前饋神經網絡(Feedforward Neural Network, FFNN)是人工神經網絡中最基本的類型,也是許多復雜神經網絡的基礎。它包括一個輸入層、一個或多個隱藏層和一個輸出層。以下是詳細介紹:
1. 結構
1. 輸入層(Input Layer):
- 包含與輸入數據特征數相同的神經元。
- 直接接收輸入數據,每個神經元對應一個輸入特征。
2. 隱藏層(Hidden Layers):
- 包含一個或多個隱藏層,每層包含若干神經元。
- 每個神經元與前一層的所有神經元相連接。
2.1. 全連接層(Dense Layer)
定義:每個神經元與前一層的所有神經元連接。
作用:
- 進行線性變換:
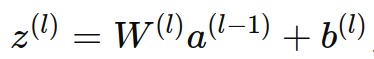
,其中 W(l) 是權重矩陣, a(l?1) 是前一層的激活值, b(l)是偏置。 - 通過激活函數進行非線性變換:
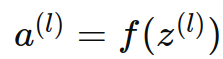
常見激活函數: - ReLU(Rectified Linear Unit)
- Sigmoid
- Tanh
示例代碼:
tf.keras.layers.Dense(64, activation='relu')
2.2. 激活函數層(Activation Layer)
定義:非線性函數,應用于每個神經元的輸出。
作用:
- 引入非線性,使網絡能夠學習復雜的模式。
常見激活函數:
- ReLU:
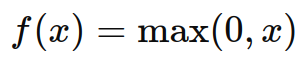
- Sigmoid:
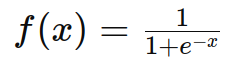
- Tanh:
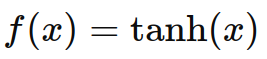
示例代碼:
tf.keras.layers.Activation('relu')
2.3. Dropout層
定義:在訓練過程中隨機丟棄一定比例的神經元。
作用:
- 防止過擬合,增強模型的泛化能力。
參數:
- rate:丟棄概率(0到1之間)。
示例代碼:
tf.keras.layers.Dropout(0.5)
2.4. 批量歸一化層(Batch Normalization Layer)
定義:在每個批次中標準化激活值。
作用:
- 加速訓練,穩定學習過程。
- 防止過擬合,增強模型的魯棒性。
示例代碼:
tf.keras.layers.BatchNormalization()
2.5. 高斯噪聲層(Gaussian Noise Layer)
定義:在訓練過程中向輸入添加高斯噪聲。
作用:
- 增強模型的魯棒性,防止過擬合。
參數:
- stddev:噪聲的標準差。
示例代碼:
tf.keras.layers.GaussianNoise(0.1)
2.6. 高斯丟棄層(Gaussian Dropout Layer)
定義:在訓練過程中以高斯分布的比例隨機丟棄神經元。
作用:
- 類似于Dropout層,但使用高斯分布的比例來丟棄神經元。
參數:
- rate:丟棄概率。
示例代碼:
tf.keras.layers.GaussianDropout(0.5)
3. 輸出層(Output Layer):
- 包含與輸出要求相匹配的神經元數量。
- 輸出神經元的數量取決于具體的任務,如回歸任務可能只有一個輸出神經元,分類任務根據類別數設置相應的神經元數。
- 使用適合任務的激活函數,如Sigmoid用于二分類,Softmax用于多分類,線性激活函數用于回歸。
2. 工作原理
-
前向傳播(Forward Propagation):
- 輸入數據通過網絡層層傳播,每層神經元計算加權和(加上偏置項),并通過激活函數進行非線性變換。
- 公式:
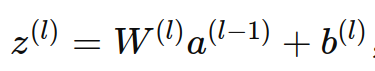
,其中z(l)是第l層的線性組合,W(l)是權重矩陣,a(l?1)是前一層的輸出,b(l)是偏置項。 - 激活函數:
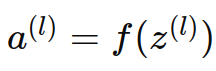
-
損失函數(Loss Function):
- 定義模型預測值與真實值之間的差異。
- 常用的損失函數包括均方誤差(MSE)用于回歸,交叉熵損失(Cross-Entropy Loss)用于分類。
- 公式:對于二分類問題,交叉熵損失函數為
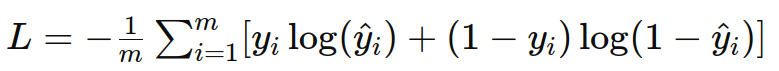
-
反向傳播(Backward Propagation):
- 通過梯度下降優化算法來更新權重和偏置,以最小化損失函數。
- 計算損失函數相對于每個參數的梯度,并反向傳播這些梯度,通過鏈式法則逐層更新權重和偏置。
- 公式:權重更新
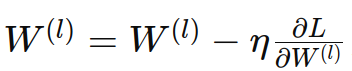
,偏置更新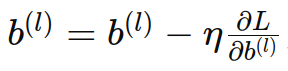
,其中 η 是學習率。
3. 特點和應用
-
特點:
- 前饋神經網絡是有向無環網絡(DAG),數據從輸入層通過隱藏層一直流向輸出層,不存在反饋循環。
- 容易實現和理解,是深度學習模型的基礎。
- 通常通過增加隱藏層數量和神經元數量來提高模型的表達能力。
-
應用:
- 適用于各種監督學習任務,包括回歸、二分類和多分類任務。
- 用于預測、分類、模式識別等領域。
- 可以與其他技術結合,如卷積神經網絡(CNN)和循環神經網絡(RNN)等,用于處理圖像、文本、時序數據等復雜任務。
示例代碼
下面是一個更復雜的前饋神經網絡示例代碼,包含多種不同類型的隱藏層,包括密集層(Dense Layer)、批量歸一化層(Batch Normalization)、Dropout層、和高斯噪聲層(Gaussian Noise Layer)。
示例代碼
import tensorflow as tf
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler# 生成示例數據
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 數據標準化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 構建模型
model = tf.keras.Sequential([tf.keras.layers.Dense(128, activation='relu', input_shape=(X_train.shape[1],)),tf.keras.layers.BatchNormalization(), # 批量歸一化層tf.keras.layers.Dropout(0.5), # Dropout層tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.BatchNormalization(),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(32, activation='relu'),tf.keras.layers.GaussianNoise(0.1), # 高斯噪聲層tf.keras.layers.BatchNormalization(),tf.keras.layers.Dense(16, activation='relu'),tf.keras.layers.BatchNormalization(),tf.keras.layers.Dense(1, activation='sigmoid') # 輸出層,適用于二分類任務
])# 編譯模型
model.compile(optimizer='adam',loss='binary_crossentropy', # 二分類交叉熵損失metrics=['accuracy'])# 訓練模型
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.2)# 評估模型
test_loss, test_accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {test_accuracy}')# 用于預測的新數據
new_data = np.random.rand(1, 20) # 示例數據
new_data = scaler.transform(new_data)
prediction = model.predict(new_data)
print(f'Prediction: {prediction}')
代碼解釋
-
數據生成:
- 使用
make_classification函數生成一個二分類的數據集,其中有1000個樣本,每個樣本有20個特征。 - 將數據集分為訓練集和測試集。
- 使用
-
數據標準化:
使用StandardScaler對數據進行標準化處理,使每個特征的均值為0,方差為1。 -
模型構建:
-
第一層:全連接層(Dense)有128個神經元,激活函數為ReLU。
-
第二層:批量歸一化層(BatchNormalization),有助于加速訓練和穩定性。
-
第三層:Dropout層,丟棄率為0.5,防止過擬合。
-
第四層:全連接層,有64個神經元,激活函數為ReLU。
-
第五層:批量歸一化層。
-
第六層:Dropout層,丟棄率為0.5。
-
第七層:全連接層,有32個神經元,激活函數為ReLU。
-
第八層:高斯噪聲層(GaussianNoise),添加標準差為0.1的高斯噪聲,增加模型魯棒性。
-
第九層:批量歸一化層。
-
第十層:全連接層,有16個神經元,激活函數為ReLU。
-
第十一層:批量歸一化層。
-
輸出層:全連接層,有1個神經元,激活函數為Sigmoid,適用于二分類任務。
-
-
模型編譯與訓練:
- 使用Adam優化器,二分類交叉熵損失函數,準確率作為評估指標。
- 訓練模型,設置訓練輪數為50,每批次訓練樣本數為32,20%的數據用于驗證。
-
模型評估與預測:
- 評估測試集上的模型表現,打印測試準確率。
- 對新數據進行預測,展示預測結果。
這個示例代碼展示了如何在前饋神經網絡中使用不同類型的隱藏層,以增強模型的表達能力和穩定性。可以根據需要進一步調整模型結構和參數。

優化支持向量機(SVM)數據分類預測(IAO-SVM))














 Mcal配置)


