
🚀 Google 深夜突襲,Gemma 2 狂卷 Llama 3
- Gemma2性能超越Llama3,提供9B和27B版本,性能接近70B模型但大小僅為其40%
- Gemma2支持高效推理,單個GPU即可實現全精度推理,廣泛的硬件支持
- Gemma2兼容多種AI框架,提供實際應用示例和指南,谷歌計劃支持通過Google Cloud Vertex AI輕松部署
🔗?https://aistudio.google.com/app/prompts/new_freeform
🔗?Google 深夜突襲,Gemma 2 狂卷 Llama 3-CSDN博客?


🤖硅基智能開源其AI數字人交互平臺?
- 可以輕松創建逼真數字人
- 提供了很完善的工具和支持,部署過程變得非常簡單和低成本。
- 功能支持:
語音識別:高效的語音輸入,支持多種語言和口音。
語音合成:生成自然流暢的語音輸出
實時交互:支持與用戶的即時互動,提供快速響應。
多終端支持:可在Android和iOS設備上輕松部署,擴大使用場景。
模型下載:提供多個數字人模型的下載和使用,無需訓練,即可使用。
🔗GitHub:https://github.com/GuijiAI/duix.ai
🔗在線體驗:https://apps.apple.com/us/app/duix-your-ai-companion/id6451088879?


📢和 GPT 4o 匹敵 世界上最快的語音機器
- 能實現500毫秒的語音到語音響應 接近人類對話的自然速度
- 為達到這種低延遲,開發團隊優化了網絡架構、AI模型性能和語音處理邏輯。
- 使用WebRTC網絡發送音頻,部署了Deepgram的快速轉錄和語音生成模型,并將所有AI模型在Cerebrium的容器中自托管,以減少延遲。
🔗在線體驗:https://fastvoiceagent.cerebrium.ai


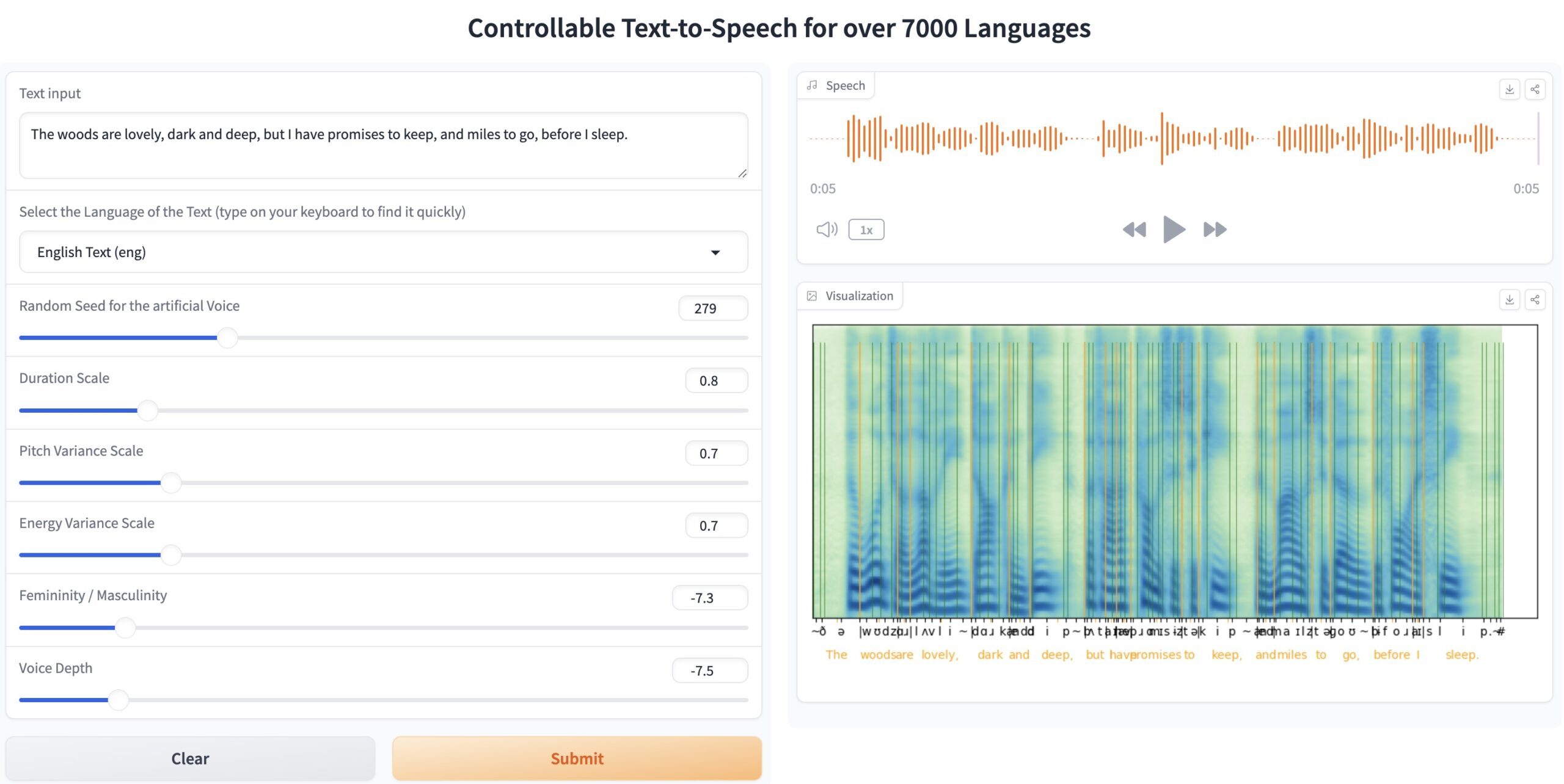
🌐ToucanTTS:支持超過 7000 多種語言的TTS模型
- 斯圖加特大學自然語言處理研究所(IMS)開發了一個超全文本轉語音模型ToucanTTS。
- 支持幾乎所有的 ISO-639-3 標準語言,這意味著它理論上可以支持超過 7000 種語言。是目前支持語言種類最多的 TTS 模型。
- 支持多說話人語音合成功能,可以模擬不同說話人的節奏、重音和語調。這對于需要風格多樣性和語音自定義的應用非常有用。
- 還允許用戶控制語音的多個參數,包括音調、語速、情感等。
🔗GitHub:https://github.com/DigitalPhonetics/IMS-Toucan
🔗在線演示:https://huggingface.co/spaces/Flux9665/MassivelyMultilingualTTS
🔗數據集:https://huggingface.co/datasets/Flux9665/BibleMMS

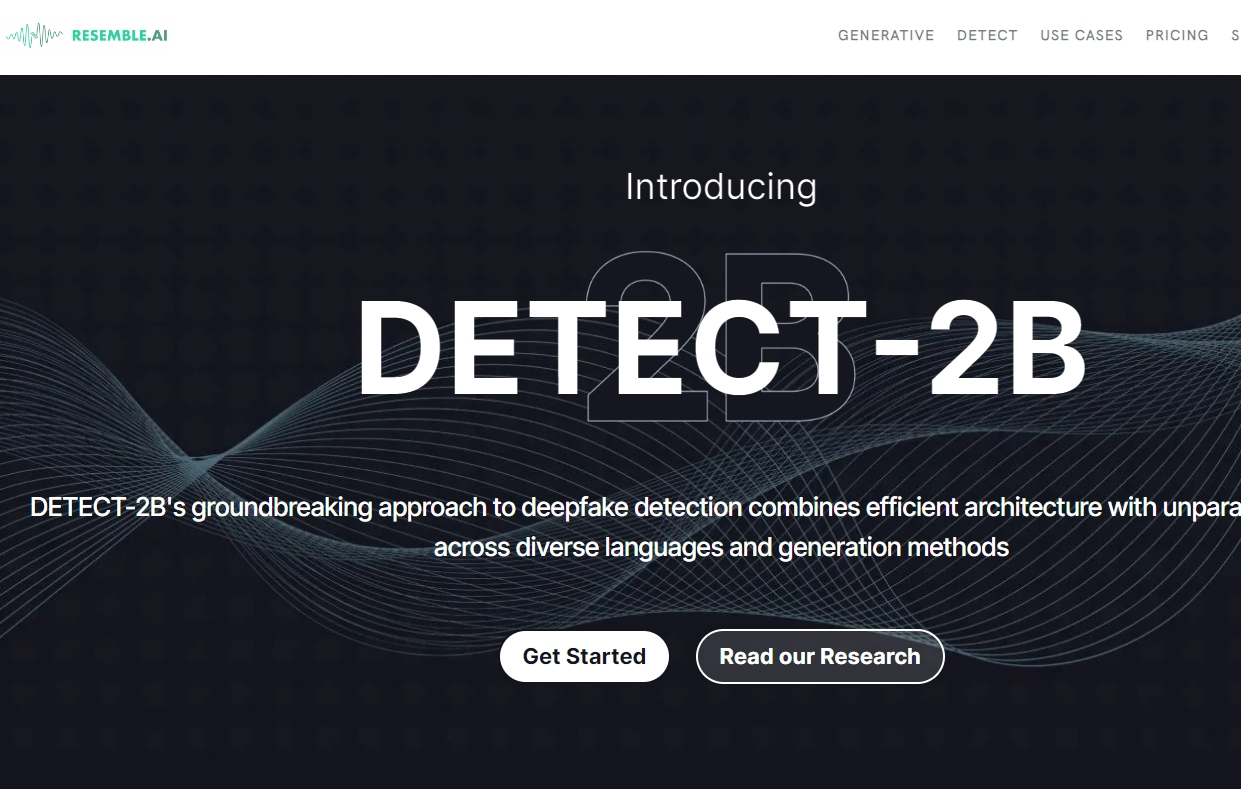
🔧Resemble AI發布AI音頻檢測模型Detect-2B 準確率達到 94%
- Detect-2B是下一代深度偽造檢測模型,準確率達94%。
- 使用預訓練的子模型和微調來檢查音頻片段,判斷是否由AI生成。
- 模型架構基于隨機概率模型,在不同語言的深度偽造音頻檢測上表現出色。
-?DETECT-2B 適用于需要檢測深度偽 造音頻的場景,可以幫助用戶識別并防范 AI 生成的欺詐音頻。
🔗?https://top.aibase.com/tool/detect-2b

🚩不靠譜?熱門AI搜索工具Perplexity被指引用錯誤信息
- Perplexity被曝引用錯誤的AI生成垃圾信息,來自可疑的博客和LinkedIn文章。
- GPTZero發現Perplexity鏈接的來源中有越來越多是AI生成的,Perplexity有時會使用這些來源中的過時和不正確信息。
- Perplexity聲稱答案來自“可靠來源”,AI算法是否真的能從好的信息中獲取好的信息值得懷疑。

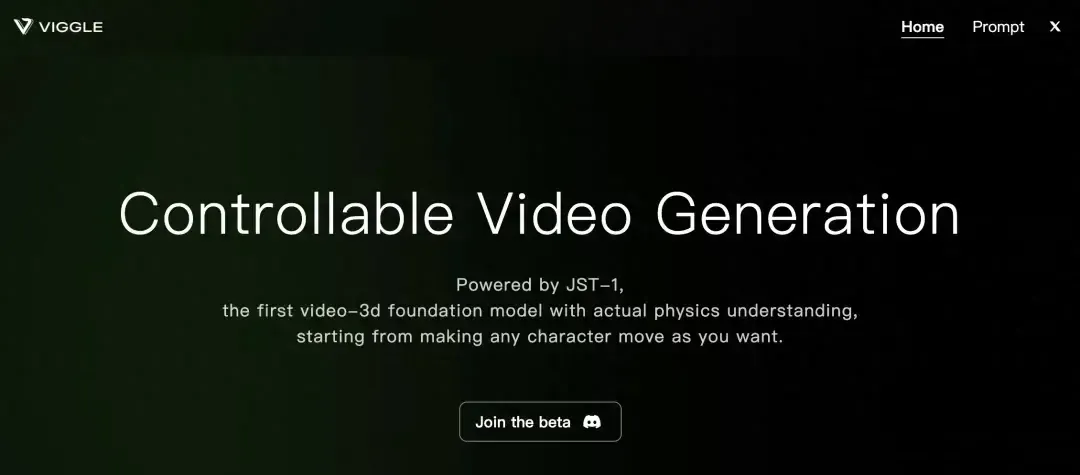
🎨Viggle推出Move功能:可保留照片的原始背景 無需額外編輯
- 保留原始背景:?"Move"功能與之前限制在綠色和白色背景的功能不同,保留照片原始背景,無需額外編輯。
- 易于訪問:用戶只需訪問https://viggle.ai 即可使用新功能。
- 無需復雜編輯:直接上傳照片,輕松為其添加動畫效果,無需繁瑣后期處理。
🔗?https://viggle.ai
🔗?https://blink.csdn.net/details/1744090
 ?
?


使用)
)

——JS介紹)

![[深度學習] 前饋神經網絡](http://pic.xiahunao.cn/[深度學習] 前饋神經網絡)

優化支持向量機(SVM)數據分類預測(IAO-SVM))









