第1關:句法分析概述
任務描述
本關任務:通過對句法分析基本概念的學習,完成相應的選擇題。
相關知識
為了完成本關任務,你需要掌握:
-
句法分析的基礎概念;
-
句法分析的數據集和評測方法。
句法分析簡介
句法分析( syntactic parsing )是自然語言處理中的關鍵技術之一,它是對輸入的文本句子進行分析以得到句子的句法結構的處理過程。對句法結構進行分析,一方面是語言理解的自身需求,句法分析是語言理解的重要一環,另一方面也為其它自然語言處理任務提供支持。例如句法驅動的統計機器翻譯需要對源語言或目標語言(或者同時兩種語言)進行句法分析。
從20世紀50年代初機器翻譯課題被提出時算起,自然語言處理研究已經有60余年的歷史,句法分析一直是自然語言處理前進的巨大障礙。句法分析主要有以下兩個難點:
-
歧義。自然語言區別于人工語言的一個重要特點就是它存在大量的歧義現象。人類自身可以依靠大量的先驗知識有效地消除各種歧義,而機器由于在知識表示和獲取方面存在嚴重不足,很難像人類那樣進行句法消歧;
-
搜索空間。句法分析是一個極為復雜的任務,候選樹個數隨句子增多呈指數級增長,搜索空間巨大。因此,必須設計出合適的解碼器,以確保能夠在可以容忍的時間內搜索到模型定義最優解。
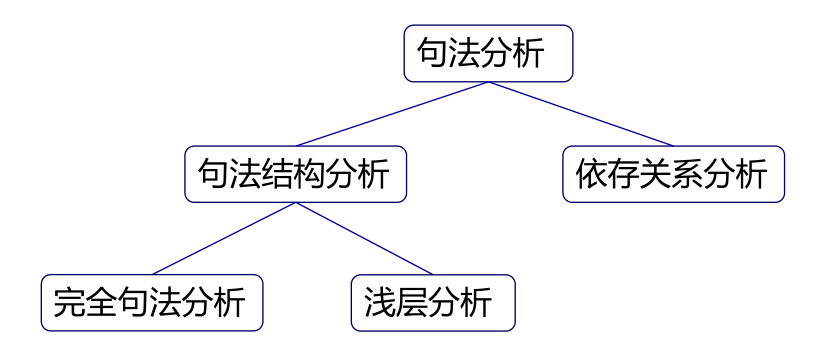
圖 1 句法分析的結構
句法分析( Parsing )是從單詞串得到句法結構的過程,而實現該過程的工具或程序被稱為句法分析器( Parser )。句法分析的種類很多,如圖1所示,這里我們根據其側重目標將其分為完全句法分析和局部句法分析兩種。兩者的差別在于,完全句法分析以獲取整個句子的句法結構為目的;而局部句法分析只關注于局部的一些成分,例如常用的依存句法分析就是一種局部分析方法。
句法分析中所用方法可以簡單地分為基于規則的方法和基于統計的方法兩大類。兩種方法的特點有:
-
基于規則的方法:處理大規模真實文本時,存在語法規則覆蓋有限、系統可遷移差等問題;
-
基于統計的方法:最典型的是 PCFG ,本質是一套面向候選樹的評價方法,給正確的句法樹賦予一個較高分值不合理的句法樹賦予一個較低分支,從而借用分值進行消歧。
句法分析的數據集
統計學習方法多需要語料數據的支撐,統計句法分析也不例外。相較于分詞或詞性注,句法分析的數據集要復雜很多,其是一種樹形的標注結構,因此又稱樹庫。
目前的樹庫有:
-
英文:英文賓州樹庫,前身為 ATIS 和 WSJ 樹庫,具有較高的一致性和標注準確率;
-
中文:中文賓州樹庫、清華樹庫、臺灣中研院樹庫等。
| 序號 | 標記代碼 | 標記名稱 |
|---|---|---|
| 1 | np | 名詞短語 |
| 2 | tp | 時間短語 |
| 3 | sp | 空間短語 |
| 4 | vp | 動詞短語 |
| 5 | ap | 形容詞短語 |
| 6 | bp | 區別詞短語 |
| 7 | dp | 副詞短語 |
如上表所示,不同的樹庫有著不同的標記體系,使用時切忌使用一種樹庫的句法分析器,然后用其他樹庫的標記體系來解釋。
句法分析的任務
語義分析通常以句法分析的輸出結果作為輸入以便獲得更多的指示信息,根據句法結構的表示形式不同,最常見的句法分析任務可以分為以下三種:
-
句法結構分析,作用是識別出句子中的短語結構以及短語之間的層次句法關系;
-
依存關系分析,又稱依存句法分析,簡稱依存分析,作用是識別句子中詞匯與詞匯之間的相互依存關系;
-
深層文法句法分析,即利用深層文法,例如詞匯化樹鄰接文法、詞匯功能文法、組合范疇文法等,對句子進行深層的句法以及語義分析。
句法分析的評測方法
句法分析評測的主要任務是評測句法分析器生成的樹結構與手工標注的樹結構之間的相似程度。其主要考慮兩方面的性能:滿意度和效率。其中滿意度是指測試句法分析器是否適合或勝任某個特定的自然語言處理任務;而效率主要用于對比句法分析器的運行時間。
目前流行的是 PARSEVAL 評測體系,主要指標有準確率(分析正確的短語個數在句法分析結果中所占比例,即分析結果中與標準句法樹相匹配的短語個數占分析結果中所有短語個數的比例)、召回率(分析得到的正確短語個數占標準分析樹全部短語個數的比例)、交叉括號數(分析得到的某一短語覆蓋范圍與標準句法分析結果的某一短語的覆蓋范圍存在重疊而不存在包含關系,從而構成一個交叉括號)。
作答要求
根據相關知識,按照要求完成右側選擇題任務。作答完畢,通過點擊“測評”,可以驗證答案的正確性。
-
1、
句法分析的主要難點有:
A、分詞
B、歧義
C、詞性標注
D、搜索空間
BD
-
2、
下列哪個不屬于 PARSEVAL 評測體系的主要指標
A、準確率
B、交叉括號數
C、符號數
D、召回率
C



>》)




![[圖解]SysML和EA建模住宅安全系統-02-現有運營領域-塊定義圖](http://pic.xiahunao.cn/[圖解]SysML和EA建模住宅安全系統-02-現有運營領域-塊定義圖)






)



