表排序能在成本和性能之間取得最佳平衡。此外,ChatGPT 在解決冷啟動問題和提供可解釋的推薦方面顯示出了前景。此外,Yuan 等人[239]和 Li 等人[110]的研究表明,基于模態的推薦模型(MoRec)和基于文本的協同過濾(TCF)在推薦系統中大有可為。
3.7.3. 性格測試
人格測試旨在測量個人的人格特質和行為傾向,而 LLM 作為強大的自然語言處理模型已被廣泛應用于此類任務中。
Bodroza等人的研究[10]調查了將Davinci003作為聊天機器人的個性特征,發現盡管其表現出親社會特征,但其回答的一致性存在差異。然而,聊天機器人的回答是由有意識的自我反思還是算法過程驅動的,這一點仍不確定。Song 等人[180]研究了語言模型中的個性表現,發現許多模型在自我評估測試中表現不可靠,并表現出固有的偏差。因此,有必要開發特定的機器人格測量工具,以提高可靠性。這些研究為更好地理解人格測試中的語言模型提供了重要啟示。Safdari 等人[168]提出了一種綜合方法,對 LLM 生成的文本中的人格特質進行有效的心理測試。為了評估 LLMs 的情商,Wang 等人[212]開發了一種新的心理測量評估方法。通過參考 500 多名成年人構建的框架,作者測試了各種主流 LLMs。結果表明,大多數 LLMs 的情商(EQ)高于平均水平,其中 GPT-4 得分為 117 分,超過了 89% 的人類參與者。然而,多變量模式分析表明,某些 LLMs 無需依賴與人類類似的機制就能達到人類水平。與人類相比,它們的表征模式在質量上存在明顯差異,這一點顯而易見。Liang等人[115]采用猜詞游戲來評估低等語言能力者的語言和思維理論智能,這是一種更具參與性和互動性的評估方法。Jentzsch和Kersting[84]討論了將幽默融入LLM,特別是ChatGPT的挑戰。他們發現,雖然 ChatGPT 在 NLP 任務中表現出了令人印象深刻的能力,但在生成幽默回復方面卻有所欠缺。這項研究強調了幽默在人類交流中的重要性,以及 LLM 在捕捉幽默的微妙之處和依賴語境的特性時所面臨的困難。它討論了當前方法的局限性,并強調了進一步研究能有效理解和生成幽默的更復雜模型的必要性。
3.7.4. 其他應用
此外,人們還開展了各種研究工作,探索 LLM 在游戲設計[101]、模型性能評估[216]和日志解析[103]等廣泛任務中的應用和評估。總之,這些發現增強了我們對在不同任務中使用 LLMs 的實際意義的理解。它們揭示了這些模型的潛力和局限性,同時為提高性能提供了寶貴的見解。
4. WHERE TO EVALUATE: 數據集 和 benchmark
LLMs 評估數據集用于測試和比較不同語言模型在各種任務中的性能,如第 3 節所述。這些數據集,如 GLUE [200] 和 SuperGLUE [199],旨在模擬真實世界的語言處理場景,涵蓋文本分類、機器翻譯、閱讀理解和對話生成等多種任務。本節將不討論語言模型的任何單一數據集,而是討論 LLM 的基準。為評估 LLM 的性能,已經出現了多種基準。在本研究中,我們選擇了 46 個流行的基準,如表 7 所示。每個基準都關注不同的方面和評估標準,為各自的領域做出了寶貴的貢獻。為了更好地總結,我們將這些基準分為三類:通用語言任務基準、特定下游任務基準和多模式任務基準。

4.1. Benchmarks for General Tasks
LLM 用于解決絕大多數任務。為此,現有基準往往會評估不同任務的性能。
Chatbot Arena [128] 和 MT-Bench [258] 是兩個重要的基準,有助于在不同環境下評估和改進聊天機器人模型和 LLM。Chatbot Arena 提供了一個通過用戶參與和投票來評估和比較各種聊天機器人模型的平臺。用戶可以參與匿名模型,并通過投票表達自己的偏好。該平臺收集了大量投票,有助于評估模型在現實場景中的性能。Chatbot Arena 為了解聊天機器人模型的優勢和局限提供了有價值的見解,從而促進了聊天機器人研究和進步。同時,MT-Bench 使用為處理對話量身定制的綜合問題,對多輪對話中的 LLM 進行評估。它提供了一套全面的問題,專門用于評估模型處理多輪對話的能力。MT-Bench 有幾個不同于傳統評估方法的顯著特點。特別是,它在模擬代表真實世界的對話場景方面表現出色,從而有助于對模型的實際性能進行更精確的評估。此外,MTBench 還有效克服了傳統評估方法的局限性,尤其是在衡量模型處理復雜的多輪對話詢問的能力方面。
HELM [114] 并不專注于特定任務和評估指標,而是對 LLM 進行全面評估。它從語言理解、生成、連貫性、上下文敏感性、常識推理和特定領域知識等多個方面對語言模型進行評估。HELM 旨在全面評估語言模型在不同任務和領域中的表現。在 LLMs Evaluator 方面,Zhang 等人[250] 提出了 LLMEval2,它包含了廣泛的能力評估。此外,Xiezhi[59]提出了一套用于評估不同學科領域大規模語言模型知識水平的綜合套件。通過 Xiezhi 進行的評估使研究人員能夠理解這些模型固有的顯著局限性,并有助于更深入地理解它們在不同領域的能力。為了評估語言模型現有能力之外的能力,BIG-bench [182] 引入了由來自 132 個機構的 450 位作者提供的 204 個具有挑戰性的任務。這些任務涉及數學、兒童發展、語言學、生物學、常識推理、社會偏見、物理學、軟件開發等多個領域。
最近的工作引導了評估語言模型知識和推理能力的基準的發展。以知識為導向的語言模型評估 KoLA [235] 主要評估語言模型的理解能力和利用語義知識進行推理的能力。因此,KoLA 是評估語言模型中語言理解和推理深度的重要基準,從而推動語言理解的進步。為了對語言任務進行眾包評估,DynaBench [94] 支持動態基準測試。DynaBench 探索了新的研究方向,包括閉環整合的效果、分布轉移特征、注釋者的效率、專家注釋者的影響以及模型在交互式環境中對抗性攻擊的魯棒性。此外,為了評估語言模型學習和應用跨學科知識的能力,最近推出了多學科知識評估 M3KE [122]。M3KE 評估知識在中國教育系統中的應用。
開發用于評估不同任務中 LLM 的標準化基準一直是研究的重點。MMLU [70] 為評估多任務背景下的文本模型提供了一套全面的測試。AlpacaEval [112] 是一種自動評估基準,其重點是評估 LLM 在各種自然語言處理任務中的性能。它提供了一系列指標、穩健性測量和多樣性評估,以衡量 LLM 的能力。AlpacaEval 極大地推動了 LLM 在不同領域的發展,并促進了對其性能的深入了解。此外,AGIEval [260] 是一個專門的評估框架,用于評估基礎模型在以人為中心的標準化考試領域中的性能。此外,OpenLLM [80] 提供了一個公共競賽平臺,用于比較和評估不同 LLM 模型在各種任務中的性能,從而起到了評估基準的作用。它鼓勵研究人員提交自己的模型,并就不同任務展開競爭,從而推動 LLM 研究的進步和競爭。
至于標準性能之外的任務,則有針對 OOD、對抗魯棒性和微調設計的基準。GLUE-X [233]是一種新穎的嘗試,旨在創建一個統一的基準,以評估 OOD 場景中 NLP 模型的魯棒性。該基準強調了魯棒性在 NLP 中的重要性,并為測量和增強模型的魯棒性提供了見解。此外,Yuan 等人[238] 提出了 BOSS,這是一個用于評估自然語言處理任務中分布外魯棒性的基準集合。PromptBench [262]側重于提示工程在微調 LLM 中的重要性。它提供了一個標準化的評估框架,用于比較不同的提示工程技術并評估其對模型性能的影響。PromptBench 有助于增強和優化 LLM 的微調方法。為了確保評估的公正性和公平性,PandaLM [216] 被引入作為一種鑒別性大規模語言模型,專門設計用于通過訓練區分多種高效 LLM。傳統的評估數據集主要強調客觀正確性,與之不同的是,PandaLM 加入了關鍵的主觀因素,包括相對簡潔、清晰、遵守說明、全面性和正式性。
4.2. Benchmarks for Specific Downstream Tasks
除了針對一般任務的基準外,還有專門針對某些下游任務的基準。
問題-解答基準已成為 LLM 及其整體性能評估的基本組成部分。MultiMedQA [177] 是一個醫療質量保證基準,重點關注醫學考試、醫學研究和消費者保健問題。它由七個與醫療質量保證相關的數據集組成,包括六個現有數據集和一個新數據集。該基準的目標是評估法律碩士在臨床知識和質量保證能力方面的表現。為了評估 LLM 在有關當前世界知識的動態質量保證方面的能力,Vu 等人[198] 引入了 FRESHQA。通過在提示中加入從搜索引擎中檢索到的相關當前信息,LLMs 在 FRESHQA 中的表現有了顯著提高。為了有效評估深度對話,Wang 等人[205]引入了對話 CoT,其中包含兩種有效的對話策略: 顯式 CoT 和 CoT。
在最近的研究中,對各種高難度任務中的 LLM 進行評估引起了廣泛關注。為此,人們引入了一系列專門的基準來評估 LLM 在特定領域和應用中的能力。其中,由 Sawada 等人提出的 ARB [171],主要測試 LLM 在跨多個領域的高級推理任務中的性能。此外,LLM 中的倫理考慮也已成為一個至關重要的領域。由 Huang 等人[79]定制的 TRUSTGPT 解決了 LLMs 中的關鍵倫理問題,包括毒性、偏見和價值一致性。此外,正如 Huang 等人的 EmotionBench 基準[76]所強調的,LLM 對人類情緒反應的模擬仍是一個具有巨大改進潛力的領域。在安全評估方面,Zhang 等人[252] 推出了 SafetyBench,這是一個專門用于測試一系列流行的中英文 LLM 安全性能的基準。評估結果揭示了當前 LLMs 中存在的重大安全缺陷。為了評估智能系統的日常決策能力,Hou 等人[75] 推出了 Choice-75。此外,為了評估 LLMs 理解復雜指令的能力,He 等人[66] 引入了 CELLO。該基準包括八個獨特功能的設計、一個綜合評估數據集的開發以及四個評估標準及其各自測量標準的建立。
還有其他一些特定的基準,如 C-Eval [78],它是第一個廣泛評估中文基礎模型的高級知識和推理能力的基準。此外,Li 等人[108] 介紹了 CMMLU 作為一個全面的中文能力標準,并評估了 18 個不同學科的 LLM 的表現。研究結果表明,大多數 LLM 在中文環境中的表現不盡如人意,突出了需要改進的地方。M3Exam[248]提供了一個獨特而全面的評估框架,它結合了多種語言、模式和水平,以測試語言學習者在不同語境中的綜合能力。此外,GAOKAO-Bench[243]提供了一個全面的評估基準,利用來自中國高考的試題來衡量大型語言模型在復雜和特定語境任務中的能力。另一方面,SOCKET [23] 是一個 NLP 基準,旨在評估 LLM 在學習和識別社會知識概念方面的性能。它由多個任務和案例研究組成,用于評估 LLM 在社會能力方面的局限性。MATH [72] 主要評估人工智能模型在數學領域的推理和解決問題能力。APPS[68]是評估代碼生成的一個更全面、更嚴格的基準,衡量語言模型根據自然語言規范生成 Python 代碼的能力。CUAD [71] 是一個由專家注釋的、特定領域的法律合同審查數據集,它是一個具有挑戰性的研究基準,具有提高深度學習模型在合同理解任務中的性能的潛力。CVALUES [229]引入了一個人文評估基準,用于評估法律合同管理與安全和責任標準的一致性。在綜合中醫領域,Wang 等人[211]引入了 CMB,這是一種植根于中國語言和文化的醫學評價基準。它解決了僅僅依賴基于英語的醫學評估可能導致的本地環境不一致的問題。在幻覺評估領域,[116] 開發了 UHGEval,這是一個專門用于評估中文 LLM 文本生成性能的基準,不受幻覺相關限制的約束。
除了現有的評估基準外,在評估 LLM 使用工具的有效性方面還存在研究空白。針對這一空白,API-Bank 基準[109]作為首個明確為工具增強型 LLM 設計的基準被引入。它包括一個全面的工具增強型 LLM 工作流,包含 53 個常用 API 工具和 264 個注釋對話,共包含 568 個 API 調用。此外,ToolBench 項目[191]旨在增強大型語言模型的開發能力,從而有效利用通用工具的功能。通過提供一個創建優化指令數據集的平臺,ToolBench 項目旨在推動語言模型的發展并加強其實際應用。為了評估多輪交互中的 LLM,Wang 等人[213]提出了 MINT,它利用了工具和自然語言反饋。
4.3. Benchmarks for Multi-modal Task
對于多模態大語言模型(MLLM)的評估,MME[46]是一個廣泛的評估基準,旨在評估其感知和認知能力。它采用精心設計的指令-答案對和簡潔的指令設計,從而保證了公平的評估條件。為了對大規模視覺語言模型進行穩健評估,Liu 等人[126] 推出了 MMBench,其中包含一個綜合數據集,并采用了 CircularEval 評估方法。此外,MMICL [253] 針對多模態輸入增強了視覺語言模型,并在 MME 和 MMBench 等任務中表現出色。此外,LAMM[234]將其研究擴展到多模態點云。LVLM-eHub [230] 利用在線競爭平臺和定量能力評估對 LVLM 進行了詳盡的評估。為了全面評估多模態大型語言模型(MLLM)的生成和理解能力,Li 等人[107] 推出了一個名為 SEEDBench 的新基準。該基準由 19,000 道多選題組成,這些多選題已由人類評估員進行了注釋。此外,評估還涉及 12 個不同方面,包括模型理解圖像和視頻中的模式的熟練程度。總之,最近的研究工作開發了強大的基準和改進的模型,推動了多模態語言的研究。
5. HOW TO EVALUA
在本節中,我們將介紹兩種常見的評估方法:自動評估和人工評估。我們的分類依據是評價標準能否自動計算。如果可以自動計算,我們就將其歸入自動評價;否則,就歸入人工評價。
5.1. Automatic Evaluation
自動評估是一種常見的評估方法,也可能是最流行的評估方法,通常使用標準指標和評估工具來評估模型性能。與人工評價相比,自動評價不需要大量的人工參與,不僅節省時間,還能減少人為主觀因素的影響,使評價過程更加規范。例如,Qin 等人[159]和 Bang 等人[6]都使用自動評估方法對大量任務進行了評估。最近,隨著 LLM 的發展,一些先進的自動評估技術也被設計出來幫助評估。Lin和Chen[121]提出了LLM-EVAL,這是一種統一的多維自動評估方法,適用于LLM的開放域對話。PandaLM [216] 通過訓練一個 LLM 作為 "法官 "來評估不同的模型,從而實現可重復的自動語言模型評估。Jain 等人[82]提出了一種自監督評估框架,通過消除對新數據的費力標注,在實際部署中實現了一種更高效的模型評估形式。此外,許多基準也應用了自動評估,如 MMLU [70]、HELM [114]、C-Eval [78]、AGIEval [260]、AlpacaFarm [38]、Chatbot Arena [128] 等。

根據采用自動評價的文獻,我們在表 9 中總結了自動評價的主要指標。主要指標包括以下四個方面:
- 準確度(Accuracy)是衡量模型在特定任務中的正確程度。準確度的概念在不同情況下可能有所不同,并取決于具體任務和問題的定義。準確度可以用精確匹配、F1 分數和 ROUGE 分數等各種指標來衡量。
-
- Exact Match(EM)是用于評估文本生成任務中模型輸出是否與參考答案精確匹配的指標。在問題解答任務中,如果模型生成的答案與人工提供的答案完全匹配,則 EM 值為 1;否則,EM 值為 0。
- F1 分數是評估二元分類模型性能的一個指標,它綜合了模型的精確度和召回率。計算公式如下計算公式如下 F 1 = 2×Precision×Recall / Precision+Recall。
- ROUGE 主要用于評估文本摘要和機器翻譯等任務的性能,涉及文本之間重疊和匹配的考慮。
- 校準(Calibrations)是指模型輸出的置信度與實際預測精度之間的一致程度。
-
- 預期校準誤差(ECE)是評價模型校準性能的常用指標之一[60]。Tian 等人[189]利用 ECE 研究了 RLHFLM 的校準,包括 ChatGPT、GPT-4、Claude 1、Claude 2 和 Llama2。在計算 ECE 時,他們根據置信度對模型預測進行分類,并測量每個置信度區間內預測的平均準確度。
- 選擇性準確率和覆蓋率的曲線下面積(AUC)[54] 是另一個常用指標。
- 公平性(Fairness)是指模型對待不同群體的方式是否一致,即模型在不同群體間的表現是否平等。這可能包括性別、種族、年齡等屬性。DecodingTrust [201] 采用了以下兩個指標來衡量公平性:
-
- 人口均等差(DPD)衡量模型的預測結果在不同人群中的分布是否均等。如果不同群體之間的預測結果差異很大,則 DPD 值較高,表明模型可能對不同群體存在不公平的偏見。
- Equalized Odds Difference (EOD) 的目的是確保模型在不同人群中提供相同的錯誤率,即模型的預測錯誤概率分布在不同人群中是相似的。EOD 的計算涉及與真陽性(TP)、真陰性(TN)、假陽性(FP)和假陰性(FN)預測相關的概率。
- 魯棒性(Robustness)評估的是模型在面對各種挑戰性輸入時的性能,包括對抗性攻擊、數據分布變化、噪聲等。ASR和PDR分別是用來衡量模型在面對攻擊時被成功攻擊的頻率和性能下降的程度。
-
- 攻擊成功率(ASR):這是用來評估大型語言模型(LLM)對抗攻擊魯棒性的一個指標。具體來說,考慮一個數據集,其中包含N對樣本(xi,yi),其中xi是輸入,yi是真實值。對于一種對抗攻擊方法A,給定一個輸入x,這種方法可以生成對抗樣本A(x)來攻擊替代模型f
- 性能下降率(PDR):這是一個新的統一指標,用來有效評估LLM在提示(prompt)下的魯棒性。PDR量化了在對提示進行對抗攻擊后的相對性能下降
5.2. Human Evaluation
在一般的自然語言任務中,LLM 的能力日益增強,這無疑超出了標準評估指標的范圍。因此,在某些不適合自動評估的非標準情況下,人工評估自然成為一種選擇。例如,在 embedding 相似度指標(如 BERTScore)不能滿足的開放式生成任務中,人工評估更為可靠[142]。雖然有些生成任務可以采用某些自動評估協議,但在這些任務中,人工評估更為有利,因為生成結果總能比標準答案更好。
人工評估是一種通過人類參與來評估模型生成結果的質量和準確性的方法。與自動評估相比,人工評估更接近實際應用場景,能夠提供更全面和準確的反饋。在對大語言模型(LLMs)進行人工評估時,通常會邀請評估者(如專家、研究人員或普通用戶)來評估模型生成的結果。例如,Ziems等人 [267] 使用專家的注釋進行生成評估。通過人工評估,Liang等人 [114] 評估了六個模型在摘要和虛假信息場景下的表現,而Bang等人 [6] 評估了類比推理任務。Bubeck等人 [15] 進行了使用GPT-4的一系列人類設計的測試,發現GPT-4在多項任務中的表現接近或甚至超過了人類的表現。這種評估需要評估者實際測試和比較模型的性能,而不僅僅是通過自動評估指標來評估模型。需要注意的是,即使是人工評估也可能存在高方差和不穩定性,這可能是由于文化和個人差異 [155]。在實際應用中,這兩種評估方法會結合實際情況進行考慮和權衡。
探索LLMs的人工評估方法需要仔細關注各種關鍵因素,以保證評估的可靠性和準確性 [178]。表10提供了人工評估的重要方面的簡要概述,包括評估者數量、評估標準和評估者的專業水平。首先,評估者的數量是一個關鍵因素,與適當的代表性和統計顯著性緊密相關。合理選擇的評估者數量有助于對所評估的LLMs有更細致和全面的理解,從而使結果能更可靠地推廣到更廣泛的背景中。

此外,評估標準是人工評估過程的基本組成部分。基于3H原則(Helpful, Honest, Harmless) [4],我們將其擴展為以下六個人工評估標準。這些標準包括準確性、相關性、流暢性、透明性、安全性和人類一致性。通過應用這些標準,可以對LLMs在句法、語義和上下文方面的性能進行全面分析,從而更全面地評估生成文本的質量。
(1)準確性(Accuracy)[178]是一個關鍵的評估標準,用于評估生成文本的精確性和正確性。它涉及審查語言模型生成的信息在多大程度上與事實知識一致,避免錯誤和不準確。
(2)相關性(Relevance)[259]關注生成內容的適當性和重要性。這個標準檢查文本如何應對給定的上下文或查詢,確保提供的信息是相關的并且直接適用。
(3)流暢性(Fluency)[196]評估語言模型生成內容的流暢程度,保持一致的語調和風格。流暢的文本不僅在語法上正確,還保證可讀性和無縫的用戶體驗。分析人員評估模型如何避免尷尬的表達和語言或主題的突然轉變,從而促進與用戶的有效溝通。
(4)透明性(Transparency)探討了語言模型決策過程的清晰度和開放性。它涉及評估模型如何清晰地傳達其思維過程,使用戶能夠理解某些響應的生成方式和原因。一個透明的模型提供其內部工作原理的見解。
(5)安全性(Safety)[85]是一個關鍵的評估標準,關注生成文本可能帶來的潛在危害或意外后果。它檢查語言模型避免生成不適當、冒犯性或有害內容的能力,確保用戶的福祉并避免錯誤信息。
(6)人類一致性(Human alignment)評估語言模型輸出與人類價值觀、偏好和期望的一致程度。它考慮生成內容的倫理影響,確保語言模型生成尊重社會規范和用戶期望的文本,促進與人類用戶的積極互動。
最后,評估者的專業水平是一個關鍵的考慮因素,涵蓋了相關領域知識、任務熟悉度和方法培訓。明確評估者所需的專業水平,確保他們具備必要的背景知識,以準確理解和評估LLMs生成的特定領域文本。這一策略為評估過程增加了一層嚴謹性,增強了研究結果的可信度和有效性。
6. SUMMARY
在本節中,我們總結了第3、4和5節中的主要發現。首先,我們想強調的是,盡管在總結現有評估工作的過程中付出了許多努力,但沒有證據明確表明某一種評估協議或基準是最有用和成功的,而是具有不同的特征和側重點。這也表明,沒有單一的模型可以在所有類型的任務中表現最佳。本文調查的目的是超越簡單地確定“最佳”基準或評估協議。通過總結和分析現有的大語言模型(LLMs)評估工作,我們可以識別LLMs的當前成功和失敗案例,得出評估協議的新趨勢,最重要的是,為未來研究提出新的挑戰和機遇。
6.1. Task: Success and Failure Cases of LLMs
現在,我們總結LLMs在不同任務中的成功和失敗案例。請注意,以下所有結論都是基于現有的評估工作,并且結果僅依賴于特定的數據集。
6.1.1. What Can LLMs do Well?
— LLMs在生成文本方面表現出色 [11, 14, 24],能夠產生流暢和精確的語言表達。
— LLMs在涉及語言理解的任務中表現令人印象深刻,包括情感分析 [52, 129, 159]、文本分類 [114, 154, 232]以及處理事實輸入 [159]。
— LLMs展示了強大的算術推理能力 [159],并在邏輯推理 [124]方面表現優異。此外,它們在時間推理 [6]方面也表現出色。更復雜的任務如數學推理 [225, 236, 243]和結構化數據推斷 [86, 151]已成為評估的主要基準。 — LLMs表現出強大的上下文理解能力,使其能夠生成與給定輸入一致的連貫響應 [187]。
— LLMs在多個自然語言處理任務中也表現出令人滿意的性能,包括機器翻譯 [6, 130, 208]、文本生成 [20]和問答 [102, 114]。
6.1.2. When Can LLMs Fail?
— 在自然語言推理(NLI)領域,LLMs表現不佳,難以準確表達人與人之間的分歧 [105]。
— LLMs在區分事件的語義相似性方面表現有限 [184],在評估基本短語方面表現不佳 [166]。
— LLMs在抽象推理能力上有限 [56],在復雜上下文中容易出現混淆或錯誤 [148]。
— 在包含非拉丁字母和資源有限的語言環境中,LLMs表現不佳 [2, 6, 100, 248]。此外,生成型LLMs在各類任務和語言中表現普遍低于預期標準 [2]。
— LLMs在處理視覺模態信息時表現出易感性 [256]。此外,它們有能力吸收、傳播和潛在地放大訓練數據集中存在的不良內容,這些內容通常包括有毒語言元素,如冒犯性、敵對和貶低性語言 [53]。
— LLMs在生成過程中可能會表現出社會偏見和有毒性 [37, 53, 153],導致生成偏見的輸出。
— LLMs可能表現出可信度不足 [201],在對話中可能產生虛假信息或錯誤事實 [163, 251]。
— LLMs在整合實時或動態信息方面存在局限性 [127],使其不適合需要最新知識或快速適應變化上下文的任務。
— LLMs對提示非常敏感,特別是對抗性提示 [262],這觸發了新的評估和算法以提高其魯棒性。
6.2. Benchmark and Evaluation Protocol

隨著LLMs的快速發展和廣泛使用,在實際應用和研究中評估它們的重要性變得至關重要。這個評估過程不僅應包括任務級別的評估,還應深入理解它們從社會角度可能帶來的潛在風險。在本節中,我們在表8中總結了現有的基準和協議。首先,從客觀計算轉向人類參與的測試,讓評估過程中更多地融入人類反饋。AdaVision [50]是一個測試視覺模型的交互過程,允許用戶標記少量數據以驗證模型的正確性,從而幫助用戶識別和修復一致的失敗模式。在AdaTest [164]中,用戶通過僅選擇高質量測試并將其組織成語義相關的主題來篩選測試樣本。其次,從靜態到眾包測試集的轉變越來越普遍。工具如DynaBench [94]、DynaBoard [132]和DynaTask [188]依賴眾包工人創建和測試難題。此外,DynamicTempLAMA [135]允許動態構建與時間相關的測試。第三,從統一設置到挑戰性設置來評估機器學習模型。雖然統一設置涉及沒有偏好任何特定任務的測試集,但挑戰性設置為特定任務創建測試集。像DeepTest [190]這樣的工具使用種子生成輸入變換進行測試,CheckList [165]基于模板構建測試集,而AdaFilter [157]對抗性地構建測試。然而,值得注意的是,AdaFilter可能并不完全公平,因為它依賴于對抗性示例。HELM [114]從不同方面評估LLMs,而Big-Bench [182]平臺用于設計機器學習模型解決的困難任務。PromptBench [262]旨在通過創建對抗性提示評估LLMs的對抗性魯棒性,這更具挑戰性,結果表明當前的LLMs對對抗性提示不夠魯棒。
7. GRAND CHALLENGES AND OPPORTUNITIES FOR FUTURE RESEARCH
評估作為新的學科: 我們對評估現狀的總結激發了我們重新設計與LLMs相關評估的各個方面。在本節中,我們提出了幾個重大挑戰。我們的關鍵觀點是,評估應被視為推動LLMs和其他AI模型成功的一個重要學科。現有的評估協議不足以全面評估LLMs的真實能力,這給LLMs評估的未來研究帶來了重大挑戰和新機遇。
7.1. Designing AGI Benchmarks
正如我們之前討論的,盡管所有任務都可能作為LLMs的評估工具,但問題在于哪些任務可以真正衡量AGI的能力。隨著我們期望LLMs展示AGI的能力,理解人類和AGI能力之間的差異對于創建AGI基準至關重要。當前的趨勢似乎將AGI概念化為超人實體,因此利用教育、心理學和社會科學等跨學科知識來設計創新的基準。然而,仍有許多未解決的問題。例如,使用人類價值作為測試構建的起點是否有意義,還是應該考慮其他視角?開發合適的AGI基準提出了許多需要進一步探索的開放問題。
7.2. Complete Behavioral Evaluation
理想的AGI評估不僅應包含常見任務的標準基準,還應包括開放任務的評估,如完整的行為測試。通過行為測試,我們指的是AGI模型應在開放環境中進行評估。例如,通過將LLMs視為中央控制器,我們可以構建由LLMs操縱的機器人評估其在實際情況下的行為。將LLMs視為完全智能機器,其多模態維度的評估也應被考慮。實際上,完整的行為評估是標準AGI基準的補充,它們應協同工作以實現更好的測試。
7.3. Robustness Evaluation
除了通用任務外,對于LLMs來說,保持對各種輸入的魯棒性至關重要,以便在日常生活中的廣泛集成中表現最佳。例如,相同的提示但不同的語法和表達方式可能導致ChatGPT和其他LLMs生成不同的結果,這表明當前的LLMs對輸入不夠魯棒。盡管已有一些關于魯棒性評估的先前工作 [206, 262],但仍有很大進展空間,如包括更多樣化的評估集,檢查更多評估方面,以及開發更高效的評估以生成魯棒性任務。同時,魯棒性的概念和定義在不斷發展。因此,考慮更新評估系統以更好地符合新興的倫理和偏見要求是至關重要的。
7.4. Dynamic and Evolving Evaluation
現有的大多數AI任務評估協議依賴于靜態和公共基準,即評估數據集和協議通常是公開的。雖然這促進了社區內的快速和方便的評估,但無法準確評估LLMs不斷發展的能力,鑒于其快速發展的速度。LLMs的能力可能隨著時間的推移而增強,這不能通過現有的靜態基準持續評估。另一方面,隨著LLMs的模型尺寸和訓練集規模不斷增大,靜態和公共基準可能會被LLMs記住,導致潛在的訓練數據污染。因此,開發動態和進化評估系統是提供公平評估LLMs的關鍵。
7.5. Principled and Trustworthy Evaluation
在引入評估系統時,確保其完整性和可信賴性至關重要。因此,可信賴計算的必要性也延伸到可靠評估系統的需求。這提出了一個將測量理論、概率等多個領域交織在一起的挑戰性研究問題。例如,我們如何確保動態測試真正生成分布外樣本?在這個領域的研究很少,希望未來的工作不僅能審查算法,還能審查評估系統本身。
7.6. Unified Evaluation that Supports All LLMs Tasks
LLMs有許多其他研究領域,我們需要開發能支持各種任務的評估系統,如價值對齊、安全性、驗證、跨學科研究、微調等。例如,PandaLM [216] 是一個通過提供開源評估模型來協助LLMs微調的評估系統,可以自動評估微調的性能。我們期望更多的評估系統變得更加通用,并可以用作特定LLMs任務的輔助。
7.7. Beyond Evaluation: LLMs Enhancement
最終,評估并不是最終目標,而是起點。在評估之后,必然會有關于性能、魯棒性、穩定性等方面的結論。一個高效的評估系統不僅應提供基準結果,還應提供深刻的分析、建議和未來研究與發展的指導。例如,PromptBench [262]不僅提供了對抗性提示的魯棒性評估結果,還通過注意力可視化進行了全面分析,闡明了對抗性文本如何導致錯誤響應。該系統還提供了詞頻分析,以識別測試集中魯棒和非魯棒的詞,從而為終端用戶提供提示工程指導。后續研究可以利用這些發現來提升LLMs。另一個例子是,Wang等人 [215]首先探索了大規模視覺語言模型在不平衡(長尾)任務中的表現,這表明了當前大模型的局限性。然后,他們探索了不同的方法來提高這些任務的性能。總之,評估后的提升有助于構建更好的LLMs,并且在未來還有很多工作可以做。
8. CONCLUSION
評估在推動AI模型,尤其是大語言模型(LLMs)的發展中具有深遠意義,變得不可或缺。本文首次全面概述了LLMs評估的三個方面:評估什么、如何評估和在哪里評估。通過總結評估任務、協議和基準,我們的目的是增強對當前LLMs狀況的理解,闡明其優點和局限性,并為未來LLMs的發展提供見解。
我們的調查顯示,當前的LLMs在許多任務中表現出一定的局限性,特別是在推理和魯棒性任務中。同時,現代評估系統需要適應和發展,以確保準確評估LLMs的內在能力和局限性。我們識別了未來研究需要解決的幾個重大挑戰,希望LLMs能夠逐步增強其對人類的服務能力。
)
)







)


![[python][Anaconda]使用jupyter打開F盤或其他盤文件](http://pic.xiahunao.cn/[python][Anaconda]使用jupyter打開F盤或其他盤文件)
![[Day 22] 區塊鏈與人工智能的聯動應用:理論、技術與實踐](http://pic.xiahunao.cn/[Day 22] 區塊鏈與人工智能的聯動應用:理論、技術與實踐)





】)