基于Transformer的語言模型在眾多自然語言處理任務上都取得了十分優異的成績,在一些任務上已經達到SOTA的效果。但是,經過預訓練后,模型能夠較好處理的序列長度就固定下來。而當前的眾多場景往往需要處理很長的上下文(如:大的代碼倉庫、書籍等長文檔的摘要、few-shot等輸入較長的in-context learning場景等等),其長度超過了模型預訓練時使用的長度,無法一次性輸入模型,導致語言模型無法充分利用長輸入中完整的知識,因而性能受到制約。
針對這一問題,研究者們提出了多種檢索的方法,從全部的歷史上文中檢索所需的相關token,放入有限的窗口內計算attention,使得模型能夠利用短的輸入窗口處理長的序列。
方法概述
受預訓練的限制,模型能夠較好處理的序列長度相對固定,通常為2048、4096等等。在不改變attention計算機制的前提下,很難保證在模型能力損失較小的同時,顯著擴展模型能夠處理的上下文長度。并且,在長文本上訓練的代價也很高,直接在長文本上從頭訓練一個窗口長度很長的模型較為困難。于是,我們希望模型能夠在有限的處理窗口中能夠關注長上下文中關鍵的token,獲取其中的信息,從而充分利用長文本中的知識,提升處理長文本的能力。
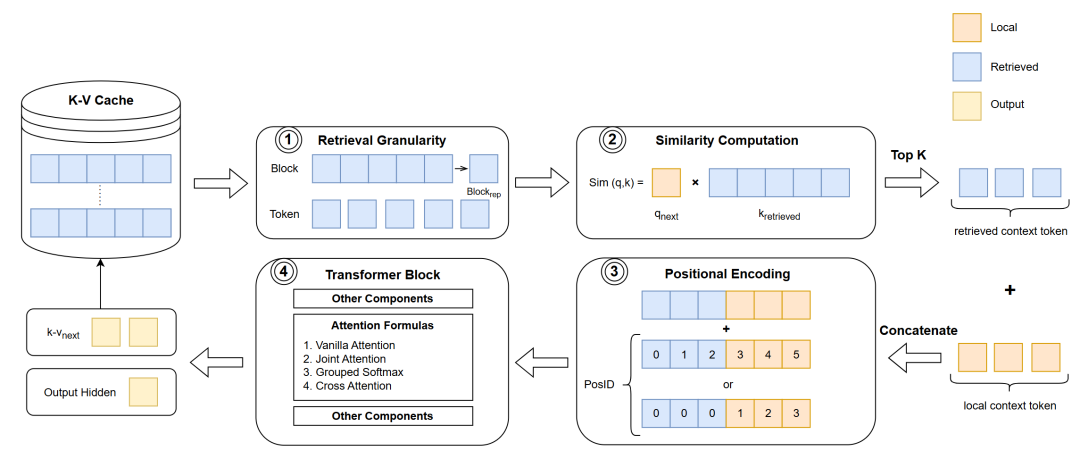
圖1 基于檢索增強的處理流程
眾多研究者提出了基于檢索增強的方法,通過在上下文歷史中查找關鍵token,并將它們放入attention計算中的方式,增強模型在長文本任務上的表現。其大致流程如圖1所示,基本思路是分段處理,通過多次調用短上下文模型來處理長上下文輸入,在此過程中保存K-V Cache供后續分段使用。引入檢索增強技術之后,模型的處理流程如下。首先,模型以不同的檢索粒度從K-V Cache中取出相應的 token 表示。然后,模型計算當前處理的token與這些歷史token的相似度,并根據相似度結果選取最相關的top-k token。檢索到的token會與當前窗口內的上下文拼接在一起,組合成新的上下文,用于當前的輸入。隨后,進行合適的位置編碼。最后,把輸入序列送入模型層,得到當前層的輸出,其中最關鍵的是attention部分。下文將按上述處理順序,對應圖1中的四個關鍵步驟依次介紹。 ## 技術交流&資料
技術要學會分享、交流,不建議閉門造車。一個人可以走的很快、一堆人可以走的更遠。
成立了大模型算法面試和技術交流群,相關資料、技術交流&答疑,均可加我們的交流群獲取,群友已超過2000人,添加時最好的備注方式為:來源+興趣方向,方便找到志同道合的朋友。
方式①、微信搜索公眾號:機器學習社區,后臺回復:加群
方式②、添加微信號:mlc2040,備注:來自CSDN + 技術交流
用通俗易懂的方式講解系列
-
重磅來襲!《大模型面試寶典》(2024版) 發布!
-
重磅來襲!《大模型實戰寶典》(2024版) 發布!
-
用通俗易懂的方式講解:一文講透最熱的大模型開發框架 LangChain
-
用通俗易懂的方式講解:這應該是最全的大模型訓練與微調關鍵技術梳理
-
用通俗易懂的方式講解:大模型訓練過程概述
-
用通俗易懂的方式講解:專補大模型短板的RAG
-
用通俗易懂的方式講解:大模型微調方法總結
-
用通俗易懂的方式講解:掌握大模型這些優化技術,優雅地進行大模型的訓練和推理!
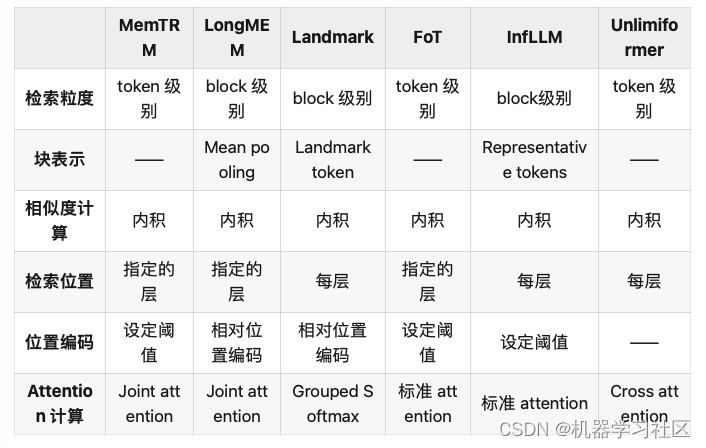
1 檢索粒度與表示
我們首先關注的問題是如何從K-V Cache中檢索與當前處理步驟最相關的一部分token,其中首要的問題是檢索粒度,也就是檢索的基本單元的大小。
最基本的是token級別的檢索。具體來說,是在K-V Cache中逐個token計算與當前待處理的token的相似度,選取相似度最高的top-k token對應的key與value向量作為檢索結果。這類方法的代表有MemTRM[1]、FoT[2]、Unlimiformer[3]等等。
盡管token級別的檢索在實現上相對簡單,但也面臨一些限制。首先,由于檢索到的是離散的token,相鄰的token并不一定能被一并檢索,這可能導致語義上的獨立。其次,每次生成新token時,都需要與K-V Cache中的所有token重新計算相似度,這增加了計算量,檢索效率較低。
為了改進這些缺陷,有研究者提出使用更粗的檢索粒度,把輸入序列分成一個個長度相同的block,在block級別進行檢索。block級別的檢索是在處理每個新的token時,從K-V Cache里以block為單位進行相似度計算,選取top-k block作為檢索結果。block級別的檢索得到是一連串相鄰的token,語義上比離散的token更連貫。另外,由于每次檢索只在block上進行一次相似度計算,大大減少了計算量并且提高了檢索效率。
然而,block級別的檢索也帶來了一個新的問題:如何有效地表示block以完成相似度計算。如圖2所示,為了充分利用block內token的信息,可以按一定規則對block內的token進行信息融合的操作,從而得到block的表示。例如,LongMEM[4]通過計算block內token表示的mean pooling來表示相應的block;而InFLLM[5]則是在block計算每個token與其他token的一種整體相似性指標(representative score),選取其中分數較高的一部分token共同作為block的表示。此外,還有方法引入額外的token來表示block,如Landmark[6]方法中在詞表內添加了一個新的token—Landmark,并將其放置在每個block的末尾作為block的代表,同時這個Landmark token也參與到序列的計算中,通過Grouped Softmax實現層次化的attention機制,我們在后面還會展開闡述Landmark的具體做法。
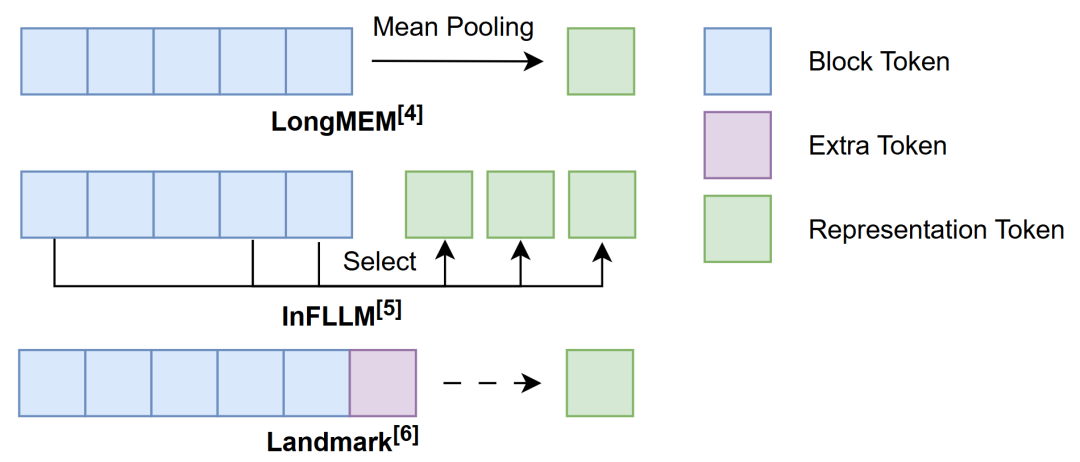
圖2 block的表示
2 相似度計算
在確定檢索粒度后,我們需要建立適當的規則來計算相似度。目前的方法幾乎都采用將當前處理的token的query向量與檢索粒度所代表的key向量進行內積計算作為相似度的標準。這種做法源于標準的attention計算機制,標準attention中所計算的query與key的內積本身就是一種便于計算的相似度,而且相似度越高,相應value的權重就越高。現有的方法充分利用這一特性,計算當前token的query向量與檢索粒度所代表的key向量相似度作為attention貢獻的度量,通過舍棄低貢獻的上下文來節省上下文窗口的可用空間,得到一種attention的有效近似。
3 位置編碼
在完成相似度計算后,我們選擇相似度最高的top-k token作為檢索的結果。我們把這部分來自上下文歷史的token記作retrieved context token,而在當前窗口范圍內的token記為local context token。把這兩類context token拼接在一起,就得到了輸入當前層的完整context token序列。
接下來,在將這一組合的context token輸入到模型進行attention計算之前,需要考慮位置編碼,以區分不同位置token。在檢索方法中,由于retrieved context token的位置不固定,并且在緩存時記錄每個token具體的位置的代價較高,很難給出準確的位置信息。因此,需要找到一個合適的編碼位置的方式來融合一定的位置信息。Sun等人[79]在PG19[8]數據集上的實驗表明,相對位置信息對遠距離的token似乎并不重要。基于此,MemTRM、FoT、InfLLM等方法直接將retrieved context token部分的位置編碼設置成相同的位置向量,忽略了retrieved context token內彼此的位置信息。而另一些方法認為retrieved context token內部的相對順序依然重要,因此為其添加了位置編碼,如LongMEM則是直接使用ALiBi[9]進行相對位置編碼,Landmark方法則將retrieved context token與local context token放在同一窗口內,對它們重新進行相對位置編碼。
4 Attention計算
在進行attention計算時,我們需要考慮如何充分利用由retrieved context token和local context token這兩類token組成的context tokens。
最簡單的處理方法是將兩類token視作同等地位,直接使用常規的attention計算方式。如在FoT與InfLLM中就是使用標準的attention進行計算;在Unlimiformer中則是使用Cross Attention完成相應的計算。
然而,對于當前處理的token來說,這兩類context token包含信息的重要性并不相同。為了充分利用它們的信息,Joint Attention對它們做了一定的區分,分別計算local context與retrieved context中各自的attention。然后,加權得到最終的attention結果,可以概括成以下的公式:
其中,表示最終的attention結果,和 分別表示利用local context和retrieved context計算的attention結果,是一個可學習的參數,用于平衡兩個部分的貢獻。在MemTRM與LongMEM 中均采用了這種方法。
Landmark在此基礎上更進一步。為區分retrieved context token內來自不同位置的信息,Landmark提出使用Grouped Softmax來更細粒度地分配權重。具體來說,該方法首先將Landmark這一類token與local context token放在一起進行softmax計算,從中選出Top-K個相關的block,同時保留softmax的計算結果。然后分別在這些block內單獨計算attention,利用先前計算softmax結果對不同block的attention進行加權,得到最終的attention結果。
5 檢索位置
另外,檢索的實現也是有一定資源的消耗,因此在平衡效率和性能的目標下,不同的方法對檢索時機的選取有所不同。其中,MemTRM、LongMEM、FoT選擇在模型中的某些指定層進行檢索,而Landmark、InfLLM則是在每一層都進行檢索。專用于encoder-decoder架構的方法則是在decoder部分進行檢索,例如Unlimiformer在每個decoder層均進行檢索。
以上就是通過檢索增強處理長文本方法的流程,可以將上述提到方法的各環節大致整理為如下的表格:
表1 上述方法各環節內容
性能對比
上述方法在一些長文本數據集上驗證其語言能力:PG-19[11](英文書籍)、arXiv(數學論文)、C4[10](網絡文檔)、GitHub(代碼)和 Isabelle(定理證明)等等。通常選用PPL作為評價的指標。此外,還涉及一些自然語言理解的任務,如SST-2[11]、MR[12]、Subj[13]、SST-5[11]、MPQA[14]等等。
雖然不同的方法選擇了其中相同的一些數據集或任務進行驗證實驗,但在各自的實驗中,使用的數據集、基線、數據處理、訓練方式等實驗設置不同,導致不同方法即便在相同數據集或任務上的實驗結果也不可比。
總的來說,現有工作各自的實驗結果在一定程度上證明了這些方法處理長文本的有效性,但目前仍然缺乏可以直接用于對比各項工作性能的公開結果。
與檢索增強生成(RAG)技術的對比
雖然通過檢索增強處理長文本的方法和檢索增強生成(Retrieval Augmented Generation,RAG)均用到了檢索,但二者之間還是存在著一定的區別。
首先,二者在檢索對象上存在區別。長文本檢索增強方法是在上下文歷史的表示中檢索,而RAG則側重于在廣泛的外部知識庫中檢索。
其次,這兩類方法在檢索的實現上也有所不同。如前面介紹的內容,長文本檢索增強方法直接利用K-V Cache中的key計算相似度,作為檢索的標準。并將檢索到的(key,value)對直接用于模型后續attention的計算。相比之下,RAG面對龐大的外部知識庫,利用一個獨立的檢索器(retriever)完成檢索。此外,RAG可能還需要額外的組件來確保檢索到的內容與生成的文本之間的一致性。由于這種結構上的復雜性,RAG通常不適用于直接處理長文本。通過上述分析,我們可以看出,雖然兩種方法都涉及檢索過程,但它們在檢索對象和檢索實現上有著不同,各有其適用的場景和限制。
那么,可以考慮采用 RAG 的方法來處理長文本嗎?答案是肯定的。RPT[15]架構正是借鑒了RAG的檢索思路來處理長文本。如圖3所示,其整體流程與前文介紹相似,但每個步驟涉及的對象和處理方式有所區別,下面進行簡要介紹。RPT采用encoder-decoder架構,在decoder階段進行檢索。它參照了RAG的實現,并配備了一個可訓練的檢索器。不同于RAG,RPT僅從encoder的輸出中進行檢索,而不涉及外部知識。具體來說,輸入首先通過encoder處理,得到最后一層的隱層表示,這些表示被存儲下來,構成檢索庫。在decode階段進行Cross Attention計算時,會借助一個額外的檢索器在這個檢索庫中檢索。檢索器首先將encoder的輸出與decoder的輸入通過一個雙向attention層進行對齊,然后計算這兩者對齊后的表示的內積作為相似度評分,最后選擇top-k的表示作為檢索結果。值得注意的是,此處的檢索是在 block-to-block 級別進行,與之前的token-to-token和token-to-block不同。檢索完成后,所得的表示還需通過一個鄰接門控(neighbor gating)機制,參與到最終的Cross Attention的計算中。這里的Cross Attention采用了 RAG 中的一種變體—Chunked Cross Attention[16],這種形式能夠有效學習到上下文的連貫性,從而更準確地預測下文。
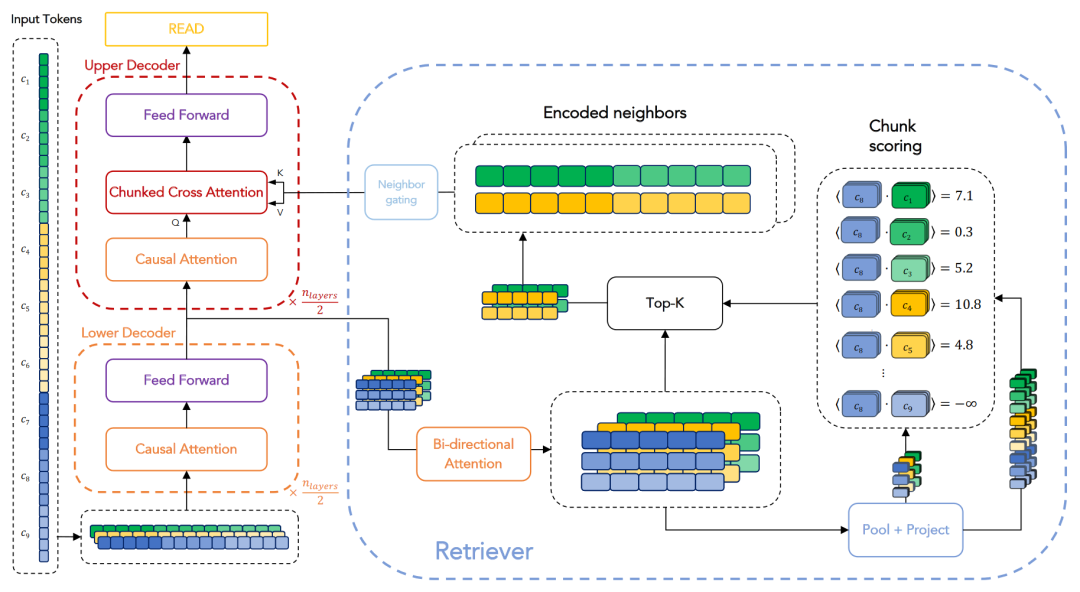
圖3 RPT[15]架構
參考文獻
[1] Wu Y, Rabe M N, Hutchins D L, et al. Memorizing transformers[J]. arXiv preprint arXiv:2203.08913, 2022.
[2] Tworkowski S, Staniszewski K, Pacek M, et al. Focused transformer: Contrastive training for context scaling[J]. Advances in Neural Information Processing Systems, 2024, 36.
[3] Bertsch A, Alon U, Neubig G, et al. Unlimiformer: Long-range transformers with unlimited length input[J]. Advances in Neural Information Processing Systems, 2024, 36.
[4] Wang W, Dong L, Cheng H, et al. Augmenting language models with long-term memory[J]. Advances in Neural Information Processing Systems, 2024, 36.
[5] Xiao C, Zhang P, Han X, et al. InfLLM: Unveiling the Intrinsic Capacity of LLMs for Understanding Extremely Long Sequences with Training-Free Memory[J]. arXiv preprint arXiv:2402.04617, 2024.
[6] Mohtashami A, Jaggi M. Random-access infinite context length for transformers[J]. Advances in Neural Information Processing Systems, 2024, 36.
[7] Dai Z, Yang Z, Yang Y, et al. Transformer-xl: Attentive language models beyond a fixed-length context[J]. arXiv preprint arXiv:1901.02860, 2019.
[8] Rae J W, Potapenko A, Jayakumar S M, et al. Compressive transformers for long-range sequence modelling[J]. arXiv preprint arXiv:1911.05507, 2019.
[9] Press O, Smith N A, Lewis M. Train short, test long: Attention with linear biases enables input length extrapolation[J]. arXiv preprint arXiv:2108.12409, 2021.
[10] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of machine learning research, 2020, 21(140): 1-67.
[11] Socher R, Perelygin A, Wu J, et al. Recursive deep models for semantic compositionality over a sentiment treebank[C]//Proceedings of the 2013 conference on empirical methods in natural language processing. 2013: 1631-1642.
[12] Auer S, Bizer C, Kobilarov G, et al. Dbpedia: A nucleus for a web of open data[C]//international semantic web conference. Berlin, Heidelberg: Springer Berlin Heidelberg, 2007: 722-735.
[13] Pang B, Lee L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts[J]. arXiv preprint cs/0409058, 2004.
[14] Wiebe J, Wilson T, Cardie C. Annotating expressions of opinions and emotions in language[J]. Language resources and evaluation, 2005, 39: 165-210.
[15] Rubin O, Berant J. Long-range language modeling with self-retrieval[J]. arXiv preprint arXiv:2306.13421, 2023.
[16] Borgeaud S, Mensch A, Hoffmann J, et al. Improving language models by retrieving from trillions of tokens[C]//International conference on machine learning. PMLR, 2022: 2206-2240.
)











)





)
