內容介紹:
模型訓練一般分為四個步驟:
1. 構建數據集。
2. 定義神經網絡模型。
3. 定義超參、損失函數及優化器。
4. 輸入數據集進行訓練與評估。
具體內容:
1. 導包
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
from download import download2. 構建數據集
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)def datapipe(path, batch_size):image_transforms = [vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]label_transform = transforms.TypeCast(mindspore.int32)dataset = MnistDataset(path)dataset = dataset.map(image_transforms, 'image')dataset = dataset.map(label_transform, 'label')dataset = dataset.batch(batch_size)return datasettrain_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)3. 定義神經網絡模型
class Network(nn.Cell):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.dense_relu_sequential = nn.SequentialCell(nn.Dense(28*28, 512),nn.ReLU(),nn.Dense(512, 512),nn.ReLU(),nn.Dense(512, 10))def construct(self, x):x = self.flatten(x)logits = self.dense_relu_sequential(x)return logitsmodel = Network()4.?定義超參、損失函數和優化器
超參(Hyperparameters)是可以調整的參數,可以控制模型訓練優化的過程,不同的超參數值可能會影響模型訓練和收斂速度。目前深度學習模型多采用批量隨機梯度下降算法進行優化。
訓練輪次(epoch):訓練時遍歷數據集的次數。
批次大小(batch size):數據集進行分批讀取訓練,設定每個批次數據的大小。batch size過小,花費時間多,同時梯度震蕩嚴重,不利于收斂;batch size過大,不同batch的梯度方向沒有任何變化,容易陷入局部極小值,因此需要選擇合適的batch size,可以有效提高模型精度、全局收斂。
學習率(learning rate):如果學習率偏小,會導致收斂的速度變慢,如果學習率偏大,則可能會導致訓練不收斂等不可預測的結果。梯度下降法被廣泛應用在最小化模型誤差的參數優化算法上。梯度下降法通過多次迭代,并在每一步中最小化損失函數來預估模型的參數。學習率就是在迭代過程中,會控制模型的學習進度。
epochs = 3
batch_size = 64
learning_rate = 1e-2損失函數(loss function)用于評估模型的預測值(logits)和目標值(targets)之間的誤差。訓練模型時,隨機初始化的神經網絡模型開始時會預測出錯誤的結果。損失函數會評估預測結果與目標值的相異程度,模型訓練的目標即為降低損失函數求得的誤差。
常見的損失函數包括用于回歸任務的`nn.MSELoss`(均方誤差)和用于分類的`nn.NLLLoss`(負對數似然)等。 `nn.CrossEntropyLoss` 結合了`nn.LogSoftmax`和`nn.NLLLoss`,可以對logits 進行歸一化并計算預測誤差。
loss_fn = nn.CrossEntropyLoss()模型優化(Optimization)是在每個訓練步驟中調整模型參數以減少模型誤差的過程。MindSpore提供多種優化算法的實現,稱之為優化器(Optimizer)。優化器內部定義了模型的參數優化過程(即梯度如何更新至模型參數),所有優化邏輯都封裝在優化器對象中。在這里,我們使用SGD(Stochastic Gradient Descent)優化器。
我們通過`model.trainable_params()`方法獲得模型的可訓練參數,并傳入學習率超參來初始化優化器。
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)在訓練過程中,通過微分函數可計算獲得參數對應的梯度,將其傳入優化器中即可實現參數優化,具體形態如下:
grads = grad_fn(inputs)
optimizer(grads)
5. 訓練與評估
設置了超參、損失函數和優化器后,我們就可以循環輸入數據來訓練模型。一次數據集的完整迭代循環稱為一輪(epoch)。每輪執行訓練時包括兩個步驟:
1. 訓練:迭代訓練數據集,并嘗試收斂到最佳參數。
2. 驗證/測試:迭代測試數據集,以檢查模型性能是否提升。
?
def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)return loss, logits# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)# Define function of one-step training
def train_step(data, label):(loss, _), grads = grad_fn(data, label)optimizer(grads)return lossdef train_loop(model, dataset):size = dataset.get_dataset_size()model.set_train()for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):loss = train_step(data, label)if batch % 100 == 0:loss, current = loss.asnumpy(), batchprint(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")def test_loop(model, dataset, loss_fn):num_batches = dataset.get_dataset_size()model.set_train(False)total, test_loss, correct = 0, 0, 0for data, label in dataset.create_tuple_iterator():pred = model(data)total += len(data)test_loss += loss_fn(pred, label).asnumpy()correct += (pred.argmax(1) == label).asnumpy().sum()test_loss /= num_batchescorrect /= totalprint(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(model, train_dataset)test_loop(model, test_dataset, loss_fn)
print("Done!")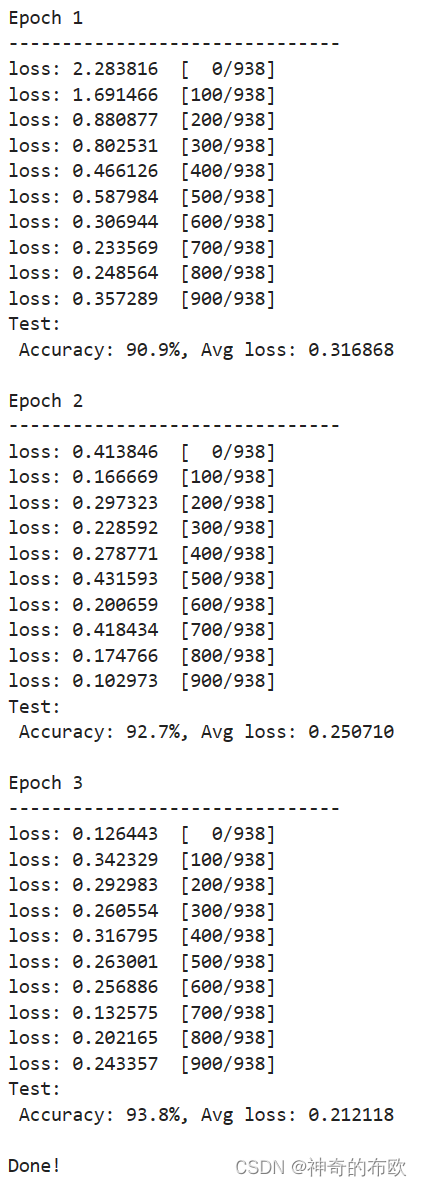
MindSpore的易用性也給我帶來了很大的便利。通過簡潔明了的API和豐富的文檔支持,我能夠快速地掌握MindSpore的使用方法,并輕松地構建自己的深度學習模型。同時,MindSpore還提供了豐富的預訓練模型和示例代碼,讓我能夠更快地入門并深入理解深度學習的應用。
在模型訓練的過程中,我深刻體會到了深度學習模型的復雜性和挑戰性。通過不斷地調整網絡結構、優化參數設置以及嘗試不同的訓練策略,我逐漸掌握了如何構建和訓練一個性能優異的深度學習模型。這個過程讓我更加明白了深度學習模型訓練需要耐心、細致和持續的努力。


】第1章-大數據概述習題與知識點回顧)
)



)







![[DALL·E 2] Hierarchical Text-Conditional Image Generation with CLIP Latents](http://pic.xiahunao.cn/[DALL·E 2] Hierarchical Text-Conditional Image Generation with CLIP Latents)



歐美股市總結:標普納指止步三日連跌,英偉達反彈6.8%,谷歌微軟新高,油價跌1%)
