分類問題
分類:根據已知樣本的某些特征,判斷一個新的樣本屬于哪種已知的樣本類
垃圾分類、圖像分類

怎么解決分類問題

分類和回歸的區別

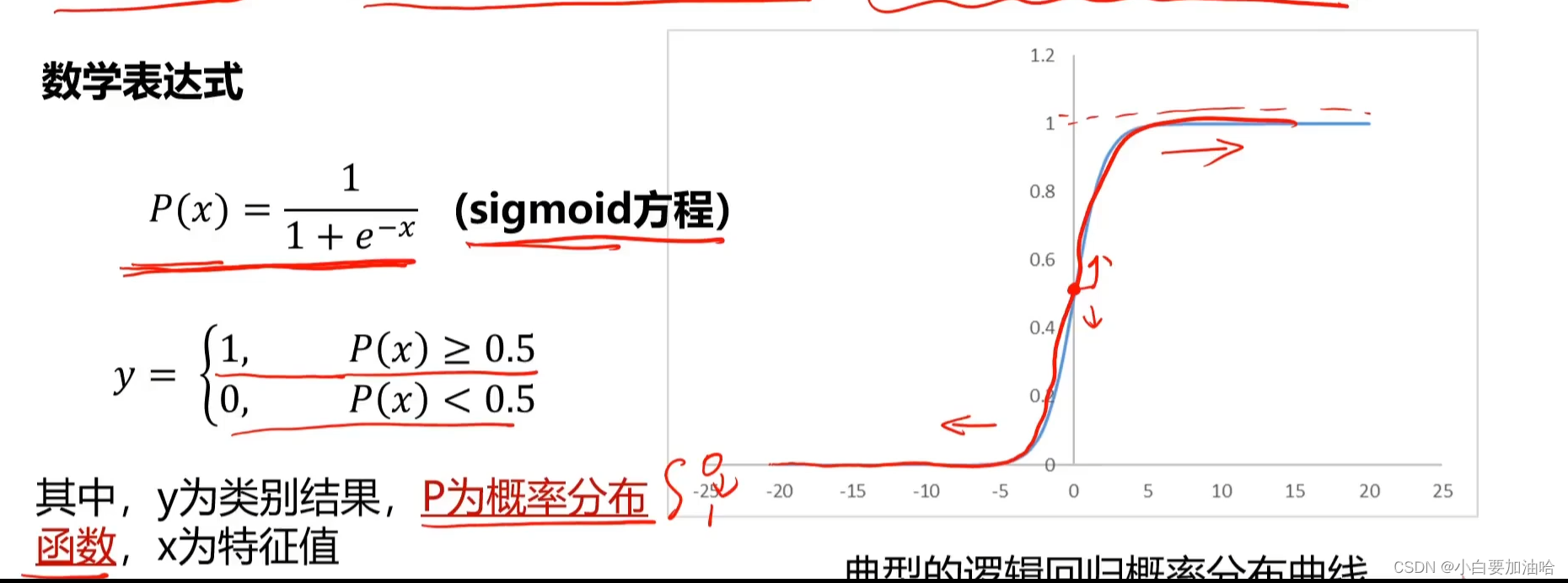
1. 邏輯回歸分類
用于解決分類問題的一種模型。根據數據特征或屬性,計算其歸屬于某一類別
的概率P,根據概率數值判斷其所屬類別。主要應用場景:二分類問題。
1. 談談你對機器學習的理解,包括回歸和分類的相同點和不同點
機器學習是一種通過數據(經驗)和算法讓計算機從中學習并改善系統自身的性能的技術。
回歸和分類的相同點:
預測性質:回歸和分類都是用來預測未知數據的屬性或類別。
監督學習:這兩種任務都屬于監督學習的范疇,即訓練數據集包含了輸入和相應的輸出(標簽)。
使用模型:它們都需要構建一個數學模型,該模型能夠從訓練數據中學習,然后用于對新數據進行預測。
回歸和分類的不同點:
預測目標:
回歸的目標是預測連續型變量的數值,例如房價、溫度等。回歸問題的輸出是一個連續的數值。
分類的目標是預測離散的類別或標簽,例如判斷郵件是否為垃圾郵件、圖片中的物體類別等。分類問題的輸出是一個離散的類別。
輸出類型:
回歸的輸出是連續的實數值,可以是任意范圍內的數字。
分類的輸出是離散的類別,通常是有限的、預定義的標簽集合。
評估指標:
回歸問題通常使用諸如均方誤差(Mean Squared Error, MSE)、均方根誤差(Root Mean Squared Error, RMSE)等連續型指標來評估預測結果的準確性。
分類問題通常使用準確率(Accuracy)、精確率(Precision)、召回率(Recall)等離散型指標來評估模型的性能。
2. 簡述機器學習的流程
抽象實際問題,獲取數據,數據預處理,特征工程,訓練模型及調優,模型評估不斷迭代模型,獲取最終模型
3. 簡述監督學習與無監督學習之間的區別
數據類型:監督學習使用有標簽的數據,無監督學習使用無標簽的數據。
目標:監督學習旨在預測輸出,無監督學習旨在發現數據中的結構和模式。
應用:監督學習用于分類和回歸,無監督學習用于聚類、降維等
4. 數據預處理的過程中,對于異常數據處理的方法有哪些
1.刪除異常值
2.修正異常值
3.數據變換
4.使用離群值檢測算法
5.使用模型
填空題
機器學習
- 機器學習的工作流程:抽象實際問題、獲取數據、數據預處理、特征工程、訓練模型及調優、模型評估、獲取最終模型
- 數據預處理的方法:數據清洗、數據變換、數據過濾
- 特征工程定義:從原始數據中進行特征構建、特征提取、特征選擇
- 數據集分為:訓練集(用于學習的數據集)、驗證集(用來預防過擬合的發生,輔助訓練過程的數據集)、測試集(用于測試和評估訓練好的模型的數據集)
- 機器學習分為:監督學習、半監督學習、無監督學習
- 監督學習:基于標簽訓練數據的機器學習模型的過程
- 半監督學習:使用大量的未標記數據、以及同時使用標記數據,來進行模型識別工作
- 無監督學習:建立及其學習模型的過程不依賴標簽訓練數據
在機器學習中,回歸和分類是兩種基本的任務類型
- 分類:根據數據的屬性或特征是否相似,來把它們歸為一類
- 回歸:評估輸入變量和輸出變量之間關系的過程
回歸和分類的不同點:
預測目標:
回歸的目標是預測連續型變量的數值,例如房價、溫度等。回歸問題的輸出是一個連續的數值。
分類的目標是預測離散的類別或標簽,例如判斷郵件是否為垃圾郵件、圖片中的物體類別等。分類問題的輸出是一個離散的類別。
輸出類型:
回歸的輸出是連續的實數值,可以是任意范圍內的數字。
分類的輸出是離散的類別,通常是有限的、預定義的標簽集合。
評估指標:
回歸問題通常使用諸如均方誤差(Mean Squared Error, MSE)、均方根誤差(Root Mean Squared Error, RMSE)等連續型指標來評估預測結果的準確性。
分類問題通常使用準確率(Accuracy)、精確率(Precision)、召回率(Recall)等離散型指標來評估模型的性能。
課本原話
區別在于輸出變量類型不同,分類的輸出是離散的,回歸的輸出是連續的,分類問題是從不同類型的數據中學習數據的邊界,而回歸問題是從同一類型的數據中學習到這種數據中不同維度間的規律,去擬合真實規律
- 數據清洗的目的:將數據集中的”臟“數據去除
- 臟數據:缺少的數據、異常的數據、重復的數據
- 缺少的數據的處理方法:直接刪去、填充為一個常量、取均值、中位數或使用頻率高的值、插值填充、模型填充
- 異常數據的發現方法:建模法、計算機檢查和人工檢查相結合、聚類、密度法
- 數據變換:對對象的屬性再數值上進行處理,包括規范化、離散化、稀疏化
- sklearn基本功能主要分為:數據預處理、數據降維、模型選擇、分類、回歸、聚類
邏輯回歸分類
邏輯回歸定義:用來解釋輸入變量和輸出變量之間關系的一種技術,主要用于二分類問題
- sigmoid()函數:
線性回歸預測
線性回歸定義:利用數理統計中回歸分析來確定兩種或兩種以上變量間相互依賴的定量關系的一種統計分析方法
聚類(無標紅,非重點)
聚類定義:根據相似性原則,將具有較高相似度的數據對象劃分為同一類簇,將具有較高相異度的數據對象劃分為不同類簇。(無監督學習)
聚類算法:K-Means算法(K均值算法)
- 初始化質點
- 聚類對象
- 更新質點
第4章 自然語言處理(NLP)
-
自然語言處理工具包:NLTK
-
使用stemming、lemmatization還原詞匯
-
詞袋模型:文本特征提取方式
-
文本分析的主要目的之一:把文本轉化為數值
-
分析文檔的步驟:1. 提取文檔 2. 轉換為數值形式
-
使用TF-IDF算法構建文檔類別檢測器
作用:對文檔所屬的類別進行檢測
TF-IDF:是一種用于信息檢索與數據挖掘的常用加權技術
TF-IDF的值是這兩個值的乘積:TF*IDF
TF-IDF主要思想:p113
TF-IDF作用:去除過濾常見的詞語,從而保留重要的詞語 -
主題模型算法不需要任何被標記的數據
-
LDA包括三層結構:詞、主題、文檔(重點)
-
LDA是非監督機器學習
課后習題
列出幾種文本特征提取算法:詞袋模型、TF-IDF、文本主題模型(LDA)
列出幾種自然語言處理開源工具包:NLTK、Gensim、TextBlob
第5章 語言識別
將音頻信號從時域轉換為頻域
- 音頻信號包括:頻率、相位、振幅的正弦波
- 信號的基本性質:時域、頻域
- 時域是唯一實際存在的域,真實世界的,頻域是一個數學構造,正弦波是頻域唯一存在的波形
- 時域的基本變量:時間
- 頻域的基本變量:頻率
- 將音頻信號從時域轉換為頻域:快速傅里葉變換
提取語音特征
- MFCC:用于從給定音頻信號中提取頻域特征
- 只使用低頻MFCC,丟棄中高頻MFCC
- 提取語言特征參數MFCC主要流程:預加重、分幀、加窗、FFT、Mel濾波器組、對數對算、DCT離散余弦變換
課后習題
-
列舉幾個語言識別技術的應用領域:通信、家電、工業、汽車電子、家庭服務、醫療、消費電子產品
-
簡單概述語言識別技術的原理:
先采集并預處理信號,使用數字信號處理技術提取聲音的特征,利用聲學模型和語言模型分析聲音的特征和語言規律,以實現對語音輸入的理解和處理 -
實現音頻信號從時域轉換為頻域:
首先將連續的模擬信號采樣為離散的數字信號。然后,使用傅里葉變換(如快速傅里葉變換)將離散時域信號轉換為頻域信號,以分析信號在不同頻率上的能量分布。
第6章 計算機視覺
視頻中移動物體檢測方法
- 幀間差分法
- 色彩空間
- 背景差分法
差分法的實現
- 視頻采集
- 圖像預處理
- 提取背景
- 二值化
- 獲取前景圖片
第7章 人工神經網絡
- 循環神經網絡基本原理:一個序列當前的輸入與前面的輸出有點聯系,在網絡會記憶前面的信息并計算當前的輸出,隱藏層之間的節點是有連接的,隱藏層的輸入包括輸入層的輸出和上一時刻隱藏層的輸出。
簡答題(概念)
- 機器學習:機器學習是一種通過數據(經驗)和算法讓計算機從中學習并改善系統自身的性能的技術,分為監督學習、半監督學習、無監督學習。
- 人工神經網絡定義:一種模仿人類大腦結構和作用的數學模型,從而模擬人腦神經系統對復雜信息處理。
- 循環神經網絡定義:是對序列數據建模的人工神經網絡,目的是處理序列數據。
- 深度學習定義:是一種精確的分層學習,指在多個計算階段中精確第分配信用,以轉換網絡中的聚合激活,從而由簡單的基礎來學習和分析處理復雜的問題。
- 卷積神經網絡:一種專門用于處理具有網格結構數據的深度學習模型,本質為前饋神經網絡,包括卷積計算且具有深度結構。
- 強化學習:解決智能體在與外部環境交互活動的過程中,能夠通過自身學習策略來應對外部環境問題,從而達到回報效益最大化的狀態。
- 前饋神經網絡:沒有反饋機制,只能向前傳播而不能反向傳播來調整權值參數的神經網絡模型。
- 神經元結構:神經元是ANN中的基本單元,每個神經元接收多個輸入信號(通常包括權重和偏置),對這些輸入信號進行加權求和,然后通過一個激活函數生成輸出。
- 感知器:感知機(Perceptron)是一種最簡單的人工神經網絡模型,通常用于二元分類任務。它由輸入層、權重、偏置、激活函數和輸出層組成
第8章 強化學習和深度學習
- 卷積層的三個參數:核大小、步長、填充
)






)











)