具有收縮和擴展路徑的全卷積神經網絡 (FCNN) 在大多數醫學圖像分割應用中表現出了突出的作用。在 FCNN 中,編碼器通過學習全局和局部特征以及上下文表示來發揮不可或缺的作用,這些特征和上下文表示可用于解碼器的語義輸出預測。
在FCNN中,收縮路徑通常用于捕獲圖像的上下文信息,并逐步減少空間維度;而擴展路徑則用于恢復空間維度,使輸出圖像的尺寸與輸入圖像相近,并提供更精細的分割結果。
?FCNN中卷積層的局部性限制了學習遠程空間遠程依賴性的能力。受到自然語言處理(NLP)轉換器最近在遠程序列學習中取得成功的啟發,將體積(3D)醫學圖像分割任務重新表述為序列到序列的預測問題。
UNET Transformers (UNETR)
利用 Transformer 作為編碼器來學習輸入量的序列表示并有效捕獲全局多尺度信息,同時也遵循成功的“U 形”網絡編碼器和解碼器的設計。
Transformer編碼器通過不同分辨率的跳躍連接直接連接到解碼器,以計算最終的語義分割輸出。
多器官分割的顱穹外多圖集標記 (BTCV) 數據集和用于腦腫瘤和脾臟分割任務的醫學分割十項全能 (MSD) 數據集?
?“U形”編碼器-解碼器架構在各種醫學語義分割任務中取得了最先進的結果。在典型的U-Net架構中,編碼器負責通過逐漸下采樣提取的特征來學習全局上下文表示,而解碼器將提取的表示上采樣到輸入分辨率,以進行像素/體素語義預測。此外,跳躍連接將編碼器的輸出與不同分辨率的解碼器合并,從而允許恢復在下采樣期間丟失的空間信息。
跳躍連接![]() https://blog.csdn.net/j_qin/article/details/127843666
https://blog.csdn.net/j_qin/article/details/127843666
盡管基于FCNN的方法具有強大的表示學習能力,但它們在學習遠程依賴性方面的性能僅限于其局部感受野。因此,捕獲多尺度信息的缺陷導致對形狀和尺度可變的結構(不同大小的腦損傷)的分割不理想。可以使用多孔卷積層來擴大感受野。然而,卷積層中感受野的局部性仍然將其學習能力限制在相對較小的區域。將自注意力模塊與卷積層相結合來提高非局部建模能力。
在自然語言處理(NLP)中,Transformer 的自注意力機制可以動態突出單詞序列的重要特征。在計算機視覺中,使用 Transformer 作為骨干編碼器是有益的,因為它們具有建模遠程依賴關系和捕獲全局上下文的強大能力。Transformer 將圖像編碼為一維補丁嵌入序列,并利用自注意力模塊來學習從隱藏層計算的值的加權和。
將三維分割任務重新表述為一維序列到序列預測問題,并利用Transformer作為編碼器從嵌入的輸入補丁中學習上下文信息。從Transformer編碼器提取的表示通過多個分辨率的跳躍連接與基于CNN的解碼器合并,以預測分割輸出。
提出的框架沒有在解碼器中使用 Transformer,而是使用基于 CNN 的解碼器。這是因為,盡管 Transformer 具有很強的學習全局信息的能力,但它們無法正確捕獲局部信息。
主要貢獻
① Transformer 編碼器直接利用嵌入式 3維 體積來有效捕獲遠程依賴性;
② 跳躍連接編碼器組合提取的不同分辨率的表示并預測分割輸出;
2. 相關工作
基于 CNN 的分割網絡:對于體積分割,三平面架構有時用于組合每個體素的三視圖切片,也稱為 2.5D 方法。相比之下,3D 方法直接利用由一系列 2D 切片或模態表示的完整體積圖像。采用不同尺寸的直觀理解是利用多掃描、多路徑模型來捕獲圖像的下采樣特征。
Vision Transformers
通過對純 Transformer 進行大規模預訓練和微調,展示了圖像分類數據集上最先進的性能。在目標檢測中,基于端到端 Transformer 的模型在多個基準測試中表現出了突出的優勢。具有不同分辨率和空間嵌入的分層Vision Transformers。這些方法逐漸降低變壓器層中特征的分辨率并利用子采樣注意模塊。
使用基于 Transformer 的模型進行 2D 圖像分割任務的可能性。Cheng等人介紹了SETR模型,其中提出了一種預訓練的變壓器編碼器,具有基于CNN的解碼器的不同變體,用于語義分割任務。Chen 等人提出了一種多器官分割方法,通過使用 Transformer 作為 U-Net 架構瓶頸中的附加層。張等人提出在單獨的流中使用 CNN 和 Transformer 并融合它們的輸出。 Valanarasu 等人提出了一種基于 Transformer 的軸向注意機制,用于 2D 醫學圖像分割。
本文模型的主要區別
- UNETR是為3D分割量身定制的,并直接利用體積數據;
- UNETR采用Transformer作為分割網絡的主要編碼器,并通過跳躍連接直接連接到解碼器,而不是將其作為分割網絡中的注意力層;
- UNETR不依賴于主干CNN用于生成輸入序列而是直接利用標記化補丁。
對于3D醫學圖像分割,提出了一個框架,該框架利用主干CNN進行特征提取,利用Transformer 來處理編碼表示,并利用CNN解碼器來預測分割輸出。Wang 等人提出在3D編碼器-解碼器CNN的連接處 使用 Transformer 來完成語義腦腫瘤分割的任務。
與這些方法相反,我們的方法通過使用跳躍連??接直接將編碼表示從轉換器連接到解碼器。
3. 架構
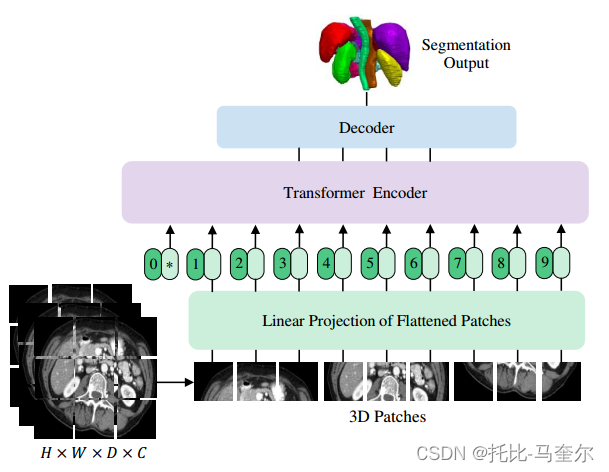
UNETR 利用由一堆變壓器組成的收縮-擴展模式作為編碼器,通過跳躍連接連接到解碼器。通過將分辨率為(H,W,D)和C個輸入通道的3D輸入體積?創建一個一維序列,將其劃分為平坦的均勻非重疊塊
,其中(P, P, P) 表示每個補丁的分辨率,
是序列的長度。
隨后,我們使用線性層講補丁投影到 K 維嵌入空間中,該空間在整個Transformer層中保持不變。為了保留提取的圖塊的空間信息,根據以下公式將一維可學習位置嵌入添加到投影圖塊嵌入
。
可學習的標記不會添加到嵌入序列中,Transformer主干是為語義分割而設計的。在嵌入層之后,利用一堆Transformer塊,其中包括多頭自注意力(MSA)和多層感知器(MLP)子層。
?
?
其中Norm()表示層歸一化,MLP由兩個具有GELU激活函數的線性層組成,?是中間塊標識符,L是Transformer 層的數量。
MSA 子層由 n 個并行的自注意力 (SA) 頭組成。具體來說,SA 塊是一個參數化函數,它學習查詢 (q) 與序列 中相應的鍵 (k) 和值 (v) 表示之間的映射。注意力權重 (A) 是通過測量 z 中兩個元素及其鍵值對之間的相似度來計算的。
其中,?是一個比例因子,用于在不同的鍵?k 值下將參數數量保持為恒定值。使用計算出的注意力權重,序列 z 中值 v 的 SA 輸出計算如下:
?v 表示輸入序列中的值, 是縮放因子。MSA 的輸出定義為
?
?其中表示多頭可訓練參數權重。
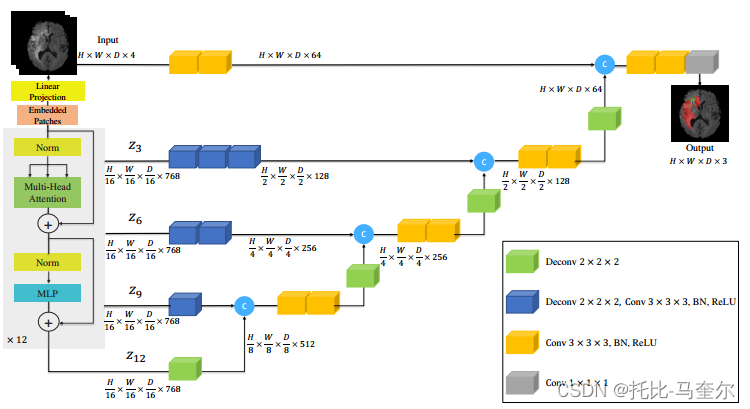
在U-Net中,編碼器的多尺度特征通常通過跳躍連接直接融合到解碼器的相應層中,以幫助保留空間細節。從Transformer 提取大小為的序列表示?
,并將它們重塑為
大小的張量。
K是特征大小(即Transformer的嵌入大小)。提取的特征序列?3×3×3卷積層完成的,這些卷積層后面通常跟著歸一化層(例如批量歸一化或層歸一化)。
在編碼器的瓶頸處(即 Transformer 的最后一層的輸出),我們將反卷積層應用于轉換后的特征圖,以將其分辨率提高 2 倍。然后,我們將調整大小后的特征圖與前一個 Transformer 輸出的特征圖(例如 z9)連接起來。并將它們輸入到連續的 3 × 3 × 3 卷積層中,并使用反卷積層對輸出進行上采樣。對所有其他后續層重復此過程,直到達到原始輸入分辨率,其中最終輸出被輸入到具有 softmax 激活函數的 1×1×1 卷積層中,以生成體素級語義預測。
3.2 損失函數
損失函數是soft dice loss 和 cross-entropy loss 的組合,并且可以根據以下方式以體素方式計算
其中 I 是體素的數量;J是類別數;表示第?
i?個體素屬于第?j?個類別的概率;?表示在one-hot編碼中,如果體素?
i?屬于類別?j,則??為1,否則為0。

)


與投影)


![[AIGC] Java CompletableFuture:簡介及示例](http://pic.xiahunao.cn/[AIGC] Java CompletableFuture:簡介及示例)



![[OpenGL] 法線貼圖](http://pic.xiahunao.cn/[OpenGL] 法線貼圖)

![[IMX6ULL驅動開發]-Linux對中斷的處理(一)](http://pic.xiahunao.cn/[IMX6ULL驅動開發]-Linux對中斷的處理(一))





