?AI目錄??sheng的學習筆記-AI目錄-CSDN博客
需要學習前置知識:聚類,可參考??sheng的學習筆記-AI-聚類(Clustering)-CSDN博客
什么是學習向量量化
“學習向量量化”(Learning Vector Quantization,簡稱LVQ)是試圖找到一組原型向量來刻畫聚類結構,但與一般聚類算法不同的是,LVQ假設數據樣本帶有類別標記,學習過程利用樣本的這些監督信息來輔助聚類。
算法代碼
給定樣本集D={(x1,y1),(x2,y2),…,(xm,ym)},每個樣本xj是由n個屬性描述的特征向量(xj1,xj2,…,xjn),yj∈Y是樣本xj的類別標記。LVQ的目標是學得一組n維原型向量{P1,P2,…,Pq},每個原型向量代表一個聚類簇,簇標記ti∈Y

- 先對原型向量進行初始化,例如對第q個簇可從類別標記為tq的樣本中隨機選取一個作為原型向量。
- 在每一輪迭代中,算法隨機選取一個有標記訓練樣本,找出與其距離最近的原型向量,并根據兩者的類別標記是否一致來對原型向量進行相應的更新。對樣本xj,若最近的原型向量pi*與xj的類別標記相同,則令pi*向xj的方向靠攏,此時新原型向量為
 ? ? ,p'和xj的距離是:
? ? ,p'和xj的距離是: 。令學習率η∈(0,1),則原型向量pi*在更新為p'之后將更接近xj。
。令學習率η∈(0,1),則原型向量pi*在更新為p'之后將更接近xj。 - 在第12行中,若算法的停止條件已滿足(例如已達到最大迭代輪數,或原型向量更新很小甚至不再更新),則將當前原型向量作為最終結果返回。
示例
用以下數據集為例來演示LVQ的學習過程

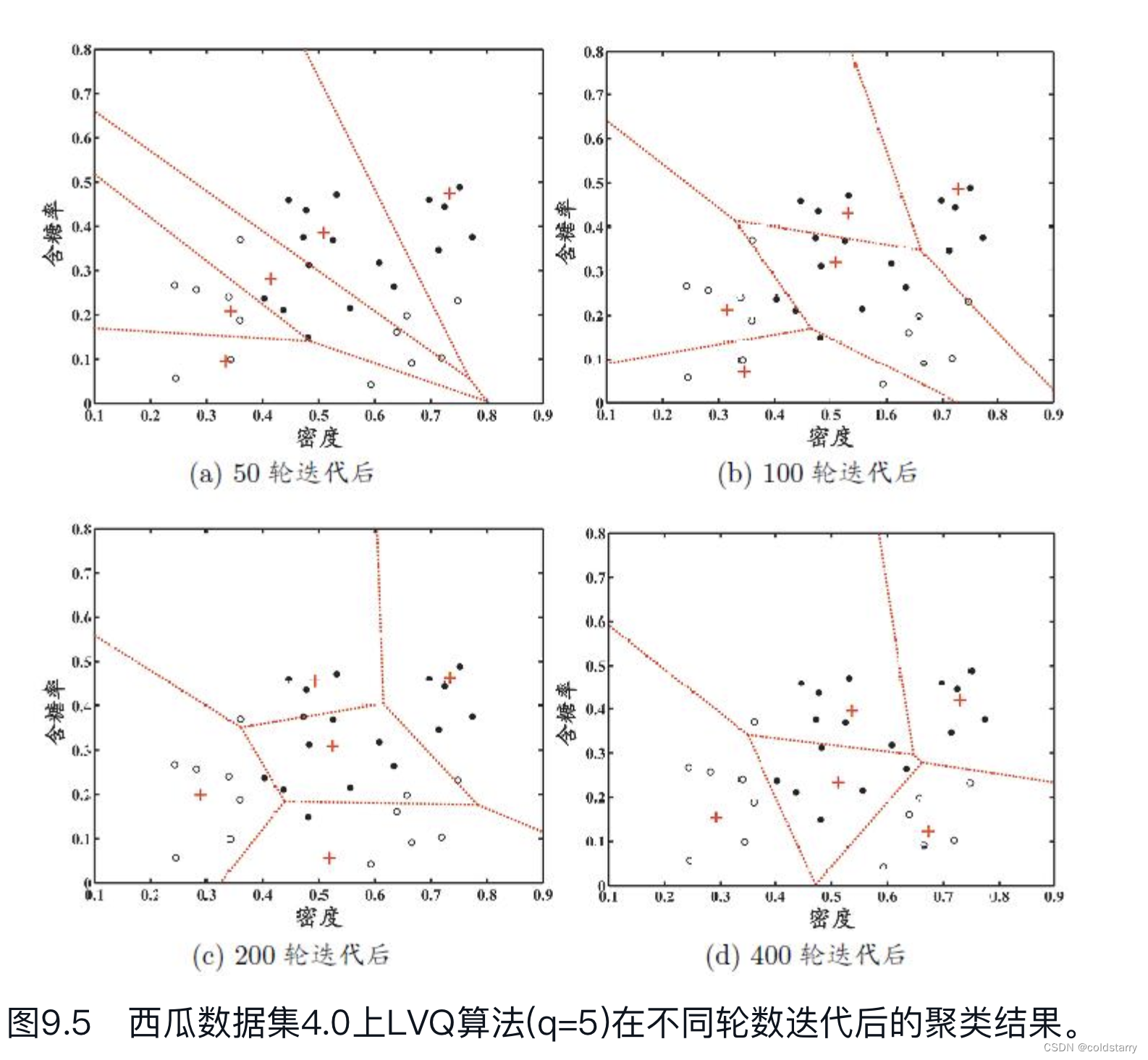
令9-21號樣本的類別標記為c2,其他樣本的類別標記為c1。假定q=5,即學習目標是找到5個原型向量p1,p2,p3,p4,p5,并假定其對應的類別標記分別為c1,c2,c2,c1,c1。
算法開始時,根據樣本的類別標記和簇的預設類別標記對原型向量進行隨機初始化,假定初始化為樣本x5,x12,x18,x23,x29。
在第一輪迭代中,假定隨機選取的樣本為x1,該樣本與當前原型向量p1,p2,p3,p4,p5的距離分別為0.283,0.506,0.434,0.260,0.032。由于p5與x1距離最近且兩者具有相同的類別標記c1,假定學習率η=0.1,則LVQ更新p5得到新原型向量

將p5更新為p'后,不斷重復上述過程,不同輪數之后的聚類結果如圖9.5所示。
?

)



-- 算法導論21.3 2題)













