第五章:注意力機制增強(IPCA)
歡迎回到1Prompt1Story🐻???
在第四章中,我們掌握了**語義向量重加權(SVR)**技術,通過語義向量調節實現核心要素強化。
但當場景從"雪地嬉戲"切換至"漿果覓食"時,仍可能出現紅狐頭部畸變或漿果異常附著等問題。這些現象源于AI注意力機制的分散性特征。
智能聚光燈:引導AI視覺焦點
將UNet神經網絡(第六章詳解)的注意力機制類比為畫家的視覺焦點:
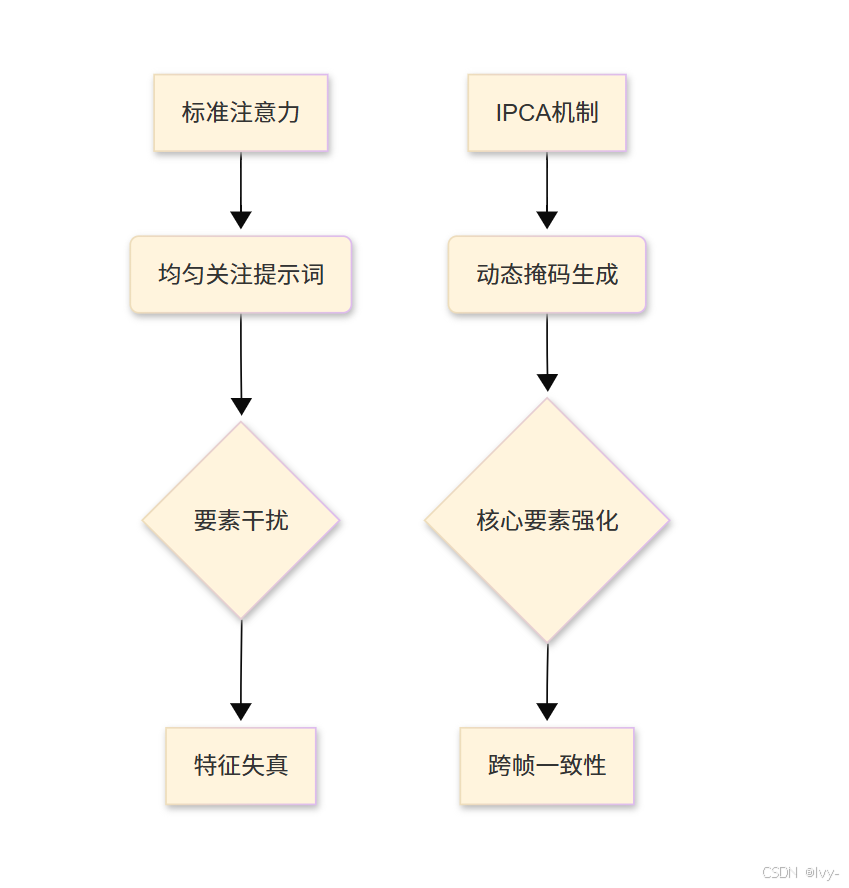
- 常規模式:均勻關注提示詞各要素,易導致
次要元素干擾 - IPCA模式:通過動態掩碼鎖定核心要素,實現注意力定向增強
IPCA啟用方法
通過生成行為控制器配置參數:
# 配置示例(摘自main.py簡化版)
from unet.unet_controller import UNetControllercontroller = UNetController()
controller.Use_ipca = True # 啟用IPCA# 層級作用域配置
controller.Ipca_position = ['down0', 'down1', 'mid', 'up1'] # 指定UNet作用層
controller.Ipca_start_step = 10 # 去噪第10步后啟用# 掩碼參數優化
controller.Use_embeds_mask = True # ID提示區域保護
controller.Ipca_dropout = 0.05 # 非核心區域隨機丟棄率
過擬合
就是模型在訓練數據上表現太好,反而在沒見過的新數據上表現很差,相當于“死記硬背不會靈活應用”。
參數解析表
| 參數 | 功能描述 | 推薦值域 |
|---|---|---|
Ipca_position | 作用網絡層(控制細節粒度) | UNet層級名稱 |
Ipca_start_step | 生效起始步數(防早期過擬合) | 總步長10%-30% |
Use_embeds_mask | 核心區域保護開關 | True/False |
Ipca_dropout | 隨機丟棄率(防過關注) | 0.01-0.1 |
技術實現
核心代碼路徑
IPCA邏輯主要實現在:
unet/unet.py的Attention模塊unet/utils.py的ipca2與ipca函數
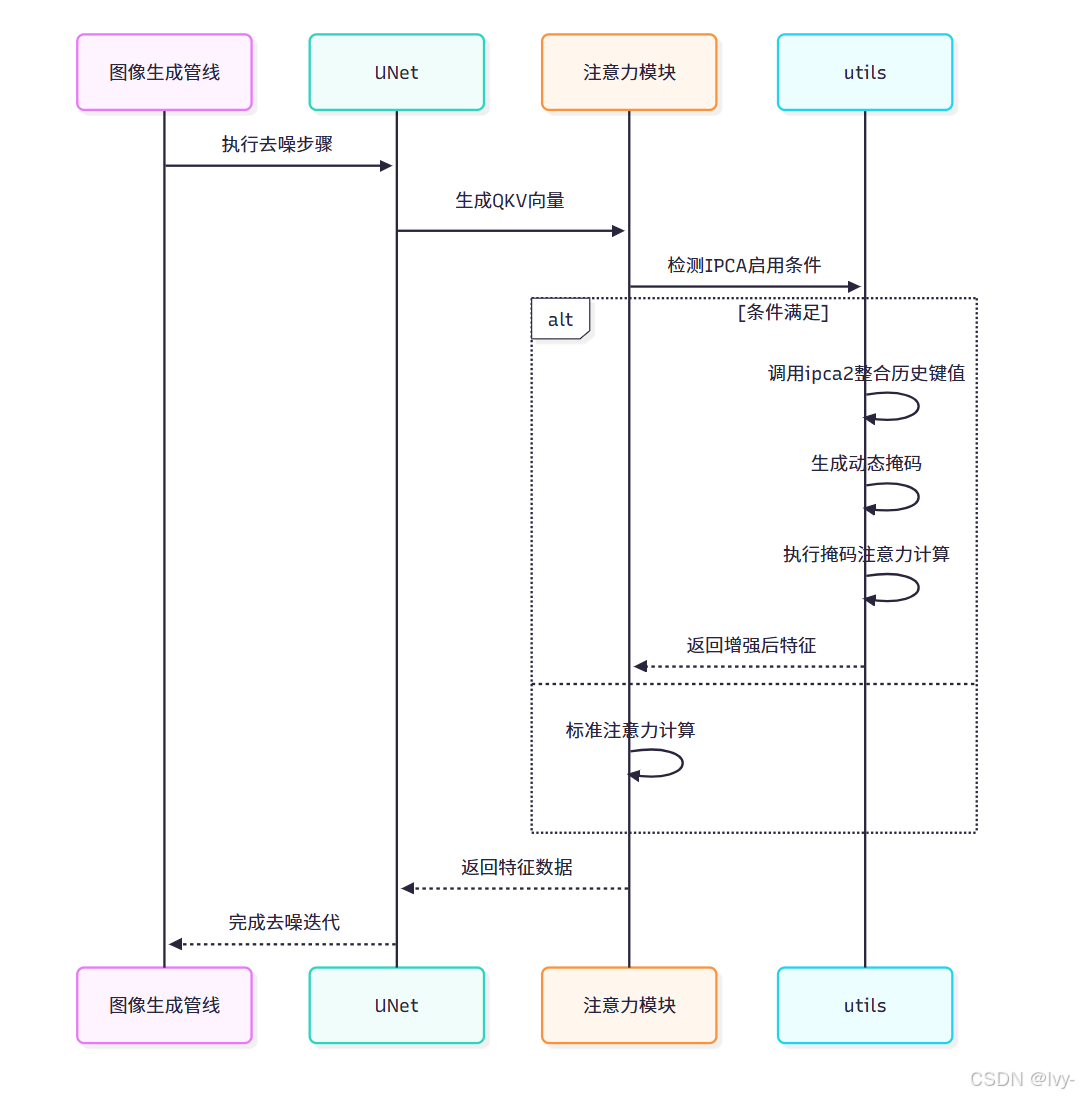
# 注意力模塊改造(unet/unet.py簡化版)
class Attention(nn.Module):def forward(self, hidden_states, unet_controller=None):# 生成QKV向量q = self.to_q(hidden_states)k = self.to_k(encoder_hidden_states)v = self.to_v(encoder_hidden_states)# IPCA條件檢測if 控制器啟用且滿足層級/步數條件:attn_output = utils.ipca2(q, k, v, scale, unet_controller)else:# 標準注意力計算attn_weights = torch.softmax(scores, dim=-1)attn_output = torch.matmul(attn_weights, v)return attn_output
IPCA核心算法
# 增強注意力計算(unet/utils.py簡化版)
def ipca(q, k, v, scale, controller):# 分離正負提示分支q_pos, q_neg = q.chunk(2)k_pos, k_neg = k.chunk(2)# 構建增強鍵值對k_plus = torch.cat([k_pos, *stored_keys], dim=2) # 歷史鍵值整合v_plus = torch.cat([v_pos, *stored_values], dim=1)# 動態掩碼生成dropout_mask = torch.bernoulli(1 - controller.Ipca_dropout) # 隨機丟棄矩陣if controller.Use_embeds_mask:embeds_mask = generate_embeds_mask(q_pos, controller.id_prompt) # ID區域掩碼final_mask = dropout_mask * embeds_mask# 掩碼注意力計算scores = (q_pos @ k_plus) * scalescores += torch.log(final_mask) # 掩碼疊加attn_weights = torch.softmax(scores, dim=-1)return attn_weights @ v_plus
IPCA(Improved Prompt-Conditioned Attention)通過動態整合歷史鍵值對和智能掩碼機制,實現更精準的注意力控制。
核心是將當前提示與歷史記憶結合,并通過隨機丟棄與語義掩碼的雙重過濾,增強關鍵特征的注意力權重。
關鍵實現邏輯:
分支處理
將查詢(q)、鍵(k)、值(v)張量沿通道維度切分為正負提示兩個獨立分支,僅對正向提示分支進行增強處理。
記憶增強
通過拼接當前鍵值(k_pos/v_pos)與存儲的歷史鍵值(stored_keys/values),擴展模型的上下文感知范圍,形成k_plus/v_plus增強鍵值對。
動態掩碼
采用伯努利采樣生成隨機丟棄矩陣(dropout_mask),結合基于ID提示生成的語義區域掩碼(embeds_mask),通過逐元素相乘得到最終注意力掩碼。
掩碼注意力
在標準注意力得分計算后,將對數掩碼值直接疊加到得分矩陣,通過softmax使被掩碼位置的權重趨近于零,實現特征級精確定位。
工作流程
技術優勢
IPCA為1Prompt1Story帶來三大突破:
- 特征鎖定:通過
歷史鍵值整合,維持跨幀特征一致性 - 干擾隔離:動態掩碼有效隔離場景變化帶來的噪聲干擾
- 自適應增強:階梯式啟用機制平衡細節生成與特征保留
結合語義向量重加權與統一噪聲基底技術,IPCA將跨幀一致性提升至新高度。
在第六章中,我們將深入解析UNet工作原理,揭示三大技術協同作用的底層機制。
第六章:去噪神經網絡(UNet)
迄今為止,我們已經學習了滑動窗口故事生成器如何巧妙準備故事提示詞,圖像生成管線如何統籌整個圖像創建流程,以及我們的"導演"——生成行為控制器如何運用語義向量重加權(SVR)和注意力機制增強(IPCA)等強大技術確保驚人的連貫性。
但所有這些準備、控制和巧妙的提示詞操作,最終都是為了一個目標:引導真正負責"繪制"圖像的核心"藝術家"。
這位藝術家就是去噪神經網絡,通常被稱為UNet。
核心藝術家:從噪點到故事
想象我們有一塊神奇的畫布,初始狀態完全被隨機噪點填滿,就像沒有信號的舊電視屏幕。我們的目標是將這些噪點轉化為"紅狐在雪地嬉戲"的美麗畫面。同時我們擁有詳細指令(提示詞)和導演(UNetController)在耳邊的指引。
UNet正是這位魔法藝術家。
它不從空白畫布開始,而是從純粹的隨機噪聲(第2章圖像生成管線中提到的"潛在變量")起步。它的工作是通過反復"去噪"——逐步消除隨機性,分步驟揭示清晰連貫的圖像。
在每個步驟中,UNet會觀察當前含噪圖像,聽取文本提示(來自第2章的"嵌入向量"),同時密切關注UNetController的具體指令(如SVR和IPCA規則)。
綜合這些信息,它預測需要去除哪些噪聲才能使圖像更清晰、更符合提示詞。這個過程重復多次(例如50步),逐步將抽象噪點轉化為具體的視覺特征。
UNet是實現原始創意轉化的核心,將抽象的"概念"(潛在表征)轉化為毛皮、樹木、雪花等真實視覺元素。
為何稱為"UNet"?U型數據流
UNet中的"U"指其特殊架構,形似字母U。
這種U型結構對圖像處理極為有效,因為它能同時理解整體形狀(如"此處有狐貍輪廓")和精細細節(如"狐貍有胡須")。
架構解析:
- 下采樣路徑(U型左側):如同畫家勾勒
大體輪廓。接收含噪圖像并逐步縮小、抽象化(降采樣)。每個階段捕捉高層級信息——非逐像素細節,而是整體形狀和概念。 - 瓶頸層(U型底部):信息
最壓縮、最抽象的層級。此處進行核心"思考",受文本提示詞深度影響。 - 上采樣路徑(U型右側):畫家
精修階段。獲取瓶頸層的抽象信息,逐步重建圖像并添加細節(升采樣)直至恢復原始尺寸。 - 跳躍連接:精妙設計!藝術家在右側精修細節時,可回看左側的原始草圖。這些"跳躍連接"直接將
同層級的下采樣信息傳遞給上采樣路徑,確保銳利邊緣等精細特征不被丟失。
1Prompt1Story如何運用UNet
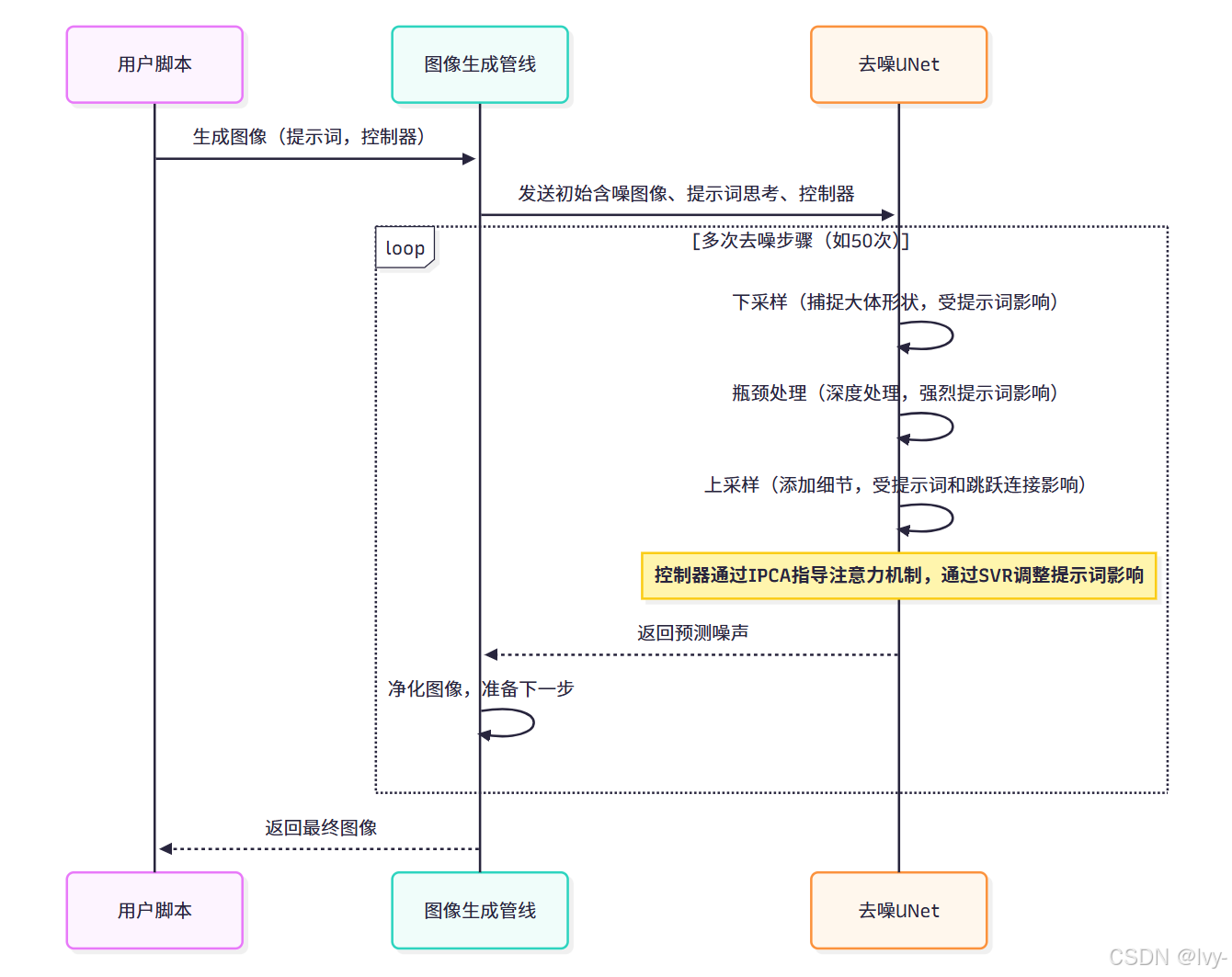
我們并不直接操作UNet,而是通過圖像生成管線來管理。每當管線執行"去噪步驟"(通常需數十次),都會將當前含噪圖像、文本提示的"思考"(嵌入向量)和UNetController傳遞給UNet。
UNet執行噪聲預測后,管線利用預測結果略微凈化圖像,循環往復。
以下是管線調用UNet的簡化流程(源自第2章圖像生成管線):
# 簡化自 unet/pipeline_stable_diffusion_xl.py(__call__方法內部)for i, t in enumerate(self.timesteps):# 將潛在變量和當前時間步傳遞給UNet# UNet使用prompt_embeds(AI的"思考")預測噪聲noise_pred = self.unet(latent_model_input, # 當前含噪圖像數據t, # 當前時間步(去噪階段指示)encoder_hidden_states=prompt_embeds, # 提示詞生成的"思考" unet_controller=unet_controller, # 實現1Prompt1Story特性的關鍵!return_dict=False,)[0]# 使用調度器應用噪聲預測,獲得更干凈的潛在變量latents = self.scheduler.step(noise_pred, t, latents)[0]# ...(后續處理流程)...
注意
unet_controller如何直接傳入self.unet調用。
這至關重要,因為它使得UNet能夠訪問第3章生成行為控制器配置的所有連貫性設置,并在繪制過程中應用。
內部機制:UNet的繪制過程
讓我們深入UNet的工作原理。
迭代精修流程
在每次循環中,UNet接收當前含噪圖像并預測其內部噪聲。這個預測過程深度依賴encoder_hidden_states(對提示詞的"思考")和unet_controller。
代碼解析:unet/unet.py
核心UNet模型定義在unet/unet.py的UNet2DConditionModel類中,主要流程體現在forward方法:
# 簡化自 unet/unet.py(UNet2DConditionModel.forward方法)class UNet2DConditionModel(ModelMixin, ConfigMixin):# ...(初始化各層:conv_in、time_embedding、down_blocks等)...def forward(self, sample, timesteps, encoder_hidden_states, added_cond_kwargs, unet_controller: Optional[UNetController] = None, **kwargs):# 1. 準備時間和文本嵌入# 'emb'包含當前去噪步驟和文本提示信息# 此處處理'added_cond_kwargs'(如第2章的text_embeds)# ...(準備'emb'的代碼)...sample = self.conv_in(sample) # 初始卷積# 2. 下采樣路徑(U型左側)# 每個下采樣塊縮小圖像尺寸并提取特征# s0、s1、s2等為"跳躍連接"保留的特征if unet_controller is not None:unet_controller.current_unet_position = 'down0' # 告知控制器當前位置sample, [s1, s2, s3] = self.down_blocks[0](sample, temb=emb)if unet_controller is not None:unet_controller.current_unet_position = 'down1'sample, [s4, s5, s6] = self.down_blocks[1](sample, temb=emb, encoder_hidden_states=encoder_hidden_states, unet_controller=unet_controller # 傳遞控制器!)# ...(類似處理其他下采樣塊)...# 3. 中間塊(U型底部)- 最深層次處理if unet_controller is not None:unet_controller.current_unet_position = 'mid'sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states, unet_controller=unet_controller)# 4. 上采樣路徑(U型右側)# 每個上采樣塊增大尺寸并添加細節,使用跳躍連接if unet_controller is not None:unet_controller.current_unet_position = 'up0'sample = self.up_blocks[0](hidden_states=sample, temb=emb, res_hidden_states_tuple=[s6, s7, s8], # 使用跳躍連接encoder_hidden_states=encoder_hidden_states, unet_controller=unet_controller)# ...(類似處理其他上采樣塊)...# 5. 最終卷積層(像素級預測)# ...(最終層處理代碼)...return [sample]
關鍵要素:
sample:當前待優化的含噪圖像數據(潛在變量)timesteps:指示去噪過程進度encoder_hidden_states:文本提示的"思考"嵌入unet_controller:實現IPCA等增強機制的關鍵
注意力機制核心
在Transformer2DModel(用于各跨注意力塊)中,Attention模塊是圖像數據與文本提示交互的核心樞紐:
# 簡化自 unet/unet.py(Attention.forward方法)class Attention(nn.Module):def forward(self, hidden_states, encoder_hidden_states=None, unet_controller: Optional[UNetController] = None):q = self.to_q(hidden_states) # 圖像特征查詢向量k = self.to_k(encoder_hidden_states) # 提示詞鍵向量v = self.to_v(encoder_hidden_states) # 提示詞值向量if (unet_controller啟用IPCA且滿足條件):# 應用IPCA增強的注意力計算attn_output = utils.ipca2(q,k,v,self.scale,unet_controller)else:# 標準注意力計算scores = torch.matmul(q, k.transpose(-2, -1)) * self.scaleattn_weights = torch.softmax(scores, dim=-1)attn_output = torch.matmul(attn_weights, v)return attn_output
此處匯聚了所有技術精華:
- 圖像特征通過跨注意力機制與提示詞交互
- SVR優化后的提示詞嵌入指導內容生成
- IPCA通過控制器動態調整注意力模式
總結
IPCA技術通過動態掩碼和歷史鍵值整合,實現AI生成圖像時的核心要素鎖定,有效解決場景切換導致的特征畸變問題。
- 該技術包含
分支處理、記憶增強和動態掩碼三大機制,通過控制器參數精確調節注意力分布。
作為核心生成引擎,UNet采用U型架構分步去噪,下采樣路徑提取整體輪廓,上采樣路徑補充細節,將隨機噪聲逐步轉化為符合提示詞的視覺內容。
- IPCA與UNet的協同工作,顯著
提升了跨幀一致性和特征保持能力,是AI圖像生成實現高質量連續敘事的關鍵技術組合
我們已觸及1Prompt1Story的核心🐻???去噪神經網絡(UNet) 是將隨機噪聲轉化為連貫圖像的動力引擎。
其U型架構既能把握整體構圖,又能雕琢精微細節,在UNetController的精密調控下,協同滑動窗口故事生成器、語義向量重加權等技術,最終實現視覺敘事的高度連貫性。
至此,我們已完成1Prompt1Story核心架構的探索之旅,相信你已經了解了這個創新工具如何將文字提示轉化為精彩視覺敘事!
END ★,°:.☆( ̄▽ ̄).°★ 。
![【P7071 [CSP-J2020] 優秀的拆分 - 洛谷 https://www.luogu.com.cn/problem/P7071】](http://pic.xiahunao.cn/【P7071 [CSP-J2020] 優秀的拆分 - 洛谷 https://www.luogu.com.cn/problem/P7071】)











)





)
