前言:
💞💞大家好,我是書生?,今天主要和大家分享一下拉鏈表的原理以及使用,希望對大家有所幫助。 大家可以關注我下方的鏈接更多優質文章供學習參考。
💞💞代碼是你的畫筆,創新是你的畫布,用它們繪出屬于你的精彩世界,不斷挑戰,無限可能!
個人主頁?: 書生?
gitee主頁🙋?♂:閑客
專欄主頁💞:大數據開發
博客領域💥:大數據開發,java編程,前端,算法,Python
寫作風格💞:超前知識點,干貨,思路講解,通俗易懂
支持博主💖:關注?,點贊、收藏?、留言💬
目錄
- 1. 引言
- 2. 什么是拉鏈表
- 3. 拉鏈表的基本原理
- 3.1 基本原理描述
- 3.2 拉鏈表原理詳解
- 3.2.1 全量導入
- 3.2.2 增量導入
- 4 . 拉鏈表的應用場景
- 5. 拉鏈表的優化策略
- 6. 實現方式
1. 引言
??在大數據和數據庫領域,拉鏈表(Slowly Changing Dimension, SCD)是一種常用的數據處理技術,用于處理維度表中緩慢變化的數據。拉鏈表通過記錄數據的歷史狀態,實現了對數據變化的高效追蹤和查詢。本文將詳細介紹拉鏈表的基本原理、應用場景以及優化策略。

2. 什么是拉鏈表
??拉鏈表是針對數據倉庫設計中表存儲數據的方式而定義的一種數據模型,主要用于記錄數據變更歷史。
- 定義:
拉鏈表是一種用于記錄數據變更歷史的表結構,它記錄了事物從開始到當前狀態的所有變化信息。
通過記錄數據的創建時間、更新時間等字段,可以方便地查詢數據變更歷史。
- 結構特點:
拉鏈表中的每個記錄通常包含字段如創建時間(create_time)、更新時間(update_time)、數據本身(如order_id、user_id等)以及可能的操作者信息等。
為了更好地跟蹤數據變化,有些拉鏈表設計會包含起始時間(start_time)和結束時間(end_time)字段,用于標識數據的有效期。
案例:
1 . 假設有一個訂單表,每天都會有新的訂單產生或已有訂單的狀態發生變化。
2. 通過監聽訂單表的變化(如使用Canal等工具),可以捕獲每天的訂單變更數據。
3. 將這些變更數據合并到拉鏈表中,形成訂單的歷史記錄。
4. 通過查詢拉鏈表,可以方便地獲取某個訂單從創建到當前的所有狀態變化信息。
3. 拉鏈表的基本原理
3.1 基本原理描述
??拉鏈表的核心思想是將數據表中的每一行記錄都視為一個版本,通過添加額外的字段(如有效開始日期和有效結束日期)來標識該版本數據的有效期。當數據發生變化時,不是直接修改原數據,而是插入一條新的記錄,并將原記錄的有效結束日期設置為當前時間戳,新記錄的有效開始日期也設置為當前時間戳
這樣,通過查詢有效開始日期和有效結束日期在指定范圍內的記錄,就可以獲取到指定時間點的數據狀態。
拉鏈表操作步驟一般分為兩部分:
- 全量導入(僅限于第一次)
- 增量導入(對于被修改以及新增的數據)
3.2 拉鏈表原理詳解
原理詳解假設第一次導入,之前數倉中沒有人任何數據的,因此我們的原理詳解包括 全量導入 和 增量導入。
注意:
我們一般導入都是導入前一天的數據
原始輸入表:
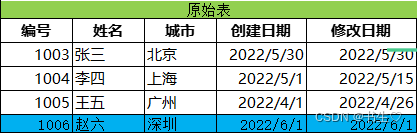
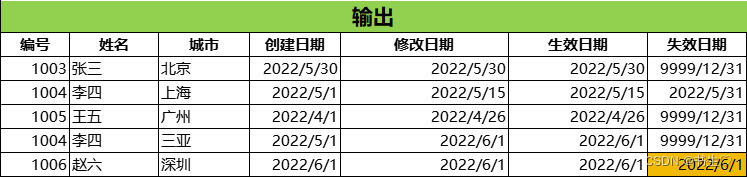
我們要的結果表:大家對比一下有什么不一樣?
- 我們新增了兩條數據,一個是修改的一個是我們新增的數據
- 我們原本被修改數據的失效日期變為了失效當天的日期
3.2.1 全量導入
??假設我們現在有這么一個mysql數據。我們第一次導入需要全部導入到我們的數倉的ods層。
原始表創建語句:
-- 在mysql中創建庫和表
DROP DATABASE IF EXISTS db_1_mysql;CREATE DATABASE db_1_mysqlDEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;USE db_1_mysql;CREATE TABLE db_1_mysql.tb_user
(id int,name varchar(32),address varchar(32),create_date date,update_date date
);INSERT INTO tb_user VALUE (1003, '張三', '北京', '2022-05-30', '2022-05-30');
INSERT INTO tb_user VALUE (1004, '李四', '上海', '2022-05-01', '2022-05-15');
INSERT INTO tb_user VALUE (1005, '王五', '廣州', '2022-04-01', '2022-04-26');
INSERT INTO tb_user VALUE (1006, '趙六', '深圳', '2022-06-01', '2022-06-01');SELECT *
FROM tb_user;
數倉 ods層和dwd層建表
-- 在hive中創建庫和表
drop database if exists db_ods cascade;
create database db_ods;use db_ods;drop table tb_user_ods;-- truncate table db_ods.tb_user_ods;create table db_ods.tb_user_ods
(id int,name string,address string,create_date string,update_date string
)partitioned by (dt string)row format delimited fields terminated by '\t';desc formatted tb_user_ods;drop database if exists db_dwd cascade;
create database db_dwd;create table db_dwd.tb_user_dwd
(id int,name string,address string,create_date string,update_date string,end_date string
)partitioned by (start_date string)row format delimited fields terminated by '\t'
;create table db_dwd.tb_user_dwd_temp
(id int,name string,address string,create_date string,update_date string,end_date string
)partitioned by (start_date string)row format delimited fields terminated by '\t'
;注意:
我們將dwd層的表成為拉鏈表,也就是說我們要將數據通過嗎,mysql導入到ods中在插入到dwd的拉鏈表中。
我們的全量導入是不包括今天的數據的,因此我們導入的時候要篩選一下(我們假設今天是2022-06-01)因此我們要選出今天之前的數據導入
我們導入到ods層是通過Datax導入的,具體的導入方法,大家可以看我的關于Datax使用的博客。
篩選的條件
SELECT *
FROM tb_user
WHERE coalesce(update_date, create_date) < '2022-06-01';
原始輸入表:
將數據從mysql通過Data X導入到ods層中(分區為處理的前一天)
WHERE coalesce(update_date, create_date) < '2022-06-01'
導入到ods層的數據

我們第一次的全量導入,導入到ods層之后就可以全部導入到我們的dwd層的拉鏈表了。
注意:
我們在插入的時候要指定我們的開始時間和失效時間,因為是第一次導入就說我們現在的數據都是有效的,因此有效日期就是我們的分區日期,至于結束日期,我們的數據都沒有結束因此我們設置為‘9999-99-99’
-- 全量數據插入拉鏈表
insert overwrite table db_dwd.tb_user_dwd partition (start_date)
select id,name,address,create_date,update_date,'9999-99-99' as end_date,dt as start_date
from db_ods.tb_user_ods;

3.2.2 增量導入
前提:假設今天時間是6月2號,處理6月1號的數據(被修改和新增的數據)
假設我們在6月1號。將id為1004的數據進行修改,城市被修改了,那么修改日期也要變,并且新增了一條數據(我表中標為藍色的部分)
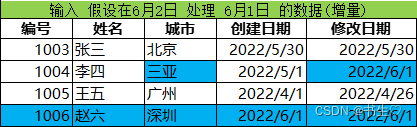
這里是MySQL的數據修改,我們還要將數據導入到ods中。
并且,我們導入的數據只是我們在6月1號修改的,所以需要篩選一下。
WHERE coalesce(update_date, create_date) = '2022-06-01'
我們通過查看 分區為‘2022-06-01’的數據

我們怎么將原本數據進行修改呢?hiv SQL是不支持行級修改的。
此時我們就要通過引入一個拉鏈表的臨時表,進行修改數據后的存儲。
我們將我們原本的拉鏈表與我們新增的數據進行左關聯
select *
from db_dwd.tb_user_dwd aleft join (select *from db_ods.tb_user_odswhere dt = '2022-06-01') b on a.id = b.id;

我們關聯之后的表就是上面這個圖這個樣子。
我們怎么修改數據,由圖可以看見我們關聯上的數據是不為空的,因此我們直接,將失效日期變為修改日期-1
關聯的條件是什么?
如果(b.id is null or a.失效日期!=‘9999-12-31’, a.失效日期,上一天日期-1(dt-1))
if(b.id is null or (b.id is not null and a.end_date != '9999-99-99'), a.end_date,date_add('2022-06-01', -1)) as end_date,
我們將這個數據插入到我們的拉鏈表的臨時表中
-- 臨時表插入數據,拉鏈表關聯篩選出來的
insert overwrite table db_dwd.tb_user_dwd_temp partition (start_date)
select a.id,a.name,a.address,a.create_date,a.update_date,if(b.id is null or (b.id is not null and a.end_date != '9999-99-99'), a.end_date,date_add('2022-06-01', -1)) as end_date,a.start_date
from db_dwd.tb_user_dwd aleft join (select *from db_ods.tb_user_odswhere dt = '2022-06-01') b on a.id = b.id;

此時我們的臨時表存儲的數據就是我們原始數據被修改之后數據了。
我們只需要將新增的數據也插入到臨時表中就可以了。
--- 將新增的直接插入進來
insert into db_dwd.tb_user_dwd_temp partition (start_date)
select id,name,address,create_date,update_date,'9999-99-99' as end_date,dt as start_date
from tb_user_ods
where dt = '2022-06-01'
;
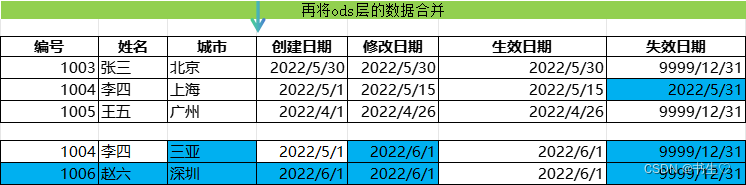
最后我們只需要**將臨時表的數據覆蓋到拉鏈表**中我們的操作就完成了。
這個地方有兩個方法:
- 通過將臨時表的數據覆蓋到拉鏈表
- 先將拉鏈表數據清空,在insert into插入就可以了,不需要覆蓋
insert overwrite table db_dwd.tb_user_dwd partition (start_date)
select id,name,address,create_date,update_date,end_date,start_date
from db_dwd.tb_user_dwd_temp;

注意:
我們在將數據插入到拉鏈表中后,要將臨時表情況,因為下一次增量操作我們還要使用臨時表
4 . 拉鏈表的應用場景
- 數據倉庫:在數據倉庫中,維度表的數據經常會發生變化,如客戶信息的更新、產品屬性的修改等。使用拉鏈表可以方便地追蹤這些變化,并生成歷史報表。
- 數據分析:在數據分析中,經常需要比較不同時間點的數據狀態,以發現數據的變化趨勢。拉鏈表可以方便地提供這種比較功能。
- 實時數據監控:在實時數據監控系統中,需要實時反映數據的最新狀態。通過定期更新拉鏈表,可以實時獲取數據的最新狀態,并進行相應的處理。
5. 拉鏈表的優化策略
- 索引優化:為了提高查詢效率,可以為拉鏈表的關鍵字段(如主鍵、有效開始日期和有效結束日期)建立索引。這樣可以加快查詢速度,提高系統的響應能力。
- 數據壓縮:由于拉鏈表會記錄數據的多個版本,因此可能會占用較多的存儲空間。為了節省存儲空間,可以采用數據壓縮技術對拉鏈表進行壓縮。常用的壓縮算法包括gzip、snappy等。
- 分區存儲:對于數據量較大的拉鏈表,可以采用分區存儲的方式將數據分散到多個物理存儲設備上。這樣可以提高數據的讀寫性能,并降低單點故障的風險。
- 定期清理:隨著時間的推移,拉鏈表中的歷史數據可能會變得不再重要。為了節省存儲空間和提高查詢效率,可以定期清理這些不再重要的歷史數據。清理策略可以根據業務需求和數據保留期限來制定。
6. 實現方式
拉鏈表的實現通常涉及到數據的增量抽取、轉換和加載(ETL)過程。
在數據倉庫中,可以通過ETL工具對操作型數據庫按照時間字段增量抽取數據,形成每天的增量數據,并合并到拉鏈表中。







)

)









