一、貪心問題
貪心算法
貪心算法(greedy algorithm),是用計算機來模擬一個「貪心」的人做出決策的過程。這個人十分貪婪,每一步行動總是按某種指標選取最優的操作。而且他目光短淺,總是只看眼前,并不考慮以后可能造成的影響。
可想而知,并不是所有的時候貪心法都能獲得最優解,所以一般使用貪心法的時候,都要確保自己能證明其正確性。
適用范圍
貪心算法在有最優子結構的問題中尤為有效。最優子結構的意思是問題能夠分解成子問題來解決,子問題的最優解能遞推到最終問題的最優解。
證明
貪心算法有兩種證明方法:反證法和歸納法。一般情況下,一道題只會用到其中的一種方法來證明。
1.反證法:如果交換方案中任意兩個元素/相鄰的兩個元素后,答案不會變得更好,那么可以推定目前的解已經是最優解了。
2.歸納法:先算得出邊界情況(例如?)的最優解?,然后再證明:對于每個情況都可以由結論推導出結果。
常見題型
在OJ的問題中,最常見的貪心有兩種。
1.「我們將 XXX 按照某某順序排序,然后按某種順序(例如從小到大)選擇。」。
2.「我們每次都取 XXX 中最大/小的東西,并更新 XXX。」(有時「XXX 中最大/小的東西」可以優化,比如用優先隊列維護)
二者的區別在于一種是離線的,先處理后選擇;一種是在線的,邊處理邊選擇。
排序解法
用排序法常見的情況是輸入一個包含幾個(一般一到兩個)權值的數組,通過排序然后遍歷模擬計算的方法求出最優值。
后悔解法
思路是無論當前的選項是否最優都接受,然后進行比較,如果選擇之后不是最優了,則反悔,舍棄掉這個選項;否則,正式接受。如此往復。
貪心算法與動態規劃的區別
貪心算法與動態規劃的不同在于它對每個子問題的解決方案都做出選擇,不能回退。動態規劃則會保存以前的運算結果,并根據以前的結果對當前進行選擇,有回退功能。
二、POJ1700 Function Run Fun
2.1問題描述
問題截圖

圖2.1 問題截圖
輸入
輸入的第一行包含一個整數T(1<=T<=20),即測試用例的數量。然后是T病例。每個案例的第一行包含N,第二行包含N個整數,給出每個人過河的時間。每個案例前面都有一個空行。不會超過1000人,沒有人會超過100秒才能穿越。
輸出
對于每個測試用例,打印一行,其中包含所有 N 人過河所需的總秒數。
2.2解題思路
題解
在解決這道過河問題時,我們可以使用貪心算法來最小化總時間。首先,將所有人的過河速度存儲在一個數組中,并對其進行排序。接著,我們考慮以下三種情況:
1.如果還有4個或更多的人未過河,我們選擇最快的人和最慢的人一起過河,然后最快的人返回;接著選擇次快的人和第二慢的人一起過河,再讓次快的人返回。重復此過程,直到只剩下3個人或更少。我們取這兩種過河方式(最快帶最慢和次快,或者最快和次快帶最慢和次慢)中所需時間較短的一種。
2.如果剩下3個人未過河,我們讓最快的人帶最慢的人過河,然后最快的人返回,再帶次慢的人過河,最后最快的人再過河。這樣,三個人就能全部過河。
3.如果只剩下1個或2個人未過河,那么他們一定是過河速度最快的人(或其中兩個),他們可以直接過河,無需再考慮時間。
算法設計路線
這里首先讀取測試用例的數量,然后依次處理每個測試用例。對于每個測試用例,讀取人數nPeople和每個人的過橋時間arrTimes。將過橋時間數組進行排序,使得過橋時間從小到大排列。這樣可以方便后續的貪心策略應用。從后往前處理每個人的過橋時間,采用貪心策略選擇最優的過橋方案:對于當前的最大時間的兩個人(arrTimes[nIndex]和arrTimes[nIndex-1]),比較兩種策略:最快的兩個人帶最慢的一個人過橋,最快的人返回,然后再帶一個最慢的人過橋,最快的人再次返回。最快的一個人帶次慢的人過橋,次慢的人返回,然后再帶兩個人過橋,最快的人返回。比較這兩種策略的時間,選擇其中較小的方案并累計到總時間nTotalTime。最后,處理剩余的情況(即人數少于等于3的情況):如果剩余3個人,直接累加這3個人的過橋時間。如果剩余2個人,累加這2個人的過橋時間。如果只剩1個人,累加這個人的過橋時間。輸出當前測試用例的最短過橋總時間。通過上述步驟,算法在每個測試用例中選擇最優的過橋方案,確保總時間最短。
2.3 C++源代碼
#include <iostream>
#include <algorithm>using namespace std;int main()
{int nTestCases, nPeople, arrTimes[1001], nIndex, nTotalTime;// 讀取測試用例的數量cin >> nTestCases;while (nTestCases--){// 讀取每個測試用例中的人數cin >> nPeople;nTotalTime = 0;// 讀取每個人的過橋時間for (nIndex = 0; nIndex < nPeople; nIndex++)cin >> arrTimes[nIndex];// 對過橋時間進行排序sort(arrTimes, arrTimes + nPeople);// 計算總時間for (nIndex = nPeople - 1; nIndex > 2; nIndex -= 2)// 比較兩種過橋方案的時間并選擇最優方案if (arrTimes[0] + 2 * arrTimes[1] + arrTimes[nIndex] > 2 * arrTimes[0] + arrTimes[nIndex - 1] + arrTimes[nIndex])nTotalTime += 2 * arrTimes[0] + arrTimes[nIndex - 1] + arrTimes[nIndex];elsenTotalTime += arrTimes[0] + 2 * arrTimes[1] + arrTimes[nIndex];// 處理剩余的情況if (nIndex == 2)nTotalTime += arrTimes[0] + arrTimes[1] + arrTimes[2];else if (nIndex == 1)nTotalTime += arrTimes[1];elsenTotalTime += arrTimes[0];// 輸出結果cout << nTotalTime << endl;}return 0;
}
正確結題截圖
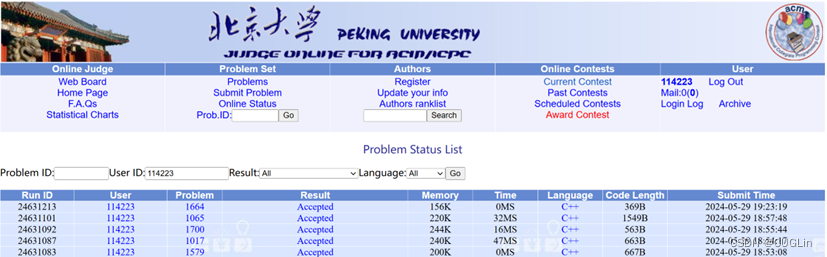
圖2.2 正確解題截圖
2.4復雜度分析
時間復雜度
1.讀取輸入:讀取測試用例的數量和每個測試用例中的人數及其過橋時間需要O(n)的時間,其中n是測試用例中的人數。
2.排序:對每個測試用例中的過橋時間進行排序,使用了快速排序算法sort(arrTimes,arrTimes+nPeople),其平均時間復雜度為O(nlogn)。
3.計算總時間:在循環中處理每個過橋策略時,最多會進行n/2次迭代(因為每次迭代處理兩個人)。每次迭代中的操作都是O(1)時間復雜度。因此,這部分的時間復雜度為O(n)。
4.處理剩余的情況:這部分處理的操作也是O(1)時間復雜度。
5.輸出結果:輸出結果需要O(1)時間復雜度。
綜上所述,對于每個測試用例,主要的時間復雜度由排序過程決定,因此總的時間復雜度為O(nlogn)。假設有m個測試用例,則總的時間復雜度為O(m*nlogn)。
空間復雜度
1.空間使用:需要一個數組arrTimes來存儲每個測試用例中的過橋時間,數組的大小為1001。其它變量如nTestCases、nPeople、nIndex和nTotalTime都是常數級的空間。
2.空間復雜度:因此,總的空間復雜度為O(1),因為無論測試用例數量和人數多少,空間需求都是固定的(數組大小固定為1001,且所有變量都是常數級別)。
綜上所述,空間復雜度為O(1)。
三、POJ1017 Packets
3.1問題描述
問題截圖

圖3.1 問題截圖
輸入
輸入文件由指定訂單的幾行組成。每行指定一個訂單。順序由六個整數描述,用一個空格分隔,依次表示從最小尺寸 1*1 到最大尺寸 6*6 的單個大小的數據包數。輸入文件的末尾由包含六個零的行表示。
輸出
輸出文件包含輸入文件中每行的一行。此行包含可以將輸入文件相應行的訂單打包到的最小包裹數量。輸出文件中沒有與輸入文件的最后一行“null”對應的行。
3.2解題思路
題解
針對這道問題,我們可以優化邏輯來確保在裝箱過程中最大化地利用空間,并且按照箱子規格從大到小的順序進行貪心裝箱。首先將所有箱子按照規格從大到小進行排序,例如先處理6x6、5x5、4x4的箱子,然后是3x3、2x2和1x1的箱子。對于6x6的箱子,因為只能裝一個且全占滿,所以直接用一個新箱子裝一個6x6的箱子。對于5x5的箱子,同樣用一個新箱子裝一個5x5的箱子,然后檢查是否可以裝入1x1的箱子。對于4x4的箱子,同樣先用新箱子裝一個4x4的箱子,然后盡可能多地裝入1x1或2x2的箱子。對于每個3x3的箱子,考慮放入已有箱子中的剩余空間或者使用新箱子。如果使用新箱子,則根據剩余空間可以裝入的2x2箱子數量(0, 1, 3, 5)來確定是裝4個、3個、2個還是1個3x3的箱子。如果將3x3的箱子放入已有箱子,則檢查剩余空間并盡可能多地裝入1x1或2x2的箱子。優先將2x2和1x1的箱子放入前面步驟中留下的剩余空間中。如果剩余空間不足以裝下一個完整的2x2或1x1箱子,則使用新箱子來裝它們。在裝入箱子時,要始終保持記錄哪些箱子有剩余空間以及剩余空間的大小。當有多個箱子可選時(例如,一個已有箱子剩余空間可以裝一個2x2或兩個1x1),優先選擇能裝入更大規格箱子的箱子,以最大化空間利用。計算出所有箱子被裝入后所需的總箱子數。最終輸出總箱子數作為結果。
通過上述步驟,我們可以確保在裝箱過程中最大化地利用了空間,并且按照箱子規格從大到小的順序進行了貪心裝箱,這樣可以有效地減少所需的總箱子數。
算法設計路線
這個算法的目的是計算所需的最少箱子數量,以便能夠裝下所有規格的箱子。每種規格的箱子都有固定的體積和占用空間。算法通過貪心策略逐步計算出所需的最少箱子數量。具體步驟如下:讀取各規格箱子的數量:1x1, 2x2, 3x3, 4x4, 5x5, 6x6。如果所有箱子的數量都是0,則結束輸入循環。將所有6x6, 5x5, 4x4箱子單獨裝箱。計算裝3x3箱子的最少箱子數量,每4個3x3箱子需要一個箱子,若有剩余則需額外的箱子。每個4x4箱子可以額外裝5個2x2箱子。計算未裝滿的3x3箱子對2x2箱子的影響(每個3x3箱子可影響剩余的2x2箱子空間)。計算是否需要額外的箱子來裝2x2箱子,若需要則增加箱子的數量。計算總箱子數剩余的1x1箱子空間,若需要則增加箱子的數量。輸出當前測試用例的最少箱子數量。
3.3 C++源代碼
#include <iostream>
using namespace std;int main() {int nBoxes1x1, nBoxes2x2, nBoxes3x3, nBoxes4x4, nBoxes5x5, nBoxes6x6; // 各種規格箱子的數量int nRemainingSpace1x1, nRemainingSpace2x2; // 分別為規格1和規格2的箱子剩余的空間int nTotalBoxes; // 所需的箱子總數量while (true) {// 讀取輸入cin >> nBoxes1x1 >> nBoxes2x2 >> nBoxes3x3 >> nBoxes4x4 >> nBoxes5x5 >> nBoxes6x6;// 當所有箱子的數量都為0時,退出循環if (nBoxes1x1 + nBoxes2x2 + nBoxes3x3 + nBoxes4x4 + nBoxes5x5 + nBoxes6x6 == 0) {break;}// 計算所需的箱子總數量nTotalBoxes = nBoxes6x6 + nBoxes4x4 + nBoxes5x5 + (nBoxes3x3 + 3) / 4;// 計算規格為2的箱子剩余空間nRemainingSpace2x2 = nBoxes4x4 * 5; // 規格4的箱子每個還能裝5個規格2的箱子// 判斷規格為3的箱子數量if (nBoxes3x3 % 4 == 3) {nRemainingSpace2x2 += 1;}else if (nBoxes3x3 % 4 == 2) {nRemainingSpace2x2 += 3;}else if (nBoxes3x3 % 4 == 1) {nRemainingSpace2x2 += 5;}// 如果規格1和規格2的箱子仍沒有裝完if (nRemainingSpace2x2 < nBoxes2x2) {nTotalBoxes += ((nBoxes2x2 - nRemainingSpace2x2) + 8) / 9;}// 計算規格1的箱子剩余空間nRemainingSpace1x1 = 36 * nTotalBoxes - 36 * nBoxes6x6 - 25 * nBoxes5x5 - 16 * nBoxes4x4 - 9 * nBoxes3x3 - 4 * nBoxes2x2;if (nRemainingSpace1x1 < nBoxes1x1) {nTotalBoxes += ((nBoxes1x1 - nRemainingSpace1x1) + 35) / 36;}// 輸出所需的箱子總數量cout << nTotalBoxes << endl;}return 0;
}
正確解題截圖
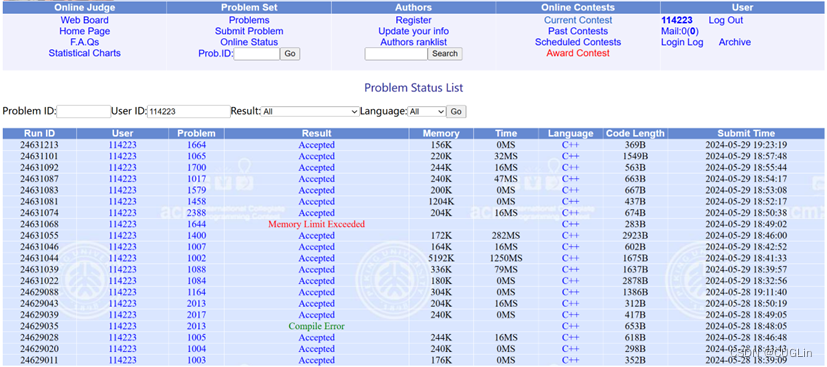
圖3.2 正確解題截圖
3.4復雜度分析
時間復雜度
1.讀取輸入和初始化:O(1)。
2.初步計算箱子數量:O(1)。
3.計算規格2的剩余空間:O(1)。
4.計算需要額外的2x2箱子數量:O(1)。
5.計算規格1的剩余空間:O(1)。
6.輸出結果: O(1)。
綜上所述,每個測試用例的時間復雜度是O(1)。對于 m 個測試用例,總的時間復雜度是O(m)。
空間復雜度
算法只使用了幾個常數級別的變量來存儲輸入和中間結果,如 nBoxes1x1, nBoxes2x2, nBoxes3x3, nRemainingSpace1x1, nRemainingSpace2x2 等。算法不依賴于輸入大小來分配額外的空間。綜上所述,空間復雜度是 O(1)。
四、POJ1065 Wooden Sticks
4.1問題描述
問題描述

圖4.1 問題截圖
輸入
輸入由 T 個測試用例組成。測試用例數 (T) 在輸入文件的第一行中給出。每個測試用例由兩行組成:第一行有一個整數 n , 1 <= n <= 5000 ,表示測試用例中木棍的數量,第二行包含 2n 個正整數 l1 , w1 , l2 , w2 ,..., ln , wn ,每個數量級最多 10000,其中 li 和 wi 是第 i 根木棍的長度和重量, 分別。2n 個整數由一個或多個空格分隔。
輸出
輸出應包含最短設置時間(以分鐘為單位),每行一個。
4.2解題思路
題解
針對這道問題,一個簡單的思路就是根據長度排序,然后找出每一個節點前面的重量小于它的節點,最為一個子序列,在找子序列時,為了不影響到后面節點的子序列,需要找出自己能夠接受的重量最大的工件放在前面,同時標記已經選過的節點,這里用到了一點點的貪心算法,最后用DP數組記錄每一個工件在子序列中的順序。最后只需要統計出每一個子序列中順序為1的個數,就可以找到子序列的個數,子序列的個數就是本題目的答案。
算法設計路線
這里首先讀取每個測試用例中的矩形數量。初始化動態規劃數組和標志數組。讀取每個矩形的長和寬。對矩形數組按照長和寬進行排序。使用雙重循環計算每個矩形的最長遞增子序列長度。內部循環用于查找前一個矩形能否接在當前矩形后面,形成遞增子序列,并更新最長遞增子序列的長度。統計最長遞增子序列的數量。
4.3 C++源代碼
#include <iostream>
#include <algorithm>using namespace std;// 定義節點結構體,表示每個矩形的長和寬
struct SNode
{int nLength; // 矩形的長度int nWidth; // 矩形的寬度SNode(int nL = 0, int nW = 0) : nLength(nL), nWidth(nW) {}
};int anDp[5007]; // 動態規劃數組,用于存儲最長遞增子序列的長度
int nNodesCount; // 矩形的數量
bool abFlag[5007]; // 標志數組,標記哪些矩形已被處理
SNode aNodes[5007]; // 矩形數組// 比較函數,用于排序節點
bool CompareNodes(const SNode& rNodeA, const SNode& rNodeB)
{if (rNodeA.nLength != rNodeB.nLength){return rNodeA.nLength < rNodeB.nLength;}else{return rNodeA.nWidth < rNodeB.nWidth;}
}// 初始化數組
void Initialize()
{for (int nIndex = 0; nIndex <= nNodesCount; nIndex++){anDp[nIndex] = 1; // 初始化每個位置的最長遞增子序列長度為1abFlag[nIndex] = true; // 初始化每個位置的標志為true}
}// 輸入函數
void Input()
{for (int nIndex = 1; nIndex <= nNodesCount; nIndex++){scanf("%d%d", &aNodes[nIndex].nLength, &aNodes[nIndex].nWidth); // 輸入每個矩形的長和寬}sort(aNodes + 1, aNodes + nNodesCount + 1, CompareNodes); // 按照長和寬進行排序
}// 動態規劃函數
void PerformDp()
{int nMaxIdx = -1; // 存儲當前最長遞增子序列的前一個位置int nMaxVal = -1; // 存儲當前最長遞增子序列的前一個位置的寬度值for (int nCurrentIdx = 1; nCurrentIdx <= nNodesCount; nCurrentIdx++){anDp[nCurrentIdx] = 1; // 初始化當前矩形的最長遞增子序列長度為1nMaxIdx = -1; // 初始化最大索引為-1nMaxVal = -1; // 初始化最大值為-1for (int nPrevIdx = nCurrentIdx - 1; nPrevIdx >= 1; nPrevIdx--){// 判斷當前矩形能否接在前一個矩形后面形成遞增子序列if (abFlag[nPrevIdx] && aNodes[nCurrentIdx].nWidth >= aNodes[nPrevIdx].nWidth){// 如果當前前一個矩形的寬度大于最大值或在相同寬度下前一個索引較大,則更新最大值和最大索引if (nMaxVal < aNodes[nPrevIdx].nWidth || (nMaxVal == aNodes[nPrevIdx].nWidth && nMaxIdx < nPrevIdx)){nMaxVal = aNodes[nPrevIdx].nWidth;nMaxIdx = nPrevIdx;}}}// 如果找到有效的前一個矩形,則更新當前矩形的最長遞增子序列長度,并標記前一個矩形為已處理if (nMaxIdx >= 1){anDp[nCurrentIdx] = anDp[nMaxIdx] + 1;abFlag[nMaxIdx] = false;}}
}// 找到結果,即找到最長遞增子序列的長度
int FindResult()
{int nResult = 0; // 初始化結果為0for (int nIndex = 1; nIndex <= nNodesCount; nIndex++){if (anDp[nIndex] == 1) // 統計長度為1的子序列個數{nResult++;}}return nResult; // 返回結果
}int main()
{int nTestCases; // 測試用例數量scanf("%d", &nTestCases);while (nTestCases--){scanf("%d", &nNodesCount); // 輸入每個測試用例中的矩形數量Initialize(); // 初始化數組Input(); // 輸入矩形數據并排序PerformDp(); // 執行動態規劃計算printf("%d\n", FindResult()); // 輸出結果}return 0;
}
正確結題截圖
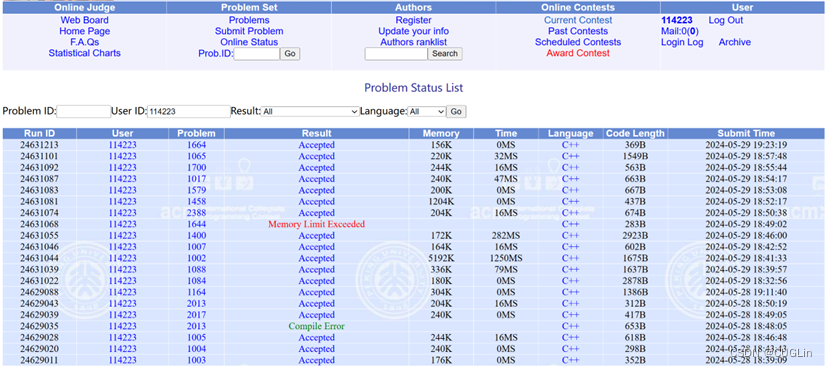
圖4.2 正確解題截圖
4.4復雜度分析
時間復雜度
1.輸入和初始化: O(n)
2.排序: O(n log n)
3.動態規劃計算: O(n^2)
4.統計結果: O(n)
綜上所述,對于每個測試用例,總的時間復雜度為 O(n^2)。
空間復雜度
算法使用了幾個大小為 n 的數組:
1.anDp 數組:存儲每個位置的最長遞增子序列長度。
2.abFlag 數組:標記哪些矩形已被處理。
3.aNodes 數組:存儲矩形的長和寬。
綜上所述,總的空間復雜度為 O(n)。
五、實習小結
經過本次貪心算法的上機實習,我深刻體驗了貪心算法的核心思想和實際應用。在實習過程中,我不僅鞏固了理論知識,還通過編程實踐加深了對貪心算法的理解。
我系統回顧了貪心算法的基本原理,即每一步都選擇當前狀態下的最優解,期望通過這些局部最優解最終導出全局最優解。通過深入學習,我了解到貪心算法的關鍵在于“貪心”的選擇標準,這需要對問題的本質有深刻的理解。
在編程實踐中,我解決了多個經典的貪心算法問題,如活動選擇問題、背包問題的貪心近似解等。這些實踐讓我更加熟悉了貪心算法的實現過程,并鍛煉了我的編程能力。在解決這些問題的過程中,我體會到了貪心算法的優勢和局限性,并學會了如何根據問題的特點選擇合適的貪心策略。
同時,我也意識到了貪心算法在實際應用中的挑戰。有些問題雖然可以使用貪心算法解決,但得到的解可能不是全局最優解。因此,在選擇使用貪心算法時,我們需要對問題的性質進行仔細分析,確保貪心策略的有效性。
此外,在實習過程中,我還注重了代碼的優化和性能分析。我嘗試使用不同的數據結構來存儲中間結果,以減少時間復雜度和空間復雜度。同時,我也對算法的執行效率進行了測試和分析,以找出可能的性能瓶頸。
總的來說,本次貪心算法的上機實習讓我收獲頗豐。我不僅掌握了貪心算法的基本原理和實現方法,還學會了如何將其應用于實際問題中。同時,我也認識到了貪心算法的局限性和挑戰,這將對我未來的學習和工作產生積極的影響。在未來,我將繼續深入學習算法知識,提高自己的編程能力和問題解決能力。


)
)






)








