1、目的
? ? ? ? CLIP + DDPM進行text-to-image生成
2、數據
? ? ? ? (x, y),x為圖像,y為相應的captions;設定和
為CLIP的image和text embeddings
3、方法
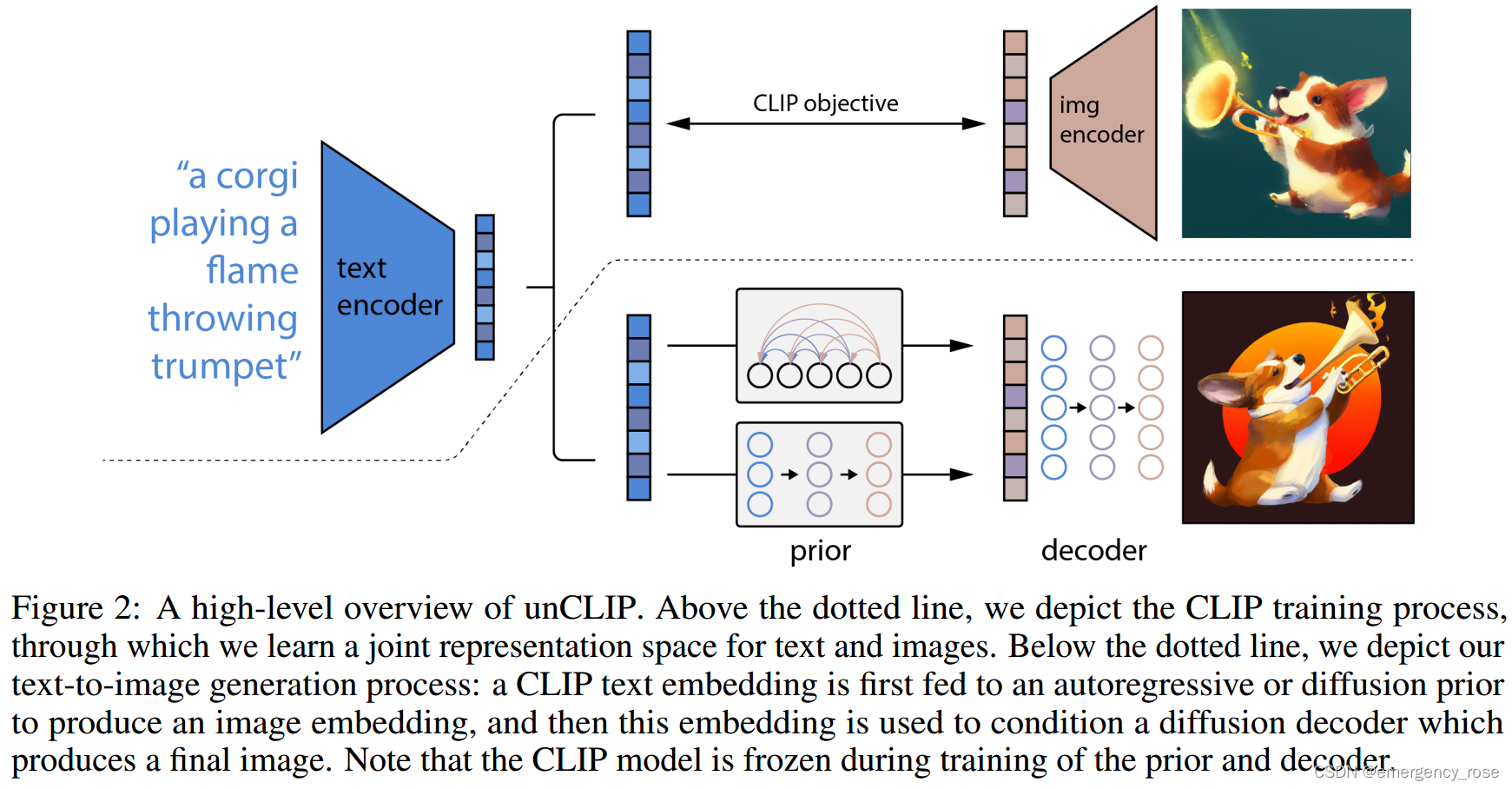
????????????????????????????????![]()
? ? ? ? 1)CLIP
? ? ? ? ? ? ? ? 學習圖像和文本的embedding;在訓練prior和decoder時固定該部分參數
? ? ? ? 2)prior model?
? ? ? ? ? ? ? ? 從給定的文本caption(或CLIP text embedding)中生成CLIP image embedding
? ? ? ? ? ? ? ? -> Autoregressive (AR) prior
? ? ? ? ? ? ? ? ? ? ? ? 用PCA對CLIP image embeddings降維(1024 - 319),然后排序和數值化

? ? ? ? ? ? ? ? ? ? ? ? 將text caption和CLIP text embedding編碼為sequence的prefix
? ? ? ? ? ? ? ? -> Diffusion prior
? ? ? ? ? ? ? ? ? ? ? ? decoder-only Transformer
? ? ? ? ? ? ? ? ? ? ? ? casual attention mask with causal attention mask on a sequence (encoded text, CLIP text embedding, embedding for the diffusion timestep, noised CLIP image embedding, final embedding whose output from the Transformer is used to predict the unnoised CLIP image embedding)
? ? ? ? ? ? ? ? ? ? ? ? 同時生成兩個,選擇與
的點積更大的那一個
? ? ? ? ? ? ? ? ? ? ? ? 不預測,而是直接預測
????????????????????????![]()
? ? ? ? 3)CLIP image embedding decoder?
? ? ? ? ? ? ? ? -> 用diffusion models、以CLIP image embeddings作為條件生成圖像(可能會用到text caption)。直接將embedding作為采樣起點效果不佳。
? ? ? ? ? ? ? ? -> 映射和添加CLIP embeddings到existing timestep embedding
? ? ? ? ? ? ? ? -> 將CLIP embedding映射到4個額外的context token中,和GLIDE text encoder的輸出并聯
? ? ? ? ? ? ? ? -> 因為是CLIP image encoder的逆過程,因此本文的方法也被稱為unCLIP
? ? ? ? ? ? ? ? -> 嘗試沿用GLIDE中的text conditioning,但作用不大
? ? ? ? ? ? ? ? -> 訓練細節
? ? ? ? ? ? ? ? ? ? ? ? 10%的概率隨機設置CLIP embedding(或learned embedding)為0,實現classifier-free guidance;50%的概率隨機去除text caption
? ? ? ? ? ? ? ? ? ? ? ? 兩個upsample網絡,64x64 - 256x256 - 1024x1024;第一個上采樣階段采用gaussian blur,第二個上采樣階段采用BSR degradation;訓練時隨機裁剪1/4大小的圖像,推理時則用正常大小;只用spatial convolution,不用attention層;網絡為unconditional ADMNets
? ? ? ? ? ? ? ? -> 備選方案:直接用caption或者text embeddings作為條件,不用prior

4、應用
? ? ? ? 1)non-deterministic,給定一個image embedding,可以生成多個圖像
 ????????2)通過插值image embedding,可以對生成圖像進行插值
????????2)通過插值image embedding,可以對生成圖像進行插值
????????????????????????????????????????????????????????????????????![]()

? ? ? ? 3)通過插值text embedding,可以對生成圖像進行插值
????????????????????????????????????????????????????????????????????????????![]()
????????????????????????????????????????????????![]()

? ? ? ? 4)可以有效抵擋CLIP容易受到影響的typographic attack

5、局限性
? ? ? ? 1)對于不同物品和屬性的關聯能力不如GLIDE。因為CLIP embedding本身不關聯物品和屬性,而decoder也會mix up屬性和物品

? ? ? ? 2)無法寫出連貫的文本。因為CLIP本身不編碼拼寫信息,BPE編碼也會模糊單詞的拼寫

? ? ? ? 3)無法生成復雜場景中的細節。因為模型在低分辨率下訓練,然后再上采樣

? ? ? ? 4)生成效果越好,制造欺騙性或有害圖片的能力就更大



歐美股市總結:標普納指止步三日連跌,英偉達反彈6.8%,谷歌微軟新高,油價跌1%)



支付方式接口(信用卡類、微信支付類實現支付接口 體現低耦合)】)











